
◆ 博主名称: 小此方-CSDN博客 大家好,欢迎来到小此方的博客。
⭐️Linux系列个人专栏: 【主题曲】Linux
⭐️此方的GitHub: github_此方
⭐️ Re系列专栏:我们思考 (Rethink) · 我们重建 (Rebuild) · 我们记录 (Record)
文章目录
- 概要&序論
- 零、深化对程序地址空间的认知
- [一、 什么是进程地址空间](#一、 什么是进程地址空间)
-
- [1.1 核心概念导入](#1.1 核心概念导入)
- [1.2 进程的独立性](#1.2 进程的独立性)
- [二、 地址空间是如何被管理的](#二、 地址空间是如何被管理的)
-
- [2.1 先描述,再组织和mm_struct(内存描述符)](#2.1 先描述,再组织和mm_struct(内存描述符))
- [2.2 区域划分的本质](#2.2 区域划分的本质)
- 2.3区域划分的规则细节
- 三、进程地址空间到物理地址空间的完整映射过程
- 四、为什么要有进程地址空间
- 五,概念补充与理解深化
- [六、 Linux 虚拟地址空间的管理核心](#六、 Linux 虚拟地址空间的管理核心)
-
- [6.1 零散虚拟内存空间的管理困境](#6.1 零散虚拟内存空间的管理困境)
-
- 6.1.1vm_area_struct结构体详解
- [6.1.2 由 vm_area_struct 构成的链表](#6.1.2 由 vm_area_struct 构成的链表)
- [6.2.1 核心源码剖析](#6.2.1 核心源码剖析)
- [6.3 VMA 增长引发的问题与红黑树优化](#6.3 VMA 增长引发的问题与红黑树优化)
-
- [6.3.1 为什么 VMA 会变多?](#6.3.1 为什么 VMA 会变多?)
- [6.3.2 红黑树优化机制](#6.3.2 红黑树优化机制)
- [6.4 关键思考](#6.4 关键思考)
-
- [6.4.1 vm_area_struct 与 mm_struct 的字段重复问题](#6.4.1 vm_area_struct 与 mm_struct 的字段重复问题)
- [6.4.2 为什么不需要将所有地址空间硬性连接?](#6.4.2 为什么不需要将所有地址空间硬性连接?)
概要&序論
Hello大家好,我是此方 ,本文将带你硬核拆解 Linux 进程虚拟地址空间的底层架构。我们将看穿操作系统为进程编织的"独占内存"谎言,纵向剖析从代码段到栈区的多维布局,并直击 MMU 内存映射与缺页中断的运作本质,好,我们直接开始吧。
下文应用的平台:kernel2.6.32 ,32位平台
零、深化对程序地址空间的认知
0.1宏观概念深化
如下,是我们在C/C++学习时期所看到的程序地址空间 布局情况,今天我们要更进一步的细化这个布局,方便我们后续的解释。
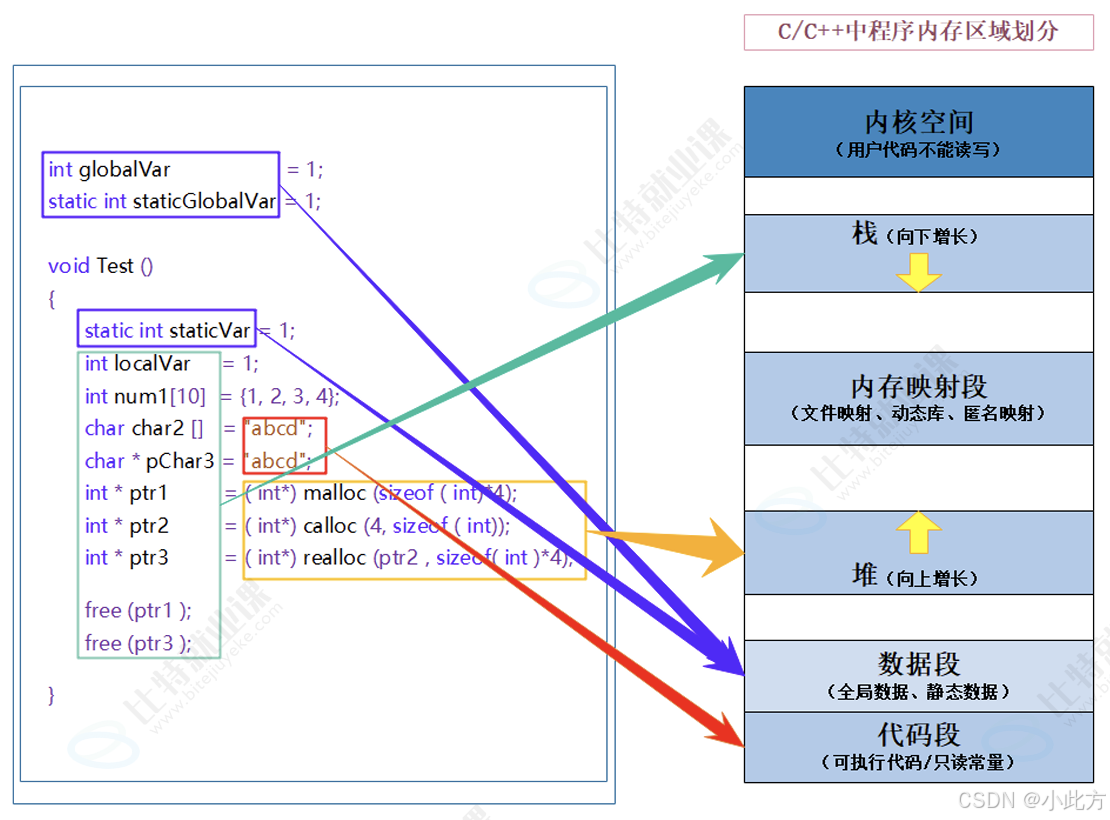
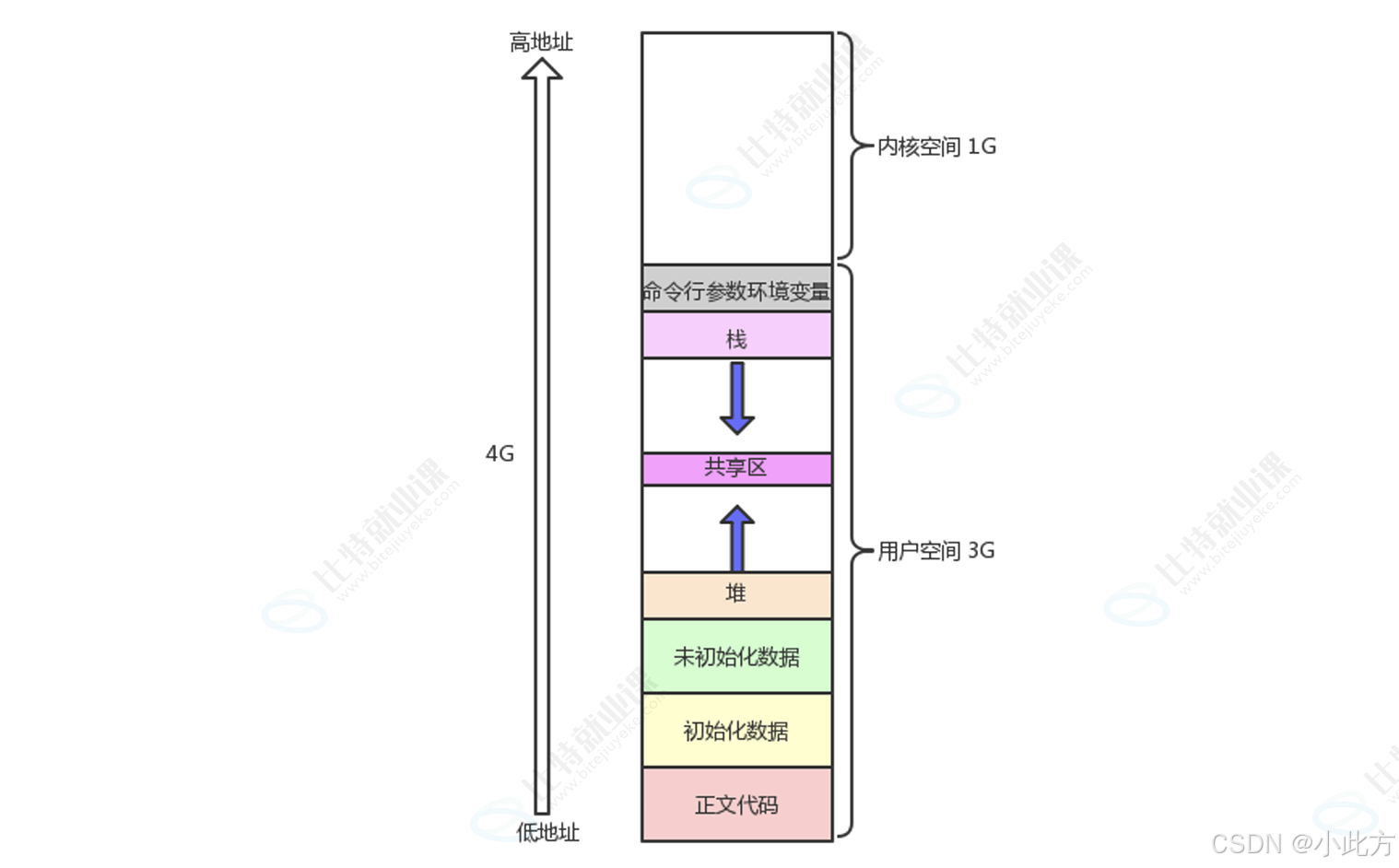
如下,我们将数据段分为初始化数据区域和未初始化数据区域 ,在栈区域的上面划分出了"命令行参数和环境变量区域 "。栈和堆之间的一大块空白(叫镂空 更好)区域是共享区 。内核空间我们不讲。
0.2微观细节补充
0.2.1代码段与只读数据段
好,我现在要补充一些细节: 第一个:常量字符串存在哪里?常量字符串在编译的时候是被硬编码成为只读数据段,只读数据段和代码被放在了一个区域,所以大家都在代码段这个内存区域 ,但是进一步细分,只读数据段应该在代码段的上面。
