一.大模型应用
1.定义
说白了,就是将"传统编程"、"AI大模型"结合起来,优缺互补。
即:利用大模型的推理、分析、生成能力,再结合传统编程的计算、控制能力来实现的混合式应用。
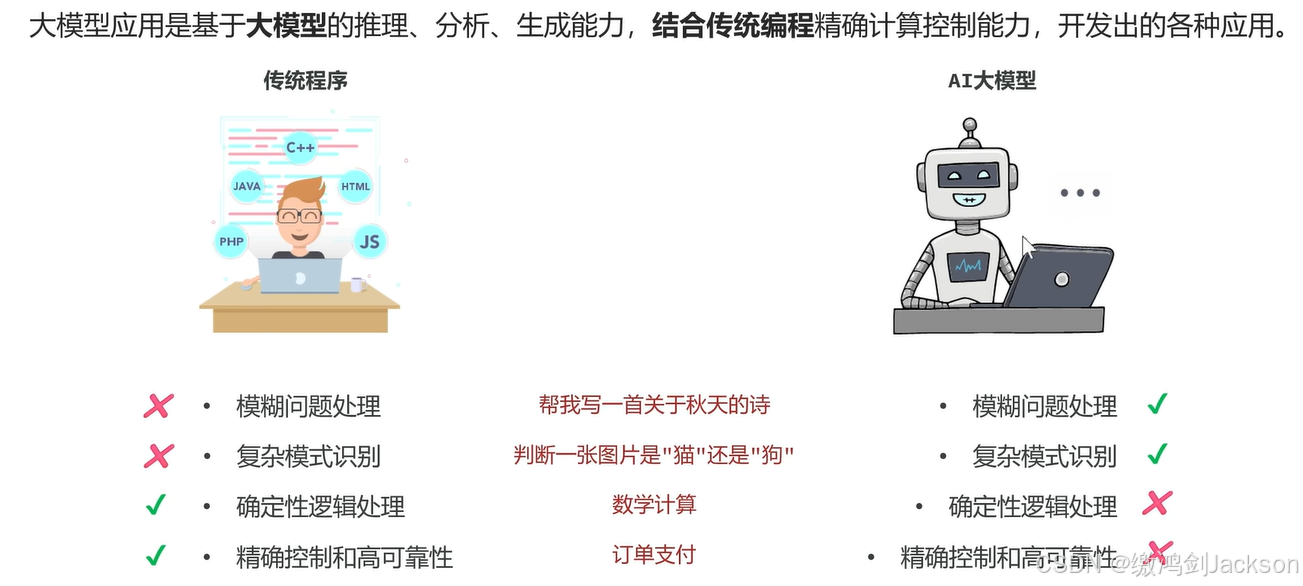

举例
- GPT是大语言模型
- ChatGpt是基于GPT的一个对话产品,是一种大模型应用
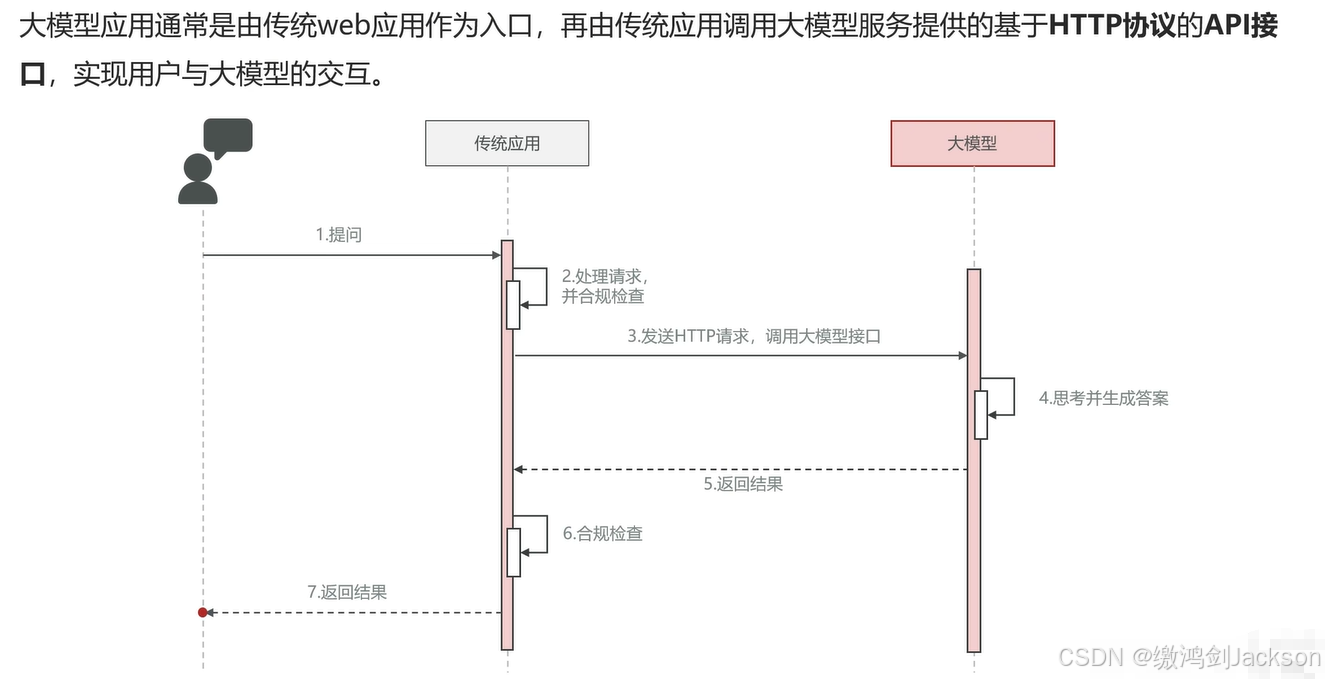
2.应用结构图
二.大模型服务
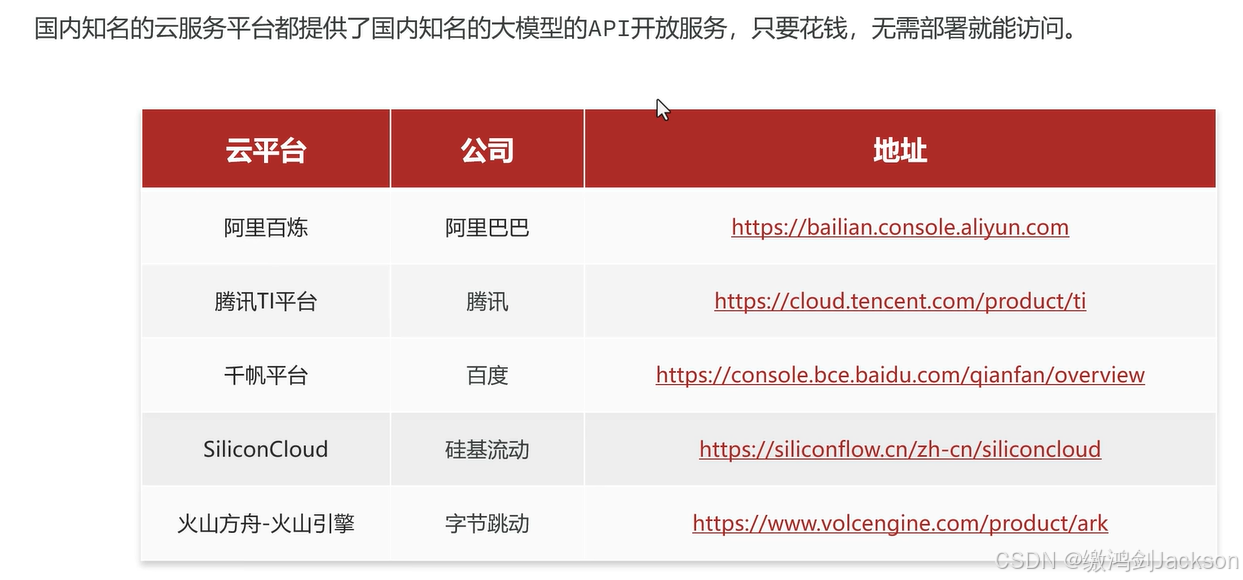
