大语言模型(Large Language Model,LLM)是以深度学习为基础、通过大规模文本或多模态数据训练得到的生成式模型。它的核心能力并不是完成某一个固定任务,而是围绕语言理解、文本生成、信息处理、推理协助、代码生成、工具调用和多模态交互等方向,形成一组通用任务能力。
传统自然语言处理模型往往针对某个具体任务训练,例如文本分类、机器翻译、情感分析或命名实体识别。大语言模型则更强调"统一建模":用户可以通过提示词(Prompt)把不同任务描述成自然语言指令,模型再根据上下文生成相应结果。
因此,大语言模型不只是"会写文字"的模型,而是一种以自然语言为接口的通用任务处理系统。它通过语言接收任务、组织信息、表达结果,并在必要时连接外部工具完成更复杂的工作。
一、大语言模型任务的基本划分
大语言模型的任务范围很广。从实际应用看,可以概括为以下几类。
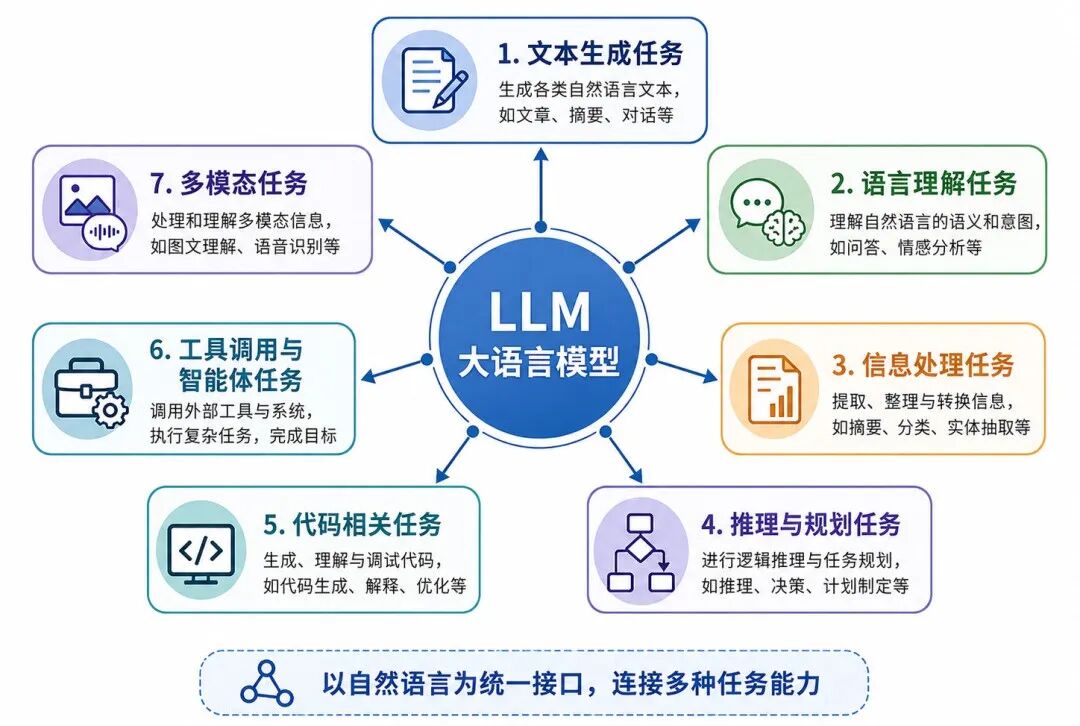
图 1:大语言模型的主要任务分类
1、文本生成任务
根据上下文生成连续文本,如续写、写作、对话、说明文生成等。
2、语言理解任务
理解文本含义、意图、结构、情绪、指代和上下文关系。
3、信息处理任务
对已有文本进行摘要、改写、翻译、提取、分类、问答和结构化整理。
4、推理与规划任务
根据条件进行分析、比较、推断、归纳和步骤安排。
5、代码相关任务
生成、解释、修改、检查、补全和调试代码。
6、工具调用与智能体任务
调用外部工具,完成检索、计算、文件处理、多步执行等工作。
7、多模态任务
结合文本、图像、音频、视频等信息进行理解与生成。
从整体上看,大语言模型的任务具有两个特点。
第一,它不是为单一任务设计的模型,而是通过统一的语言接口处理多种任务。
第二,它不只是输出文本,还可以在文本、代码、图像、工具和外部资料之间建立联系,从而承担更复杂的信息处理和任务执行工作。
二、文本生成任务:根据上下文生成连续语言
文本生成(Text Generation)是大语言模型最基础、最典型的任务。它的目标是根据已有上下文,预测并生成后续文本。
常见文本生成任务包括:
• 根据一句话继续写一段文章
• 根据主题生成说明文、故事、邮件或报告
• 根据问题生成自然语言回答
• 根据对话历史生成下一轮回复
• 根据提纲扩展成完整文章
• 根据资料生成结构化说明
大语言模型生成文本的基本方式,是根据前面的 token 预测下一个 token。这里的 token 可以理解为模型处理文本时使用的基本单位,它可能是一个字、一个词,也可能是一个词片段。
其基本形式可以写成:
其中:
• xₜ 表示第 t 个 token
• p(xₜ ∣ x₁,x₂,...,xₜ₋₁) 表示在前文条件下生成当前 token 的概率
• T 表示文本序列长度
• ∏ 表示连乘
整段文本的生成概率可以分解为逐步预测每个 token 的条件概率。
这说明,大语言模型并不是一次性生成整篇文章,而是在上下文约束下逐步生成文本。
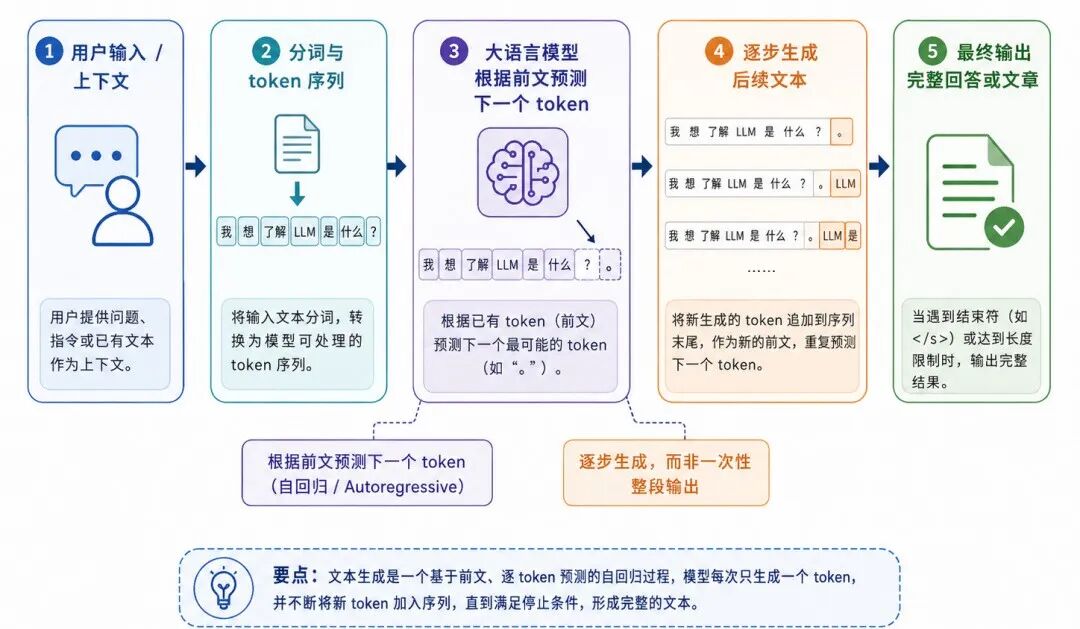
图 2:文本生成的一般过程
1、续写与扩写
续写(Continuation)是指模型根据已有文本继续生成后续内容。
扩写(Expansion)则是在保留原有主题或结构的基础上,将简短内容扩展为更完整的文本。
例如:
• 根据一句开头续写故事
• 根据一个观点扩写成议论文段落
• 根据提纲扩写成完整文章
• 根据短说明扩写成教材内容
• 根据一句结论扩展出论证过程
