系列简介 :从零搭建一个多 Agent AI 助手,覆盖原理、实现、部署全链路。不讲空话,每篇都有可运行的代码。
项目地址 :github.com/CodeMomentY...
本篇目标:给 Agent 加上记忆能力------短期对话历史 + 长期 RAG 知识检索,让它不再"每次见面都是陌生人"。

前言
大家好,我是一名前端工程师。都说前端"已死",那与其担心被 AI 替代,不如打入敌人内部,于是我开始折腾 Agent 开发。
折腾下来发现,Agent 的核心不是算法,而是"工程能力"(怎么设计架构、怎么串联服务、怎么把 LLM 的能力落地成产品)。这些恰好是我们擅长的事。
这个系列记录我从零搭建多 Agent 系统的完整过程。只聊技术知识和设计思路,代码交给 AI 写。如果你也想从应用层切入 AI,希望这个系列对你有帮助。
读完本篇你将学到:
- Agent 为什么"没记性",记忆该怎么分层设计;
- 短期记忆:用 JSON 文件持久化每个 session 的对话历史;
- 长期记忆:用 ChromaDB 做向量存储 + 关键词检索,让 Agent 能"回忆"跨会话的内容;
背景与动机
上一篇我们把 Agent 搬进了浏览器,有了对话界面和流式输出。但你试几轮就会发现一个问题:换个会话,Agent 就把你忘了。
比如:你跟它说"我叫小明,喜欢吃火锅",下一轮问"我喜欢吃什么",它一脸茫然。
这不是 Bug,而是 LLM 的本质特性------无状态。每次调用 LLM 都是一次全新的对话,它不会自动记住上一轮说了什么。所谓的"记忆",全靠我们把历史消息塞进 Prompt 里。
但塞多少合适?全塞进去会爆 Token 限制(大部分模型 4K-128K),而且历史越长,LLM 越容易"走神"------注意力被无关信息分散。
所以我们需要分层记忆:近期的完整保留,久远的按相关性检索。
核心概念
两种记忆的分工
| 短期记忆 | 长期记忆 | |
|---|---|---|
| 存什么 | 当前 session 的完整对话历史 | 所有 session 的对话摘要 + 知识库 |
| 怎么存 | JSON 文件(按 session_id 隔离) | ChromaDB 向量库 |
| 怎么取 | 全量加载,拼到 messages 里 | 按当前问题做相似度检索,取 top_k |
| 生命周期 | 会话内有效 | 永久保留 |
| 类比 | 工作记忆(你正在聊的话题) | 长期记忆(你记得去年聊过的事) |
RAG 是什么?
RAG = Retrieval Augmented Generation,拆开来看:
- Retrieval(检索):从知识库里找到和当前问题相关的内容;
- Augmented(增强):把检索到的内容塞进 Prompt,作为上下文;
- Generation(生成) :LLM 基于增强后的 Prompt 生成回答(一句话:先查资料,再回答问题);
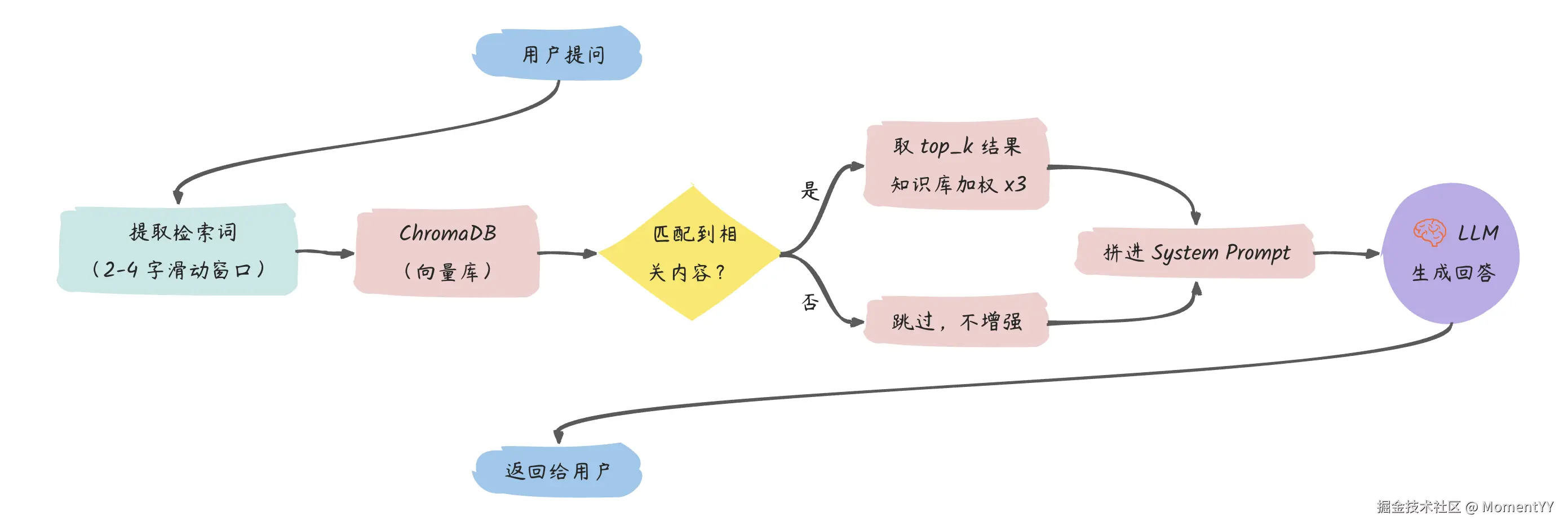
整体数据流
把短期记忆和长期记忆结合起来,每次请求的完整流程是:
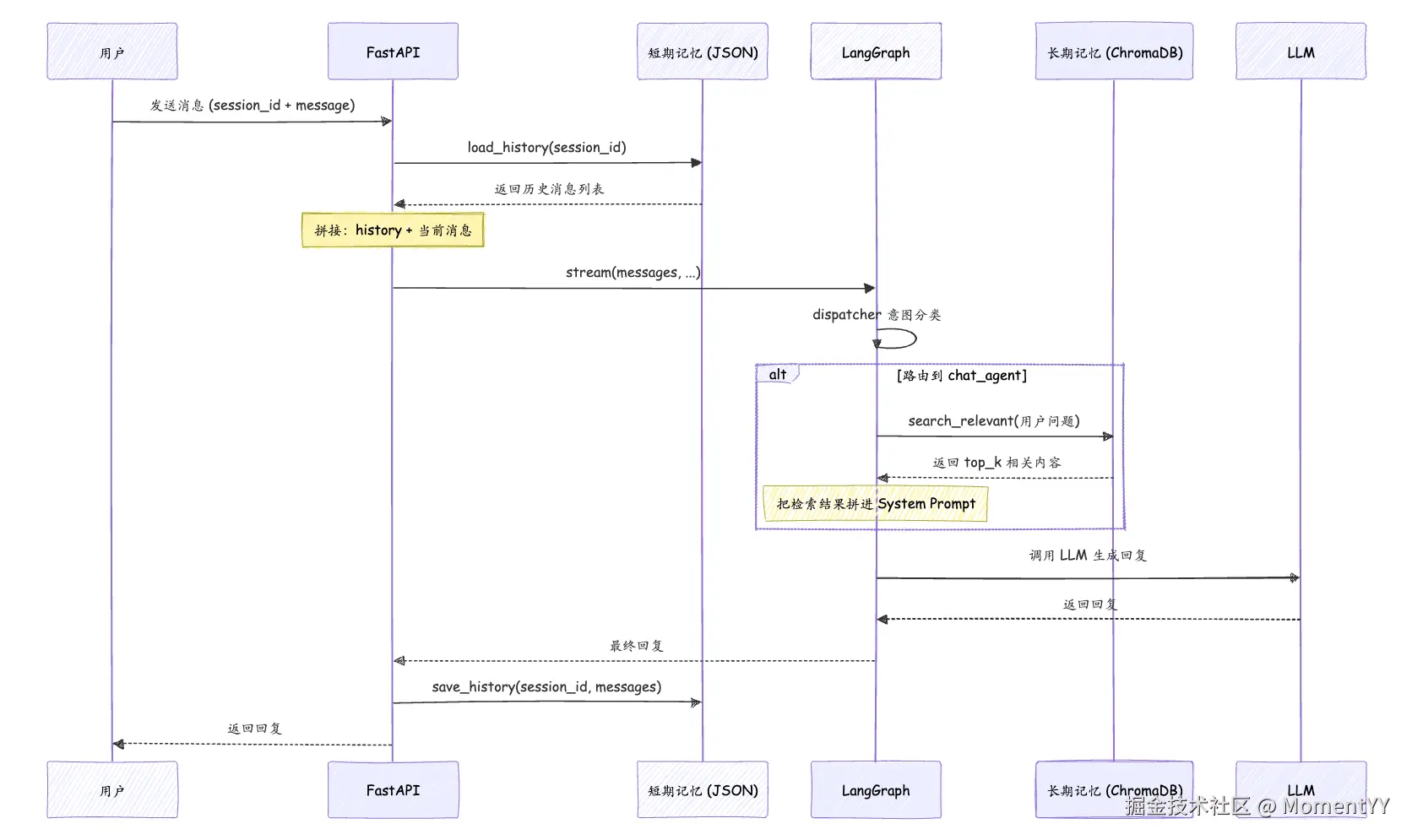
动手实现
Step 1:短期记忆(JSON 文件存 session)
最简单的方案:每个 session_id 对应一个 JSON 文件,里面存序列化后的 LangChain 消息列表。
python
