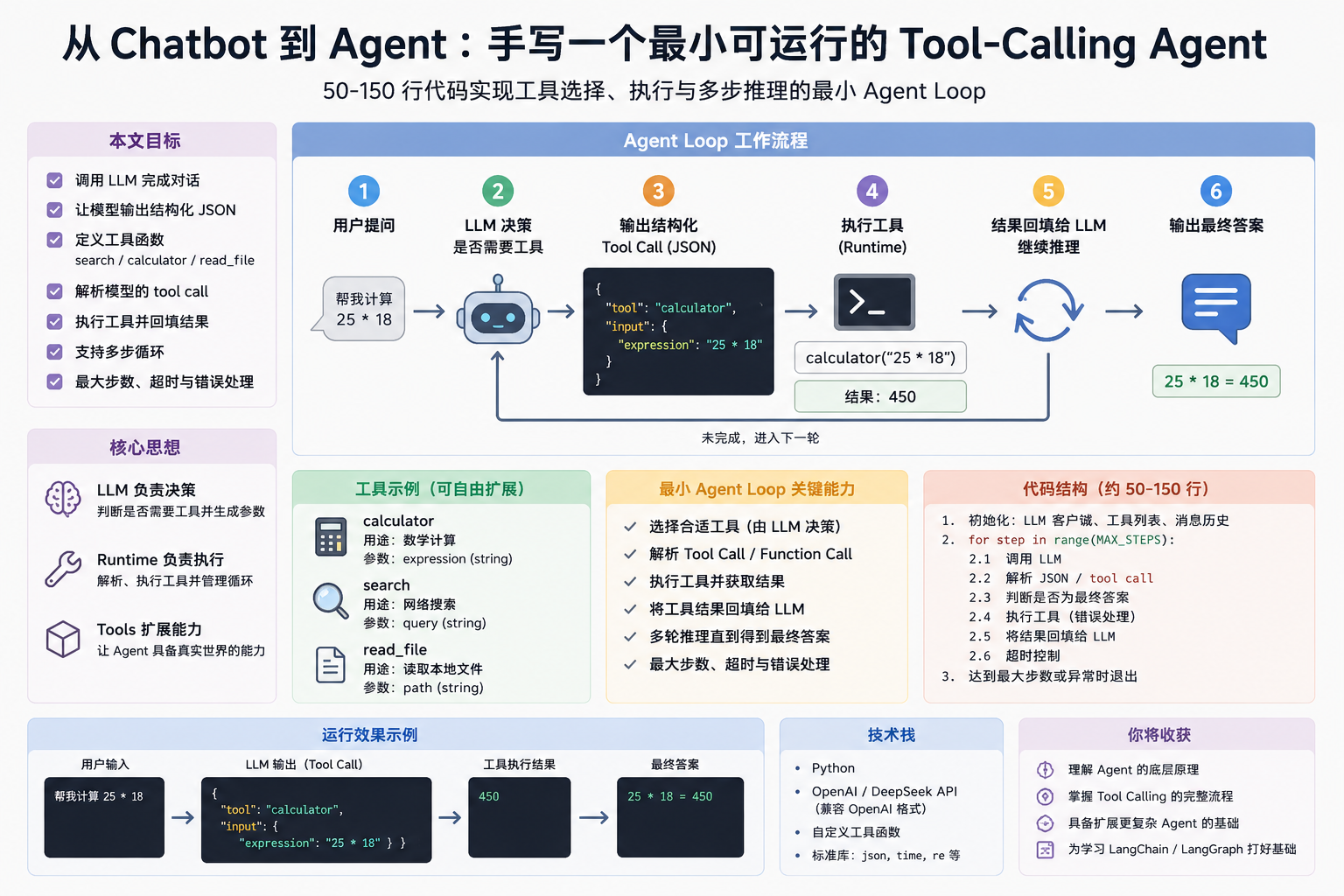
在学习大模型应用开发的过程中,我们通常从 Chatbot 开始:输入问题,调用 LLM,得到回答。但很快会发现,Chatbot 只能"回答问题",却无法"执行任务",例如计算、查文件或调用外部 API。为了解决这个问题,Agent 的概念被提出,它让 LLM 不仅能思考,还能决定是否调用工具并执行多步任务。本文将从零实现一个最小 Agent Runtime(约 50--150 行代码),不依赖任何框架,完整还原 tool calling、工具执行与结果回填的核心机制,从底层理解 Agent 的运行方式
Stage 1: Build A Minimal Agent Loop
- 会用一个 LLM API 完成普通对话。
- 会让模型输出结构化 JSON。
- 会定义一个工具函数,例如 search、calculator、read_file。
- 会解析模型的 tool call / function call。
- 会执行工具,并把工具结果喂回模型。
- 会给 agent loop 加最大步数、超时和错误处理。
推荐阅读:
产出:一个 50-150 行的最小 agent,可以选择工具、执行工具、返回最终答案。
文章目录
- [Stage 1: Build A Minimal Agent Loop](#Stage 1: Build A Minimal Agent Loop)
-
- [1.用一个 LLM API 完成普通对话](#1.用一个 LLM API 完成普通对话)
-
- [标准 4 种 role](#标准 4 种 role)
- [2.让模型输出结构化 JSON](#2.让模型输出结构化 JSON)
- [3.定义一个工具函数,例如 search、calculator、read_file](#3.定义一个工具函数,例如 search、calculator、read_file)
- [4.解析模型的TOOL CALL](#4.解析模型的TOOL CALL)
- 5.执行工具,并把工具结果返回给模型
- [6.给agent loop加最大步数、超时和错误处理](#6.给agent loop加最大步数、超时和错误处理)
1.用一个 LLM API 完成普通对话
1)安装依赖:
bash
pip install openai python-dotenv2)创建.env
DEEPSEEK_API_KEY=你的deepseek key3)创建main.py实现普通聊天
python
from openai import OpenAI
from dotenv import load_dotenv
import os
# 读取 .env
load_dotenv()
# 创建 DeepSeek Client
client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com"
)
# 调用模型
response = client.chat.completions.create(
model="deepseek-chat",
messages=[
{
"role": "user",
"content": "你好"
}
]
)
# 输出结果
print(response.choices[0].message.content)标准 4 种 role
1. system(系统消息)
用来定义"规则 / 角色 / 行为约束"
python
{"role": "system", "content": "你是一个严谨的AI助手"}特点:
- 最优先级
- 定义模型"性格 + 规则 + 工具使用方式"
- 通常只出现 1 条(放最前面)
2. user(用户消息)
就是用户输入
python
{"role": "user", "content": "帮我算 2+2"}特点:
- 每次用户输入都会新增一条
- Agent 的起点
3. assistant(模型输出)
LLM 的回答
python
{"role": "assistant", "content": "答案是 4"}特点:
- 模型生成的内容
- Agent loop 的"思考步骤"之一
4. tool(工具返回结果)🔥(Agent 核心)
工具执行后的结果
python
{
"role": "tool",
"content": "4"
}特点:
- 只在 tool calling / function calling 场景出现
- 用来"喂回工具结果"
- Agent loop 的关键闭环
2.让模型输出结构化 JSON
让模型输出结构化 JSON,本质不是"让它变成 JSON",而是:约束它的输出格式
-
法一:在prompt里强制要求JSON
pythonmessages = [ { "role": "system", "content": "你是一个数据输出助手,请只输出 JSON,不要解释,不要多余文本。" }, { "role": "user", "content": "给我一个用户信息:名字张三,年龄20" } ] -
法二:明确JSON schema
pythonmessages = [ { "role": "system", "content": """ 你必须严格按照以下 JSON 格式输出: { "name": string, "age": number } 禁止输出任何额外文本。 """ }, { "role": "user", "content": "张三 20岁" } ] -
法三:用 response_format(如果 SDK 支持)
pythonresponse = client.chat.completions.create( model="deepseek-chat", messages=[...], response_format={"type": "json_object"} )注意:即使规定了
response_format={"type": "json_object"},仍然建议在 system prompt 里说明 JSON 输出二者是双保险+不同分工
-
response_format={"type": "json_object"}在API层约束强制模型必须输合法JSON出在生成过程中就被"锁死格式"
-
system prompt在prompt层引导模型按结构思考
-
3.定义一个工具函数,例如 search、calculator、read_file
Tool 本质就是"带描述的函数",描述是给 LLM 看的,函数是给 Runtime 执行的,LLM负责决定何时调用
User
↓
LLM(决定用不用工具)
↓
JSON(tool + input)
↓
Python执行工具
↓
结果回填给LLM
↓
LLM输出最终答案eg:
python
from datetime import datetime
def calculator(expression: str):
return eval(expression)
# eval:Python 内置函数
# 把字符串当 Python 代码执行
def get_time():
return datetime.now().strftime("%Y-%m-%d %H:%M:%S")
def read_file(filename: str):
with open(filename, "r", encoding="utf-8") as f:
return f.read()
# Tool描述 给LLM看
TOOlS = [
{
"name": "calculator",
"description": "用于数字计算",
"parameters": {
"expression": "数学表达式"
}
},
{
"name": "get_time",
"description": "获取当前时间",
"parameters": {}
},
{
"name": "read_file",
"description": "读取文件内容",
"parameters": {
"filename": "文件名"
}
}
]
# 工具注册表
TOOl_MAP = {
"calculator": calculator,