这类任务的关键在于:模型需要保持语义连贯、风格一致、结构合理。
例如,给定上下文:
模型生成后续文本:
其中:
• c 表示已有上下文
• n 表示已有 token 数量
• k 表示需要继续生成的 token 数量
• x̂ 表示模型生成的后续内容
续写任务表面上是在"接着写",本质上是在保持上下文一致性的条件下进行概率生成。
2、写作与创作
大语言模型还可以完成更开放的写作任务,例如:
• 新闻稿
• 教材文章
• 科普文章
• 演讲稿
• 广告文案
• 故事脚本
• 社交媒体文案
• 工作邮件
• 产品说明
• 研究综述
与简单续写相比,写作任务通常需要同时满足主题、结构、语气、受众、篇幅和格式等多种约束。
这类任务可以表示为:
其中:
• p 表示提示词或写作要求
• c 表示可用上下文或背景材料
• r 表示风格、格式、篇幅等约束
• ŷ 表示生成文本
因此,大语言模型写作并不只是"生成语言",而是根据多重约束组织内容。
3、对话生成
对话生成(Dialogue Generation)是大语言模型在人机交互中的核心任务。它要求模型根据用户当前输入和历史对话,生成合适的回复。
对话任务可以表示为:
其中:
• uₜ 表示当前轮用户输入
• H 表示历史对话上下文
• r̂ 表示模型生成的回复
• f 表示大语言模型
对话生成与普通文本生成不同。它不仅要求语言自然,还要求模型保持上下文一致,理解用户意图,并根据当前任务选择合适的回答方式。
例如,在多轮写作修改中,用户可能先要求"写一篇文章",随后又要求"第二节再通俗一点""小结控制在 120 字以内"。
模型需要记住前文要求,并把新的约束应用到当前任务中。
三、语言理解任务:识别文本的含义、意图与结构
语言理解(Language Understanding)是大语言模型的重要任务。它要求模型不仅能生成文字,还能理解输入文本的含义、结构和上下文关系。
例如:
• 判断用户真正想问什么
• 理解一句话中的隐含关系
• 识别文本中的情绪倾向
• 判断两个句子是否表达相同意思
• 分析文章结构和论证逻辑
• 理解上下文中的省略、指代和转折
语言理解任务可以简化表示为:
其中:
• x 表示输入文本
• fθ 表示带参数 θ 的大语言模型
• h 表示模型对文本形成的内部语义表示
• θ 表示模型参数
模型并不是只记住词语表面形式,而是把文本转换为内部表示,再基于这种表示完成判断、回答或生成。
1、意图识别
意图识别(Intent Recognition)是指判断用户输入背后的任务目标。
例如,用户输入:
go
帮我把这段话写得更正式一点。模型需要识别出用户的意图是"文本改写",而不是单纯询问"正式"是什么意思。
常见意图包括:
• 提问
• 写作
• 翻译
• 摘要
• 改写
• 分类
• 推理
• 代码生成
• 工具调用
• 文件处理
• 图像理解
在对话系统中,意图识别决定了模型后续应该采用什么方式回答。
2、语义理解
语义理解(Semantic Understanding)关注的是文本所表达的真实含义,而不只是词语表面。
例如:
go
这个方案不是不可以。这句话表面上有两个否定,但实际语义更接近"可以考虑"。模型需要理解否定、转折、语气和上下文关系。
语义理解常涉及:
• 指代关系:理解"他""它""这件事"指什么
• 否定关系:理解"不是""不能""并非"的作用
• 因果关系:识别原因与结果
• 对比关系:理解"虽然......但是......"
