论文标题:SSD: Single Shot MultiBox Detector
地址:https://arxiv.org/pdf/1512.02325
SSD(Single Shot MultiBox Detector)是一种高效的目标检测算法,其核心思想是在单次前向传播中同时预测目标的类别和位置。相较于传统的两阶段检测方法(如Faster R-CNN),SSD通过结合多尺度特征图与预定义先验框(Prior Boxes),实现了速度与精度的平衡。
为了改进R-CNN,后续出现Fast-RCNN , Faster-RCNN , Mask-RCNN 等一系列改进算法。这些算法虽然取得了更高的准确率,但是在速度方面还是有所欠缺。SSD就恰巧解决了这一点,SSD基本可以达到实时检测的速度要求,并且在准确性和计算速度方面具有良好的平衡。
SSD:Single Shot(单步):目标定位和分类在网络的单个前向传递中完成;MultiBox:边界框回归技术;Detector(检测器):对检测到的对象进行分类。
SSD 在一张图像的多个不同尺度特征图上,同时预测所有目标的类别和边界框,一步完成检测,没有单独的区域建议阶段。核心设计:1.单步检测:没有 RPN,前向传播一次直接输出所有目标的类别和坐标;2.多尺度特征图预测:用不同大小的特征图检测不同大小的目标;3.密集先验框:每个特征点生成多个不同尺度、宽高比的先验框。
1.经典的 SSD300(输入 300×300 图像)
SSD300架构基于VGG-16构建,使用VGG的前五个卷积,Conv6层以上使用辅助卷积层而不是全连接层。使用VGG-16作为基础网络的原因是其高质量的图像分类和迁移学习以改善结果。使用辅助卷积层,我们可以提取多个尺度的特征,并逐步减小每个后续层的尺寸。越往前的feature map层(越大的feature map)让它检测越小的物体,越靠后的层(越小的feature map)检测比较大的物体。
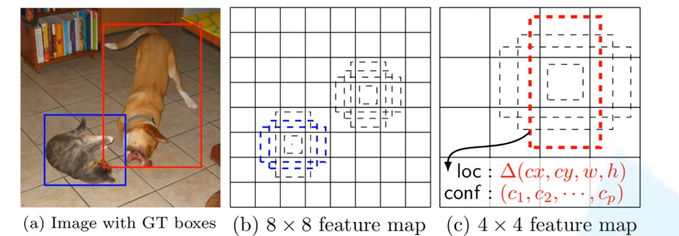
例如,这个较小的猫就适合在比较大的8×8feature map层进行检测,这个狗比较大,所以它就适合在比较小的4×4层进行检测。
VGG16 原本的结构是:5个卷积块和3个全连接层(fc6、fc7、fc8)。而SSD 为了做成全卷积网络,把 VGG 原来的两个全连接层fc6 和 fc7 ,改成了卷积层 Conv6 和 Conv7 。
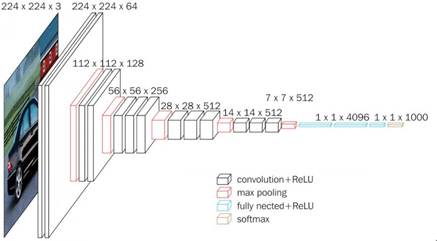
VGG16架构
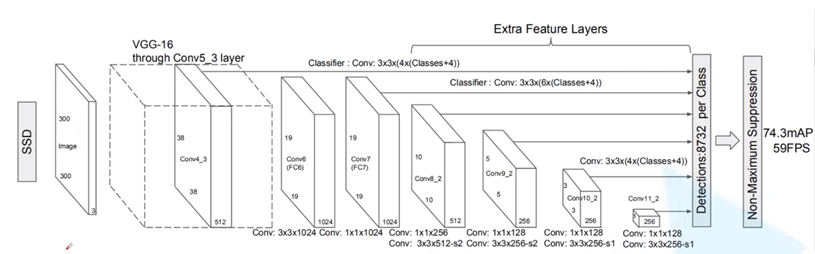
SSD300(Conv5_3是第5个卷积块的第3个卷积层遵循VGG 系列网络标准层命名规则)
| 层名称 | 类型 | 输出尺寸 | 作用 |
|---|---|---|---|
| 输入 | - | 300×300×3 | 输入RGB彩色图像 |
| VGG16 骨干**(最终输出就是Conv5_3)** | 卷积块 | 19×19×512 | 提取基础特征 |
| Conv4_3 | VGG 原生卷积 | 38×38×512 | 检测小目标 |
| Conv5_3 | VGG 原生卷积 | 19×19×512 | 基础特征输出 |
| Conv6 | 3×3 膨胀卷积(VGG改造层) | 19×19×1024 | 扩大感受野 |
| Conv7 | 1×1 卷积(VGG改造层) | 19×19×1024 | 检测中小目标 |
| Conv8_1 + Conv8_2 | 1×1+3×3卷积(额外) | 10×10×512 | 检测中目标 |
| Conv9_1 + Conv9_2 | 1×1+3×3卷积(额外) | 5×5×256 | 检测中大目标 |
| Conv10_1 + Conv10_2 | 1×1+3×3卷积(额外) | 3×3×256 | 检测大目标 |
| Conv11_1 + Conv11_2 | 1×1+3×3卷积(额外) | 1×1×256 | 检测超大目标 |
| 所有检测头输出拼接 | - | (8732, num_classes + 4) | 汇总6个特征图的所有检测结果 |
| NMS后处理 | - | (N, num_classes + 5) | 去除重复检测框 |
