前言
大模型(Large Language Model,LLM)正在成为企业智能化转型的核心基础设施。从客服机器人、内容生成到代码辅助开发,大模型 API 已经成为现代应用架构中不可或缺的组件。然而,随着大模型 API 的大规模接入,一个严峻的问题浮出水面:如何确保大模型接口的安全?
2023 年至 2024 年间,国内外多个大模型平台相继曝出 API Key 泄露、Token 盗刷、异常并发等安全事件。这些事件不仅造成了直接的经济损失(Token 费用被恶意消耗),更带来了数据泄露和隐私合规的风险。因此,构建一套完善的大模型接口鉴权与访问控制体系,是每一个接入大模型能力的企业必须正视的核心技术命题。
本文将从安全威胁分析出发,深入剖析主流鉴权方案的技术原理与适用场景,详细讲解签名算法的工程实现,展示基于 RBAC 的细粒度权限控制设计,提供 Spring Security 与大模型网关集成的实战方案,并覆盖 Token 管理、限流配额、审计日志、敏感数据脱敏等企业级必备的安全机制。文章配套的四张技术架构图(接口鉴权体系架构图、Token 生成与验证流程图、RBAC 权限模型图、API 安全防护体系图)将帮助读者建立系统性的安全架构视图。
────────────────────────────────────────────────────────────
一、大模型接口的安全威胁分析
1.1 API Key 泄露:最常见也是最危险的漏洞
API Key 是调用大模型服务的第一道凭证。大多数大模型提供商(OpenAI、Anthropic、Azure OpenAI、Google Gemini 等)都采用静态 API Key 作为主要的认证手段。这种方式简单直接,但一旦泄露,攻击者即可在无需任何额外验证的情况下,以受害者的账户余额无限调用大模型服务。
API Key 泄露的途径多种多样:
前端代码泄露是最常见的场景。很多开发者在开发阶段习惯将 API Key 硬编码在前端 JavaScript 代码中,然后部署到生产环境。攻击者只需打开浏览器的开发者工具,查看 Network 请求或者在 Console 中搜索关键词,就能轻易获取明文传输的 API Key。即便是经过压缩混淆的代码,也无法抵御有经验攻击者的逆向。
Git 泄露同样触目惊心。开发者可能在一个公有仓库中意外提交了包含真实 API Key 的代码,或者在 CI/CD 流水线的日志中输出了敏感的 Key 信息。GitHub Secret Scanning、GitLab Secret Detection 等工具虽然能够检测一部分泄露,但仍然无法覆盖所有场景。
日志文件泄露也是一个被忽视的途径。在调试阶段打印完整的 HTTP 请求和响应日志,可能会将 Authorization Header 中的 API Key 一并记录。如果日志文件没有得到妥善保护,攻击者获取服务器访问权限后就能从中提取 Key。
第三方服务泄露同样值得警惕。如果企业使用的日志服务、监控平台或者 API 管理平台发生数据泄露,攻击者同样可能获取到存放在这些平台中的 API Key。
1.2 Token 滥用:细水长流式的持续消耗
与 API Key 泄露的急性爆发不同,Token 滥用更像是一种慢性攻击。攻击者在获取到有效的访问令牌后,并不会立即进行大规模调用,而是以一个相对低的频率、长时间地使用受害者的额度。这种攻击方式很难被短期的用量异常检测发现,但日积月累也会造成可观的损失。
Token 滥用的典型场景包括:攻击者获取 Token 后,以每小时几十次调用的频率长期挂载,持续消耗受害者的账户余额;或者攻击者将获取的 Token 打包成 API 代理服务,出售给第三方使用,同时从多个受害者账户中抽取额度。
Token 滥用之所以难以检测,核心原因在于其流量模式与正常使用的界限模糊。正常的 API 调用往往也具有一定的随机性和稀疏性,这使得简单的用量阈值告警容易产生误报。
1.3 并发盗刷:burst 流量导致的瞬时穿透
大模型服务的计费通常基于 Token 数量和 API 调用次数。一些服务商会设置每分钟或每秒的并发限制,但如果攻击者使用了分布式IP、多账号绕过或者利用某些接口的竞态条件,就可能突破这些限制,在短时间内消耗大量额度。
并发盗刷的特点是突发性强、峰值极高。正常的业务调用即使在高峰期也很难在单分钟内触发数万次请求,但如果监控不及时,一次并发盗刷可能在几分钟内烧掉数千乃至数万元的额度。
这种攻击方式还可能与 Token 滥用结合:攻击者预先获取多个账户的认证信息,然后在特定时间窗口内同时发起大量请求,造成整体系统的服务降级,影响所有用户的使用体验。
1.4 提示词注入与数据泄露
大模型的安全威胁不仅来自外部攻击,内部的数据泄露风险同样不容忽视。提示词注入(Prompt Injection)是一种特殊攻击手段,攻击者通过在输入中嵌入恶意指令,诱导大模型泄露系统 Prompt、训练数据或者此前对话中的敏感信息。
例如,攻击者可能通过构造特殊的用户输入,覆盖系统指令中设定的安全边界,让大模型返回原本被限制访问的信息。在多租户场景下,如果不同租户的数据隔离不完善,还可能出现跨租户的数据泄露问题------用户A的对话历史可能被用户B通过精心构造的提示词诱导出来。
1.5 中间人攻击与通信链路窃听
虽然现代 Web 应用普遍使用 HTTPS 加密,但仍然存在 SSL 剥离攻击、证书伪造等手段窃听通信内容。如果企业内部的代理服务器、API 网关或者负载均衡器配置不当,可能导致请求内容在某些节点以明文形式传输。
大模型 API 调用通常涉及用户输入的敏感数据(如客户个人信息、商业机密等),如果这些数据在传输过程中被窃听,后果不堪设想。尤其是企业使用自建的大模型推理服务时,通信链路的安全性更需要重点关注。
────────────────────────────────────────────────────────────
二、主流鉴权方案对比:从 API Key 到 STS 临时凭证
2.1 API Key:简单但脆弱
API Key 是最为简单直接的鉴权方式。用户在平台注册后获得一对 Key(通常包含 Key ID 和 Secret Key),调用 API 时将 Key 放在 HTTP Header 或请求参数中传递给服务端。服务端根据 Key 识别调用者身份,并进行权限校验和配额管理。
优势体现在以下几个方面:
实现极为简单,API 提供商和消费者都能快速上手,集成成本低。适用性广,几乎所有大模型提供商都原生支持 API Key 认证。性能开销小,不需要复杂的签名计算或者加密操作。
劣势同样明显:
安全性有限,静态 Key一旦泄露无法自动撤销,必须依赖人工干预。权限粒度粗,API Key 通常绑定到账户级别,无法对不同应用、不同接口设置差异化的权限。无状态导致无法追踪具体操作,一个 Key 被多人共享使用时,难以区分不同调用者的行为。
适用场景:个人开发者快速验证、小规模内部使用、不涉及敏感数据的概念验证阶段。
2.2 JWT:自包含的无状态令牌
JSON Web Token(JWT) 是一种开放标准(RFC 7519),它将用户身份和声明信息编码为一个 JSON 对象,并使用数字签名保证内容的不可篡改性。JWT 由三部分组成:Header(头部,声明算法和类型)、Payload(载荷,包含声明信息)、Signature(签名,由前两部分与密钥计算得出)。
JWT 在大模型网关场景中的典型工作流程如下:
- 用户通过 API Key 或者用户名密码向鉴权服务器换取 JWT
- JWT 中包含了用户的身份标识(sub)、权限范围(scope)、过期时间(exp)等声明
- 后续所有 API 请求直接携带 JWT,无需再次验证 credentials
- 网关/服务端通过验证 JWT 签名和过期时间来确认请求有效性
JWT 结构示例:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.
eyJzdWIiOiJ1c2VyXzEyMyIsImV4cCI6MTcwOTI0MDAwMCwic2NvcGUiOiJsbG06Z2V0LWNoYXQ6Z3B0LTQifQ.
