Ai-Agent学习历程------ 阶段2------LangChain Core(基本调用、tools、简单上下文等)
- 章节简介
-
- 第一阶段回顾
- 第二阶段简介
-
-
- [一、 LCEL 声明式流处理 (架构基石)](#一、 LCEL 声明式流处理 (架构基石))
- [二、 结构化输出与 Java 跨语言对齐 (重中之重)](#二、 结构化输出与 Java 跨语言对齐 (重中之重))
- [三、 上下文管理与长对话 (打破"金鱼记忆")](#三、 上下文管理与长对话 (打破“金鱼记忆”))
- [四、 Tool Calling 工具调用 (从 ChatBot 进化为 Agent)](#四、 Tool Calling 工具调用 (从 ChatBot 进化为 Agent))
- [五、 接入 LangSmith (AI 时代的"日志系统")](#五、 接入 LangSmith (AI 时代的“日志系统”))
- [六、 阶段最终实战 Demo:具备长记忆的天气智能 Agent](#六、 阶段最终实战 Demo:具备长记忆的天气智能 Agent)
-
- 前期准备
- [一、LCEL 声明式流处理 (架构基石)](#一、LCEL 声明式流处理 (架构基石))
-
- [1.1 核心概念与基础语法 (Hello World)](#1.1 核心概念与基础语法 (Hello World))
- [1.2 四种执行方式 (玩转 Runnable 接口)](#1.2 四种执行方式 (玩转 Runnable 接口))
- [1.3 数据路由与透传 (RunnablePassthrough 与字典构建)](#1.3 数据路由与透传 (RunnablePassthrough 与字典构建))
-
- [1. 为什么需要数据路由与透传?](#1. 为什么需要数据路由与透传?)
- [2. 核心概念](#2. 核心概念)
- [3. 实战代码:动态组装上下文](#3. 实战代码:动态组装上下文)
- [4. 数据流动慢动作回放](#4. 数据流动慢动作回放)
- [5. 为什么这在你的阶段三(RAG)中极其重要?](#5. 为什么这在你的阶段三(RAG)中极其重要?)
- [6. RunnableParallel的深层次思考(多个参数怎么搞)](#6. RunnableParallel的深层次思考(多个参数怎么搞))
- [1.4 工程化增强 (Fallbacks 容错处理)](#1.4 工程化增强 (Fallbacks 容错处理))
-
- [1. Fallback的必要性](#1. Fallback的必要性)
- [2. 代码实践](#2. 代码实践)
- [二、 结构化输出与 Java 跨语言对齐 (重中之重)](#二、 结构化输出与 Java 跨语言对齐 (重中之重))
-
- [2.1 蓝图定义 (Pydantic 核心回顾)](#2.1 蓝图定义 (Pydantic 核心回顾))
-
- [1. 核心思维转换:写给 AI 看的"注释"](#1. 核心思维转换:写给 AI 看的“注释”)
- [2. 实战演练](#2. 实战演练)
- [3. 代码解析与 Java 对比](#3. 代码解析与 Java 对比)
- [💡 架构师经验分享:`reasoning` 字段的魔法](#💡 架构师经验分享:
reasoning字段的魔法)
- [2.2 现代魔法:原生结构化输出 (`.with_structured_output()`)](#2.2 现代魔法:原生结构化输出 (
.with_structured_output())) - [2.3 传统手艺与容错兜底 (`PydanticOutputParser`)](#2.3 传统手艺与容错兜底 (
PydanticOutputParser)) -
- [(1)经典的 PydanticOutputParser](#(1)经典的 PydanticOutputParser)
- [(2)更强的 OutputFixingParser](#(2)更强的 OutputFixingParser)
- 三、上下文管理与长对话 (打破"金鱼记忆")
-
- [💡 架构层面的预热 (Java 视角)](#💡 架构层面的预热 (Java 视角))
- 思考为什么出现最大上下文的概念
-
- [1. 架构维度:纯粹的无状态 (Stateless) 与极致的扩缩容](#1. 架构维度:纯粹的无状态 (Stateless) 与极致的扩缩容)
- [2. 硬件原理:不仅是存硬盘,更是"存显存" (KV Cache)](#2. 硬件原理:不仅是存硬盘,更是“存显存” (KV Cache))
- [3. 商业与生态责任:把"记忆的控制权"交还给开发者](#3. 商业与生态责任:把“记忆的控制权”交还给开发者)
- [💡 结论与"破局之道"](#💡 结论与“破局之道”)
- [3.1 历史记录占位符 (MessagesPlaceholder)](#3.1 历史记录占位符 (MessagesPlaceholder))
-
- [(1)概念理论知识:什么是 MessagesPlaceholder?](#(1)概念理论知识:什么是 MessagesPlaceholder?)
- (2)详细例子:在控制台手动喂养占位符
- (3)运行与测试指南
- (4)总结
- [3.2 动态注入与会话隔离 (RunnableWithMessageHistory)](#3.2 动态注入与会话隔离 (RunnableWithMessageHistory))
-
- [(1) 概念理论知识:拦截器与会话存储](#(1) 概念理论知识:拦截器与会话存储)
- (2)详细示例:多用户交替聊天的"防串线"测试
- (3)现象复盘:为什么这证明了绝对隔离?
- [3.3 记忆修剪与压缩 (Token 极限控制) ------ 【工程化必修】](#3.3 记忆修剪与压缩 (Token 极限控制) —— 【工程化必修】)
-
- [(1)💡 核心策略设计1:保留"最近的 N 句话"](#(1)💡 核心策略设计1:保留“最近的 N 句话”)
- [(2)🚀 实战演示:记忆修剪过滤器](#(2)🚀 实战演示:记忆修剪过滤器)
- [🧐 (3)架构层面解析:为什么这么设计?](#🧐 (3)架构层面解析:为什么这么设计?)
- (4)核心策略设计2:合理的上下文压缩(滚动摘要)
- [四、Tool Calling 工具调用](#四、Tool Calling 工具调用)
-
- [4.1 认知重塑:Tool Calling 的底层协议 (它不是魔法)](#4.1 认知重塑:Tool Calling 的底层协议 (它不是魔法))
- [4.2 定义武器库:`@tool` 装饰器与 Schema 映射](#4.2 定义武器库:
@tool装饰器与 Schema 映射) - [4.3 绑定与截获:`bind_tools` 与 `tool_calls` 解析](#4.3 绑定与截获:
bind_tools与tool_calls解析) - [4.4 闭环反馈:`ToolMessage` 与工具路由 (Agent 雏形)](#4.4 闭环反馈:
ToolMessage与工具路由 (Agent 雏形)) -
- [(1)🚀 终极实战:手写一个原生的 Agent 循环!](#(1)🚀 终极实战:手写一个原生的 Agent 循环!)
- [(2)👨💻 架构师复盘:这就叫"智能体 (Agent)"!](#(2)👨💻 架构师复盘:这就叫“智能体 (Agent)”!)
- [(3)基于 InMemoryChatMessageHistory 和 MessagesPlaceholder 的改进](#(3)基于 InMemoryChatMessageHistory 和 MessagesPlaceholder 的改进)
- [💡 架构层面的预热:这和 Java 后端有什么关系?](#💡 架构层面的预热:这和 Java 后端有什么关系?)
- [五、 接入 LangSmith (AI 时代的"日志系统")](#五、 接入 LangSmith (AI 时代的“日志系统”))
-
- [5.1 零代码接入与环境配置 (Zero-Code Integration)](#5.1 零代码接入与环境配置 (Zero-Code Integration))
-
- [第一步:注册并获取 LangSmith 专属秘钥](#第一步:注册并获取 LangSmith 专属秘钥)
- 第二步:配置环境变量
- 第三步:制造监控数据
- 第四步:登录云端,查看数据
- 注意点:关于LangSmith的隐私保护
-
- [1. 私有化部署LangSmith](#1. 私有化部署LangSmith)
- [2. 数据动态脱敏](#2. 数据动态脱敏)
- [3. 寻找开源平替](#3. 寻找开源平替)
- [4. 手搓一个监控](#4. 手搓一个监控)
- [5.2 可视化监控与链路追踪 (Trace & Debugging)](#5.2 可视化监控与链路追踪 (Trace & Debugging))
-
- [🔍 视点一:宏观大盘与账单](#🔍 视点一:宏观大盘与账单)
- [🔬 视点二:显微镜下的瀑布流](#🔬 视点二:显微镜下的瀑布流)
- [🃏 视点三:看穿 AI 的底牌](#🃏 视点三:看穿 AI 的底牌)
- [🃏 视点四:分析底层的Token消耗](#🃏 视点四:分析底层的Token消耗)
- [🎯 架构师排错实战演练 (Debugging 场景)](#🎯 架构师排错实战演练 (Debugging 场景))
- 六、天气Agent实现demo
- 总结
章节简介
欢迎来到第二阶段:LangChain Core,核心链路构建。第一阶段我们是打了个地基,可以先简单回顾一下第一阶段。
第一阶段回顾
- conda: 这是在AI中使用的重头工具,解决不同版本Python的冲突,也是管理各种AI依赖的重要一员。
- Pydantic: 作为和Ai沟通的重要桥梁,Pydantic绝对是核心工具,这是解决格式转换必不可缺的一项。
- Jupyter Notebook: 一个基于 Web 的
交互式计算环境,可以用来单步调试,但实际上有点不太好用,可以选择使用。
第二阶段简介
📝 简单来说大模型就是一个聪明的"无状态大脑 ",没有上下文和手脚,而Agent不就是赋予了大模型这些能力吗。所以这一章节我们主要是使用LangChain 这个框架给大模型装上记忆,从而达到长对话的效果,同时配备一些工具,实现多样化功能。
LangChain是老祖宗,虽然我们后期用的都是LanGraph,这一部分还是需要学习一下理论。但是我们是不会学习之前臃肿和过时的知识点,而是使用现代化的LCEL,更加的轻便。
本阶段的核心目标是:掌握现代化的大模型标准交互范式,具备让 AI 调用外部工具的"单点能力",并确保工程稳定性。
一、 LCEL 声明式流处理 (架构基石)
这是贯穿后续所有开发的语法灵魂。
- 核心概念 :彻底摒弃老旧的
Chain类,学习使用|(管道符) 构建Runnable协议流水线,实现数据像水流一样穿过各个组件。 - 异步与流式 :掌握
invoke(同步) 和stream(流式输出,这是后续做打字机效果、SSE 推送的基础)。 - 容错增强 :由于网络和大模型的不稳定性,在流水线中加入
.with_retry()(自动重试) 和.with_fallbacks()(主模型挂了自动切备用模型),提升工程健壮性。
二、 结构化输出与 Java 跨语言对齐 (重中之重)
解决"如何让 Java 听懂 Python AI 说话"的问题。
- Pydantic 进阶实战:复用第一阶段的知识,定义严格的 Python 数据模型。
- 格式锁定 :学习
PydanticOutputParser或模型原生的.with_structured_output()方法,强制大模型输出合法的 JSON 字符串。 - 对齐意义 :确保输出的数据可以直接传给 Java 后端,通过
Jackson或Fastjson安全反序列化为 Java 对象。
三、 上下文管理与长对话 (打破"金鱼记忆")
解决大模型原生无状态的问题。
- Message History 机制:学习大模型是如何通过携带历史记录(Chat History)来实现"记事"的。
- 动态注入 :掌握
RunnableWithMessageHistory,实现基于内存 (List) 或外部缓存的 Session 级别上下文管理,让天气助手能应对"北京天气如何?" -> "那上海呢?" 这种追加提问。
四、 Tool Calling 工具调用 (从 ChatBot 进化为 Agent)
赋予 AI 改变世界的能力。
- 定义工具 :使用
@tool装饰器,将普通的 Python 函数(如查询数据库、调用天气 API)包装成大模型能懂的工具。 - 绑定与调用 :使用
.bind_tools()将工具挂载到模型上,解析模型返回的tool_calls结构。 - 【防坑预警】 :千万不要去学网上的老教程使用
AgentExecutor或initialize_agent!那些已经被淘汰。这一步只学原生的工具绑定,为第四阶段的 LangGraph 打下纯净的基础。
核心目标:打破大模型"只能打字聊天"的结界,赋予它联网查数据、读写数据库、调用企业微服务的"手和脚"。
五、 接入 LangSmith (AI 时代的"日志系统")
解决"AI 发疯了怎么办"的排查难题。
- 零代码接入:通过配置环境变量开启 Trace。
- 可视化监控:在云端后台查看每一轮对话中,Prompt 具体是什么样、耗时多久、Token 消耗多少、Tool 工具调用的参数对不对。
六、 阶段最终实战 Demo:具备长记忆的天气智能 Agent
- 验收目标:将上述六个模块融会贯通。写一个能记住用户上下文、能自动调用天气 API 查数据、能将天气结果转化为结构化 JSON 建议输出的智能助手,并在 LangSmith 中跑通完整的监控链路。
前期准备
- Python环境: 这里我是用的是Conda搭建的Python环境,版本是"3.13.12"。
- Pycharm工具: 这里我使用的是2026.1最新版。
- AI模型准备: 目前使用DeepSeekV4进行操作。
备注:DeepSeek模型密钥在官网开发者平台自己搞一个,成本控制在几块。
一、LCEL 声明式流处理 (架构基石)
首先我们需要对照官方文档进行学习,同时最好配备Gemini,这是一个非常好的学习搭子。
关于文档的选择,如果英文好的话可以看官网,经过对比发现中文网实际上核心都差不多。
1.1 核心概念与基础语法 (Hello World)
- 目标 :理解 LangChain 中的上帝接口:
Runnable。 - 内容 :
- 理解在 LangChain 中,几乎所有的组件(Prompt, 模型, 解析器)都实现了
Runnable协议。 - 学习使用管道符
|将这三个基础组件拼接成一条流水线(Chain)。 - 实操:写一个最简单的翻译助手流水线(输入中文 -> 输出英文)。
- 理解在 LangChain 中,几乎所有的组件(Prompt, 模型, 解析器)都实现了
(1)官网对应文档
可以先简单看一下这个文档,针对这一部分内容,实际上一个例子就可以了。
(2)核心方法的对应参数
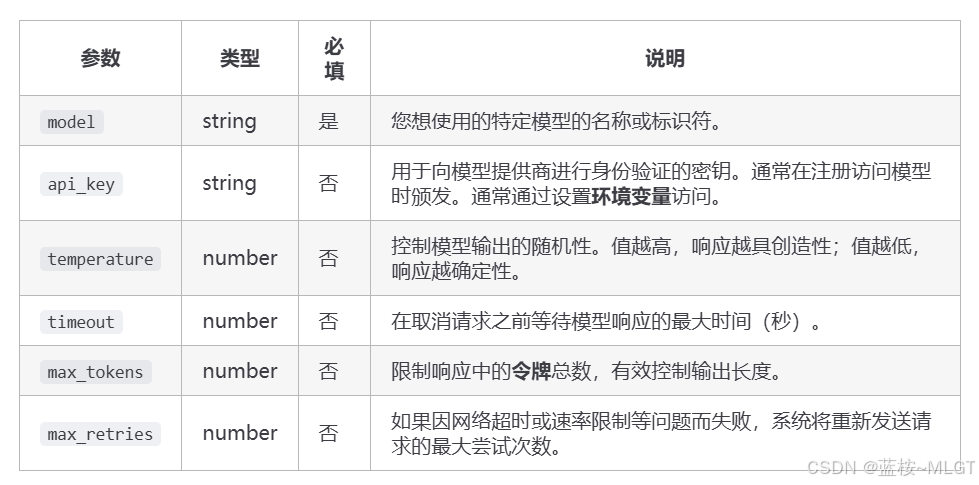
(3)代码实践
解决环境问题
插播一条内容,如果是最新版Conda在使用pycharm创建项目时可能会提示下面的内容
powershell
CondaToSNonInteractiveError: Terms of Service have not been accepted for the following channels. Please accept or remove them before proceeding:
- https://repo.anaconda.com/pkgs/main
- https://repo.anaconda.com/pkgs/r
- https://repo.anaconda.com/pkgs/msys2
To accept these channels' Terms of Service, run the following commands:
conda tos accept --override-channels --channel https://repo.anaconda.com/pkgs/main
conda tos accept --override-channels --channel https://repo.anaconda.com/pkgs/r
conda tos accept --override-channels --channel https://repo.anaconda.com/pkgs/msys2
For information on safely removing channels from your conda configuration,
please see the official documentation:
https://www.anaconda.com/docs/tools/working-with-conda/channels
1: 进程 C:\Users\19355\Miniconda3\condabin\conda.bat create -y -n stydy2 python=3.13 已退出,代码为 1一旦出现上面的内容,虽然代码能正常运行,因为Python环境还是在的,就是得手动在控制台激活Conda,无法直接执行pip命令,所以需要进行简单的配置。
- 打开Conda自带的控制台
- 依次执行下面的几个命令
- 错误原因:更新后官网需要默认接受几个协议条款,因为我们没有打开Conda的客户端,当然也不需要下载那东西。
bash
conda tos accept --override-channels --channel https://repo.anaconda.com/pkgs/main
conda tos accept --override-channels --channel https://repo.anaconda.com/pkgs/r
conda tos accept --override-channels --channel https://repo.anaconda.com/pkgs/msys2安装对应的依赖
bash
# 确保安装了最新的核心包和 OpenAI 接口包
pip install -U langchain-core langchain-openai
# 安装从环境变量读取API密钥的依赖
pip install -U python-dotenv langchain-core langchain-openai具体Demo
创建一个.env文件,写入配置的DeepSeek密钥
bash
DEEPSEEK_API_KEY=sk-xxxxxxxxxxxxxxx
python
import os
from dotenv import load_dotenv
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
# 1. 【加载配置】自动读取 .env 文件中的键值对到系统环境变量中
load_dotenv()
# 2. 【核心组件】创建 Prompt 和 Parser (这两者与具体的模型无关,完全解耦)
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个资深的程序员。请用一句简短的话,解释给定的技术名词。"),
("user", "名词:{topic}")
])
parser = StrOutputParser()
# 3. 【实例化模型 B】: DeepSeekV4
# 因为 DeepSeek 兼容 OpenAI 格式,直接用 ChatOpenAI,但要覆盖 base_url 和 api_key
llm_deepseek = ChatOpenAI(
model="deepseek-v4-pro", # DeepSeek 的模型调用名称(视官方最新文档而定,代表 V4)
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com", # DeepSeek 的官方接口地址
temperature=0.7
)
# 4. 【组装流水线】使用 LCEL
chain_deepseek = prompt | llm_deepseek | parser
# 5. 执行测试
topic = "面向对象编程(OOP)"
# 测试 DeepSeek
print("🧠 正在呼叫 DeepSeekV4...")
result_deepseek = chain_deepseek.invoke({"topic": topic})
print(f"✅ DeepSeek 输出: {result_deepseek}\n")输出效果:

代码关键解析(重点)
在阅读代码之后有一个关键的写法如下:
python
chain = prompt | llm | parser初次看到这一段是非常懵的,我也是,经过资料查阅这段代码的原始结构为:
python
# 传统的嵌套调用写法(很难看)
result = parser.invoke(llm.invoke(prompt.invoke({"topic": "黑洞"})))这里对应的就是Java中的 Function 接口的 .andThen() 方法,原理就是:把左边组件的输出,无缝当作右边组件的输入
java
// 在 Java 中完全等价的伪代码思维:
Function<Map, PromptValue> promptFunc = prompt;
Function<PromptValue, AIMessage> llmFunc = llm;
Function<AIMessage, String> parserFunc = parser;
// chain 本质上是一个组合后的宏大 Function
Function<Map, String> chain = promptFunc.andThen(llmFunc).andThen(parserFunc);
// 只有当你调用 invoke 时,流水线才真正开动
String result = chain.apply(Map.of("topic", "黑洞"));至于为什么这么写,因为这几个接口都实现了Runnable接口,所以可以通过链式调用,而Langchain内部封装了这种写法,是非常方便的。
1.2 四种执行方式 (玩转 Runnable 接口)
- 目标:掌握流水线组装好后,如何触发运行。
- 内容 :
invoke(input): 同步调用。(最常用,类似单次 HTTP 请求)stream(input): 流式调用。(极其重要!这是前端实现打字机效果、Java 后端对接 SSE 的基石)batch([input1, input2]): 批处理。(并发执行多条任务)ainvoke,astream: 了解它们的异步(Async)版本(Python 的async/await语法)。
在上一阶段我们使用了简单的invoke同步方法进行测试,这是简单的同步调用,和在java中执行一个数据库请求差不多,必须等待结果返回才会进行下一步,但是正常情况下完全不符合要求,一般AI都是流式输出的,或者说异步请求。
(1)stream和batch调用方式
python
import os
from dotenv import load_dotenv
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
import time
# 1. 【加载配置】自动读取 .env 文件中的键值对到系统环境变量中
load_dotenv()
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个富有诗意的讲解员。请用大约50个字生动地解释给定事物。"),
("user", "事物:{topic}")
])
# 实例化模型与流水线
llm = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v1",
temperature=0.7
)
parser = StrOutputParser()
chain = prompt | llm | parser
# ==========================================
# 演示 1:Stream (流式输出) -> 打字机效果
# ==========================================
print("\n" + "="*40)
print("▶️ 开始演示 Stream (流式输出)")
print("="*40)
topic_stream = "黑洞"
print(f"请讲解:{topic_stream}\n回复: ", end="", flush=True)
# chain.stream 返回的是一个生成器 (Generator)
# 大模型每生成一个字/词 (chunk),就会进入一次 for 循环
for chunk in chain.stream({"topic": topic_stream}):
# print(..., end="", flush=True) 用于在控制台同一行打印,不换行
print(chunk, end="", flush=True)
# 稍微睡一下,让你能更明显地看清打字机效果(实际业务中不需要)
time.sleep(0.05)
print("\n\n(流式输出完毕)")
# ==========================================
# 演示 2:Batch (并发批处理)
# ==========================================
print("\n" + "="*40)
print("▶️ 开始演示 Batch (并发批处理)")
print("="*40)
# 传入一个包含多个字典的 List
topics_batch = [
{"topic": "量子力学"},
{"topic": "Java Spring"},
{"topic": "区块链"}
]
print("正在并发请求 3 个名词的解释,请稍候...")
