在前一篇文章中,我们聊了什么是 RAG 以及为什么它会成为当前企业级 AI 项目的"标配"。简单来说,RAG 就是让大模型在回答问题前先"开卷翻书"。
然而,在实际的工程落地中,RAG 绝对不是"把文档丢进数据库,然后调一下 OpenAI 接口"那么简单。一个能够真正支撑起商业应用、具备高准确率的 RAG 系统,其背后是一套精密协同的工程流水线。
今天这篇博客,我们就来 深度拆解 RAG 的完整工作流程。
RAG 核心生命周期概述
从整体架构上看,一个完整的 RAG 系统主要由两大核心流水线(Pipeline)组成:
-
数据准备阶段(Offline Pipeline - 离线流程): 负责把海量的原始文档进行清洗、切分、向量化,并安全地建立索引存储到向量数据库中。这相当于"建造一座数字化图书馆"。
-
检索与生成阶段(Online Pipeline - 在线流程): 当用户输入问题时,系统实时去"图书馆"中检索最相关的资料,融合成 Prompt 喂给大模型,最终输出答案。
下面,我们将顺着这两个阶段,一步步拆解其背后涉及的 10 个核心步骤。
第一部分:离线数据准备流水线(Data Ingestion)
数据准备是 RAG 系统的基石。如果输入的数据本身是混乱的,那么检索出来的结果必然也是错误的,即业界常说的"Garbage in, Garbage out"。
[原始文档] ──> [文档解析] ──> [文本分块(Chunking)] ──> [向量化(Embedding)] ──> [存入向量数据库]步骤 1:文档加载与多格式解析(Document Parsing)
企业内部的知识往往散落在各个角落,格式千奇百怪(PDF、Word、Excel、Markdown、HTML、PPT 等)。
-
技术难点: PDF 的解析是公认的行业痛点。双栏排版、页眉页脚、扫描件、论文中的复杂图表,都会导致解析出的文本顺序错乱、产生大量噪音。
-
工程实践:
-
对于结构简单的文档,常用 PyPDF、python-docx 等轻量级库。
-
对于复杂的 PDF 或包含表格的文档,通常需要引入基于深度学习的布局分析工具(如 LayoutLM、Marker)或 OCR 技术(如 PaddleOCR),甚至利用多模态大模型来对图表进行"结构化还原"。
-
步骤 2:文本清洗与预处理(Data Cleaning)
解析出来的纯文本不能直接使用,需要剔除与核心知识无关的噪音。
-
处理内容: 去除不必要的换行符、HTML 标签、控制字符;脱敏敏感信息(如身份证、手机号);处理统一的简写与术语映射。
-
目的: 提高数据的纯净度,避免噪音对后续的向量化特征提取产生干扰。
步骤 3:智能文本分块(Text Chunking)
大模型由于受到上下文窗口(Context Window)的限制,无法直接吞下整个长篇大论;同时,过长的文本会导致检索粒度太粗。因此,必须将长文本切割成一个个小的"文本块(Chunk)"。
-
主流分块策略:
-
固定大小分块(Fixed-size Chunking): 设定固定 token 长度(如 500 token),并设置一定的重叠度(Overlap,如 50 token)。重叠度的存在是为了防止两块语义在切分点被强行割裂。
-
基于规则/结构的切分(Structure-aware Chunking): 顺着 Markdown 的标题级别(
#,##)、段落标签(\n\n)进行自然切分,保证每块内容的逻辑完整性。 -
