本文构建了一套完整的 Airflow 3.2.1 智能工作流编排环境,将 Apache Airflow 的 AgentOperator、多种 Toolset(SQL/Hook/MCP)、对象存储(MinIO)、大语言模型代理(LiteLLM)融为一体,实现了自然语言驱动数据操作的 AI Agent 工作流。
整体架构如下
HTTP
触发 DAG Run
DAG 元数据
查询 DagRun /
TaskInstance
推送任务消息
拉取任务
Execution API
获取上下文
结果 / XCom
AgentOperator
SQLToolset
HookToolset / S3Hook
MCPToolset
触发器事件
用户
Airflow UI / CLI
API Server
REST API v2 + UI
:8080
DAG Processor
解析 DAG 文件
检测变更 / 激活状态
Scheduler
任务调度
决定执行时机
Redis
消息代理
任务队列
Worker
Celery Worker
执行任务
Triggerer
管理 Deferrable
Operator 触发器
PostgreSQL
元数据库
XCom / 连接 / 变量
LiteLLM
:4000
12 models
sample_db
业务数据
MinIO
:9003 / :9004
S3 兼容存储
MCP Server
:3001
JSON-RPC
核心数据流
- 用户通过 Airflow UI 或 CLI 触发 DAG
- Scheduler 调度任务
- Celery Worker 执行 AgentOperator
- Agent 通过 pydantic-ai 框架调用 LiteLLM 代理的 LLM
- LLM 决策调用 Toolset(SQL/Hook/MCP)
- Toolset 执行实际操作(查询数据库、读写 S3、调用 MCP 工具)
- 结果返回 LLM 继续推理
- 最终输出汇总
理论基础
Airflow 3.x 架构
Airflow 3.x 相比 2.x 进行了重大架构调整。最显著的变化是将传统的 webserver 拆分为独立的 api-server。这一变更并非简单的重命名,而是反映了 Airflow 对 API-First 设计理念的拥抱:所有 UI 操作底层都通过 REST API v2 实现,API Server 成为所有管理操作的唯一入口。
与此配套的是 dag-processor 从 scheduler 中独立出来。在 Airflow 2.x 中,scheduler 既负责 DAG 解析又负责任务调度,职责耦合导致性能瓶颈。3.x 将 DAG 文件解析、激活状态管理交给独立的 dag-processor,scheduler 专注于任务调度逻辑,两者通过数据库协调状态。
新增的 AIRFLOW__CORE__EXECUTION_API_SERVER_URL 配置项是 3.x 的关键变更。Worker 和 Triggerer 不再直接访问数据库获取任务上下文,而是通过 Execution API(/execution/ 端点)与 API Server 通信。这种隔离确保执行面组件可以在不同网络分区甚至不同集群中运行。但控制面组件(Scheduler、DAG Processor)仍然直连元数据库------它们是同一信任域内的核心服务。
这个"控制面直连、执行面走 API"的分层设计是有意为之的:
-
为什么控制面直连数据库? Scheduler 的调度循环每秒执行一次,每次需要查询 DagRun、创建 TaskInstance、处理执行器事件。如果这些操作都经过 API Server 中转,API Server 会成为性能瓶颈。控制面组件(API Server、Scheduler、DAG Processor)部署在同一信任域内,共享数据库连接池,直连是最优的架构选择。源码中 Scheduler 使用
create_session()(封装了 SQLAlchemy Session)直接操作数据库,DAG Processor Manager 通过@provide_session装饰器获取数据库 session 写入解析结果。 -
为什么执行面不走数据库? Worker 和 Triggerer 是可水平扩展的执行组件,可能部署在不同的 Kubernetes 命名空间、不同的可用区甚至不同的集群。如果每个 Worker 都直连元数据库,数据库连接数会随 Worker 数量线性增长。通过 Execution API 集中访问,API Server 可以做连接池化、权限校验、限流,保护数据库不被打爆。源码中 Worker 的
run()函数没有create_session调用,所有上下文通过Execution API获取;Triggerer Supervisor 通过self.client.*(API Client)访问 XCom、变量等资源。
本项目的 docker-compose.yaml 中体现这些架构变化:
yaml
# docker-compose.yaml 关键配置
AIRFLOW__CORE__EXECUTION_API_SERVER_URL: "http://airflow-apiserver:8080/execution/"五个核心组件详解
API Server 是整个系统的"前台"。它暴露 REST API v2 和 Web UI,是用户和外部系统与 Airflow 交互的唯一入口。它负责:
- 提供 Airflow Web UI(默认 :8080)
- 处理 DAG 触发、暂停、删除等管理操作
- 暴露 Execution API(
/execution/),供 Worker 和 Triggerer 获取任务上下文 - 处理健康检查端点(
/api/v2/monitor/health) - 管理用户认证和权限(通过 FabAuthManager Provider,仅负责用户管理,不再驱动整个 Web 框架)
在 CeleryExecutor 模式下,API Server 不执行任何任务。它只负责"接收请求,写入数据库,等待结果"。
DAG Processor 是 DAG 文件的"编译器"。它独立运行,周期性地扫描 DAG 目录(/opt/airflow/dags/),对每个 Python 文件进行解析:
- 为每个 DAG 文件启动独立的子进程执行 Python 代码,提取 DAG 对象和 Task 对象
- 子进程解析完成后,DAG Processor Manager 将结果直连写入元数据库
- 检测文件变更(新增、修改、删除),更新元数据库中的 DAG 注册信息
- 管理 DAG 的激活/暂停状态
- 将解析错误记录到
import_errors表,不影响其他 DAG
子进程中的 DAG 代码如果需要访问 Airflow 资源(连接、变量、XCom 等),通过 IPC 向父进程发送请求,父进程通过 API Client 转发到 API Server。
在 Airflow 2.x 中,这些职责由 Scheduler 的 DagFileProcessorManager 承担。3.x 将其独立为服务,Scheduler 不再需要处理 DAG 解析,减少了 CPU 和内存争用。
Scheduler 是任务调度的"大脑"。它从元数据库读取已激活的 DAG 定义,根据调度规则决定何时创建 DAG Run 和 Task Instance:
- 为有调度的 DAG(
schedule="*/5 * * * *"等)自动创建 DAG Run - 处理手动触发的 DAG Run(
airflow dags trigger) - 将就绪的 Task Instance 推送到 Celery 任务队列(Redis)
- 跟踪任务状态(queued → running → success/failed),处理重试逻辑
- 通过心跳机制报告自身健康状态(
/health端点,端口 8974)
Scheduler 不执行任务本身,它只负责"决定谁该跑,然后派发出去"。
Worker(Celery Worker) 是任务的"执行引擎"。它从 Redis 消息队列拉取任务,在独立进程中执行:
- 注册到 Celery 应用(