"""
对话历史管理
每个 session_id 对应一个 JSON 文件
生产级会用 Redis / PostgreSQL,但学习阶段 JSON 文件最直观
"""
import os, json
from langchain_core.messages import HumanMessage, AIMessage, ToolMessage
MEMORY_DIR = "data/memory"
def load_history(session_id: str) -> list:
"""加载某个 session 的对话历史"""
file_path = _get_session_file(session_id)
if not os.path.exists(file_path):
return []
with open(file_path, "r", encoding="utf-8") as f:
data_list = json.load(f)
return [_deserialize_message(d) for d in data_list]
def save_history(session_id: str, messages: list):
"""保存对话历史(覆盖写入)"""
file_path = _get_session_file(session_id)
data_list = [_serialize_message(msg) for msg in messages]
with open(file_path, "w", encoding="utf-8") as f:
json.dump(data_list, f, ensure_ascii=False, indent=2) 序列化的关键是把 LangChain 的消息对象转成 dict,存 type(HumanMessage / AIMessage / ToolMessage)和 content,加载时再还原回来。
在 API 层的使用方式:
python
# 每次请求前:加载历史 → 拼到 state 里
history = load_history(session_id)
all_messages = history + [HumanMessage(content=request.message)]
# Agent 执行完后:追加新消息 → 保存
history.append(HumanMessage(content=request.message))
history.append(AIMessage(content=reply))
save_history(session_id, history)这样同一个 session 内的对话就能连贯了------Agent 知道你上一句说了什么,结合上下文信息来回答你。
Step 2:长期记忆(ChromaDB 向量库)
短期记忆解决了"本次会话内的连贯性",但跨会话就失效了。长期记忆用向量库来解决:把每轮对话存进去,下次提问时按相似度检索。
python
"""
向量记忆存储(RAG 长期记忆)
使用 ChromaDB 存储对话历史的向量表示
"""
import time
import chromadb
from pathlib import Path
CHROMA_PATH = Path("data/chroma")
_client = chromadb.PersistentClient(path=str(CHROMA_PATH))
