GPT架构
GPT 架构本质是 Transformer 的纯解码器(Decoder‑Only)堆叠 ,用因果掩码 做自回归生成,核心是多头自注意力 + 前馈网络 + 残差与层归一化。
使其在文本生成和对话任务中表现出色。这种架构的设计和其工作方式天然地适应了序列生成的需求。
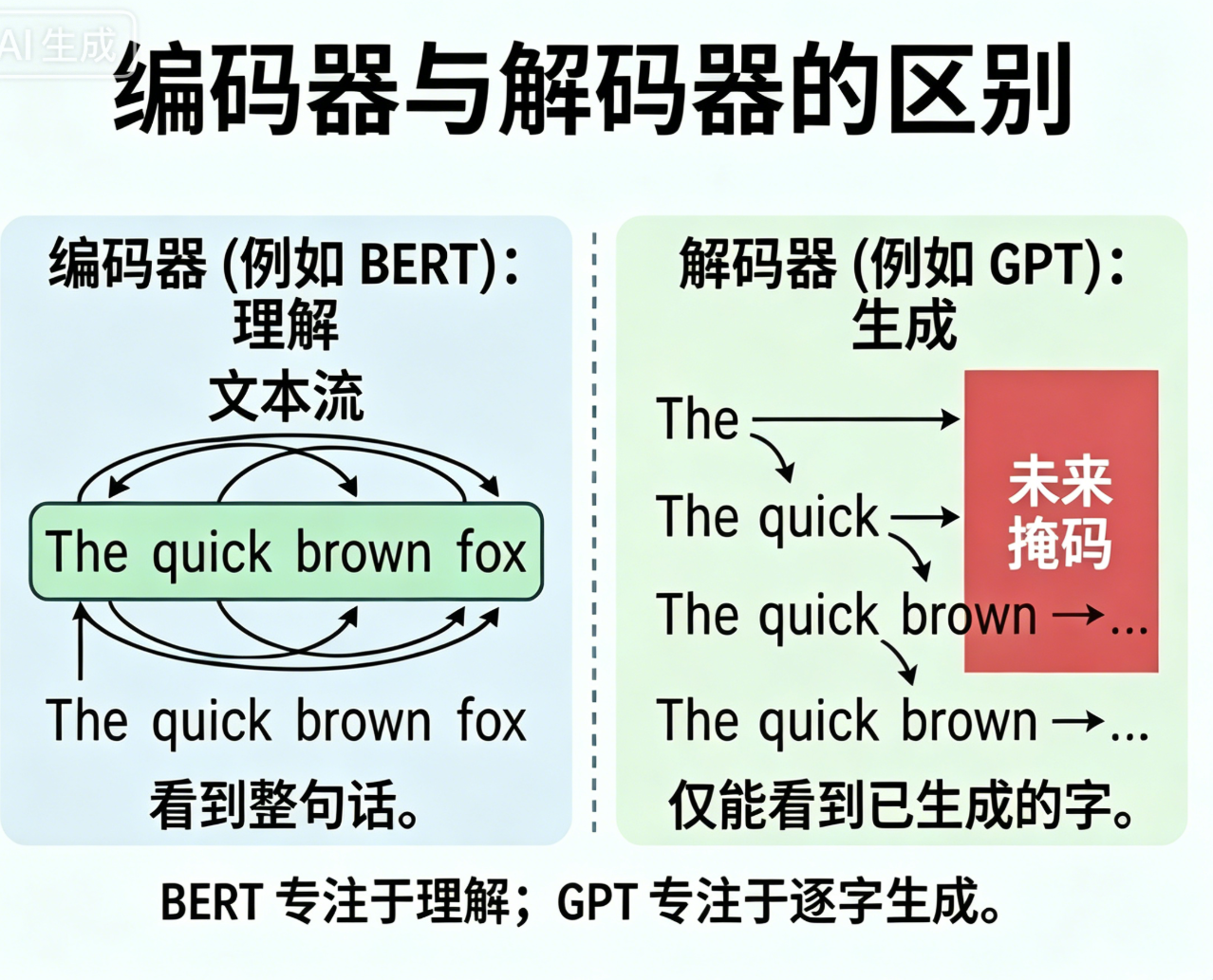
编码器和解码器区别
编码器:理解整句话;解码器:逐字生成新句子
编码器 Encoder(只负责理解)
-
结构:双向自注意力
-
能看到全文所有字,前后都能关联
-
作用:把原文压缩成语义特征
-
适用:翻译输入、文本分类、理解内容
-
代表模型:BERT
解码器 Decoder(只负责生成)
-
结构:单向掩码自注意力
-
只能看已经生成的字,看不到未来字
-
作用:按顺序逐词输出文字
-
适用:聊天、写诗、续写、回答
-
代表模型:GPT 全系(纯解码器)
GPT为什么使用纯解码器
天生适配逐字生成,结构最简单、生成效果最优
1. 任务天生就是自回归续写