▲ 高地址
│
├─ .bss (未初始化全局/静态变量)
├─ .data (已初始化全局/静态变量)
│
├─ .rodata (只读数据段:存放常量字符串、const全局变量) ◄─── 地址较高
├─ .text (正文代码段:存放机器指令) ◄─── 地址较低
│
▼ 低地址 (0x400000 左右或由 PIE 随机化的基地址)0.2.2初始化数据区域和未初始化数据区域
已初始化数据区 (.data 段):
- 存什么 :存储在代码中明确赋了初值的全局变量和静态变量。
- 特点:这些初始值直接存储在可执行二进制文件中,程序加载时直接读入内存。
未初始化数据区 (.bss 段):
- 存什么 :存储在代码中没有赋初值(或赋初值为 0)的全局变量和静态变量。
- 特点 :在可执行文件中不占据实际磁盘空间(只记录大小)。程序启动后,操作系统会自动将这块内存全部清零。
| 变量类型 | 存储位置 | 生命周期 |
|---|---|---|
| 普通局部变量 | 栈 | 函数调用结束即销毁 |
| 已初始化全局/静态变量 | .data 段 | 程序结束才销毁 |
| 未初始化全局/静态变量 | .bss 段 | 程序结束才销毁 |
| 动态内存 | 堆 | 手动释放或程序结束销毁 |
0.2.3矫正错误观念
我们之前在C/C++内存管理的学习中,用了上面这个图,但是在任何一本C/C++教学的书中都不会有这张图,因为这根本就不是语言层的知识。 它是操作系统层的内容。
Re:从零开始的 C++ 入門篇(十一):全站最全面的C/C++内存管理的底层剖析与硬核指南
我们要矫正一个名称"程序地址空间",不应该这么叫,而应该叫 "进程地址空间"或者是"虚拟地址空间"。 为什么这么叫?虚拟地址空间是内存吗?答:"虚拟地址空间不是物理内存"。
下面这个代码,我们在进程父子关系中提到过,同一个地址映射出两个不同的值,这就证明了:"虚拟地址空间不是物理内存"。
cpp
#include <stdio.h>
#include <unistd.h>
int gval = 100;
int main(){
pid_t id = fork();
if(id == 0){
while(1){
printf("子: gval: %d, &gval: %p, pid: %d, ppid: %d\n", gval, &gval, getpid(), getppid());
sleep(1); gval++;
}
}
else{
while(1){
printf("父: gval: %d, &gval: %p, pid: %d, ppid: %d\n", gval, &gval, getpid(), getppid());
sleep(1);
}
}
}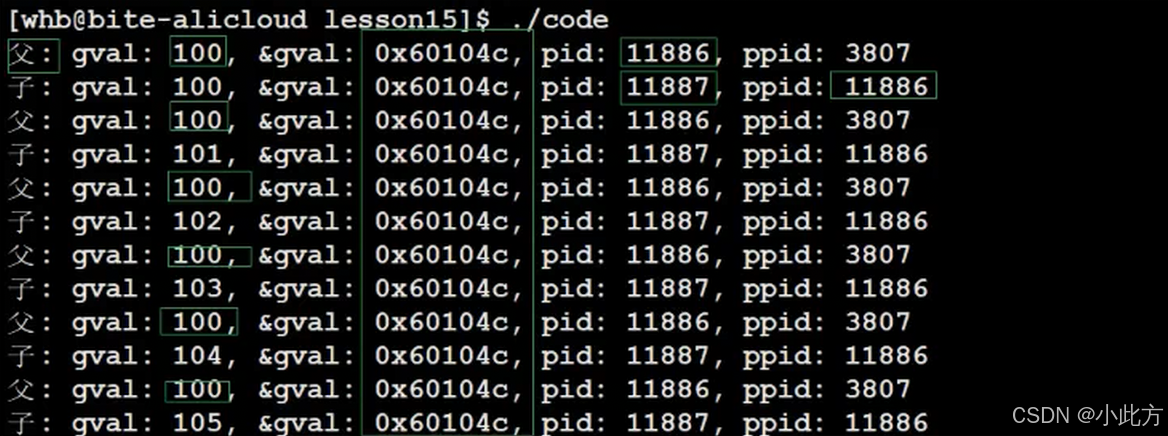
- 变量内容不一样,所以父子进程输出的变量绝对不是同一个变量
- 但地址值是一样的,说明,该地址绝对不是物理地址!
- 在Linux地址下,这种地址叫做 虚拟地址
- 我们在用C/C++语言所看到的地址,全部都是虚拟地址!物理地址,用户一概看不到,由OS统一管理。
- OS必须负责将虚拟地址转化成物理地址。
对!你没有听错,虚拟地址空间不是物理内存!很颠覆,但是读完整篇文章后你就会明白。
一、 什么是进程地址空间
1.1 核心概念导入
1.1.1大富翁的例子