1.获取大模型服务的方式
①大模型API
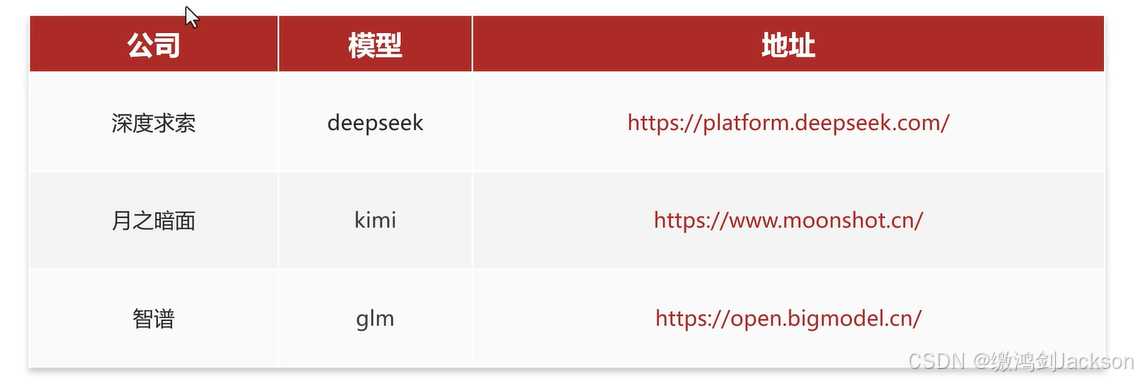
②私有部署
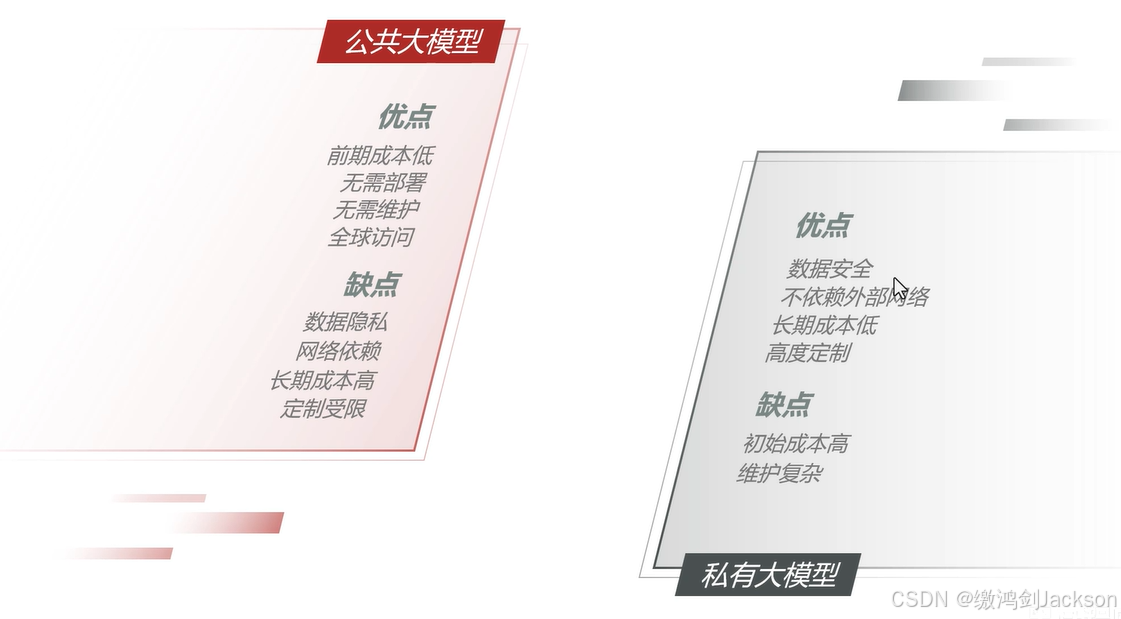
优缺点对比
2.注册、使用DeepSeek的大模型API
官网地址:
①登录
②实名认证
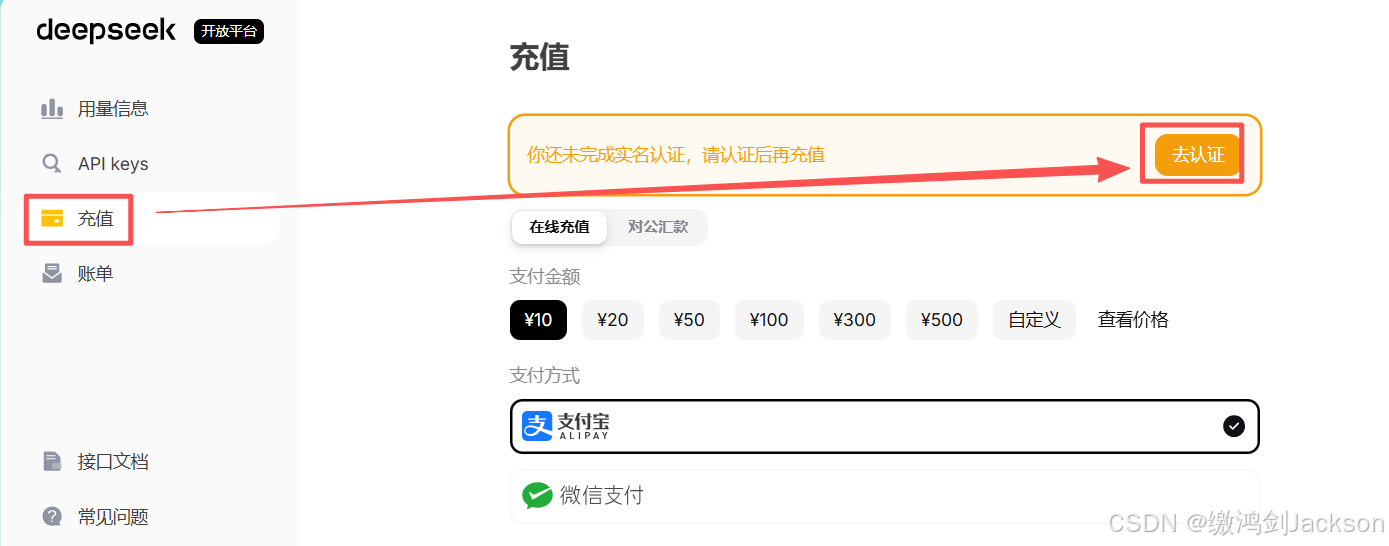
③充值(可选,但是花不了几块,不是很贵)
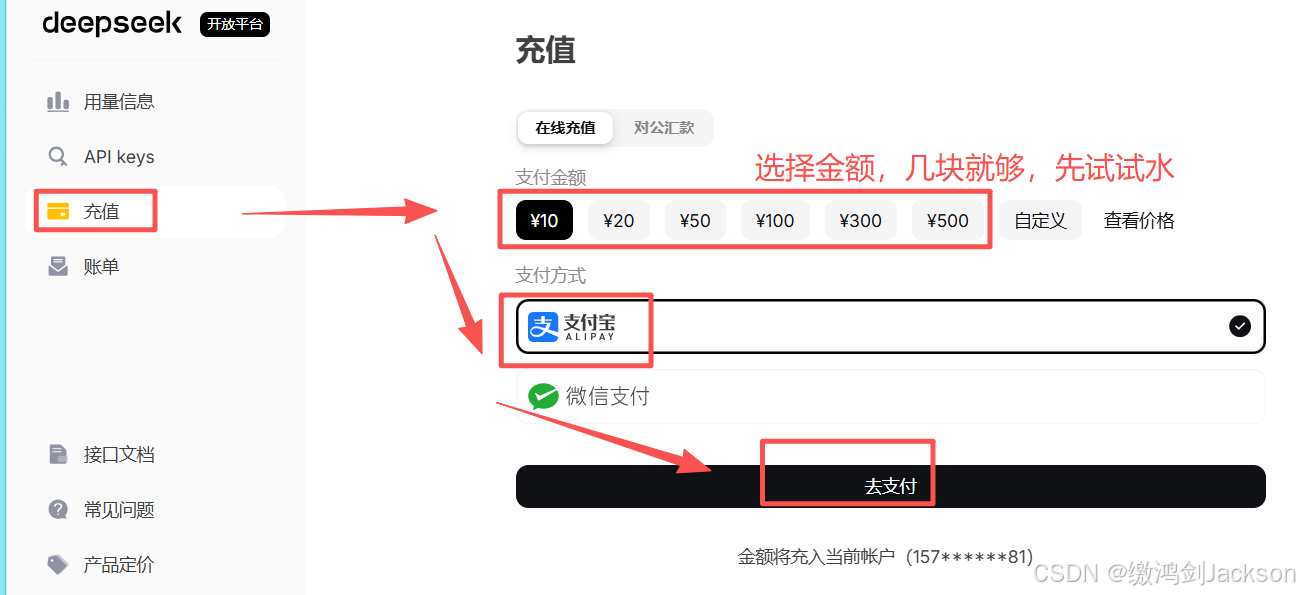