"get_time": get_time,
"read_file": read_file
}把TOOL介绍和问题组成成prompt发给LLM
python
from tools import TOOlS
from openai import OpenAI
from dotenv import load_dotenv
import os
import json
load_dotenv()
client = OpenAI(
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com"
)
# 动态构建 Tool Prompt
tool_prompt = ""
for tool in TOOlS:
tool_prompt += f"""
工具名: {tool["name"]}
用途: {tool["description"]}
参数: {tool["parameters"]}
"""
# 拼接 SYSTEM PROMPT
SYSTEM_PROMPT = f"""
你是一个AI Agent。
你可以使用以下工具:
{tool_prompt}
规则:
1. 你必须只输出JSON
2. 不要输出Markdown
如果需要调用工具:
{{
"tool": "工具名",
"input": {{
"参数名": "参数值"
}}
}}
如果任务完成:
{{
"tool": "final",
"answer": "最终答案"
}}
"""
# print(SYSTEM_PROMPT)
messages = [
{
"role": "system",
"content": SYSTEM_PROMPT
},
{
"role": "user",
"content": "帮我算 25 * 18"
}
]
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
temperature=0
)
content = response.choices[0].message.content
# print("\n===== LLM原始输出 =====")
# print(content)4.解析模型的TOOL CALL
把模型输出的"工具调用描述(通常是 JSON / 文本)解析成可执行的函数参数"
python
# 清洗 markdown(防止模型输出 ```json)
content = content.replace("```json", "")
content = content.replace("```", "")
content = content.strip()
# JSON解析
data = json.loads(content)
print("\n===== 解析后的Python对象 =====")
print(data)
print("\n===== Tool Name =====")
print(data["tool"])
print("\n===== Tool Input =====")
print(data["input"])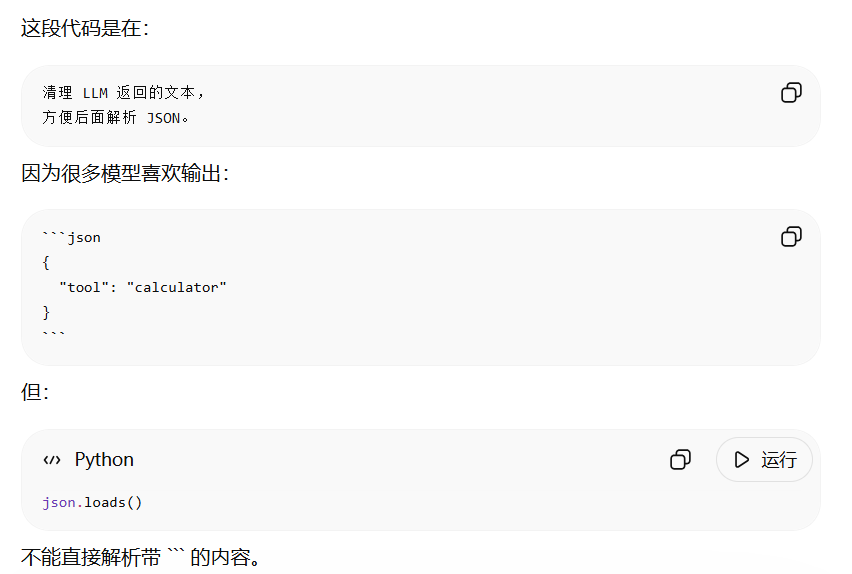
5.执行工具,并把工具结果返回给模型
1.执行工具
python
# 5.执行TOOL
tool_name = data["tool"] # 拿到工具名
tool_func = TOOl_MAP[tool_name] # 找到真正的函数
tool_input = data["input"]
result = tool_func(**tool_input)
print(result)**就是把字典"拆开",变成函数的命名参数,拆成 key=value 形式
2.把工具结果返回给模型
python
# 6.把工具结果返回给LLM
messages.append({
"role": "assistant",
"content": json.dumps(data) # 上一次 tool call
})
messages.append({
"role": "user",