start_time = time.time()
# invoke 是串行,batch 底层会自动开线程并发请求
results = chain.batch(topics_batch)
end_time = time.time()
for i, res in enumerate(results):
print(f"\n[{topics_batch[i]['topic']}] 的解释:")
print(res)
print(f"\n⏳ 批处理总耗时: {end_time - start_time:.2f} 秒")运行结果:
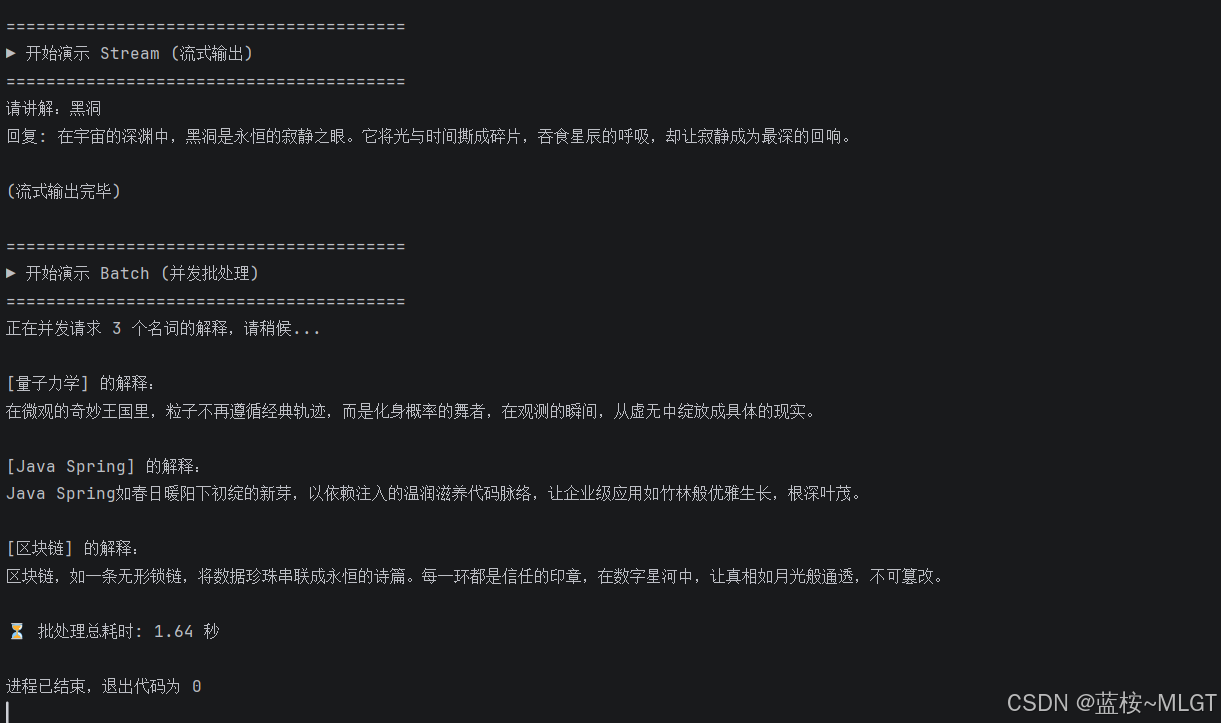
其实这段代码也不难,只是为了让我们了解这种调用方式。
(2)ainvoke和astream
这是异步调用的方式,当然一般情况下很少遇到,这里不做演示,用到的时候自行搜索即可。
1.3 数据路由与透传 (RunnablePassthrough 与字典构建)
- 目标:解决复杂参数传递的问题。
- 痛点:第一步的流水线往往只有一个输入变量(比如直接传一段话)。但实际业务中,Prompt 可能需要多个变量(例如:传入"用户输入"的同时,还要传入"当前时间"和"用户的上下文")。
- 内容 :
- 学习如何向流水线的起始端喂入一个 Dictionary(Map)。
- 学习组件
RunnablePassthrough,它允许你把上一层的数据原封不动地"透传"给下一层。
1. 为什么需要数据路由与透传?
在前面的例子中,我们在触发流水线时,总是老老实实地传一个字典:
chain.invoke({"topic": "黑洞"})
但这在实际开发中非常死板。想象以下两个场景:
- 场景A(输入不匹配) :前端传给你的就只是一个纯字符串
"黑洞",但是你的Prompt里却需要两个变量,比如{topic}和{language}。你怎么把一个简单的字符串,动态"包装"成复杂的字典喂给 Prompt? - 场景B(数据拼装) :在你路线图的第三阶段"RAG 知识检索"中,用户提问是
"如何请假"。你需要拿这句话先去数据库 里搜出规章制度(Context),然后再把 问题 + 规章制度 一起喂给大模型。
这就需要用到 LangChain 的神级组件:RunnablePassthrough(直译为:可运行的透传组件)。
2. 核心概念
把 RunnablePassthrough() 想象成 Java Stream 里的 Function.identity(),也就是 x -> x。它的作用就是接收上一层传来的东西,原封不动地传给下一层。
更强大的是,在 LCEL 中,如果你写了一个普通的 字典 (Dictionary) ,并且字典的值(Value)是 Runnable,LangChain 底层会自动把这个字典升级为一个 并行处理节点 (RunnableParallel)。
3. 实战代码:动态组装上下文
新建文件 test_passthrough.py
python
import os
from dotenv import load_dotenv
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
# 引入透传组件!
from langchain_core.runnables import RunnablePassthrough
load_dotenv()
# 1. 定义一个需要【两个变量】的 Prompt
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个编程老师。请结合【{language}】这门语言的特性,用一句话解释【{topic}】这个概念。"),
("user", "开始解释吧。")
])
llm = ChatOpenAI(model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v1",
temperature=0.7)
parser = StrOutputParser()
# 2. 模拟一个外部函数(比如去查数据库、查全局配置,或者获取当前时间)
def get_current_language(input_string):
# 这里我们简单模拟,如果是实际项目,这里可能是查库逻辑
return "Java"
# 3. 【核心!】构建数据组装节点
# 当输入流经这个字典时,它会并发执行字典里的每一项:
setup_and_retrieval = {
# 拿到用户的原始输入字符串,原封不动地塞给 "topic" 键
"topic": RunnablePassthrough(),
# 拿到用户的原始输入字符串,传给自定义函数去执行,把返回值塞给 "language" 键
"language": get_current_language
}
# 4. 组装终极流水线
# 现在的流水线是四步: 组装数据 -> Prompt -> LLM -> Parser
chain = setup_and_retrieval | prompt | llm | parser
# ========================================================
# 5. 执行测试:注意看 invoke 里的参数!
# ========================================================
print("正在测试数据透传...")
# 奇迹发生:我们直接传入一个纯字符串,而不是字典!
# 为什么可以这样?因为第一站的 setup_and_retrieval 会把它拦截下来,包装成字典。
result = chain.invoke("多态 (Polymorphism)")
print(f"\n✅ 最终输出:\n{result}")4. 数据流动慢动作回放
- 输入 :字符串
"多态 (Polymorphism)" - 到达
setup_and_retrieval节点 :"topic": RunnablePassthrough()发现输入是"多态",于是把它透传过来。"language": get_current_language发现输入是"多态",把它传给get_current_language函数,函数返回"Java"。- 节点输出 :生成了一个字典
{"topic": "多态 (Polymorphism)", "language": "Java"}
- 到达
prompt节点:它正好需要这两个 Key,完美填充! - 后续的 LLM 和 Parser 照常工作。
5. 为什么这在你的阶段三(RAG)中极其重要?
在未来的知识库问答中,你的代码结构将是这样的:
python
retrieval_chain = {
"context": retriever, # 去 Milvus 向量库查资料
"question": RunnablePassthrough() # 原封不动保留用户的提问
} | prompt | llm正是 RunnablePassthrough 这个小小的组件,把"死"的顺序执行链,变成了可以中途抓取外部数据的"活"网。
6. RunnableParallel的深层次思考(多个参数怎么搞)
📝 调用大模型实际上就是通过官方的方法传递对应的参数,获取到想要的结果。但是这个参数怎么动态的拼接更加优雅是个问题,总不能按照我们正常的编程一样,前面写一堆准备工作,最后拼接参数对象进行传递,这对大模型来说还是有点Low的。
python
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个编程老师。请结合【{language}】这门语言的特性,用一句话解释【{topic}】这个概念。"),
("user", "开始解释吧。")
])这段代码核心就在system的value中那两个参数,而我们使用优雅的方式给值的时候是通过
python
setup_and_retrieval = {
# 拿到用户的原始输入字符串,原封不动地塞给 "topic" 键
"topic": RunnablePassthrough(),
# 拿到用户的原始输入字符串,传给自定义函数去执行,把返回值塞给 "language" 键
"language": get_current_language
}topic: 使用RunnablePassthrough接收。
language: 使用get_current_language函数接收。
其实吧,RunnablePassthrough就是lambda表达式,这和 lambda x: x 是一样的。
但实际在开发过程中,前台很少会只有一个参数,即使前台只有一个,后台也必须拼接一堆其他的参数进行限制,不然结果是不准确的。所以多个参数的情况下,这个代码应该怎么写,让我们研究一下子。
python
from langchain_core.prompts import ChatPromptTemplate
# 引入 itemgetter,专门用来从字典里"摘取"字段
from operator import itemgetter
# 1. 假设这是你的 Prompt,它需要三个参数
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专属客服。当前用户VIP等级:{vip_level}。请根据用户上传的图片(内容描述:{img_desc}),回答他的问题。"),
("user", "问题:{ask}")
])
# 2. 模拟根据 user_id 去查数据库的函数
def fetch_vip_level(user_id):
# 真实场景里这里会执行 SELECT * FROM user WHERE id = user_id
if user_id == "u_1001":
return "钻石VIP"
return "普通用户"
# 3. 模拟图像识别服务 (把前端传的 base64 图片转成文字描述)
def analyze_image(img_base64):
if img_base64:
return "这是一张包含 Java 代码报错截图的图片"
return "无图片"
# 4. 【核心编排!】处理前端传来的多参数复杂字典
setup_data = {
# 单纯提取,用 itemgetter 没问题 (因为不需要用 |)
"ask": itemgetter("question"),
# 提取并处理:直接用 lambda!
# 意思是:传入整个字典 x,取出 user_id,丢进函数里
"vip_level": lambda x: fetch_vip_level(x["user_id"]),
# 同理
"img_desc": lambda x: analyze_image(x["image_base64"])
}
# 5. 组装链条 (我们先不加 llm,只加 prompt 看看组装效果)
chain = setup_data | prompt
# 6. 模拟前端发来的 JSON 数据
frontend_request = {
"question": "这段代码怎么老是报 NullPointer?",
"user_id": "u_1001",
"image_base64": "fake_base64_string_here",
"other_useless_info": "这个字段会被丢弃"
}
print("开始处理前端复杂请求...")
# 触发流水线
final_prompt_value = chain.invoke(frontend_request)
print("\n✅ LangChain 最终组装出来的 Prompt 长这样:")
print(final_prompt_value.messages[0].content)
print(final_prompt_value.messages[1].content)运行结果:

不要害怕之后遇到的那些专业且复杂的名词,只需要搞懂原理其实并不复杂,这有可能只是为了方便编程者的一种方式而已。
1.4 工程化增强 (Fallbacks 容错处理)
- 目标:加上这层防护,你的代码才敢上生产环境。
- 内容 :
- 学习
.with_fallbacks()。 - 实操:模拟配置一个主模型(如 OpenAI),一个备用模型。当故意把主模型 API Key 写错导致报错时,LCEL 会自动无缝切换到备用模型输出结果,保证服务不中断。
- 学习
1. Fallback的必要性
在调用第三方的API时不能保证其稳定性,尤其是AI本身就是极其不稳定的,经常会出现以下几种情况
- API平台宕机(尤其是现有的中转商)
- 瞬间并发太高,平台限流
- API余额不足
这其实对应的就是常见的服务降级、熔断等概念,我们需要一定的手段进行处理,比如:
- 调用备用模型
- 前台返回对应的提示如:服务器繁忙
备注:这里讲解是按照Agent的模式进行的,下面的例子中写法不太一样,但原理是一样的。
2. 代码实践
python
import os
from dotenv import load_dotenv, find_dotenv
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
import time
# 1. 自动向上寻找并加载 .env 文件中的环境变量
_ = load_dotenv(find_dotenv(), override=True)
# ==========================================
# 2. 定义配置(此时不产生任何网络开销)
# ==========================================
# 【必挂掉】的主模型配置 (用一个假 Key 模拟欠费或配额超限)
llm_primary = ChatOpenAI(
model="gpt-4",
api_key="sk-fake-key-123456",
max_retries=0,
timeout=5
)
# 【稳定】的备用模型配置 (从环境变量动态读取真实 Key)
llm_backup = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v1",
temperature=0.7
)
# 【核心装配】组装一个带有"降级保护"的聚合模型对象
llm_robust = llm_primary.with_fallbacks([llm_backup])
# ==========================================
# 3. 组装流水线
# ==========================================
prompt = ChatPromptTemplate.from_messages([
("user", "请用一句话解释:在微服务架构中,什么是降级(Fallback)机制?")
])
parser = StrOutputParser()
# 普通的裸奔流水线
chain_normal = prompt | llm_primary | parser
# 穿了防弹衣的流水线
chain_robust = prompt | llm_robust | parser
# ==========================================
# 4. 执行对比测试 (这里才真正开始发 HTTP 请求!)
# ==========================================
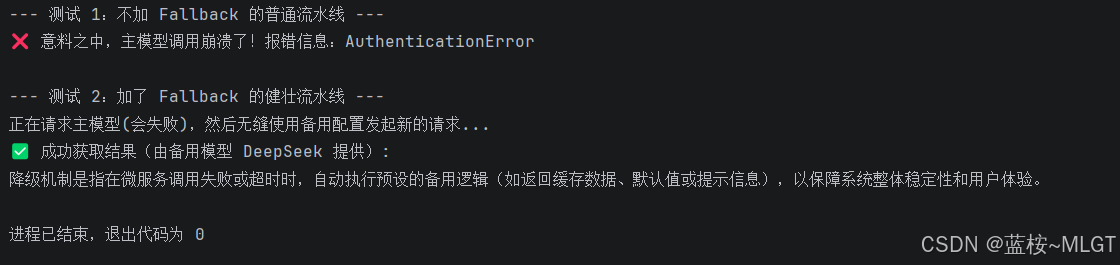
print("--- 测试 1:不加 Fallback 的普通流水线 ---")
try:
chain_normal.invoke({})
except Exception as e:
print(f"❌ 意料之中,主模型调用崩溃了!报错信息:{type(e).__name__}\n")
time.sleep(1)
print("--- 测试 2:加了 Fallback 的健壮流水线 ---")
print("正在请求主模型(会失败),然后无缝使用备用配置发起新的请求...")
try:
# 这里底层拦截了主模型的失败,自动使用了 llm_backup 的配置发出请求
result = chain_robust.invoke({})
print(f"✅ 成功获取结果(由备用模型 DeepSeek 提供):\n{result}")
except Exception as e:
print(f"❌ 竟然全挂了?报错信息:{e}")输出结果:
二、 结构化输出与 Java 跨语言对齐 (重中之重)
📝 在一般的AI对话输出的结果都是纯文本,且不带格式,这对程序来说无法做到很好的处理,如果我要要对其进行处理最好的是转换为JSON或者其他的格式。
2.1 蓝图定义 (Pydantic 核心回顾)
- 目标:告诉大模型,我们需要什么样的数据结构(类似 Java 里的定义 DTO / Entity)。
- 内容 :
- 复习你第一阶段学过的
Pydantic库。 - 学习如何使用
BaseModel和Field为字段添加"描述注释"(这对大模型的理解极其重要)。 - 实操 :定义一个
UserProfile(用户画像)类,包含姓名、年龄、兴趣爱好(List)等字段。
- 复习你第一阶段学过的
1. 核心思维转换:写给 AI 看的"注释"
在传统编程中,代码的注释或字段描述是写给程序员 看的,机器执行时会直接忽略。
但在大模型开发中,Pydantic 模型里定义的 Field(description="..."),就是直接写给大模型看的 Prompt(提示词)!
大模型会严格阅读你的 description,并按照你的要求去提取或推理数据。这就是所谓的Schema Engineering------结构工程。
2. 实战演练
python
from pydantic import BaseModel, Field
from typing import List, Optional
import json
# ==========================================
# 1. 定义数据蓝图 (等价于 Java 的 public class UserProfileDTO)
# ==========================================
class UserProfile(BaseModel):
# 基础类型 + 明确的描述
name: str = Field(description="用户的完整姓名。如果只提到了姓氏,请保留姓氏。")
# 增加一点逻辑性的描述,让大模型具备"推断能力"
age: Optional[int] = Field(default=None, description="用户的真实年龄。如果是成年人/未成年人等模糊描述,请设为 null。")
# 复杂类型:List 数组
hobbies: List[str] = Field(default_factory=list, description="用户的兴趣爱好列表。请提炼成2-4个字的简短标签,例如:['打篮球', '看书']。")
# 【高级技巧】思维链 (Chain of Thought) 字段
# 极其强烈建议在每个复杂的结构体最后,加上一个推理过程字段。
# 这就像让学生在写出最终答案前,先在草稿纸上写步骤,能大幅提高 JSON 提取的准确率!
reasoning: str = Field(description="请详细解释你是如何从原文中提取出上述信息的推理过程。")
# ==========================================
# 2. 揭秘:大模型真正看到的是什么?
# ==========================================
print("--- 这是你在 Python 里定义的类 ---")
print("class UserProfile(BaseModel): ...\n")
print("--- 这是 LangChain 偷偷发给大模型的 JSON Schema (底层协议) ---")
# Pydantic v2 的标准写法,将类转为 JSON Schema
schema_dict = UserProfile.model_json_schema()
print(json.dumps(schema_dict, indent=2, ensure_ascii=False))3. 代码解析与 Java 对比
运行这段代码后,你会看到控制台打印出了一长串 JSON。这就是 LangChain 在底层与大模型沟通的"暗号"。
对照Java 知识体系:
BaseModel:相当于让你的类实现了Serializable接口,赋予了它被序列化和校验的能力。name: str:相当于private String name;。Optional[int]:相当于 Java 的包装类Integer(允许为 null),而不是基本类型int。Field(description="..."):完美等价于 Swagger 里的@Schema(description = "...")或者 Fastjson 的@JSONField。
💡 架构师经验分享:reasoning 字段的魔法
请特别注意代码中的 reasoning(推理过程)字段。
如果你让大模型直接输出 {"age": 18},它可能脑子一热就猜错了。
但如果你规定结构体里包含 reasoning,大模型的生成顺序会是:先生成 reasoning: "用户说他刚上大一,通常大一学生是18岁...",然后再生成 age: 18。
这就相当于强行让大模型实现了 CoT(Chain of Thought 思维链),提取准确率可以直接飙升 30% 以上!
