一.冒泡排序 Bubblesort
(升序为例)理解冒泡排序,就要明白,每次从头到尾进行相邻元素两两之间的比较交换,最后都会让本轮数组中最大的数走到数组的最后(有隐形收束边界的意味),当待排数组只剩一个数时,冒泡排序就完成了。(很多人说冒泡排序很好理解,但我觉得,其实理解挺有难度的)
(1)代码实现
//升序为例
void Bubblesort(int* arr,int n)
{
for(int j =0;j<n-1;j++)
{
int i = 0;
int flag = 1;
for(i = 0;i<n-1-j;i++)
{
if(arr[i]>arr[i+1])
{
Swap(&arr[i],&arr[i+1];
flag = 0;
}
}
if(flag)
break;
}
}(2)细节理解
内外层循环各自代表了什么?循环条件又有什么样的含义?
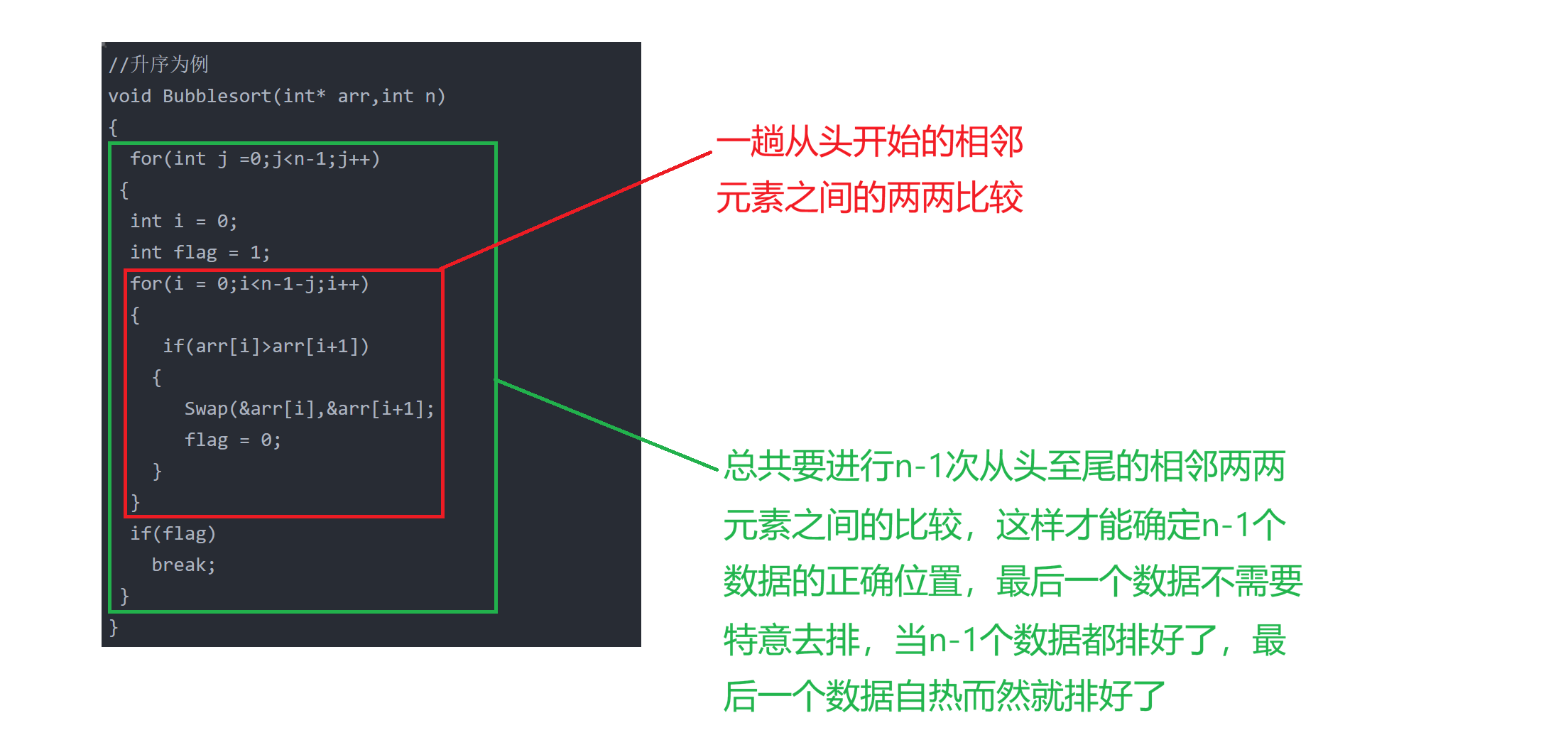
红色循环条件:相邻两两元素之间的比较,由于我写的是i和i+1位置上的元素之间的比较,为了不让i+1越界,所以i首先要小于n-1,其次,由于没进行完一次从头至尾的相邻两两元素之间的比较,就会有一个数据走到了数组"后方"的正确位置上(以升序为例),所以不需要把正确排序位置上的数据再拉进排序的比较行列中,体现在代码上,就是i<n-1-j。
绿色循环条件:总共要进行n-1次的从头至尾的相邻两两元素之间的比较,这样才能确定n-1个数据的正确位置,当然,也可以排n趟,但是没有必要,当n-1个数据都已经到了它们的正确位置之后,最后一个数据自然就到了它的正确位置。
二.快速排序 Quicksort
(一)递归版快速排序
(1)hoare法
以升序为例,取数组第一个数据下标为key,定义begin为数组第一个数据的下标,end为数组最后一个数据的下标,先判断end对应数据和key对应数据的大小关系,如果是key对应数据更大,就不要动end,如果end对应数据更大,就让end--(向前走一步),继续与key对应数据进行大小比较,出现key对应数据更大的情况后,就去看begin。
同样,也要判断begin对应数据的下标和key对应数据的大小,如果是begin对应数据更小,那就不要动begin,如果是key对应数据更小,那就begin++(向后走一步),继续与key对应数据进行大小比较,直到出现key对应数据更小的情况,再将对应end和begin位置的数据进行交换,则比key大的数据走到了数组的后方,比key小的数据走到了数组的前方,重复上述操作,等begin和end相遇之后,再将相遇位置的数据和key位置的数据进行交换,就能实现数组的升序。这就是hoare法的快速排序。