SflKxwRJSMeKKF2QT4fwpMeJf36POk6yJV_adQssw5c
优势:
无状态验证,JWT 本身包含了所有验证所需的信息,服务端无需维护会话存储,极大降低了存储压力和部署复杂度。支持细粒度声明,Payload 中可以灵活存储用户 ID、权限范围、配额额度、模型限制等信息。跨服务传递方便,JWT 可以在多个服务之间共享,适用于微服务架构。
劣势:
无法主动撤销,JWT 一旦签发,在过期之前一直有效。即使服务器端将用户加入黑名单,jwt 也无法感知。过期时间需要合理设计,过短导致频繁刷新影响体验,过长则增加安全风险。Payload 体积限制,虽然 JWT 可以存储丰富的信息,但过大的 Token 会增加每次请求的网络开销。
适用场景:微服务架构中的内部 API 调用、需要支持跨域认证的场景、对性能要求高且可以接受一定安全权衡的系统。
2.3 OAuth2:企业级的授权框架
OAuth2 是一个开放标准授权协议(RFC 6749),它允许第三方应用在用户授权的前提下,访问用户在资源服务器上的受保护资源,而无需获取用户的凭证。OAuth2 定义了四种授权模式:授权码模式(Authorization Code)、隐式模式(Implicit)、密码凭证模式(Resource Owner Password Credentials)和客户端凭证模式(Client Credentials)。
对于大模型 API 接入场景,最常用的是 授权码模式 和 客户端凭证模式。
授权码模式适用于有前端参与的应用(如 Web App、移动 App)。用户通过浏览器或 App 跳转到授权服务器登录并授权,授权服务器返回一个授权码,应用使用授权码换取访问令牌(Access Token)和刷新令牌(Refresh Token)。这种模式的最大优点是授权码不能直接用于访问资源,必须配合客户端凭证才能换Token,极大地降低了令牌泄露的风险。
客户端凭证模式适用于服务端到服务端的通信,没有用户参与。客户端使用自己的 Client ID 和 Client Secret 直接换取 Access Token。这种模式适合微服务之间或者 AI Agent 与大模型网关之间的通信。
OAuth2 的核心优势在于:
完整的授权流程,支持用户授权、Scope 细粒度控制、令牌刷新和撤销。标准成熟,生态完善,大多数语言和框架都有现成的 OAuth2 库和中间件。与 OIDC(OpenID Connect)结合,可以实现身份认证和授权的标准化。
劣势:
实现复杂度高,需要建设授权服务器、维护令牌状态、处理多种异常场景。性能开销较大,每次令牌刷新都需要与授权服务器通信。
2.4 STS 临时凭证:最小权限原则的极致实践
STS(Security Token Service) 是一种安全机制,用于签发临时访问凭证。AWS STS 是这种模式的典型代表,近年来也被引入到大模型 API 安全管理中。
STS 的核心思想是:不发放长期有效的静态凭证,而是按需签发具有短生命周期和有限权限的临时凭证。临时凭证通常包含三个要素:Access Key ID(临时访问密钥ID)、Secret Access Key(临时密钥)、Security Token(安全令牌)。此外,临时凭证还会绑定一个过期时间,通常在 15 分钟到 12 小时之间。
STS 的工作流程:
- 应用通过主账号或 IAM 角色向 STS 服务申请临时凭证
- STS 验证请求者的身份和权限,签发包含受限权限的临时凭证
- 应用使用临时凭证调用大模型 API
- 临时凭证过期后自动失效,需要重新向 STS 申请
优势:
安全性极高,即使临时凭证泄露,攻击者也只能在极短的时间窗口内使用,最大限度降低损失。最小权限原则,每个临时凭证只包含完成特定任务所需的最小权限集合。支持细粒度策略,可以针对不同的 API、不同的模型、不同的操作签发不同的凭证。
劣势:
实现复杂度最高,需要额外部署和维护 STS 服务,或者使用云提供商的托管 STS。客户端需要实现凭证的自动刷新逻辑,增加了开发工作量。临时凭证不支持主动撤销(因为它已经在倒计时了)。
2.5 方案对比总览
|------------|-------------|-----------|------------|------------------|
| 特性 | API Key | JWT | OAuth2 | STS 临时凭证 |
| 安全性 | 低 | 中 | 高 | 极高 |
| 实现复杂度 | 极低 | 低 | 高 | 高 |
| 细粒度权限 | 无 | 中 | 高 | 极高 |
| 无状态验证 | 支持 | 支持 | 否 | 支持 |
| 可撤销性 | 支持(删除Key) | 否(需加入黑名单) | 支持 | 不需要(自动过期) |
| 适用场景 | 内部/PoC | 微服务 | 企业应用 | 高安全敏感 |
| Token 生命周期 | 长期 | 可配置 | 可配置 | 极短(分钟级) |
在实际生产环境中,推荐的做法是组合使用多种方案:对外暴露的 API 使用 API Key 或 OAuth2 进行认证,内部微服务之间使用 JWT 进行无状态验证,涉及高敏感操作时使用 STS 临时凭证。通过多层防御(defense in depth),在不同层面部署不同的鉴权机制,即使某一层被攻破,攻击者仍然无法获得完整的系统权限。
────────────────────────────────────────────────────────────
三、签名算法实现:HMAC-SHA256 与 AES 加密
3.1 HMAC-SHA256:请求签名验证
HMAC-SHA256(Hash-based Message Authentication Code with SHA-256)是一种基于 SHA-256 哈希函数的消息认证码算法。它结合了哈希函数的单向性和消息认证码的密钥共享机制,能够有效验证消息的完整性和真实性。
在大模型 API 安全场景中,HMAC-SHA256 主要用于 请求签名验证。其核心思想是:客户端使用一个只有自己和服务器知道的密钥(Secret Key),对请求的关键信息(如时间戳、请求路径、请求体哈希等)进行签名计算,将签名结果附加在请求中发送到服务器。服务器使用同样的算法和密钥重新计算签名,与客户端传来的签名比对,如果一致则说明请求未被篡改。
HMAC-SHA256 签名计算过程:
待签名字符串 = HTTP_METHOD + "\n" +
REQUEST_PATH + "\n" +
TIMESTAMP + "\n" +
SHA256(REQUEST_BODY)
签名 = Base64(HMAC-SHA256(SECRET_KEY, 待签名字符串))
一个典型的签名请求头设置:
X-API-Key: ak_xxxxxxxxxxxx
X-Timestamp: 1709200000
X-Signature: sha256=YWJjZGVmZ2hpamtsbW5vcHFyc3R1dnd4eXoxMjM0NTY=
Authorization: Bearer eyJhbGciOiJIUzI1NiJ9...
Python 实现签名计算:
import hmac
import hashlib
import base64
import time
from typing import Dict
class RequestSigner:
"""请求签名器,使用 HMAC-SHA256 计算请求签名"""
def init(self, secret_key: str):
self.secret_key = secret_key.encode('utf-8')
def sign(
self,
method: str,
path: str,
body: str = "",
timestamp: int = None,
nonce: str = None
) -> Dictstr, str:
"""
计算请求签名
Args:
method: HTTP 方法 (GET, POST, PUT, DELETE)
path: 请求路径 (例如 /v1/chat/completions)
body: 请求体 JSON 字符串
timestamp: Unix 时间戳(秒),默认当前时间
nonce: 随机字符串,用于防止重放攻击
"""
if timestamp is None:
timestamp = int(time.time())
if nonce is None:
import secrets
nonce = secrets.token_hex(16)
计算请求体的 SHA-256 哈希
body_hash = hashlib.sha256(body.encode('utf-8')).hexdigest()
构造待签名字符串(按字典序排序以保证一致性)
string_to_sign = f"{method.upper()}\n{path}\n{timestamp}\n{nonce}\n{body_hash}"
计算 HMAC-SHA256 签名
signature = hmac.new(
self.secret_key,
string_to_sign.encode('utf-8'),
hashlib.sha256
).digest()
signature_b64 = base64.b64encode(signature).decode('utf-8')
return {
"X-Timestamp": str(timestamp),
"X-Nonce": nonce,
"X-Signature": f"sha256={signature_b64}",
"X-Body-Hash": body_hash
}
def verify(
self,
method: str,
path: str,
body: str,
timestamp: int,
nonce: str,
signature: str
) -> bool:
"""
验证请求签名是否有效
Args:
method: HTTP 方法
path: 请求路径
body: 请求体
timestamp: 时间戳
nonce: 随机数
signature: 待验证的签名
Returns:
签名是否有效
"""
检查时间戳是否在允许范围内(5分钟窗口)
current_time = int(time.time())
if abs(current_time - timestamp) > 300:
return False # 时间戳过期,可能为重放攻击
expected = self.sign(method, path, body, timestamp, nonce)
return hmac.compare_digest(expected"X-Signature", signature)
3.2 AES-256-GCM:API Key 的安全存储与传输加密
AES(Advanced Encryption Standard)是美国政府采用的区块加密标准,其中 AES-256-GCM(Galois/Counter Mode)是最为安全的变体之一,它同时提供了加密和消息认证(Authentication Tag)功能,能够检测密文的任何篡改行为。
在大模型 API 安全设计中,AES-256-GCM 主要用于两个场景:
场景一:API Key 的静态加密存储
数据库中存储的 API Key 不应以明文形式保存,而应该使用 AES-256-GCM 加密后存储。加密时需要使用一个主密钥(Master Key),通常存储在密钥管理服务(KMS)中,与应用代码隔离。
import base64
import os
from cryptography.hazmat.primitives.ciphers.aead import AESGCM
class KeyEncryptor:
"""使用 AES-256-GCM 加密和解密敏感数据"""
def init(self, master_key: bytes):
"""
初始化加密器
Args:
master_key: 32字节的主密钥(从 KMS 或环境变量获取)
"""
if len(master_key) != 32:
raise ValueError("Master key must be 32 bytes for AES-256")
self.aesgcm = AESGCM(master_key)
def encrypt(self, plaintext: str) -> str:
"""
加密明文数据
Args:
plaintext: 待加密的字符串
Returns:
Base64 编码的密文(包含 nonce + ciphertext + tag)
"""
nonce = os.urandom(12) # GCM 推荐 96 位(12字节)nonce
plaintext_bytes = plaintext.encode('utf-8')
ciphertext = self.aesgcm.encrypt(nonce, plaintext_bytes, None)
将 nonce 和密文拼接后 Base64 编码
return base64.b64encode(nonce + ciphertext).decode('utf-8')
def decrypt(self, encrypted: str) -> str:
"""
解密密文数据
Args:
encrypted: Base64 编码的加密字符串
Returns:
解密后的明文
"""
encrypted_bytes = base64.b64decode(encrypted)
nonce = encrypted_bytes:12
ciphertext = encrypted_bytes12:
plaintext_bytes = self.aesgcm.decrypt(nonce, ciphertext, None)
return plaintext_bytes.decode('utf-8')
场景二:敏感数据的端到端加密传输
如果大模型 API 调用涉及极其敏感的数据,可以在应用层使用 AES-256-GCM 对请求体和响应体进行额外加密。只有持有密钥的特定服务端才能解密数据,即使 TLS 传输层被攻破,应用层数据仍然受到保护。
import json
import base64
class SecureLLMClient:
"""
支持端到端加密的大模型客户端
数据在发送前使用 AES-256-GCM 加密
响应数据同样以加密形式返回
"""
def init(self, api_key: str, encryption_key: bytes):
self.api_key = api_key
self.encryptor = KeyEncryptor(encryption_key)
def _encrypt_payload(self, data: dict) -> str:
"""将请求数据加密后编码为 Base64 字符串"""
plaintext = json.dumps(data, ensure_ascii=False)
return self.encryptor.encrypt(plaintext)
def _decrypt_response(self, encrypted_data: str) -> dict:
"""解密 Base64 编码的密文响应"""
decrypted = self.encryptor.decrypt(encrypted_data)
return json.loads(decrypted)
def chat(self, messages: list, model: str = "gpt-4") -> dict:
"""
发送加密的聊天请求
Args:
messages: 消息列表 {"role": "user", "content": "..."}
model: 模型名称
Returns:
解密后的大模型响应
"""
request_data = {
"model": model,
"messages": messages,
"temperature": 0.7
}
encrypted_payload = self._encrypt_payload(request_data)
实际项目中,这里通过 HTTP 发送加密数据
encrypted_response = http_post("/api/llm/chat", encrypted_payload)
示例:模拟加密响应
response_data = {
"id": "chatcmpl-xxx",
"object": "chat.completion",
"choices": {"message": {"content": "这是一个加密响应"}}
}
return response_data
3.3 密钥派生:PBKDF2 与 HKDF
在实际应用中,我们很少直接使用用户提供的密码或 API Secret 作为加密密钥。通常需要通过密钥派生函数(Key Derivation Function,KDF)从主密钥或口令中派生出符合要求的子密钥。
PBKDF2(Password-Based KDF2) 通过多次哈希迭代和盐值(Salt)混合,将用户口令转换为固定长度的加密密钥。这种设计使得暴力破解口令的成本急剧上升------每增加一次迭代,攻击者的计算量就翻倍。
import hashlib
import base64
import os
class KeyDerivation:
"""密钥派生工具,支持 PBKDF2 和 HKDF"""
@staticmethod
def pbkdf2_sha256(
password: str,
salt: bytes,
iterations: int = 100000,
key_length: int = 32
) -> bytes:
"""
使用 PBKDF2-HMAC-SHA256 派生密钥
Args:
password: 用户口令
salt: 随机盐值(至少16字节)
iterations: 迭代次数(建议 >= 100000)
key_length: 派生密钥长度(字节)
Returns:
派生的密钥
"""
return hashlib.pbkdf2_hmac(