GPT 做聊天、问答、续写,都是按顺序一个字一个字往外吐
解码器自带因果掩码,天然只能看前面文字、预测下一个字
编码器双向看全文,没法顺序生成文本。
2. 结构极简,训练推理效率高
-
纯 Decoder:一套模块反复堆叠,无编码器、无交叉注意力
-
参数利用率高,大参数量下更容易收敛、提速
3. 上下文连贯能力更强
单向建模语序、语法、上下文逻辑,贴合人类说话习惯
越长对话、越长文本续写,纯解码器稳定性更好。
4. 对比一眼看懂
-
纯编码器 (BERT) :理解分类强,不能生成
-
编解码 (翻译):适合一对一一对应转换
-
纯解码器 (GPT):自由创作、对话、长文本生成最强
GPT的核心优势
GPT 架构的核心是其单向注意力机制 ,这使其成为一个出色的自回归模型。
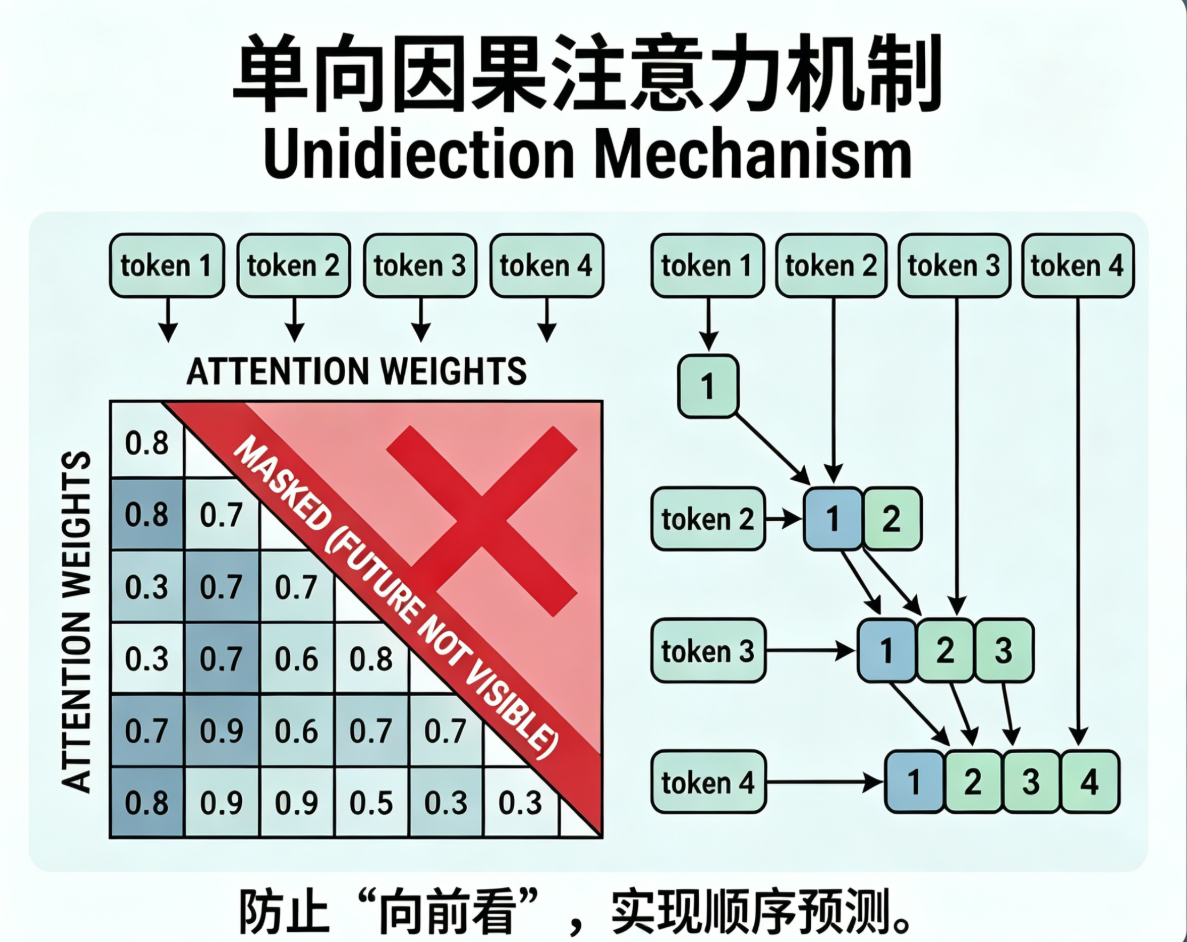
单向注意力机制(GPT 核心)
一句话:只能看向过去,不能偷看未来
1. 定义
只允许当前 token 关注它前面所有 token ,屏蔽后面未生成的 token ,也叫因果掩码注意力。