(注意:可能存在begin、end相遇前并没有进行过一次交换的情况,那这就是直接让相遇位置的数据和key位置的数据进行交换就好。)
1.朴素版
void Quicksort(int* arr,int left,int right)
{
//递归结束的条件
if(left<=right)
return;
int begin = left;
int end = right;
int key = left;
while(begin<end)
{
while(begin<end && arr[key]<=arr[end])
end--;
while(begin<end && arr[key]>= arr[begin])
begin++;
//都找到了要交换的数据
Swap(&arr[begin],&arr[end]);
}
//相遇后,要和key位置上的数据交换
Swap(&arr[begin],&arr[key]);
key = begin;
//完成了第一次排序,确定了key位置上的数据的正确位置
//递归
Quicksort(arr,left,key-1);
Quicksort(arr,key+1,right);
}2.三数取中
有时候取得key位置上的值太大了或者太小了,就会导致递归时栈太深,有栈溢出的风险,为了优化这种情况,我们可以在头尾和中间的数据中取一个中间值作为arrkey,尽量避免选到太大或太小的数,这就是三数取中。
int GetMid(int* arr,int left,int right)
{
int mid = (left+right)/2;
if(arr[left]>arr[mid])
{
if(arr[mid]>arr[right])
//left>mid>right
return mid;
else
{
if(arr[left]>arr[right])
//left>right>mid
return right;
else
//right>left>mid
return left;
}
}
else
{
if(arr[left]>arr[right])
//mid>left>right
return left;
else
{
if(arr[mid]>arr[right]
//mid>right>left
return right;
else
//right>mid>left
return mid;
}
}
}
void Quicksort(int* arr,int left,int right)
{
//递归结束的条件
if(left<=right)
return;
int begin = left;
int end = right;
//三数取中
