目录
-
- 前言
- 一、YOLO26-Sem推理详解(Python)
-
- [1. YOLO26-Sem预测](#1. YOLO26-Sem预测)
- [2. YOLO26-Sem预处理](#2. YOLO26-Sem预处理)
- [3. YOLO26-Sem后处理](#3. YOLO26-Sem后处理)
- [4. YOLO26-Sem推理](#4. YOLO26-Sem推理)
- 二、YOLO26-Sem推理详解(C++)
-
- [1. ONNX导出](#1. ONNX导出)
- [2. YOLO26-Sem预处理](#2. YOLO26-Sem预处理)
- [3. YOLO26-Sem后处理](#3. YOLO26-Sem后处理)
- [4. YOLO26-Sem推理](#4. YOLO26-Sem推理)
- 三、YOLO26-Sem部署
-
- [1. 源码下载](#1. 源码下载)
- [2. 环境配置](#2. 环境配置)
-
- [2.1 配置CMakeLists.txt](#2.1 配置CMakeLists.txt)
- [2.2 配置Makefile](#2.2 配置Makefile)
- [3. ONNX导出](#3. ONNX导出)
- [4. 源码修改](#4. 源码修改)
- 补充
- 结语
- 下载链接
- 参考
前言
Ultralytics 最近更新了 Semantic Segmentation 语义分割任务的支持,本篇文章梳理下 YOLO26-Sem 的预处理和后处理流程,顺便让 tensorRT_Pro 支持 YOLO26-Sem
一、YOLO26-Sem推理详解(Python)
语义分割(semantic segmentation) 为图像中的每个像素分配一个类别标签,生成覆盖整个场景的密集类别图。与 实例分割(instance segmentation) 区分各个独立物体不同,语义分割将所有属于同一类别的像素归为一组,无论场景中存在多少个不同的物体。
语义分割模型的输出是一张与输入图像等高的单通道类别图,其中每个像素值对应一个预测的类别ID。这使得语义分割非常适合场景解析任务,如自动驾驶、医学影像和土地覆盖制图等。
1. YOLO26-Sem预测
我们先尝试利用官方预训练权重来推理一张图片并保存,看能否成功
在 ultralytics 主目录下新建 predict-sem.py 预测文件,其内容如下:
python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo26s-sem.pt") # load an official model
# Predict with the model
results = model("munster_000000_000019_leftImg8bit.png") # predict on an image
# Access the results
for result in results:
semantic_mask = result.semantic_mask.data # class map, shape (H,W), integer dtype selected by class count
result.save("result.jpg")模型推理保存的结果图像如下所示:
在上述代码中我们通过 YOLO(..) 成功加载了官方语义分割模型,并将一张图片送入模型中推理得到了输出 results,results 中保存着不同任务的结果,我们这里是语义分割任务,因此只需要拿到对应的 mask 即可。
拿到 mask 后我们就可以将对应的 mask 绘制在图像上保存。
关于用于推理的示例图片这里博主拿的是 Cityscapes 验证集中的一张图片,图片下载于:https://www.kaggle.com/datasets/xiaose/cityscapes

2. YOLO26-Sem预处理
模型预测成功后我们就需要自己动手来写下 YOLO26-Sem 的预处理和后处理,方便后续在 C++ 上的实现,我们先来看看预处理的实现
经过我们的调试分析可知 YOLO26-Sem 的预处理过程在 ultralytics/engine/predictor.py 文件中,可以参考:predictor.py#L153
代码如下:
python
def preprocess(self, im: torch.Tensor | list[np.ndarray]) -> torch.Tensor:
"""Prepare input image before inference.
Args:
im (torch.Tensor | list[np.ndarray]): Images of shape (N, 3, H, W) for tensor, [(H, W, 3) x N] for list.
Returns:
(torch.Tensor): Preprocessed image tensor of shape (N, 3, H, W).
"""
not_tensor = not isinstance(im, torch.Tensor)
if not_tensor:
im = np.stack(self.pre_transform(im))
if im.shape[-1] == 3:
im = im[..., ::-1] # BGR to RGB
im = im.transpose((0, 3, 1, 2)) # BHWC to BCHW, (n, 3, h, w)
im = np.ascontiguousarray(im) # contiguous
im = torch.from_numpy(im)
im = im.to(self.device)
im = im.half() if self.model.fp16 else im.float() # uint8 to fp16/32
if not_tensor:
im /= 255 # 0 - 255 to 0.0 - 1.0
return im它包含以下步骤:
- self.pre_transform:即 letterbox 添加灰条
- np.stack:添加 batch 维度
- im..., ::-1:BGR → RGB
- im.transpose((0, 3, 1, 2)):HWC → CHW
- torch.from_numpy:to Tensor
- im /= 255:除以 255,归一化
大家如果对 YOLO 系列的预处理熟悉的话,会发现 YOLO26-Sem 的预处理和 YOLOv5、YOLOv8、YOLOv11 的预处理一模一样,因此我们不难写出对应的预处理代码,如下所示:
python
def preprocess_warpAffine(image, dst_width=1024, dst_height=512):
scale = min((dst_width / image.shape[1], dst_height / image.shape[0]))
ox = (dst_width - scale * image.shape[1]) / 2
oy = (dst_height - scale * image.shape[0]) / 2
M = np.array([
[scale, 0, ox],
[0, scale, oy]
], dtype=np.float32)
img_pre = cv2.warpAffine(image, M, (dst_width, dst_height), flags=cv2.INTER_LINEAR,
borderMode=cv2.BORDER_CONSTANT, borderValue=(114, 114, 114))
IM = cv2.invertAffineTransform(M)
img_pre = (img_pre[...,::-1] / 255.0).astype(np.float32)
img_pre = img_pre.transpose(2, 0, 1)[None]
img_pre = torch.from_numpy(img_pre)
return img_pre, IM其中的 letterbox 添加灰条步骤我们可以通过仿射变换 warpAffine 实现,warpAffine 非常适合在 CUDA 上加速,关于 warpAffine 仿射变换的细节大家可以参考 YOLOv5推理详解及预处理高性能实现,这边不再赘述。其它步骤倒是和官方的没有区别。
值得注意得是,letterbox 的操作是先将长边缩放到 1024,再将短边按比例缩放,同时确保缩放后的短边能整除 32,如果不能则向上取整多余部分填充。warpAffine 的操作则是将图像分辨率固定在 1024x512,多余部分添加灰条,博主对一张宽高是 810x1080 分辨率的图像经过两种不同预处理后的结果进行了对比,如下图所示:

图1-1 LeeterBox预处理图像

图1-2 WarpAffine预处理图像
可以看到二者明显的差别,letterbox 中没有灰条,因为长边缩放到 1024 后短边刚好缩放到 768,能整除 32。而 warpAffine 则是固定分辨率 1024x512,因此短边多余部分将用灰条填充。
warpAffine 预处理方法将图像分辨率固定在 1024x512,主要有以下几点考虑:(from chatGPT)
- 简化处理逻辑:所有预处理后的图像分辨率相同,可以简化 CUDA 中并行处理的逻辑,使得代码更易于编写和维护。