2.2 现代魔法:原生结构化输出 (.with_structured_output())
- 目标:掌握当前(2024-2026)业界最主流、最稳定的 JSON 提取方案。
- 内容 :
- 不再依赖在 Prompt 里苦口婆心地对大模型说"请输出 JSON",而是直接调用大模型底层 API 的原生能力。
- 学习模型对象的
.with_structured_output()方法。 - 实操 :输入一段混乱的用户留言(如:"我叫张三,今年18了,平时喜欢打篮球和写Java"),让大模型自动提纯并返回一个完美的
UserProfilePython 对象,并转换为 JSON 字符串。
(1)代码实战
阅读并运行以下代码,这串代码看起来是没有问题的,但弊端就是没有兼容性,虽然DeepSeek兼容了99%的openAi接口,但是一部分还是不行的,比如下面的 with_structured_output()。
python
import os
from dotenv import load_dotenv, find_dotenv
from pydantic import BaseModel, Field
from typing import List, Optional
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# 1. 加载环境变量 (读取你的 DEEPSEEK_API_KEY)
_ = load_dotenv(find_dotenv(), override=True)
# ==========================================
# 第一步:定义数据蓝图 (Pydantic DTO)
# ==========================================
class UserProfile(BaseModel):
name: str = Field(description="用户的完整姓名。如果只提到了姓氏,请保留姓氏。")
age: Optional[int] = Field(default=None, description="用户的真实年龄。")
hobbies: List[str] = Field(default_factory=list, description="用户的兴趣爱好列表。请提炼成2-4个字的简短标签。")
reasoning: str = Field(description="请详细解释你是如何从原文中提取出上述信息的推理过程。")
# ==========================================
# 第二步:初始化模型与绑定结构 (核心魔法)
# ==========================================
llm = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v1",
temperature=0 # 提取任务务必将 temperature 设为 0,保证稳定不发散
)
# 【核心!】让大模型原生支持结构化输出
# 这行代码告诉 DeepSeek:不要给我乱七八糟的废话,只准返回严格符合 UserProfile 结构的 JSON!
structured_llm = llm.with_structured_output(UserProfile)
# ==========================================
# 第三步:组装 LCEL 流水线并调用
# ==========================================
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个精准的信息提取专家。请从用户的口语化表达中提取所需字段。"),
("user", "{text}")
])
# 现在的流水线极度简洁:Prompt -> 绑定了结构的大模型
# 注意:我们这里不需要再手动加 StrOutputParser 了,因为 structured_llm 内部自带了解析器!
chain = prompt | structured_llm
# ==========================================
# 第四步:见证奇迹的时刻
# ==========================================
messy_text = "我叫李雷,韩梅梅是我同学。我今年刚大学毕业,已经22岁了。平时周末我基本都在峡谷里打王者荣耀,偶尔也去操场踢足球。"
print("正在分析用户输入:", messy_text)
print("-" * 40)
print("🧠 DeepSeek 正在努力提取并转换为 Python 对象...")
# 执行提取
result = chain.invoke({"text": messy_text})
# 打印结果和类型
print("\n✅ 提取成功!来看看结果对象的类型:")
print(type(result)) # 你会看到它是 <class '__main__.UserProfile'>
print("\n📦 可以像普通 Java/Python 对象一样直接点出属性:")
print(f"姓名 (name) : {result.name}")
print(f"年龄 (age) : {result.age}")
print(f"爱好 (hobbies): {result.hobbies}")
print(f"推理 (reason): {result.reasoning}")运行结果:

(2)json_schema协议兼容
出现上述问题的核心原因是我们使用了OpenAI的接口进行调用,所以LangChain默认会使用其新定义的功能Strict JSON Schema,底层使用了response_format={"type": "json_schema"} 协议,此时DeepSeek并没有完全兼容,所以这时候就需要降级了。
2.3 传统手艺与容错兜底 (PydanticOutputParser)
- 目标:为了兼容那些不支持原生结构化输出的"低端/旧版模型",以及处理解析报错。
- 内容 :
- 学习经典的
PydanticOutputParser,如何把格式要求动态注入到 Prompt 中(get_format_instructions())。 - 学习当大模型输出的 JSON 缺斤少两(比如漏了逗号)时,如何使用
OutputFixingParser(自动修复解析器)让大模型"返工"。 - 实操:使用低端模型,配合 OutputParser 强行提取 JSON,并体验自动修复报错的魔法。
- 学习经典的
(1)经典的 PydanticOutputParser
python
import os
from dotenv import load_dotenv, find_dotenv
from pydantic import BaseModel, Field
from typing import List, Optional
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
# 【核心引入】:传统解析器
from langchain_core.output_parsers import PydanticOutputParser
_ = load_dotenv(find_dotenv(), override=True)
# 1. 蓝图定义 (保持不变)
class UserProfile(BaseModel):
name: str = Field(description="用户的姓名")
age: Optional[int] = Field(default=None, description="用户的真实年龄")
hobbies: List[str] = Field(default_factory=list, description="兴趣爱好")
# 2. 实例化解析器 (重点来了)
# 把我们的 Pydantic 类塞进解析器里
parser = PydanticOutputParser(pydantic_object=UserProfile)
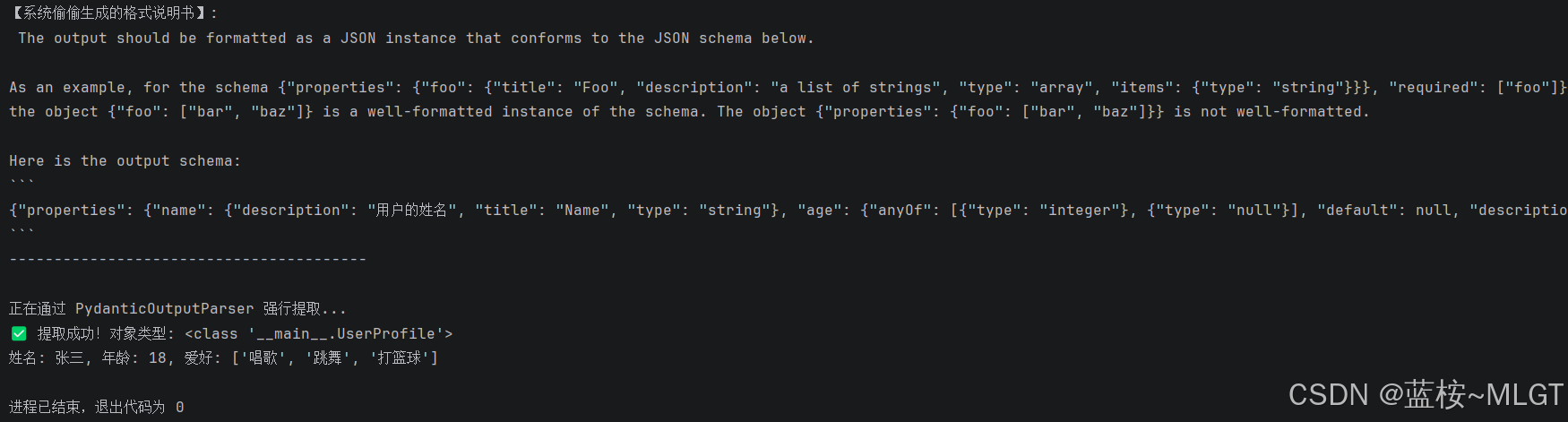
# 魔法:解析器能自动把类结构,翻译成一大串给大模型看的 Prompt 说明书!
format_instructions = parser.get_format_instructions()
print("【系统偷偷生成的格式说明书】:\n", format_instructions)
print("-" * 40)
# 3. 组装 Prompt (把说明书动态塞进去)
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个精准的信息提取专家。\n\n{format_instructions}"),
("user", "{text}")
])
# 4. 实例化模型 (普通的,不需要调用 with_structured_output)
llm = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v1",
temperature=0
)
# 5. 组装最经典的 LCEL 流水线
chain = prompt | llm | parser
# 6. 执行测试
messy_text = "我是张三,刚过完18岁生日,喜欢唱歌、跳舞、打篮球。"
print("\n正在通过 PydanticOutputParser 强行提取...")
# 必须把 format_instructions 传给 Prompt!
result = chain.invoke({
"text": messy_text,
"format_instructions": format_instructions
})
print("✅ 提取成功!对象类型:", type(result))
print(f"姓名: {result.name}, 年龄: {result.age}, 爱好: {result.hobbies}")运行结果:
(2)更强的 OutputFixingParser
在执行代码执行,先安装一个依赖
python
pip install -U langchain-classic
python
import os
from dotenv import load_dotenv, find_dotenv
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import PydanticOutputParser
# 【核心引入】:自动修复解析器
from langchain_classic.output_parsers import OutputFixingParser
_ = load_dotenv(find_dotenv(), override=True)
# 1. 定义数据蓝图
class Actor(BaseModel):
name: str = Field(description="演员的名字")
film_names: list[str] = Field(description="出演过的电影列表")
# 2. 实例化基础解析器
base_parser = PydanticOutputParser(pydantic_object=Actor)
# ==========================================
# 3. 案发现场:伪造一个"极其糟糕"的大模型输出
# ==========================================
# 错误点 1:用了单引号(标准的 JSON 必须用双引号)
# 错误点 2:缺少了最外层的结束大括号 '}'
# 错误点 3:列表末尾多了一个逗号
bad_response = "{'name': '吴京', 'film_names': ['战狼', '流浪地球',],"
print("🚨 大模型返回了残缺的字符串:")
print(bad_response)
print("-" * 40)
# ==========================================
# 4. 对比测试 A:使用普通解析器 (必然崩溃)
# ==========================================
print("💥 测试 1:普通解析器强行解析...")
try:
base_parser.parse(bad_response)
except Exception as e:
print(f"❌ 解析惨败!报错信息:\n{e}\n")
# ==========================================
# 5. 对比测试 B:召唤 OutputFixingParser 救场!
# ==========================================
print("🚑 测试 2:召唤 OutputFixingParser 进行修复...")
# 实例化一个用来"干杂活/修Bug"的大模型
# 修 Bug 不需要太聪明的模型,便宜且速度快的模型(如 DeepSeek)最合适
llm_fixer = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v1",
temperature=0
)
# 【核心装配】:用大模型把基础解析器包裹起来
fixing_parser = OutputFixingParser.from_llm(
parser=base_parser,
llm=llm_fixer
)
# 见证奇迹:它内部抓到了异常,并悄悄让 DeepSeek 帮你修复了 JSON!
fixed_actor = fixing_parser.parse(bad_response)
print("✅ 修复成功!来看看完美的 Python 对象:")
print(type(fixed_actor))
print(f"姓名: {fixed_actor.name}, 电影: {fixed_actor.film_names}")三、上下文管理与长对话 (打破"金鱼记忆")
- 目标:解决大模型原生无状态的问题,实现支持连续追问的多轮会话(Multi-turn Conversation)。
- 痛点 :
- 大模型的 API 本质上和纯 HTTP 协议一样,是绝对无状态的。
- 如果你问:"北京今天天气如何?",它会告诉你。紧接着你再发一次请求问:"那上海呢?",大模型会彻底懵掉,因为它完全记不得上一秒你刚问过天气。
- 如果在代码里手动维护一个 List,每次请求前自己去拼装所有的历史对话,不仅代码极度臃肿,而且很容易超出模型的 Token 限制。
- 内容 :
- 核心组件学习 :学习
MessagesPlaceholder。掌握如何在ChatPromptTemplate中预留一个动态的"占位符",用来在每次请求时,自动把历史对话记录整个塞进 Prompt 里。 - 现代化包装器 :彻底抛弃旧版 LangChain 中老旧的
ConversationChain或ConversationBufferMemory(它们已被标记为即将废弃)。学习使用最新的RunnableWithMessageHistory包装器。 - 会话隔离 (Session Management) :结合 Java 后端开发的经验,理解如何通过
session_id来隔离不同用户的记忆字典(这完全等价于 Java 里的HttpSession或者存在 Redis 里的 Token)。 - 实操:写一个可以连续追问的聊天机器人。当你说"我叫张三",再问"我刚才说我叫什么?"时,它能准确回答出来。
- 核心组件学习 :学习
💡 架构层面的预热 (Java 视角)
在进入代码实操前,需要建立一个架构直觉:
大模型怎么实现记忆?其实就是"笨办法"------每次都把以前聊过的话,原封不动地再给它发一遍。
- 第 1 次请求发给大模型 :
[User: 我叫张三] - 第 2 次请求发给大模型 :
[User: 我叫张三, AI: 好的,张三你好, User: 我叫啥?]
所以,上下文管理在底层做的唯一一件事,就是帮你自动拦截输入和输出,并存到一个数据库(或内存 Map)里,下次请求时自动拿出来拼装。
思考为什么出现最大上下文的概念
📝 问题: "我都付了 API 费了,服务器端也生成了对话 ID,凭什么还要我每次都把历史记录像搬砖一样来回传?大厂的服务器是买不起硬盘存我这点文本吗?"
要回答这个问题,我们要从架构设计、GPU 原理 和商业模式三个维度来彻底扒开大模型的底裤。
1. 架构维度:纯粹的无状态 (Stateless) 与极致的扩缩容
你在浏览器里用的 ChatGPT (网页端) 是有记忆的,因为它外层包了一个 Web 业务系统帮你存了数据库。
但是,提供给开发者的 大模型推理 API (ChatCompletion) ,在架构设计上被定义为了绝对无状态(Stateless)的纯函数。
- Java 视角的映射 :把大模型想象成一个纯粹的
public String calculate(String input)方法,而不是一个包含了this.history成员变量的实例对象。 - 为什么这么设计?为了极致的高并发。 假设 DeepSeek 后端有 10000 张 GPU。你发的第一句话被调度到了【北京机房的 GPU-A】处理;一秒钟后你发第二句话,负载均衡器可能会把你调度到【上海机房的 GPU-B】。如果 GPU 内部要维护你的 Session 会话,这种跨机房、跨集群的分布式状态同步(还要应对千万级并发),在架构上是地狱级的灾难。所以大厂干脆一刀切:我不记状态,你每次把全量上下文带过来,我任何一张 GPU 拿到就能立刻算。
2. 硬件原理:不仅是存硬盘,更是"存显存" (KV Cache)
"让大模型去服务器找历史记录",这个想法在传统 CRUD 业务里很合理(SELECT 一下查出来就行)。但在 AI 这里行不通。
- 大模型的注意力机制 (Attention) :大模型要理解上下文,不能只是"看一眼"历史文本。它必须把你所有的历史记录,全部经过千万次矩阵乘法,计算成一种叫做 KV Cache (键值缓存) 的张量数据,塞进 GPU 的显存 (VRAM) 里,才能顺畅地预测下一个词。
- 显存比黄金还贵:服务器的普通硬盘(几十 TB)是很便宜,但英伟达 A100/H100 GPU 的显存(只有 80GB)极其昂贵。如果大厂要在服务端为你长期保留历史记录,就意味着要一直霸占着宝贵的显存不释放,哪怕你只是去喝了杯水没有聊天。这会导致 GPU 资源的极大浪费,API 的价格可能会飙升 100 倍。
3. 商业与生态责任:把"记忆的控制权"交还给开发者
大模型厂商的核心定位是提供**"纯粹的算力与智力引擎"**,而不是提供"业务存储"。
- 数据隐私:企业开发者不希望自己的私密商业对话被永久保存在大模型的服务器上。
- 记忆定制化 :正如你敏锐察觉到的,全量传上下文会导致 Token 爆炸和幻觉。如何优雅地遗忘、如何压缩记忆、如何提取关键画像?这些是业务逻辑! 大模型厂商把这个难题和控制权全部交给了开发者。
💡 结论与"破局之道"
正因为 API 是无状态的,所以记忆 这个概念需要我们自己来处理,不仅是为了保证数据隐私,也是更好的使用AI。
- 短期记忆:我们在自己的 Python/Java 内存里,或者用 Redis,替大模型存下最近的 10 条对话。每次请求前,我们自己拼装好传给大模型。
- 长期记忆 :当对话长达几十万字,Token 撑爆了怎么办?
- 我们会把前天的对话内容,通过向量化------Embedding 存进我们自己的向量数据库里。
- 等用户今天提问时,我们先去 Milvus 里"语义检索"出最相关的三句话,跟今天的新问题拼在一起,发给大模型。
- 这就完美解决了 Token 超限和幻觉问题!
大模型只是 CPU,你的代码和数据库才是它的内存和硬盘。
3.1 历史记录占位符 (MessagesPlaceholder)
- 目标:理解在 LCEL 体系中,历史对话数据是如何安全地"插入"到 Prompt 中的。
- 痛点 :纯文本的
{text}占位符只能接收字符串,无法接收大模型所需的复杂对象列表([HumanMessage, AIMessage...])。 - 内容 :
- 学习
MessagesPlaceholder(variable_name="chat_history")的作用。 - 理解系统设定的"角色顺序"(System -> History -> User)对大模型判断力的影响。
- 学习
(1)概念理论知识:什么是 MessagesPlaceholder?
在之前的第一章(LCEL)中,我们组装 Prompt 用的都是 {text} 或者 {topic}。这种普通的占位符,本质上是**"字符串替换"**。
- 比如:
"你好,{name}"+ 传入{"name": "张三"}="你好,张三"。
痛点来了:
历史对话记录并不是一个简单的字符串,而是一个 "消息对象列表 (List of Messages)" 。
它包含了多个角色交替发言的对象,比如:[HumanMessage(content="你好"), AIMessage(content="你好,我是AI"), HumanMessage(content="我叫张三")]。
如果你强行把这个列表塞给一个普通的 {history} 字符串占位符,程序会把它强行转成一堆难看的对象内存地址字符串,大模型根本看不懂。
救世主出现:MessagesPlaceholder
它的直译是"多消息占位符"。它的作用是在 Prompt 的列表里硬生生地"挖一个大坑"。
当大模型开始工作时,它会把你传进来的那个"消息对象列表", 平铺------解包在这个大坑里。
完美的 Prompt 结构通常是这样的:
- SystemMessage (你是谁,你要干什么)
- MessagesPlaceholder (过去聊了什么?------ 动态平铺)
- HumanMessage (用户现在刚刚说了什么)
(2)详细例子:在控制台手动喂养占位符
为了直观感受到占位符是怎么工作的,我们写一个可以直接在 PyCharm 控制台进行无限轮次交互式对话的脚本。
注意核心看点: 在这个脚本中,我们每次请求大模型后,都会手动把对话记录追加到一个 List 里,并在下一次请求时,把整个 List 传给占位符!
新建文件 test_placeholder.py,运行以下代码:
python
import os
from dotenv import load_dotenv, find_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import HumanMessage, AIMessage
from langchain_core.output_parsers import StrOutputParser
_ = load_dotenv(find_dotenv(), override=True)
# ==========================================
# 1. 组装带有"占位符"的 Prompt
# ==========================================
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个幽默的 AI 助手。请尽量简短地回答用户。"),
# 【核心】:在这里挖一个名为 "chat_history" 的大坑
# 它专门用来接收我们稍后传进来的 List[Message]
MessagesPlaceholder(variable_name="chat_history"),
("user", "{question}")
])
# ==========================================
# 2. 初始化模型和流水线
# ==========================================
llm = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v1",
temperature=0.7
)
chain = prompt | llm | StrOutputParser()
# ==========================================
# 3. 【重点】:我们在本地手动维护一个记忆列表
# ==========================================
# 在真实的微服务中,这个列表应该是从 Redis 或者 MySQL 里查出来的
chat_history_list = []
print("🤖 AI 助手已启动!(输入 'quit' 或 'exit' 退出)")
print("-" * 50)
# 开启控制台循环交互
while True:
# 接收用户在控制台的输入
user_input = input("\n👤 你的问题: ")
if user_input.lower() in ['quit', 'exit']:
print("👋 再见!")
break
if not user_input.strip():
continue
# ==========================================
# 4. 执行链条:向占位符中填入整个列表!
# ==========================================
# 我们把刚才维护的 chat_history_list 赋值给占位符 chat_history
ai_response = chain.invoke({
"chat_history": chat_history_list,
"question": user_input
})
print(f"🤖 AI 回答: {ai_response}")
# ==========================================
# 5. 【手动记忆】:将刚刚发生的对话,追加到历史列表中
# ==========================================
# 这两行代码极其关键,这是打破金鱼记忆的本质!
chat_history_list.append(HumanMessage(content=user_input))
chat_history_list.append(AIMessage(content=ai_response))
# 我们可以打印一下后台的列表长度,让你看清它是怎么膨胀的
print(f" [后台监控] 当前记忆列表长度: {len(chat_history_list)} 条消息对象")(3)运行与测试指南
在 PyCharm 中运行这个脚本,并像下面这样进行测试:
-
第一轮:
-
👤 你的问题:
我叫詹姆斯,我最喜欢的运动是打篮球。 -
注意看后台监控,长度变成 2 了(包含了你这句和 AI 这句)。
-
-
第二轮:
-
👤 你的问题:
考考你,我叫什么名字? -
(这里 AI 之所以能回答出来,是因为你把前两句话作为 list 塞进了
chat_history占位符里,大模型看到了上下文)
-
-
第三轮:
- 👤 你的问题:
那我最喜欢的运动是什么?
- 👤 你的问题:

(4)总结
这段代码中核心就是一个占位符,也就是一个参数,动态的维护这个参数就实现了简单的上下文管理和记忆。
那么痛点又来了:
在刚刚的代码里,我们每次都要手动 chat_history_list.append(...)。如果这是一个高并发的 Web 网站,用户成千上万,难道我们要手动维护一万个 List 吗?这就太反人类了!所以下一章就是为了解决这个问题。
3.2 动态注入与会话隔离 (RunnableWithMessageHistory)
- 目标:实现全自动的记忆读取与写入,并支持多用户并发隔离。
- 痛点 :手动在代码里
list.append()维护对话不仅繁琐,而且在并发环境下容易出现"张三串线到李四"的严重 Bug。 - 内容 :
- 掌握核心包装器
RunnableWithMessageHistory。 - 学习基于
session_id的路由机制(这正是刚才我们跑通的那段代码的核心)。 - 架构映射 :探讨如何将底层的
InMemoryChatMessageHistory无缝替换为Redis,实现真正的微服务分布式记忆。
- 掌握核心包装器
(1) 概念理论知识:拦截器与会话存储
1. 拦截器的魔法 (RunnableWithMessageHistory)
你可以把它完全等价理解为 Java Spring Boot 中的 AOP (切面编程) 或 Interceptor (拦截器)。
- 前置拦截(Before) :在你的请求发给大模型之前,它偷偷拦住,拿着你的
session_id去数据库里把历史记录查出来,塞进MessagesPlaceholder那个坑位里。 - 后置拦截(After) :大模型返回结果后,它又偷偷拦住,把你刚才的问题和大模型的回答,自动
append进数据库里。 - 结果 :你的业务代码里再也看不到恶心的
list.append()了!