| 最终检测结果 | - | (K, 6) | 输出K个目标:x1,y1,x2,y2, 置信度,类别 |
所有的 "额外卷积层" 其实都是两层一组 (1×1降维 + 3×3卷积)。其中,Conv6和Conv7共同构成了第一个额外特征块,最终输出的是Conv7特征图。Conv6用的是3×3 膨胀卷积( dilation=6 ),这是SSD的一个关键设计,用来在不降低特征图分辨率的情况下,大幅扩大感受野。
所有检测头输出拼接的输出尺寸是(8732, num_classes + 4):8732 个先验框;num_classes:数据集类别数(如 VOC2007 是 20 类);+4:每个先验框的 4 个坐标偏移量。
2. SSD 算法核心的锚框(Anchor)机制原理
SSD 在图像的不同位置、不同尺度上,预先定义好大量不同大小、不同形状的 "模板框"(锚框),网络不需要从零开始预测物体位置,只需要预测这些模板框和真实物体之间的偏移量,同时预测每个框里有没有物体、是什么物体。

对每个像素生成多个以它为中心的多个锚框,给定n个锚框尺度(大小)参数s1,...,sn和m个宽高比,就是生成n+m−1个锚框,其大小和高宽比分别为:(s1,r1),(s2,r2),....(sn,r1),(s1,r2),....(s1,rm)。
上图的网格是特征图的网格 (比如 38×38、19×19 的特征图);每个网格交叉点(特征点),都会生成多个以它为中心的彩色框,这些就是锚框;图里每个点生成了6个锚框,对应SSD标准设计:3种大小 + 3种宽高比。
3.模型
SSD模型主要由基础网络组成,其后是几个多尺度特征块。基本网络用于从输入图像中提取特征,因此它可以使用深度卷积神经网络。单发多框检测论文中选用了VGG,现在也常用ResNet替代。我们可以设计基础网络,使它输出的高和宽较大,使得基于该特征图生成的锚框数量较多,可以用来检测尺寸较小的目标。接下来的每个多尺度特征块将上一层提供的特征图的高和宽缩小(如减半),并使得特征图中每个单元在输入图像上的感受野变得更广阔。
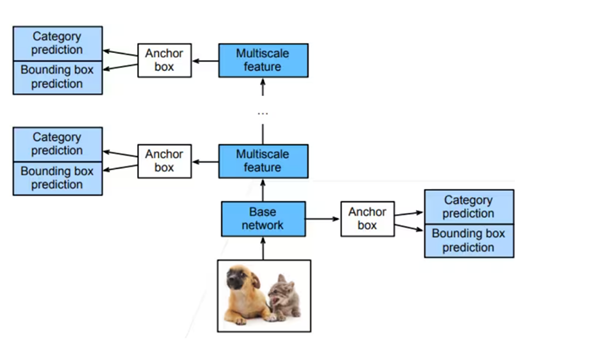
SSD 完整的检测流程(这是一个多尺度目标检测模型)
SSD的所有预测都是基于预先定义好的锚框 进行的:网络不直接预测物体的绝对坐标 ,只预测锚框到真实物体框的偏移量 ;网络同时预测每个锚框包含物体的类别概率 ;每个锚框对应独立的类别预测分支 和独立的边界框预测分支。
SSD 所有特征图的检测头都采用完全相同的设计 :两个并行的 3×3 卷积层。
3×3卷积(分类分支)→ 输出类别概率
3×3卷积(回归分支)→ 输出边界框偏移量
(1)类别预测(分类分支)
类别分支输出的是每个锚框属于各个类别的概率。例如,对于VOC2007数据集,每个锚框输出21个概率值:第0个值:属于背景的概率;第1-20个值:分别属于20个物体类别的概率。
(2)边界框预测(回归分支)
边界框分支输出的不是最终的框坐标 (x1,y1,x2,y2),而是4个偏移量 (dx, dy, dw, dh),表示锚框需要如何调整才能对准真实物体。用偏移量不直接预测坐标得原因:
训练更稳定:偏移量的数值范围很小(通常在- 1到1之间),比直接预测几百像素的坐标更容易收敛。
泛化能力强:网络学习的是相对位置关系,而不是绝对坐标,对不同大小的物体都适用。
符合锚框设计思想:锚框已经提供了很好的初始位置,网络只需要做微小调整。
SSD 算法的核心原理总结:
(1)输入图像之后,首先进入一个基础网络来抽取特征,抽取完特征之后对每个像素生成大量的锚框(每个锚框就是一个样本,然后预测锚框的类别以及到真实边界框的偏移)。锚框不是网络学习的,是预先定义好的,网络学习的只是锚框的偏移量,不是锚框本身的位置和大小。
(2)SSD 在给定锚框之后直接对锚框进行预测,而不需要做两阶段(SSD 通过做不同分辨率下的预测来提升最终的效果)。
(3)SSD 不再使用 RPN 网络,而是直接在生成的大量样本(锚框)上做预测,看是否包含目标物体;如果包含目标物体,再预测该样本到真实边缘框的偏移。
| 对比维度 | SSD | Faster R-CNN |
|---|---|---|
