一、理论基础:从单智能体到多智能体
1.1 单智能体的能力边界与瓶颈
经过前面的学习,我们已经掌握了工业级单智能体的开发,但在面对复杂任务时,单智能体存在以下无法突破的瓶颈:
| 瓶颈类型 | 具体表现 | 工业级场景示例 |
|---|---|---|
| 能力单一 | 单个智能体无法同时精通多个领域 | 一份财务报告需要数据分析师、财务专家、文案专家共同完成 |
| 注意力有限 | 任务复杂度提升时,容易遗漏关键信息 | 分析 100 页的行业报告,单智能体容易出现信息遗漏和幻觉 |
| 效率低下 | 只能串行执行任务,无法并行处理 | 同时检索多个数据源、生成多个章节的报告 |
| 容错性差 | 单个步骤出错会导致整个任务失败 | 工具调用失败后,单智能体容易陷入死循环或给出错误答案 |
| 可扩展性差 | 新增能力需要修改原有代码,违反开闭原则 | 为智能体添加代码生成能力,需要修改整个思考逻辑 |
1.2 多智能体系统的核心价值与本质
多智能体系统(Multi-Agent System, MAS)的本质是 "分而治之" 的软件工程思想在 AI 领域的延伸 。它将一个复杂的大任务分解为多个简单的小任务,每个小任务由一个专门的智能体负责,通过智能体之间的协作共同完成目标。
核心价值:
- 专业专精:每个智能体只专注于一个领域,通过提示词工程和微调可以达到专家级水平
- 并行处理:多个智能体可以同时执行独立的子任务,大幅提升系统效率
- 容错性强:单个智能体出错不会影响整个系统,其他智能体可以发现并纠正错误
- 可扩展性好:新增能力只需要添加新的智能体,不需要修改原有代码
- 复杂度可控:将复杂任务分解为多个简单子任务,降低系统设计和调试难度
- 团队协作:模拟人类团队的工作方式,更容易被企业用户理解和接受
1.3 多智能体系统的核心架构与协作模式
1.3.1 三种核心架构深度对比
| 架构类型 | 核心思想 | 适用场景 | 优点 | 缺点 | 工业级成熟度 |
|---|---|---|---|---|---|
| 主从式架构 | 一个主智能体负责全局协调和任务分配,多个从智能体负责执行具体任务 | 任务分配、流程控制、项目管理 | 结构简单、易于控制、逻辑清晰 | 主智能体成为性能瓶颈和单点故障 | ★★★★★ |
| 对等式架构 | 所有智能体地位平等,自主决策,通过消息传递进行通信和协作 | 分布式决策、群体智能、去中心化系统 | 容错性强、可扩展性好、负载均衡 | 协调难度大、容易出现冲突、通信开销大 | ★★★☆☆ |
| 流水线式架构 | 智能体按顺序执行任务,前一个智能体的输出是后一个智能体的输入 | 内容生成、数据处理、流水线作业 | 逻辑清晰、易于调试、性能稳定 | 灵活性差、无法并行处理、瓶颈在最慢的环节 | ★★★★★ |
1.3.2 四种常见协作模式深度解析
-
分工协作模式
- 核心思想:将任务分解为多个独立的子任务,每个智能体负责一个子任务
- 示例:研究员收集数据 → 分析师分析数据 → 写作家生成报告 → 设计师制作图表
- 适用场景:结构化、流程化的任务
- 关键技术:任务分解、结果汇总、阶段切换
-
评审迭代模式
- 核心思想:一个智能体生成结果,另一个智能体评审并提出修改意见,迭代优化直到满足要求
- 示例:程序员写代码 → 代码审查员审查代码 → 程序员修改代码 → 再次审查
- 适用场景:对质量要求高的任务
- 关键技术:评审标准、迭代控制、终止条件
-
并行处理模式
- 核心思想:多个智能体同时执行独立的子任务,最后汇总结果
- 示例:同时检索市场数据、竞品数据、用户数据,然后汇总分析
- 适用场景:数据收集、信息检索、多源数据聚合
- 关键技术:并行执行、结果合并、冲突解决
-
协商决策模式
- 核心思想:多个智能体通过协商达成一致决策
- 示例:多个专家智能体共同诊断疾病,投票得出最终结论
- 适用场景:复杂决策、风险评估、专家系统
- 关键技术:投票机制、协商协议、冲突解决
1.4 LangGraph 多智能体实现原理深度解析
LangGraph 并没有提供专门的 "多智能体" 类,而是通过 "状态共享 + 节点分工 + 路由控制" 的方式实现多智能体系统,这也是 LangGraph 最强大和最优雅的设计之一。
核心原理:
- 状态共享:所有智能体共享同一个全局状态(State),这是智能体之间通信的唯一方式
- 节点分工:每个智能体对应图中的一个节点,负责执行一个特定的任务
- 路由控制:路由函数根据当前状态决定下一个执行哪个智能体节点
- 工具共享:所有智能体可以共享同一个工具集,也可以拥有自己的私有工具
- 特性复用:原生支持 Checkpoint、人类介入、流式输出等所有单智能体的高级特性
LangGraph 多智能体 vs 其他框架:
- 无需学习新的 API,完全复用单智能体的知识和经验
- 状态统一管理,避免了复杂的通信协议和消息传递