_collection = _client.get_or_create_collection(
name="conversations",
metadata={"hnsw:space": "cosine"}, # 余弦相似度
)
def save_conversation(session_id: str, user_message: str, ai_reply: str):
"""保存一轮对话到向量库"""
doc = f"用户:{user_message}\n助手:{ai_reply}"
doc_id = f"{session_id}_{int(time.time() * 1000)}"
_collection.add(
documents=[doc],
metadatas=[{"session_id": session_id, "timestamp": str(int(time.time()))}],
ids=[doc_id],
)ChromaDB 会自动用内置的 embedding 模型把文本转成向量存储。查询时也是先把 query 转向量,再做余弦相似度匹配。
Step 3:检索------中文场景的坑
理论上,检索应该用向量相似度来匹配。但实际跑下来发现一个问题:ChromaDB 默认的 Embedding 模型(all-MiniLM-L6-v2)对中文支持很差。
比如你存了"北京今天晴天 25°C",查"北京天气"可能检索不到------因为英文模型对中文语义的理解很有限。
解决方案有两条路:
- 换中文 Embedding 模型(如 text2vec-chinese、bge-base-zh),但需要额外下载模型,部署成本高;
- 关键词检索兜底:用滑动窗口提取 2-4 字的 n-gram,做字面匹配;
这里我们关键词检索兜底,学习阶段够用,而且不依赖额外模型:
python
def search_relevant(query: str, top_k: int = 3) -> list[str]:
"""根据当前问题检索相关内容(关键词匹配兜底)"""
if _collection.count() == 0:
return []
results_with_score = []
all_data = _collection.get(include=["documents", "metadatas"])
query_terms = _extract_terms(query) # 提取检索词
for doc, meta in zip(all_data["documents"], all_data["metadatas"]):
score = 0
for term in query_terms:
if term in doc.lower():
score += len(term)
if score > 0:
# 知识库内容加权(优先级更高)
if meta and meta.get("session_id") == "knowledge":
score *= 3
results_with_score.append((score, doc))
results_with_score.sort(key=lambda x: x[0], reverse=True)
return [doc for _, doc in results_with_score[:top_k]]