- 优化内存访问:在 GPU 上,连续的内存访问模式通常比非连续的访问更高效。如果所有图像具有相同的大小和布局,这可以帮助优化内存访问,提高处理速度。
- 避免动态内存分配:动态内存分配和释放是昂贵的操作,特别是在 GPU 上。固定分辨率意味着可以预先分配足够的内存,而不需要根据每个图像的大小动态调整内存大小。
这两种不同的预处理方法生成的图片输入到神经网络时的维度不同,letterbox 的输入是 torch.Size(1, 3, 1024, 768) ,warpAffine 的输入是 torch.Size(1, 3, 512, 1024) 。由于输入维度不同将导致模型输出维度的差异,经过 8 倍降采样hou,letterbox 的输出 mask 是 1x19x128x96 ,而 warpAffine 的输出是 1x3x64x128,这点大家需要清楚。
3. YOLO26-Sem后处理
我们再来看看后处理的实现
经过我们的调试分析可知 YOLO26-Sem 的后处理部分在 ultralytics/models/yolo/semantic/predict.py 文件中,可以参考:semantic/predict.py#L40
python
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
from __future__ import annotations
import torch
from ultralytics.engine.predictor import BasePredictor
from ultralytics.engine.results import Results
from ultralytics.utils import DEFAULT_CFG, ops
class SemanticSegmentationPredictor(BasePredictor):
"""Predictor for semantic segmentation models.
This predictor processes model outputs to produce per-pixel class label maps.
Examples:
>>> from ultralytics.models.yolo.semantic import SemanticSegmentationPredictor
>>> args = dict(model="yolo26n-sem.pt", source="path/to/image.jpg")
>>> predictor = SemanticSegmentationPredictor(overrides=args)
>>> predictor.predict_cli()
"""
def __init__(self, cfg=DEFAULT_CFG, overrides=None, _callbacks=None):
"""Initialize SemanticSegmentationPredictor.
Args:
cfg (dict): Configuration for the predictor.
overrides (dict, optional): Configuration overrides.
_callbacks (dict, optional): Callback functions.
"""
super().__init__(cfg, overrides, _callbacks)
self.args.task = "semantic"
@staticmethod
def _class_map_dtype(num_classes: int) -> torch.dtype:
"""Return the smallest practical integer dtype for semantic class IDs."""
return torch.uint8 if num_classes <= 256 else torch.int16 if num_classes <= 32768 else torch.int32
def postprocess(self, preds, img, orig_imgs):
"""Convert model logits to semantic segmentation results.
Args:
preds (torch.Tensor | tuple): Model output logits.
img (torch.Tensor): Preprocessed input image tensor.
orig_imgs (list | torch.Tensor): Original images.
Returns:
(list[Results]): List of Results objects with semantic masks.
"""
if isinstance(preds, (tuple, list)):
preds = preds[0]
if not isinstance(orig_imgs, list): # input images are a torch.Tensor, not a list
orig_imgs = ops.convert_torch2numpy_batch(orig_imgs)[..., ::-1]
results = []
for i, (pred, orig_img) in enumerate(zip(preds, orig_imgs)):
img_path = self.batch[0][i] if isinstance(self.batch[0], list) else self.batch[0]
# pred: [nc, H, W] logits on letterboxed input. Remove padding, then resize to original image.
pred = ops.scale_masks(pred.unsqueeze(0), orig_img.shape[:2])[0]
dtype = self._class_map_dtype(max(pred.shape[0], 2))
class_map = pred.argmax(0).to(dtype) if pred.shape[0] > 1 else pred.gt(0).squeeze(0).to(dtype)
results.append(Results(orig_img, path=img_path, names=self.model.names, semantic_mask=class_map))
return results它包含以下步骤:
- ops.scale_masks:将预测的 mask 从模型输出尺寸缩放到原图图像尺寸
- pred.argmax(0):根据类别数生成类别图,每个 pixel 对应一个类别
可以看到这个后处理还是非常简单的,主要是上采样到原图大小,然后拿到原图中每个 pixel 的类别最大值即可,因此我们不难写出对应的后处理代码,如下所示:
python
def scale_masks_warpAffine(masks, IM, shape):
H_pre, W_pre = 512, 1024
H_ori, W_ori = shape[:2]
if W_ori / H_ori == 2:
masks = F.interpolate(masks, size=(H_ori, W_ori), mode='bilinear', align_corners=False)
return masks
else:
masks = F.interpolate(masks, size=(H_pre, W_pre), mode='bilinear', align_corners=False)
masks = masks[0].cpu().numpy()
masks = masks.transpose(1, 2, 0)
masks = cv2.warpAffine(masks, IM, (W_ori, H_ori), flags=cv2.INTER_LINEAR,
borderMode=cv2.BORDER_CONSTANT, borderValue=0)
masks = masks.transpose(2, 0, 1)
return torch.from_numpy(masks)[None]
# postprocess
pred = scale_masks_warpAffine(pred, IM, img.shape[:2])[0] # [nc, H, W] -> [H, W]
class_map = pred.argmax(0).to(torch.uint8) 注意,scale_masks_warpAffine 中有两个分支,第一个分支的含义是如果输入图像的宽高比和模型的宽高比一致,则直接上采样插值到原图即可,这是因为如果宽高比一致则意味着没有任何的灰条填充直接插值即可。
第二个分支的含义是如果输入图像的宽高比和模型的宽高比不一致,则需要先将模型的预测输出 mask 上采样到模型的输入大小,然后通过仿射变换逆矩阵 IM 映射回原图大小。
拿到了和原图大小相同的 mask 后我们对每个 pixel 拿到最大类别的索引 index,因此 class_map 对应的就是每个 pixel 预测的类别,之后再通过类别预测的结果进行可视化就行。
