在linux软件开发过程中,我们常遇到使用top指令发现某一进程性能占用过高,或者被要求降低某一进程CPU占用的情况。本文将从调试、开发和测试三方面来针对进程性能占用进行分析和优化。
1.调试阶段
在调试过程中,我们需要定位性能瓶颈在哪里。这个阶段的目标是找到代码中消耗 CPU 时间最多的函数或代码路径。
使用perf top 可以实时显示当前系统中 CPU 占用最高的函数,或者使用perf top -p <PID>可以针对某一特定进程查看其中函数对CPU的占用情况。
注意:perf的权限由/proc/sys/kernel/perf_event_paranoid中的值决定,如遇权限不足的情况,请修改/proc/sys/kernel/perf_event_paranoid中的值为-1
输出结果如下格式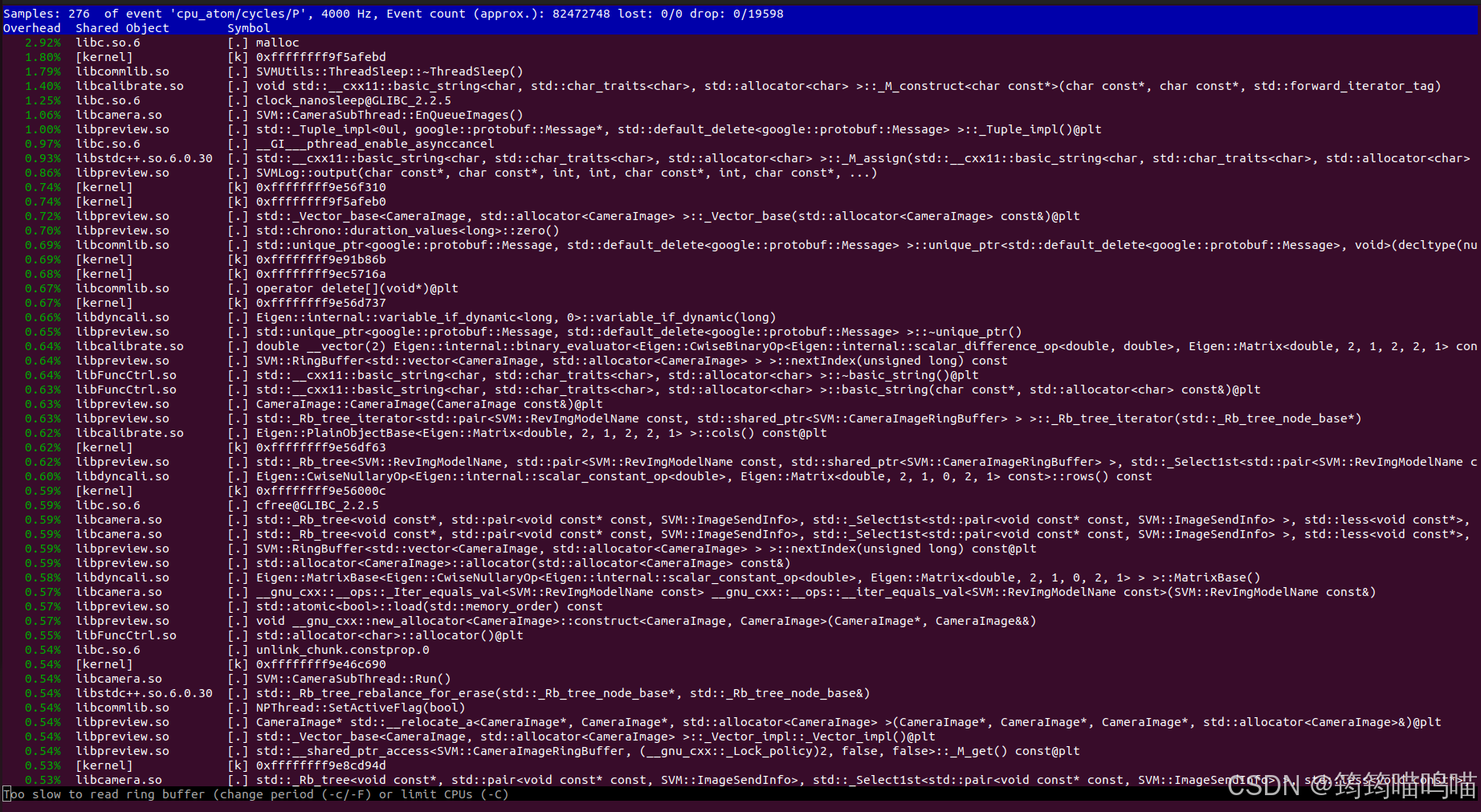
如果需要更详细的数据信息,也可以录制一段时间的数据(例如录制 30 秒)
bash
perf record -g -p <PID> -- sleep 30
perf report -g graph输出结果类似下图: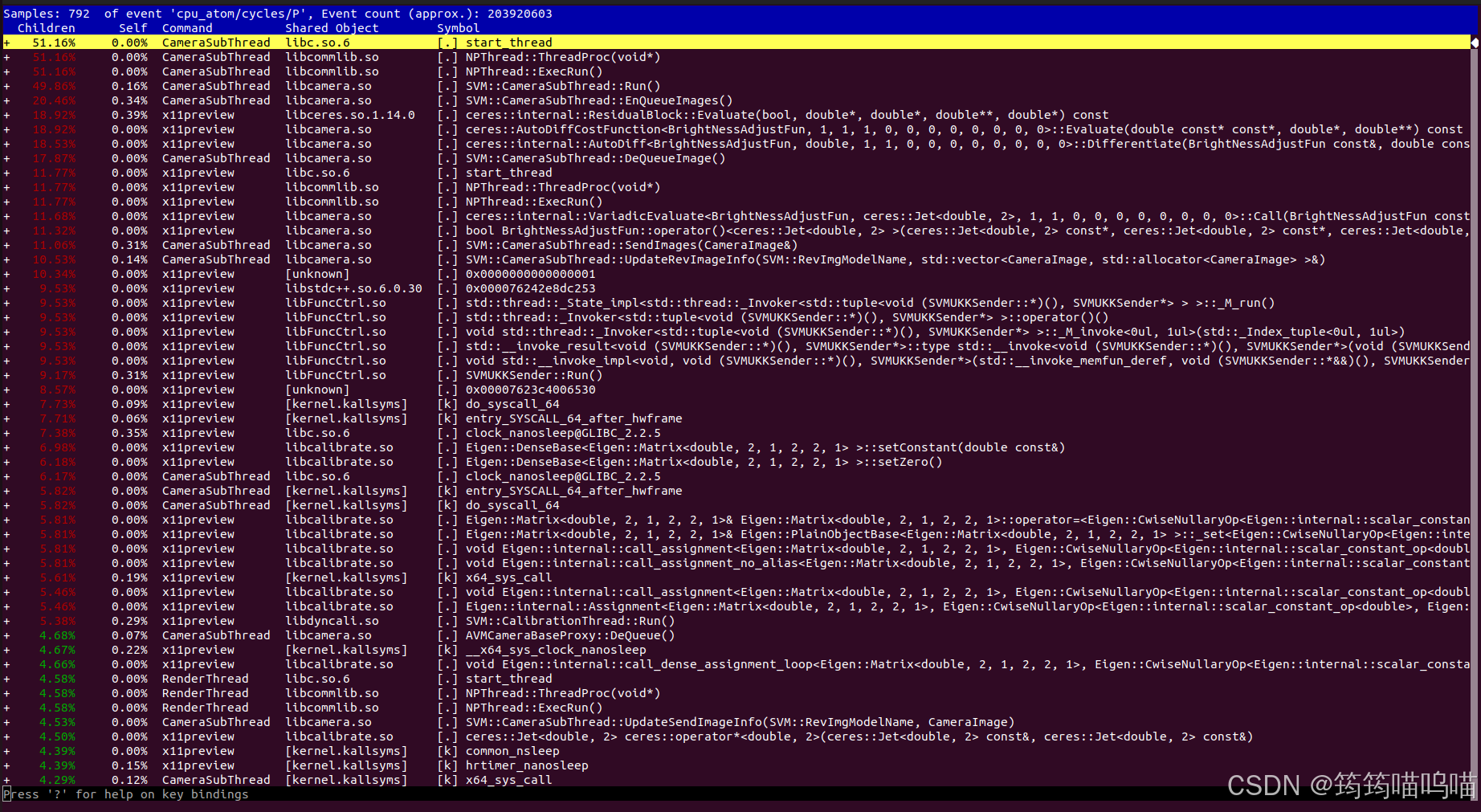
在 perf report 中,按上下键浏览,按回车展开调用栈,可以看到热点是从哪个函数调用过来的。
2.开发阶段
除了针对调试过程中使用perf找到的频繁调用或性能占用过高的函数进行优化外,还可以通过绑核的方式优化CPU缓存。
现代 CPU 通常采用多级缓存架构:L1 和 L2 缓存是每个 CPU 核心私有的,而 L3 缓存则由所有核心共享。当一个进程在不同的 CPU 核心之间频繁切换时,其缓存内容会不断被清空和重新填充,导致缓存命中率下降,从而影响性能。
在代码中调用 sched_setaffinity() 将每个线程绑定到指定核心可以提高缓存命中率从而优化CPU性能。
cpp//
cpu_set_t cpuset;
CPU_ZERO(&cpuset);