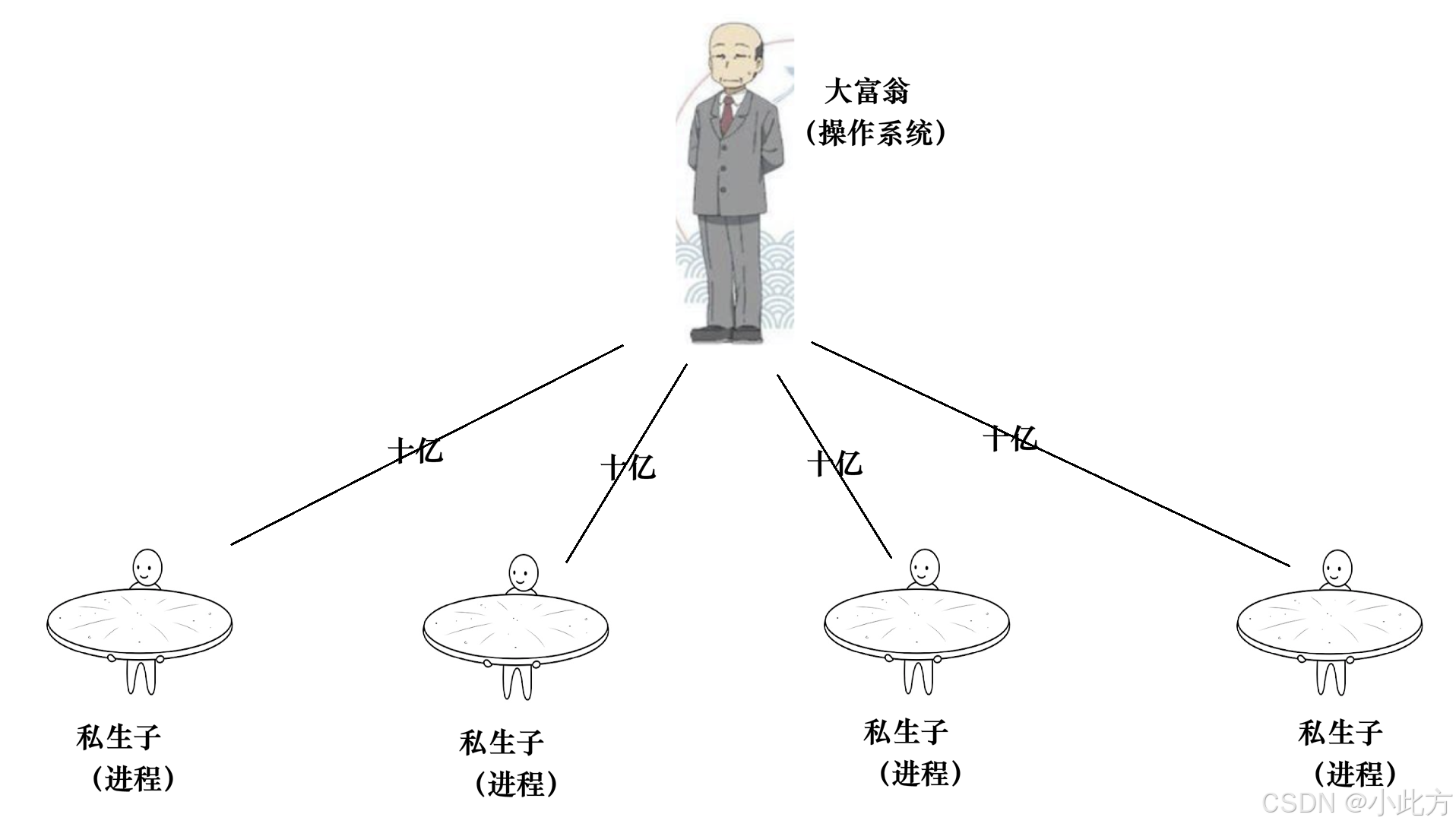
究竟什么是进程地址空间?我有一个大富翁例子 :
一个身价 10 个亿的大富翁,他有 4 个私生子。这 4 个私生子彼此之间互不相识,都以为自己是独生子。富翁对每个私生子都画了一个大饼:"儿子,我这 10 个亿的资产未来全是你的! " 于是,每个私生子都认为自己拥有 10 个亿。当私生子 A 想向富翁要 50 万买车时,富翁随手就给了他;私生子 B 想要 100 万创业,富翁也满足了。
1.1.2进程地址空间的概念
在上面的故事中,大富翁就是操作系统(OS) ,他手里的 10 亿资产就是物理内存 。而那 4 个私生子就是操作系统中的一个个进程 ,富翁给他们画的大饼就是"虚拟地址空间"。
操作系统通过这种方式,让每一个进程都认为自己独占了整个系统的物理内存资源 (在 32 位机器下就是 4GB)。进程可以任意规划它的内存分配(代码、栈、堆等布局),但实际上,只有当它真正需要物理内存时 ,操作系统才通过某种映射机制,在物理内存上切出来给他们。
1.2 进程的独立性
操作系统为什么要费尽心机搞这么一套虚拟地址空间呢?核心原因在于保证进程的独立性。
- 内核数据结构独立 :每个进程都有自己专属的
task_struct等等。 - 代码和数据独立 :通过虚拟地址到物理地址的映射,不同进程的代码和数据被隔离开,加载进物理内存的不同区域。一个进程崩溃、乱写内存,绝对不会影响到另一个进程。
二、 地址空间是如何被管理的
2.1 先描述,再组织和mm_struct(内存描述符)
大富翁给私生子画的大饼,总不能只是口头说说,他必须在自己的本子上记录下每个私生子的情况。同样的,虚拟地址空间虽然是"虚拟"的,但操作系统也必须对其进行管理。
Linux 管理地址空间的内核设计哲学依然是:先描述,再组织。
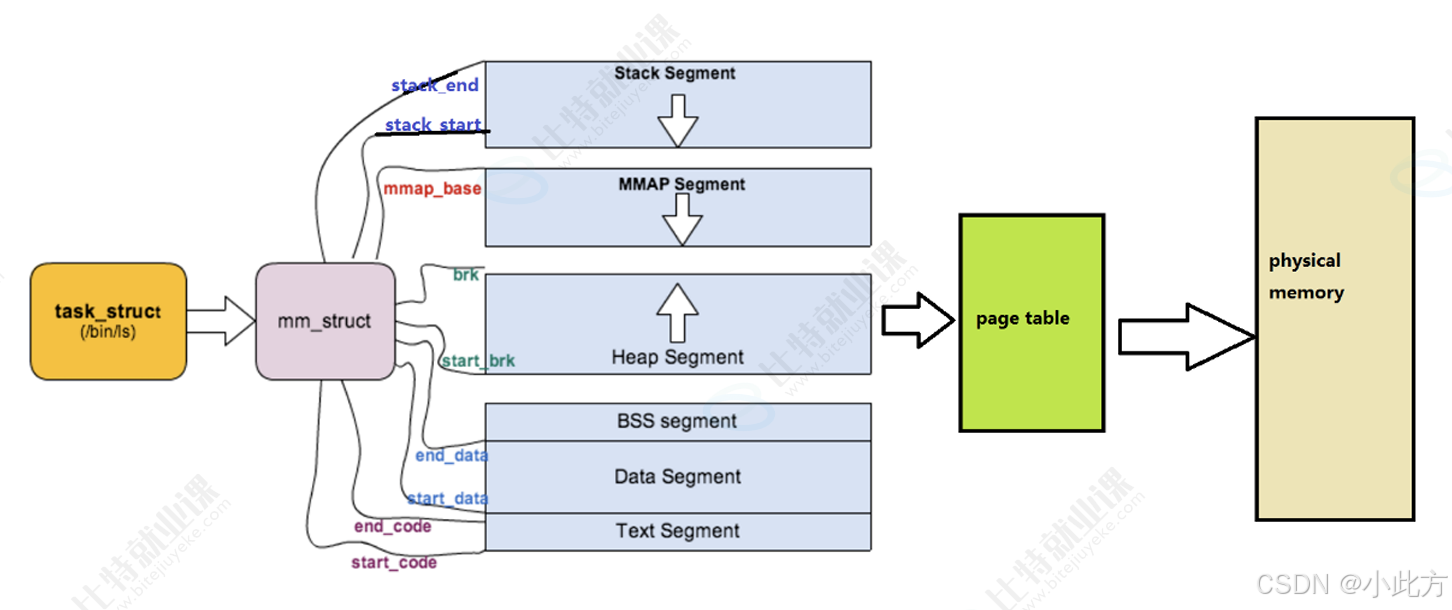
在 Linux 内核中,进程地址空间本质上是一个内核数据结构 ,叫做 struct mm_struct 。每一个进程的进程控制块 struct task_struct 中,都包含一个指向其专属 mm_struct 的指针 struct mm_struct *mm;
cpp
struct task_struct
{
/*...*/
struct mm_struct *mm;
//对于普通的用户进程来说该字段指向
//他的虚拟地址空间的用户空间部分,
//对于内核线程来说这部分为NULL。
struct mm_struct *active_mm;
// 该字段是内核线程使用的。当该进程是内核线程时,
//它的mm字段为NULL,表示没有内存地址空间,
//可也并不是真正的没有,这是因为所有进程关
//于内核的映射都是一样的,
//内核线程可以使用任意进程的地址空间。
/*...*/
}我知道你 上的注释一定看不懂,因为这是线程的知识,我们后面会讲。你只需要知道一点,真正指向mm_struct的是后面那个指针。
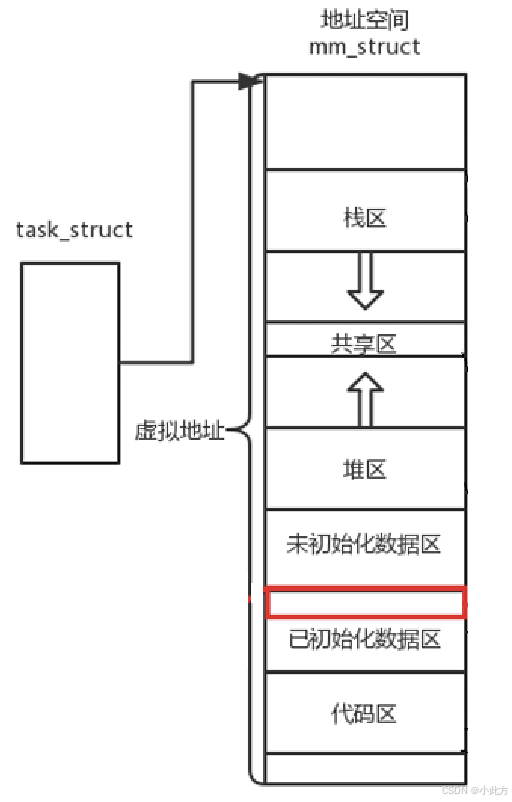
可以说,mm_struct 结构是对整个用户空间的描述。每一个进程都会有自己独立的 mm_struct,这样每一个进程都会有自己独立的地址空间才能互不干扰。先来看看由 task_struct 到 mm_struct,进程的地址空间的分布情况:
2.2 区域划分的本质
2.2.1从"分桌子"引入
我们在前文看到的堆区、栈区、代码区,在内核中究竟是怎么划分的?