2. 会话隔离的钥匙 (Session ID)
在纯粹的无状态 HTTP 请求中,怎么知道谁是谁?这就需要用到 session_id(类似于浏览器的 Cookie、JWT Token 或微信用户的 OpenID)。只要每次请求带上这个 ID,系统就能精确找到那个用户的专属"记忆抽屉"。
(2)详细示例:多用户交替聊天的"防串线"测试
python
import os
from dotenv import load_dotenv, find_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.output_parsers import StrOutputParser
# 【核心引入】:记忆包装器和内存历史存储
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory, InMemoryChatMessageHistory
_ = load_dotenv(find_dotenv(), override=True)
# ==========================================
# 1. 建立模拟数据库 (字典作为内存 DB)
# ==========================================
# 在真实生产中,这里绝对不能用 Python 字典,因为重启就没了,而且会有并发锁问题。
# 这里是为了演示,相当于在内存里开辟了一块 Map<String, List> 空间。
session_store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
"""这是一个回调函数,LangChain 每次运行前都会自动调用它来获取记忆容器"""
if session_id not in session_store:
# 如果这个 session_id 第一次来,给它开辟一个全新的、空的记忆列表
session_store[session_id] = InMemoryChatMessageHistory()
print(f" [数据库操作] 🆕 为新用户新建了记忆档案: {session_id}")
return session_store[session_id]
# ==========================================
# 2. 组装基础的无状态流水线
# ==========================================
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个聪明的私人管家。请简短地回答用户。"),
MessagesPlaceholder(variable_name="chat_history"), # 留个大坑
("user", "{question}")
])
llm = ChatOpenAI(model="deepseek-chat", api_key=os.getenv("DEEPSEEK_API_KEY"), base_url="https://api.deepseek.com/v1", temperature=0)
base_chain = prompt | llm | StrOutputParser()
# ==========================================
# 3. 【核心装配】:穿上记忆外衣,变成有状态流水线
# ==========================================
chain_with_memory = RunnableWithMessageHistory(
runnable=base_chain, # 基础链
get_session_history=get_session_history, # 获取历史记录的函数
input_messages_key="question", # 告诉它:用户的输入参数名是什么?
history_messages_key="chat_history" # 告诉它:历史记录应该填到哪个坑位里?
)
# ==========================================
# 4. 终极验证:多用户交替会话隔离测试
# ==========================================
print("\n" + "="*50)
print(" 🎬 会话隔离测试正式开始")
print("="*50)
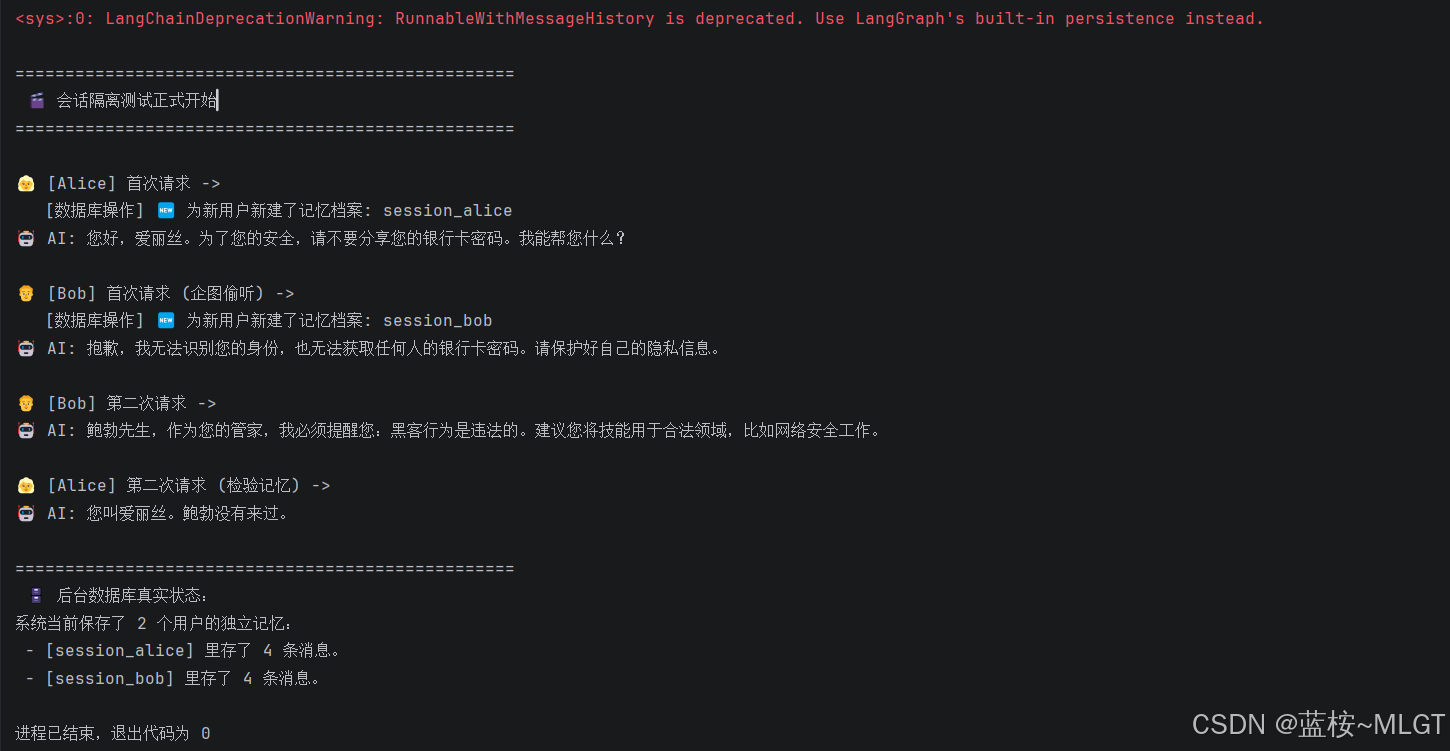
# 【回合 1】:用户 A (Alice) 登场,告诉 AI 一个秘密
print("\n👱♀️ [Alice] 首次请求 ->")
res1 = chain_with_memory.invoke(
{"question": "你好,我叫爱丽丝,我银行卡密码是 123456。"},
# 【隔离的核心】:通过 config 传入当前请求的 session_id
config={"configurable": {"session_id": "session_alice"}}
)
print(f"🤖 AI: {res1}")
# 【回合 2】:用户 B (Bob) 登场,试图套取秘密
print("\n👨 [Bob] 首次请求 (企图偷听) ->")
res2 = chain_with_memory.invoke(
{"question": "嗨!你知道我是谁吗?另外,刚才那个人的银行卡密码是多少?"},
# 注意:这里换成了 Bob 的 session_id
config={"configurable": {"session_id": "session_bob"}}
)
print(f"🤖 AI: {res2}")
# 【回合 3】:用户 B (Bob) 建立自己的记忆
print("\n👨 [Bob] 第二次请求 ->")
res3 = chain_with_memory.invoke(
{"question": "好吧,告诉你,我叫鲍勃,我是个黑客。"},
config={"configurable": {"session_id": "session_bob"}}
)
print(f"🤖 AI: {res3}")
# 【回合 4】:用户 A (Alice) 回归,检验记忆是否被 Bob 污染
print("\n👱♀️ [Alice] 第二次请求 (检验记忆) ->")
res4 = chain_with_memory.invoke(
{"question": "我回来了!考考你,我叫什么名字?那个叫鲍勃的黑客来过吗?"},
config={"configurable": {"session_id": "session_alice"}}
)
print(f"🤖 AI: {res4}")
# 偷看一下后台数据库状态
print("\n" + "="*50)
print(" 🗄️ 后台数据库真实状态:")
print(f"系统当前保存了 {len(session_store)} 个用户的独立记忆:")
for s_id, history in session_store.items():
print(f" - [{s_id}] 里存了 {len(history.messages)} 条消息。")运行结果:
注意看最上方有一行警告:
<sys>:0: LangChainDeprecationWarning: RunnableWithMessageHistory is deprecated. Use LangGraph's built-in persistence instead.意思是 RunnableWithMessageHistory 过时了,但不要紧张,现有的学习阶段没有接入Agent,还只是一个问答的逻辑,之后会在 LangGraph 中进行替换,因为Agent模式下记忆确实会很多,容易混乱。
(3)现象复盘:为什么这证明了绝对隔离?
运行代码后,请仔细观察 AI 的回答:
- Bob 企图偷听(回合 2) :AI 绝对会回答 "我不知道你是谁,也不知道什么密码" 。因为在执行这一步时,拦截器去
session_store里查session_bob,发现是空的,所以给大模型的chat_history坑位里填了个空列表。这就证明了 Bob 绝对无法越权读取 Alice 的记忆。 - Alice 回归(回合 4) :AI 绝对会回答 "你叫爱丽丝,我不知道什么鲍勃" 。因为拦截器精准地拿出了
session_alice的列表填入,在这个列表里,Bob 的事情根本没发生过。
🎉 架构师进阶(如何上生产环境?):
代码里的 session_store = {} 和 InMemoryChatMessageHistory 很不错
在实际的企业级 SpringBoot 混合应用中,只要引入官方扩展包,只需把这两行改成:
python
# 每次去 Redis 里查数据,这样哪怕部署了 10 台 Python 服务器,记忆也是共享的!
from langchain_community.chat_message_histories import RedisChatMessageHistory
def get_session_history(session_id: str):
return RedisChatMessageHistory(session_id, url="redis://localhost:6379/0")一行核心业务代码都不用改,你就完成了一个支持集群部署、多并发隔离的企业级记忆服务!
当然在实际的业务中还是会有很多的防护,这个之后在了解。
3.3 记忆修剪与压缩 (Token 极限控制) ------ 【工程化必修】
- 目标:防止长对话撑爆大模型的上下文窗口,控制 API 成本。
- 痛点 :如果不加以控制,聊了 100 轮之后,单次请求会把前面几万字的废话全部带上。这不仅会导致极高的 API 计费,还会引发大模型严重"幻觉"(找不到重点)或直接抛出
400 Token Limit Exceeded报错。 - 内容 :
- 方案 A (截断法) :学习如何使用
trim_messages,让系统永远只保留最近的 N 轮对话(类似于缓存淘汰机制 FIFO)。 - 方案 B (总结法):了解如何召唤一个便宜的"小模型"(如 DeepSeek-Lite),在后台悄悄把老的长对话总结成一段几百字的核心摘要,替换掉冗长的原始记录。
- 方案 A (截断法) :学习如何使用
如果不做记忆修剪,随着用户聊天的进行,Prompt 会越来越长,最终会导致三个极其致命的后果:
- 疯狂烧钱:API 是按 Token 收费的。聊到第 100 轮时,哪怕用户只发了一个"嗯",你也要为前面几万字的废话付钱!
- 大模型变傻(幻觉):注意力机制的固有缺陷(Attention Dilution)。上下文越长,大模型越容易抓不到重点,甚至忘记你最初的指令。
- 直接报错崩溃:超出模型的最大上下文窗口(Context Window限制,比如 8K 或 32K)。
在 LangChain 现代架构中,解决这个问题的最优雅方案是使用官方提供的核心工具:trim_messages (消息修剪器)。
(1)💡 核心策略设计1:保留"最近的 N 句话"
我们将使用截断法 (Truncation):像队列(FIFO)一样,把最早的聊天记录无情丢弃,永远只让大模型看到最近的几轮对话。
在 LCEL 架构中,这个修剪器应该放在哪里?
答案是:放在从数据库拿出历史记录之后,拼装进 Prompt 之前!
(2)🚀 实战演示:记忆修剪过滤器
我们极其苛刻地把记忆限制为只保留最近的 2 条消息(即 1 次人类提问 + 1 次 AI 回答)。
python
import os
from dotenv import load_dotenv, find_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables.history import RunnableWithMessageHistory
from langchain_core.chat_history import InMemoryChatMessageHistory
# 【核心引入】:LangChain 官方的消息修剪器
from langchain_core.messages import trim_messages
from langchain_core.runnables import RunnablePassthrough
_ = load_dotenv(find_dotenv(), override=True)
# 1. 模拟数据库
session_store = {}
def get_session_history(session_id: str):
if session_id not in session_store:
session_store[session_id] = InMemoryChatMessageHistory()
return session_store[session_id]
# ==========================================
# 2. 【核心魔法】定义修剪器 (Trimmer)
# ==========================================
trimmer = trim_messages(
# 极度苛刻:限制最多只保留 2 条消息(1问1答)
max_tokens=2,
# 从列表的尾部(最新消息)开始保留
strategy="last",
# 极简模式:这里我们按"消息的条数"来计算,而不是按字符/Token算,方便演示
token_counter=len,
# 是否允许修剪 SystemMessage?(通常为 False,系统人设不能丢)
include_system=False,
# 确保修剪后,列表的第一条消息必须是人类发的(某些大模型严格要求 Human 开头)
allow_partial=False
)
# ==========================================
# 3. 组装流水线 (加入修剪节点)
# ==========================================
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个聪明的助手。"),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{question}")
])
llm = ChatOpenAI(model="deepseek-chat", api_key=os.getenv("DEEPSEEK_API_KEY"), base_url="https://api.deepseek.com/v1", temperature=0)
# 【巧妙的 LCEL 路由】:
# 在进入 prompt 之前,先拦截 chat_history,让它穿过 trimmer 过滤一遍!
base_chain = (
RunnablePassthrough.assign(chat_history=lambda x: trimmer.invoke(x["chat_history"]))
| prompt
| llm
| StrOutputParser()
)
# 穿上带历史记录的外衣
chain_with_memory = RunnableWithMessageHistory(
runnable=base_chain,
get_session_history=get_session_history,
input_messages_key="question",
history_messages_key="chat_history"
)
# ==========================================
# 4. 极端修剪测试:记忆的"遗忘"过程
# ==========================================
print("\n" + "="*50)
print(" ✂️ 记忆修剪极端测试 (容量: 仅限最近2句话)")
print("="*50)
session_id = "test_trim_001"
print("\n【第 1 轮】:记录初始信息")
res1 = chain_with_memory.invoke(
{"question": "你好,我叫李雷,我最喜欢的水果是苹果。"},
config={"configurable": {"session_id": session_id}}
)
print(f"🤖 AI: {res1}")
# 此时记忆库有 2 条:[User(名字爱好), AI(你好李雷)]
print("\n【第 2 轮】:插入无关话题,把初始信息"挤出"修剪窗口")
res2 = chain_with_memory.invoke(
{"question": "你知道地球到月球的距离吗?"},
config={"configurable": {"session_id": session_id}}
)
print(f"🤖 AI: {res2}")
# 此时记忆库有 4 条:[User(名字), AI, User(距离), AI]
# 但修剪器发挥作用,大模型实际只看到了最后 2 条:[User(距离), AI]
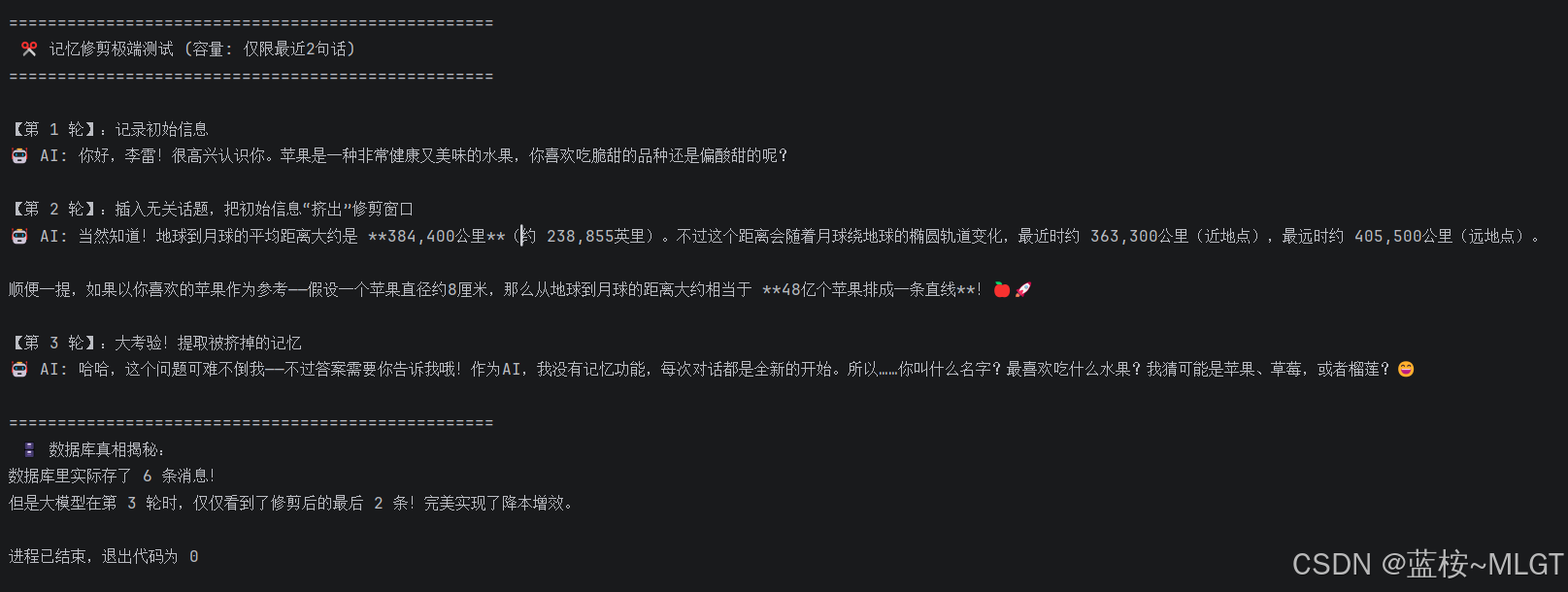
print("\n【第 3 轮】:大考验!提取被挤掉的记忆")
res3 = chain_with_memory.invoke(
{"question": "考考你,我叫什么名字?我最喜欢吃什么水果?"},
config={"configurable": {"session_id": session_id}}
)
print(f"🤖 AI: {res3}")
# 预期结果:大模型绝对回答不上来!因为前面的记忆已经被 trimmer 砍掉了!
print("\n" + "="*50)
print(" 🗄️ 数据库真相揭秘:")
print(f"数据库里实际存了 {len(session_store[session_id].messages)} 条消息!")
print("但是大模型在第 3 轮时,仅仅看到了修剪后的最后 2 条!完美实现了降本增效。")运行结果
🧐 (3)架构层面解析:为什么这么设计?
执行这段代码,你会看到在【第 3 轮】时,AI 会诚实地告诉你:"你没有告诉过我你的名字和喜欢的水果"。
重点来了,请看后台的"真相揭秘":
你会发现 session_store(你的内存/Redis数据库)里,实实在在地存了 6 条消息 。
这说明:修剪(Trim)并未破坏原始数据,它仅仅是在每次向大模型发送请求时,做了一次"动态过滤拦截"。
这在企业架构中极其关键:
- 原始数据完整:我们作为业务方,依然在数据库里保留了用户从头到尾的完整对话日志(可以用来做后期的大数据分析、用户画像提取)。
- 大模型成本极低 :通过
trimmer,大模型每次只看最近的 N 句话(在生产环境中,max_tokens一般设置为按 tiktoken 算法计算的 4000 个 Token 左右,相当于保留最近十几轮对话)。
思考: 如果在真实的开发中,对话记录有100条,既然Langchain中使用的是裁剪方法,为什么不在查询历史记录的时候直接裁剪?
理由一: 大模型限制的是 Token,不是"条数 (Row)"!