2. 原理:掩码遮掉未来位置
-
注意力矩阵上三角全部屏蔽
-
计算时只用到左侧历史文字
-
右边还没生成的字,直接看不见
3. 和双向注意力对比
-
单向注意力(GPT)
往前看、时序顺序、适合
生成文本
-
双向注意力(BERT)
前后都看、全局理解、适合
分类阅读理解
4. 工作流程
-
输入一串依次出现的字词
-
每个字只和前面已出现的字算关联
-
根据历史语义,预测下一个字
-
逐字输出,不会逻辑错乱、剧透未来
5. 核心特点
-
遵守语言先后顺序,符合人类说话逻辑
-
保证自回归生成合法合规
-
长对话上下文承接自然
-
结构简单,大模型训练推理高效
所以为什么GPT要使用纯解码机制,就是配合单向注意力机制
单向自回归机制
依靠单向注意力约束视野,逐序逐个生成文本的模式
-
单向
依托掩码注意力,每个字符仅能参照前文,无法看到后续未生成内容。
-
自回归
把上一步预测出的字符,并入输入序列,循环推算下一个字符。
运行流程
输入初始文本→单向注意力提取历史语义→预测单个 token→拼接回原文→重复迭代→生成完整语句
核心特点
-
严格遵循语序逻辑,不会出现语序颠倒、内容剧透
-
GPT 模型的基础生成模式
-
适配对话、续写、文案创作等场景
对比区分
-
单向:视野限制规则
-
自回归:迭代生成方式
-
单向自回归:二者结合的完整生成机制
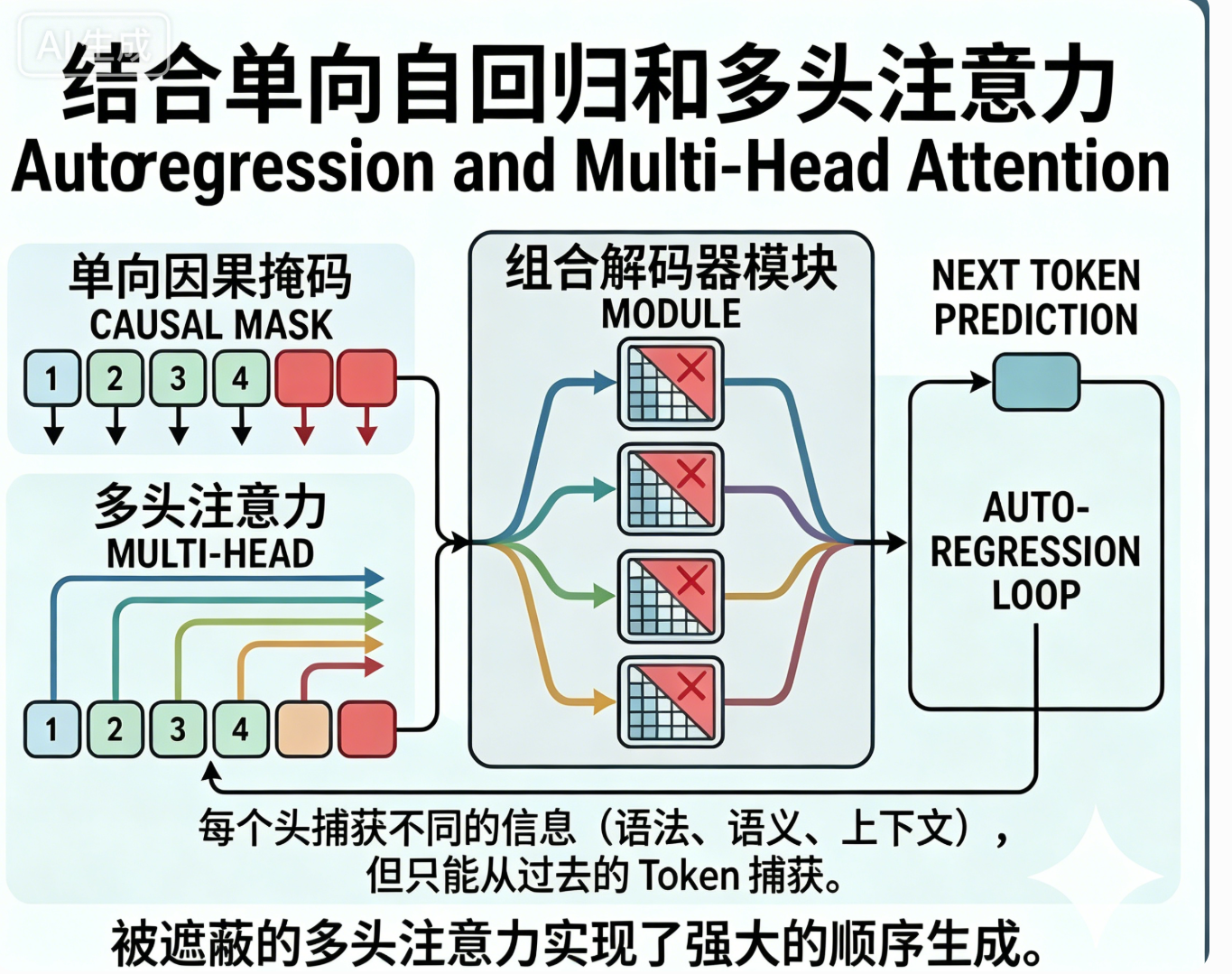
单向注意力和多头注意力区别
两个机制完全不冲突完全不冲突,两个是不同维度概念,可以叠加共存
多头注意力 :并行拆分计算
把单组注意力拆成多个头,各自捕捉词语远近、语法、语义等不同关联,最后拼接融合,提升表达能力。
单向注意力 :可视范围限制
用掩码挡住后续位置,规定每个 token 只能看向前文,禁止查看后文,约束时序规则。
组合逻辑(GPT 实际用法)
掩码多头单向注意力
-
先拆分多头,分头计算注意力权重
-
施加因果掩码,屏蔽未来位置
-
融合多头结果,完成特征计算
通俗类比
-
多头:多双眼睛同时观察文本
-
单向:每只眼睛只许看左边过往内容,不许看右边未出现内容
GPT的单向自回归和多头注意力