'sha256',
password.encode('utf-8'),
salt,
iterations,
dklen=key_length
)
@staticmethod
def hkdf_sha256(
ikm: bytes,
salt: bytes,
info: bytes,
length: int = 32
) -> bytes:
"""
使用 HKDF(HMAC-based KDF)从输入密钥材料派生密钥
Args:
ikm: 输入密钥材料(Input Key Material)
salt: 盐值(可选)
info: 上下文信息(用于绑定派生密钥到特定用途)
length: 派生密钥长度
Returns:
派生的密钥
"""
HKDF 由两步组成:Extract 和 Expand
Extract: 将不规则的输入密钥材料转换为伪随机密钥
prk = hmac.new(salt, ikm, hashlib.sha256).digest()
Expand: 从伪随机密钥派生出指定长度的输出
t = b""
result = b""
counter = 1
while len(result) < length:
t = hmac.new(prk, t + info + bytes(counter), hashlib.sha256).digest()
result += t
counter += 1
return result:length
示例:从 API Secret 派生会话密钥
api_secret = "sk-prod-xxxxxxxxxxxx"
salt = os.urandom(16)
session_key = KeyDerivation.pbkdf2_sha256(
password=api_secret,
salt=salt,
iterations=100000,
key_length=32
)
print(f"派生的会话密钥: {base64.b64encode(session_key).decode()}")
────────────────────────────────────────────────────────────
四、基于 RBAC 的细粒度权限控制设计
4.1 RBAC 模型核心概念
RBAC(Role-Based Access Control,基于角色的访问控制)是一种经典的企业级权限管理模型。它将权限不直接分配给用户,而是分配给角色,再将角色分配给用户,从而实现了权限与用户之间的解耦。
RBAC 的核心要素包括:
用户(User):系统中的实际操作者,可以是人员、服务账号或者 AI Agent。
角色(Role):权限的集合,代表了某种职责或职能。例如 ROLE_ADMIN、ROLE_DEVELOPER、ROLE_QUERY。
权限(Permission):对特定资源的特定操作的许可。用资源:操作的形式表示,例如 llm:chat:gpt-4 表示调用 GPT-4 聊天接口的权限,quota:read 表示读取配额的权限。
角色-权限分配(Role-Permission Assignment,PA):角色与权限之间的多对多关系。
用户-角色分配(User-Role Assignment,UA):用户与角色之间的多对多关系。
RBAC 授权链条:
用户 -> (UA) -> 角色 -> (PA) -> 权限 -> 资源 + 操作
4.2 大模型场景下的 RBAC 扩展设计
标准 RBAC 在大模型 API 管理场景下需要做针对性扩展,因为大模型的权限维度比传统系统更为复杂。
模型维度:不同用户可以调用的模型不同。管理员可以调用 GPT-4、Claude-3.5、Gemini Pro 等全系列模型,普通开发者只能调用 GPT-4o-mini、Claude-3-Haiku 等轻量级模型。
操作维度:除了调用模型,用户还可以有管理 API Key、查看用量报表、配置 Webhook 等操作权限。
配额维度:不同角色的用户有不同的 API 调用配额。管理员拥有无限制配额,付费用户有较高的日配额,试用用户有严格受限的配额。
时间维度:某些敏感操作可能只在工作时间内允许(如 9:00-18:00),下班后需要额外审批。
数据维度:多租户场景下,用户只能访问自己租户下的数据,不能跨租户调用 API 或查看数据。
IP 维度:企业内网用户可以访问所有 API,通过公网访问的用户则需要额外的认证步骤。
4.3 权限模型数据库设计
-- 用户表
CREATE TABLE users (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
username VARCHAR(64) NOT NULL UNIQUE,
email VARCHAR(255) NOT NULL UNIQUE,
password_hash VARCHAR(255) NOT NULL,
tenant_id BIGINT,
status TINYINT DEFAULT 1 COMMENT '0:禁用 1:启用',
created_at DATETIME DEFAULT CURRENT_TIMESTAMP,
updated_at DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
INDEX idx_tenant (tenant_id)
);
-- 角色表
CREATE TABLE roles (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
role_code VARCHAR(64) NOT NULL UNIQUE COMMENT '角色代码,如 ROLE_ADMIN',
role_name VARCHAR(128) NOT NULL COMMENT '角色名称',
role_desc VARCHAR(512),
tenant_id BIGINT COMMENT 'NULL表示系统级角色',
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);
-- 权限表
CREATE TABLE permissions (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
perm_code VARCHAR(128) NOT NULL UNIQUE COMMENT '权限代码',
perm_name VARCHAR(128) NOT NULL COMMENT '权限名称',
resource_type VARCHAR(64) COMMENT '资源类型: model/api/quota',
action VARCHAR(64) COMMENT '操作类型: chat/embed/admin',
created_at DATETIME DEFAULT CURRENT_TIMESTAMP
);
-- 角色-权限关联表
CREATE TABLE role_permissions (
role_id BIGINT NOT NULL,
perm_id BIGINT NOT NULL,
PRIMARY KEY (role_id, perm_id),
FOREIGN KEY (role_id) REFERENCES roles(id),
FOREIGN KEY (perm_id) REFERENCES permissions(id)
);
-- 用户-角色关联表
CREATE TABLE user_roles (
user_id BIGINT NOT NULL,
role_id BIGINT NOT NULL,
PRIMARY KEY (user_id, role_id),
FOREIGN KEY (user_id) REFERENCES users(id),
FOREIGN KEY (role_id) REFERENCES roles(id)
);
-- 用户配额表
CREATE TABLE user_quotas (
user_id BIGINT PRIMARY KEY,
daily_limit INT DEFAULT 1000 COMMENT '日调用限额',
monthly_limit INT COMMENT '月调用限额',
current_daily INT DEFAULT 0 COMMENT '当日已调用数',
current_monthly INT DEFAULT 0 COMMENT '当月已调用数',
quota_reset_at DATETIME COMMENT '配额重置时间',
FOREIGN KEY (user_id) REFERENCES users(id)
);
4.4 权限校验服务实现
from typing import List, Optional
from dataclasses import dataclass
from datetime import datetime, time
import ipaddress
@dataclass
class AuthContext:
"""认证上下文,包含用户身份和权限信息"""
user_id: int
username: str
tenant_id: int
roles: Liststr
permissions: Liststr
quotas: dict
ip_address: str
request_time: datetime
class PermissionService:
"""权限校验服务"""
系统预定义权限
SYSTEM_PERMISSIONS = {
模型调用权限
"llm:chat:gpt-4": "调用 GPT-4 聊天接口",
"llm:chat:gpt-4o": "调用 GPT-4o 聊天接口",
"llm:chat:gpt-4o-mini": "调用 GPT-4o-mini 聊天接口",
"llm:chat:claude-3.5": "调用 Claude-3.5 聊天接口",
"llm:chat:claude-3-haiku": "调用 Claude-3-Haiku 聊天接口",
"llm:embedding:ada": "调用 Embedding 接口",
操作权限
"api:read": "读取 API 配置",
"api:write": "修改 API 配置",
"api:admin": "管理级 API 操作",
"quota:read": "查看配额使用",
"quota:write": "修改配额配置",
"key:create": "创建 API Key",
"key:revoke": "撤销 API Key",
"audit:read": "查看审计日志",
}
def init(self, db_pool):
self.db = db_pool
def check_permission(
self,
ctx: AuthContext,
required_permission: str
) -> tuplebool, str:
"""
检查用户是否拥有指定权限
Returns:
(是否通过, 拒绝原因)
"""
1. 检查权限是否在用户权限列表中
if required_permission not in ctx.permissions:
return False, f"权限不足: 需要 {required_permission}"
2. 如果是管理员角色,跳过其他检查
if "ROLE_ADMIN" in ctx.roles:
return True, "OK"
3. 时间维度检查(如果权限配置了时间限制)
now = ctx.request_time
current_time = now.time()
if not self._check_time_window(ctx, required_permission, current_time):
return False, "当前时间不在允许的时间窗口内"
4. IP 维度检查
if not self._check_ip_whitelist(ctx):
return False, "请求 IP 不在白名单范围内"
return True, "OK"
def check_quota(self, ctx: AuthContext, model: str) -> tuplebool, str:
"""
检查用户配额是否允许本次调用
Returns:
(是否通过, 消息)
"""
quotas = ctx.quotas
检查日限额
daily_limit = quotas.get("daily_limit", 0)
current_daily = quotas.get("current_daily", 0)
if daily_limit > 0 and current_daily >= daily_limit:
return False, f"日配额已用尽 ({current_daily}/{daily_limit})"
检查月限额
monthly_limit = quotas.get("monthly_limit", 0)
current_monthly = quotas.get("current_monthly", 0)
if monthly_limit > 0 and current_monthly >= monthly_limit:
return False, f"月配额已用尽 ({current_monthly}/{monthly_limit})"
return True, "OK"
def _check_time_window(
self,
ctx: AuthContext,
permission: str,
current_time
) -> bool:
"""检查当前时间是否在权限允许的时间窗口内"""
简化实现:从权限配置或用户配置中读取时间窗口
allowed_start = time(9, 0) # 9:00 AM
allowed_end = time(18, 0) # 6:00 PM
管理员不受时间限制
if "ROLE_ADMIN" in ctx.roles:
return True
某些敏感权限需要检查时间窗口
sensitive_permissions = "llm:chat:gpt-4", "api:admin", "key:create"
if permission in sensitive_permissions:
return allowed_start <= current_time <= allowed_end
return True
def _check_ip_whitelist(self, ctx: AuthContext) -> bool:
"""检查请求 IP 是否在白名单内"""
从数据库加载用户的 IP 白名单配置
whitelist_cidrs = "10.0.0.0/8", "172.16.0.0/12", "192.168.0.0/16"
try:
request_ip = ipaddress.ip_address(ctx.ip_address)
for cidr in whitelist_cidrs:
if request_ip in ipaddress.ip_network(cidr):
return True
如果没有配置白名单,默认允许(或者反过来,默认拒绝)
return True
except ValueError:
return False # 无效 IP 地址
────────────────────────────────────────────────────────────
五、Spring Security 与大模型接口鉴权实战
5.1 整体架构设计
在 Spring Boot 应用中集成大模型 API 鉴权,整体架构分为三层:
接入层(Gateway):使用 Spring Cloud Gateway 或 Nginx 作为 API 网关,统一处理鉴权、限流、日志。外部请求首先到达网关,网关完成身份验证后才将请求转发到后端服务。
业务层(Service):Spring Boot 应用,包含大模型调用逻辑和业务处理。使用 Spring Security OAuth2 Resource Server 验证 JWT Token,从 Token 中提取权限信息进行业务层面的权限校验。
数据层(Data):MySQL 存储用户、角色、权限、API Key 等数据;Redis 存储 Token 黑名单、限流计数器、会话状态。
外部请求
↓
Spring Cloud Gateway\] ←→ \[Redis Session
↓ (验证通过)
Spring Boot Service\] ←→ \[MySQL / Redis
↓
LLM Provider API
5.2 Spring Security JWT 配置
package com.example.llmgateway.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.config.annotation.method.configuration.EnableMethodSecurity;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
import org.springframework.security.config.http.SessionCreationPolicy;
import org.springframework.security.crypto.bcrypt.BCryptPasswordEncoder;
import org.springframework.security.crypto.password.PasswordEncoder;
import org.springframework.security.oauth2.jwt.JwtDecoder;
import org.springframework.security.oauth2.jwt.NimbusJwtDecoder;
import org.springframework.security.web.SecurityFilterChain;