对于一张 2048x1024(宽x高) 的图像,预处理会将其缩放到 1024x512,然后模型的输出是 1x19x64x128,四个维度代表的含义分别是 batch、classes、mask_h、mask_w。其中 batch 维度是 1,代表只有一张图像输入模型,classes 是 19,对应的是 Cityscapes 数据集中的 19 个类别,mask_h 和 mask_w 是输入图像经过 8 倍降采样得到的 mask 掩码图。
4. YOLO26-Sem推理
通过上面对 YOLO26-Sem 的预处理和后处理分析之后,整个推理过程就显而易见了。YOLO26-Sem 的推理包括图像预处理、模型推理、预测结果后处理三部分,其中预处理主要包括 warpAffine 仿射变换 ,后处理主要包括 mask 的处理。
完整推理代码如下:
python
import cv2
import torch
import numpy as np
import torch.nn.functional as F
from ultralytics.nn.autobackend import AutoBackend
from ultralytics.utils.plotting import Colors
def preprocess_warpAffine(image, dst_width=1024, dst_height=512):
scale = min((dst_width / image.shape[1], dst_height / image.shape[0]))
ox = (dst_width - scale * image.shape[1]) / 2
oy = (dst_height - scale * image.shape[0]) / 2
M = np.array([
[scale, 0, ox],
[0, scale, oy]
], dtype=np.float32)
img_pre = cv2.warpAffine(image, M, (dst_width, dst_height), flags=cv2.INTER_LINEAR,
borderMode=cv2.BORDER_CONSTANT, borderValue=(114, 114, 114))
IM = cv2.invertAffineTransform(M)
img_pre = (img_pre[...,::-1] / 255.0).astype(np.float32)
img_pre = img_pre.transpose(2, 0, 1)[None]
img_pre = torch.from_numpy(img_pre)
return img_pre, IM
def scale_masks_warpAffine(masks, IM, shape):
H_pre, W_pre = 512, 1024
H_ori, W_ori = shape[:2]
if W_ori / H_ori == 2:
masks = F.interpolate(masks, size=(H_ori, W_ori), mode='bilinear', align_corners=False)
return masks
else:
masks = F.interpolate(masks, size=(H_pre, W_pre), mode='bilinear', align_corners=False)
masks = masks[0].cpu().numpy()
masks = masks.transpose(1, 2, 0)
masks = cv2.warpAffine(masks, IM, (W_ori, H_ori), flags=cv2.INTER_LINEAR,
borderMode=cv2.BORDER_CONSTANT, borderValue=0)
masks = masks.transpose(2, 0, 1)
return torch.from_numpy(masks)[None]
def save_semantic_result(image, class_map, save_path, alpha=0.5, ignore_index=255):
class_map = class_map.cpu().numpy()
colors = Colors()
overlay = np.zeros_like(image)
for cls_id in np.unique(class_map):
if cls_id == ignore_index:
continue
overlay[class_map == cls_id] = colors(int(cls_id), bgr=True)
result = cv2.addWeighted(image, 1 - alpha, overlay, alpha, 0)
cv2.imwrite(save_path, result)
print(f'Saved to {save_path}')
if __name__ == "__main__":
# preprocess
img = cv2.imread("munster_000000_000019_leftImg8bit.png")
img_pre, IM = preprocess_warpAffine(img)
# inference
model = AutoBackend(model="yolo26s-sem.pt")
pred = model(img_pre)
# postprocess
pred = scale_masks_warpAffine(pred, IM, img.shape[:2])[0]
class_map = pred.argmax(0).to(torch.uint8)
# visualize and save
save_semantic_result(img, class_map, "semantic_result.jpg")Note :可视化部分参考自:ultralytics/utils/plotting.py#L413
当然我们也可以用官方的 LetterBox 预处理方式以及 scale_masks 后处理完成整个推理,实现代码如下:
python
import cv2
import torch
import numpy as np
import torch.nn.functional as F
from ultralytics.nn.autobackend import AutoBackend
from ultralytics.utils.plotting import Colors
def preprocess_warpAffine(image, dst_width=1024, dst_height=512):
scale = min((dst_width / image.shape[1], dst_height / image.shape[0]))
ox = (dst_width - scale * image.shape[1]) / 2
oy = (dst_height - scale * image.shape[0]) / 2
M = np.array([
[scale, 0, ox],
[0, scale, oy]
], dtype=np.float32)
img_pre = cv2.warpAffine(image, M, (dst_width, dst_height), flags=cv2.INTER_LINEAR,
borderMode=cv2.BORDER_CONSTANT, borderValue=(114, 114, 114))
IM = cv2.invertAffineTransform(M)
img_pre = (img_pre[...,::-1] / 255.0).astype(np.float32)
img_pre = img_pre.transpose(2, 0, 1)[None]
img_pre = torch.from_numpy(img_pre)
return img_pre, IM
def scale_masks_warpAffine(masks, IM, shape):
H_pre, W_pre = 512, 1024
H_ori, W_ori = shape[:2]
if W_ori / H_ori == 2:
masks = F.interpolate(masks, size=(H_ori, W_ori), mode='bilinear', align_corners=False)
return masks
else:
masks = F.interpolate(masks, size=(H_pre, W_pre), mode='bilinear', align_corners=False)
masks = masks[0].cpu().numpy()
masks = masks.transpose(1, 2, 0)
masks = cv2.warpAffine(masks, IM, (W_ori, H_ori), flags=cv2.INTER_LINEAR,
borderMode=cv2.BORDER_CONSTANT, borderValue=0)
masks = masks.transpose(2, 0, 1)