airflow.providers.celery.executors.celery_executor.app) - 监听
default队列(可配置多个队列实现优先级隔离) - 每个任务在独立子进程中执行(通过
dumb-init管理进程生命周期) - 通过 Execution API 从 API Server 获取任务上下文(而非直接访问数据库)。
- 执行完成后,通过 Execution API 将结果(包括 XCom 值)写回
Worker 是整个系统中唯一实际"干活"的组件。当 AgentOperator 执行时,Worker 进程内会创建 pydantic-ai Agent 实例,调用 LLM,执行 Toolset 操作。
Worker 调用了以下 Execution API 端点:
方法 路径 用途 PATCH/execution/task-instances/{id}/run获取任务上下文并标记为运行中 PUT/execution/task-instances/{id}/heartbeat发送心跳 PUT/execution/task-instances/{id}/rtif写入 Rendered Task Instance Fields GET/execution/connections/{conn_id}获取连接配置(如 pydanticai_default、minio_s3) POST/execution/xcoms/{dag_id}/{run_id}/{task_id}/{key}写入 XCom 值 PATCH/execution/task-instances/{id}/state更新任务状态(success/failed)
Triggerer 是 Deferrable Operator 的"事件监听器"。当任务执行 defer() 方法时,Worker 进程释放回任务池,Triggerer 接管监听:
- 管理 Trigger 实例(如
DateTimeTrigger、FileTrigger) - 持续监听外部事件(时间到达、文件变更、HTTP 回调等)
- 当触发条件满足时,通过 Scheduler 重新调度任务(resume)
- 每个 Trigger 是一个 async 协程,单个 Triggerer 进程可管理数千个并发 Trigger
在包含传感器(Sensor)或异步等待的工作流中,Triggerer 是节省 Worker 资源的关键组件。
组件间的协作关系
执行面
数据面
控制面
读写元数据
UI / REST API
写入 DAG 元数据
查询/创建
DagRun / TaskInstance
推送任务消息
拉取任务
Execution API
获取/写回上下文
API Client
XCom / 变量 / 状态
触发器就绪
重新入队
API Server
Scheduler
DAG Processor
PostgreSQL
元数据库
Redis
消息队列
Worker
Triggerer
Airflow 3.x 的数据访问分为两层:
- 控制面 (API Server、Scheduler、DAG Processor)直接访问元数据库。API Server 处理 UI 和 REST API 请求;Scheduler 通过
create_session()查询和创建 DagRun/TaskInstance;DAG Processor Manager 将解析结果写入数据库。它们是"可信组件",共享数据库连接池。 - 执行面 (Worker、Triggerer)不直接访问数据库。Worker 通过 Execution API(
/execution/端点)与 API Server 通信,获取任务上下文并写回结果;Triggerer Supervisor 通过 API Client(self.client.*)读写 XCom、变量和任务状态。这种隔离确保执行面组件可以在不同网络分区甚至不同集群中运行。
队列是控制面和执行面之间的唯一消息通道:本例中Scheduler 将任务推入 Redis 队列,Worker 从队列拉取执行。
DAG 从提交到执行的完整流程
以 airflow dags trigger sql_toolset_demo 为例,追踪一个 DAG Run 的完整生命周期:
LiteLLM Worker Redis Scheduler PostgreSQL API Server 用户 (CLI/UI) LiteLLM Worker Redis Scheduler PostgreSQL API Server 用户 (CLI/UI) loop Scheduler 调度循环 SQLToolset 直连 sample_db 执行 SQL loop Agent 工具调用循环 POST /dags/sql_toolset_demo/dagRuns 创建 DagRun (state=queued) 查询未调度的 DagRun 创建 TaskInstance (state=scheduled) 推送 execute_workload 消息 拉取任务消息 GET /execution/task_instances/{id} (获取上下文) 返回 TaskInstance 上下文 执行 AgentOperator.execute() POST /v1/chat/completions (Agent 推理) 返回工具调用决策 POST /v1/chat/completions (继续推理) 下一步决策或最终回答 PUT /execution/task_instances/{id} (写回结果 + XCom) 更新 TaskInstance (state=success) 更新 DagRun (state=success)
流程分解为四个阶段:
-
DAG 注册 (由 DAG Processor 完成)
DAG Processor 周期性扫描
/opt/airflow/dags/目录,执行每个.py文件。对于sql_toolset_demo.py,解析出 DAG 对象(dag_id、schedule、task 列表),写入dag、dag_version、task等元数据表。首次注册时 DAG 默认处于is_paused=True状态(由AIRFLOW__CORE__DAGS_ARE_PAUSED_AT_CREATION控制)。 -
触发与调度 (由 API Server + Scheduler 完成)
用户通过 CLI 或 UI 触发 DAG。API Server 在
dag_run表创建一条记录(state=queued,run_type=manual)。Scheduler 的调度循环(默认每秒一次)检测到新的 DagRun,根据 DAG 拓扑结构创建 TaskInstance(state=scheduled),然后将任务封装为 Celery 消息推送到 Redis。 -
任务执行 (由 Worker 完成)
Worker 从 Redis 拉取
execute_workload消息,通过 Execution API 从 API Server 获取 TaskInstance 上下文(包括 DAG 定义、任务参数、上游 XCom 等)。Worker 在子进程中执行AgentOperator.execute():创建 pydantic-ai Agent,连接 LiteLLM,启动推理循环。Agent 根据工具调用结果反复与 LLM 交互,直到生成最终答案。最终结果通过 Execution API 写回,API Server 更新 TaskInstance 状态为 success 并存储 XCom 值。 -
DAG Run 完成
当 DAG 中所有 TaskInstance 都达到终态(success/failed/skipped),API Server 将 DagRun 状态更新为对应终态。对于有依赖关系的多任务 DAG(如 chain_durable_demo),Scheduler 在上游任务成功后才创建下游 TaskInstance,形成级联调度。
CeleryExecutor 与分布式任务执行
CeleryExecutor 是 Airflow 最成熟的分布式执行器。其核心架构依赖三个组件:
- Broker(Redis):任务队列,scheduler 将待执行任务以消息形式推入队列