"content": f"工具执行结果:{result}"
})assistant代表LLM
为啥要把上回大模型输出的也发回去,只发TOOl处理结果还不够吗?
因为LLM 每次调用都是"重新读上下文做推理",只给 tool 结果它不知道这个结果是怎么来的,也不知道该回答什么问题。
再次调用LLM(第二轮思考)
python
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
temperature=0
)
final_output = response.choices[0].message.content
print("最终输出:", final_output)6.给agent loop加最大步数、超时和错误处理
python
MAX_STEPS = 5
import time
for step in range(MAX_STEPS):
print(f"\n===== Step {step+1} =====")
try:
# ======================
# 1. 调 LLM
# ======================
response = client.chat.completions.create(
model="deepseek-chat",
messages=messages,
temperature=0,
)
content = response.choices[0].message.content
# 清洗 JSON
content = content.replace("```json", "").replace("```", "").strip()
data = json.loads(content)
print("LLM输出:", data)
# ======================
# 2. 判断是否结束
# ======================
if data["tool"] == "final":
print("\n🎯 FINAL ANSWER:")
print(data["answer"])
break
# ======================
# 3. 执行工具(加错误保护)
# ======================
tool_name = data["tool"]
tool_input = data["input"]
if tool_name not in TOOL_MAP:
tool_result = f"错误:未知工具 {tool_name}"
else:
try:
tool_func = TOOL_MAP[tool_name]
tool_result = tool_func(**tool_input)
except Exception as e:
tool_result = f"工具执行失败: {str(e)}"
print("工具结果:", tool_result)
# ======================
# 4. 回填给 LLM
# ======================
messages.append({
"role": "assistant",
"content": json.dumps(data)
})
messages.append({
"role": "user",
"content": f"工具执行结果:{tool_result}"
})
# ======================
# 5. 超时控制(简单版)
# ======================
time.sleep(0.2)
except json.JSONDecodeError:
print("❌ JSON解析失败")
break
except Exception as e:
print("❌ Agent运行错误:", str(e))
break
else:
print("\n⚠️ 达到最大步数,强制结束")总结 :Agent 本质上就是:LLM 负责思考决策,程序负责解析、调用工具、执行循环,并把结果再反馈给 LLM 继续决策