return torch.from_numpy(masks)[None]
def save_semantic_result(image, class_map, save_path, alpha=0.5, ignore_index=255):
class_map = class_map.cpu().numpy()
colors = Colors()
overlay = np.zeros_like(image)
for cls_id in np.unique(class_map):
if cls_id == ignore_index:
continue
overlay[class_map == cls_id] = colors(int(cls_id), bgr=True)
result = cv2.addWeighted(image, 1 - alpha, overlay, alpha, 0)
cv2.imwrite(save_path, result)
print(f'Saved to {save_path}')
if __name__ == "__main__":
# preprocess
img = cv2.imread("munster_000000_000019_leftImg8bit.png")
img_pre, IM = preprocess_warpAffine(img)
# inference
model = AutoBackend(model="yolo26s-sem.pt")
pred = model(img_pre)
# postprocess
pred = scale_masks_warpAffine(pred, IM, img.shape[:2])[0]
class_map = pred.argmax(0).to(torch.uint8)
# visualize and save
save_semantic_result(img, class_map, "semantic_result.jpg")两者执行后可视化结果对比如下图所示(上-warpAffine,下-LetterBox):

大家如果仔细对比会发现两者的分割细粒度还是有一些差异的,例如右下角穿白衣服的人头部以及右边第二个杆顶部等等,这个差异主要是因为预处理方式的不同(由于输入图像尺寸是 2048x1024,所以后处理是一致的),导致输入模型的图像像素存在细微差异。如果是有灰条填充的输入图像,例如那张经典的 bus.jpg 图,两者分割结果差异更大,大家感兴趣的可以自己试试。
至此,我们在 Python 上面完成了 YOLO26-Sem 的整个推理过程,下面我们去 C++ 上实现。
二、YOLO26-Sem推理详解(C++)
C++ 上的实现我们使用的 repo 依旧是 tensorRT_Pro,现在我们就基于 tensorRT_Pro 完成 YOLO26-Sem 在 C++ 上的推理。
1. ONNX导出
首先我们需要将 YOLO26-Sem 模型导出为 ONNX,为了适配 tensorRT_Pro 我们需要做一些修改,主要有以下几点:
- 修改输出节点名为 output
- 输入输出只让 batch 维度动态,宽高不动态
具体修改如下:
1. 在 ultralytics/engine/exporter.py 文件中改动两处
- 638 行:修改输出节点名为 output
- 641 行:输出只让 batch 动态,宽高不动态
python
# ========== exporter.py ==========
# ultralytics/engine/exporter.py 第 638 行
# output_names = ["output0", "output1"] if self.model.task == "segment" else ["output1"]
# dynamic = self.args.dynamic
# if dynamic:
# dynamic = {"images": {0: "batch", 2: "height", 3: "width"}} # shape(1,3,640,640)
# 修改为:
output_names = ["output0", "output1"] if self.model.task == "segment" else ["output"]
dynamic = self.args.dynamic
if dynamic:
dynamic = {"images": {0: "batch"}} # shape(1,3,640,640)以上就是为了适配 tensorRT_Pro 而做出的代码修改,修改好以后,将预训练权重 yolo26s-sem.pt 放在 ultralytics 主目录下,新建导出文件 export.py,内容如下:
python
from ultralytics import YOLO
# Load a model
model = YOLO("yolo26s-sem.pt") # load an official model
# Export the model
model.export(format="onnx", imgsz=(512, 1024), dynamic=True, simplify=True)值得注意的是,imgsz 如果不指定默认导出的是 1024x1024 分辨率的模型,而 YOLO26-Sem 模型是在分辨率为 1024x2048 的 Cityscapes 数据集下训练的,这里博主固定为 512x1024 的输入。
在终端执行如下指令即可完成 onnx 导出:
shell
python export.py导出过程如下图所示:
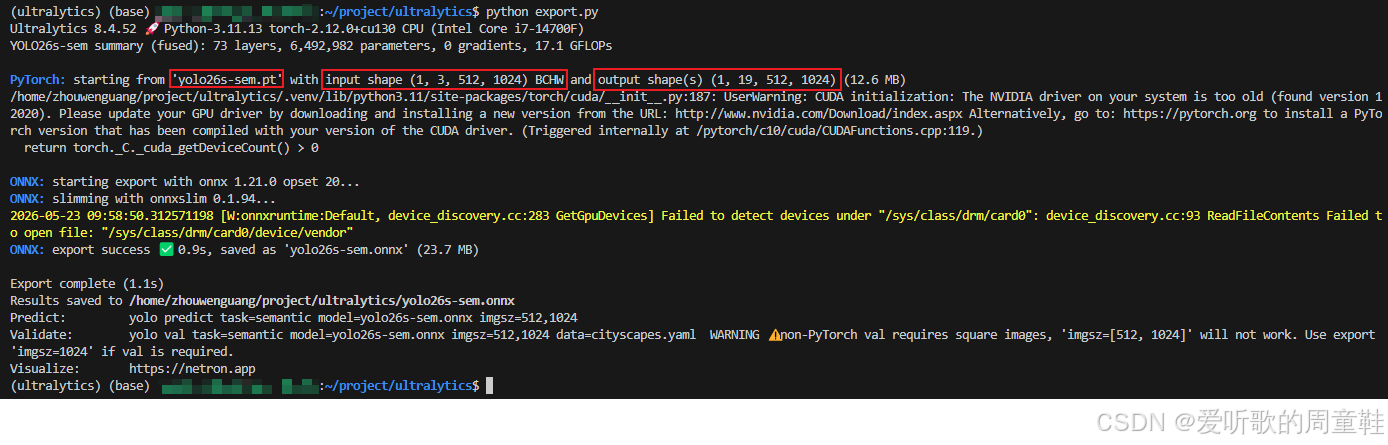
可以看到导出的 onnx 模型的输入 shape 是 1x3x512x1024,输出 shape 是 1x19x512x1024,符合我们的预期。
那大家可能会有所困惑,模型不是经过 8 倍降采样得到 mask 图吗?按理来说,输出 shape 应该是 1x19x64x128 才对呀,为什么输出的 mask 图和输入分辨率保持一致呢?
关键就在 SemanticSegment.forward() 方法中,在 ultralytics/nn/modules/head.py#L1849 有如下代码:
python
class SemanticSegment(nn.Module):
"""YOLO semantic segmentation head for per-pixel classification.
This head produces dense per-pixel class predictions. Unlike instance segmentation, no bounding boxes or instance
masks are produced.
Attributes:
nc (int): Number of semantic classes.
nl (int): Number of input feature levels.
stride (torch.Tensor): Feature map strides.
export (bool): Export mode flag.
format (str): Export format.
classifier (nn.Sequential): Final convolutional classifier head.
aux_head (nn.Sequential | None): Auxiliary classifier on P4 for deep supervision.
"""
export = False # export mode
format = None # export format
def __init__(self, nc=19, ch=()):
"""Initialize the semantic segmentation head.
Args:
nc (int): Number of semantic classes.
ch (tuple): Tuple of channel sizes from neck feature maps (P3, P4).
"""
super().__init__()
self.nc = nc
self.nl = len(ch)
self.stride = torch.zeros(self.nl)
c_mid = ch[0] # use P3 channel width as intermediate dimension
# Final classifier
self.classifier = nn.Sequential(Conv(c_mid, c_mid, 3), nn.Conv2d(c_mid, nc, 1))
# Auxiliary head on P4 (index 1) for training
self.aux_head = nn.Sequential(Conv(ch[1], c_mid, 3), nn.Conv2d(c_mid, nc, 1)) if len(ch) > 1 else None
def forward(self, x):
"""Forward pass: fuse multi-scale features and predict per-pixel classes.