- Result Backend(PostgreSQL):存储任务执行结果
- Worker(Celery 进程):从队列拉取任务并执行
在本项目中,Redis 7.2 作为消息代理,PostgreSQL 同时作为 Airflow 元数据库和 Celery 结果后端:
yaml
# docker-compose.yaml
AIRFLOW__CORE__EXECUTOR: CeleryExecutor
AIRFLOW__CELERY__RESULT_BACKEND: db+postgresql://airflow:airflow@postgres/airflow
AIRFLOW__CELERY__BROKER_URL: redis://:@redis:6379/0Celery Worker 的健康检查使用 celery inspect ping 命令确认 Worker 进程存活。Worker 启动后注册到 Celery 应用(airflow.providers.celery.executors.celery_executor.app),Scheduler 将任务推送到 Redis 的 default 队列,Worker 监听该队列并拉取执行。
AgentOperator 与 pydantic-ai
AgentOperator 是 apache-airflow-providers-common-ai 提供的核心 Operator,它封装了 pydantic-ai 框架的 Agent 模型。其工作原理:
- 接收用户 prompt 和 system_prompt
- 通过
llm_conn_id连接到 LLM 服务 - 将 Toolset 注册为 pydantic-ai 可调用的工具
- 启动 Agent 循环:LLM 推理 → 决定是否调用工具 → 执行工具 → 返回结果给 LLM → 继续推理或输出最终答案
- 将最终结果写入 XCom
这种设计让 LLM 成为"大脑",Toolset 成为"手脚",实现了自然语言到具体操作的闭环。
Toolset 体系
SQLToolset 基于 sqlglot 实现 SQL 生成和验证。它提供了四个核心工具:
list_tables:列出数据库中的表get_schema:获取表结构定义query:执行 SQL 查询(经 sqlglot 验证安全性)query_description:描述查询结果
HookToolset 将 Airflow 的 Hook(如 S3Hook)包装为 LLM 可调用的工具。
- 通过
allowed_methods限制 LLM 可调用的方法,防止越权操作。工具名自动加上tool_name_prefix前缀,便于 LLM 区分不同来源的工具。
MCPToolset 实现了 Model Context Protocol(MCP)集成。定义了 tools/list(列出可用工具)和 tools/call(调用工具)两个核心方法。支持三种传输方式:
http:基于 StreamableHTTP 的 JSON-RPC(本项目使用)sse:基于 Server-Sent Eventsstdio:基于标准输入输出(适用于本地进程)
LLMOperator 与 XCom 数据传递
LLMOperator 是轻量级的 LLM 调用封装,不绑定任何 Toolset,纯文本输入输出。它支持 Jinja2 模板语法,可以通过 {``{ task_instance.xcom_pull(task_ids='...') }} 拉取上游任务的输出作为 prompt 输入。这使得"Agent 查询 → LLM 总结 → Python 处理"的链式工作流成为可能。
XCom(Cross-Communication)是 Airflow 任务间数据传递的核心机制。在 CeleryExecutor 下,XCom 值存储在 PostgreSQL 的 xcom 表中。AgentOperator 的 execute() 方法将 LLM 的最终输出写入 XCom,下游任务通过 xcom_pull() 读取。
基础设施配置
docker-compose配置
自定义 Airflow 镜像基于官方 apache/airflow:3.2.1,安装了项目所需的全部依赖:
apache-airflow-providers-common-ai>=0.1.0:提供 AgentOperator、LLMOperator、SQLToolset、HookToolset、MCPToolset。实际安装版本为 0.2.0,依赖 pydantic-ai 框架apache-airflow-providers-amazon[aiobotocore]:提供 S3Hook,用于 HookToolset 的 S3 操作sqlglot:SQLToolset 的 SQL 解析和验证引擎,虽为可选依赖但对 SQLToolset 功能是必需的mcp:MCPToolset 的传输层实现,支持 HTTP/SSE/Stdio 三种协议
dockerfile
FROM apache/airflow:3.2.1
USER root
RUN chown -R airflow:0 /home/airflow
USER airflow
RUN pip install --no-cache-dir \
"apache-airflow-providers-common-ai>=0.1.0" \
apache-airflow-providers-postgres \
"apache-airflow-providers-amazon[aiobotocore]" \
psycopg2-binary \
sqlalchemy \
sqlglot \
mcp值得注意的是 sqlglot 和 mcp 两个包不在 common-ai 的核心依赖中,但分别在 SQLToolset 和 MCPToolset 运行时是必需的。缺少 sqlglot 会导致 SQLToolset 导入失败,缺少 mcp 会导致 MCPToolset 运行时报 ImportError。
docker-compose.yaml 定义了 10 个服务,采用 YAML anchor 复用通用配置:
yaml
x-airflow-common: &airflow-common
image: airflow-agent:local
env_file:
- .env
environment: &airflow-common-env
AIRFLOW__CORE__EXECUTOR: CeleryExecutor
AIRFLOW__CORE__AUTH_MANAGER: airflow.providers.fab.auth_manager.fab_auth_manager.FabAuthManager
AIRFLOW__DATABASE__SQL_ALCHEMY_CONN: postgresql+psycopg2://airflow:airflow@postgres/airflow
AIRFLOW__CELERY__RESULT_BACKEND: db+postgresql://airflow:airflow@postgres/airflow
AIRFLOW__CELERY__BROKER_URL: redis://:@redis:6379/0
AIRFLOW__CORE__FERNET_KEY: ${AIRFLOW__CORE__FERNET_KEY}
AIRFLOW__CORE__DAGS_ARE_PAUSED_AT_CREATION: "true"
AIRFLOW__CORE__LOAD_EXAMPLES: "false"
AIRFLOW__CORE__EXECUTION_API_SERVER_URL: "http://airflow-apiserver:8080/execution/"
AIRFLOW__API_AUTH__JWT_SECRET: ${AIRFLOW__API_AUTH__JWT_SECRET:-airflow_jwt_secret}
AIRFLOW__API_AUTH__JWT_ISSUER: ${AIRFLOW__API_AUTH__JWT_ISSUER:-airflow}