其实非常简单,就像你跟你女同桌给自己的桌子划分区域一样。如果一张桌子长 100cm,你同桌想和你五五分,只需要在心里或者用刻度定义:[0, 49] 是我的区域,[50, 100] 是同桌的区域。
区域划分的本质:"确认区域的开始和结束位置"
2.2.2mm_struct内部的实现原理
在 struct mm_struct 内部,就是通过大量的整数变量(刻度)来定义和调整各个区域的边界 。在 32 位机器下,虚拟地址的范围是 0x00000000 到 0xFFFFFFFF(4GB)
cpp
struct mm_struct {
unsigned long total_vm; // 进程总虚拟内存大小
// 区域边界描述
unsigned long start_code, end_code; // 代码段的开始与结束
unsigned long start_data, end_data; // 初始化数据段的开始与结束
unsigned long start_brk, brk; // 堆区的开始与当前边界
unsigned long start_stack; // 栈区的开始位置
unsigned long arg_start, arg_end; // 命令行参数区域
unsigned long env_start, env_end; // 环境变量区域
// ... 后文会进一步扩展
}; 区域调整的本质: 比如当我们进行所谓的"堆区扩容"(例如 C 语言中的 malloc 或 C++ 中的 new),在虚拟地址空间层面的操作,其实就是让 brk 边界指针向高地址方向移动,即 brk += size;。这就是区域划分与调整 的底层逻辑。
2.3区域划分的规则细节
以32位系统为例子,按理说 区域划分的数值应该在(0,3GB)的区间内。
2.3.1顶部:stack_start
stack_start :确实在 3GB 附近,但它是"浮动"在 32 位 Linux 中,用户空间的最高地址确实是 0xC0000000 (3GB)。
- 理论上 :栈底(起始点)应该就是 0xC0000000。
- 现实中 :为了防止黑客利用固定的内存地址进行攻击(这种攻击叫缓冲区溢出),Linux 引入了 ASLR(地址空间布局随机化)。
- 结果 :每次你运行程序,stack_start 会在 3GB 往下的一小段范围内随机跳动 。比如这次是 0xBFFFFA00 ,下次可能是 0xBFFFFC10。开天辟地它永远"撑"在最顶端。
2.3.2底部:code_start
code_start :并不是从 0x00000000 开始,这可能出乎你的意料。在 Linux 中,虚拟地址 0 附近的一段空间通常是禁止访问的。
- 为什么 :为了捕获空指针(NULL)错误。
- 逻辑 :如果 code_start 真的从 0 开始,那么当你写了 **int p = NULL; p = 1; 时,程序可能会真的改写掉你的代码段。
- 现实 :在经典的 32 位系统里,代码段通常从 0x08048000 开始。从 0 到这个地址之间是一片"禁区"。一旦你的 C++ 代码尝试访问这个区间的数值,就会立刻报错,Segmentation Fault。
| 锚点变量 | 作用 | 现实特征 |
|---|---|---|
| start_stack | 虚拟空间的天花板 | 靠近 3GB,程序运行期间不再变动。 |
| start_code | 虚拟空间的地基 | 靠近 0,程序运行期间不再变动。 |
补充概念:页表
进程手里的
mm_struct仅仅是一张蓝图,它给出的地址全是虚拟地址 。当 CPU 需要真正执行指令、读取数据时,必须将虚拟地址转换为物理内存地址 。负责这个转换的核心是页表(Page Table)。
三、进程地址空间到物理地址空间的完整映射过程
3.1初始化虚拟地址空间和构建虚拟物理映射关系的全过程
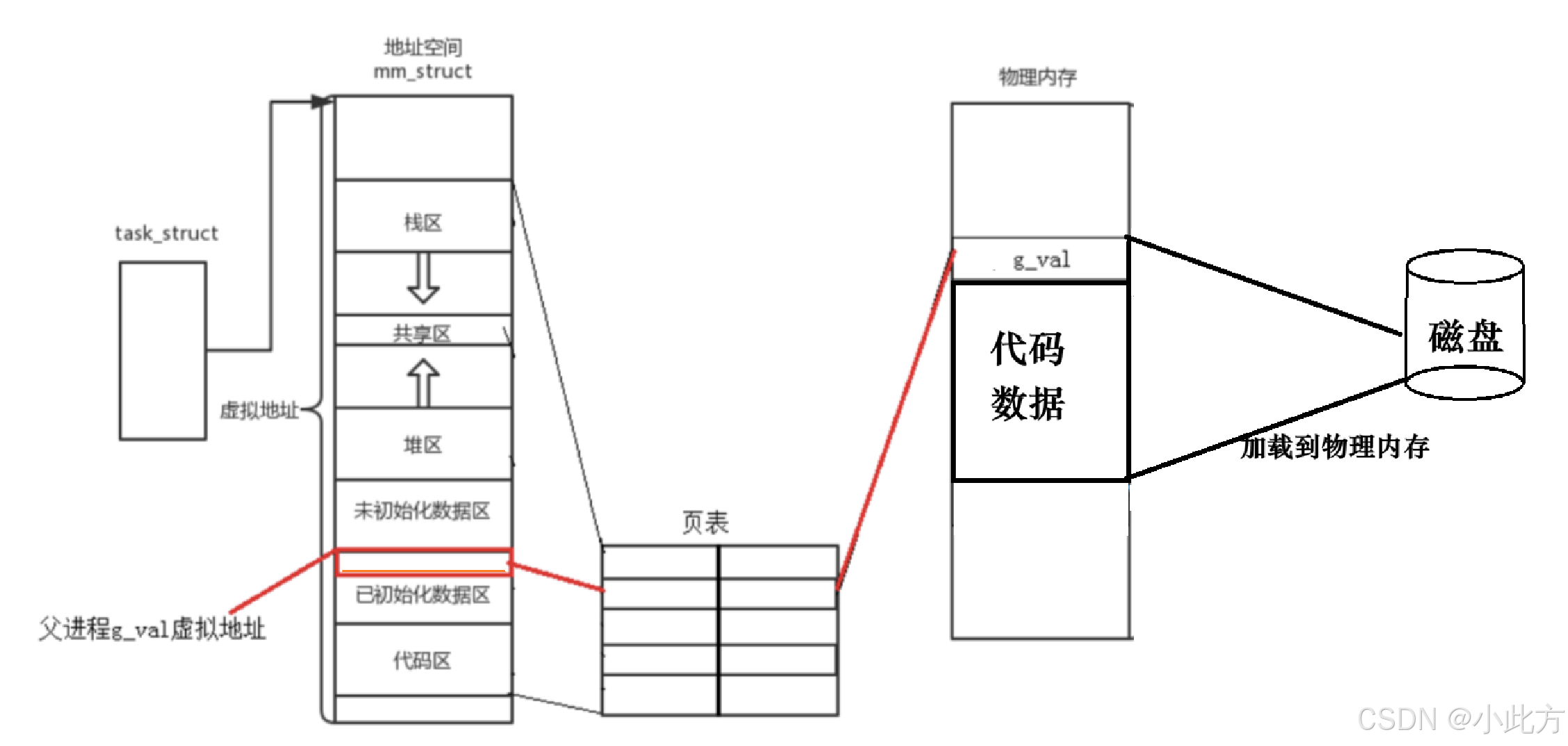
如上图,进程创建后,操作系统会为你的进程创建三个东西:PCB、进程地址空间、页表。
必须先创建 task_struct、mm_struct 等内核数据结构,然后再加载(映射)代码和数据。
- 申请物理内存,把进程的代码和数据拷贝到物理内存当中。
- 在虚拟地址空间中根据代码和数据的大小,给所有的指针(整型)赋值,让他们指向初始位置
- 开始填表:将所有的代码和数据在虚拟地址空间中的地址填入页表的左侧。将所有代码和数据在物理内存中的地址填入页表的右侧
- 访问:g_val首先在虚拟地址空间中找到g_val的地址,然后到页表中去查找映射关系,对应到物理内存中的地址。找到数值返回
补充细节
一个整型有四个字节,于是有四个地址来存储,我们取得它的地址就是取得其中最小的那个地址。那么如何访问到数据?