Args:
x (list[torch.Tensor]): List of feature maps [P3, P4].
Returns:
(torch.Tensor): Logits of shape [B, nc, H/8, W/8] during training, inference, and CoreML export. Other
export formats return upsampled logits of shape [B, nc, H, W].
"""
# Classify
logits = self.classifier(x[0]) # [B, nc, H/8, W/8]
if self.training:
if self.aux_head is not None:
return logits, self.aux_head(x[1]) # main + aux (P4)
return logits
if self.export and self.format != "coreml": # coreml does not support interpolate
return F.interpolate(logits, scale_factor=8, mode="bilinear", align_corners=False)
return logits如果是 self.export 也就是导出 ONNX 时,代码会将 mask 直接插值到原图分辨率,这是为了让导出的 ONNX 自包含 resize 节点,在部署时我们就不需要额外的上采样后处理了,直接拿到和输入同分辨率的语义分割结果。
导出成功后会在当前目录下生成 yolo26s-sem.onnx 模型,我们可以使用 Netron 可视化工具查看,如下图所示:
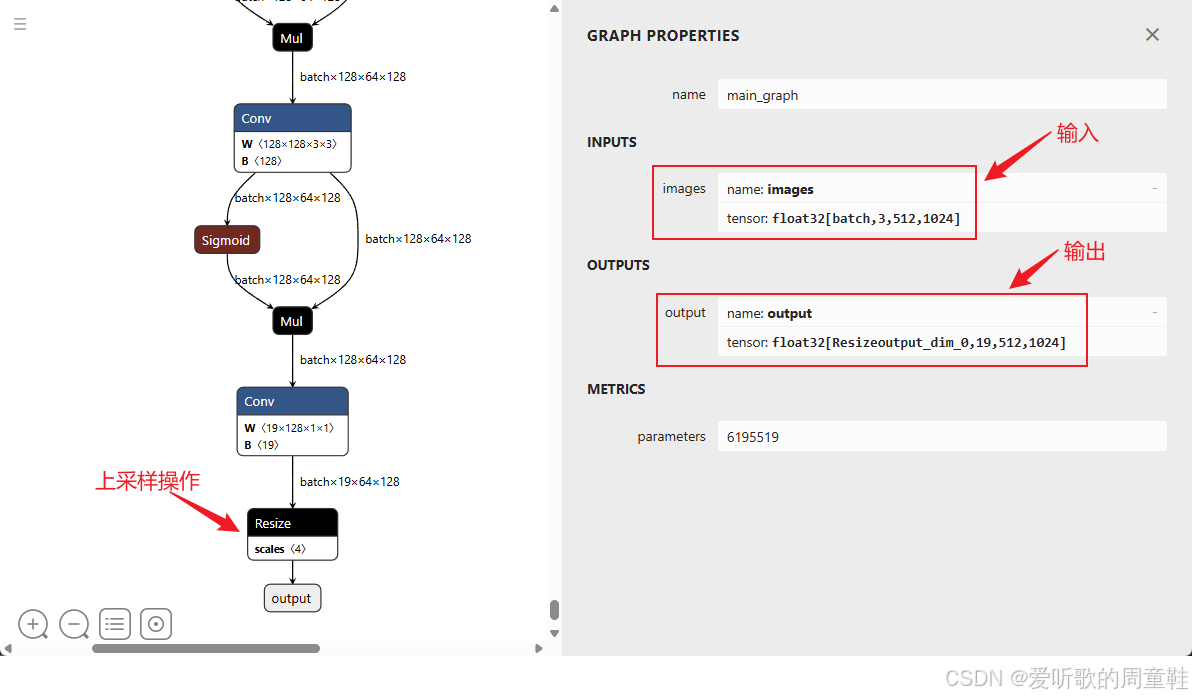
可以看到输入节点名是 images ,维度是 batchx3x512x1024,保证只有 batch 维度动态,输出节点名是 output,维度是 Resizeoutput_dim_0x19x512x1024,保证只有 batch 维度动态,符合 tensorRT_Pro 的格式。
2. YOLO26-Sem预处理
之前有提到过 YOLO26-Sem 的预处理部分和 YOLO 系列实现一模一样,因此我们在 tensorRT_Pro 中 YOLO26-Sem 模型的预处理可以直接使用 YOLOv5 等模型的预处理。
tensorRT_Pro 中预处理代码如下:
cpp
__global__ void warp_affine_bilinear_and_normalize_plane_kernel(uint8_t* src, int src_line_size, int src_width, int src_height, float* dst, int dst_width, int dst_height,
uint8_t const_value_st, float* warp_affine_matrix_2_3, Norm norm, int edge){
int position = blockDim.x * blockIdx.x + threadIdx.x;
if (position >= edge) return;
float m_x1 = warp_affine_matrix_2_3[0];
float m_y1 = warp_affine_matrix_2_3[1];
float m_z1 = warp_affine_matrix_2_3[2];
float m_x2 = warp_affine_matrix_2_3[3];
float m_y2 = warp_affine_matrix_2_3[4];
float m_z2 = warp_affine_matrix_2_3[5];
int dx = position % dst_width;
int dy = position / dst_width;
float src_x = m_x1 * dx + m_y1 * dy + m_z1;
float src_y = m_x2 * dx + m_y2 * dy + m_z2;
float c0, c1, c2;
if(src_x <= -1 || src_x >= src_width || src_y <= -1 || src_y >= src_height){
// out of range
c0 = const_value_st;
c1 = const_value_st;
c2 = const_value_st;
}else{
int y_low = floorf(src_y);
int x_low = floorf(src_x);
int y_high = y_low + 1;
int x_high = x_low + 1;
uint8_t const_value[] = {const_value_st, const_value_st, const_value_st};
float ly = src_y - y_low;
float lx = src_x - x_low;
float hy = 1 - ly;
float hx = 1 - lx;
float w1 = hy * hx, w2 = hy * lx, w3 = ly * hx, w4 = ly * lx;
uint8_t* v1 = const_value;