语义切块(Semantic Chunking): 利用轻量级 Embedding 模型计算相邻句子的语义相似度,当发现前后两句话的语义发生了断崖式下跌,就自动在这里切一刀。
-
步骤 4:文本向量化(Text Embedding)
把切好的文本块(Chunk)转化为计算机看得懂的稠密向量(Dense Vector)。
-
原理: Embedding 模型(如 OpenAI 的
text-embedding-3、开源的BGE、M3E)会将一段文本映射到一个高维空间(通常是 768 或 1536 维)。如果两个文本块谈论的是同一件事,它们在这条高维空间里的距离就会非常近。 -
注意点: 必须保证离线阶段向量化文本 使用的 Embedding 模型,与在线阶段向量化用户问题使用的模型是同一个,否则检索完全失效。
步骤 5:建立索引与存入向量数据库(Vector Storage)
将"向量"连同对应的"原始文本(Payload)"以及"元数据(Metadata,如文件名、作者、页码、修改时间)"一起存入向量数据库。
- 索引加速技术: 为了在海量向量中实现毫秒级搜索,向量数据库(如 Milvus、Qdrant、Pinecone、Chroma)不会用最原始的蛮力挨个对比,而是会构建近似最近邻索引(ANN),最常用的就是 HNSW(Hierarchical Navigable Small World) 图索引或 IVF(Inverted File) 倒排索引。
第二部分:在线检索与增强流水线(Retrieval & Augmentation)
当用户在界面上敲下回车,提出一个问题时,在线流程瞬间启动。这套流程追求的是高并发、低延迟、高准确。
[用户提问] ──> [Query 优化] ──> [混合检索] ──> [重排(Rerank)] ──> [上下文压缩] ──> [大模型生成]步骤 6:用户查询预处理与优化(Query Transformation)
用户输入的原始问题往往含糊不清、口语化严重,甚至存在错别字。直接拿去检索,效果往往不佳。
-
进阶工程手段:
-
Query Rewrite(查询改写): 利用一个轻量级大模型,结合当前的对话上下文,把口语化的提问改写成语义清晰、更适合检索的学术/技术语。
-
Query Expansion(查询扩展/Hypothetical Document Embeddings - HyDE): 预先让大模型生成一页"假设性正确答案",然后拿着这个"假答案"去数据库里检索。因为"假答案"和"真答案"的形式、用词极其相似,这能显著提升检索召回率。
-
步骤 7:多模态/混合检索(Hybrid Search)
在检索阶段,如果只用向量检索,很容易漏掉特定型号、专有名词、编码等关键信息。
-
混合检索方案: 现在的优秀 AI 项目都会采用 向量检索 + 传统关键词检索(BM25) 的双路并发机制。
-
向量检索: 负责捕捉"苹果手机好用吗"与"iPhone 体验如何"之间的底层语义关联。
-
关键词检索(BM25): 负责精准匹配"A16芯片"、"SKU-9023"等生硬的特有字符。
-
-
检索计算: 向量数据库在后台通过数学公式计算 Query 向量与库中 Chunk 向量的距离。例如最常用的余弦相似度(Cosine Similarity):
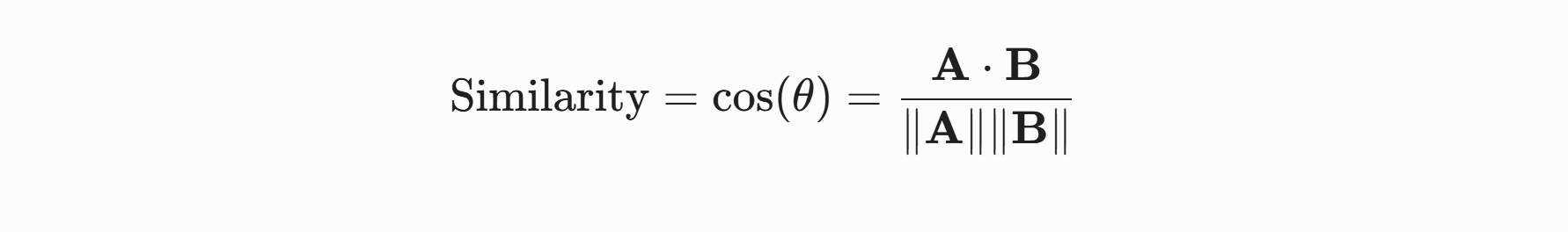
步骤 8:双路合并与重排(Reranking)
混合检索出来的两条链路结果(比如向量检索返回了 10 条,关键词检索返回了 10 条),如何将它们融合并合理排序?