AIRFLOW__SCHEDULER__ENABLE_HEALTH_CHECK: "true"
AIRFLOW__COMMON_AI__DURABLE_CACHE_PATH: "file:///tmp/airflow_durable_cache"
_PIP_ADDITIONAL_REQUIREMENTS: ""
volumes:
- ./dags:/opt/airflow/dags
- ./logs:/opt/airflow/logs
- ./plugins:/opt/airflow/plugins
user: "${AIRFLOW_UID:-50000}:0"
extra_hosts:
- "host.docker.internal:host-gateway"extra_hosts: host.docker.internal:host-gateway 是 Linux Docker 环境的关键配置。这使得 Airflow 容器可以通过 http://host.docker.internal:4000 访问宿主机上运行的 LiteLLM 服务。
此外,Airflow 3.x 的 API Server 已从 Flask-AppBuilder(FAB)迁移到 FastAPI + Uvicorn 。FAB 不再作为整个 Web 框架,而是降级为一个可选的 Auth Manager Provider(airflow.providers.fab),仅负责向后兼容的用户管理(登录、角色、权限)。FabAuthManager 通过 get_fastapi_app() 方法将认证路由挂载到 FastAPI 主应用上。另一个可选的 Auth Manager 是 AwsAuthManager(基于 Amazon Verified Permissions)。
yaml
# Auth Manager 配置
AIRFLOW__CORE__AUTH_MANAGER: airflow.providers.fab.auth_manager.fab_auth_manager.FabAuthManagerJWT 认证用于 Execution API 的内部通信(Worker/Triggerer 与 API Server 之间的身份验证)。
环境变量
.env 文件集中管理敏感配置和可变参数:
bash
AIRFLOW_UID=50000
AIRFLOW_GID=0
_AIRFLOW_WWW_USER_USERNAME=airflow
_AIRFLOW_WWW_USER_PASSWORD=airflow
AIRFLOW__CORE__FERNET_KEY=MwNg87tUC16MDC1LE7GH7bKUKJyvmcqMlFoZSi27Dog=
AIRFLOW__DATABASE__SQL_ALCHEMY_CONN=postgresql+psycopg2://airflow:airflow@postgres/airflow
AIRFLOW__CELERY__RESULT_BACKEND=db+postgresql://airflow:airflow@postgres/airflow
AIRFLOW__CELERY__BROKER_URL=redis://redis:6379/0
AIRFLOW__CORE__EXECUTOR=CeleryExecutor
AIRFLOW__CORE__LOAD_EXAMPLES=False
LITELLM_MASTER_KEY=OFgmU5MBxxxxxxxxxxxxxxxyguU=
LITELLM_BASE_URL=http://host.docker.internal:4000/v1
DEFAULT_MODEL=openai:qwen3-coderFernet Key 是 Airflow 加密敏感数据(如连接密码)的对称密钥。LITELLM_MASTER_KEY 是 LiteLLM 代理的认证令牌,在创建 pydanticai_default 连接时作为 conn-password 传入,AgentOperator 调用 LLM 时自动携带此密钥。
PostgreSQL
PostgreSQL 16 承担双重角色Airflow 元数据库和业务示例数据库。Airflow 元数据库(airflow database)存储 DAG 定义、任务实例、XCom、连接、变量等所有运行时状态。CeleryExecutor 也使用此数据库作为 Result Backend。
sample_db 是独立的业务数据库,包含两张表:
sql
-- customers 表:50 条记录
CREATE TABLE customers (
id SERIAL PRIMARY KEY,
name VARCHAR(100) NOT NULL,
email VARCHAR(255) NOT NULL,
city VARCHAR(100) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- orders 表:155 条记录
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
customer_id INTEGER NOT NULL REFERENCES customers(id),
product VARCHAR(200) NOT NULL,
amount DECIMAL(10, 2) NOT NULL,
order_date DATE NOT NULL
);示例数据覆盖 10 个中国城市客户和 30+ 种电子产品订单,时间跨度 2024-2025 年。SQLToolset 的 allowed_tables 参数限制 LLM 只能查询这两张表。
MinIO
MinIO 作为 S3 兼容对象存储,为 HookToolset 提供 S3 操作环境。端口映射为 9003(API)和 9004(Console),避开已被 rustfs-server 占用的 9000-9001 端口。
yaml
minio:
image: minio/minio
command: server /data --console-address ":9001"
environment:
MINIO_ROOT_USER: minioadmin
MINIO_ROOT_PASSWORD: minioadmin
ports:
- "9003:9000"
- "9004:9001"sample-bucket 通过 mc(MinIO Client)创建,包含一个示例数据文件 sample-data.txt。Airflow 连接 minio_s3 配置了内部端点 http://minio:9000(Docker 网络内通信),S3Hook 通过此连接访问 MinIO。
LiteLLM 代理层
LiteLLM 作为统一的大语言模型代理服务运行在宿主机 :4000 端口。Airflow 容器通过 host.docker.internal:4000 访问 LiteLLM。连接配置:
conn_id: pydanticai_default
conn_type: pydanticai
conn_host: http://host.docker.internal:4000/v1
conn_password: <LITELLM_MASTER_KEY>
conn_extra: {"model": "openai:qwen3-coder"}conn_extra 中的 model 字段使用 openai: 前缀,告诉 pydantic-ai 使用 OpenAI 兼容协议(LiteLLM 暴露 OpenAI 兼容 API)。qwen3-coder 是默认模型,在四个 DAG 的实际执行中表现良好 -- 能够正确调用工具并生成结构化的工具调用参数。
初始化流程
airflow-init 服务使用 user: "0:0"(root 用户)运行,以获得安装系统包和执行数据库操作的权限。初始化脚本按顺序完成六个步骤:
bash
# Step 1: 数据库迁移
/entrypoint airflow db migrate
# Step 2: 创建管理员用户
/entrypoint airflow users create --username airflow --password airflow ...