CPU_SET(0, &cpuset);
pthread_setaffinity_np(pthread_self(), sizeof(cpuset), &cpuset);除了绑核优化,在开发阶段还可以从多个维度进行系统性优化。下表汇总了常见的优化类别、思路、说明及适用场景:
| 优化类别 | 优化思路 | 简要说明 | 典型适用场景 |
|---|---|---|---|
| 内存管理 | 内存池 / 对象池 | 预分配连续内存块,O(1) 分配与回收,避免频繁 malloc/free | 高频创建销毁的对象(网络连接、任务队列、游戏实体) |
| 预先分配(Preallocation) | 启动时一次性申请大块内存,运行时切片使用 | 实时系统、嵌入式设备、延迟敏感型服务 | |
| 减少内存分配次数 | 合并小分配,使用容器预扩容(如 vector::reserve) |
数据处理、字符串拼接、动态数组频繁增长 | |
| 内存对齐(Alignment) | 用 alignas(64) 等对齐到缓存行边界,避免伪共享 |
多线程共享数据结构、高性能环形缓冲区 | |
| 并发与锁 | 无锁编程(Lock‑Free) | 基于原子操作(CAS)实现线程安全,避免阻塞与上下文切换 | 高并发队列、计数器、统计指标收集 |
| 读写锁替代互斥锁 | 允许多个读者并发,仅在写者修改时互斥 | 配置读取多、写入少的场景(路由表、黑白名单) | |
| 减少锁粒度 | 将大锁拆分为多个小锁(如分片锁、分段锁) | 哈希表、大数组的并行访问 | |
| 线程局部存储(TLS) | 为每个线程独立保存副本,消除锁竞争 | 随机数生成器、累加统计(每个线程先累加,最后汇总) | |
| 编译器优化 | 链接时优化(LTO) | 跨编译单元的内联和常量传播,生成更紧凑的代码 | 大型多文件项目,静态链接的程序 |
| 配置文件引导优化(PGO) | 基于运行采样数据优化分支预测、代码布局 | 发布前最终优化,典型工作负载固定的服务 | |