uint8_t* v2 = const_value;
uint8_t* v3 = const_value;
uint8_t* v4 = const_value;
if(y_low >= 0){
if (x_low >= 0)
v1 = src + y_low * src_line_size + x_low * 3;
if (x_high < src_width)
v2 = src + y_low * src_line_size + x_high * 3;
}
if(y_high < src_height){
if (x_low >= 0)
v3 = src + y_high * src_line_size + x_low * 3;
if (x_high < src_width)
v4 = src + y_high * src_line_size + x_high * 3;
}
// same to opencv
c0 = floorf(w1 * v1[0] + w2 * v2[0] + w3 * v3[0] + w4 * v4[0] + 0.5f);
c1 = floorf(w1 * v1[1] + w2 * v2[1] + w3 * v3[1] + w4 * v4[1] + 0.5f);
c2 = floorf(w1 * v1[2] + w2 * v2[2] + w3 * v3[2] + w4 * v4[2] + 0.5f);
}
if(norm.channel_type == ChannelType::Invert){
float t = c2;
c2 = c0; c0 = t;
}
if(norm.type == NormType::MeanStd){
c0 = (c0 * norm.alpha - norm.mean[0]) / norm.std[0];
c1 = (c1 * norm.alpha - norm.mean[1]) / norm.std[1];
c2 = (c2 * norm.alpha - norm.mean[2]) / norm.std[2];
}else if(norm.type == NormType::AlphaBeta){
c0 = c0 * norm.alpha + norm.beta;
c1 = c1 * norm.alpha + norm.beta;
c2 = c2 * norm.alpha + norm.beta;
}
int area = dst_width * dst_height;
float* pdst_c0 = dst + dy * dst_width + dx;
float* pdst_c1 = pdst_c0 + area;
float* pdst_c2 = pdst_c1 + area;
*pdst_c0 = c0;
*pdst_c1 = c1;
*pdst_c2 = c2;
}关于预处理部分其实就是调用了上述 CUDA 核函数来实现 warpAffine,由于在 CUDA 中我们是对每个像素进行操作,因此非常容易实现 BGR → RGB,/255.0 等操作。关于代码的具体分析可以参考 YOLOv5推理详解及预处理高性能实现,这边不再赘述。
3. YOLO26-Sem后处理
YOLO26-Sem 的后处理也非常简单,前面我们分析过,首先通过 warpAffine 逆矩阵映射到原图大小,然后拿到每个 pixel 的最大类别 index 即可。
因此我们不难写出 YOLO26-Sem 的 mask 后处理实现代码,如下所示:
cpp
template<typename _T>
static __inline__ __device__ _T limit(_T value, _T low, _T high){
return value < low ? low : (value > high ? high : value);
}
__global__ void warp_affine_semantic_mask_kernel(
float* src, int src_width, int src_height, int num_classes,
uint8_t* dst, int dst_width, int dst_height,
float* matrix_2_3, int edge
){
int position = blockDim.x * blockIdx.x + threadIdx.x;
if (position >= edge) return;
float m_x1 = matrix_2_3[0];
float m_y1 = matrix_2_3[1];
float m_z1 = matrix_2_3[2];
float m_x2 = matrix_2_3[3];
float m_y2 = matrix_2_3[4];
float m_z2 = matrix_2_3[5];
int dx = position % dst_width;
int dy = position / dst_width;
float src_x = m_x1 * dx + m_y1 * dy + m_z1;
float src_y = m_x2 * dx + m_y2 * dy + m_z2;
if(src_x <= -1 || src_x >= src_width || src_y <= -1 || src_y >= src_height){