首地址取得+变量类型(偏移量计算)=实际取得的数据
3.2子进程拷贝父进程与引发的写时拷贝
3.2.1子进程拷贝父进程
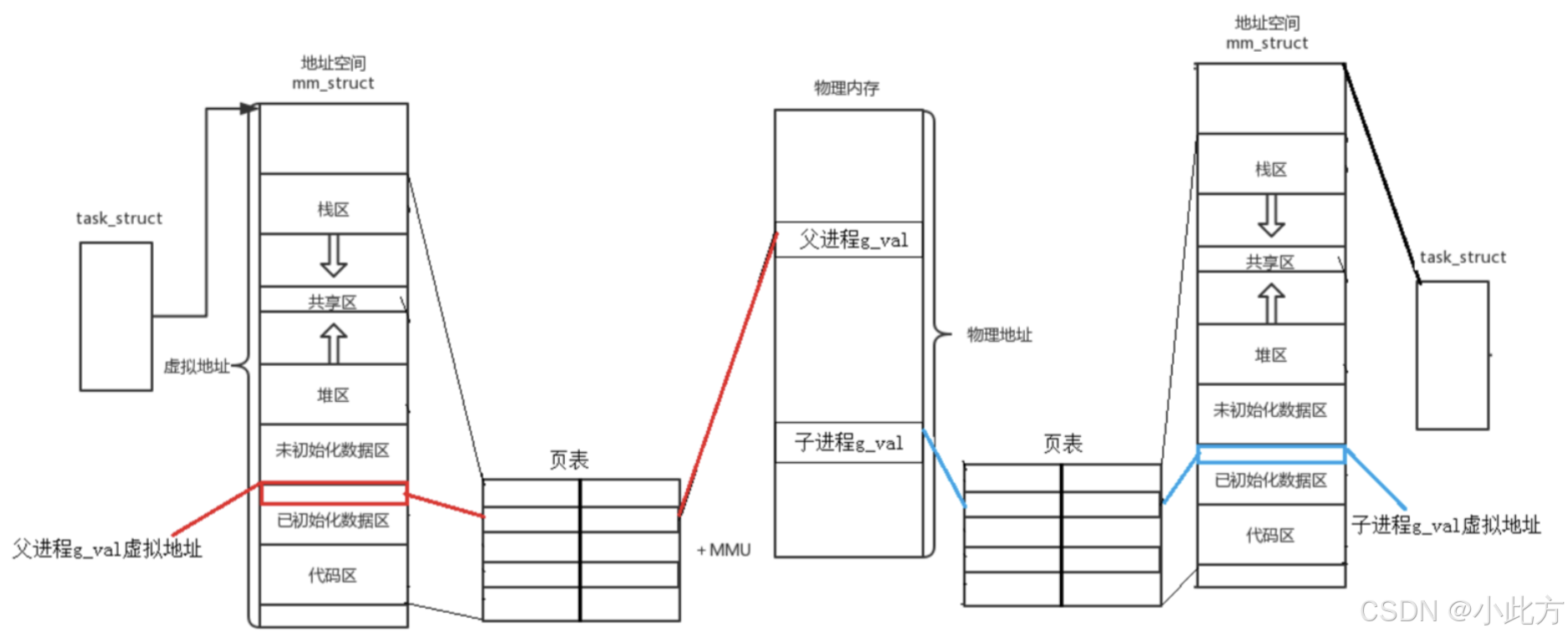
当子进程被创建时,它会拷贝 父进程的1.PCB 2. 进程地址空间 3. 页表. (因此两者的代码和数据也基本一样)
子进程也复制了父进程的页表 ,所以初始状态下,父子进程的虚拟地址映射到了同一块物理内存 上。
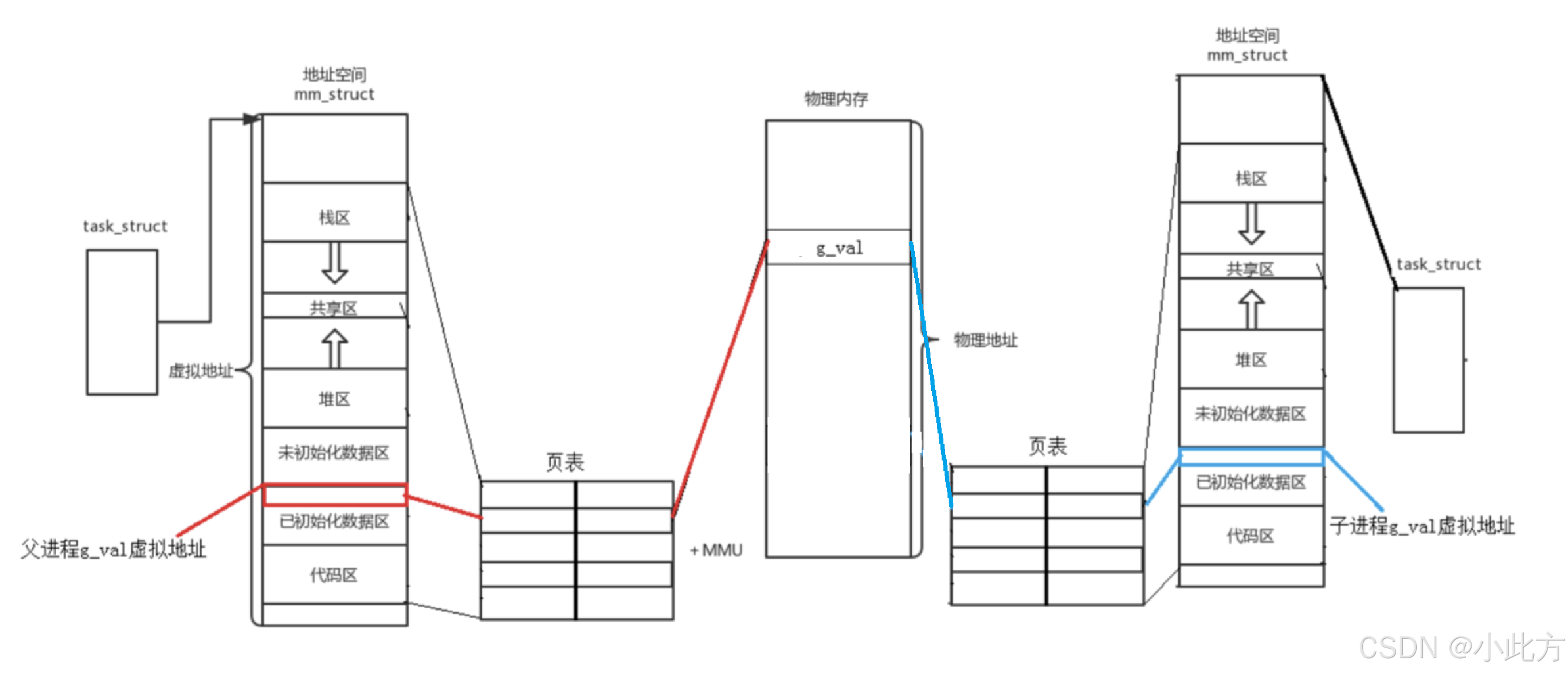
3.2.2子进程写时拷贝
子进程对某个变量进行修改写入,子进程发生了写时拷贝。 于是就出现了,同一个 "数值一致" 的虚拟地址映射出两个不同的物理地址。
四、为什么要有进程地址空间
我们不免会产生一个核心疑问:为什么不让进程直接访问物理内存? ,而一定要在中间横插一层虚拟地址空间?事实上,现代操作系统之所以大费周章地构建出这套虚拟地址体系,主要为了解决以下三大核心问题:
4.1地址有序化
这个没什么干货,很好理解。
各种乱七八糟的进程加载进内存,然后通过页表映射成为有序的虚拟地址空间。
或者一个非常大的项目加载的时候分块加载,代码东一块西一块。也可以通过页表变成有序的。
4.2保护物理地址空间
4.2.1野指针访问拒止
先说结论 :地址转换的过程中,也可以对你的地址和操作进行合法性判定,进而保护物理内存!
4.2.2页表权限位与只读访问拒止
在 X86 等架构的页表项中,除了存放物理页地址,还挤进了几个关键的标志位:
- R/W (Read/Write):读写位。如果该位为 0,表示这块内存只读。
- U/S (User/Supervisor):用户/特权位。区分这块内存是给用户进程用的(3GB 空间),还是给内核用的(1GB 空间)。
- NX (No-Execute):不可执行位。现在的操作系统会把堆和栈标记为 NX。这意味着你可以在堆里存数据,但如果你尝试跳到堆里的地址去执行指令,CPU 会拒绝。
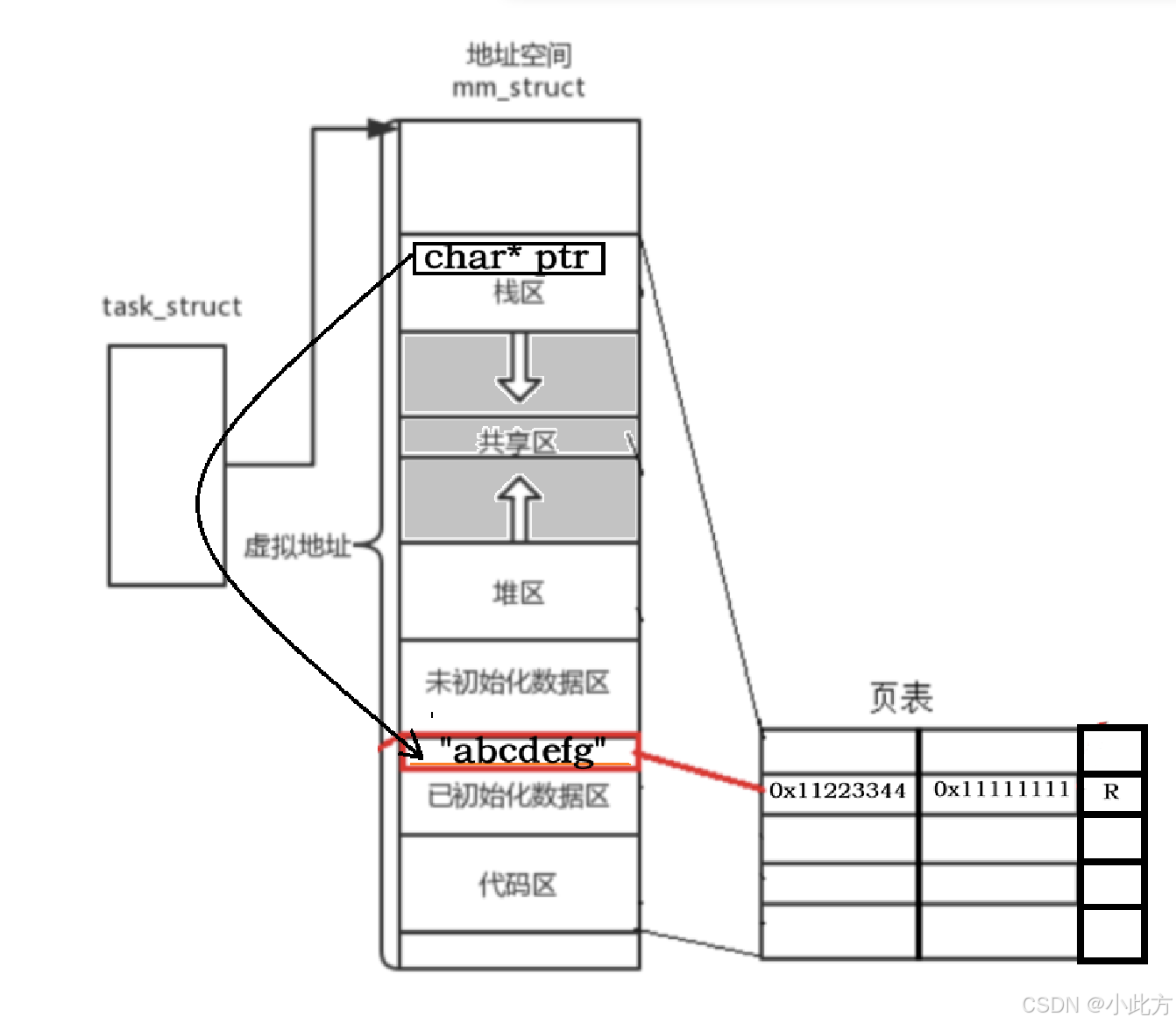
cpp
//尝试触发错误:
char *str = "helloworld";
*str = 'H';
//这是一个由栈中的一个指针指向的一个字符串常量,
//当然这里这样写实在有点挫,但是我需要这样子写来演示。为什么在字符常量区写入,就会崩溃??? 原因是字符串常量在进程地址空间的常量区---------这是以前我们的说法。如今我们有了更加深刻的见解,原因是查找页表的时候,权限拦截了!!