• 隐含含义:理解没有直接说出的意思
• 上下文关系:根据前后文补全省略信息
例如:
其中:
• surface(x) 表示文本表层形式
• meaning(x) 表示文本实际含义
• ≠ 表示二者不一定完全相同
这说明,语言理解不能停留在词语层面,而要进入语义关系层面。
3、上下文理解
上下文理解(Context Understanding)是大语言模型区别于许多传统文本模型的重要能力。模型不仅要理解当前句子,还要结合前文、任务要求和对话历史判断真正含义。
例如,用户先说:
go
请把这篇文章改得更适合初学者。随后又说:
go
第二节再通俗一些。此时,"第二节"指的是前文中的文章结构,"再通俗一些"指的是修改风格。模型需要结合上下文才能正确执行。
上下文理解可以表示为:
其中:
• x 表示当前输入
• H 表示上下文信息
• ŷ 表示模型输出
• f 表示大语言模型
上下文理解使大语言模型能够处理多轮对话、长文档分析、连续修改和复杂任务拆解。
四、信息处理任务:整理、压缩与提取文本信息
信息处理任务(Information Processing Task)是大语言模型在学习、办公、研究和知识管理中非常常见的应用方向。它的目标是把已有文本整理成更清晰、更紧凑或更有结构的信息。
常见任务包括:
• 摘要
• 改写
• 翻译
• 信息抽取
• 文本分类
• 问答
• 结构化整理
• 要点归纳
• 表格化整理
这类任务的共同特点是:输入材料已经存在,模型的任务不是凭空创造,而是对已有信息进行理解、转换、压缩和重组。
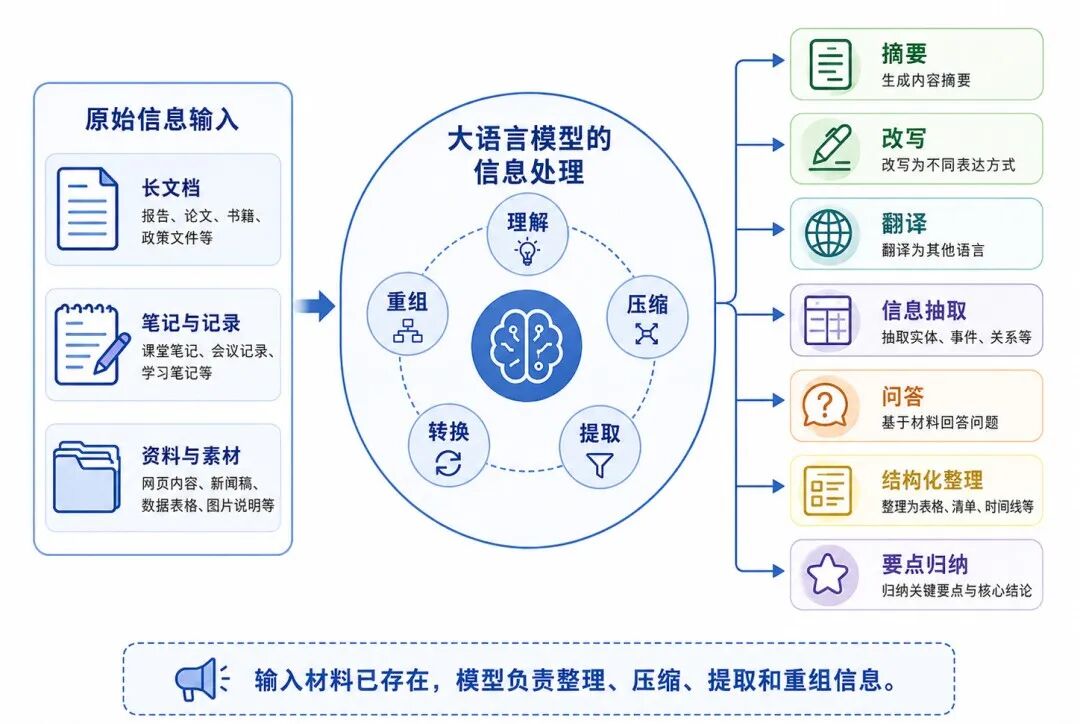
图 3:信息处理任务的一般方向
1、文本摘要
文本摘要(Summarization)的目标是从长文本中提炼主要内容,生成较短的概括。
摘要任务可以写成:
其中:
• d 表示原始文档
• s 表示摘要
• f 表示摘要生成模型
摘要可以分为两类:
• 抽取式摘要:从原文中选取关键句
• 生成式摘要:在理解原文基础上重新组织语言
大语言模型更擅长生成式摘要,因为它可以根据文章结构、重点和上下文重新组织表达。
好的摘要通常应满足:
• 保留核心信息
• 删除次要细节
• 避免改变原意
• 结构简明清晰
• 不添加原文没有的信息
摘要任务看似简单,但它对模型的忠实性要求很高。模型不能为了语言流畅而添加原文没有的内容,也不能遗漏关键事实。
2、信息抽取
信息抽取(Information Extraction)的目标是从文本中提取指定信息。
例如,从一段会议记录中提取:
• 会议时间
• 参会人员
• 讨论议题
• 决策结果
• 后续任务
• 截止日期
信息抽取可以表示为:
其中:
• x 表示原始文本
• q 表示需要提取的信息类型或问题
• z 表示提取结果
例如,给定文本:
go
项目将在 5 月 10 日前完成第一轮测试,由张三负责。模型可以提取出:
• 截止日期:5 月 10 日
• 任务:完成第一轮测试
• 负责人:张三
信息抽取的重点是准确性。它要求模型尽量基于原文,不应随意补充或编造。
3、问答任务
问答(Question Answering,QA)是大语言模型最常见的人机交互任务之一。用户提出问题,模型根据已有知识、上下文或外部资料生成回答。
问答任务可以表示为:
其中:
• q 表示问题
• c 表示上下文、资料或检索结果
• a 表示回答
根据依据来源不同,问答任务可分为:
• 闭卷问答:主要依赖模型内部知识
• 开卷问答:结合外部资料、搜索结果或文档内容
• 多轮问答:结合历史对话进行连续回答
• 文档问答:依据指定文档内容回答问题
在实际应用中,高质量问答不仅要求语言流畅,还要求事实准确、依据清晰、边界明确。
4、改写与翻译
改写(Rewriting)是指在保持原意基本不变的前提下,改变文本表达方式。
翻译(Translation)则是在不同语言之间转换文本含义。
改写任务可以表示为:
其中:
• x 表示原始文本
• r 表示改写要求,例如更正式、更通俗、更简洁
• x̂ 表示改写后的文本
翻译任务可以表示为:
其中:
• x 表示源语言文本
• Lₛ 表示源语言
• Lₜ 表示目标语言
• y 表示翻译结果
改写和翻译都要求模型处理"意义保持"问题。也就是说,表达可以变化,但核心含义不能随意改变。
五、推理与规划任务:从条件到结论的分析过程
推理与规划(Reasoning and Planning)是大语言模型的重要能力方向。它要求模型不仅复述信息,还要根据条件进行分析、比较、归纳、演绎和步骤安排。
例如:
• 分析一个方案是否合理
• 根据条件推断可能结果
• 设计学习计划或项目计划
• 比较多个选项的优缺点
• 解决数学题或逻辑题
• 根据目标拆分任务步骤
• 检查一段论证是否自洽
推理任务可以简化表示为:
其中:
• p₁,p₂,...,pₙ 表示已知前提
• c 表示根据前提推出的结论
• f 表示推理过程
这类任务的关键不只是给出答案,而是让答案符合前提、逻辑和约束。
1、逻辑推理
逻辑推理(Logical Reasoning)要求模型根据明确条件判断结论是否成立。
例如,已知:
• 所有 A 都属于 B
• x 是 A
则可以推出:
其中:
• x ∈ A 表示 x 属于集合 A
• A ⊆ B 表示 A 是 B 的子集
• x ∈ B 表示 x 也属于集合 B
• ⇒ 表示可以推出
在自然语言任务中,逻辑推理常用于判断:
• 条件是否充分
• 结论是否成立
• 说法是否矛盾
• 论证是否完整
• 推断是否超出前提
大语言模型可以辅助逻辑分析,但在复杂推理中仍需要注意验证,因为语言流畅并不必然等于逻辑正确。
2、数学推导与计算辅助
大语言模型也常用于数学解释、公式推导和解题辅助。
例如:
• 解释公式含义
• 推导简单数学关系
• 分析题目条件
• 给出解题步骤