int key = GetMid(arr,left,right);
Swap(&arr[begin],&arr[key]);
key = begin;
while(begin<end)
{
while(begin<end && arr[key]<=arr[end])
end--;
while(begin<end && arr[key]>= arr[begin])
begin++;
//都找到了要交换的数据
Swap(&arr[begin],&arr[end]);
}
//相遇后,要和key位置上的数据交换
Swap(&arr[begin],&arr[key]);
key = begin;
//完成了第一次排序,确定了key位置上的数据的正确位置
//递归
Quicksort(arr,left,key-1);
Quicksort(arr,key+1,right);
}将key位置上的数据和begin位置上的数据交换,使key位置还是数组的首位置,这样while循环的逻辑就不用改变,注意,除了要交换数据外,还要将begin的值赋给key。
3.小区间优化
快排的递归过程很像二叉树的前序遍历,由此我们能大概知道,处理最后的一些小区间(叶子)会占到程序执行时间的一半左右,如果我们让小区间不再走递归那一套,而是直接进行现有的排序(堆排序、插入排序、希尔排序等等),时不时就能实现快排的优化呢?实际上确实是这样的。
void Quicksort(int* arr,int left,int right)
{
//递归结束的条件
if(left<=right)
return;
//小区间优化
if((right-left-1) < 10)
Insertsort(arr+left,right-left+1);
else
{
int begin = left;
int end = right;
//三数取中
int key = GetMid(arr,left,right);
Swap(&arr[begin],&arr[key]);
key = begin;
while(begin<end)
{
while(begin<end && arr[key]<=arr[end])
end--;
while(begin<end && arr[key]>= arr[begin])
begin++;
//都找到了要交换的数据
Swap(&arr[begin],&arr[end]);
}
//相遇后,要和key位置上的数据交换
Swap(&arr[begin],&arr[key]);
key = begin;
//完成了第一次排序,确定了key位置上的数据的正确位置
//递归
Quicksort(arr,left,key-1);