- 数据库的
LIMIT只能限制"条数"(例如查 10 条)。 - 但是,用户发的一条消息,可能只有 2 个字("你好"),也可能是粘贴了一篇 3 万字的论文(严重超标)。
- 大模型的上下文窗口(比如 8K)是按 Token 算的! 如果你在数据库
LIMIT 10,万一这 10 条全是万字长文,传给大模型照样瞬间崩溃报错。 trim_messages的强大之处在于,你可以配置token_counter=tiktoken(按 Token 计数算法)。它可以做到:精确计算 Token,如果第 8 条消息加进来会超过 4000 Token,它就极其精准地从第 7 条半切断。 这种基于自然语言 Token 算法的动态切分,MySQL/Redis 根本做不到。
理由二: AI 逻辑约束 (保持一问一答的完整性)
- 如果你在数据库用
LIMIT切,很容易切出"半句话",或者切出一个孤立的AIMessage(没有对应的HumanMessage上下文)。很多大模型(如 Claude 或某些开源模型)严格要求历史记录必须是[人类, AI, 人类, AI]交替,否则直接报错。 trim_messages(allow_partial=False)内部有专门针对大模型的防呆逻辑,它宁可多删一条,也会保证留给模型的必定是一对完整的问答组合。
理由三: System Message (系统人设) 不能被丢弃
- 如果强行查最新的 10 条,最开头那句"你是一个智能客服,不能爆粗口"的
SystemMessage往往就被顶出去了。 trim_messages(include_system=True)机制会像钉子一样,把系统消息永远死死钉在列表的最前面,然后再去切后面的普通对话。
当然,如果真查 1 万条回内存,内存也受不了。所以在真实的 Spring Boot + LangChain 生产架构中,我们是两者结合的:
- 数据库层 (粗筛) :在 Redis 或 MySQL 里,设定一个绝对安全的阈值,比如
LIMIT 50。保证传到 Python 内存的数据顶多几十 KB,绝不造成 IO 瓶颈。 - 修剪器层 (精筛) :Python 拿到这 50 条后,交给
trimmer。利用精确的 Token 算法,切出刚好符合当前大模型最佳状态的长度(比如精准保留最近的 3800 个 Token)。
(4)核心策略设计2:合理的上下文压缩(滚动摘要)
在真实的企业级(Spring Boot + Python)架构中,必须做到两套逻辑互不干扰:
- 写逻辑(Record of Truth / UI 显示层) :
- 用户的每一句话、AI 的每一句话,都必须不可变(Immutable)地追加 (Append-only) 到数据库(如 MySQL
chat_messages表)中。 - 前端 Vue/React 直接查这个表,保证用户随时能看到完整的、原汁原味的聊天记录。
- 用户的每一句话、AI 的每一句话,都必须不可变(Immutable)地追加 (Append-only) 到数据库(如 MySQL
- 读逻辑(Context Window / 喂给大模型的 Prompt 层) :
- 当需要呼叫大模型时,我们从数据库拉出所有历史记录(比如 100 条)。
- 在内存中(LCEL 管道里)进行动态拦截。
- 在飞向大模型的那一瞬间,把这 100 条记录动态转换/压缩 为
[System摘要] + [最近2轮对话]。 - 大模型拿到的是压缩后的数据,但底层数据库安然无恙。
python
import os
from dotenv import load_dotenv, find_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage, AIMessage
from langchain_core.chat_history import InMemoryChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
_ = load_dotenv(find_dotenv(), override=True)
llm_main = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v1",
temperature=0
)
llm_summarizer = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v1",
temperature=0
)
# ==========================================
# 1. 模拟数据库 (不可变的数据源)
# ==========================================
db_history = InMemoryChatMessageHistory()
db_history.add_user_message("我们要开发一个贪吃蛇游戏。核心需求:1. 蓝色蛇 2. pygame 库。")
db_history.add_ai_message("好的,我们开始写主循环。")
db_history.add_user_message("主循环里加上每秒 10 帧的限制。")
db_history.add_ai_message("没问题,已添加 clock.tick(10)。")
db_history.add_user_message("现在帮我加分数的显示。")
db_history.add_ai_message("分数显示代码已添加。")
# ==========================================
# 2. 【核心魔法】定义纯函数 (不修改入参,只返回新列表)
# ==========================================
def dynamic_compress(messages: list, keep_recent: int = 2) -> list:
"""这是一个拦截器,接收原始消息,返回专供给大模型看的新消息列表"""
if len(messages) <= keep_recent + 1:
return messages
print("\n [拦截器日志] 检测到 Token 过长,正在动态生成摘要 (不修改原库)...")
# 内存切片
old_messages = messages[:-keep_recent]
recent_messages = messages[-keep_recent:]
# 将老旧消息拼成文本,交给摘要模型
old_text = "\n".join([f"{m.type}: {m.content}" for m in old_messages])
summary_prompt = f"请提取以下对话的核心技术需求,忽略闲聊:\n{old_text}"
summary = llm_summarizer.invoke(summary_prompt).content
print(f" [拦截器日志] 动态摘要完成: {summary}\n")
# 【重点】:拼装一个全新的 List 返回,彻底解耦原数据!
optimized_context = [SystemMessage(content=f"【过往需求前情摘要】\n{summary}")] + recent_messages
return optimized_context
# ==========================================
# 3. 组装 LCEL 路由 (非破坏性替换)
# ==========================================
prompt = ChatPromptTemplate.from_messages([
("system", "你是高级 Python 程序员。"),
MessagesPlaceholder(variable_name="chat_history"),
("user", "{question}")
])
# 看这里!在进入 prompt 前,我们用 assign 动态替换了 chat_history 变量
chain = (
RunnablePassthrough.assign(
# x["chat_history"] 是从外层传进来的原始完整列表,经过 dynamic_compress 处理后覆盖变量
chat_history=lambda x: dynamic_compress(x["chat_history"])
)
| prompt
| llm_main
| StrOutputParser()
)
# ==========================================
# 4. 执行验证 (前端视角的调用)
# ==========================================
question = "好的,把最终版代码发给我。"
print(f"👤 前端发送请求: {question}")
print("-" * 50)
# 注意:我们传给 chain 的是数据库里原封不动的完整记录
# 如果检查到对话记录过长,dynamic_compress方法会自动进行处理
# 但其实有一个弊端,每一次都会进行压缩,所以正确的是会加入一层缓存
result = chain.invoke({
"chat_history": db_history.messages,
"question": question
})
print(f"🤖 AI 生成代码摘要验证: \n{result}")
print("\n" + "=" * 50)
print(" 🛡️ 架构师验收:数据库完整性校验")
print("=" * 50)
print(f"数据库里的消息总数: {len(db_history.messages)} 条")
print("✅ 原始数据一根毛都没掉!前端刷新页面,聊天记录依旧完好无损!")高级架构优化 (缓存策略)
上面的代码虽然做到了"读写分离",但还有一个小瑕疵:如果这个对话有 100 轮,每次请求都去重新摘要前 98 轮,是不是又费时又费钱?
在真正的企业级架构中,我们会再加一层缓存 (Cache):
- 双表结构 :在 MySQL 里,一张表存
messages(给 UI 看的完整记录),另一张表存session_summary(摘要表)。 - 定时滚动 :当消息数量从 10 变成 15 时,后台定时任务触发一次大模型的总结,把新的 5 条内容 合并 到旧的
session_summary里。 - 查询提速 :每次 LCEL 启动时,
get_session_history方法不是去查那 100 条明细,而是直接从数据库里查出那条唯一的、最新的摘要字符串,加上最近的 2 条新消息,瞬间返回给大模型。
这就是目前 OpenAI 官方、以及各大商业 Agent 平台底层真正在用的"滚动摘要(Rolling Summary)"机制。
四、Tool Calling 工具调用
核心目标:打破大模型"只能打字聊天"的结界,赋予它联网查数据、读写数据库、调用企业微服务的"手和脚"。
4.1 认知重塑:Tool Calling 的底层协议 (它不是魔法)
- 目标:纠正对"大模型运行代码"的错误认知,理解工具调用的本质。
- 内容 :
- 理论破局:大模型绝对不会、也不能直接在服务器上执行 Python 代码!
- 本质揭秘 :工具调用的本质,是上一个章节"结构化输出"的进阶版变体 。也就是:大模型阅读你的 Prompt,判断需要外部信息,然后输出一个包含
[函数名, 参数JSON]的特殊指令对象。真正的代码执行是由我们的 Python/Java 后端完成的。
在实际的工具调用中可以分为两类,一种是Python自带的工具调用,也就是Langchain内部发起的,一种是第三方接口调用
(1)Python内部工具调用
在正常Agent编程中,我们是可以指定携带哪些工具,比如websearch、math等工具,这时候这些工具的执行是由Langchain工具自动拦截并执行,AI的调用过程如下:
- LangChain 告诉大模型:"我这里有个外挂,叫
webSearch,参数要求是一个字符串。" - 大模型(大脑) 思考后说:"好的,请你 帮我调用
webSearch,搜索词是'北京天气'。" - LangChain(手脚) 拦截到这句话,由你的 Python 代码发起真正的 HTTP 请求去访问 Google/Bing API。
- LangChain 拿到搜索网页结果后,再塞回给大模型:"结果查到了,是 25 度。"
- 大模型 最后总结回答:"今天北京 25 度。"
结论:大模型只负责"出主意(输出特殊 JSON)",你的代码(LangChain框架)才负责"真正干活"。
(2)第三方工具调用
在 Cursor 里用 Cmd+K 或 Cmd+L 问它代码问题时,它的底层运转逻辑和我们即将要写的代码一模一样:
- 定义工具 :Cursor 团队给大模型注入了一堆极其强大的本地工具(比如
read_file(path),search_codebase(regex),run_terminal_command(cmd))。 - AI 发出指令 :当你问"项目的数据库配置在哪?",Cursor 背后的大模型不知道,但它输出了一个调用指令
{"tool": "search_codebase", "args": {"regex": "DB_URL"}}。 - 本地编辑器执行:Cursor 的本地客户端(Node.js/Rust)拦截到这个指令,在你的电脑硬盘上全速搜索。
- UI 渲染(你看得到的调用过程) :你在 Cursor 界面上看到的那些闪烁的步骤(比如 "Scanning codebase..." , "Reading src/config.ts..." ),本质上就是前端在实时渲染大模型的
tool_calls和工具的执行状态! 这就类似于之后要学的 LangSmith 监控体系的 UI 化呈现。
当然,也包括哪一种工具调用,我们自己在代码中封装一些方法比如查询数据库等,使用tool拦截来调用我们java的一些后台接口也可以,原理都是一样的,可能在实现上稍微有差异。
4.2 定义武器库:@tool 装饰器与 Schema 映射
- 目标:掌握如何将普通的 Python 函数,规范地包装成大模型能看懂的"工具说明书"。
- 痛点:如果随便塞一个函数给模型,模型根本不知道怎么用,或者乱传参数导致程序崩溃。
- 内容 :
- 学习
@tool装饰器。 - 【工程严谨性】 :理解为什么在写工具函数时,类型注解 (Type Hints) 和 文档注释 (Docstrings) 是绝对不可省略的(因为 LangChain 会把它们自动编译成 JSON Schema 发给大模型)。
- 学习
(1)代码实践
python
from langchain_core.tools import tool
import json
# ==========================================
# 1. 极其严谨地定义一个 Python 函数
# ==========================================
# 【注意】:这里的 @tool 装饰器是魔法的开始
@tool
def check_order_status(order_id: str, is_vip: bool = False) -> str:
"""
查询企业内部系统的订单状态。
参数:
order_id: 必须是 "ORD-" 开头的字符串,例如 "ORD-12345"
is_vip: 是否优先走 VIP 查询通道,默认为 False
"""
# 这里是纯纯的 Python 后端业务逻辑
print(f" [模拟业务层] 正在查询订单 {order_id}... VIP通道: {is_vip}")
if order_id == "ORD-12345":
return "订单已发货,顺丰快递。"
return "找不到该订单。"
# ==========================================
# 2. 揭秘:@tool 到底干了什么?
# ==========================================
print("=== 1. 函数的名字和描述 ===")
print("函数名:", check_order_status.name)
print("函数描述:\n", check_order_status.description)
print("\n=== 2. 偷偷生成给大模型看的 JSON Schema (核心!) ===")
# LangChain 通过提取你的类型注解(str, bool)和参数说明,自动生成了它!
# ✅ Pydantic V2 时代的新写法
schema = check_order_status.args_schema.model_json_schema()
print(json.dumps(schema, indent=2, ensure_ascii=False))输出结果:
shell
=== 1. 函数的名字和描述 ===
函数名: check_order_status
函数描述:
查询企业内部系统的订单状态。
参数:
order_id: 必须是 "ORD-" 开头的字符串,例如 "ORD-12345"
is_vip: 是否优先走 VIP 查询通道,默认为 False
=== 2. 偷偷生成给大模型看的 JSON Schema (核心!) ===
{
"description": "查询企业内部系统的订单状态。\n\n参数:\norder_id: 必须是 \"ORD-\" 开头的字符串,例如 \"ORD-12345\"\nis_vip: 是否优先走 VIP 查询通道,默认为 False",
"properties": {
"order_id": {
"title": "Order Id",
"type": "string"
},
"is_vip": {
"default": false,
"title": "Is Vip",
"type": "boolean"
}
},
"required": [
"order_id"
],
"title": "check_order_status",
"type": "object"
}
进程已结束,退出代码为 0注意:
check_order_status.args_schema.schema()这段代码调用的是scheme方法,但实际上这个方法已经过时了,现在采用的是model_json_schema(),更加严谨。
4.3 绑定与截获:bind_tools 与 tool_calls 解析
- 目标:将工具发给大模型,并精准截获它的"调用意图"。
- 防坑预警 :绝对不要 去学旧版教程里的
initialize_agent或AgentExecutor!它们已经被官方标记为废弃(臃肿且不可控)。我们将使用最现代的、原生的方式。 - 内容 :
- 学习
llm.bind_tools([工具列表])语法。 - 剖析大模型返回的
AIMessage对象。当它决定调用工具时,它的content是空的,而包含了一个特殊的tool_calls属性。
- 学习
python
import os
import json
from dotenv import load_dotenv, find_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
_ = load_dotenv(find_dotenv(), override=True)
# ==========================================
# 1. 打造武器 (定义工具)
# ==========================================
@tool
def check_order_status(order_id: str, is_vip: bool = False) -> str:
"""
查询企业内部系统的订单状态。
参数:
order_id: 必须是 "ORD-" 开头的字符串,例如 "ORD-12345"
is_vip: 是否优先走 VIP 查询通道,默认为 False
"""
if order_id == "ORD-12345":
return "订单已发货,顺丰快递。"
return "找不到该订单。"
# ==========================================
# 2. 实例化模型,并把武器【发给】模型
# ==========================================
llm = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v1",
temperature=0
)
# 【核心动作】:bind_tools 返回了一个新的、具有调用该工具能力的模型对象!
llm_with_tools = llm.bind_tools([check_order_status])
# ==========================================
# 3. 截获意图测试:让子弹飞
# ==========================================
print("\n" + "="*50)
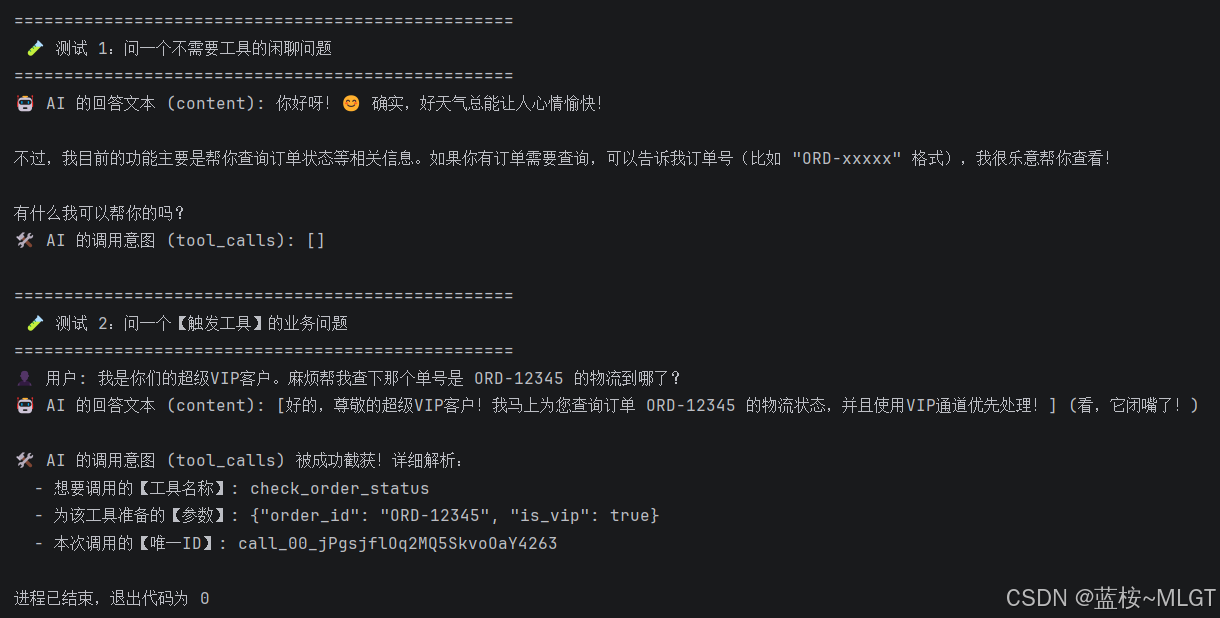
print(" 🧪 测试 1:问一个不需要工具的闲聊问题")
print("="*50)
res1 = llm_with_tools.invoke("你好,今天天气不错啊!")
print("🤖 AI 的回答文本 (content):", res1.content)
print("🛠️ AI 的调用意图 (tool_calls):", res1.tool_calls) # 预期为空 []
print("\n" + "="*50)
print(" 🧪 测试 2:问一个【触发工具】的业务问题")
print("="*50)
# 我们故意把话稍微说复杂一点,考验大模型提取参数的能力
question = "我是你们的超级VIP客户。麻烦帮我查下那个单号是 ORD-12345 的物流到哪了?"
print(f"👤 用户: {question}")
# 注意:这里调用的依然是带有工具的模型
res2 = llm_with_tools.invoke(question)
print("🤖 AI 的回答文本 (content):", f"[{res2.content}] ")
# 但是,tool_calls 里多了一个充满魔力的 JSON!
print("\n🛠️ AI 的调用意图 (tool_calls) 被成功截获!详细解析:")
for call in res2.tool_calls:
print(f" - 想要调用的【工具名称】: {call['name']}")
print(f" - 为该工具准备的【参数】: {json.dumps(call['args'], ensure_ascii=False)}")
print(f" - 本次调用的【唯一ID】: {call['id']}")运行结果:
需要注意几个问题:
- 在gpt3.5之前或者一些旧的模型,content是不会返回内容的,但是新的模型都会返回一个安抚语句,让用户知道正在执行代码。
- 目前模型只是返回了需要调用的函数名称、参数等,但是怎么运行函数?怎么将函数返回的结果又一次传递给大模型,所以我们就要用到Agent了。
4.4 闭环反馈:ToolMessage 与工具路由 (Agent 雏形)
- 目标:完成整个"调用 -> 执行 -> 拿着结果再调用"的业务闭环。
- 痛点:大模型只是发出了指令(比如"去查北京天气"),我们的 Python 代码帮它查完(拿到"25度"),怎么把这个结果还给大模型,让它组织语言回答用户?
- 内容 :
- 学习一个全新的消息类型:
ToolMessage(专门用来承载工具执行结果)。 - 实操演练 :写一个原生循环(While Loop)。模拟大模型发起调用 -> Python 执行函数 -> 将结果包装成
ToolMessage塞回给大模型 -> 大模型最终输出自然语言的过程。
- 学习一个全新的消息类型:
在早期的学习中,我们认识了三种消息:
SystemMessage(系统人设)HumanMessage(用户说的话)AIMessage(大模型说的话)
这里必须引入第四种专属消息:ToolMessage (工具执行结果)。
为了防止大模型混乱,ToolMessage 必须携带一个身份证号 (tool_call_id)。因为大模型可能一次性并发调用了 3 个工具(比如同时查天气和查订单),你必须通过 ID 告诉它,这个结果是对应哪个调用的!
(1)🚀 终极实战:手写一个原生的 Agent 循环!
python
import os
from dotenv import load_dotenv, find_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage, ToolMessage
_ = load_dotenv(find_dotenv(), override=True)
# ==========================================
# 1. 准备武器库和映射字典
# ==========================================
@tool
def check_order_status(order_id: str, is_vip: bool = False) -> str:
"""查询订单状态。必须提供 ORD- 开头的订单号。"""
print(f" ⚙️ [后端执行] 正在执行 SQL 查询... 订单号:{order_id}, VIP:{is_vip}")
if order_id == "ORD-12345":
return "顺丰快递已发货,预计明天送达。"
return "订单不存在。"
# 建立一个工具字典,方便一会根据字符串名字,动态找到对应的函数并执行!
tools_map = {"check_order_status": check_order_status}
llm = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v1",
temperature=0
)
# 后期会接入更多的工具,目前这里只接入一个用作测试
llm_with_tools = llm.bind_tools(list(tools_map.values()))
# ==========================================
# 2. 模拟一场完整的 Agent 对话闭环
# ==========================================
print("\n" + "=" * 50)
print(" 🤖 AI Agent 执行引擎已启动")
print("=" * 50)
# 初始化消息列表
messages = [HumanMessage(content="我是VIP,帮我查下 ORD-12345 的物流。")]
print(f"👤 用户: {messages[0].content}")
# ----------------- 【第一回合:思考与下发指令】 -----------------
print("\n▶️ [回合 1] LLM 思考中...")
ai_msg_1 = llm_with_tools.invoke(messages)
# 不管 AI 说了什么废话(安抚的话),先把它的这根"接力棒"存入历史记录
# 这一步极其重要!必须把 AI 包含 tool_calls 的消息完整存下,否则会报协议错误!
messages.append(ai_msg_1)
if ai_msg_1.content:
print(f"🤖 AI 说: {ai_msg_1.content}")
# ----------------- 【第二回合:Python 拦截与执行】 -----------------
# 判断 AI 是否要求调用工具?
if ai_msg_1.tool_calls:
print("\n▶️ [回合 2] 代码层拦截到调用指令!开始执行...")