• 检查计算思路
• 把公式转换为代码实现
一个基本的数学求解任务可以表示为:
其中:
• x 表示题目输入
• 𝒞 表示题目条件集合
• ŷ 表示模型给出的结果
需要注意的是,大语言模型本质上仍是语言模型。对于高精度计算、符号代数、大规模数值计算等任务,通常应结合计算器、编程环境或专业数学工具进行验证。
3、任务规划
任务规划(Task Planning)是指模型根据目标拆分步骤、安排顺序和组织执行路径。
例如:
• 制定学习计划
• 规划写作流程
• 拆分项目任务
• 设计实验步骤
• 安排数据分析流程
• 制定资料检索路径
• 规划产品开发流程
任务规划可以表示为:
其中:
• P 表示计划
• a₁,a₂,...,aₙ 表示一系列行动步骤
• 步骤之间通常存在先后依赖关系
一个好的任务规划通常应满足:
• 目标明确
• 步骤可执行
• 顺序合理
• 资源约束清楚
• 风险与检查点明确
大语言模型在规划任务中更像一个"语言化的组织器":它可以帮助人把模糊目标拆成较清晰的行动结构。
六、代码相关任务:理解、生成与修改程序
代码任务(Code Task)是大语言模型的重要应用方向。由于代码也是一种结构化语言,大语言模型可以学习代码语法、常见模式、接口用法和程序逻辑,从而辅助编程。
常见代码任务包括:
• 代码生成
• 代码解释
• 代码补全
• 代码改写
• 代码调试
• 错误分析
• 单元测试生成
• 文档注释生成
• 代码迁移
• 代码审查
代码生成任务可以写成:
其中:
• r 表示编程需求
• ĉ 表示生成的代码
• f 表示大语言模型
代码任务与普通文本生成不同,因为代码必须满足语法正确、逻辑正确、依赖正确和运行环境匹配等要求。
1、代码生成
代码生成(Code Generation)是指根据自然语言需求生成程序代码。
例如:
• 用 Python 读取 CSV 文件并绘图
• 用 JavaScript 编写网页交互
• 用 SQL 查询指定数据
• 用 Python 实现机器学习训练流程
• 用 HTML 和 CSS 编写网页结构
代码生成的关键不只是"写出代码",还包括:
• 理解需求
• 选择合适库或语言特性
• 组织程序结构
• 处理异常情况
• 保证代码可运行
• 保持代码可读性和可维护性
例如,用户提出:
go
用 Python 读取一个 CSV 文件,并按月份统计销售额。模型需要把自然语言需求转换为程序步骤:读取文件、解析日期、按月份分组、计算销售额、输出结果或绘制图表。
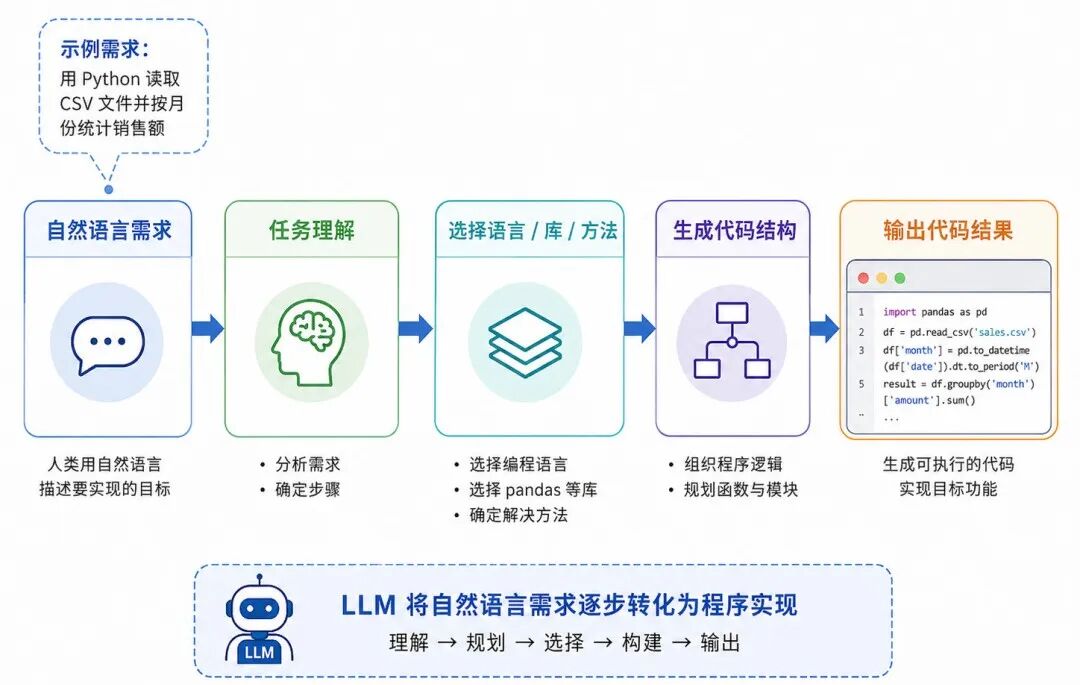
图 4:代码生成的一般过程
2、代码解释与调试
代码解释(Code Explanation)是指用自然语言说明代码的作用、结构和执行过程。
代码调试(Debugging)则要求模型根据错误信息、代码上下文和运行结果,分析问题原因并提出修改方案。
调试任务可以表示为:
其中:
• c 表示代码
• e 表示错误信息或异常现象
• b̂ 表示模型判断出的可能问题
代码调试通常需要关注:
• 语法错误
• 类型错误
• 变量作用域问题
• 依赖版本问题
• 数据格式问题
• 边界条件问题
• 逻辑错误
• 性能问题
• 安全风险
需要注意的是,大语言模型可以帮助定位问题,但最终仍应通过实际运行和测试验证代码是否正确。
3、测试与代码审查
除了生成和解释代码,大语言模型还可以辅助生成测试用例和进行代码审查。
单元测试生成可以表示为:
其中:
• c 表示待测试代码
• r 表示测试要求
• t̂ 表示生成的测试代码
代码审查则关注:
• 代码是否符合需求
• 是否存在边界条件遗漏
• 是否存在重复逻辑
• 是否存在潜在异常
• 是否存在安全隐患
• 是否可以提升可读性
这说明,大语言模型在编程中的价值不仅是"写代码",还包括解释代码、检查代码和改进代码。
七、工具调用与智能体任务:从回答问题到执行任务
工具调用(Tool Use)是大语言模型从"文本生成系统"走向"任务执行系统"的关键能力。模型不仅生成回答,还可以根据任务需要调用外部工具。
例如:
• 调用搜索工具获取最新信息
• 调用计算器完成精确计算
• 调用代码环境处理数据
• 调用文档工具生成文件
• 调用日历、邮件、数据库等系统完成操作
• 调用图像工具生成或编辑图片
工具调用任务可以表示为:
其中:
• T 表示外部工具
• a 表示传给工具的参数
• o 表示工具返回的结果
大语言模型在其中的作用,是理解任务、选择工具、组织参数、解释结果。
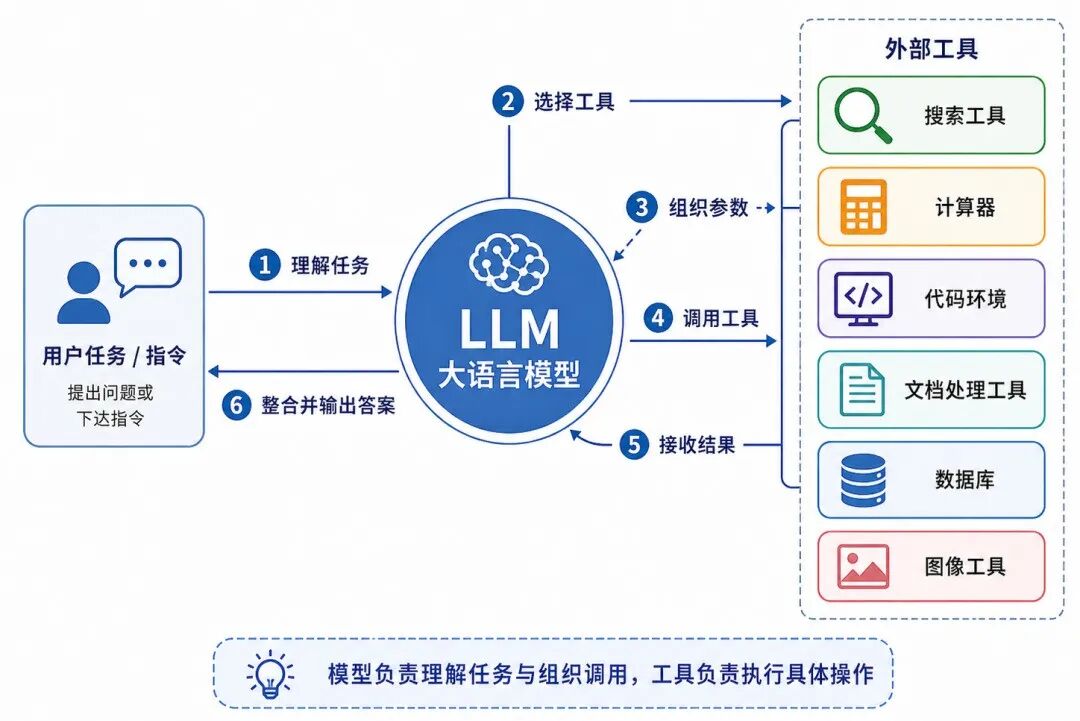
图 5:大语言模型工具调用过程
工具调用使大语言模型不再只依赖自身参数中的知识,而能够连接外部环境,完成更新、更精确或更复杂的任务。
1、检索增强生成
检索增强生成(Retrieval-Augmented Generation,RAG)是大语言模型常见的工具增强方式。它先从外部资料中检索相关内容,再基于检索结果生成回答。
其基本流程是如下图所示:
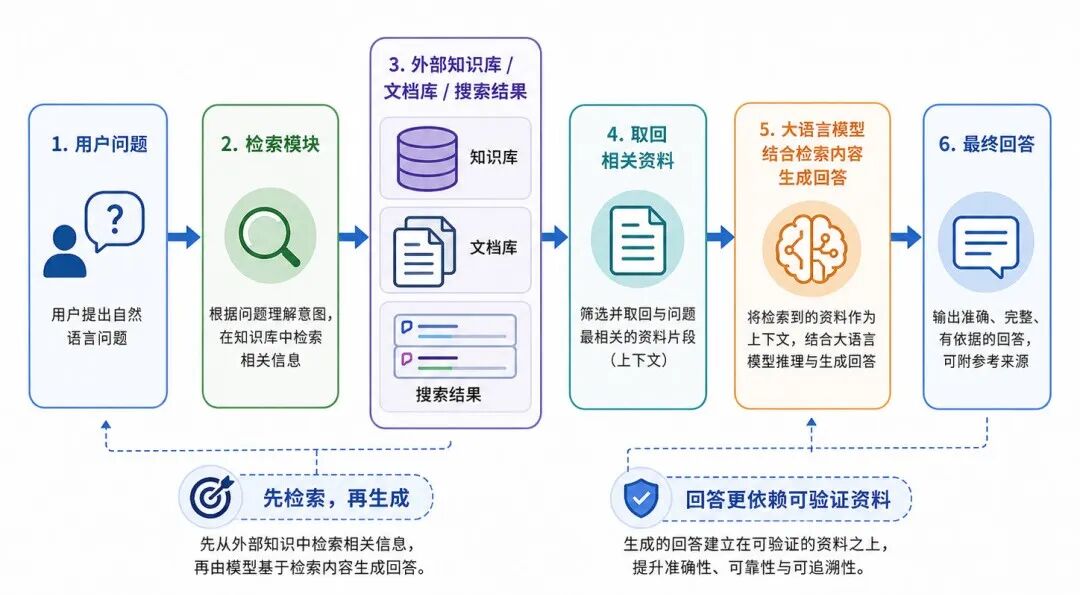
图 6:检索增强生成的一般流程
可以简化表示为:
其中:
• q 表示用户问题
• R(q) 表示根据问题检索到的资料
• a 表示最终回答
RAG 的意义在于:它可以减少模型仅凭内部记忆回答带来的不确定性,使回答更依赖可验证资料。
需要注意的是,RAG 并不等于"绝对正确"。检索资料是否相关、资料本身是否可靠、模型是否正确理解资料,都会影响最终回答质量。
2、智能体任务
智能体任务(Agent Task)是指大语言模型围绕目标进行多步决策、工具调用和结果检查。
例如:
• 自动整理资料并生成报告
• 根据目标规划搜索路径
• 分析数据并生成图表
• 读取文件、提取信息、生成文档
• 在多个工具之间协调完成复杂任务