Quicksort(arr,key+1,right);
}
}细节理解:
①为什么刚好begin和end相遇的位置是小于arrkey的?
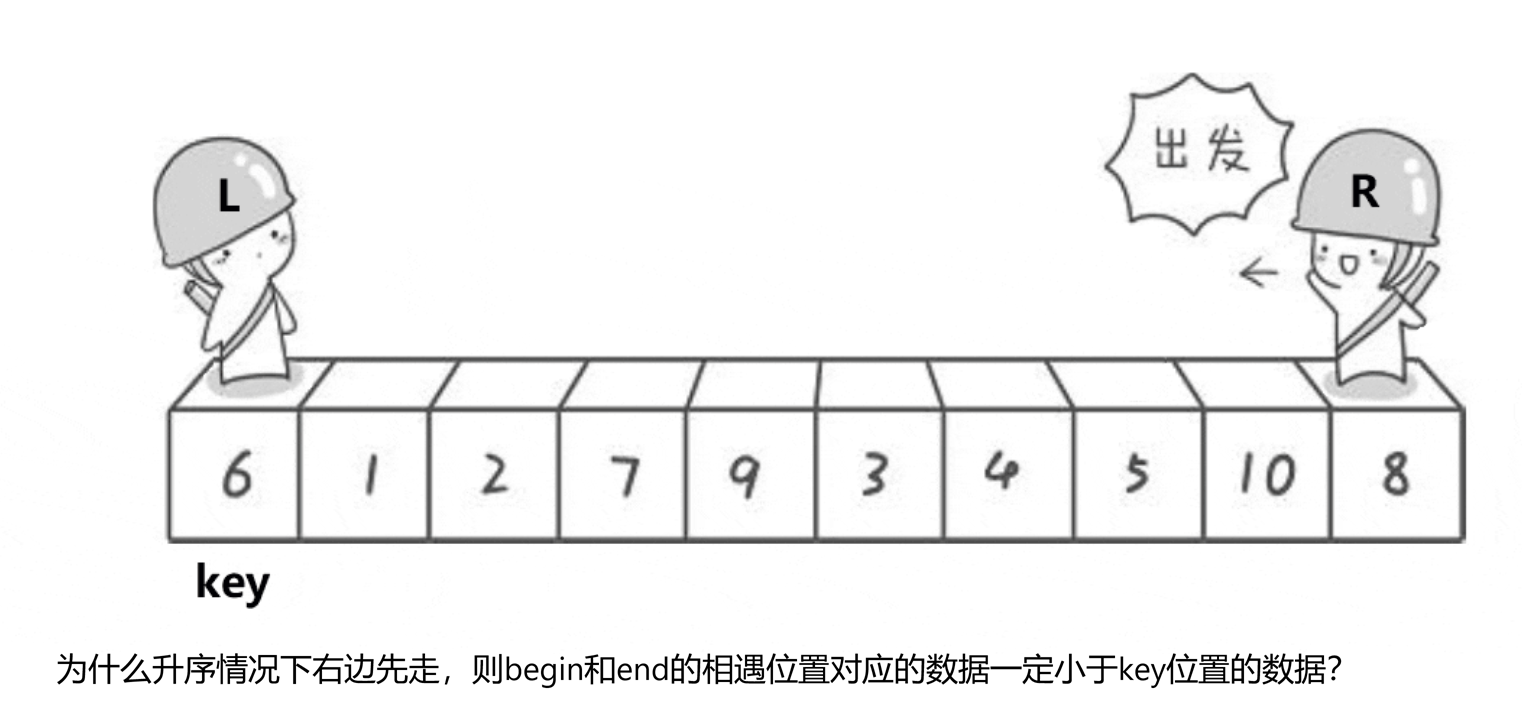
(先不解释为啥升序是end先走,后面自会有详细解释)
相遇无非就两种情况,要么begin遇到end,要么end遇到begin。
a.begin遇到end:
end先走,begin遇到end,那说明end肯定是停在了某个需要交换数据的位置上,也就是end找到了比key位置上的数据要小的数据,begin和end的相遇位置就是end停着的那个位置,也就是说相遇位置的数据是比key位置数据更小的数据。
b.end遇到begin:
end先走,直到遇见begin都没有找到需要交换的数据,由于每次都是end先走begin后走,等begin停下了了,就说明begin和end位置上的数据要交换了,则新一轮end遇到的begin,是上一轮已经交换过数据的的begin,begin位置上是比key位置更小的数据,所以在end遇到begin的情况下,相遇的位置的数据还是比key位置的数据要小。
②为什么升序需要end先走(先进行判断)?降序呢?
先明确一下,什么叫先走(先判断):即先判断end位置上的数据和key位置上的数据的大小关系。
让end先走先判断,就是为了让end掌握主动权在每一轮比较的开始,这样,无论是begin遇到找到小数据需要交换的end,还是end遇到上一轮已经变成小数据的begin,都能保证begin和end相遇位置的数据比key位置数据要小,交换后,才符合升序的题目要求。
如果是降序,就应该让begin先走先判断,这样begin掌握主动权在每一轮比较的开始,当begin遇到end时,就是begin遇到上一轮已经换成大数据的end,当end遇到begin时,就是end遇到找到大数据需要交换的begin了,这样才能保证begin和end相遇位置的数据是比key位置的数据大,再交换后,才能满足题目降序的要求。
③为什么内层循环的两个循环条件都带有等号?begin从key位置出发,会出现key位置的数据在begin和end相遇前被提前换走的情况吗(如何避免?)?
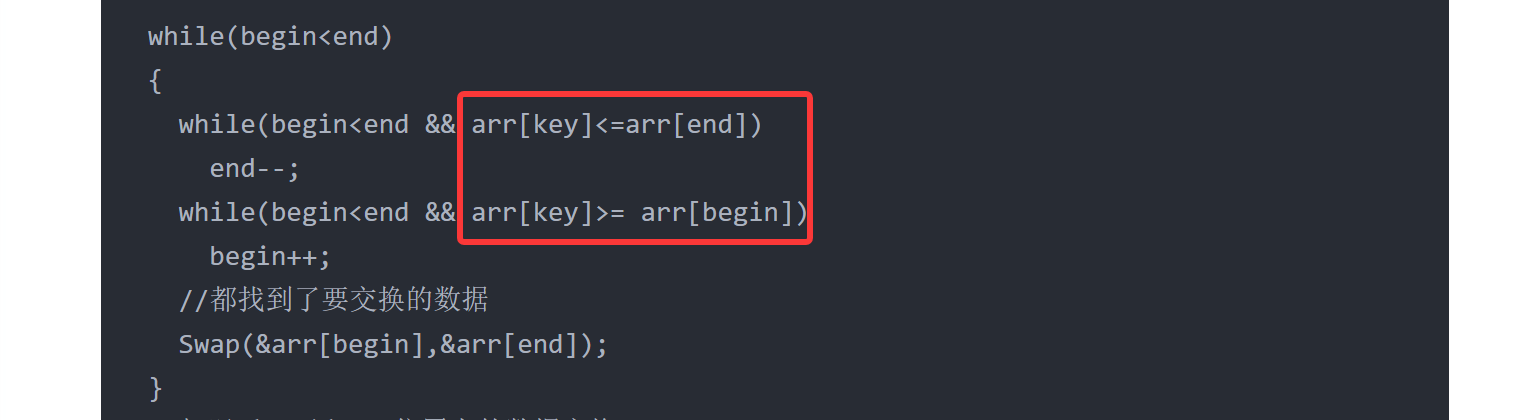
可能乍一想两边的判断都加=很奇怪,当两边的判断都加上=时,key位置的数据还能被交换到正确位置上吗?其实是可以的。
数组现在的构成是小于等于arr\[key arrkey 大于等于arrkey],arrkey所处的位置是合适的,等排好小于等于arr\[key]和大于等于arr\[key]两部分后,数组就能成为升序或降序。
那可以两边都不加=吗?