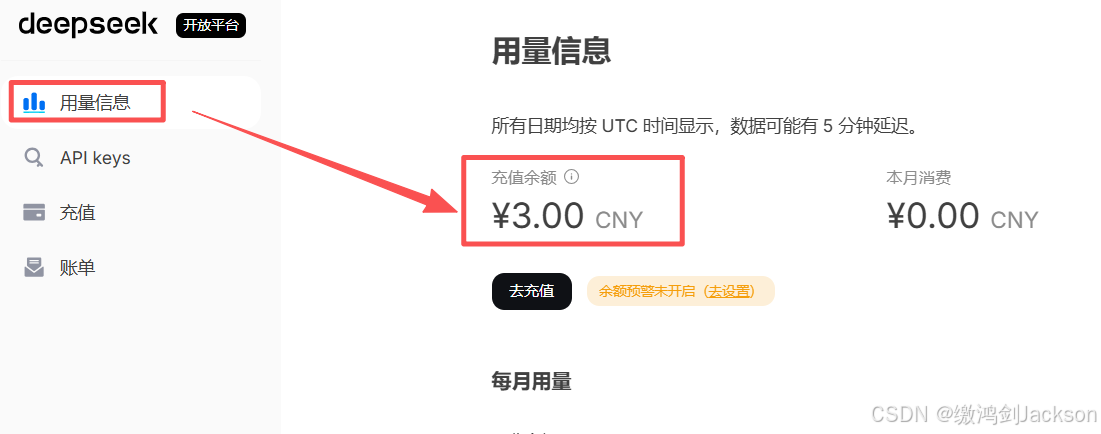
我们此时只充了3块钱,先试试水。
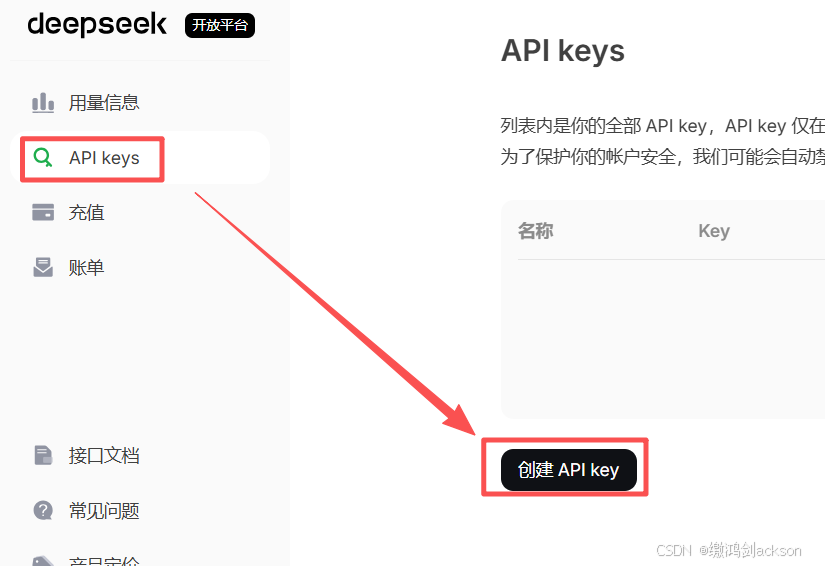
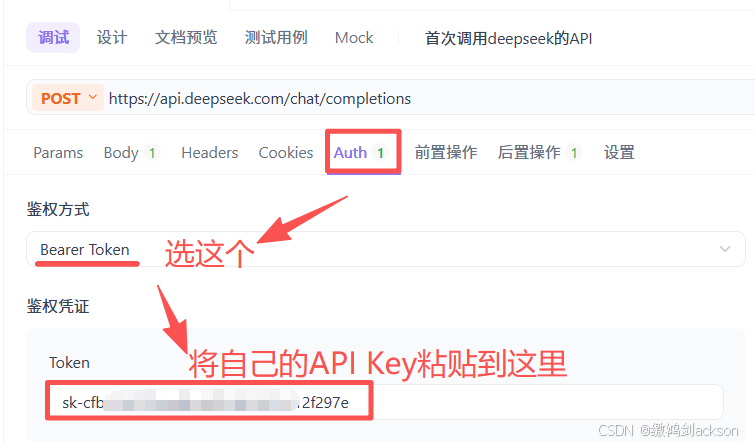
④创建API Key,保护账号安全
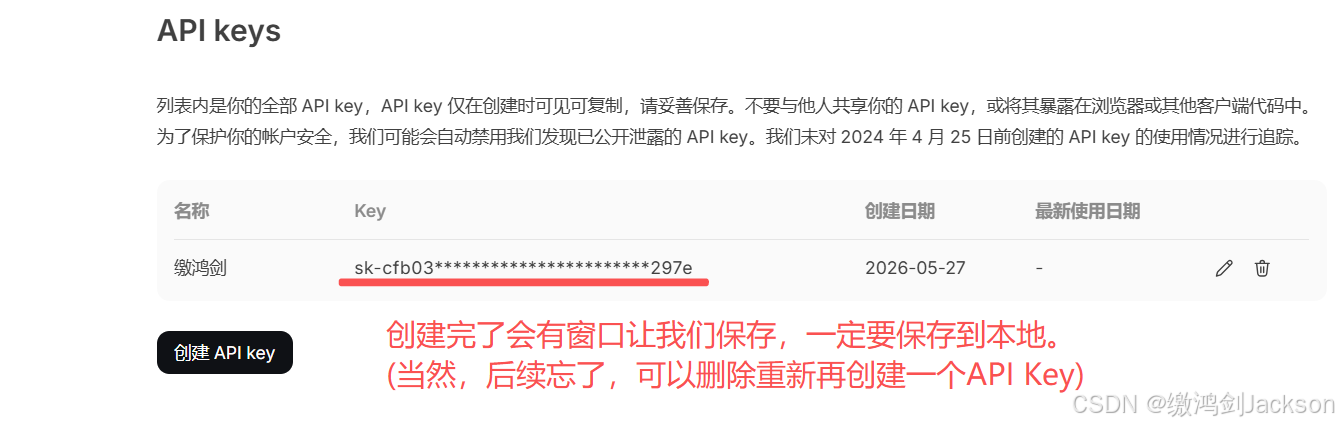
⑤首次调用API(重要)
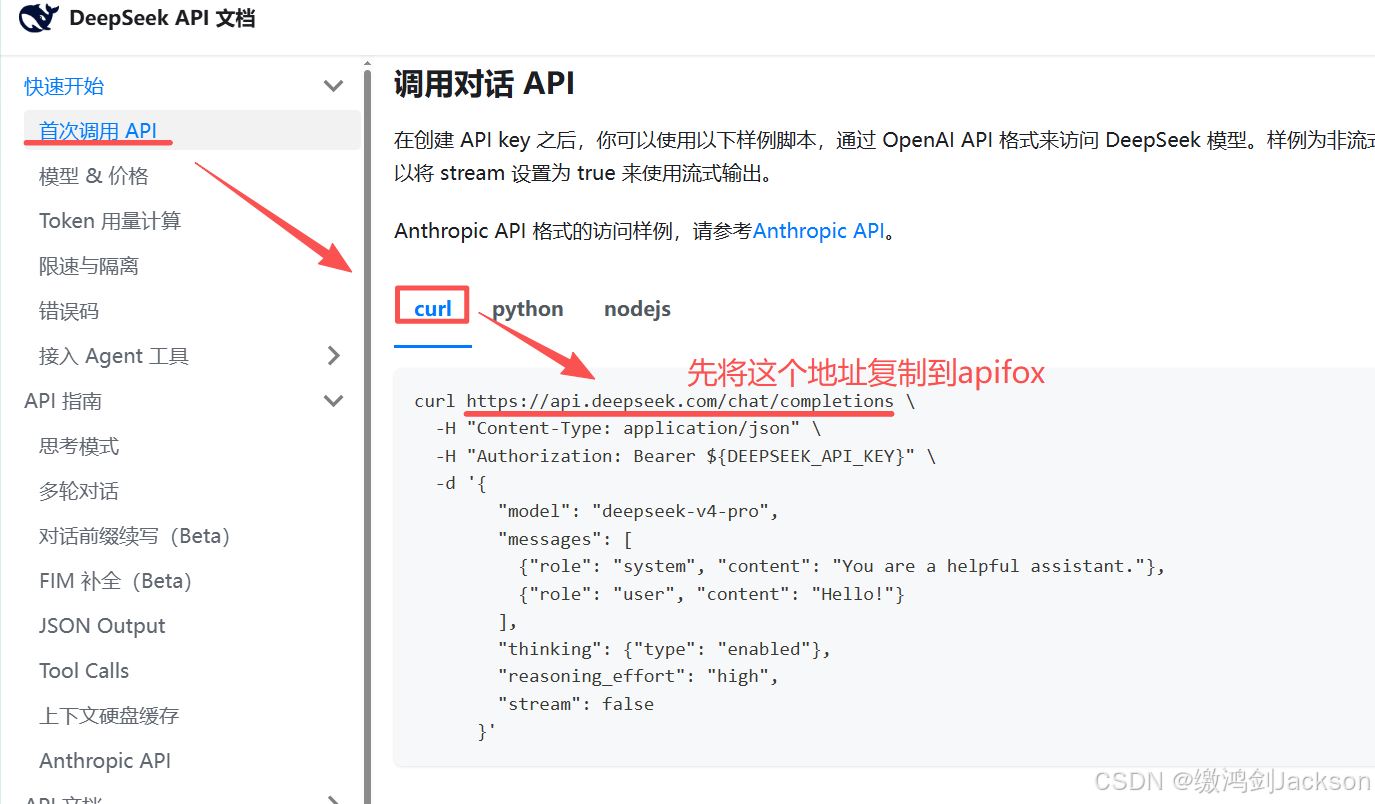