# Step 3: 安装 postgresql-client 并创建 sample_db
apt-get install -y postgresql-client
PGPASSWORD=airflow psql -h postgres -U airflow -d postgres -c "CREATE DATABASE sample_db;"
# Step 4: 加载示例数据
PGPASSWORD=airflow psql -h postgres -U airflow -d sample_db -f /init-scripts/02-sample-data.sql
# Step 5: 创建 Airflow 连接
/entrypoint airflow connections add pydanticai_default --conn-type pydanticai \
--conn-host http://host.docker.internal:4000/v1 \
--conn-password "${LITELLM_MASTER_KEY}" \
--conn-extra '{"model": "openai:qwen3-coder"}'
# ... sample_db, minio_s3, mcp_default
# Step 6: MinIO bucket 创建注意使用 /entrypoint airflow 而非直接 airflow 命令。在 user: "0:0" 环境下,root 用户的 PATH 不包含 airflow 的安装路径,必须通过 /entrypoint 包装器执行,该包装器会切换到 airflow 用户并正确设置环境。
Dag开发与AgentOperator 实战
SQL 查询 Agent
展示 AgentOperator结合SQLToolset 的基本用法
python
from airflow.providers.common.ai.operators.agent import AgentOperator
from airflow.providers.common.ai.toolsets.sql import SQLToolset
from airflow.decorators import dag
from datetime import datetime
@dag(
dag_id="sql_toolset_demo",
start_date=datetime(2025, 1, 1),
schedule=None,
catchup=False,
tags=["ai-agent", "sql"],
)
def sql_agent_demo():
AgentOperator(
task_id="ask_question",
prompt="查询消费金额最高的前5名客户及其总消费,用中文回答",
llm_conn_id="pydanticai_default",
system_prompt="你是一个数据分析助手。使用可用的数据库工具来探索表结构并回答问题。",
toolsets=[
SQLToolset(
db_conn_id="sample_db",
allowed_tables=["customers", "orders"],
max_rows=20,
)
],
)
sql_agent_demo()执行日志揭示了 LLM 的推理过程:
Tool call: list_tables → 发现 customers, orders 表
Tool call: get_schema (customers) → 获取客户表结构
Tool call: get_schema (orders) → 获取订单表结构
Tool call: query → 执行 SQL 查询
LLM run complete: requests=5, tool_calls=4, input_tokens=3669, output_tokens=222
Tool call sequence: list_tables -> get_schema -> get_schema -> query这个调用序列完美复现了人类数据分析师的工作流程:先看有哪些表,再了解表结构,最后构造 SQL 查询。LLM 共发起 5 次 LLM 请求(含工具调用决策和最终回答),4 次工具调用,总耗时约 27 秒。
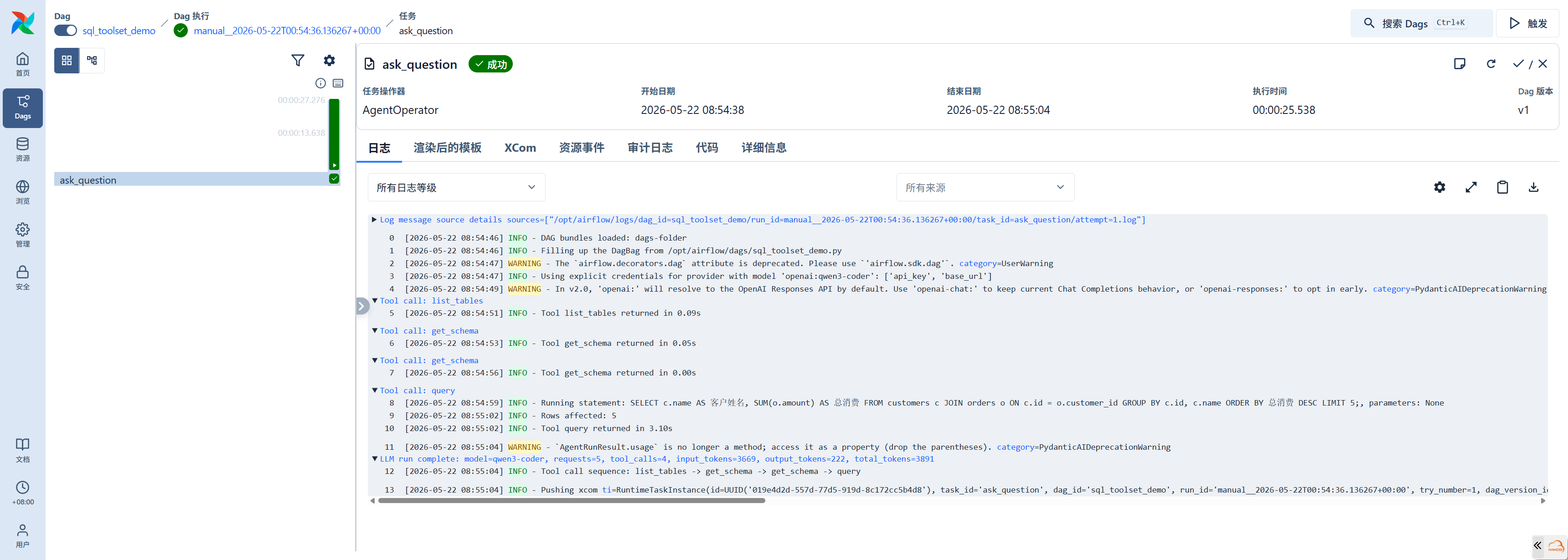
SQLToolset 的 allowed_tables 参数是安全边界 -- LLM 只能查询白名单内的表。max_rows=20 限制查询返回行数,防止大量数据传输影响性能。底层依赖 sqlglot 对 LLM 生成的 SQL 进行安全验证。
S3 浏览 Agent
展示 HookToolset 将 Airflow S3Hook 包装为 LLM 工具:
python