// out of range, set ignore index
dst[position] = 255;
return;
}
int y_low = floorf(src_y);
int x_low = floorf(src_x);
int y_high = limit(y_low + 1, 0, src_height - 1);
int x_high = limit(x_low + 1, 0, src_width - 1);
y_low = limit(y_low, 0, src_height - 1);
x_low = limit(x_low, 0, src_width - 1);
float ly = src_y - y_low;
float lx = src_x - x_low;
float hy = 1 - ly;
float hx = 1 - lx;
float w1 = hy * hx, w2 = hy * lx, w3 = ly * hx, w4 = ly * lx;
int src_area = src_width * src_height;
int idx_v1 = y_low * src_width + x_low;
int idx_v2 = y_low * src_width + x_high;
int idx_v3 = y_high * src_width + x_low;
int idx_v4 = y_high * src_width + x_high;
float max_val = -1e30f;
int max_class = 0;
for(int c = 0; c < num_classes; ++c){
int base = c * src_area;
float v1 = src[base + idx_v1];
float v2 = src[base + idx_v2];
float v3 = src[base + idx_v3];
float v4 = src[base + idx_v4];
float val = w1 * v1 + w2 * v2 + w3 * v3 + w4 * v4;
if(val > max_val){
max_val = val;
max_class = c;
}
}
dst[position] = (uint8_t)max_class;
}关于后处理部分其实就是调用了上面的 warp_affine_semantic_mask_kernel 这个 CUDA 核函数来实现从网络输出 mask 到原图 class_map 的映射。由于在 CUDA 中我们是对每个像素进行操作,因此非常容易实现 warpAffine 逆映射、双线性插值采样所有类别的 logits 并取 argmax 等操作。
具体来说,核函数对原图的每个像素 (dx, dy),先用 i2d 仿射矩阵计算出该像素在 512×1024 网络输出空间中的亚像素坐标 (src_x, src_y),然后对每个类别通道独立做双线性插值采样,在所有类别的插值结果中取最大值对应的类别索引作为该像素的语义标签。
对于落在网络输出区域之外的像素(即原图 letterbox 黑边区域),直接赋予 ignore_index (255)。整个过程完全在 GPU 端完成,无需 CPU 参与任何像素级计算。
4. YOLO26-Sem推理
通过上面对 YOLO26-Sem 的预处理和后处理分析之后,整个推理过程就显而易见了。C++ 上的 YOLO26-Sem 的预处理部分可直接沿用 YOLOv5 等模型的预处理,后处理也是类似于 warpAffine 的双线性插值,只需单独处理下每个 classes 即可。
我们在终端执行如下指令即可完成推理(注意!完整流程博主会在后续内容介绍,这边只是简单演示)
shell
make yolo_sem编译图解如下所示:
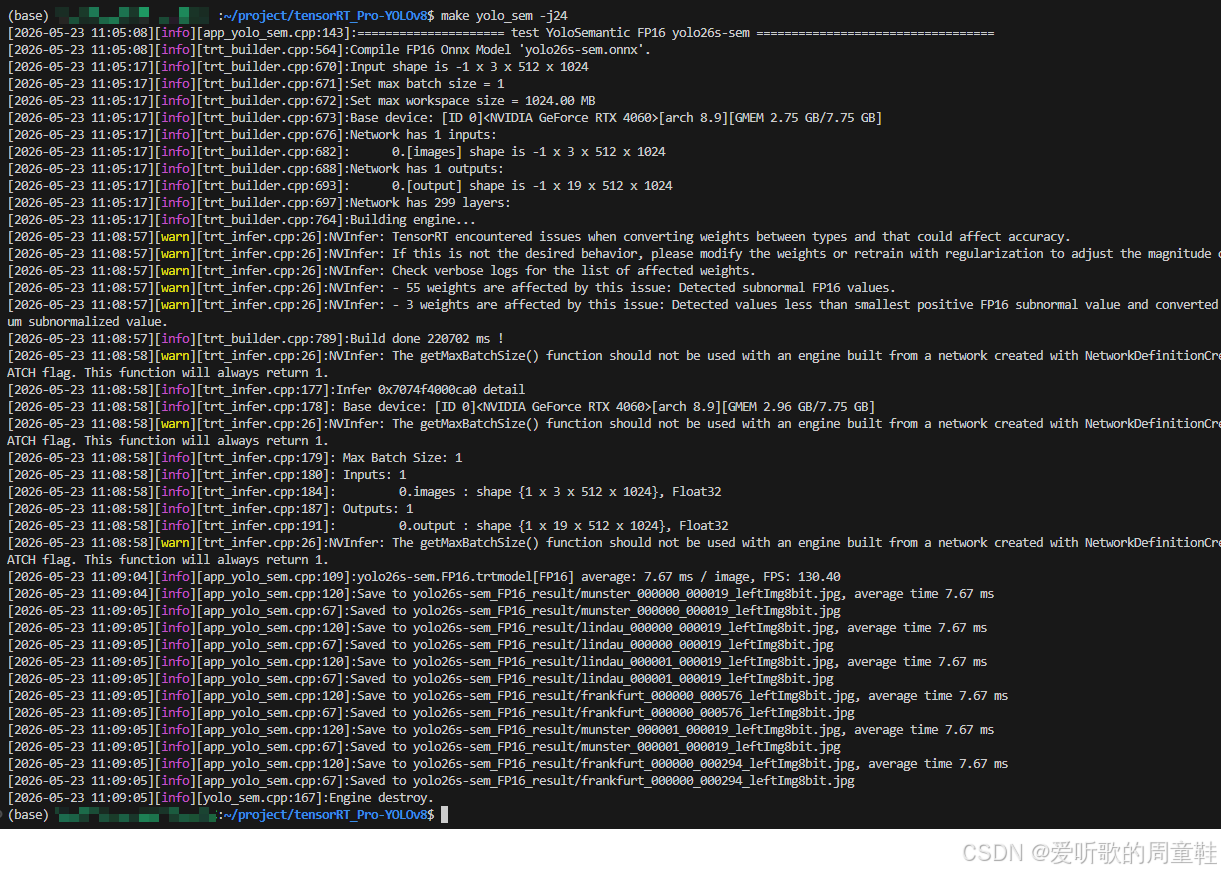
推理结果如下图所示:

至此,我们在 C++ 上面完成了 YOLO26-Sem 的整个推理过程,下面我们将完整的走一遍流程。
三、YOLO26-Sem部署
博主新建了一个仓库 tensorRT_Pro-YOLOv8,该仓库基于 shouxieai/tensorRT_Pro,并进行了调整以支持 Ultralytics 的各项任务,目前已支持分类、目标检测、旋转目标检测、实例分割、姿态点估计、语义分割任务。
下面我们就来具体看看如何利用 tensorRT_Pro-YOLOv8 这个 repo 完成 YOLO26-Sem 的推理。
1. 源码下载
tensorRT_Pro-YOLOv8 的代码可以直接从 GitHub 官网上下载,源码下载地址是 https://github.com/Melody-Zhou/tensorRT_Pro-YOLOv8,Linux 下代码克隆指令如下:
shell
git clone https://github.com/Melody-Zhou/tensorRT_Pro-YOLOv8.git也可手动点击下载,点击右上角的 Code 按键,将代码下载下来。至此整个项目就已经准备好了。也可以点击 here 下载博主准备好的源代码(注意代码下载于 2026/5/23 日,若有改动请参考最新)
2. 环境配置
需要使用的软件环境有 TensorRT、CUDA、cuDNN、OpenCV、Protobuf ,所有软件环境的安装可以参考 Ubuntu20.04软件安装大全,这里不再赘述,需要各位看官自行配置好相关环境😄,外网访问较慢,这里提供下博主安装过程中的软件安装包下载链接 Baidu Drive【pwd:yolo】🚀🚀🚀