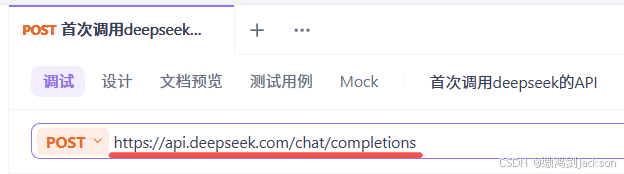
第一步:先用apifox创建一个post请求
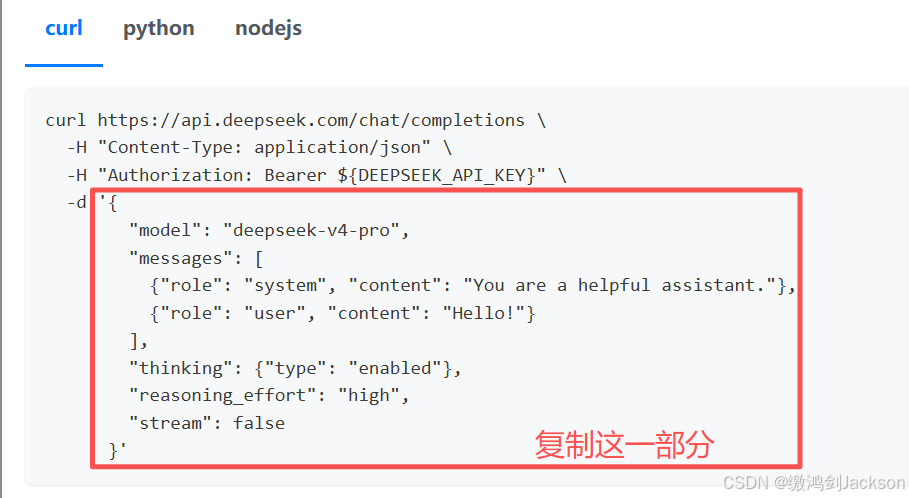
第二步:将下图CURL中的ip赋值到apifox
第三步:设置自己的API Key到Auth认证的Bear中
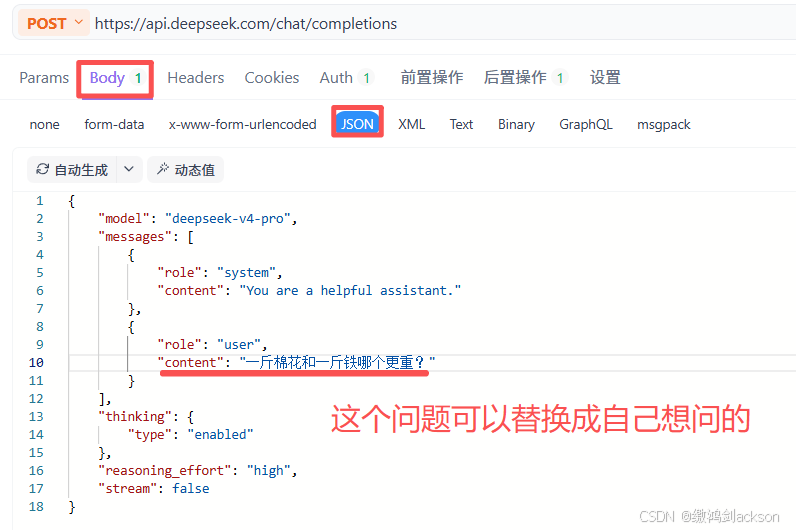
第四步:将下图CURL中的JSON复制到apifox中
最后,查看返回结果即可:


3.注册、使用阿里百炼的大模型API