from airflow.providers.common.ai.operators.agent import AgentOperator
from airflow.providers.common.ai.toolsets.hook import HookToolset
from airflow.providers.amazon.aws.hooks.s3 import S3Hook
from airflow.decorators import dag
from datetime import datetime
@dag(
dag_id="hook_toolset_demo",
start_date=datetime(2025, 1, 1),
schedule=None,
catchup=False,
tags=["ai-agent", "hook"],
)
def hook_agent_demo():
s3_hook = S3Hook(aws_conn_id="minio_s3")
AgentOperator(
task_id="s3_explorer",
prompt="列出 sample-bucket 中的所有文件,读取其中一个文件的内容,用中文描述文件内容",
llm_conn_id="pydanticai_default",
system_prompt="你是一个数据探索助手。使用 S3 工具来浏览和读取文件。",
toolsets=[
HookToolset(
s3_hook,
allowed_methods=["list_keys", "read_key", "check_for_key"],
tool_name_prefix="s3_",
)
],
)
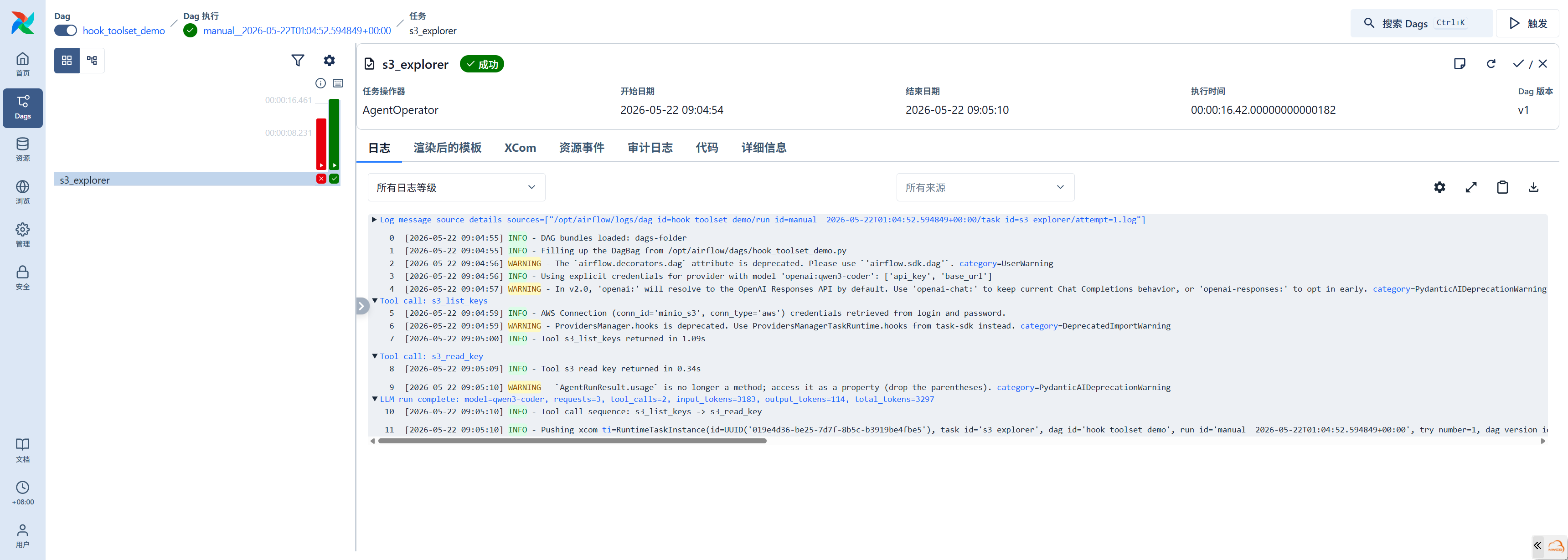
hook_agent_demo()执行日志:
Tool call: s3_list_keys → 列出 sample-bucket 中的文件
Tool call: s3_read_key → 读取文件内容
LLM run complete: requests=3, tool_calls=2, input_tokens=3183, output_tokens=114
Tool call sequence: s3_list_keys -> s3_read_keyLLM 的行为简洁高效:先列出文件,再读取内容。allowed_methods 将 LLM 可调用的 S3Hook 方法限制在读取操作范围内,防止 LLM 意外删除或修改数据。tool_name_prefix="s3_" 为工具名添加前缀,在多 Toolset 场景下避免命名冲突。
MCP 工具调用 Agent
展示 MCPToolset 集成外部 MCP Server
python
from airflow.providers.common.ai.operators.agent import AgentOperator
from airflow.providers.common.ai.toolsets.mcp import MCPToolset
from airflow.decorators import dag
from datetime import datetime
@dag(
dag_id="mcp_toolset_demo",
start_date=datetime(2025, 1, 1),
schedule=None,
catchup=False,
tags=["ai-agent", "mcp"],
)
def mcp_agent_demo():
AgentOperator(
task_id="ask_mcp",
prompt="请告诉我当前时间,然后回显一条消息:Airflow MCP 集成测试成功",
llm_conn_id="pydanticai_default",
system_prompt="你是一个助手。使用可用的 MCP 工具来完成任务。",
toolsets=[
MCPToolset(mcp_conn_id="mcp_default", tool_prefix="mcp_")
],
)
mcp_agent_demo()执行日志:
Tool call: mcp__get_current_time → 获取当前时间
Tool call: mcp__echo → 回显消息
LLM run complete: requests=2, tool_calls=2, input_tokens=791, output_tokens=89
Tool call sequence: mcp__get_current_time -> mcp__echoMCPToolset 在初始化时通过 mcp_conn_id 获取 MCP Server 的连接信息,使用 MCPServerStreamableHTTP(http transport)建立通信。工具名自动添加 mcp_ 前缀(双下划线,因为 tool_prefix="mcp_" + MCP Server 注册的工具名),在日志中清晰可辨。