不行。
有一个特殊的情况,当数组的每个值都一样时,如果两边的判断都没有加上=,那么就会陷入死循环。
譬如数组3,3,3,3,begin=0,key=0,end=3,在判断的时候,arrend=3不大于arrkey需要交换,则end停在下标为3的位置,arrbegin=3不小于arrkey需要交换,则begin停在下标为0的位置,Swap之后,arrend=3和arrbegin=3依旧,那么还是不用end--、begin++,还是继续交换,可是交换后只会是无穷的交换,这就是陷入了死循环。
那可以一边有=一边没有=吗?
理论是可以的,一边有等号,遇到和arrkey相等的数据时不会停下,但另一边没有等号,遇到和arrkey相等的数据时会停下,等交换后,和arrkey相等的数据被换到了有等号的那边,进入循环,进行自减或自增,就跳过了与arrkey相等的数据,不会陷入死循环。
但这里还有一个问题:begin从key位置出发,会出现key位置的数据在begin和end相遇前被提前换走的情况吗?我们是通过什么来避免的?
先说结论:这个问题确实是会发生的,可我们能通过下面的红色语句来避免,也就是在比较时加上等号。
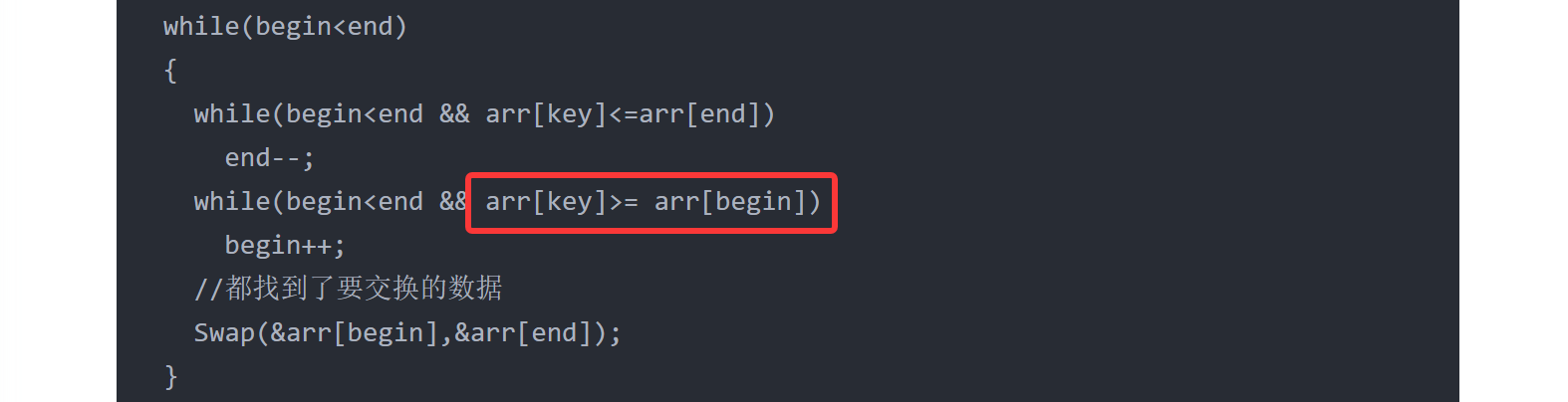
在begin比较时加上等号,这样从下标为0位置开始的begin遇到和arrkey数据相等的数据时,就可以进入循环begin++跳过第一个值,这样就不会存在key位置的数据在begin和end相遇前被提前换走的情况了。
所以结论是:不管end如何,begin这一端一定要加上等号。
④为什么内层循环的循环条件还有与一个begin<end?