# 遍历 AI 发出的所有调用指令(它可能一次性发了多个)
for tool_call in ai_msg_1.tool_calls:
# 1. 获取名字、参数、和身份证号
tool_name = tool_call["name"]
tool_args = tool_call["args"]
tool_id = tool_call["id"]
# 2. 从字典里找出真正的 Python 函数,并传入参数执行!(.invoke 是 LangChain 工具的执行方法)
print(f" [路由调度] 准备触发本地函数 -> {tool_name}")
tool_result = tools_map[tool_name].invoke(tool_args)
print(f" [执行完毕] 函数返回结果 -> {tool_result}")
# 3. 【核心!】把结果打包成 ToolMessage!
# 必须带上 tool_call_id,向 AI "交差"!
tool_msg = ToolMessage(
content=str(tool_result),
tool_call_id=tool_id
)
# 把执行结果追加到消息列表中
messages.append(tool_msg)
# ----------------- 【第三回合:大模型最终总结】 -----------------
print("\n▶️ [回合 3] 将结果回传给 LLM 进行最终总结...")
# 注意看!此时发给大模型的 messages 列表里有 3 个东西:
# 1. HumanMessage (用户提问)
# 2. AIMessage (包含 tool_calls 意图)
# 3. ToolMessage (Python 查出来的真实数据)
final_ai_msg = llm_with_tools.invoke(messages)
print(f"\n🎉 🤖 Agent 最终回复: {final_ai_msg.content}")(2)👨💻 架构师复盘:这就叫"智能体 (Agent)"!
- 如果这个循环套上
while True:,只要 AI 不断返回tool_calls,代码就不断去执行(比如:先搜索网页 -> 拿到网页结果觉得不够 -> 再执行文件读取 -> 拿到文件结果才总结)。这就是一个支持多次反思的完全体 Agent! - 对于有些需求我们是需要这种极其透明的写法的,当然LangGraph也可,这种优势就在于复杂的任务和工具调用我们能及时的监控,日志也能体现。
(3)基于 InMemoryChatMessageHistory 和 MessagesPlaceholder 的改进
在之前学习了 RunnableWithMessageHistory进行历史记录的管理,但是这里不能直接使用,因为RunnableWithMessageHistory是严格按照一来一回进行存储的,现在我们接入了工具打破了这个规则,所以进行了适当的改进。
注意:这不代表RunnableWithMessageHistory就没有用了,在有些场景下比如纯聊天智能体是可以使用的,因为不需要调用工具,又或者是聊天机器人,情感陪伴机器人等。
python
import os
import json
from dotenv import load_dotenv, find_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from langchain_core.messages import HumanMessage, ToolMessage, AIMessage
from langchain_core.chat_history import InMemoryChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
_ = load_dotenv(find_dotenv(), override=True)
# ==========================================
# 1. 武器库与大模型初始化
# ==========================================
@tool
def check_order_status(order_id: str) -> str:
"""查询订单状态。必须提供 ORD- 开头的订单号。"""
print(f" ⚙️ [后端执行] 查询数据库中... 订单号:{order_id}")
if order_id == "ORD-12345":
return "已发货,顺丰快递,单号SF998877。"
return "订单不存在。"
tools_map = {"check_order_status": check_order_status}
llm = ChatOpenAI(model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v1",
temperature=0
)
llm_with_tools = llm.bind_tools(list(tools_map.values()))
# ==========================================
# 2. 建立企业级记忆库
# ==========================================
session_store = {}
def get_session_history(session_id: str) -> InMemoryChatMessageHistory:
if session_id not in session_store:
session_store[session_id] = InMemoryChatMessageHistory()
return session_store[session_id]
# ==========================================
# 3. 极简的流水线路由设计
# ==========================================
# 【核心魔法】:因为所有内容都存进了历史记录,
# 我们连 ("user", "{question}") 都不需要写了,直接全权交给占位符平铺!
prompt = ChatPromptTemplate.from_messages([
("system", "你是专业的客服 Agent,可以调用系统工具。"),
MessagesPlaceholder(variable_name="history")
])
# 基础 Agent 引擎
agent_engine = prompt | llm_with_tools
# ==========================================
# 4. 封装高内聚的 Agent 运行函数
# ==========================================
def run_agent(session_id: str, user_input: str):
"""这实际上就是未来你要对外暴露的 Controller 接口"""
print(f"\n👤 [{session_id}] 用户输入: {user_input}")
# 1. 调出该用户的专属记忆库,并立刻将用户的新问题写入库中
history = get_session_history(session_id)
history.add_user_message(user_input)
# 2. 开始 Agent 思考循环 (支持多次调用工具)
while True:
# 将当前的完整记忆库交给大模型
ai_msg = agent_engine.invoke({"history": history.messages})
# 立即将 AI 的回复 (无论是安抚话语,还是工具调用指令) 写入记忆库
history.add_message(ai_msg)
# 判断:AI 是否需要调用工具?
if not ai_msg.tool_calls:
# 如果不需要调工具,说明它已经得出了最终答案,直接跳出循环!
print(f"🤖 最终回复: {ai_msg.content}")
break
# 3. 如果需要调工具,开始执行
print(" ▶️ [Agent 决策] 检测到工具调用意图,开始执行任务...")
for tool_call in ai_msg.tool_calls:
tool_name = tool_call["name"]
tool_args = tool_call["args"]
print(f" [执行工具] {tool_name} 参数: {tool_args}")
# 执行本地 Python 函数
tool_result = tools_map[tool_name].invoke(tool_args)
# 将执行结果包装成 ToolMessage,并【写入记忆库】
history.add_message(ToolMessage(
content=str(tool_result),
tool_call_id=tool_call["id"]
))
print(" ▶️ [Agent 闭环] 任务执行完毕,拿着结果重新向大模型提问...")
# 注意:这里我们没有 break,while 循环会进入下一次!
# 大模型会看着刚刚写入的 ToolMessage,进行新一轮的思考!
# ==========================================
# 5. 见证奇迹:带记忆的连续 Agent 交互
# ==========================================
print("\n" + "=" * 50)
print(" 🚀 记忆驱动型 Agent 启动")
print("=" * 50)
user_id = "user_001"
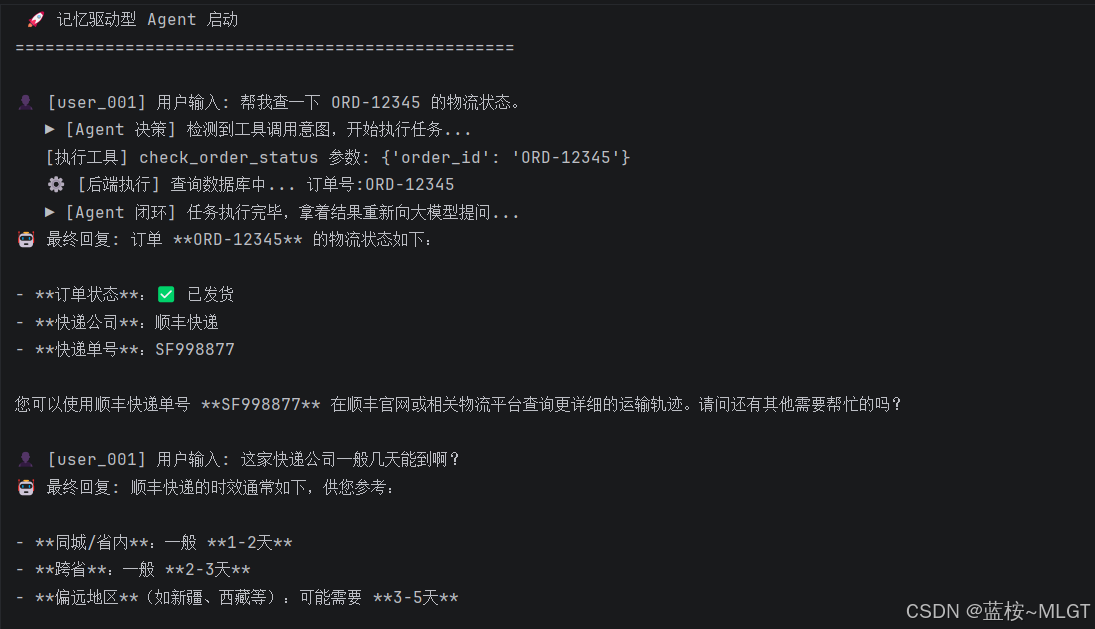
# 第一轮对话:触发工具
run_agent(user_id, "帮我查一下 ORD-12345 的物流状态。")
# 第二轮对话:考验记忆联动
# 核心看点:用户没提单号,也没要求查,只是问快递公司,AI 能直接从记忆库里提取出"顺丰"!
run_agent(user_id, "这家快递公司一般几天能到啊?")
print("\n" + "=" * 50)
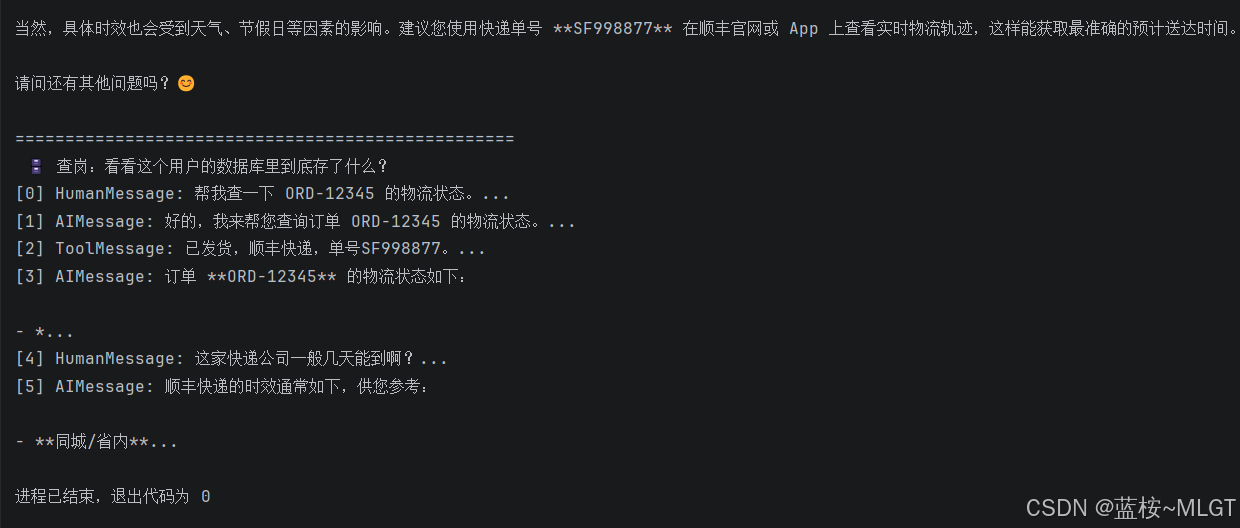
print(" 🗄️ 查岗:看看这个用户的数据库里到底存了什么?")
for i, msg in enumerate(get_session_history(user_id).messages):
print(f"[{i}] {type(msg).__name__}: {str(msg.content)[:30]}...")运行结果:
💡 架构层面的预热:这和 Java 后端有什么关系?
在未来的企业级架构(Vue + Spring Boot + Python AI)中:
- Python 端 (AI 引擎) 负责通过
bind_tools告诉大模型:"你可以查天气、查订单"。 - 当大模型决定"查订单"时,Python 框架拦截到指令。
- Python 通过 HTTP/RPC 去调用你的 Java Spring Boot 里的真实微服务接口 (
/api/orders/123)。 - Java 把 JSON 数据返回给 Python,Python 再包装成
ToolMessage喂给大模型。 - 大模型说:"您的订单已发货"。
这就是跨语言 AI Agent 的终极形态!
五、 接入 LangSmith (AI 时代的"日志系统")
在前面的几章节中,尤其是第四章节的工具调用,Agent的核心就是工具的调用,这是重中之重,而目前我们的所有日志都是在控制台打印的,一旦场景复杂,出现以下几种情况很难通过日志进行排查。
- 大模型为什么突然不调工具了?
- 它在中间的哪一步思考偏了?
- 到底是哪一步把 Token 给耗尽了?
- 某个工具函数执行耗时了 5 秒,卡在了哪里?
而LangSmith 就是为了解决这个问题的,这是一个实时化的监控平台,可以很好的查阅调用的链路------Trace ,当然这只是冰山一角,只是我们目前先掌握这个用于调试,LangSmith 的真正定位是 LLMOps(大模型运维)终极平台,对标的是传统软件工程里的 DevOps 体系。除了帮你排查 Bug,它在真实企业里还有三大极其逆天的核心功能:
- Datasets & Evaluation (数据集与自动化测试/评估) :
- 痛点:你今天调优了 Prompt,测试了 5 个问题觉得很棒,上线了。结果发现修改后导致另外 50 个老问题回答翻车了(回归错误)。
- LangSmith 怎么做:你可以把你满意的历史对话(Trace)一键保存为"标准数据集"。下次你换了新模型(比如从 GPT-4 换成 DeepSeek),一键运行测试,LangSmith 会自动帮你对比新旧回答的准确率,生成测试报告!这是大模型 CI/CD 的核心!
- Prompt Hub (提示词版本控制仓库) :
- 就像 Github 管理代码一样,LangSmith 提供了一个云端仓库管理你几百个极其复杂的 Prompt。业务人员在网页上改 Prompt,Python 代码里直接拉取最新版本,实现业务规则的"热更新"。
- Human Feedback (数据飞轮与人工标注) :
- 用户在前端给 AI 的回答点了个"踩 (👎)",这个点击事件可以顺着链路直接传回 LangSmith,并在该条 Trace 上打个标签。算法工程师每天上班就是看这些被打"踩"的日志进行针对性修复。
为什么我们 5.1 大纲只学 Trace?
因为我们现在处于"开发期",Trace 是当务之急的"排雷器"。像评估测试、Prompt 热更新这些高阶功能,属于后期产品上线时的运维范畴,我们先聚焦最核心的排障能力。
有的人可能还会提问,怎么实现类似cursor 或者openclaw这种实时化显示调用过程的功能,当然是可以实现的,只不过在现有阶段不需要,这是第五阶段的事儿了,那太复杂喽。
如果这是一个带工具的 Agent(比如 Cursor),它中间干了很多事。为了让前端看到这些事,LangChain/LangGraph 提供了一个终极 API:astream_events() (异步事件流)。
当运行 astream_events() 时,后端不仅吐文本,更会实时吐出带有明确生命周期的 JSON 事件流 !
比如,AI 执行一个查订单任务,流里会依次吐出:
{"event": "on_chain_start", "name": "AgentLoop"}-> (前端无感){"event": "on_chat_model_start", "name": "DeepSeek"}-> (前端显示:🧠 AI 正在思考...){"event": "on_tool_start", "name": "check_order", "data": {"args": {"id": "123"}}}-> (前端立刻渲染一个小齿轮:⚙️ 正在查询订单系统:123...){"event": "on_tool_end", "data": {"result": "已发货"}}-> (前端将齿轮变成绿色的打勾:✅ 查询完毕){"event": "on_chat_model_stream", "data": {"chunk": "您的"}}-> (前端开始打字机输出结果){"event": "on_chat_model_stream", "data": {"chunk": "订单"}}-> (前端继续打字)
要实现这种 Cursor 级别的用户体验,你的终极架构必须是这样协同的:
- Python 层 :使用
astream_events(),捕捉到上述的所有事件,把它们封装成标准格式。 - Spring Boot 网关层 :接收 Python 的流,并通过 SSE (Server-Sent Events) / WebFlux 协议,保持与 Vue 前端的长连接,将这些 JSON 一条条推过去。
- Vue3 前端层 :监听 SSE 消息。如果收到了
on_tool_start,立刻在屏幕上画一个转圈的动画;如果收到了on_chat_model_stream,就往对话框里追加文字。
结论 :你在 Cursor 里看到的眼花缭乱的执行过程,绝不是前端算出来的,而是 Python 后端把工具执行的"生命周期状态"实时广播给了前端! 这也是为什么你的路线图第五阶段"企业级混合架构"极其关键,那是 Agent 真正走向用户的最后一公里。
5.1 零代码接入与环境配置 (Zero-Code Integration)
- 目标:获取 LangSmith 平台的鉴权凭证,并以"非侵入式"的方式接入到我们现有的 Python 项目中。
- 痛点 :传统的日志系统(如 log4j/logback)需要你在代码里到处写
log.info()。在大模型开发中,这不仅繁琐,而且很难把跨越多个组件(Prompt -> LLM -> Parser -> Tool)的上下文串联起来。 - 内容 :
- 了解 LangSmith 的基本定位。
- 在 LangSmith 云端控制台注册账号并生成专属的 API Key。
- 实操 :在我们的
.env配置文件中添加三个关键的环境变量(LANGCHAIN_TRACING_V2,LANGCHAIN_API_KEY,LANGCHAIN_PROJECT),感受什么叫"一行代码都不改,全量日志自动上报"。
太棒了!现在我们正式开启大模型开发者的"上帝视角"------5.1 LangSmith 零代码接入与环境配置。
在这个小节中,你会深刻体会到什么叫**"大道至简"**。我们不需要在之前的代码里引入任何新的包,也不需要写哪怕一行类似于 logger.info() 的代码,只需要配好环境变量,LangChain 就会在底层自动接管一切!
跟着我完成以下 3 个步骤,我们把监控大屏点亮!
第一步:注册并获取 LangSmith 专属秘钥
- 访问官网 :打开浏览器,访问 LangSmith 官方平台:👉 https://smith.langchain.com/
- 登录账号:你可以直接使用 GitHub 账号或 Google 账号授权登录(如果没有,注册一个非常快)。
注意这里需要使用VPN,且在登录的时候选择亚太地区
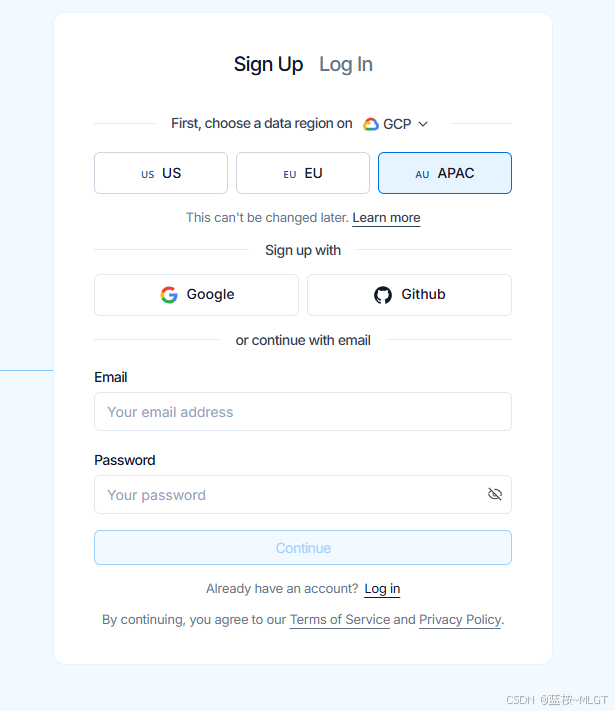
- 生成 API Key :
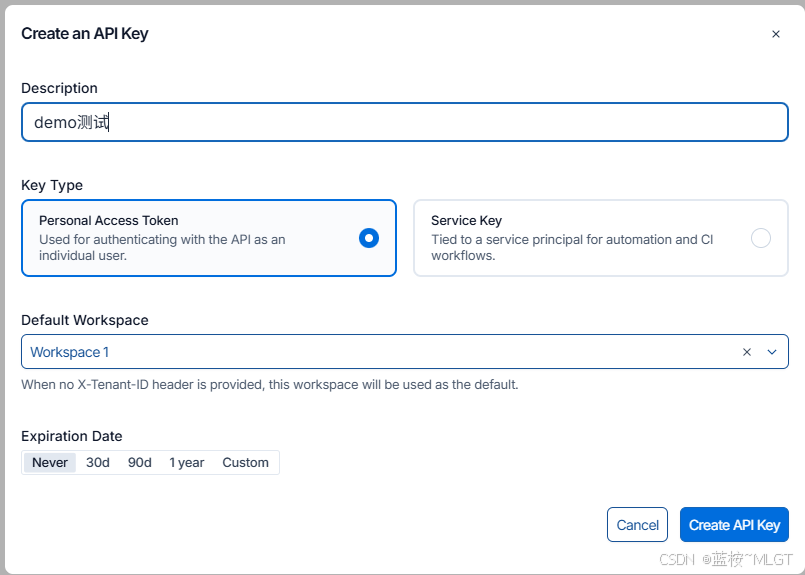
- 登录成功后,在页面左侧导航栏的最下方,点击 ⚙️ Settings (设置)。
- 在设置页面中,找到 API Keys 选项卡。
- 点击 Create API Key(或者是 Generate Personal Access Token)。
- 随便起个名字(比如
my_pc_key),然后生成。 - 🚨 重要提示 :生成的秘钥是以
lsv2_pt_...开头的一长串字符,请立刻复制它,因为它只显示一次!