- 性能更高,没有额外的通信开销和序列化开销
- 调试更简单,可以通过 LangSmith 追踪整个系统的执行过程
1.5 多智能体系统设计的五大原则
- 单一职责原则:每个智能体只能有一个明确的角色和职责,不要让一个智能体做太多事情
- 明确边界原则:每个智能体的任务边界要清晰,输入输出要明确
- 状态最小化原则:状态应该只存储必要的信息,避免状态过大导致性能问题
- 可观测性原则:每个智能体的输入输出都要记录日志,便于调试和审计
- 容错性原则:设计时要考虑到智能体可能出错的情况,要有错误处理和降级机制
二、核心实战:"研究员 + 写作家" 双智能体系统
我们将实现一个工业级的双智能体报告生成系统,这是企业中最常见的多智能体应用场景。整个系统采用流水线式架构,分为两个阶段:研究阶段和写作阶段。
2.1 第一步:系统设计与状态定义
2.1.1 角色与职责设计(核心理论)
为什么选择 "研究员 + 写作家" 的分工?
- 这是人类社会最经典的分工模式之一,经过了长期的实践验证
- 研究和写作需要完全不同的能力:研究需要严谨、准确、逻辑性强;写作需要创造力、表达能力、结构化思维
- 这种分工可以让每个智能体专注于自己擅长的领域,大幅提升输出质量
- 便于后续扩展:可以添加评审员、设计师等角色,而不需要修改原有代码
详细的角色与职责定义:
| 智能体 | 角色定位 | 核心能力 | 输入 | 输出 | 拥有的工具 | 温度设置 |
|---|---|---|---|---|---|---|
| 研究员 | 信息收集与分析专家 | 信息检索、数据分析、要点整理、信息评估 | 用户的报告需求 | 结构化的研究要点 | 企业知识库检索、计算器、当前时间 | 0.1(低温度,保证准确性) |
| 写作家 | 内容生成与润色专家 | 大纲生成、内容撰写、文字润色、结构化输出 | 研究员的研究要点 | 完整的商业报告 | 无(只负责生成内容) | 0.7(高温度,提升创造性) |
2.1.2 状态设计(核心理论)
多智能体状态设计的核心原则:
- 复用优先:尽可能复用已有的状态字段,避免重复定义
- 分层设计:将状态分为基础层、多智能体层、业务层
- 增量更新:消息历史等字段使用增量更新,避免覆盖历史数据
- 可追踪性:添加任务阶段、迭代次数等字段,清晰记录系统的执行过程
状态定义与代码实现:
python
# core/multi_agent.py
from typing import List, Annotated
from pydantic import BaseModel, Field
from langchain_core.messages import BaseMessage
import operator
from enum import Enum
# 复用第8天的审核状态
from core.react_agent import ApprovalStatus
class TaskPhase(str, Enum):
"""任务阶段枚举,清晰标记系统当前处于哪个阶段"""
RESEARCH = "research" # 研究阶段
WRITING = "writing" # 写作阶段
REVIEW = "review" # 评审阶段(预留扩展)
COMPLETED = "completed" # 完成阶段
class MultiAgentState(BaseModel):
"""双智能体系统状态(分层设计)"""
# 基础层:复用单智能体的通用字段
messages: Annotated[List[BaseMessage], operator.add] = Field(default_factory=list)
iteration_count: int = Field(default=0)
max_iterations: int = Field(default=10) # 多智能体迭代次数更多
user_id: str = Field(default="default_user")
# 多智能体层:多智能体系统通用字段
task_phase: TaskPhase = Field(default=TaskPhase.RESEARCH)
current_agent: str = Field(default="researcher")
# 业务层:报告生成业务特有字段
research_notes: str = Field(default="", description="研究员整理的结构化研究要点")
report_outline: str = Field(default="", description="报告大纲(预留扩展)")
report_draft: str = Field(default="", description="报告草稿(预留扩展)")
final_report: str = Field(default="", description="最终生成的完整报告")