import org.springframework.web.cors.CorsConfiguration;
import org.springframework.web.cors.CorsConfigurationSource;
import org.springframework.web.cors.UrlBasedCorsConfigurationSource;
import javax.crypto.spec.SecretKeySpec;
import java.util.Arrays;
import java.util.List;
@Configuration
@EnableWebSecurity
@EnableMethodSecurity(prePostEnabled = true)
public class SecurityConfig {
private static final String JWT_SECRET = "your-256-bit-secret-key-for-jwt-signing";
@Bean
public SecurityFilterChain filterChain(HttpSecurity http) throws Exception {
http
// 禁用 CSRF(前后端分离场景下使用 Token 验证,无需 CSRF)
.csrf(csrf -> csrf.disable())
// CORS 配置
.cors(cors -> cors.configurationSource(corsConfigurationSource()))
// 禁用 Session,使用无状态 JWT
.sessionManagement(session ->
session.sessionCreationPolicy(SessionCreationPolicy.STATELESS))
// 授权规则配置
.authorizeHttpRequests(auth -> auth
// 公开端点
.requestMatchers("/api/auth/login", "/api/auth/register",
"/api/health", "/swagger-ui/**", "/v3/api-docs/**").permitAll()
// 模型调用接口需要认证
.requestMatchers("/api/llm/**").authenticated()
// 管理接口需要 ADMIN 角色
.requestMatchers("/api/admin/**").hasRole("ADMIN")
// 其他请求需要认证
.anyRequest().authenticated()
)
// 添加 JWT 过滤器
.addFilterBefore(
new JwtAuthenticationFilter(jwtDecoder()),
org.springframework.security.web.authentication.UsernamePasswordAuthenticationFilter.class
)
// 添加签名验证过滤器
.addFilterAfter(
new RequestSignatureFilter(),
JwtAuthenticationFilter.class
);
return http.build();
}
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
@Bean
public JwtDecoder jwtDecoder() {
byte\[\] secretBytes = JWT_SECRET.getBytes();
SecretKeySpec secretKey = new SecretKeySpec(secretBytes, "HmacSHA256");
return NimbusJwtDecoder.withSecretKey(secretKey).build();
}
@Bean
public CorsConfigurationSource corsConfigurationSource() {
CorsConfiguration configuration = new CorsConfiguration();
configuration.setAllowedOrigins(List.of(
"https://your-frontend-domain.com",
"http://localhost:3000"
));
configuration.setAllowedMethods(Arrays.asList("GET", "POST", "PUT", "DELETE", "OPTIONS"));
configuration.setAllowedHeaders(Arrays.asList(
"Authorization",
"Content-Type",
"X-API-Key",
"X-Timestamp",
"X-Nonce",
"X-Signature"
));
configuration.setExposedHeaders(List.of("X-RateLimit-Remaining", "X-Request-Id"));
configuration.setAllowCredentials(true);
configuration.setMaxAge(3600L);
UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource();
source.registerCorsConfiguration("/**", configuration);
return source;
}
}
5.3 JWT 认证过滤器实现
package com.example.llmgateway.filter;
import jakarta.servlet.FilterChain;
import jakarta.servlet.ServletException;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import org.springframework.security.authentication.UsernamePasswordAuthenticationToken;
import org.springframework.security.core.authority.SimpleGrantedAuthority;
import org.springframework.security.core.context.SecurityContextHolder;
import org.springframework.security.oauth2.jwt.Jwt;
import org.springframework.security.oauth2.jwt.JwtDecoder;
import org.springframework.security.oauth2.jwt.JwtException;
import org.springframework.stereotype.Component;
import org.springframework.web.filter.OncePerRequestFilter;
import java.io.IOException;
import java.util.List;
import java.util.stream.Collectors;
@Component
public class JwtAuthenticationFilter extends OncePerRequestFilter {
private final JwtDecoder jwtDecoder;
public JwtAuthenticationFilter(JwtDecoder jwtDecoder) {
this.jwtDecoder = jwtDecoder;
}
@Override
protected void doFilterInternal(
HttpServletRequest request,
HttpServletResponse response,
FilterChain filterChain
) throws ServletException, IOException {
String authHeader = request.getHeader("Authorization");
if (authHeader == null || !authHeader.startsWith("Bearer ")) {
filterChain.doFilter(request, response);
return;
}
String token = authHeader.substring(7);
try {
Jwt jwt = jwtDecoder.decode(token);
// 从 JWT 中提取用户信息和权限
String username = jwt.getSubject();
List<String> scopes = jwt.getClaimAsStringList("scope");
List<String> roles = jwt.getClaimAsStringList("roles");
// 合并 scope 和 roles
List<SimpleGrantedAuthority> authorities = scopes.stream()
.map(scope -> new SimpleGrantedAuthority("SCOPE_" + scope))
.collect(Collectors.toList());
if (roles != null) {
roles.stream()
.map(role -> new SimpleGrantedAuthority("ROLE_" + role))
.forEach(authorities::add);
}
// 构建认证对象并存入 SecurityContext
UsernamePasswordAuthenticationToken authentication =
new UsernamePasswordAuthenticationToken(username, null, authorities);
// 将 JWT 信息附加到认证对象中,方便后续使用
authentication.setDetails(new JwtAuthDetails(jwt));
SecurityContextHolder.getContext().setAuthentication(authentication);
} catch (JwtException e) {
logger.warn("Invalid JWT token: " + e.getMessage());
response.setStatus(HttpServletResponse.SC_UNAUTHORIZED);
response.getWriter().write("{\"error\": \"invalid_token\", \"message\": \"" + e.getMessage() + "\"}");
return;
}
filterChain.doFilter(request, response);
}
@Override
protected boolean shouldNotFilter(HttpServletRequest request) {
String path = request.getServletPath();
// 公开路径不需要 JWT 过滤
return path.startsWith("/api/auth/") || path.startsWith("/api/health");
}
// JWT 附加信息的容器类
public record JwtAuthDetails(Jwt jwt) {}
}
5.4 签名验证过滤器
package com.example.llmgateway.filter;
import jakarta.servlet.FilterChain;
import jakarta.servlet.ServletException;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import org.springframework.stereotype.Component;
import org.springframework.web.filter.OncePerRequestFilter;
import org.springframework.web.util.ContentCachingRequestWrapper;
import javax.crypto.Mac;
import javax.crypto.spec.SecretKeySpec;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
import java.security.InvalidKeyException;
import java.security.MessageDigest;
import java.security.NoSuchAlgorithmException;
import java.time.Instant;
import java.util.Base64;
@Component
public class RequestSignatureFilter extends OncePerRequestFilter {
private static final String SIGNATURE_HEADER = "X-Signature";
private static final String TIMESTAMP_HEADER = "X-Timestamp";
private static final String NONCE_HEADER = "X-Nonce";
private static final long MAX_TIMESTAMP_DIFF_SECONDS = 300; // 5分钟
// 在实际项目中,这个密钥应该从安全的密钥管理服务获取
private static final String SIGNING_SECRET = "your-signing-secret-key";
@Override
protected void doFilterInternal(
HttpServletRequest request,
HttpServletResponse response,
FilterChain filterChain
) throws ServletException, IOException {
// 仅对 POST/PUT/PATCH 请求验证签名
if (!requiresSignature(request)) {
filterChain.doFilter(request, response);
return;
}
String signature = request.getHeader(SIGNATURE_HEADER);
String timestampStr = request.getHeader(TIMESTAMP_HEADER);
String nonce = request.getHeader(NONCE_HEADER);
// 签名相关头缺失
if (signature == null || timestampStr == null || nonce == null) {
sendError(response, HttpServletResponse.SC_UNAUTHORIZED,
"Missing required signature headers");
return;
}
// 时间戳验证,防止重放攻击
long timestamp;
try {
timestamp = Long.parseLong(timestampStr);
} catch (NumberFormatException e) {
sendError(response, HttpServletResponse.SC_BAD_REQUEST, "Invalid timestamp");
return;
}
long currentTime = Instant.now().getEpochSecond();
if (Math.abs(currentTime - timestamp) > MAX_TIMESTAMP_DIFF_SECONDS) {
sendError(response, HttpServletResponse.SC_UNAUTHORIZED,
"Request timestamp expired (possible replay attack)");
return;
}
// 将请求包装为可重复读取的请求体
ContentCachingRequestWrapper wrappedRequest =
new ContentCachingRequestWrapper(request);
// 先获取请求体(需要读取后才能缓存)
byte\[\] bodyBytes = wrappedRequest.getInputStream().readAllBytes();
String body = new String(bodyBytes, StandardCharsets.UTF_8);
// 验证签名
String expectedSignature = computeSignature(
request.getMethod(),
request.getRequestURI(),
timestampStr,
nonce,
body
);
if (!MessageDigest.isEqual(
signature.getBytes(StandardCharsets.UTF_8),