• 根据中间结果继续调整后续步骤
智能体任务可以表示为:
其中:
• G 表示用户目标
• a₁,a₂,...,aₙ 表示多个行动步骤
• R 表示最终结果
与普通问答不同,智能体任务强调"多步执行"。模型需要不断根据中间结果调整后续行动。
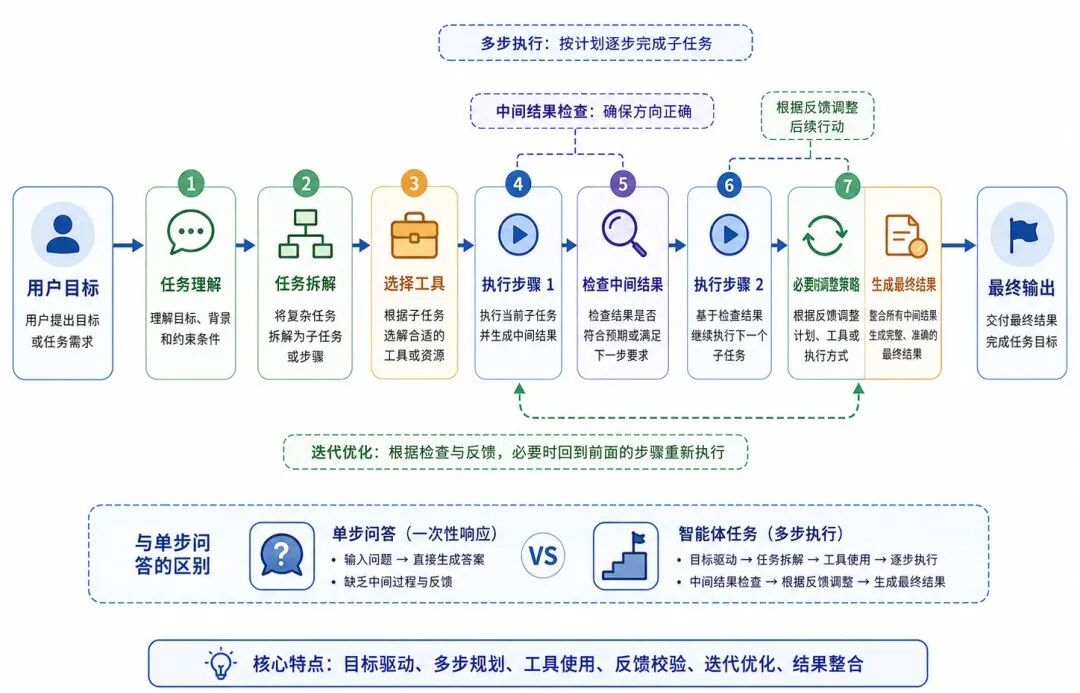
图 7:智能体任务的一般结构
智能体任务是大语言模型能力扩展的重要方向,但也对可靠性提出了更高要求。模型需要明确任务边界、检查中间结果,并避免在没有依据的情况下继续执行错误步骤。
八、多模态任务:连接文本、图像、音频与视频
多模态任务(Multimodal Task)是大语言模型发展的重要方向。传统大语言模型主要处理文本,而多模态大模型可以同时处理文本、图像、音频、视频等信息。
例如:
• 看图回答问题
• 描述图片内容
• 分析图表信息
• 根据图片生成文字说明
• 根据文字生成图像
• 理解视频中的事件
• 结合语音和文本进行对话
• 根据截图分析界面问题
多模态任务的基本思想是:把不同类型的数据映射到可以共同理解的表示空间。
可以写成:
其中:
• x_text 表示文本输入
• x_image 表示图像输入
• h_text 表示文本表示
• h_image 表示图像表示
如果文本和图像语义相关,它们在表示空间中应当具有较高相似度。
1、图文理解
图文理解(Vision-Language Understanding)是多模态任务中的基础方向。它要求模型同时理解图像内容和文本问题。
例如,用户给出一张图片并提问:
go
图中这辆车停放是否合理?模型需要先识别图像中的车辆、道路、标志线、停车位置等信息,再结合问题进行判断。
图文理解任务可以表示为:
其中:
• q 表示用户问题
• x_image 表示输入图像
• a 表示模型回答
这类任务不只是"看图说话",还需要把视觉信息与语言问题结合起来。
2、图表理解
图表理解(Chart Understanding)是多模态大模型在学习、办公和数据分析中的重要任务。
例如:
• 读取柱状图趋势
• 分析折线图变化
• 解释散点图关系
• 根据图表回答问题
• 从表格截图中提取数据
图表理解通常需要同时处理:
• 文字标签
• 坐标轴
• 图例
• 数值关系
• 趋势变化
• 视觉布局
它比普通图片描述更复杂,因为图表本质上是"视觉化的数据结构"。模型不仅要看见图形,还要理解图形背后的数量关系。
3、语音与视频理解
多模态大模型还可以处理语音和视频任务。
语音理解任务包括:
• 语音转文字
• 语音情绪识别
• 会议内容摘要
• 多轮语音对话
视频理解任务包括:
• 描述视频内容
• 识别视频中的动作
• 分析视频中的事件变化
• 根据视频回答问题
视频理解比图像理解更复杂,因为视频不仅包含空间信息,还包含时间变化。模型需要理解对象在连续画面中的运动、关系和事件发展。