# 审核层:复用第8天的审核字段
approval_status: ApprovalStatus = Field(default=ApprovalStatus.PENDING)
approver: str = Field(default="")
approval_comment: str = Field(default="")2.2 第二步:研究员智能体实现
2.2.1 研究员智能体设计核心理论
研究员的核心能力模型:
- 需求理解能力:准确理解用户的报告需求,明确需要收集哪些信息
- 信息检索能力:熟练使用各种工具检索相关信息
- 信息筛选能力:从大量信息中筛选出有用的信息
- 信息整理能力:将筛选后的信息整理成结构化的要点
- 信息评估能力:评估信息是否足够生成一份完整的报告
研究员提示词设计原则:
- 明确任务边界:明确告诉研究员只负责收集和整理信息,不生成完整报告
- 强调准确性:所有信息必须来自工具检索,绝对不能编造
- 结构化输出:要求研究员输出结构化的要点,便于写作家使用
- 明确终止条件:告诉研究员什么时候应该结束研究,进入写作阶段
- 工具使用指导:详细说明每个工具的使用场景和方法
2.2.2 核心代码实现
python
from core.llm_factory import LLMFactory
from core.tools import PRODUCTION_TOOLS
from langgraph.prebuilt import ToolNode
from utils.logger import logger
# 初始化LLM并绑定工具(研究员需要使用工具)
researcher_llm = LLMFactory.get_llm(temperature=0.1) # 低温度,保证准确性
researcher_llm_with_tools = researcher_llm.bind_tools(PRODUCTION_TOOLS)
# 研究员系统提示词
RESEARCHER_PROMPT = """
你是一位专业的企业研究员,擅长收集和分析信息。
你的任务是:
1. 深入理解用户的报告需求
2. 使用提供的工具检索相关信息
3. 整理成清晰、结构化的研究要点
4. 评估信息是否足够生成一份完整的报告
5. 如果信息不足,继续检索;如果足够,将研究要点传递给写作家
你必须严格遵守以下规则:
1. 所有信息必须来自工具检索,绝对不能编造
2. 研究要点要全面、准确、有条理
3. 每个要点都要有对应的信息来源
4. 当你认为信息足够时,明确说"研究完成,可以开始写作"
5. 不要生成完整的报告,只生成研究要点
你可以使用以下工具:
{tools_description}
"""
tools_description = "\n".join([f"- {tool.name}: {tool.description}" for tool in PRODUCTION_TOOLS])
researcher_system_message = SystemMessage(content=RESEARCHER_PROMPT.format(tools_description=tools_description))
def researcher_node(state: MultiAgentState) -> dict:
"""研究员智能体节点"""
logger.info(f"🔍 研究员开始工作,迭代次数:{state.iteration_count}/{state.max_iterations}")
# 构建消息列表:系统提示词 + 对话历史
messages = [researcher_system_message] + state.messages
# 调用LLM
response = researcher_llm_with_tools.invoke(messages)
# 检查是否超过最大迭代次数
if state.iteration_count >= state.max_iterations:
logger.warning("⚠️ 超过最大迭代次数,强制进入写作阶段")
return {
"messages": [response],
"iteration_count": state.iteration_count + 1,
"task_phase": TaskPhase.WRITING,
"research_notes": response.content
}
# 检查是否研究完成
if "研究完成" in response.content and "可以开始写作" in response.content:
logger.info("✅ 研究完成,进入写作阶段")
return {
"messages": [response],