如果不与上begin<end,那么到执行交换的语句的条件是end和begin都找到了要交换的数据,那么就不能处理begin和end相遇的情况,当begin遇到end时,end停在了大于arrkey的位置,可begin不会停下,而是会直接路过end向后走。所以需要与begin<end。
⑤为什么是定义数组首元素的下标为key,而不是数组首元素的值为key呢?
需要能真正交换数组内的数据,就不能是对临时变量进行交换,所以是下标而不是拷贝了数组值的临时变量,有点传值调用传址调用的意味。
⑥为什么递归的结束条件是left<=right?
等于比较好想,就是区间内只有一个数据,此时直接return,但left<right,其实可以假定key=right,在进入新的函数后,left=key+1=right原+1,right=right原,那么就有left<right了,这种情况也是不用再排序了递归了,直接return就好。
(2)前后指针法

(升序为例)如上图的初始情况,判断arrcur和arrkey的大小,如果arrcur大于arrkey,那就直接让cur向前走一步,如果arrcur小于arrkey,那就让prev向前走一步,然后交换pcur和prev位置的数据,再让cur向前走一步,直到pcur走出边界外,最后,再将prev位置的数据和key位置的数据进行交换就行。
2-1 代码实现
void Quicksort(int* arr,int left,int right)
{
//递归的结束条件
if(begin<=end)
return;
//小区间优化
if((right-left+1) < 10)
Insertsort(arr+left,right-left+1);
else
{
//三数取中
int mid = GetMid(arr,left,right);
Swap(&arr[left],&arr[mid]);
int key = left;
//前后指针法
int prev = left;
int pcur = prev+1;
while(pcur<=right)
{
if(arr[pcur]<=arr[key])
{
prev = prev+1;
Swap(&arr[prev],&arr[pcur]);
pcur = pcur+1;
}
else
pcur = pcur+1;
}
Swap(&arr[key],&arr[prev]);
key = prev;
//确定好了key位置对应的数据的位置
//递归
Quicksort(arr,left,key-1);
Quicksort(arr,key+1,right);
}
}2-2 细节分析
①前后指针是怎么实现升序的?
过程是prev从数组第一个位置开始,pcur从数组的第二个位置开始,判断arrpcur和arrkey的大小,如果arrpcur更大,则只让pcur向下走一步,这样大于arrkey的数也被夹在prev和pcur之间,如果arrpcur更小,则prev先向下走一步(prev走到了prev和pcur之间夹的大于arrkey的数据),再交换prev和pcur对应数据,这样小于arrkey的数据就被换到了prev的位置上,大于arrkey的数据就被换到了pcur的位置上,再让pcur走一步,这样大于arrkey的数又被夹在了prev和pcur之间。
按照这个过程进行下去,当pcur走出边界时,prev和pcur之间夹的是大于arrkey的数据,prev位置的数据是小于arrkey的,最后再交换prev和key位置的数据,就能让key走到它的正确位置。此时数组的构成就是小于等于arr\[key arrkey 大于等于arrkey]。等排好各个区间的顺序之后,就能实现升序。
②代码还能实现优化吗?