| 预测阶段 | 单阶段,直接在锚框上做最终预测 | 两阶段,先 RPN 生成候选框,再对候选框做第二次预测 |
| 预测对象 | 所有锚框(8732个) | 筛选后的候选框(2000个) |
| 分类分支 | 直接预测所有物体类别 | 先二分类(前景/背景),再多分类 |
| 速度 | 快 | 慢 |
| 小目标检测 | 较好(多尺度特征) | 更好(两阶段精细检测) |
4.代码示例
python
import torch
import torch.nn as nn
import torchvision.models as models
import numpy as np
# L2归一化层
'''
SSD论文专属层
作用:Conv4_3特征图数值范围太大,归一化后才能稳定训练
'''
class L2Norm(nn.Module):
def __init__(self, in_channels=512, scale=20):
super().__init__()
# 可学习的缩放参数,初始值20(论文固定值)
self.gamma = nn.Parameter(torch.ones(in_channels) * scale)
self.eps = 1e-10
def forward(self, x):
# L2归一化公式:x / 模长 * 缩放系数
norm = x.pow(2).sum(dim=1, keepdim=True).sqrt() + self.eps
return x / norm * self.gamma.view(1, -1, 1, 1)
# SSD300模型
class SSD300(nn.Module):
def __init__(self, num_classes=21):
super().__init__()
# 固定参数 6个特征图的锚框数量 VOC数据集:20类+背景=21类
self.num_anchors = [4, 6, 6, 6, 4, 4]
self.num_classes = num_classes
# 加载VGG16并修改池化层
vgg = models.vgg16(weights=models.VGG16_Weights.IMAGENET1K_V1).features
# 修改所有池化层的ceil_mode=True,确保尺寸正确 保证300×300输入 → 特征图尺寸严格为[38,19,10,5,3,1]
for layer in vgg:
if isinstance(layer, nn.MaxPool2d):
layer.ceil_mode = True
# 去掉VGG的池化层
self.vgg = nn.ModuleList(list(vgg.children())[:-1])
# 给Conv4_3特征图加归一化
self.l2_norm = L2Norm()
# 额外特征层(官方结构)
# 作用:在VGG后新增4层,生成小尺寸特征图(检测大目标)
self.extras = nn.ModuleList([
# Conv6 → Conv7(VGG改造,生成19×19特征图)
nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6),
nn.ReLU(inplace=True),
nn.Conv2d(1024, 1024, kernel_size=1),
nn.ReLU(inplace=True),
# Conv8(生成10×10特征图) 额外层1
nn.Conv2d(1024, 256, kernel_size=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 512, kernel_size=3, stride=2, padding=1),
nn.ReLU(inplace=True),
# Conv9(生成5×5特征图) 额外层2
nn.Conv2d(512, 128, kernel_size=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 256, kernel_size=3, stride=2, padding=1),
nn.ReLU(inplace=True),