官网地址:
https://bailian.console.aliyun.com
后续操作和上述DeepSeek大差不差,可自行前往探索,此处不做赘述。
三.大模型API
1.接口规范
主要包含三部分:
- 平台的基础URL(DeepSeek、千问等平台各有自己的基础URL)
- API Key要放到请求的Authorization认证下的Bearer中
- 要发Post请求,请求体用Body/JSON来传输,JSON格式如下图所示

除了下面的这些字段,还有很多,我们可以自行去DeepSeek官方网站中查看。
rust
{
"model": "deepseek-v4-pro", // 指定要使用的模型名称(如版本或变体)
"messages": [ // 对话消息列表,包含系统提示和用户输入
{
"role": "system", // 消息角色:系统级指令,定义助手的行为方式
"content": "You are a helpful assistant." // 系统提示内容,让模型扮演一个乐于助人的助手
},
{
"role": "user", // 消息角色:用户提出的问题或请求
"content": "一斤棉花和一斤铁哪个更重?" // 用户实际输入的文字
}
],
"thinking": { // 控制模型内部"思考"过程的配置(非标准字段,可能是自定义扩展)
"type": "enabled" // 开启显式的思考步骤(让模型生成推理过程后再输出答案)
},
"reasoning_effort": "high", // 控制推理的深度或计算投入程度(例如 low/medium/high)
"stream": true // 是否启用流式输出(true 表示逐字返回,false 表示一次性返回完整结果)