-
RRF(Reciprocal Rank Fusion): 一种纯数学工程算法,根据两个列表的排名名次进行加权融合,不需要额外算力。
-
Reranker 模型重排(核心关键): 融合后的初筛结果(如 Top-20)会被送入一个专门的 重排模型(Cross-Encoder,如 BGE-Reranker)。
- 为什么不一开始就用重排模型? 因为重排模型计算极其精准且耗时,无法在大规模库里做全局搜索。但在初筛出的 20 条数据里做精细化打分,耗时只有几十毫秒。它会完全从语义契合度出发,重新排定前 3~5 条真正最关键的信息(Top-K)。
步骤 9:提示词拼接与上下文压缩(Prompt Augmentation)
拿到了最精准的几条文本块,接下来不能直接把它们大喇喇地塞给大模型,还需要面对"中间丢失(Lost in the Middle)"的现象------大模型往往容易记住上下文的开头和结尾,忽视中间的内容。
-
处理方式: * 将分数最高的 Chunk 放置在上下文的最前和最后。
- 利用 LLMLingua 等上下文压缩工具,剔除文本块中的废话、停用词,只保留高信息密度的词汇,既节省大模型的 Context Token,又能提高响应速度。
-
Prompt 组装: 将压缩后的上下文、用户的原始问题,以及系统角色设定(System Prompt)组装成一个结构化的输入。
第三部分:大模型生成与后处理流水线(Generation & Post-processing)
步骤 10:大模型生成(Generation)
大模型(LLM)接收到精心准备的"开卷考试题"后,开始进行推理生成。
-
工程配置: * 通常将
temperature(温度)设置为较低的值(如 0.0 或 0.1),以确保其回答严格基于参考资料,减少随机性。- 开启
Stream(流式输出),让答案像打字机一样逐字蹦出,极大优化前端用户的交互体验。
- 开启
补充步骤:后处理与安全护栏(Post-processing & Guardrails)
在商业落地项目中,大模型输出后,往往还会有一层看不见的"安全筛"。
-
幻觉核查(Fact-Checking): 检查生成的答案中提到的实体、数据,是否真的出现在检索出的文档中。
-
合规性过滤: 敏感词过滤、防反动、防涉密审查。
-
格式化提取: 如果是 Agent 或下游系统调用,后处理阶段还会用正则或大模型结构化输出(Structured Outputs)强制将答案转化为 JSON 格式。
RAG 完整流程核心指标一览表
优化一个 RAG 系统,就像是在调校一台复杂的跑车。为了帮助大家在日常开发中进行性能调优,我们可以把这些技术节点总结为以下的关键考核维度:
| 阶段 | 核心组件 | 关键优化手段 | 评估指标 |
|---|---|---|---|
| 数据准备 | 文档解析、切块 | 语义切块、OCR版面分析、Chunk 重叠度 | 解析准确率、分块语义完整度 |
| 检索阶段 | 混合检索、向量库 | 引入 HNSW 索引、Query 改写、HyDE | 召回率(Recall):能搜到正确答案 |
| 重排阶段 | Cross-Encoder | 引入 BGE/Cohere Reranker 模型 | 精确率(Precision):排在最前的确实最相关 |
| 生成阶段 | 大模型、提示词 | 低温度系数(Temperature)、上下文压缩 | 忠实度(Faithfulness):无幻觉、答到点子上 |
结语
RAG 的表面是一个简单的"检索 + 生成"闭环,其工程内核却是一个链路极长的系统性工程。文档解析的颗粒度、切块的优雅度、双路检索的互补度、重排模型的敏感度,这其中的任何一个细节出现短板,都会导致最终的用户体验大打折扣。
在当前的 AI Agent(智能体)时代,RAG 更是成为了 Agent 获取记忆、调用工具、实现长期规划的底层依赖。理解了这 10 个步骤,你就抓住了当前 AI 落地项目的技术命脉。