# Conv10(生成3×3特征图) 额外层3
nn.Conv2d(256, 128, kernel_size=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 256, kernel_size=3),
nn.ReLU(inplace=True),
# Conv11(生成1×1特征图) 额外层4
nn.Conv2d(256, 128, kernel_size=1),
nn.ReLU(inplace=True),
nn.Conv2d(128, 256, kernel_size=3),
nn.ReLU(inplace=True),
])
# 检测头
# 作用:对6个特征图分别预测 边界框 + 类别
# 边界框预测:每个锚框输出4个值 (x,y,w,h偏移量)
self.loc_layers = nn.ModuleList([
nn.Conv2d(512, 4*4, 3, padding=1), # 特征图0:4锚框 → 16通道 对应conv4_3
nn.Conv2d(1024, 6*4, 3, padding=1), # 特征图1:6锚框 → 24通道 对应conv6+conv7
nn.Conv2d(512, 6*4, 3, padding=1), # 特征图2:6锚框 → 24通道 对应conv8_2
nn.Conv2d(256, 6*4, 3, padding=1), # 特征图3:6锚框 → 24通道 对应conv9_2
nn.Conv2d(256, 4*4, 3, padding=1), # 特征图4:4锚框 → 16通道 对应conv10_2
nn.Conv2d(256, 4*4, 3, padding=1), # 特征图5:4锚框 → 16通道 对应conv11_2
])
# 类别预测:每个锚框输出21个概率(VOC21类)
self.conf_layers = nn.ModuleList([
nn.Conv2d(512, 4*num_classes, 3, padding=1),
nn.Conv2d(1024, 6*num_classes, 3, padding=1),
nn.Conv2d(512, 6*num_classes, 3, padding=1),
nn.Conv2d(256, 6*num_classes, 3, padding=1),
nn.Conv2d(256, 4*num_classes, 3, padding=1),
nn.Conv2d(256, 4*num_classes, 3, padding=1),
])
def forward(self, x):
features = [] # 存放6个检测特征图
# 提取Conv4_3(现在尺寸是38x38) 提取第0个特征图(38×38,检测小目标)
for i in range(23):
x = self.vgg[i](x)
features.append(self.l2_norm(x))
# 提取VGG剩余部分 提取第1个特征图(19×19,检测中目标)
for i in range(23, len(self.vgg)):
x = self.vgg[i](x)
# 提取额外特征 提取剩余4个特征图(10×10 /5×5 /3×3 /1×1)
for i, layer in enumerate(self.extras):
x = layer(x)
# 只保留每个块的最后输出(共4个)
if i in [3, 7, 11, 15, 19]:
features.append(x)
# 调试打印
print("\n===== 每个特征图的锚框数 =====")
total = 0
for idx, feat in enumerate(features):
h, w = feat.size(2), feat.size(3)
num_anchors = self.num_anchors[idx]
feat_anchors = h * w * num_anchors
print(f"特征图{idx} ({feat.shape}): {feat_anchors} 个锚框")
total += feat_anchors
print(f"模型输出总锚框数: {total}")