expectedSignature.getBytes(StandardCharsets.UTF_8))) {
sendError(response, HttpServletResponse.SC_UNAUTHORIZED, "Invalid signature");
return;
}
// 将原始 body 放回请求中
CachedBodyHttpServletRequest cachedRequest =
new CachedBodyHttpServletRequest(wrappedRequest, bodyBytes);
filterChain.doFilter(cachedRequest, response);
}
private boolean requiresSignature(HttpServletRequest request) {
String method = request.getMethod();
String path = request.getServletPath();
return ("POST".equals(method) || "PUT".equals(method) || "PATCH".equals(method))
&& path.startsWith("/api/llm/")
&& !path.startsWith("/api/auth/");
}
private String computeSignature(
String method,
String path,
String timestamp,
String nonce,
String body
) {
try {
String bodyHash = sha256Hex(body);
String stringToSign = method + "\n" + path + "\n" + timestamp + "\n"
- nonce + "\n" + bodyHash;
Mac mac = Mac.getInstance("HmacSHA256");
SecretKeySpec secretKey =
new SecretKeySpec(SIGNING_SECRET.getBytes(StandardCharsets.UTF_8), "HmacSHA256");
mac.init(secretKey);
byte\[\] signatureBytes = mac.doFinal(stringToSign.getBytes(StandardCharsets.UTF_8));
return Base64.getEncoder().encodeToString(signatureBytes);
} catch (NoSuchAlgorithmException | InvalidKeyException e) {
throw new RuntimeException("Failed to compute signature", e);
}
}
private String sha256Hex(String input) {
try {
MessageDigest digest = MessageDigest.getInstance("SHA-256");
byte\[\] hash = digest.digest(input.getBytes(StandardCharsets.UTF_8));
StringBuilder hexString = new StringBuilder();
for (byte b : hash) {
String hex = Integer.toHexString(0xff & b);
if (hex.length() == 1) hexString.append('0');
hexString.append(hex);
}
return hexString.toString();
} catch (NoSuchAlgorithmException e) {
throw new RuntimeException("SHA-256 not available", e);
}
}
private void sendError(HttpServletResponse response, int status, String message)
throws IOException {
response.setStatus(status);
response.setContentType("application/json");
response.getWriter().write(
String.format("{\"error\": \"signature_failed\", \"message\": \"%s\"}", message)
);
}
@Override
protected boolean shouldNotFilter(HttpServletRequest request) {
// 只对 /api/ 路径下的修改性操作进行签名验证
return !request.getServletPath().startsWith("/api/");
}
}
5.5 大模型接口控制器
package com.example.llmgateway.controller;
import com.example.llmgateway.dto.ChatRequest;
import com.example.llmgateway.dto.ChatResponse;
import com.example.llmgateway.service.LLMService;
import com.example.llmgateway.service.PermissionService;
import jakarta.validation.Valid;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.security.access.AccessDeniedException;
import org.springframework.security.access.prepost.PreAuthorize;
import org.springframework.security.core.Authentication;
import org.springframework.security.core.context.SecurityContextHolder;
import org.springframework.web.bind.annotation.*;
import java.util.HashMap;
import java.util.Map;
@RestController
@RequestMapping("/api/llm")
public class LLMController {
private final LLMService llmService;
private final PermissionService permissionService;
public LLMController(LLMService llmService, PermissionService permissionService) {
this.llmService = llmService;
this.permissionService = permissionService;
}
@PostMapping("/chat")
@PreAuthorize("hasAuthority('SCOPE_llm:chat')")
public ResponseEntity<ChatResponse> chat(@Valid @RequestBody ChatRequest request) {
Authentication auth = SecurityContextHolder.getContext().getAuthentication();
String username = auth.getName();
// 获取 JWT 中的附加信息
Object details = auth.getDetails();
if (details instanceof JwtAuthDetails jwtDetails) {
// 可以从这里获取额外的信息,如 tenant_id
String tenantId = jwtDetails.jwt().getClaimAsString("tenant_id");
}
ChatResponse response = llmService.chat(request);
return ResponseEntity.ok(response);
}
@PostMapping("/chat/{model}")
@PreAuthorize("hasAuthority('SCOPE_llm:chat')")
public ResponseEntity<ChatResponse> chatWithModel(
@PathVariable String model,
@Valid @RequestBody ChatRequest request) {
// 检查用户是否有调用该模型的权限
String requiredPermission = "llm:chat:" + model;
// 从用户权限列表中检查(实际项目中应从权限服务查询)
Authentication auth = SecurityContextHolder.getContext().getAuthentication();
boolean hasPermission = auth.getAuthorities().stream()
.anyMatch(a -> a.getAuthority().equals("SCOPE_" + requiredPermission)
|| a.getAuthority().equals("ROLE_ADMIN"));
if (!hasPermission) {
throw new AccessDeniedException(
"您没有调用模型 " + model + " 的权限,请联系管理员申请"
);
}
ChatResponse response = llmService.chatWithModel(model, request);
return ResponseEntity.ok(response);
}
@GetMapping("/models")
@PreAuthorize("hasAuthority('SCOPE_llm:chat')")
public ResponseEntity<Map<String, Object>> listModels() {
// 根据用户权限返回可用的模型列表
Authentication auth = SecurityContextHolder.getContext().getAuthentication();
boolean isAdmin = auth.getAuthorities().stream()
.anyMatch(a -> a.getAuthority().equals("ROLE_ADMIN"));
Map<String, Object> models = new HashMap<>();
if (isAdmin) {
models.put("available", new String\[\]{"gpt-4", "gpt-4o", "gpt-4o-mini",
"claude-3.5", "claude-3-haiku", "gemini-pro"});
} else {
models.put("available", new String\[\]{"gpt-4o-mini", "claude-3-haiku"});
}
return ResponseEntity.ok(models);
}
@ExceptionHandler(AccessDeniedException.class)
public ResponseEntity<Map<String, String>> handleAccessDenied(AccessDeniedException e) {
Map<String, String> error = new HashMap<>();
error.put("error", "access_denied");
error.put("message", e.getMessage());
return ResponseEntity.status(HttpStatus.FORBIDDEN).body(error);
}
}
────────────────────────────────────────────────────────────
六、Token管理与主动刷新机制
6.1 Token 生命周期管理的核心原则
Token 生命周期管理是大模型 API 安全的核心环节。一个完善的 Token 管理体系需要解决以下核心问题:
Token 的有效期设计需要权衡安全性和用户体验。如果 Token 有效期太短(如 5 分钟),用户需要频繁刷新,体验很差;如果太长(如 7 天),则 Token 泄露后的风险窗口过大。一般建议 Access Token 的有效期设置为 15-60 分钟,Refresh Token 的有效期设置为 7-30 天。
Token 的刷新策略需要考虑无感知更新。在用户无感知的情况下完成 Token 的刷新和平滑过渡,避免突然中断正在进行的操作。
Token 的主动撤销需要支持多种触发条件。当用户主动注销、账户被禁用、密码被修改、检测到异常行为时,应该能够立即撤销已签发的 Token,使其失效。
6.2 多层 Token 体系设计
import time
import uuid
import hashlib
import redis
from dataclasses import dataclass
from typing import Optional, Tuple
from enum import Enum
class TokenType(Enum):
ACCESS = "access" # 短期访问令牌(15分钟)
REFRESH = "refresh" # 刷新令牌(7天)
API = "api" # API密钥(长期,需配合签名)
@dataclass
class TokenClaims:
"""Token 声明"""
sub: str # 用户ID
type: TokenType # 令牌类型
jti: str # 令牌唯一ID
iat: int # 签发时间
exp: int # 过期时间
scope: liststr # 权限范围
tenant_id: str # 租户ID
device_id: str # 设备ID(可选)
class TokenManager:
"""
多层 Token 管理系统
支持 Access Token / Refresh Token / API Key 三层架构
"""
def init(self, redis_client: redis.Redis, signing_key: bytes):
self.redis = redis_client
self.signing_key = signing_key
Token 有效期配置(秒)
self.ACCESS_TOKEN_TTL = 15 * 60 # 15分钟
self.REFRESH_TOKEN_TTL = 7 * 24 * 3600 # 7天
self.API_KEY_TTL = 365 * 24 * 3600 # 1年(需要主动撤销)
def issue_tokens(self, user_id: str, scopes: liststr, tenant_id: str) -> dict:
"""
签发完整的 Token 套件
Returns:
{
"access_token": "...",
"refresh_token": "...",
"api_key": "...",
"expires_in": 900
}
"""
jti_access = f"access:{uuid.uuid4().hex}"
jti_refresh = f"refresh:{uuid.uuid4().hex}"
now = int(time.time())
Access Token
access_claims = TokenClaims(
sub=user_id,
type=TokenType.ACCESS,
jti=jti_access,
iat=now,
exp=now + self.ACCESS_TOKEN_TTL,
scope=scopes,
tenant_id=tenant_id,
device_id=""
)
access_token = self._create_jwt(access_claims)
Refresh Token(包含更长的有效期,用于重新签发 Access Token)
refresh_claims = TokenClaims(
sub=user_id,
type=TokenType.REFRESH,
jti=jti_refresh,
iat=now,
exp=now + self.REFRESH_TOKEN_TTL,
scope=scopes,
tenant_id=tenant_id,
device_id=""
)
refresh_token = self._create_jwt(refresh_claims)
API Key(长期密钥,用于服务端到服务端的调用)
api_key = self._generate_api_key(user_id, tenant_id)
将 Refresh Token 和 API Key 的 JTI 存入 Redis(用于撤销)
self.redis.setex(
f"token:blacklist:{jti_refresh}",
self.REFRESH_TOKEN_TTL,
"1"
)
self.redis.setex(