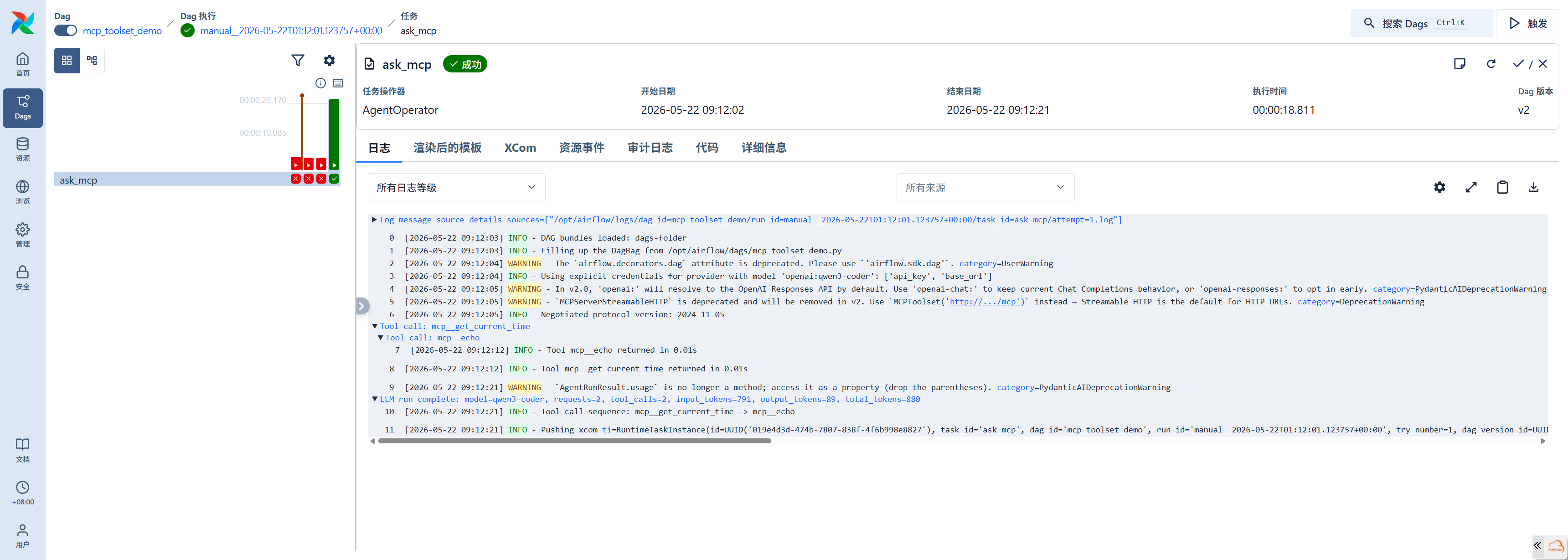
MCP 连接配置为 transport http,对应 pydantic-ai 的 MCPServerStreamableHTTP 实现。注意不能使用 streamable-http 字符串,Airflow MCPHook 只识别 http、sse、stdio 三种 transport 标识。
多步骤链式工作流
最复杂的 DAG,展示 AgentOperator + LLMOperator + 普通 @task 的链式编排:
{{ task_instance.xcom_pull(task_ids='query_agent') }} 是 Airflow 的 Jinja2 模板引擎,在任务执行前由 Airflow 渲染,和 LLMOperator 无关。渲染发生在 Worker 进程中,早于 Operator 的
execute()方法调用。流程是:
- Airflow 从数据库读取 TaskInstance 的模板字段(
prompt、bash_command等)- Jinja2 引擎执行模板渲染:
{``{ task_instance.xcom_pull(task_ids='query_agent') }}→ 替换为实际 XCom 值- 渲染后的纯文本字符串传给
LLMOperator.execute()- LLMOperator 拿到的已经是一段包含原始数据的完整文本
所有 Airflow Operator 的模板参数(如
BashOperator.bash_command、EmailOperator.html_content)都支持 Jinja2 模板语法。{``{ }}是 Jinja2 的表达式定界符,task_instance.xcom_pull()是 Airflow 暴露给模板的内置方法
python
from airflow.providers.common.ai.operators.agent import AgentOperator
from airflow.providers.common.ai.operators.llm import LLMOperator
from airflow.providers.common.ai.toolsets.sql import SQLToolset
from airflow.decorators import dag, task
from datetime import datetime
@dag(
dag_id="chain_durable_demo",
start_date=datetime(2025, 1, 1),
schedule=None,
catchup=False,
tags=["ai-agent", "chain", "durable"],
)
def chain_durable_demo():
# Step 1: Agent 查询数据库获取原始数据
query_agent = AgentOperator(
task_id="query_agent",
prompt="查询每个产品的总销售额,按销售额从高到低排序,返回前5个产品",
llm_conn_id="pydanticai_default",
system_prompt="你是数据分析师,使用 SQL 工具回答问题。",
toolsets=[
SQLToolset(
db_conn_id="sample_db",
allowed_tables=["customers", "orders"],
max_rows=20,
)
],
durable=False,
)
# Step 2: LLM 总结 Agent 输出
summarize = LLMOperator(
task_id="summarize",
prompt="{{ task_instance.xcom_pull(task_ids='query_agent') }}\n\n请基于以上查询结果,用中文总结关键发现。",
llm_conn_id="pydanticai_default",
)
# Step 3: 普通任务处理最终结果
@task
def report(**kwargs):
ti = kwargs["ti"]
analysis = ti.xcom_pull(task_ids="summarize")
print(f"=== 销售报告 ===\n{analysis}")
return analysis
query_agent >> summarize >> report()
chain_durable_demo()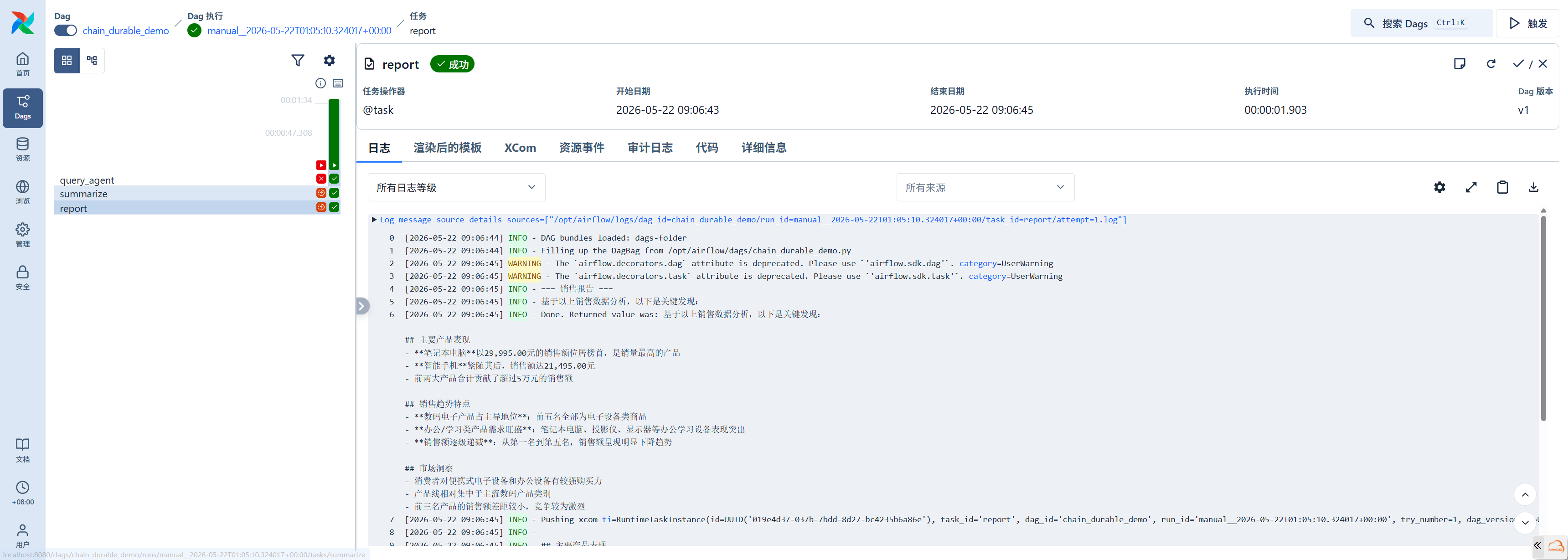
执行过程涉及三个任务,通过 XCom 传递数据:
query_agent(27s):
shell
Tool call: list_tables → get_schema → get_schema → query
LLM run complete: requests=5, tool_calls=4, input_tokens=3898, output_tokens=431summarize(LLMOperator):
shell
LLM run complete: requests=1, tool_calls=0, input_tokens=160, output_tokens=202report(@task):从 XCom 拉取 summarize 的输出并打印。
数据流:query_agent 将 SQL 查询结果写入 XCom → summarize 通过 Jinja2 模板 {``{ task_instance.xcom_pull(task_ids='query_agent') }} 拉取上游输出,LLM 生成中文总结 → report 通过 ti.xcom_pull(task_ids="summarize") 获取总结并打印。
注意 durable=False 的设置。durable=True 启用 Airflow 的 Agent 执行缓存机制(模型响应持久化),需要配置 AIRFLOW__COMMON_AI__DURABLE_CACHE_PATH。当前版本此功能需要额外的目录配置和 volume 挂载。
故障排查
DAG 首次批量触发时,3 个 DAG 失败,仅 sql_toolset_demo 成功。
NoSuchBucket: An error occurred (NoSuchBucket) when calling the ListObjectsV2 operation:
The specified bucket does not exist原因:init 脚本使用 curl -X PUT "http://minio:9000/sample-bucket" 创建 bucket,但 MinIO 的 bucket 创建需要 S3 兼容的签名认证,普通 curl 无法完成。修复:使用 mc(MinIO Client)在容器内执行 mc mb myminio/sample-bucket。
ImportError: MCP support requires the `mcp` package.
Install it with: pip install "pydantic-ai-slim[mcp]"安装 mcp 包后失败:
Expected response header Content-Type to contain 'text/event-stream', got 'application/json'原因:init 脚本中 MCP 连接配置了 transport: "streamable-http",但 Airflow MCPHook 只识别 http、sse、stdio。改为 sse 后又因为 MCP Server 返回 application/json 而非 text/event-stream 失败。最终改为 http transport(MCPServerStreamableHTTP)。
ValueError: durable=True requires [common.ai] durable_cache_path to be set.
Example: durable_cache_path = file:///tmp/airflow_durable_cache原因:durable=True 启用模型响应缓存机制,需要配置缓存目录。快速修复:将 durable=True 改为 durable=False。正式环境可在 docker-compose.yaml 中配置 AIRFLOW__COMMON_AI__DURABLE_CACHE_PATH: "file:///tmp/airflow_durable_cache" 并挂载 volume。
参考文档
-
Airflow 3.x Architecture --- API Server、Scheduler、DAG Processor、Worker、Triggerer 五大组件架构
-
Execution API --- Worker/Triggerer 通过 Execution API 与 API Server 通信的端点定义
-
apache-airflow-providers-common-ai 0.2.0 --- AgentOperator、LLMOperator、Toolset(SQL/Hook/MCP)官方文档
-
Airflow AI Blog Post --- common-ai provider 的设计理念和功能介绍
-
pydantic-ai-slim 1.100.0 --- AgentOperator 底层使用的 AI Agent 框架