# 预测输出
locs = [] # 存放所有边界框预测
confs = [] # 存放所有类别预测
for i in range(6):
# 预测边界框 + 维度变换(把特征图展平)
loc = self.loc_layers[i](features[i])
loc = loc.permute(0, 2, 3, 1).contiguous().view(x.size(0), -1)
locs.append(loc)
# 预测类别 + 维度变换
conf = self.conf_layers[i](features[i])
conf = conf.permute(0, 2, 3, 1).contiguous().view(x.size(0), -1)
confs.append(conf)
# 拼接所有结果 → 输出标准形状
return torch.cat(locs, dim=1).view(x.size(0), -1, 4), \
torch.cat(confs, dim=1).view(x.size(0), -1, self.num_classes)
# 锚框生成函数(固定8732个)
def generate_anchors():
# 标准参数
feature_map_sizes = [38, 19, 10, 5, 3, 1] # 6个特征图尺寸
steps = [8, 16, 32, 64, 100, 300] # 感受野步长
scales = [0.1, 0.2, 0.375, 0.55, 0.725, 0.9, 1.05] # 锚框大小
aspect_ratios = [[2], [2, 3], [2, 3], [2, 3], [2], [2]] # 宽高比
anchors = []
# 遍历每个特征图,生成所有锚框
for k, f in enumerate(feature_map_sizes):
for i in range(f):
for j in range(f):
# 计算锚框中心坐标
cx = (j + 0.5) * steps[k] / 300.0
cy = (i + 0.5) * steps[k] / 300.0
# 生成不同大小/形状的锚框
s = scales[k]
anchors.append([cx, cy, s, s])
s_prime = np.sqrt(scales[k] * scales[k + 1])
anchors.append([cx, cy, s_prime, s_prime])
for ar in aspect_ratios[k]:
anchors.append([cx, cy, s * np.sqrt(ar), s / np.sqrt(ar)])
anchors.append([cx, cy, s / np.sqrt(ar), s * np.sqrt(ar)])
return torch.tensor(anchors, dtype=torch.float32)
# 4. 测试运行
if __name__ == "__main__":
model = SSD300(num_classes=21)
anchors = generate_anchors()
print(f"锚框生成成功,总数:{len(anchors)}")
test_input = torch.randn(1, 3, 300, 300) # 输入1张300×300图片
with torch.no_grad():
locs, confs = model(test_input)
print(f"边界框输出形状: {locs.shape}") # [批次大小, 锚框总数, 预测特征数]
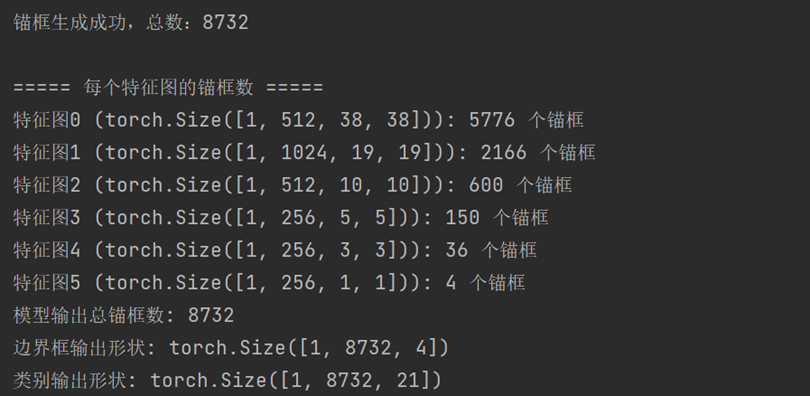
print(f"类别输出形状: {confs.shape}") # [批次大小, 锚框总数, VOC 数据集的总类别数] (SSD300 默认训练数据集)运行结果如下:
5.优势与局限
-
优势:实时性强(如VGG-SSD在Titan X上达59 FPS),对小目标检测效果较好。
-
局限:极端长宽比目标易漏检,深层特征分辨率低影响小目标精度。
SSD为后续算法(如YOLO、RetinaNet)提供了重要设计思路,至今仍是平衡速度与精度的经典方案。