def _extract_terms(text: str) -> list[str]:
"""从文本中提取检索词(2-4字滑动窗口 + 英文单词)"""
clean = ''.join(c for c in text if c.isalnum() or c in '的了吗呢是')
terms = set()
for size in [2, 3, 4]:
for i in range(len(clean) - size + 1):
term = clean[i:i+size]
if term not in ('的了', '了吗', '吗呢', '是的'):
terms.add(term)
# 英文单词也加入
import re
for w in re.findall(r'[a-zA-Z]+', text):
if len(w) >= 2:
terms.add(w.lower())
return list(terms)这个方案不完美,但在中文场景下比默认的向量检索靠谱得多。后续如果要提升效果,换一个中文 Embedding 模型就行,检索接口不用改。
Step 4:把 RAG 接入 chat_agent
chat_agent 在回答之前,先用当前问题去向量库检索相关内容,找到了就拼进 System Prompt:
python
def chat_agent_node(state):
"""聊天 Agent:检索相关历史 + 调 LLM 回答"""
# 取最后一条用户消息
last_user_msg = ""
for msg in reversed(state["messages"]):
if hasattr(msg, "type") and msg.type == "human":
last_user_msg = msg.content
break
# RAG 检索
prompt = CHAT_PROMPT
if last_user_msg:
relevant = search_relevant(last_user_msg, top_k=3)
if relevant:
memory_context = "\n\n".join(relevant)
prompt += f"\n\n【重要】以下是相关的参考资料和历史对话,请优先基于这些内容回答:\n\n{memory_context}"
messages = [SystemMessage(content=prompt)] + list(state["messages"])
response = invoke_llm(messages)
return {"messages": [response]}逻辑很简单:有相关内容就塞进去,没有就正常回答。LLM 会自动判断检索到的内容是否有用。
Step 5:知识库导入
除了对话历史,我们还可以主动往向量库里灌知识。比如把公司文档、产品说明喂进去,Agent 就能回答相关问题。
导入时用 session_id="knowledge" 作为标识,检索时对知识库内容加权(×3),优先返回:
python
# 导入知识
save_conversation(
session_id="knowledge",
user_message="项目用了哪些技术栈?",
ai_reply="项目前端用 Vue3 + TypeScript,后端用 FastAPI + LangGraph,向量库用 ChromaDB..."