f"apikey:valid:{api_key:16}", # API Key 前缀作为 key
self.API_KEY_TTL,
user_id
)
return {
"access_token": access_token,
"refresh_token": refresh_token,
"api_key": api_key,
"expires_in": self.ACCESS_TOKEN_TTL,
"token_type": "Bearer"
}
def refresh_access_token(self, refresh_token: str) -> Optionaldict:
"""
使用 Refresh Token 刷新 Access Token
Args:
refresh_token: 有效的 Refresh Token
Returns:
新的 Access Token 和 Refresh Token(Refresh Token 也需要轮换)
如果 Refresh Token 无效或已撤销,返回 None
"""
验证 Refresh Token
claims = self._verify_jwt(refresh_token)
if not claims:
return None
if claims.type != TokenType.REFRESH:
return None # 必须是 Refresh Token
检查是否在黑名单中(已被撤销)
if self.redis.exists(f"token:blacklist:{claims.jti}"):
return None
now = int(time.time())
轮换 Refresh Token(旧 Token 立即加入黑名单)
self.redis.setex(f"token:blacklist:{claims.jti}", 3600, "1") # 保留1小时,允许grace period
签发新的 Access Token 和 Refresh Token
new_jti_access = f"access:{uuid.uuid4().hex}"
new_jti_refresh = f"refresh:{uuid.uuid4().hex}"
new_access_claims = TokenClaims(
sub=claims.sub,
type=TokenType.ACCESS,
jti=new_jti_access,
iat=now,
exp=now + self.ACCESS_TOKEN_TTL,
scope=claims.scope,
tenant_id=claims.tenant_id,
device_id=claims.device_id
)
new_refresh_claims = TokenClaims(
sub=claims.sub,
type=TokenType.REFRESH,
jti=new_jti_refresh,
iat=now,
exp=now + self.REFRESH_TOKEN_TTL,
scope=claims.scope,
tenant_id=claims.tenant_id,
device_id=claims.device_id
)
将新的 Refresh Token 加入黑名单追踪
self.redis.setex(
f"token:blacklist:{new_jti_refresh}",
self.REFRESH_TOKEN_TTL,
"1"
)
return {
"access_token": self._create_jwt(new_access_claims),
"refresh_token": self._create_jwt(new_refresh_claims),
"expires_in": self.ACCESS_TOKEN_TTL,
"token_type": "Bearer"
}
def revoke_token(self, token: str, token_type_hint: str = None) -> bool:
"""
撤销指定的 Token
Args:
token: 要撤销的 Token
token_type_hint: Token 类型提示(可选)
Returns:
是否撤销成功
"""
claims = self._verify_jwt(token)
if not claims:
return False
将 Token 的 JTI 加入黑名单
ttl = claims.exp - int(time.time())
if ttl > 0:
self.redis.setex(f"token:blacklist:{claims.jti}", ttl, "1")
return True
return False
def revoke_all_user_tokens(self, user_id: str) -> int:
"""
撤销用户的所有 Token(用于密码修改、账户禁用等场景)
Returns:
撤销的 Token 数量
"""
在实际实现中,需要维护用户 -> Token JTI 列表的映射
这里简化为通过 Redis 的 SCAN 查找
pattern = f"token:user:{user_id}:*"
count = 0
for key in self.redis.scan_iter(match=pattern):
self.redis.delete(key)
count += 1
同时撤销该用户的所有 API Key
for key in self.redis.scan_iter(match="apikey:valid:*"):
self.redis.delete(key)
count += 1
return count
def is_token_blacklisted(self, jti: str) -> bool:
"""检查 Token 是否已被撤销"""
return self.redis.exists(f"token:blacklist:{jti}") > 0
def _create_jwt(self, claims: TokenClaims) -> str:
"""创建 JWT(简化实现,实际项目中应使用 PyJWT 或 jwcrypto)"""
import json
import base64
header = {"alg": "HS256", "typ": "JWT"}
payload = {
"sub": claims.sub,
"type": claims.type.value,
"jti": claims.jti,
"iat": claims.iat,
"exp": claims.exp,
"scope": claims.scope,
"tenant_id": claims.tenant_id,
"device_id": claims.device_id
}
header_b64 = base64.urlsafe_b64encode(
json.dumps(header).encode()
).rstrip(b'=').decode()
payload_b64 = base64.urlsafe_b64encode(
json.dumps(payload).encode()
).rstrip(b'=').decode()
import hmac
import hashlib
signature = hmac.new(
self.signing_key,
f"{header_b64}.{payload_b64}".encode(),
hashlib.sha256
).digest()
signature_b64 = base64.urlsafe_b64encode(signature).rstrip(b'=').decode()
return f"{header_b64}.{payload_b64}.{signature_b64}"
def _verify_jwt(self, token: str) -> OptionalTokenClaims:
"""验证 JWT 并返回 Claims"""
import json
import base64
import hmac
import hashlib
try:
parts = token.split('.')
if len(parts) != 3:
return None
header_b64, payload_b64, signature_b64 = parts
验证签名
expected_sig = hmac.new(
self.signing_key,
f"{header_b64}.{payload_b64}".encode(),
hashlib.sha256
).digest()
expected_sig_b64 = base64.urlsafe_b64encode(expected_sig).rstrip(b'=')
if not hmac.compare_digest(signature_b64.encode(), expected_sig_b64):
return None
解析 payload
payload_json = base64.urlsafe_b64decode(
payload_b64 + '=' * (4 - len(payload_b64) % 4)
)
payload = json.loads(payload_json)
检查过期
if payload'exp' < int(time.time()):
return None
return TokenClaims(
sub=payload'sub',
type=TokenType(payload'type'),
jti=payload'jti',
iat=payload'iat',
exp=payload'exp',
scope=payload'scope',
tenant_id=payload'tenant_id',
device_id=payload.get('device_id', '')
)
except Exception:
return None
def generate_api_key(self, user_id: str, tenant_id: str) -> str:
"""生成 API Key(格式:前缀_userid_hash)"""
random_part = uuid.uuid4().hex:24
return f"sk{user_id:8}_{random_part}"
6.3 客户端 Token 自动刷新
客户端应该在 Token 过期前主动刷新,避免请求失败。以下是一个 Python 客户端的参考实现:
import threading
import time
import requests
from typing import Callable, Optional
class TokenRefreshClient:
"""
自动刷新 Token 的 HTTP 客户端
在 Token 过期前主动刷新,对调用方透明
"""
def init(
self,
auth_url: str,
client_id: str,
client_secret: str,
on_token_refreshed: OptionalCallable\[\[str, None]] = None
):
self.auth_url = auth_url
self.client_id = client_id
self.client_secret = client_secret
self.on_token_refreshed = on_token_refreshed
self._access_token: Optionalstr = None
self._refresh_token: Optionalstr = None
self._expires_at: float = 0
self._lock = threading.Lock()
def _refresh_tokens(self) -> bool:
"""调用刷新接口获取新的 Token"""
response = requests.post(
f"{self.auth_url}/oauth/token",
data={
"grant_type": "refresh_token",
"refresh_token": self._refresh_token,
"client_id": self.client_id,
"client_secret": self.client_secret
},
timeout=10
)
if response.status_code != 200:
return False
data = response.json()
with self._lock:
self._access_token = data"access_token"
self._refresh_token = data"refresh_token"
self._expires_at = time.time() + data"expires_in" * 0.8 # 提前20%刷新
if self.on_token_refreshed:
self.on_token_refreshed(self._access_token)
return True
def get_valid_token(self) -> Optionalstr:
"""
获取当前有效的 Token(如果即将过期则自动刷新)
Returns:
有效的 access token
"""
with self._lock:
if self._access_token is None:
return None
如果 Token 即将过期(剩余时间不足 60 秒),主动刷新
if time.time() > self._expires_at - 60:
self._refresh_tokens()
return self._access_token
def request(self, method: str, url: str, **kwargs) -> requests.Response:
"""
发起 HTTP 请求,自动携带有效的 Token
"""
token = self.get_valid_token()
if token:
kwargs.setdefault("headers", {})
kwargs"headers""Authorization" = f"Bearer {token}"
response = requests.request(method, url, **kwargs)
如果收到 401,说明 Token 已经失效(可能服务器端已经撤销)
尝试刷新 Token 并重试一次
if response.status_code == 401 and self._refresh_token:
if self._refresh_tokens():
kwargs"headers""Authorization" = f"Bearer {self._access_token}"
response = requests.request(method, url, **kwargs)
return response
────────────────────────────────────────────────────────────
七、接口调用频率限制与配额管理
7.1 限流算法对比
限流是保护大模型 API 免受滥用和突发流量冲击的关键机制。以下是几种主流的限流算法及其在大模型场景下的适用性分析。
固定窗口计数器(Fixed Window Counter) 是最简单直接的限流算法。它在固定时间窗口内统计请求次数,当达到阈值时拒绝请求。优点是实现简单、计算成本低;缺点是存在边界突刺问题------如果时间窗口恰好在两个窗口的交界处,理论上允许的请求量可能翻倍。
滑动窗口日志(Sliding Window Log) 解决了固定窗口的边界问题。它以请求时间为键,每次请求都记录精确的时间戳。验证时,统计当前时间往前推一个窗口内的请求数。这种方式精确度高,但存储成本高,每个请求都需要一条记录。
令牌桶算法(Token Bucket) 是大模型 API 限流中最常用的算法。系统以固定速率向桶中添加令牌,每个请求消耗一个令牌。令牌桶允许一定程度的突发流量------只要桶中有令牌,即使请求速率超过平均速率,也能处理。同时,令牌桶还能平滑输出,避免流量抖动。
漏桶算法(Leaky Bucket) 与令牌桶相反,它以固定速率"漏出"请求进行处理。无论上游流量多大,漏桶的输出速率始终恒定。这适合需要对输出速率进行严格控制的场景,但不适合需要处理突发流量的大模型 API。
7.2 令牌桶实现
import time
import threading
import redis
from dataclasses import dataclass
from typing import Optional
@dataclass
class RateLimitResult:
"""限流检查结果"""
allowed: bool # 是否允许通过
remaining: int # 剩余可用次数
limit: int # 当前限制数
reset_at: float # 限流重置时间(Unix时间戳)
retry_after: Optionalint # 需要重试的秒数(仅在被拒绝时)
class TokenBucketRateLimiter:
"""
基于令牌桶算法的限流器
支持多维度限流:用户级别、应用级别、模型级别、IP级别
"""
def init(self, redis_client: redis.Redis):
self.redis = redis_client
self.local_buckets: dictstr, tuple\[int, float] = {}
self.lock = threading.Lock()
def check_rate_limit(
self,
key: str,
rate: int,
window_seconds: int,
burst: int = 0