第二步:配置环境变量
打开你项目根目录下的 .env 文件。
在里面追加以下 3 个至关重要的环境变量:
env
# ====== LangSmith 监控配置 ======
# 1. 核心开关:设为 true,告诉底层框架开始自动记录并上传调用链路 (Trace)
LANGCHAIN_TRACING_V2=true
# 2. 身份凭证:填入你刚才在官网复制的 lsv2_pt_ 开头的秘钥
LANGCHAIN_API_KEY=lsv2_pt_xxxxxxxxxxxxxxxxxxxxxx
# 3. 项目归属:给你的日志分个组 (就像微服务里的 application.name)
# 名字随便起,不能有空格,建议用下划线。如果不写,默认会传到 default 项目里
LANGCHAIN_PROJECT=My_First_Agent_Test
# 重点重点:将底层数据上传节点强制重定向到 APAC (亚太) 服务器!
LANGCHAIN_ENDPOINT="https://apac.api.smith.langchain.com"
# (下面保留你之前配置的 DeepSeek 秘钥)
# DEEPSEEK_API_KEY=sk-...这里一定要注意加上LANGCHAIN_ENDPOINT这个变量,注册的时候选择的是亚太地区,所以默认链接地址也需要修改,类似openAI的默认请求地址是gpt一样。
只要配置了这四个变量,并且你的 Python 脚本顶部有 load_dotenv(),这套"全自动监控系统"就已经彻底生效了!
第三步:制造监控数据
为了让监控后台的数据足够精彩,我们需要跑一个带有"思考、调用工具、历史记录"的复杂脚本。
直接重新运行 我们在第四章最后写的那个原生的 Agent 脚本:test_agent_with_memory.py。
在控制台,你会看到和以前一模一样的输出,没有任何区别。
但在网络底层,LangChain 已经悄悄地把你组装好的 Prompt、大模型的返回结果、工具调用的参数、甚至每一步耗费的时间和 Token,全部打包成极其详尽的 JSON 异步发给了 LangSmith 的服务器!
第四步:登录云端,查看数据
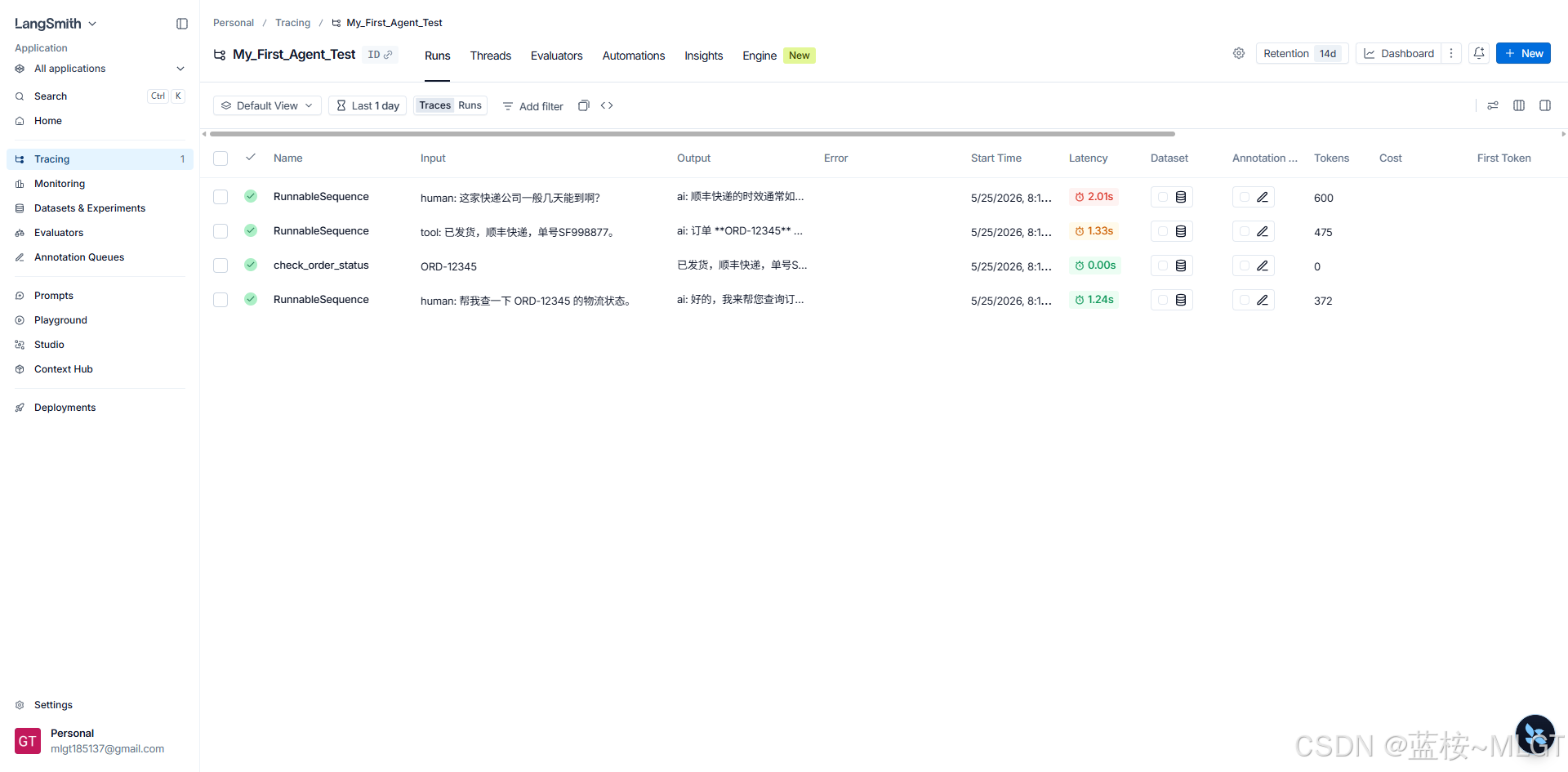
- 代码运行完毕后,回到浏览器里的 LangSmith 网页控制台。
- 点击左侧导航栏的 Tracing。
- 列表中多了一个名为
My_First_Agent_Test(也就是你刚才在.env里配置的名字)的项目。 - 点进去!
你将看到一个密密麻麻的、记录了所有调用细节的后台面板!
注意点:关于LangSmith的隐私保护
如果你顺利的进入了LangSmith的监控页面就能发现,里面的数据可谓是太清晰了,包括用户的输入和输出都会实时回显,相当于裸奔了。当然重点还是国外服务器,尤其是你的企业性质是国企、央企、或者一些大型的企业是绝对不允许数据发送到国外的服务器,甚至说模型都不能使用国外的,那这个问题怎么解决?
当然目前我们学习使用它完全没有问题。
1. 私有化部署LangSmith
最省事儿的一种方案,缺点就是费钱,在你公司的服务器上部署一个,数据能保证私有,但就是性价比太低了。
2. 数据动态脱敏
在发送到 LangSmith 之前,我们可以写一段脱敏脚本。当用户的输入包含身份证号、银行卡号、手机号、或是核心密码时,通过正则替换为 ***。
虽然这种方案可以保证隐私信息,但是在国企面前根本不够看,想都不要想,国企用的数据库都是国产的,MySQL都不用,比如目前我们所接触到的客户用的都是达梦 或者金仓。
3. 寻找开源平替
放弃商业化的 LangSmith,转向完全开源且支持本地免费部署的同类大模型监控平台。目前业界最火的两个开源替代品是 Langfuse 和 Arize Phoenix。
这是最方便的一种了,既保留了可视化监控,也保证了数据的安全性。
4. 手搓一个监控
这是最最保底的一个方案,依旧老艺术家手搓,将一步一步的调用过程用日志实现,然后实时存储到数据库,前台回显,手搓一个监控平台。
当然要是有这个时间,那估摸着就是老板事儿太多了。
5.2 可视化监控与链路追踪 (Trace & Debugging)
- 目标:学会"看懂" LangSmith 的后台面板,掌握排查 Agent 故障的核心思路。
- 痛点:在刚才手写 Agent 的代码中,如果大模型调用工具失败,或者进入了死循环,仅靠终端打印的文本极难定位问题根源。
- 内容 :
- 理解 Trace(调用树)和 Run(单次执行)的概念(完美对标 Java 微服务中的 SkyWalking/Zipkin 分布式追踪)。
- 实操 :运行我们第四章写好的带有 Tool Calling 的 Agent 脚本,然后登录 LangSmith 后台,通过可视化 UI 查看:
- 底层 Prompt 的真实样貌(看清那些被系统偷偷塞进去的 JSON Schema 和记忆数据)。
- 时间与性能损耗(哪一步最慢?网络耗时多少?)。
- Token 与成本账单(到底消耗了多少 Token?)。
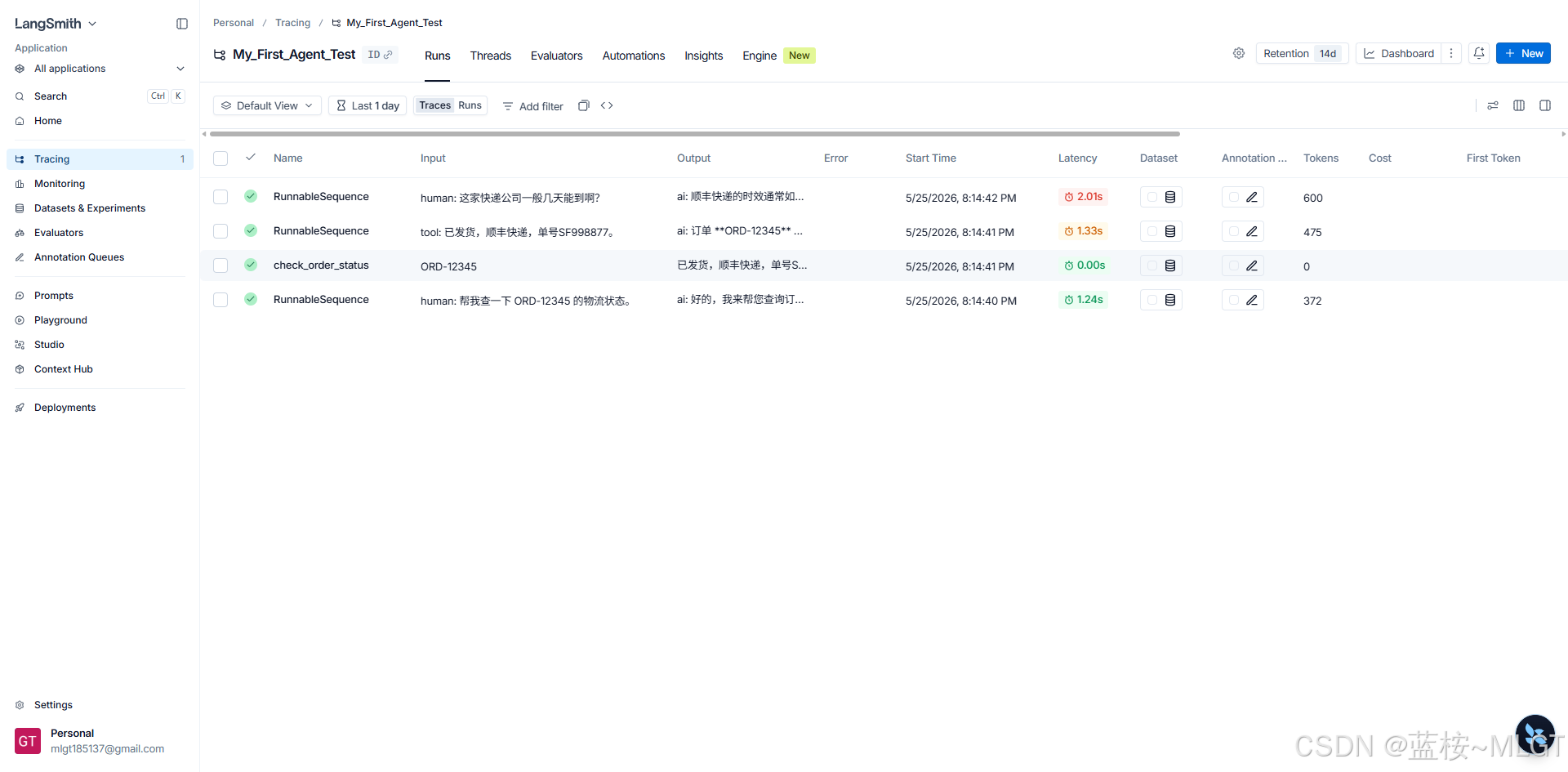
🔍 视点一:宏观大盘与账单
这里对标的是 Java 微服务里的接口请求流水。
- Name (组件名称) :
- 你看到了
RunnableSequence(这代表你用|组装的整条 LCEL 流水线被触发了)。 - 你还看到了绿色的
check_order_status!这说明系统极其精准地捕获到了本地 Python 工具函数的执行记录。
- 你看到了
- Latency (耗时分析) :
- 你看大模型回答第一句花了
1.24s,最后总结花了2.01s。 - 但看
check_order_status的耗时是0.00s!这说明什么?说明你的本地 Python 逻辑执行得飞快,整个系统的性能瓶颈 100% 在大模型的网络请求上。未来优化系统时,你就知道该去优化哪个环节了。
- 你看大模型回答第一句花了
- Tokens (成本账单) :
- 看最右侧,从
372涨到了475,最后一次是600。为什么会涨?因为咱们的记忆系统在生效! 历史记录越来越长,Token 消耗自然增加。这就是为什么我们在 3.3 节要学记忆修剪的原因,LangSmith 帮你把成本算得明明白白。
- 看最右侧,从
🔬 视点二:显微镜下的瀑布流
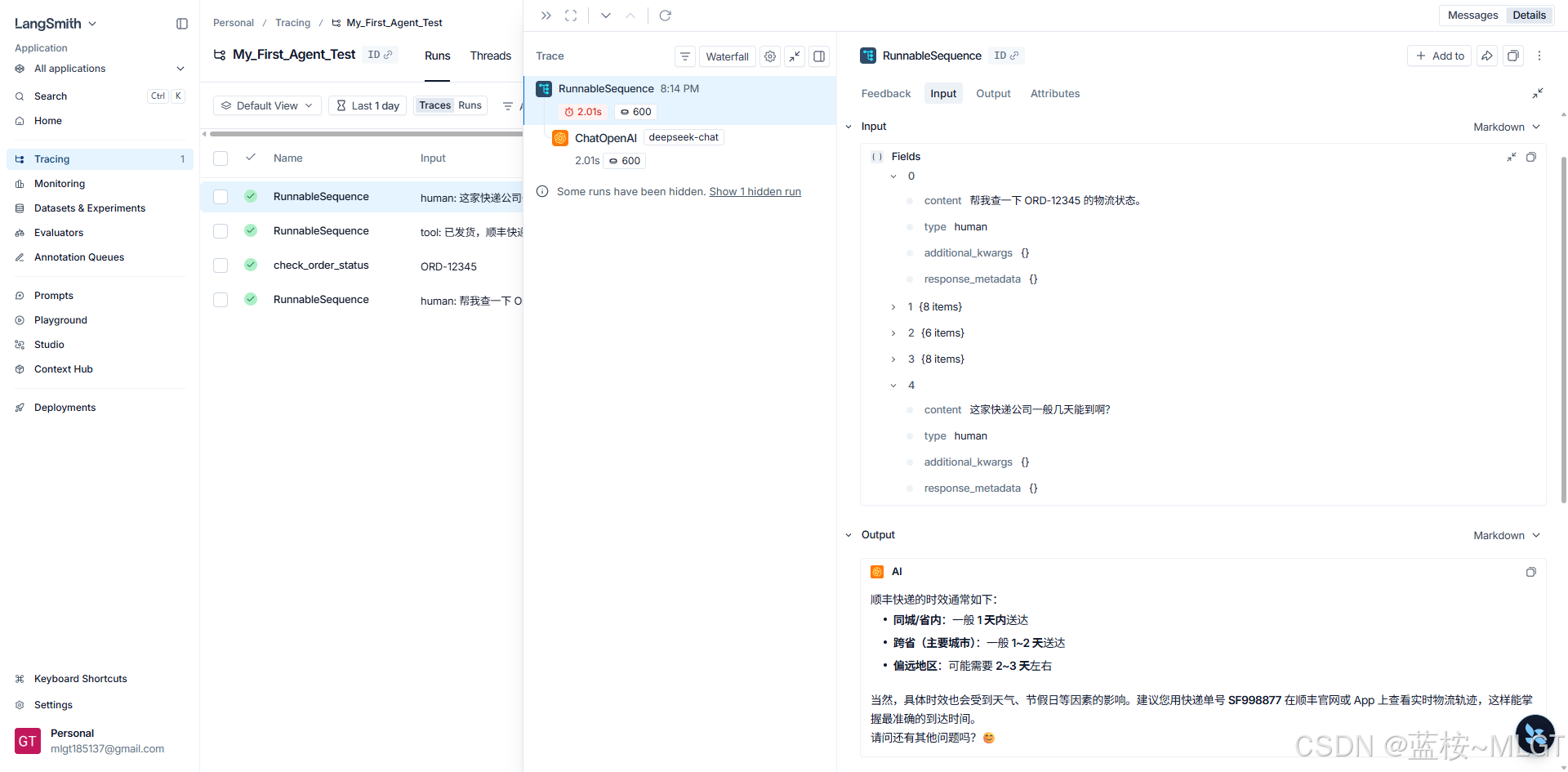
中间面板叫 Trace Waterfall (瀑布流视图)。对标 SkyWalking 的链路追踪。
- 层级嵌套 (Parent-Child) :
- 最外层是
RunnableSequence,耗时 2.01s。 - 它下面包着一个
ChatOpenAI (deepseek-chat),耗时也是 2.01s。 - 如果在更复杂的 Agent 里,你会在这里看到一个巨大的树状图:大模型思考 -> 调用工具 A -> 工具 A 查数据库 -> 大模型继续思考 -> 调用工具 B... 所有的时序一览无余!一旦出了 Bug,红色的报错会精准定位在某一个叶子节点上。
- 最外层是
🃏 视点三:看穿 AI 的底牌
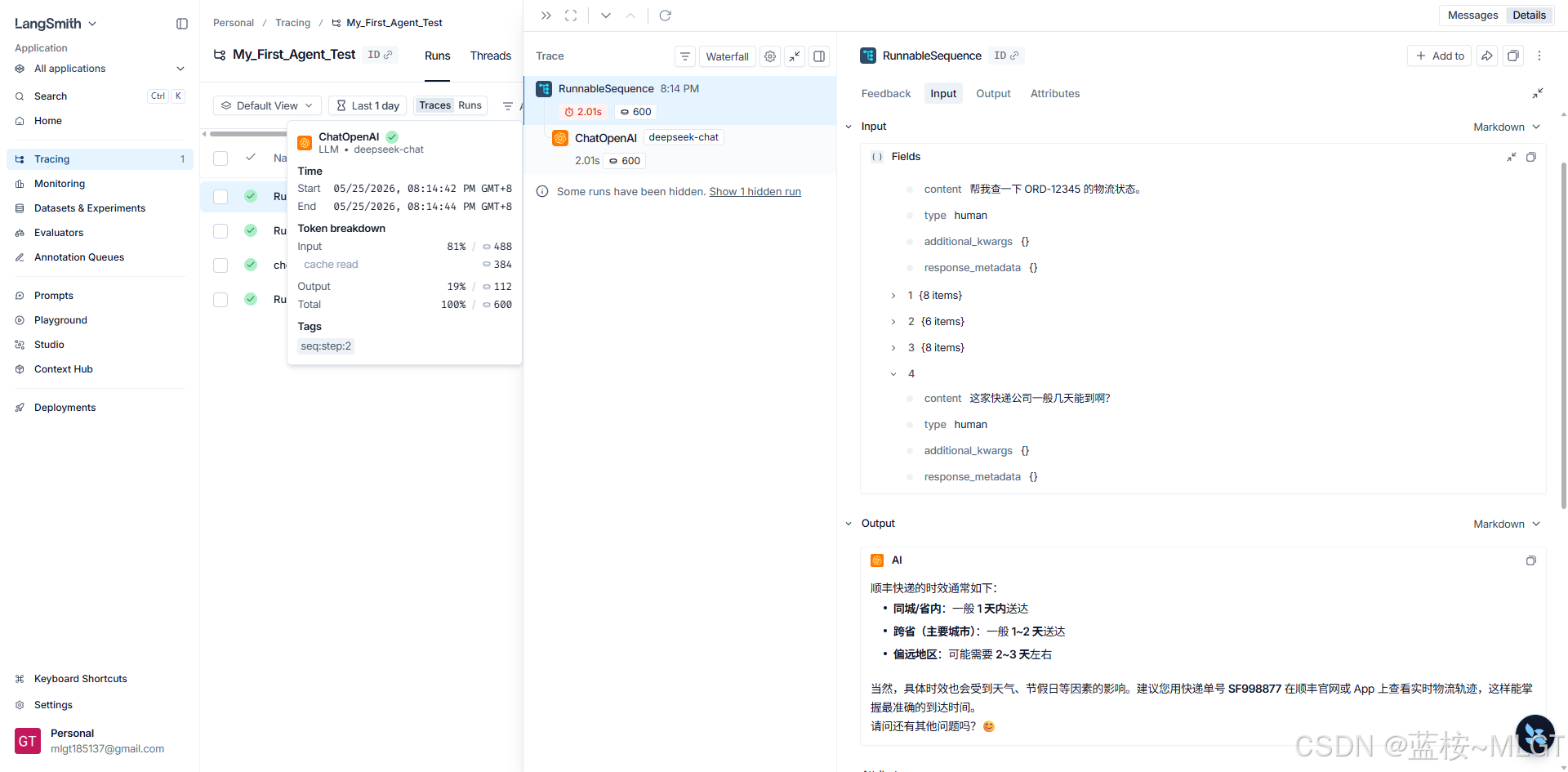
这是 LangSmith 最最最核心、最值钱的功能!解决 LCEL "黑盒"的终极武器!