"iteration_count": state.iteration_count + 1,
"task_phase": TaskPhase.WRITING,
"research_notes": response.content
}
# 否则继续研究
return {
"messages": [response],
"iteration_count": state.iteration_count + 1
}关键设计要点:
- 低温度设置:研究员需要准确性,所以设置 temperature=0.1
- 明确的任务边界:研究员只负责收集和整理信息,不生成完整报告
- 自动阶段切换:当研究员说 "研究完成" 时,自动切换到写作阶段
- 安全限制:设置最大迭代次数,防止无限研究
2.3 第三步:写作家智能体实现
写作家智能体负责将研究员的研究要点转化为一份专业、结构化的报告。
python
# 初始化写作家LLM(不需要工具,高温度提升创造性)
writer_llm = LLMFactory.get_llm(temperature=0.7)
# 写作家系统提示词
WRITER_PROMPT = """
你是一位专业的企业文案写作专家,擅长撰写结构化、专业的商业报告。
你的任务是:
1. 根据研究员提供的研究要点生成一份完整的商业报告
2. 报告结构要清晰,包含标题、摘要、正文、结论等部分
3. 语言要专业、准确、简洁,符合企业内部沟通规范
4. 所有内容必须基于研究员提供的研究要点,不能添加任何外部信息
5. 生成完成后,明确说"报告生成完成"
报告结构要求:
# 报告标题
## 一、摘要
简要概括报告的核心内容和结论
## 二、研究背景
说明报告的目的和背景
## 三、核心发现
分点列出最重要的研究发现
## 四、详细分析
对每个核心发现进行详细分析
## 五、结论与建议
总结报告内容,提出具体的建议
研究员的研究要点:
{research_notes}
"""
def writer_node(state: MultiAgentState) -> dict:
"""写作家智能体节点"""
logger.info("✍️ 写作家开始工作")
# 构建提示词,包含研究员的研究要点
prompt = WRITER_PROMPT.format(research_notes=state.research_notes)
# 调用LLM生成报告
response = writer_llm.invoke(prompt)
logger.info("✅ 报告生成完成")
return {
"messages": [response],
"iteration_count": state.iteration_count + 1,
"task_phase": TaskPhase.COMPLETED,
"final_report": response.content
}关键设计要点:
- 高温度设置:写作家需要一定的创造性,所以设置 temperature=0.7
- 结构化输出:明确要求报告的结构,保证输出的一致性
- 严格的信息边界:所有内容必须基于研究员的研究要点,防止幻觉
- 自动完成标记:生成完成后明确标记,便于系统识别
2.4 第四步:协作流程与路由函数设计
路由函数是多智能体系统的大脑,它决定了下一个执行哪个智能体。
python
from langgraph.graph import END
def multi_agent_router(state: MultiAgentState) -> str:
"""多智能体路由函数,决定下一个执行的节点"""
last_message = state.messages[-1]
# 检查是否有工具调用(研究员需要调用工具)
if last_message.tool_calls:
logger.info(f"🔧 研究员需要调用工具:{[tc['name'] for tc in last_message.tool_calls]}")
return "tools"
# 根据任务阶段路由
if state.task_phase == TaskPhase.RESEARCH:
return "researcher"
elif state.task_phase == TaskPhase.WRITING:
return "writer"
elif state.task_phase == TaskPhase.COMPLETED:
return END
else:
logger.error(f"❌ 未知的任务阶段:{state.task_phase}")
return END路由逻辑:
- 如果有工具调用,先执行工具节点
- 如果处于研究阶段,执行研究员节点
- 如果处于写作阶段,执行写作家节点
- 如果任务完成,结束执行
2.5 第五步:构建与编译双智能体图
python
from langgraph.graph import StateGraph