) -> RateLimitResult:
"""
检查限流
Args:
key: 限流维度标识(如 "user:123" 或 "ip:192.168.1.1")
rate: 每秒添加的令牌数(平均速率)
window_seconds: 限流窗口(秒)
burst: 突发容量(额外令牌储备)
"""
now = time.time()
redis_key = f"ratelimit:{key}"
使用 Lua 脚本保证原子性(Redis 单线程执行)
lua_script = """
local key = KEYS1
local rate = tonumber(ARGV1)
local window = tonumber(ARGV2)
local burst = tonumber(ARGV3)
local now = tonumber(ARGV4)
local bucket = redis.call('HMGET', key, 'tokens', 'last_refill')
local tokens = tonumber(bucket1)
local last_refill = tonumber(bucket2)
if tokens == nil then
tokens = burst
last_refill = now
end
-- 计算应该添加的令牌数(时间差 × 速率)
local elapsed = now - last_refill
local add_tokens = elapsed * rate
tokens = math.min(burst, tokens + add_tokens)
local allowed = 0
local remaining = 0
if tokens >= 1 then
tokens = tokens - 1
allowed = 1
remaining = math.floor(tokens)
else
remaining = 0
end
-- 保存更新后的状态
redis.call('HMSET', key, 'tokens', tokens, 'last_refill', now)
redis.call('EXPIRE', key, window)
-- 计算重置时间
local reset_at = now + (burst - tokens) / rate
return {allowed, remaining, math.floor(burst), reset_at}
"""
result = self.redis.eval(
lua_script,
1,
redis_key,
rate,
window_seconds,
burst,
now
)
allowed, remaining, limit, reset_at = float(x) for x in result
return RateLimitResult(
allowed=bool(allowed),
remaining=int(remaining),
limit=int(limit),
reset_at=reset_at,
retry_after=None if allowed else int(window_seconds)
)
def check_user_limit(
self,
user_id: str,
model: str,
request_tokens: int = 1
) -> RateLimitResult:
"""
检查用户对特定模型的调用限制
大模型场景下的限流维度:
- 用户维度的请求次数限制
- 模型维度的 Token 消耗限制
- 组合维度的并发限制
"""
维度1:用户整体调用频率(每分钟最多 N 次)
user_result = self.check_rate_limit(
key=f"user:{user_id}:rpm",
rate=10, # 每秒补充10个令牌
window_seconds=60,
burst=20 # 允许突发20次
)
if not user_result.allowed:
return user_result
维度2:模型维度的 Token 消耗(每秒最多 M 个Token)
model_result = self.check_rate_limit(
key=f"model:{model}:tps",
rate=1000, # 每秒1000 Token
window_seconds=1,
burst=2000 # 允许2秒突发
)
if not model_result.allowed:
return model_result
维度3:用户+模型的组合限制
user_model_result = self.check_rate_limit(
key=f"user:{user_id}:model:{model}",
rate=5,
window_seconds=60,
burst=10
)
return user_model_result
def check_daily_quota(self, user_id: str, quota_limit: int) -> RateLimitResult:
"""
检查用户的日配额限制
Args:
user_id: 用户ID
quota_limit: 日配额上限
"""
today = time.strftime("%Y-%m-%d")
redis_key = f"quota:user:{user_id}:daily:{today}"
current = self.redis.get(redis_key)
current_count = int(current) if current else 0
if current_count >= quota_limit:
计算距离次日 UTC 0 点还有多少秒
tomorrow = time.strptime(
time.strftime("%Y-%m-%d 23:59:59", time.localtime()),
"%Y-%m-%d %H:%M:%S"
)
seconds_until_reset = int(tomorrow5) + 1 # 简化计算
return RateLimitResult(
allowed=False,
remaining=0,
limit=quota_limit,
reset_at=time.time() + seconds_until_reset,
retry_after=seconds_until_reset
)
使用 Lua 脚本原子递增并检查
lua_script = """
local key = KEYS1
local limit = tonumber(ARGV1)
local current = redis.call('INCR', key)
if current == 1 then
-- 第一次当天请求,设置过期时间为次日 UTC 0 点
redis.call('EXPIREAT', key,
tonumber(ARGV2))
end
return current
"""
计算次日 UTC 0 点的时间戳
import datetime
tomorrow_midnight = (
datetime.datetime.utcnow() +
datetime.timedelta(days=1)
).replace(hour=0, minute=0, second=0, microsecond=0)
reset_timestamp = int(tomorrow_midnight.timestamp())
new_count = self.redis.eval(
lua_script,
1,
redis_key,
quota_limit,
reset_timestamp
)
return RateLimitResult(
allowed=True,
remaining=quota_limit - int(new_count),
limit=quota_limit,
reset_at=reset_timestamp,
retry_after=None
)
7.3 限流中间件实现
package com.example.llmgateway.filter;
import jakarta.servlet.*;
import jakarta.servlet.http.HttpServletRequest;
import jakarta.servlet.http.HttpServletResponse;
import org.springframework.core.annotation.Order;
import org.springframework.stereotype.Component;
import java.io.IOException;
@Component
@Order(2) // 在 JwtAuthenticationFilter 之后执行
public class RateLimitFilter implements Filter {
private final RateLimiter rateLimiter;
public RateLimitFilter(RateLimiter rateLimiter) {
this.rateLimiter = rateLimiter;
}
@Override
public void doFilter(
HttpServletRequest request,
HttpServletResponse response,
FilterChain chain
) throws IOException, ServletException {
String path = request.getServletPath();
// 只对 LLM API 路径进行限流
if (!path.startsWith("/api/llm/")) {
chain.doFilter(request, response);
return;
}
String userId = getUserIdFromContext(); // 从 SecurityContext 获取
String clientIp = getClientIp(request);
String model = extractModelFromPath(path);
// 1. 检查用户 RPM 限制
RateLimitResult rpmResult = rateLimiter.checkUserRPM(userId);
if (!rpmResult.isAllowed()) {
sendRateLimitResponse(response, rpmResult, "RPM limit exceeded");
return;
}
// 2. 检查模型 TPM 限制
RateLimitResult tpmResult = rateLimiter.checkModelTPM(model);
if (!tpmResult.isAllowed()) {
sendRateLimitResponse(response, tpmResult, "Model TPM limit exceeded");
return;
}
// 3. 检查日配额
RateLimitResult quotaResult = rateLimiter.checkDailyQuota(userId);
if (!quotaResult.isAllowed()) {
sendQuotaExceededResponse(response, quotaResult);
return;
}
// 在响应头中添加限流信息
response.setHeader("X-RateLimit-Remaining", String.valueOf(rpmResult.getRemaining()));
response.setHeader("X-RateLimit-Limit", String.valueOf(rpmResult.getLimit()));
response.setHeader("X-RateLimit-Reset", String.valueOf(rpmResult.getResetAt()));
chain.doFilter(request, response);
}
private void sendRateLimitResponse(
HttpServletResponse response,
RateLimitResult result,
String message
) throws IOException {
response.setStatus(429);
response.setContentType("application/json");
response.setHeader("Retry-After", String.valueOf(result.getRetryAfter()));
response.setHeader("X-RateLimit-Remaining", "0");
response.getWriter().write(String.format(
"{\"error\":\"rate_limit_exceeded\",\"message\":\"%s\",\"retry_after\":%d}",
message, result.getRetryAfter()
));
}
private void sendQuotaExceededResponse(
HttpServletResponse response,
RateLimitResult result
) throws IOException {
response.setStatus(403);
response.setContentType("application/json");
response.setHeader("X-Quota-Limit", String.valueOf(result.getLimit()));
response.setHeader("X-Quota-Remaining", "0");
response.setHeader("X-Quota-Reset", String.valueOf(result.getResetAt()));
response.getWriter().write(String.format(
"{\"error\":\"daily_quota_exceeded\",\"message\":\"日配额已用尽,请明日再试\",\"quota_reset_at\":%d}",
result.getResetAt()
));
}
}
────────────────────────────────────────────────────────────
八、审计日志与异常行为检测
8.1 全链路审计日志设计
审计日志是企业安全的基石,它记录了每一次 API 调用的完整轨迹,使得安全事件可以追溯、异常行为可以检测、合规要求可以满足。
-- 审计日志表
CREATE TABLE audit_logs (
id BIGINT PRIMARY KEY AUTO_INCREMENT,
trace_id VARCHAR(64) NOT NULL COMMENT '分布式追踪ID',
span_id VARCHAR(32) COMMENT '调用链中的Span ID',
user_id BIGINT COMMENT '用户ID(未登录时为NULL)',
username VARCHAR(64) COMMENT '用户名',
tenant_id BIGINT COMMENT '租户ID',
api_key_id VARCHAR(64) COMMENT '使用的API Key ID',
client_ip VARCHAR(45) COMMENT '客户端IP(支持IPv6)',
user_agent VARCHAR(512) COMMENT 'User-Agent',
request_method VARCHAR(10) NOT NULL,
request_path VARCHAR(256) NOT NULL,
request_body_hash VARCHAR(64) COMMENT '请求体SHA-256哈希(用于追溯但不存储明文)',
request_params TEXT COMMENT '请求参数(JSON,需要脱敏)',
response_status INT COMMENT '响应状态码',
response_time_ms INT COMMENT '响应时间(毫秒)',
model_called VARCHAR(64) COMMENT '调用的模型名称',
input_tokens INT COMMENT '输入Token数',
output_tokens INT COMMENT '输出Token数',
cost_estimate DECIMAL(10, 6) COMMENT '费用估算',
error_code VARCHAR(32) COMMENT '错误码',
error_message TEXT COMMENT '错误信息(脱敏后)',
risk_score INT COMMENT '风险评分(0-100)',
risk_tags VARCHAR(256) COMMENT '风险标签,逗号分隔',
created_at DATETIME DEFAULT CURRENT_TIMESTAMP,
INDEX idx_user_time (user_id, created_at),
INDEX idx_trace (trace_id),
INDEX idx_tenant_time (tenant_id, created_at),
INDEX idx_risk_score (risk_score, created_at),
INDEX idx_client_ip (client_ip, created_at)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
8.2 审计日志切面实现
package com.example.llmgateway.aspect;