在没有 LangSmith 之前,LCEL 的管道符 | 把数据包得严严实实,你根本不知道最终发给大模型的那一坨数据长什么样。现在你看图 2 右侧的 Input 面板:
- 多轮记忆铁证如山 :
- 看
Fields -> 0这个数组。它展开了有 5 个元素(0到4)。 0里面写着:content: 帮我查一下 ORD-12345...(这是第一轮对话)4里面写着:content: 这家快递公司一般几天能到啊?(这是第二轮对话)- 这完美证明了:我们写的
RunnableWithMessageHistory或者数据库拦截器,确确实实把上一次的对话拿出来,塞进了这次的请求里!
- 看
- Output (最终输出) :
- 清清楚楚地记录了大模型最后吐出的关于顺丰快递时效的 Markdown 文本。
- 【隐藏的宝藏】 :
- 如果在 Input 里展开更深,你甚至能看到 LangChain 偷偷塞进去的关于
check_order_status的 JSON Schema 描述。大模型就是看了那个描述才知道怎么调工具的。
- 如果在 Input 里展开更深,你甚至能看到 LangChain 偷偷塞进去的关于
🃏 视点四:分析底层的Token消耗
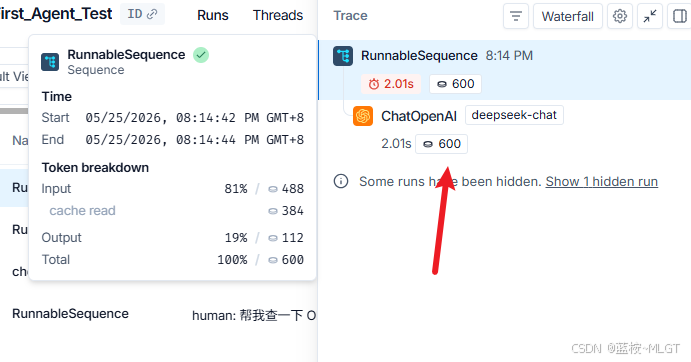
这里能明确的看到输入 、输出 、Cache命中等多维度信息,当然后期可能还需要工具的调用等更加详细的信息比如cursor的:
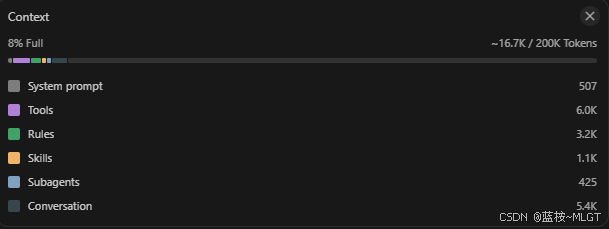
可以看到有具体的context上下文、系统prompt、tools等等。
🎯 架构师排错实战演练 (Debugging 场景)
掌握了看图技巧,以后你遇到这三种经典 Bug,就能秒杀:
- "AI 报错说格式不对" -> 立刻点开右侧的 Input ,检查是不是你的 Prompt 拼错了,或者动态参数(比如
itemgetter)提取成了 null。 - "AI 开始胡说八道/产生幻觉" -> 检查 Input 里的数组,是不是记忆修剪(Trimmer)切得太狠,把核心的需求
SystemMessage给切丢了? - "系统卡死了 10 秒没反应" -> 看中间的 Waterfall 瀑布图,看红色的长条卡在哪里,是数据库查得慢,还是大模型 API 超时?
六、天气Agent实现demo
这一章就到了总结的时候了,大家可以发挥想象做一个简单的Agent,必要时建议大家先手搓一个简单的骨架,遇到不会或者说不好解决的可以参考我的代码或者说使用大模型来给你修改,这样能复习学过的知识。
下面的demo实现逻辑比较简单,就是一个通过用户给出的目的地和时间,查询天气,给出穿衣建议等,但是用到了上述所学的所有知识点,是一个完全的白盒Agent,可控性很强。
但是比较是demo,有很多架构级别的功能是没有实现的,核心还是为了演示。
python
import os
import time
from datetime import datetime
from dotenv import load_dotenv, find_dotenv
from langchain_classic.output_parsers import OutputFixingParser
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.tools import tool
from langchain_core.messages import SystemMessage, ToolMessage
from langchain_core.chat_history import InMemoryChatMessageHistory
_ = load_dotenv(find_dotenv(), override=True)
# ==========================================
# 1. 打造武器库 (3 个核心工具)
# ==========================================
@tool
def get_current_location() -> str:
"""获取用户当前的地理位置(国家/城市)"""
print(" ⚙️ [系统工具执行] 正在定位用户当前位置...")
time.sleep(0.5) # 模拟真实耗时
return "United States"
@tool
def get_current_time() -> str:
"""获取系统当前的准确时间"""
print(" ⚙️ [系统工具执行] 正在获取系统时间...")
# 模拟真实世界时间
return datetime.now().strftime("%Y-%m-%d %H:%M:%S")
@tool
def find_weather(place_name: str, date: str) -> str:
"""查询对应地址在指定日期的天气情况"""
print(f" ☁️ [网络请求执行] 调用气象局API -> 地址:{place_name}, 日期:{date}...")
time.sleep(1) # 模拟网络请求耗时
# 简单的 Mock 数据
if "United States" in place_name or "US" in place_name:
return f"{date} {place_name} 天气:晴朗,气温 20-25 摄氏度,微风。"
elif "北京" in place_name:
return f"{date} {place_name} 天气:雷阵雨,气温 15-22 摄氏度,出门务必带伞。"
else:
return f"{date} {place_name} 天气:多云,气温适宜外出。"
tools_map = {
"find_weather": find_weather,
"get_current_time": get_current_time,
"get_current_location": get_current_location
}
# ==========================================
# 2. 核心架构初始化 (主模型与总结模型)
# ==========================================
# 主 Agent 引擎
llm = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v1",
temperature=0.7, timeout=30, max_retries=2
)
llm_with_tools = llm.bind_tools(list(tools_map.values()))
# 后台专用的廉价/精确模型 (专门用来做记忆压缩和 JSON 提取,温度设为0)
llm_backend = ChatOpenAI(
model="deepseek-chat",
api_key=os.getenv("DEEPSEEK_API_KEY"),
base_url="https://api.deepseek.com/v1",
temperature=0
)
# ==========================================
# 3. 记忆管理与滚动摘要 (Memory Trimming)
# ==========================================
session_store = {}
def get_session_history(session_id: str) -> InMemoryChatMessageHistory:
if session_id not in session_store:
session_store[session_id] = InMemoryChatMessageHistory()
return session_store[session_id]
def check_and_compress_memory(history: InMemoryChatMessageHistory):
"""【需求实现】动态记忆压缩。为方便演示,超过 6 条消息(约等于 5K Token)即触发压缩"""
if len(history.messages) > 6:
print("\n 🚨 [后台守护进程] 检测到上下文过长,触发滚动摘要机制...")
# 保留最近的 2 条消息,其余全压缩
old_messages = history.messages[:-2]
recent_messages = history.messages[-2:]
# 提取摘要
old_text = "\n".join([f"{m.type}: {str(m.content)[:50]}" for m in old_messages])
summary = llm_backend.invoke(f"请提炼以下历史对话的核心需求和提到的地点/天气信息:\n{old_text}").content
print(f" 📝 [记忆已压缩] 摘要生成: {summary}")
# 改写数据库
history.clear()
history.add_message(SystemMessage(content=f"【过往历史摘要】{summary}"))
for msg in recent_messages:
history.add_message(msg)
from langchain_core.output_parsers import PydanticOutputParser
# ==========================================
# 4. 后台数据清洗器
# ==========================================
class WeatherRecordDTO(BaseModel):
query_location: str = Field(description="用户查询的地点")
query_date: str = Field(description="用户查询的时间")
weather_desc: str = Field(description="天气状况的简短概括")
advice: str = Field(description="给出的出行建议")
# 实例化解析器,拿到说明书
base_parser = PydanticOutputParser(pydantic_object=WeatherRecordDTO)
format_instructions = base_parser.get_format_instructions()
fixing_parser = OutputFixingParser.from_llm(
parser=base_parser,
llm=llm_backend
)
# 专门为后台提取任务定制的 Prompt
extract_prompt = ChatPromptTemplate.from_messages([
("system",
"你是一个后台数据清洗程序。请从下面这段人类与AI的对话记录中,提取出天气查询的结构化信息。\n\n【严格遵守以下输出格式】:\n{format_instructions}"),
("user", "对话记录如下:\n{chat_history}")
])
# 组装后台专用的清洗流水线
data_extractor_chain = extract_prompt | llm_backend | fixing_parser
def async_save_to_db(chat_messages: list):
"""模拟异步线程去提取 JSON 并存库"""
print("\n 💾 [后台清洗系统] 正在从对话记录中提取结构化数据入库...")
try:
# 为了防干扰,我们把消息对象列表转成纯文本对话日志
chat_text = "\n".join([f"[{m.type}]: {str(m.content)}" for m in chat_messages])
# 触发流水线
record = data_extractor_chain.invoke({
"chat_history": chat_text,
"format_instructions": format_instructions
})
print(" ✅ [入库成功] 提取到的 JSON 数据如下:")
print(f" {record.model_dump_json(indent=2)}")
except Exception as e:
print(f" ❌ [入库失败] 未能提取到有效的天气咨询: {e}")
# ==========================================
# 5. Agent 极简主循环
# ==========================================
prompt = ChatPromptTemplate.from_messages([
("system",
"你是全球智能出行管家。你需要主动使用工具获取用户的当前时间、位置,然后再去查询天气,最后给出专业的旅游和穿衣建议。"),
MessagesPlaceholder(variable_name="history")
])
agent_engine = prompt | llm_with_tools
print("✈️ 全球出行管家 Agent 已启动!(输入 'quit' 退出)")
print("-" * 60)
session_id = "user_vip_01"
while True:
user_input = input("\n👤 你的需求: ")
if user_input.lower() in ['quit', 'exit']: break
if not user_input.strip(): continue
history = get_session_history(session_id)
history.add_user_message(user_input)
# 每次请求前,检查是否需要修剪记忆
check_and_compress_memory(history)
# 1. 发起 Agent 思考循环
print("🤖 Agent 思考中...")
while True:
# 调用大模型 (求稳,使用 invoke 处理工具调用)
ai_msg = agent_engine.invoke({"history": history.messages})
history.add_message(ai_msg)
if not ai_msg.tool_calls:
# 没有工具调用了,说明大模型思考完毕,给出最终答案
print(f"\n💬 管家回复: {ai_msg.content}")
break
# 截获工具调用指令并执行
for tool_call in ai_msg.tool_calls:
t_name = tool_call["name"]
t_args = tool_call["args"]
# 动态路由执行对应的 Python 函数
result = tools_map[t_name].invoke(t_args)
# 拿着结果交差
history.add_message(ToolMessage(
content=str(result),
tool_call_id=tool_call["id"]
))
# 2. 【需求实现】一轮对话结束,触发后台结构化数据清洗!
# 在真实项目中,这里通常会开一个 Thread 异步执行,不卡住主线程
async_save_to_db(history.messages)运行结果
shell
✈️ 全球出行管家 Agent 已启动!(输入 'quit' 退出)
------------------------------------------------------------
👤 你的需求: 明天出去玩,有什么建议,我要去纽约
🤖 Agent 思考中...
⚙️ [系统工具执行] 正在获取系统时间...
⚙️ [系统工具执行] 正在定位用户当前位置...
☁️ [网络请求执行] 调用气象局API -> 地址:纽约, 日期:2026-05-27...
💬 管家回复: 太棒了!纽约明天的天气情况如下:
---
## 🗽 纽约 5月27日(周三)出行建议
### 🌤 天气概况
- **天气状况**:多云
- **体感**:气温适宜外出
### 👔 穿衣建议
| 时间 | 建议穿搭 |
|------|---------|
| **白天** | 薄长袖T恤/衬衫 + 休闲裤/牛仔裤,舒适为主 |
| **早晚** | 建议带一件**薄外套或风衣**,5月底纽约早晚可能微凉 |
| **鞋子** | 舒适的运动鞋或平底鞋(纽约靠走🚶) |
### 🎯 游玩推荐
1. **经典打卡** 🏛
- 自由女神像、时代广场、中央公园(多云天气散步超舒服!)
- 大都会博物馆、百老汇看场剧
2. **美食体验** 🍕
- 尝尝纽约披萨、贝果、街头热狗
3. **交通提示** 🚇
- 纽约地铁方便,建议买张MetroCard或刷手机支付
### ⚠️ 小贴士
- 多云天气紫外线依然存在,建议**带墨镜和防晒**
- 纽约人多,注意保管好随身物品
祝你在纽约玩得开心!🎉 还有什么想了解的随时问我~
💾 [后台清洗系统] 正在从对话记录中提取结构化数据入库...
✅ [入库成功] 提取到的 JSON 数据如下:
{
"query_location": "纽约",
"query_date": "2026-05-27",
"weather_desc": "多云,气温适宜外出",
"advice": "建议穿薄长袖T恤或衬衫搭配休闲裤,早晚带薄外套;游玩推荐自由女神像、时代广场、中央公园等;注意防晒和保管随身物品。"
}
👤 你的需求: 那去北京玩呢,具体时间是下个月6号
🚨 [后台守护进程] 检测到上下文过长,触发滚动摘要机制...
📝 [记忆已压缩] 摘要生成: 好的,根据您提供的对话内容,我已提炼出核心需求及地点/天气信息如下:
**核心需求:**
用户计划明天(2026年5月27日)外出游玩,希望获得针对纽约的出行建议。
**地点/天气信息:**
- **地点:** 纽约
- **天气:** 多云,气温适宜外出。
🤖 Agent 思考中...
⚙️ [系统工具执行] 正在获取系统时间...
⚙️ [系统工具执行] 正在定位用户当前位置...
☁️ [网络请求执行] 调用气象局API -> 地址:北京, 日期:2026-06-06...
💬 管家回复: 好的,北京6月6日的天气信息出来了,给您一份详细攻略👇
---
## 🏯 北京 6月6日(周六)出行建议
### 🌧 天气概况
| 项目 | 详情 |
|------|------|
| **天气** | ⛈ **雷阵雨** |
| **气温** | **15°C ~ 22°C** |
| **提醒** | **出门务必带伞!** |
### 👔 穿衣建议
| 场景 | 穿搭推荐 |
|------|---------|
| **整体** | 长袖T恤/薄衬衫 + 长裤(15~22°C偏凉爽) |
| **外套** | 🧥 **强烈建议带一件薄夹克或风衣**,下雨+降温体感更凉 |
| **鞋子** | 👟 防滑/防水的鞋子最佳(下雨路面湿滑) |
| **雨具** | ☂️ **雨伞必备!** 最好再带个防水小包保护手机/相机 |
### 🎯 游玩推荐(室内外兼顾)
**🏛 室内首选(避开雷阵雨)**
- **故宫博物院** --- 宏伟壮观,廊道遮雨,逛起来没问题!
- **国家博物馆** --- 天安门广场旁,文化底蕴深厚
- **798艺术区** --- 室内画廊+咖啡馆,文艺范十足
**🌿 室外景点(雨停可去)**
- **颐和园** / **天坛** --- 雨后的北京别有一番韵味
- **南锣鼓巷** --- 胡同里走走,找家小店躲雨喝茶🍵
### ⚠️ 特别提醒
1. **雷阵雨来得快去得也快**,建议灵活安排行程,下雨时进室内场馆
2. 15°C~22°C温差较大,**早晚偏凉**,别只带短袖哦
3. 北京6月已进入夏季,但遇雨天会凉爽,**别着凉了**🤧
---
从纽约飞北京大概13~14小时,记得调整好时差(北京比纽约快12小时)!祝您北京之旅玩得尽兴~🎉 还有问题随时问我!
💾 [后台清洗系统] 正在从对话记录中提取结构化数据入库...
✅ [入库成功] 提取到的 JSON 数据如下:
{
"query_location": "北京",
"query_date": "2026-06-06",
"weather_desc": "雷阵雨,气温15-22摄氏度",
"advice": "出门务必带伞,建议穿长袖T恤和薄夹克,注意防滑和保暖,灵活安排室内外行程"
}
👤 你的需求: exit
进程已结束,退出代码为 0监控数据:
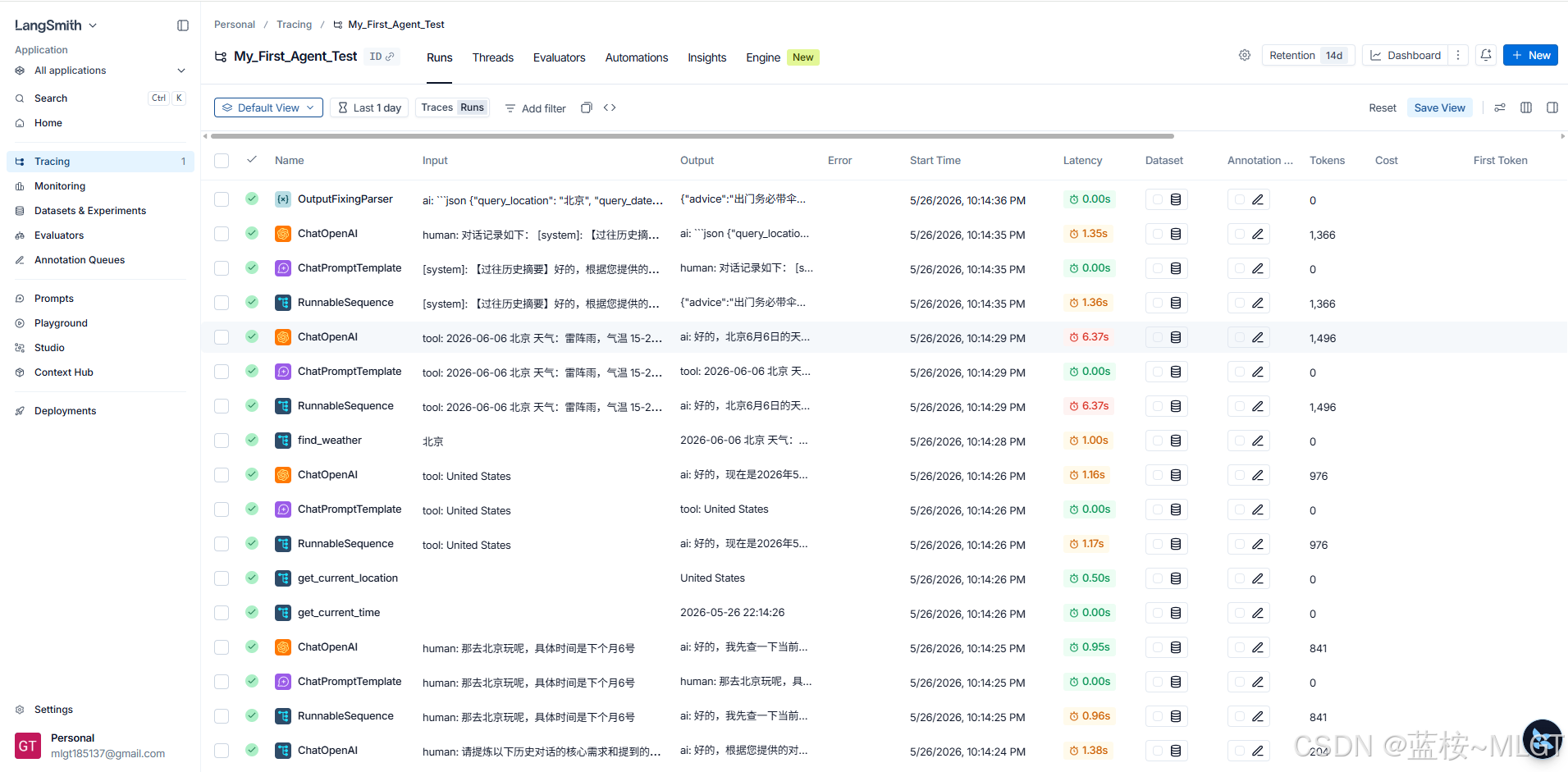
总结
这一章对Agent的底层实现有了清晰的认识,如果说现在手搓一个还是有点困难,但是原理我们明白了。怎么赋予AI执行工具的能力,怎么实现记忆等。
但是不要着急,要真正理解Agent和做出一个Agent还需要一段时间,接下来我们将进入Rag时代,没有知识检索还是不行的,不然缺少灵魂,一步一步来,最后通过实战代码就逐渐掌握Agent开发了,毕竟这需要时间。加油!