from core.checkpoint import postgres_checkpointer # 复用第8天的Checkpoint
def build_research_writer_agent() -> StateGraph:
"""构建研究员+写作家双智能体系统"""
builder = StateGraph(MultiAgentState)
# 添加节点
builder.add_node("researcher", researcher_node)
builder.add_node("tools", ToolNode(PRODUCTION_TOOLS))
builder.add_node("writer", writer_node)
# 添加边
builder.add_edge("tools", "researcher") # 工具执行完回到研究员
builder.add_edge("writer", END) # 写作家执行完结束
# 添加条件边
builder.add_conditional_edges("researcher", multi_agent_router)
# 设置入口点
builder.set_entry_point("researcher")
# 编译图,配置Checkpoint和中断点
graph = builder.compile(
checkpointer=postgres_checkpointer,
interrupt_before=["writer"] # 在写作前添加中断点,支持人工审核研究结果
)
logger.info("✅ 研究员+写作家双智能体系统构建完成")
return graph
# 全局单例
research_writer_agent = build_research_writer_agent()三、项目整合:将双智能体集成到现有系统
3.1 升级 RAGService,支持双智能体
python
# core/rag_service.py
# 在原有导入基础上添加
from core.multi_agent import research_writer_agent, TaskPhase
from langchain_core.messages import HumanMessage
class RAGService:
# 原有方法保持不变...
# ======================
# 新增:双智能体报告生成
# ======================
def generate_report(
self,
topic: str,
user_id: str,
auto_approve: bool = False
) -> dict:
"""
生成报告(双智能体系统)
:param topic: 报告主题
:param user_id: 用户ID
:param auto_approve: 是否自动批准研究结果,跳过人工审核
"""
config = {"configurable": {"thread_id": f"report_{user_id}_{int(time.time())}"}}
logger.info(f"用户[{user_id}]请求生成报告:{topic}")
# 启动双智能体系统
result = research_writer_agent.invoke(
{
"messages": [HumanMessage(content=topic)],
"user_id": user_id
},
config=config
)
state = research_writer_agent.get_state(config)
# 如果需要人工审核
if state.next and "writer" in state.next:
if auto_approve:
logger.info("自动批准研究结果,继续生成报告")
result = research_writer_agent.invoke(None, config=config)
return {
"task_id": config["configurable"]["thread_id"],
"status": "completed",
"report": result["final_report"]
}
else:
return {
"task_id": config["configurable"]["thread_id"],
"status": "pending_review",
"research_notes": state.values["research_notes"],
"message": "研究完成,等待人工审核"
}
# 如果已经完成
return {
"task_id": config["configurable"]["thread_id"],