当pcur和prev之间没有夹数据时,pcur遇到比arrkey小的数据时,prev向后走一步,则prev和pcur指向了数组的同一位置,那么prev和pcur的数据交换,就是pcur自个之间的交换,这步其实是可以省略的;两个分支下都需要进行pcur=pcur+1,那就不用单独写else了,直接把pcur=pcur+1提出来。
最终的优化代码如下:
while(pcur<=right)
{
if(arr[pcur]<=arr[key] && ++prev != prur)
//前置++,++prev后与pcur进行大小比较
//如果不相等,才进入if语句进行交换
Swap(&arr[prev],&arr[pcur]);
pcur = pcur+1;
}(3)挖坑法
(升序为例)取arrkey=arr0,数组的第一个位置形成坑位,end从数组最后先往前走找比arrkey小的数据,找到后填入数组的首位置(也就是坑位),那end停下的位置就是新的坑位,begin从数组前方向后找比arrkey大的数据,找到后填入坑位,然后begin停下的位置就是新的坑位了,直到begin、end相遇,再将arrkey填入begin、end坑位里。
(二)非递归版快速排序
快速排序最关键的是每次排序时的边界left、right(begin、end),只要每次都知道边界,其实排序并不难,要能存储边界值,又要能模拟体现递归的过程,我们可以利用栈实现快速排序的非递归。
(1)代码实现
void QuicksortNonR(int* arr,int n,int left,int right)
{
ST st;
STInit(&st);
STPush(&st,right);
STPush(&st,left);
while(!STEmpty(&st))
{
int begin = STTop(&st);
int begin0 = begin;
STPop(&st);