事实上我们不能去访问它,因为这种规则的限制,底层页表的制约。我们必须用const限制自己的手脚 const char *str = "helloworld"; ,不让我们去做这件事情这是一种编译器级别的保护,(在effectiveC++的第二条款中讲到过)
4.3操作系统的进程管理与内存管理解耦
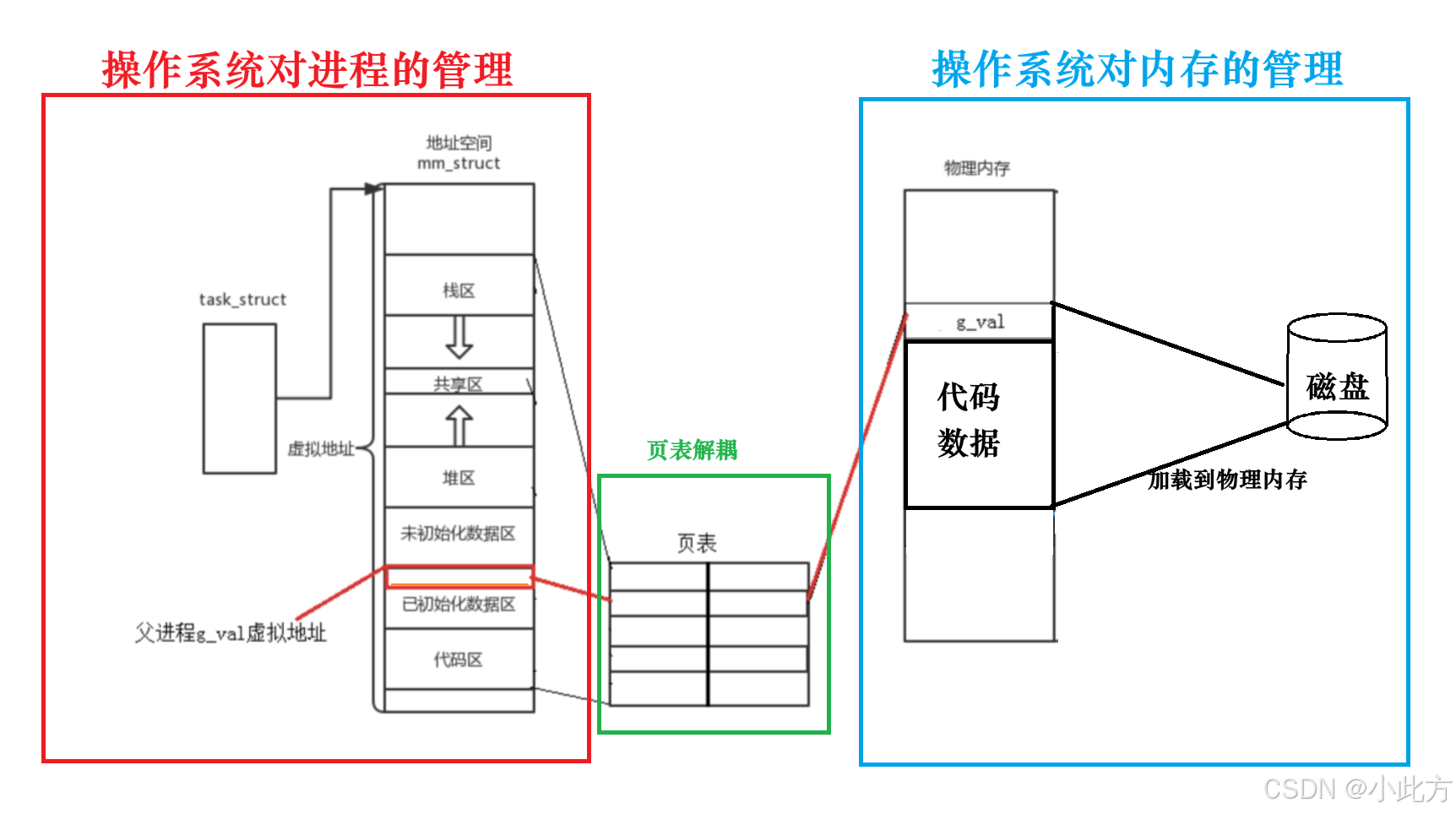
如果没有页表来解耦,PCB就必须伸出指针来直接指向物理内存,物理内存的IO操作会让PCB的指针操作异常复杂。同时也不利于维护。
五,概念补充与理解深化
5.1缺页中断
5.1.1什么是缺页中断
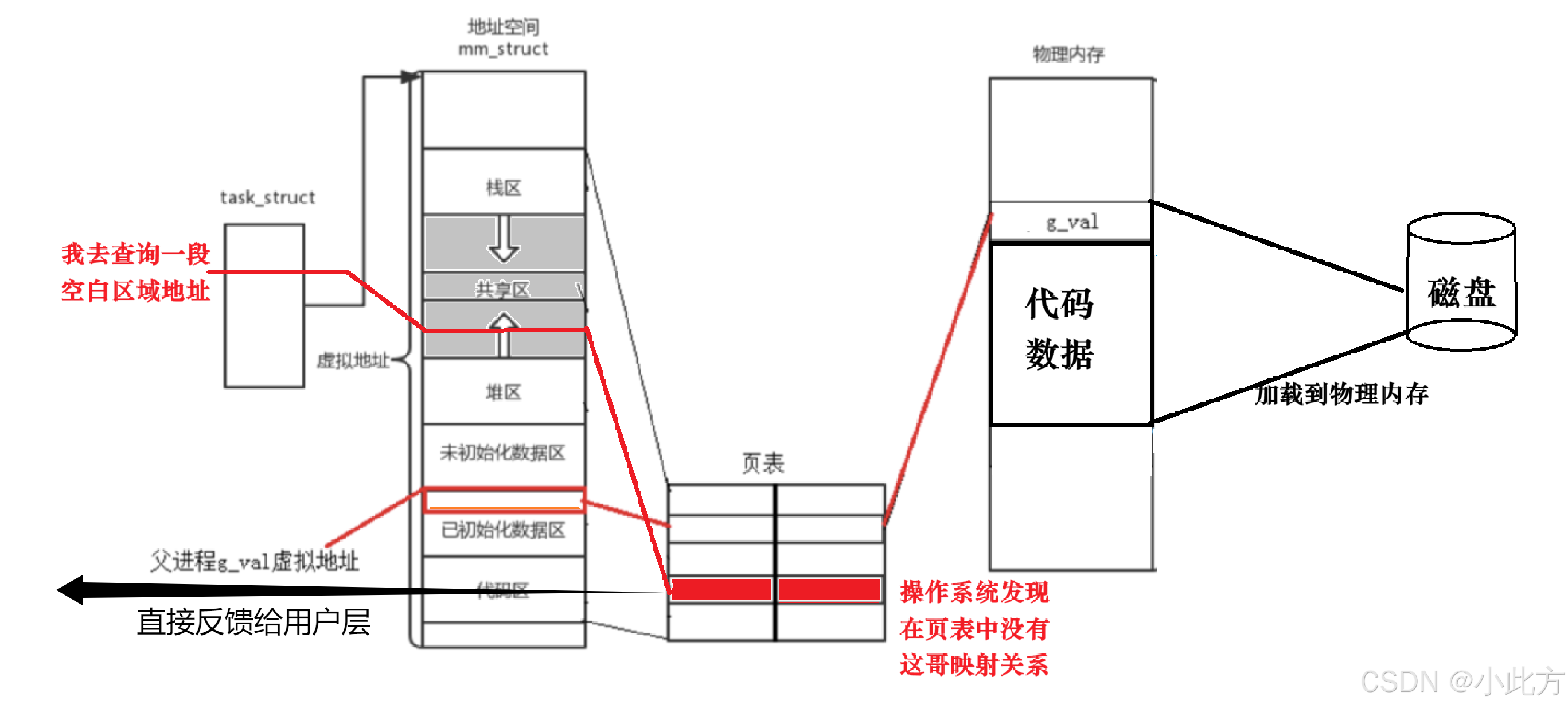
我们的物理内存是有限的,为了容纳这么多进程的代码和数据于是操作系统会进行一种操作:把代码和数据(比如一共有4GB)先全部开到虚拟地址空间里面,表示合法 。然后在物理内存中只加载500MB。并且在页表中也只建立前500MB的虚拟-物理映射。
于是当前500MB的代码跑完了,在第500MB零1段代码的时候,访问页表,发现没有对应的映射关系 ,但是由于其合法性,于是中断进程,OS访问外设,重新加载第二部分的500MB到内存,然后重新在页表建立映射关系 ,进行映射。最后继续运行。这就是缺页中断。
5.1.2更激进的缺页中断
更激进的,我们一个进程被加载的时候,实际上可以只创建PCB和进程地址空间,并在页表中只填写一半,不加载任何数据和代码到真实物理内存,可不可以?实际上是可以的。我们的页表除了权限标志位以外,还有一个映射标志位,表示我这个虚拟地址是否有对应的物理映射。
当我们的程序运行这个进程的时候,就必须停下来(因为缺页中断)等待磁盘内容自动加载并完成页表填充。然后再运行。
5.2挂起的真正意义
重新回来我们解释一下挂起的真正过程:
- 程序物理内存空间严重告急------>
- 操作系统找到部分状态为S(阻塞)的进程------>
- 将进程的PCB中状态值改为挂起(T)------>
- 在PCB中找到mm_struct。------>
- 保留它,并将页表中对应映射位:保留虚拟地址映射位,清空物理地址映射位。------>
- 将物理内存内容全部挂到磁盘中的指定位置。
六、 Linux 虚拟地址空间的管理核心
6.1 零散虚拟内存空间的管理困境
当我们在 C/C++ 程序中调用 malloc() 或 new 时,内核会为进程在虚拟地址空间的堆区(Heap) 分配对应的空间。随着程序的运行,频繁的内存申请和释放会导致虚拟内存空间不连续 。
因此,内核有必要对这些虚拟内存区域进行精细化管理: 我不卖关子了直接说结论:
mm_struct内部维护着一个指针(mmap),该指针指向一个由vm_area_struct(VMA )构成的链表。
