一、SSD 是什么?
SSD 全称:
- SSD: Single Shot MultiBox Detector
是经典的:
text
One-Stage(单阶段)目标检测算法核心特点:
text
一次前向传播
直接完成:
分类
定位即:
text
Single Shot不需要:
- Proposal
- RoI Pooling
因此速度很快。
二、目标检测发展背景
SSD 在检测历史中的位置非常重要。
1. Two-Stage Detector
代表:
- R-CNN
- Fast R-CNN
- Faster R-CNN
流程:
text
先生成候选框
→ 再分类优点:
- 精度高
缺点:
- 慢
2. One-Stage Detector
代表:
- YOLO
- SSD
流程:
text
直接预测所有框优点:
- 快
缺点:
- 小目标较弱
三、SSD 的核心思想
SSD 本质:
text
多尺度 Feature Map
+
Anchor机制
+
Dense Prediction四、SSD 的整体结构
整体流程:
text
输入图片
↓
Backbone提特征
↓
多个Feature Map
↓
每层生成Anchor
↓
卷积预测:
分类
回归
↓
NMS
↓
最终结果五、SSD 的 Backbone
经典 Backbone
原论文使用:
- VGG16
但:
text
去掉FC层原因:
FC 会:
text
丢失空间信息检测任务需要:
text
位置感知因此 SSD:
text
全卷积化六、Feature Map 多尺度检测
这是 SSD 最大创新之一。
为什么需要多尺度?
目标大小不同:
- 小目标
- 大目标
例如:
text
远处人脸
近处汽车尺度差异巨大。
SSD 做法
在不同层上检测。
SSD300 典型 Feature Map
| 层 | Feature Size |
|---|---|
| conv4_3 | 38×38 |
| conv7 | 19×19 |
| conv8_2 | 10×10 |
| conv9_2 | 5×5 |
| conv10_2 | 3×3 |
| conv11_2 | 1×1 |
浅层 vs 深层
浅层
特点:
text
分辨率高
细节丰富适合:
text
小目标深层
特点:
text
语义强适合:
text
大目标七、SSD 没有 FPN
SSD:
text
没有真正FPN只是:
text
不同层分别检测没有:
text
跨层融合FPN 和 SSD 的区别
SSD
text
多层单独检测FPN
text
高层语义
+
低层分辨率
融合因此:
FPN 小目标能力更强。
八、SSD 的 Anchor 机制
这是 SSD 核心。
1. 什么是 Anchor?
Anchor:
text
预设框模板不是直接预测 bbox。
而是:
text
在Anchor基础上修正2. Feature Map 每个点生成多个 Anchor
例如:
text
38×38 Feature Map每个点:
生成:
- 小框
- 大框
- 横向框
- 纵向框
例如:
text
4~6个Anchor3. Anchor 的中心
Feature Map:
text
每个位置对应:
text
原图一个感受野中心Anchor 中心:
放在这里。
4. Anchor 的尺度
每层定义:
text
scale浅层:
text
小Anchor深层:
text
大Anchor5. Aspect Ratio
SSD 使用:
| ratio |
|---|
| 1:1 |
| 2:1 |
| 1:2 |
| 3:1 |
| 1:3 |
适应不同目标形状。
九、SSD 的 Dense Prediction
SSD 本质:
text
密集预测即:
text
Feature Map每个位置都预测十、SSD 与 YOLOv1 的区别
YOLOv1
显式 Grid
text
7×7每个 Grid:
直接预测 bbox。
SSD
Feature Map 网格
text
隐式Grid每个位置:
text
多个Anchor预测:
text
Anchor修正量十一、SSD 的预测过程
每个 Anchor 预测:
1. 分类
预测:
text
类别概率例如:
- dog
- cat
- person
- background
2. 回归
预测:
text
dx
dy
dw
dh即:
- 中心偏移
- 宽高缩放
十二、回归本质
SSD:
text
不直接预测绝对坐标而是:
text
预测Anchor偏移编码公式
Anchor:
text
(xa, ya, wa, ha)GT:
text
(x, y, w, h)训练目标:
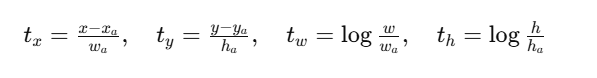
解码公式
推理时:
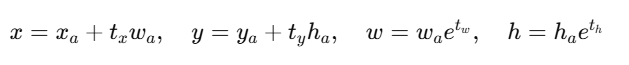
恢复真实框。
十三、SSD 的 Head
SSD Head:
本质:
text
卷积预测器通常:
text
3×3 Conv直接输出:
- 分类
- 回归
举例
假设:
text
38×38每点:
text
4个Anchor类别:
text
21类分类输出通道
4x21=84
输出:
text
38×38×84回归输出通道
4x4=16
输出:
text
38×38×16十四、SSD 为什么预测框数量巨大?
SSD300:
总 Anchor 数:
text
8732远大于:
- YOLOv1
的:
text
98个框为什么?
因为:
text
Dense Detection需要:
text
高空间覆盖率十五、正负样本匹配
训练时:
必须知道:
text
哪个Anchor负责哪个GT使用 IoU
正样本
text
IoU > 0.5负样本
text
IoU < 0.5强制匹配
每个 GT:
text
至少匹配一个Anchor即使:
text
IoU不够也强制分配最佳 Anchor。
十六、SSD Loss
总损失:
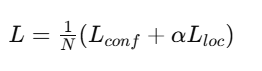
1. 分类 Loss
通常:
text
Cross Entropy2. 回归 Loss
通常:
text
Smooth L1 Loss比 L2 更稳定。
十七、Hard Negative Mining
SSD 极其重要机制。
为什么需要?
8732 个 Anchor:
绝大多数:
text
都是背景例如:
text
8700负样本
30正样本SSD 做法
只保留:
text
最难负样本保持:
text
负 : 正 = 3 : 1十八、推理流程
1. Forward
输出:
- 分类
- 回归
2. Decode
恢复 bbox。
3. Score Filter
删除低分框。
4. NMS
删除重复框。
NMS流程
Step1 排序
按 score。
Step2 取最高分
Step3 删除高IoU框
例如:
text
IoU > 0.45Step4 重复
直到结束。
十九、SSD 的优点
1. 速度快
Single Shot。
2. 结构简单
纯卷积。
3. 多尺度检测
比 YOLOv1 强。
4. Dense Prediction
召回率更高。
二十、SSD 的缺点
1. 小目标仍较弱
因为:
text
没有FPN浅层语义不足。
2. Anchor太多
正负样本严重失衡。
3. Anchor设计复杂
需要:
- scale
- ratio
手工设计。
二十一、SSD 的历史意义
SSD 对后续影响巨大。
影响了:
- RetinaNet
- YOLOv3
- EfficientDet
SSD 奠定了:
1. Anchor-based Detection
2. Dense Prediction
3. Multi-scale Detection
4. One-Stage Detector
二十二、现代角度看 SSD
现在:
SSD 已不算 SOTA。
现代更多:
- YOLOv8
- RT-DETR
- RetinaNet
但:
SSD 是:
text
理解目标检测原理
最经典的入门算法因为:
text
逻辑完整
结构清晰非常适合理解:
- Anchor
- Dense Prediction
- 多尺度检测
- 正负样本匹配
- 回归机制
- NMS
这些现代检测核心思想。