)
# 检索时知识库内容权重更高
if meta.get("session_id") == "knowledge":
score *= 3当我们提问内容中有关键词,就会触发 RAG 检索,匹配到的信息用来丰富上下文,然后再塞给 LLM 分析总结------这就是 RAG 的魅力。
Step 6:验证效果
用 curl 快速验证:
bash
# 第一轮:告诉 Agent 信息
curl -X POST /api/chat -d '{"message": "我叫小明,最喜欢吃火锅", "session_id": "test-1"}'
# → "好的小明,记住了!火锅确实好吃。"
# 第二轮:同一个 session,Agent 记得
curl -X POST /api/chat -d '{"message": "我喜欢吃什么?", "session_id": "test-1"}'
# → "你之前说最喜欢吃火锅!"
# 第三轮:换一个 session,短期记忆失效,但长期记忆能检索到
curl -X POST /api/chat -d '{"message": "小明喜欢吃什么?", "session_id": "test-2"}'
# → "根据之前的对话记录,小明最喜欢吃火锅。"在 Web 界面上的效果:
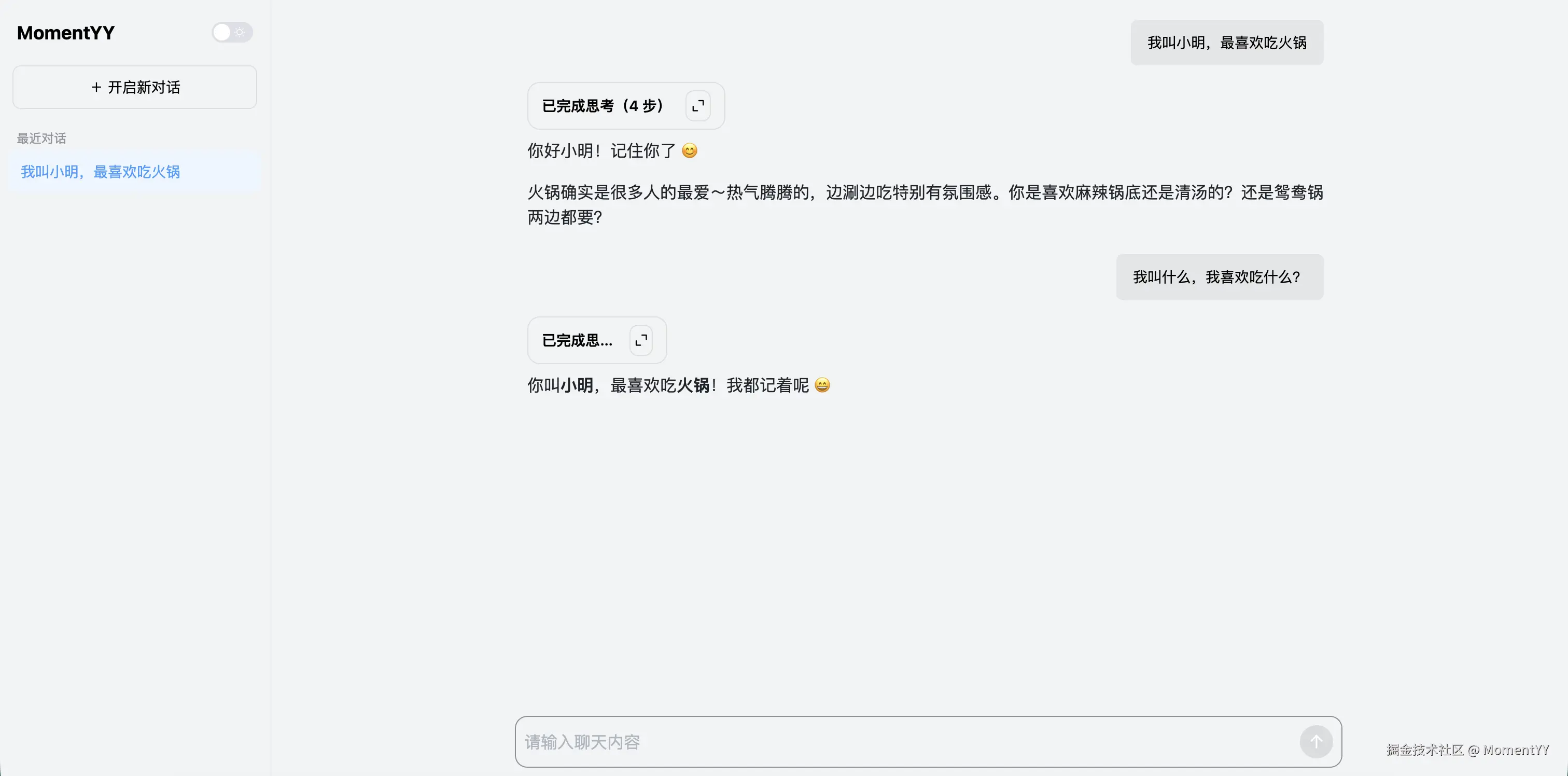
刨根问底
| 序号 | 问题 |
|---|---|
| 1️⃣ | Q:为什么不直接把所有历史都塞进 Prompt? |
| A:Token 限制 + 噪声问题。假设每轮对话 200 token,聊 50 轮就是 10K token,再加上 System Prompt 和工具描述,很容易超限。而且无关的历史会分散 LLM 的注意力,回答质量反而下降。 | |