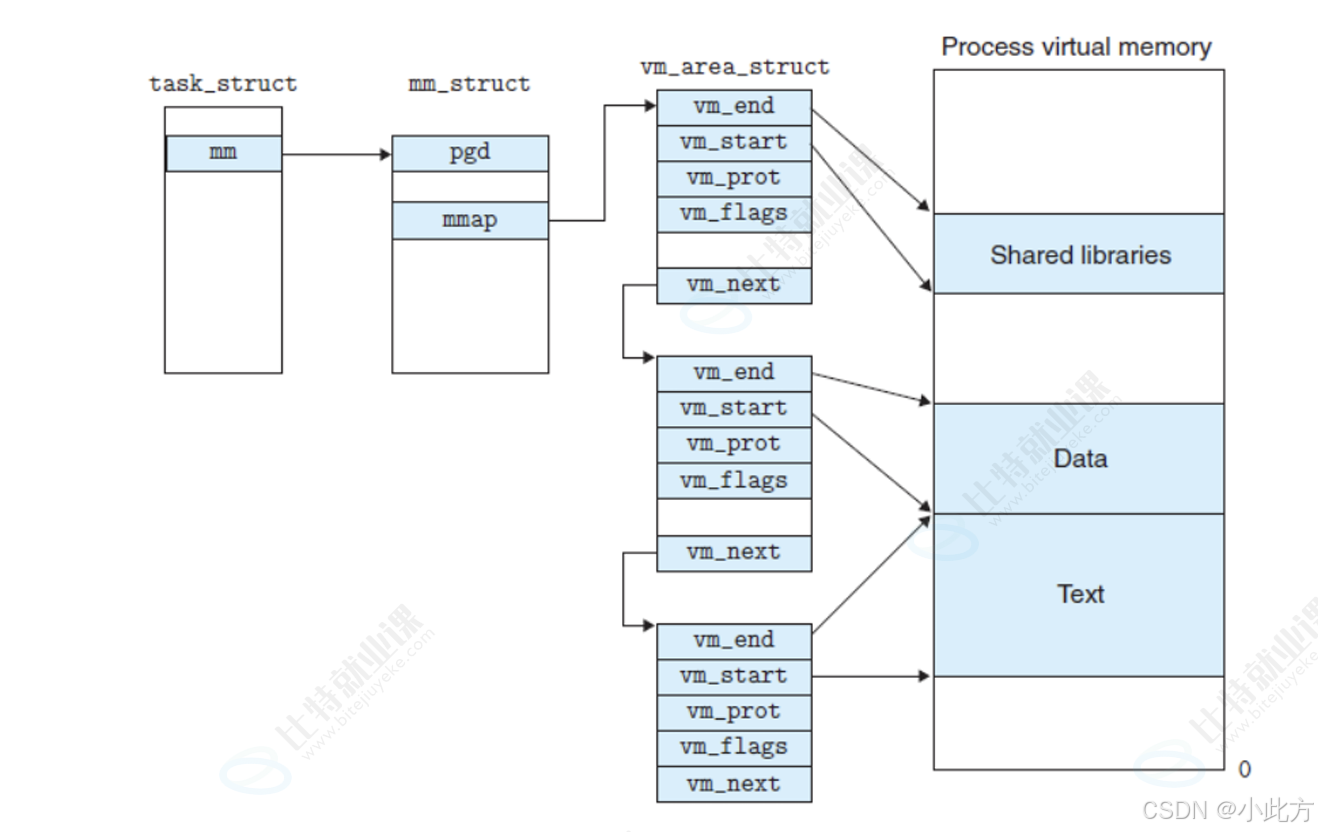
哎呀有人肯定要问了,什么是:"vm_area_struct",什么又是:由 vm_area_struct 构成的链表。
6.1.1vm_area_struct结构体详解
vm_area_struct 是 Linux 内核中用来描述一个独立的、连续的虚拟内存区域的核心结构体 。由于每个不同质的虚拟内存区域功能和内部机制 都不同,一个进程会使用多个 vm_area_struct 结构来分别表示不同类型的虚拟内存区域。
6.1.2 由 vm_area_struct 构成的链表
为了方便管理,内核将这些描述一块块虚拟内存区域的结构体链接起来,这就形成了链表。这正是操作系统中"先描述,再组织" 的典型体现。我们每次 malloc 一块空间,底层都会创建一个 vm_area_struct 结构体来维护这块空间。
6.2.1 核心源码剖析
根据内核源码,vm_area_struct 的主要定义如下:
c
struct vm_area_struct {
unsigned long vm_start; // 虚存区起始地址
unsigned long vm_end; // 虚存区结束地址
struct vm_area_struct *vm_next, *vm_prev; // 前后指针,构成双向链表
struct rb_node vm_rb; // 红黑树中的位置节点
unsigned long rb_subtree_gap;
struct mm_struct *vm_mm; // 所属的 mm_struct 结构体
pgprot_t vm_page_prot; // 保护位权限(如只读、可读写)
unsigned long vm_flags; // 标志位(如 VM_READ, VM_WRITE, VM_EXEC 等)
struct {
struct rb_node rb;
unsigned long rb_subtree_last;
} shared;
struct list_head anon_vma_chain;
struct anon_vma *anon_vma;
const struct vm_operations_struct *vm_ops; // VMA 对应的实际操作函数集
unsigned long vm_pgoff; // 文件映射偏移量
struct file * vm_file; // 映射的文件(若是匿名映射则为 NULL)
void * vm_private_data; // 私有数据
atomic_long_t swap_readahead_info;
#ifndef CONFIG_MMU