| 明确分支预测(likely/unlikely) | 用 __builtin_expect 告知编译器哪条分支更常执行 |
错误处理路径、冷热分离代码 | |
| I/O 优化 | 异步 I/O(AIO / io_uring) | 不阻塞调用线程,内核完成后再通知 | 高并发网络服务器、大量磁盘读写(数据库、日志) |
| 零拷贝(Zero‑Copy) | 利用 sendfile、splice 或 mmap 避免用户态与内核态之间拷贝数据 |
文件服务器、大文件传输 | |
| 批量读写(Batching) | 积累多次小 I/O 为一次大 I/O(如 readv/writev) |
日志输出、网络数据包聚合 | |
| 指令级优化 | 减少分支误预测 | 将数据驱动分支改为表查找或布尔运算 | 状态机、解析器、协议处理 |
| 避免数据依赖链 | 调整计算顺序,减少同一寄存器的写后读等待 | 循环中多个累加器、多项式求值 |
3.测试阶段
通过以下指令测试修改前后的应用,并检查其性能指标是否得到了优化:
bash
# 测试优化前的版本
perf stat -e cycles,instructions,cache-misses,branch-misses ./myapp_old
# 测试优化后的版本
perf stat -e cycles,instructions,cache-misses,branch-misses ./myapp_new-
cycles / instructions:每指令周期数,即执行一条指令平均所需的 CPU 周期数。该值越低,表示 CPU 在每个时钟周期内能执行更多指令。
-
cache-misses:CPU 访问数据或指令时,所需内容不在 L1/L2/L3 缓存中、必须从主存读取的次数。该值越高,访存延迟越严重。
-
branch-misses:分支预测失败的次数。CPU 猜错条件跳转的方向时,会冲刷流水线并重新取指,该值越高表示预测错误越频繁。