| 2️⃣ | Q:ChromaDB 默认 embedding 对中文效果怎么样? |
| A:不太行。默认用的 all-MiniLM-L6-v2 是英文模型,中文语义理解很弱。生产环境建议换 bge-base-zh 或 text2vec-chinese。我们用关键词检索兜底,学习阶段够用。 | |
| 3️⃣ | Q:短期记忆为什么用 JSON 不用 Redis? |
| A:学习阶段追求直观可调试------打开文件就能看到完整对话历史,方便排查问题。生产环境肯定要换 Redis 或数据库,支持过期、并发、持久化。 |
本篇小结
- LLM 本身无状态,"记忆"全靠工程手段实现;
- 短期记忆 (JSON 文件)解决会话内连贯性,长期记忆(ChromaDB)解决跨会话检索;
- RAG 的本质是"先查资料再回答",把检索结果塞进 Prompt 就行;
- 中文 embedding 是个坑,关键词检索是务实的兜底方案;
写在最后
记忆是 Agent 从"工具"变成"助手"的关键一步。一个能记住你偏好的 Agent,和一个每次都要重新自我介绍的 Agent,体验差距是巨大的。
但记忆也带来了新问题:存什么、存多久、什么时候该忘记?这些都是工程上需要持续优化的点。目前我们的方案够用,但离"好用"还有距离------比如对话摘要压缩、记忆淘汰策略、多用户隔离等,后续有机会再聊,感兴趣的小伙伴也可以慢慢摸索。
我们这个系列最关键还是了解 Agent 核心构建过程和设计思路,真正企业级产品针对各个技术点会有更加完善的解决方案。
下一篇预告:Agent 现在有了记忆,但它的能力还是被我们手写的几个工具限制住了。下一篇是系列完结篇,最后聊聊 MCP(Model Context Protocol),让 Agent 能调用整个开放工具生态,顺便回顾整个系列的全景架构。