struct vm_region *vm_region; /* NOMMU mapping region */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *vm_policy; /* NUMA policy for the VMA */
#endif
struct vm_userfaultfd_ctx vm_userfaultfd_ctx;
} __randomize_layout;除了堆区,其他区域也有vm_area_struct维护。
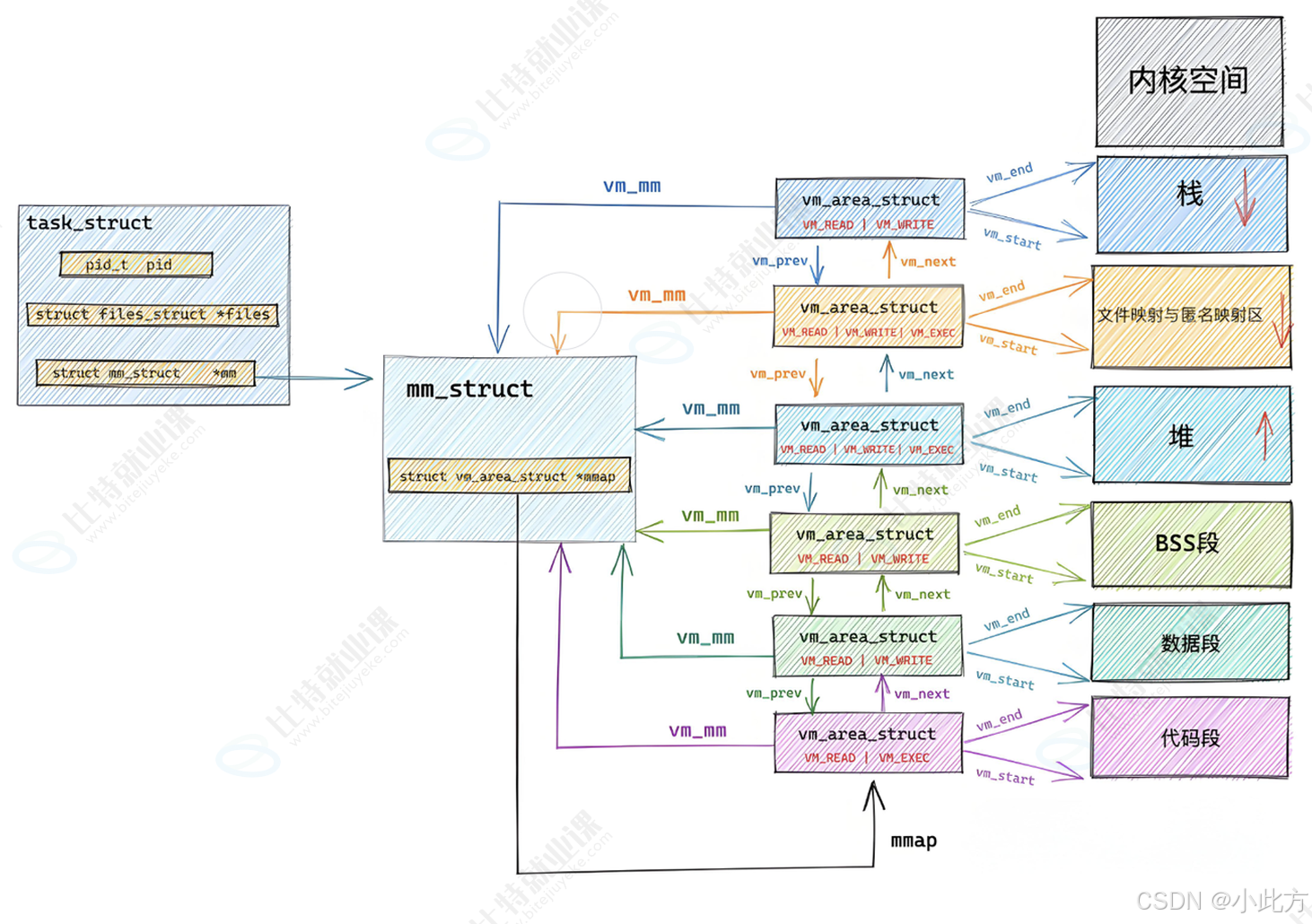
6.3 VMA 增长引发的问题与红黑树优化
6.3.1 为什么 VMA 会变多?
当程序频繁进行大块内存申请虚拟内存被频繁打碎,导致 vm_area_struct 节点的数量急剧增加。
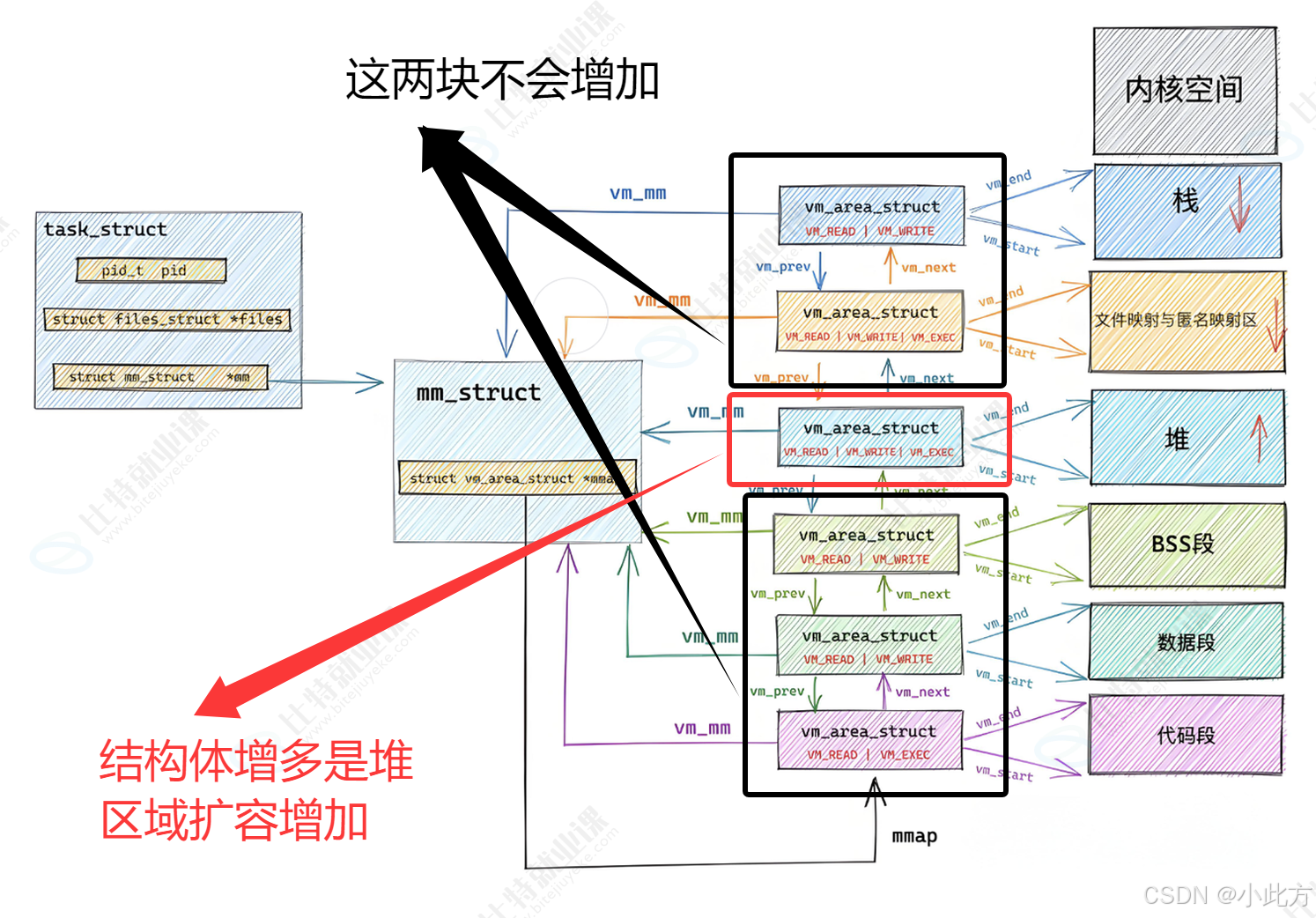
6.3.2 红黑树优化机制
这个mm里面还有一个闲置的rb指针,当这个链表不断变长的时候,达到一个阈值,就会把这个链表重新组织成为一个红黑树。这样查找的效率就会高一点这个和Java中的哈希桶的设计思路是非常相似的。
内核并不是"达到阈值才变红黑树"。实际上,只要有 VMA 存在,内核就会同时维护这两者。当你只有 2-3 个 VMA 时,链表查询也很快。当 VMA 数量增加(比如几百个零散的堆块或映射),红黑树的 O ( log n ) O(\log n) O(logn) 查找效率就远高于链表的 O ( n ) O(n) O(n) 了。
相比mm_struct 数量再多,task_struct也不会把他们变成红黑树。
6.4 关键思考
6.4.1 vm_area_struct 与 mm_struct 的字段重复问题
有人可能会疑惑:mm_struct 内部已经通过 start_brk、end_brk 等字段把各个空间的边界标明得很清楚了,这与 VMA 是否重复?
其实并不重复,两者分工不同:
mm_struct是整体描述:它负责从宏观上勾勒出整个进程地址空间的框架。vm_area_struct是具体描述:它负责微观、精细化地管理每一个独立的小区域。当程序去寻址时,有时候就会直接走更具体的 VMA 路线。
6.4.2 为什么不需要将所有地址空间硬性连接?
在实际管理中,我们其实没有必要把这一个一个的独立地址空间盲目地连接起来。因为在内核中,只要找到了进程的 PCB(task_struct),就能够找到 mm_struct,进而通过 VMA 链表或红黑树掌控整个进程的地址空间。
好的本期内容就到这里,如果对你有帮助,还不要忘记点赞三联支持。我是此方,我们下期再见。bye!