九、大语言模型任务之间的区别与联系
大语言模型的任务虽然很多,但可以从三个层次理解。
1、语言层任务
语言层任务主要围绕自然语言本身展开,包括续写、写作、摘要、翻译、改写、问答等。
这类任务强调语言生成、语言转换和信息表达。
2、认知层任务
认知层任务包括理解、推理、规划、比较、归纳、解释等。
这类任务要求模型不仅处理语言,还要组织概念、关系和逻辑。
3、行动层任务
行动层任务包括工具调用、代码执行、检索增强、文件处理、多步任务执行等。
这类任务要求模型从"生成回答"进一步走向"辅助完成任务"。
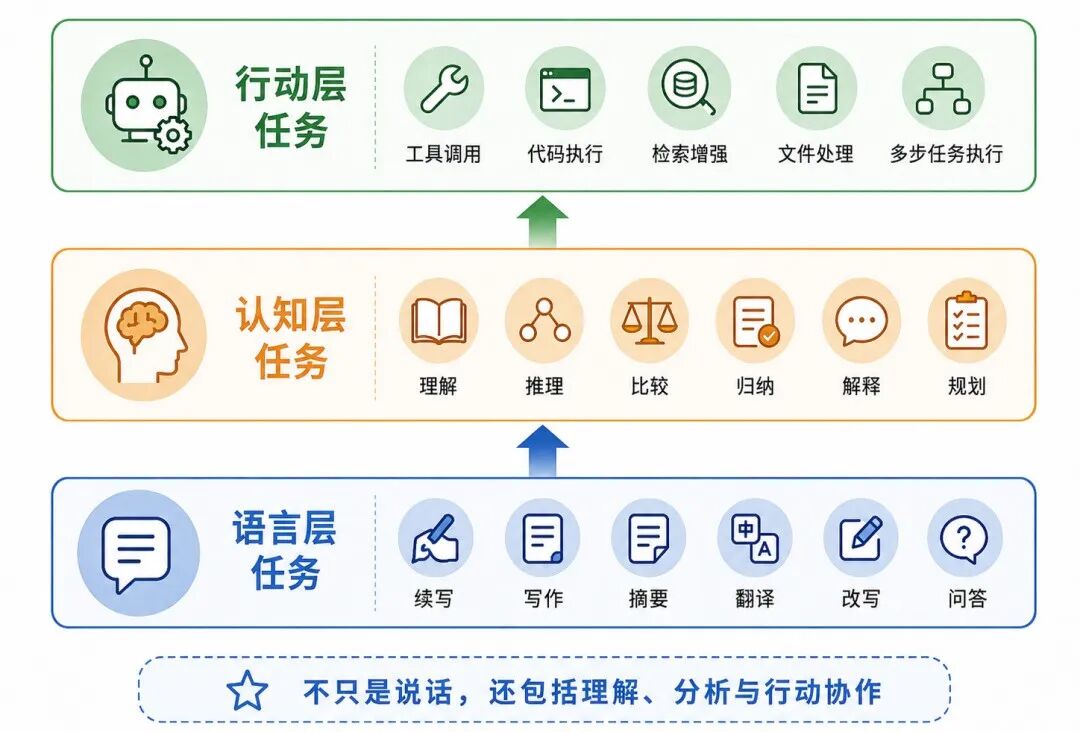
图 8:大语言模型任务的三个层次
如果用更直观的话概括:
• 文本生成任务回答"怎样把话说出来"
• 语言理解任务回答"这段话是什么意思"
• 信息处理任务回答"如何整理已有信息"
• 推理与规划任务回答"根据条件应该怎样分析"
• 代码任务回答"怎样把需求转成程序"
• 工具调用任务回答"怎样借助外部系统完成任务"
• 多模态任务回答"怎样把文本与图像、音频、视频结合起来理解"
需要注意的是,这些任务在实际应用中经常相互交织。例如,回答一个复杂问题,可能同时需要理解问题、检索资料、摘要证据、进行推理,并最终生成回答;完成一个数据分析任务,可能同时涉及代码生成、工具调用、结果解释和报告写作。
因此,大语言模型的价值不只在于生成流畅文本,而在于它把语言变成了一种通用任务接口。用户可以用自然语言描述目标,模型则把目标转化为理解、生成、推理、检索、调用工具或执行步骤。
十、大语言模型任务的能力边界
大语言模型具有很强的通用性,但它并不等于全知、全能或绝对可靠。理解其任务边界,有助于更合理地使用大语言模型。
第一,大语言模型可能生成看似合理但并不准确的内容。
因此,在事实性问题、专业判断、法律、医疗、金融等高风险场景中,应结合可靠资料或专业工具进行验证。
第二,大语言模型的推理能力受到提示词、上下文长度、任务复杂度和外部工具条件的影响。
对于复杂计算、符号推导和精确数据处理,通常需要结合计算器、代码环境或专业软件。
第三,大语言模型的回答质量与输入质量密切相关。
任务目标越明确、约束越清楚、资料越充分,模型越容易给出高质量结果。
第四,多步任务尤其需要检查中间结果。
智能体任务虽然可以自动拆解和执行步骤,但如果前一步判断错误,后续步骤也可能被带偏。
因此,大语言模型更适合被理解为一种"语言驱动的智能协作工具":它能够帮助人理解信息、组织内容、生成方案、辅助推理和调用工具,但最终仍需要人根据任务重要性进行判断、验证和取舍。
📘 小结
大语言模型的主要任务包括文本生成、语言理解、信息处理、推理规划、代码辅助、工具调用、智能体执行和多模态理解。它以自然语言为统一接口,把写作、问答、分析、编程、检索和任务执行连接起来,是生成式人工智能的重要基础。

"点赞有美意,赞赏是鼓励"