tensorRT_Pro-YOLOv8 提供 CMakeLists.txt 和 Makefile 两种方式编译,二者选一即可
2.1 配置CMakeLists.txt
主要修改五处
1. 修改第 13 行,修改 OpenCV 路径
cpp
set(OpenCV_DIR "/usr/local/include/opencv4")2. 修改第 15 行,修改 CUDA 路径
cpp
set(CUDA_TOOLKIT_ROOT_DIR "/usr/local/cuda-11.6")3. 修改第 16 行,修改 cuDNN 路径
cpp
set(CUDNN_DIR "/usr/local/cudnn8.4.0.27-cuda11.6")4. 修改第 17 行,修改 tensorRT 路径
cpp
set(TENSORRT_DIR "/opt/TensorRT-8.4.1.5")5. 修改第 20 行,修改 protobuf 路径
cpp
set(PROTOBUF_DIR "/home/jarvis/protobuf")2.2 配置Makefile
主要修改五处
1. 修改第 4 行,修改 protobuf 路径
cpp
lean_protobuf := /home/jarvis/protobuf2. 修改第 5 行,修改 tensorRT 路径
cpp
lean_tensor_rt := /opt/TensorRT-8.4.1.53. 修改第 6 行,修改 cuDNN 路径
cpp
lean_cudnn := /usr/local/cudnn8.4.0.27-cuda11.64. 修改第 7 行,修改 OpenCV 路径
cpp
lean_opencv := /usr/local5. 修改第 8 行,修改 CUDA 路径
cpp
lean_cuda := /usr/local/cuda-11.63. ONNX导出
导出细节可以查看之前的内容,这边不再赘述。记得将导出的 ONNX 模型放在 tensorRT_Pro-YOLOv8/workspace 文件夹下。
4. 源码修改
如果你想推理自己训练的模型还需要修改下源代码,YOLO26-Sem 模型的推理代码主要在 app_yolo_sem.cpp 文件中,我们就只需要修改这一个文件中的内容即可,源码修改较简单主要有以下几点:
- 1. app_yolo_sem.cpp 244 行,"yolo26s-sem" 修改为你导出的 ONNX 模型名
具体修改示例如下:
cpp
test(TRT::Mode::FP32, "best"); // 修改1 244 行 "yolo26s-sem" 改成 "best"OK!源码修改好了,Makefile 编译文件也搞定了,ONNX 模型也准备好了,现在可以编译运行了,直接在终端执行如下指令即可:
shell
make yolo_sem编译过程如下所示:
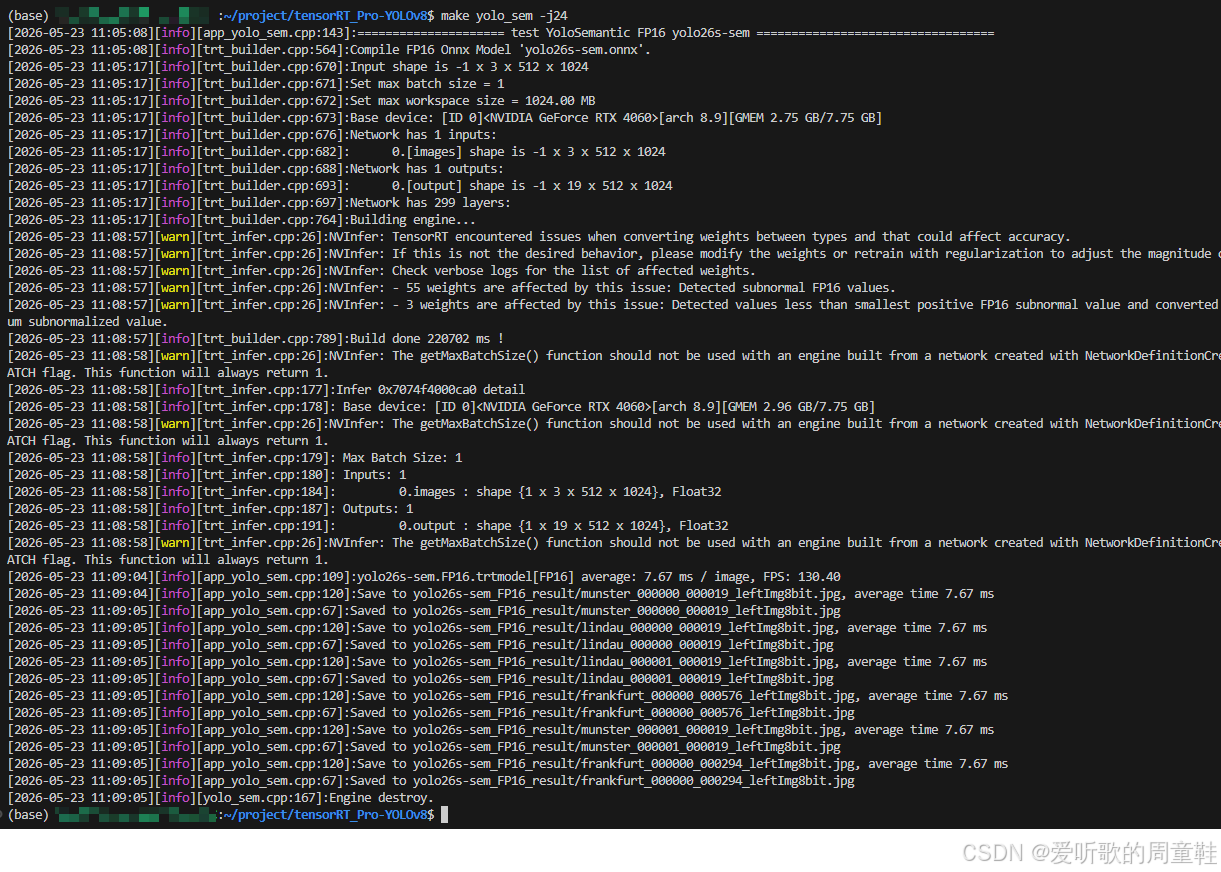
编译运行成功后在 workspace 文件夹下会生成 engine 文件 yolo26s-sem.FP32.trtmodel 用于模型推理,同时它还会生成 yolo26s-sem_FP32_result 文件夹,该文件夹下保存了推理的图片。
模型推理效果如下图所示:

OK!以上就是使用 tensorRT_Pro-YOLOv8 推理 YOLO26-Sem 的大致流程,若有问题,欢迎各位看官批评指正。
补充
关于分割精度的问题,有以下说明:
1. 推理时尽量保持输入图像宽高比与模型训练时的宽高比一致
- 当宽高比一致时,预处理无需添加灰条
- 此时模型只需 一次双线性上采样 即可恢复到原图分辨率,分割结果更加精细
2. 宽高比不一致时 warpAffine 分割精度要差于 letterbox 分割精度
- 当宽高比不一致时,例如 bus.jpg 这张分辨率为 810x1080 的图像,预处理 warpAffine 与 LettetBox 在实现和插值上存在差异,前面也分析讨论过
- warpAffine 处理方式下后处理需要两步:先上采样到预处理尺寸,在通过仿射变换逆矩阵
IM变换回原图 - 两次插值累积误差,导致分割精度明显低于 LettetBox 方式,下图是两者的对比(左图-WarpAffine,右图-LetterBox)

3. C++ 部署中的速度与精度权衡
- 预处理使用 warpAffine 并固定模型输入尺寸,主要是方便利用 warpAffine 的 CUDA 核函数加速(一次性完成缩放+平移)
- 后处理可编写类似的 CUDA 核函数,完成从特征图到原图的仿射变换上采样
- Python → C++ 精度损失是存在的,一个是预处理方式的差异,一个是后处理上采样的方式,特别是当宽高比不一致时损失更大,当然考虑精度对齐预处理也可以使用 letterbox 方式
- 对比图如下(上图-Python 官方,下图-C++ 部署实现)

结语
博主在这里针对 YOLO26-Sem 的预处理和后处理做了简单分析,同时与大家分享了 C++ 上的实现流程,目的是帮大家理清思路,更好的完成后续的部署工作😄。感谢各位看到最后,创作不易,读后有收获的看官请帮忙点个👍⭐️
最后大家如果觉得 tensorRT_Pro-YOLOv8 这个 repo 对你有帮助的话,不妨点个 ⭐️ 支持一波,这对博主来说非常重要,感谢各位🙏。