"status": "completed",
"report": result["final_report"]
}
def approve_research(self, task_id: str) -> dict:
"""批准研究结果,继续生成报告"""
config = {"configurable": {"thread_id": task_id}}
state = research_writer_agent.get_state(config)
if not state.next or "writer" not in state.next:
raise ValueError("当前任务不需要审核或已被处理")
logger.info(f"批准任务{task_id}的研究结果,开始生成报告")
result = research_writer_agent.invoke(None, config=config)
return {
"task_id": task_id,
"status": "completed",
"report": result["final_report"]
}
def reject_research(self, task_id: str, reason: str) -> dict:
"""拒绝研究结果,要求重新研究"""
config = {"configurable": {"thread_id": task_id}}
logger.info(f"拒绝任务{task_id}的研究结果,原因:{reason}")
# 更新状态,添加拒绝消息,让研究员重新研究
research_writer_agent.update_state(
config,
{
"messages": [HumanMessage(content=f"研究结果被拒绝,原因:{reason}。请重新研究。")],
"task_phase": TaskPhase.RESEARCH
}
)
# 重新执行研究员节点
result = research_writer_agent.invoke(None, config=config)
state = research_writer_agent.get_state(config)
return {
"task_id": task_id,
"status": "pending_review",
"research_notes": state.values["research_notes"],
"message": "已重新研究,等待再次审核"
}3.2 新增双智能体 API 接口
python
# main8.py
# 在原有请求模型基础上添加
class ReportRequest(BaseModel):
topic: str
user_id: str
auto_approve: bool = False
class TaskIdRequest(BaseModel):
task_id: str
reason: str = ""
# 在原有接口基础上添加
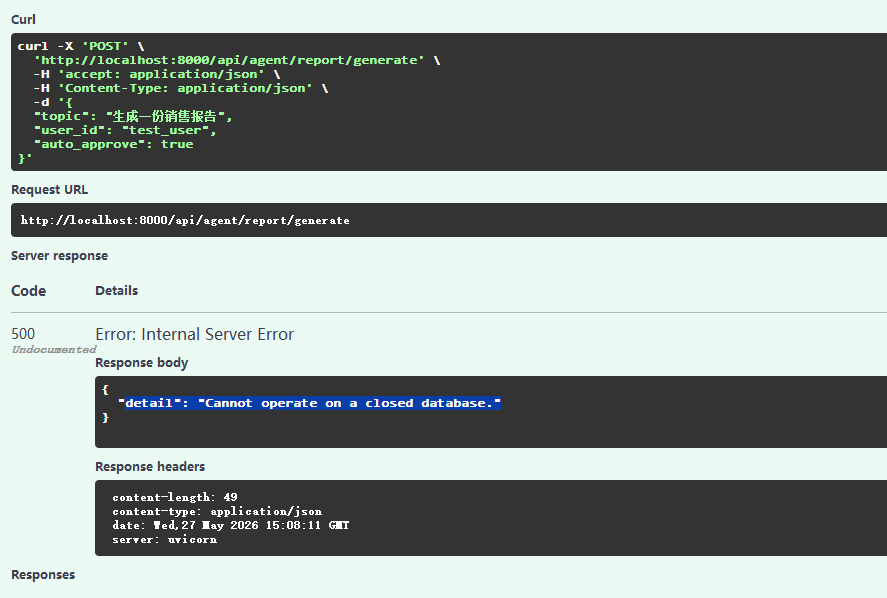
@app.post("/api/agent/report/generate")
async def generate_report(request: ReportRequest):
"""生成报告(双智能体系统)"""
try:
return rag_service.generate_report(
topic=request.topic,
user_id=request.user_id,
auto_approve=request.auto_approve
)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.post("/api/agent/report/approve")
async def approve_report(request: TaskIdRequest):
"""批准研究结果,生成报告"""
try:
return rag_service.approve_research(request.task_id)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.post("/api/agent/report/reject")
async def reject_report(request: TaskIdRequest):
"""拒绝研究结果,要求重新研究"""
try:
return rag_service.reject_research(request.task_id, request.reason)
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
访问时遇到以下问题,下一节处理。