}2.会话记忆
①先看一个问题

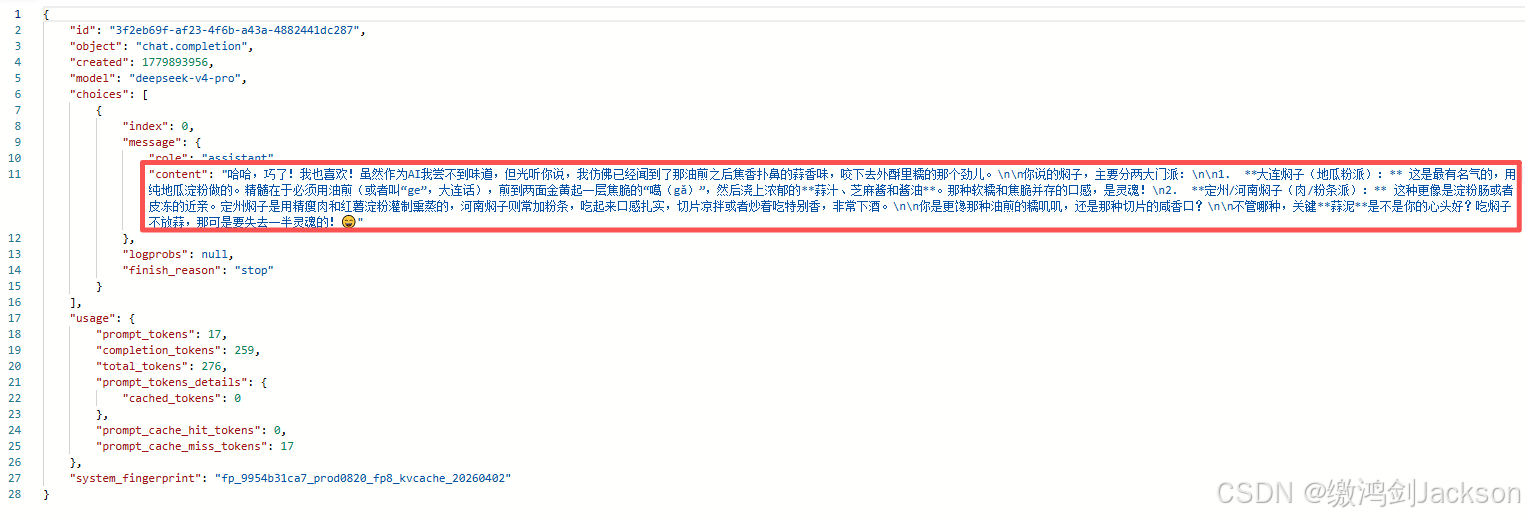
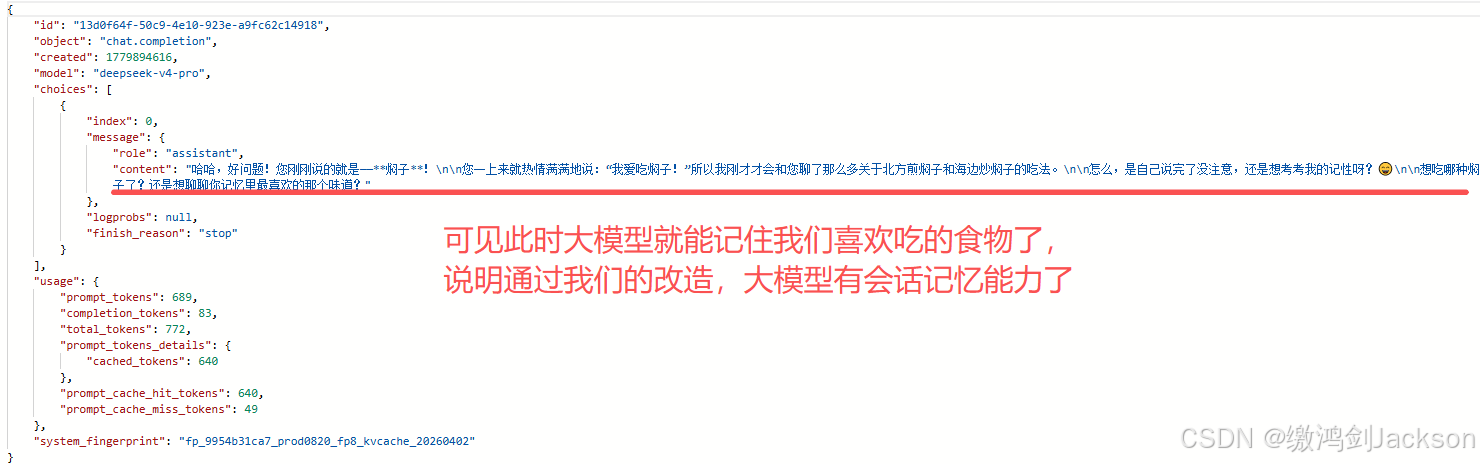
此时AI做出了评价。
下面我们反问AI我们喜欢吃什么

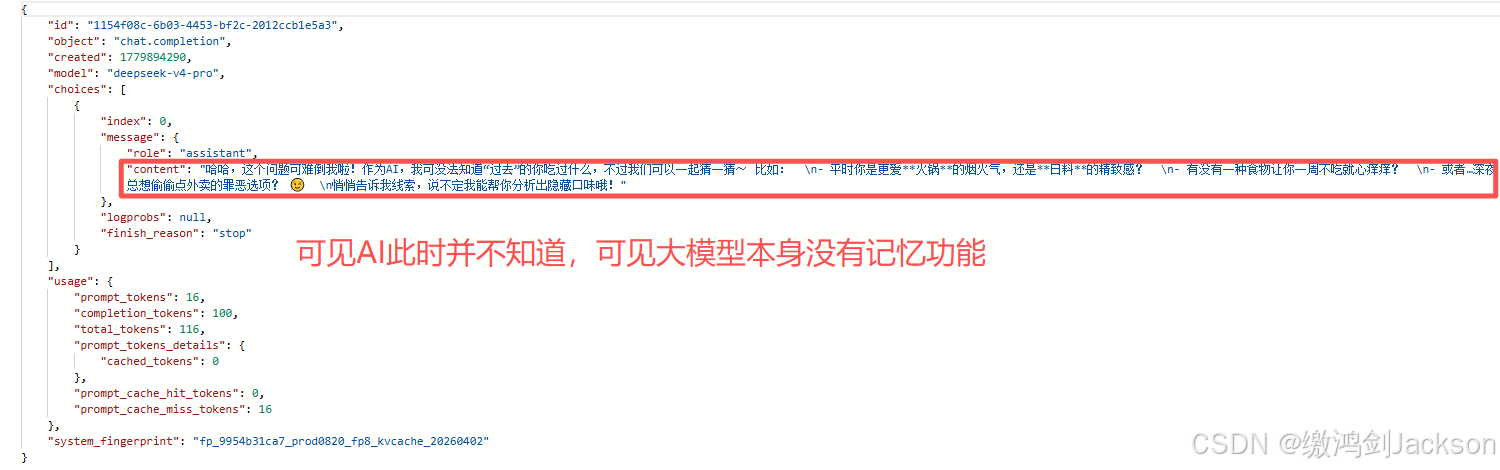
②结论:大模型本身没有记忆功能
③解决会话记忆问题

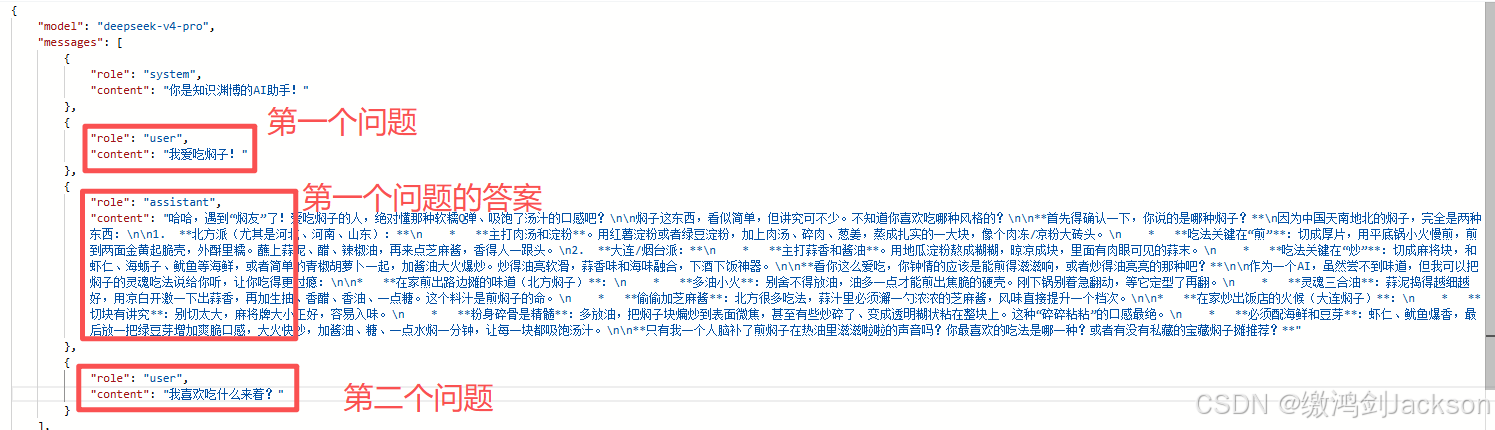
此时再调一下接口,看看大模型能否记住我们爱吃的食物