int end = STPop(&st);
int end0 = end;
STPop(&st);
//三数取中
int mid = GetMid(arr,begin,left);
Swap(&arr[begin],&arr[mid]);
int key = begin;
//三法取一
while(begin<end)
{
while(begin<end && arr[key]<=arr[end])
end--;
while(begin<end && arr[key]>= arr[begin])
begin++;
//都找到了要交换的数据
Swap(&arr[begin],&arr[end]);
}
//相遇后,要和key位置上的数据交换
Swap(&arr[begin],&arr[key]);
key = begin;
//右区间[key+1,end0]
//左区间[begin0,key-1]
if(key+1<end0)
{
STPush(&st,end0);
STPush(&st,key+1);
}
if(begin0<key-1)
{
STPush(&st,key-1);
STPush(&st,begin0);
}
}
STDestroy(&st);
}也可以小区间优化。
(2)细节理解
栈是如何模拟实现递归的过程的?
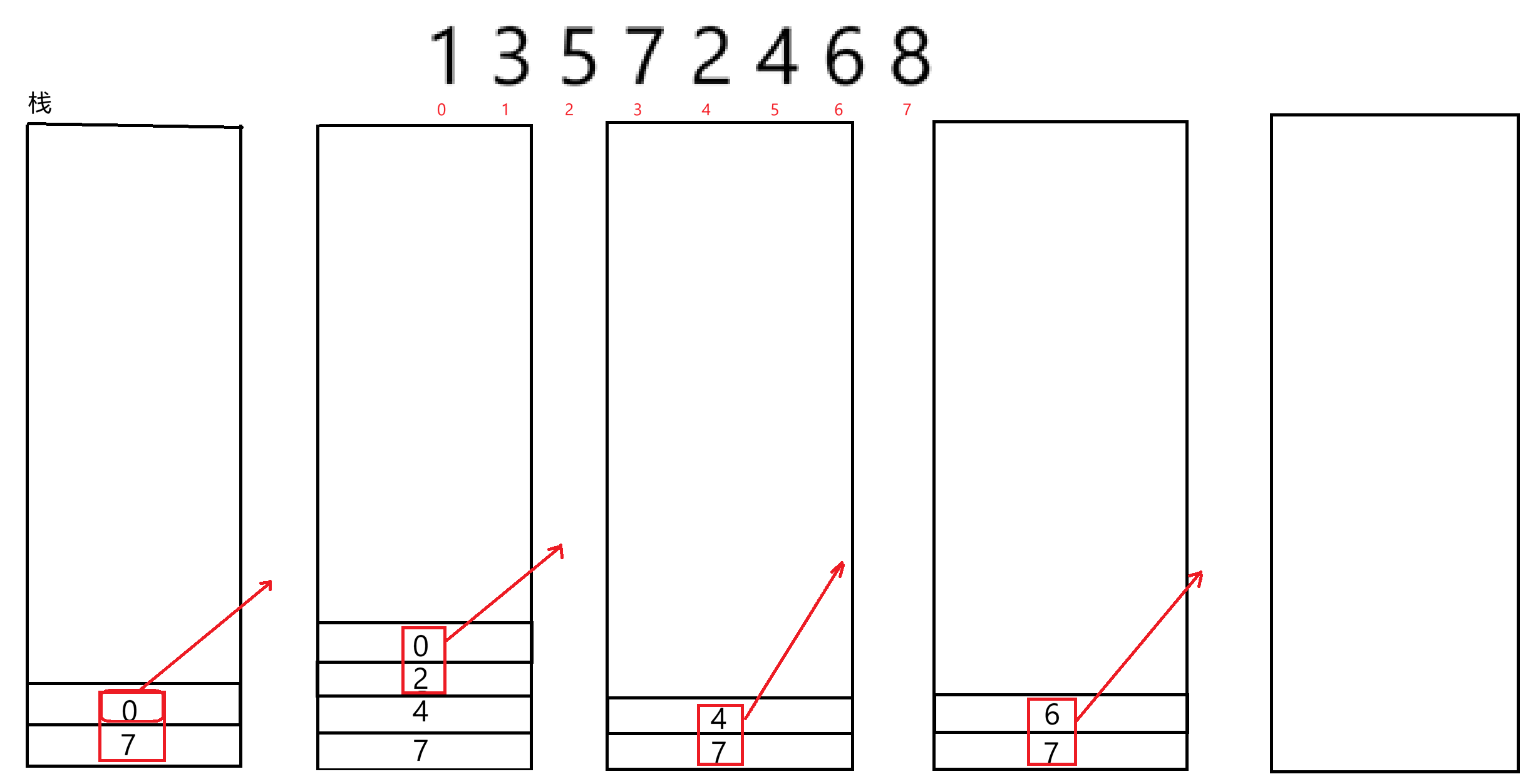
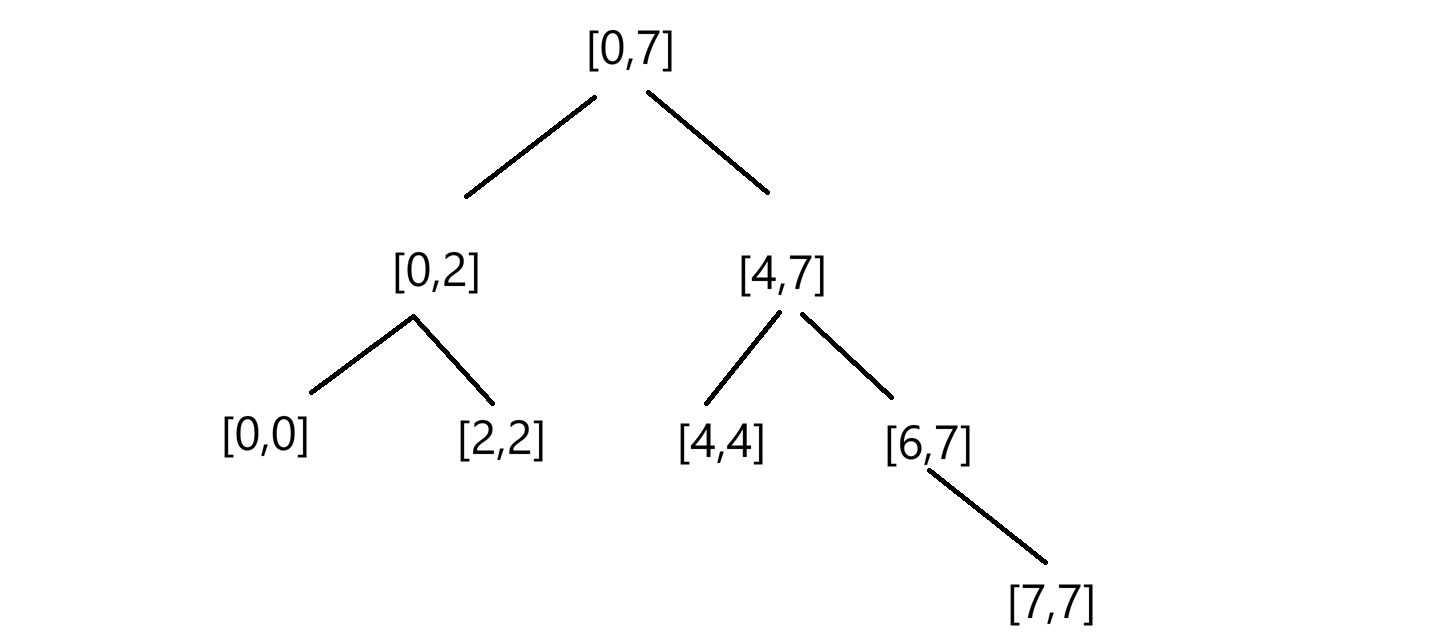
栈是先进后出,则我们先存右边界再存左边界,这样取出来就是先得到左边界再得到右边界,为了模拟递归的过程,那排序也是要先处理好左区间再看右区间,那么入栈应该是是入右区间的右左边界,再入左区间的右左边界,这样才能先取出左边界,如果左边界还能细分,就继续入栈小边界的边界值,就不会立刻取出右边界处理右区间的排序,而是先深入处理完左区间,这和递归的过程是相同的。
------end------