import com.example.llmgateway.annotation.AuditLog;
import com.example.llmgateway.service.AuditLogService;
import com.example.llmgateway.util.SecurityUtils;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.reflect.MethodSignature;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.slf4j.MDC;
import org.springframework.stereotype.Component;
import java.lang.reflect.Method;
import java.security.MessageDigest;
import java.time.Instant;
import java.util.HashMap;
import java.util.Map;
@Aspect
@Component
public class AuditLogAspect {
private static final Logger log = LoggerFactory.getLogger(AuditLogAspect.class);
private final AuditLogService auditLogService;
private final ObjectMapper objectMapper;
private final SecurityUtils securityUtils;
public AuditLogAspect(
AuditLogService auditLogService,
ObjectMapper objectMapper,
SecurityUtils securityUtils
) {
this.auditLogService = auditLogService;
this.objectMapper = objectMapper;
this.securityUtils = securityUtils;
}
@Around("@annotation(com.example.llmgateway.annotation.AuditLog)")
public Object around(ProceedingJoinPoint joinPoint) throws Throwable {
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
AuditLog auditLog = method.getAnnotation(AuditLog.class);
long startTime = System.currentTimeMillis();
String traceId = MDC.get("traceId");
// 构建审计日志基础信息
Map<String, Object> auditInfo = new HashMap<>();
auditInfo.put("traceId", traceId);
auditInfo.put("method", method.getName());
auditInfo.put("className", joinPoint.getTarget().getClass().getSimpleName());
auditInfo.put("userId", securityUtils.getCurrentUserId());
auditInfo.put("username", securityUtils.getCurrentUsername());
auditInfo.put("tenantId", securityUtils.getCurrentTenantId());
auditInfo.put("clientIp", securityUtils.getClientIp());
auditInfo.put("userAgent", securityUtils.getUserAgent());
// 记录请求参数(脱敏)
if (auditLog.logParams()) {
Object\[\] args = joinPoint.getArgs();
String\[\] paramNames = signature.getParameterNames();
Map<String, Object> sanitizedParams = sanitizeParams(paramNames, args);
auditInfo.put("params", sanitizedParams);
}
Object result = null;
Exception exception = null;
int statusCode = 200;
try {
result = joinPoint.proceed();
return result;
} catch (Exception e) {
exception = e;
statusCode = 500;
throw e;
} finally {
long duration = System.currentTimeMillis() - startTime;
// 提取响应信息
if (result != null && auditLog.logResponse()) {
auditInfo.put("responseType", result.getClass().getSimpleName());
}
// 异步保存审计日志
try {
auditLogService.saveAsync(AuditLogEntry.builder()
.traceId(traceId)
.userId((Long) auditInfo.get("userId"))
.username((String) auditInfo.get("username"))
.tenantId((Long) auditInfo.get("tenantId"))
.clientIp((String) auditInfo.get("clientIp"))
.requestMethod((String) auditInfo.get("method"))
.requestPath(joinPoint.getStaticPart().toString())
.requestParamsHash(hashRequestParams(auditInfo.get("params")))
.responseStatus(statusCode)
.responseTimeMs((int) duration)
.errorCode(exception != null ? exception.getClass().getSimpleName() : null)
.errorMessage(exception != null ? sanitizeErrorMessage(exception.getMessage()) : null)
.createdAt(Instant.now())
.build());
} catch (Exception e) {
log.error("Failed to save audit log", e);
}
}
}
private Map<String, Object> sanitizeParams(String\[\] paramNames, Object\[\] args) {
Map<String, Object> sanitized = new HashMap<>();
if (paramNames == null || args == null) return sanitized;
for (int i = 0; i < Math.min(paramNames.length, args.length); i++) {
String name = paramNamesi;
Object value = argsi;
// 敏感字段脱敏
if (isSensitiveField(name)) {
sanitized.put(name, "***REDACTED***");
} else if (value != null && isComplexType(value)) {
sanitized.put(name, value.getClass().getSimpleName());
} else {
sanitized.put(name, value);
}
}
return sanitized;
}
private boolean isSensitiveField(String fieldName) {
return fieldName.toLowerCase().contains("password")
|| fieldName.toLowerCase().contains("secret")
|| fieldName.toLowerCase().contains("token")
|| fieldName.toLowerCase().contains("key")
|| fieldName.toLowerCase().contains("credential")
|| fieldName.toLowerCase().contains("authorization");
}
private boolean isComplexType(Object obj) {
return obj instanceof Map || obj instanceof Collection
|| obj.getClass().getName().contains("Request")
|| obj.getClass().getName().contains("Dto");
}
private String hashRequestParams(Object params) {
if (params == null) return null;
try {
String json = objectMapper.writeValueAsString(params);
return sha256(json);
} catch (Exception e) {
return null;
}
}
private String sha256(String input) {
try {
MessageDigest digest = MessageDigest.getInstance("SHA-256");
byte\[\] hash = digest.digest(input.getBytes());
StringBuilder hexString = new StringBuilder();
for (byte b : hash) {
String hex = Integer.toHexString(0xff & b);
if (hex.length() == 1) hexString.append('0');
hexString.append(hex);
}
return hexString.toString();
} catch (Exception e) {
return null;
}
}
private String sanitizeErrorMessage(String message) {
if (message == null) return null;
// 移除可能包含的敏感信息
return message
.replaceAll("A-Za-z0-9_-{20,}", "***") // 替换长令牌
.replaceAll("\\b\\d{11,}\\b", "***") // 替换长数字
.replaceAll("token=\^\&\\\\s+", "token=***")
.replaceAll("key=\^\&\\\\s+", "key=***");
}
}
8.3 异常行为检测引擎
from typing import List, Dict, Optional
from dataclasses import dataclass
from datetime import datetime, timedelta
import numpy as np
from collections import defaultdict
@dataclass
class BehaviorEvent:
"""用户行为事件"""
user_id: str
event_type: str # api_call, login, config_change
timestamp: datetime
ip_address: str
user_agent: str
model: str
tokens_used: int
cost: float
success: bool
metadata: dict
class AnomalyDetector:
"""
基于统计和规则的用户异常行为检测引擎
检测维度:
- 调用频率异常(平时低,突然爆发)
- 调用时段异常(深夜/节假日突然大量调用)
- 调用地域异常(短时间内跨地域调用)
- 费用异常(单日/月费用突增)
- 批量数据导出异常(短时间大量数据读取)
- Token 消耗异常(单次请求 Token 数突增)
"""
def init(self, redis_client):
self.redis = redis_client
历史基线(从数据库加载)
self.baseline_cache: Dictstr, dict = {}
def analyze(self, events: ListBehaviorEvent) -> ListDict:
"""
分析行为事件序列,检测异常
Returns:
检测到的异常列表,每个异常包含类型、置信度和建议
"""
anomalies = \[\]
检测维度1:频率异常(调用频率突增)
freq_anomalies = self._detect_frequency_anomaly(events)
anomalies.extend(freq_anomalies)
检测维度2:地域异常(跨地域调用)
geo_anomalies = self._detect_geo_anomaly(events)
anomalies.extend(geo_anomalies)
检测维度3:Token 消耗异常
token_anomalies = self._detect_token_anomaly(events)
anomalies.extend(token_anomalies)
检测维度4:费用异常
cost_anomalies = self._detect_cost_anomaly(events)
anomalies.extend(cost_anomalies)
检测维度5:时段异常
time_anomalies = self._detect_time_anomaly(events)
anomalies.extend(time_anomalies)
return anomalies
def _detect_frequency_anomaly(self, events: ListBehaviorEvent) -> ListDict:
"""检测调用频率异常"""
if not events:
return \[\]
user_id = events0.user_id
anomalies = \[\]
统计最近1小时和1天的调用次数
now = datetime.now()
last_hour = e for e in events if now - e.timestamp \< timedelta(hours=1)
last_day = e for e in events if now - e.timestamp \< timedelta(days=1)
获取用户历史基线(简化实现,实际应从数据库查询)
baseline = self._get_user_baseline(user_id)
hourly_baseline = baseline.get("hourly_avg", 10)
daily_baseline = baseline.get("daily_avg", 100)
if len(last_hour) > hourly_baseline * 3:
anomalies.append({
"type": "frequency_burst",
"severity": "high" if len(last_hour) > hourly_baseline * 10 else "medium",
"confidence": min(0.95, len(last_hour) / (hourly_baseline * 3) * 0.8),
"user_id": user_id,
"description": f"1小时内调用 {len(last_hour)} 次,是基线({hourly_baseline})的"
f"{len(last_hour) / hourly_baseline:.1f} 倍",
"suggested_action": "暂时冻结账户,通知用户确认"
})
return anomalies
def _detect_geo_anomaly(self, events: ListBehaviorEvent) -> ListDict:
"""检测地域异常(短时间内跨多个地区)"""
if len(events) < 3:
return \[\]
recent_events = e for e in events
if datetime.now() - e.timestamp \< timedelta(hours=2)
unique_ips = set(e.ip_address for e in recent_events)
超过3个不同 IP 则视为异常
if len(unique_ips) > 3:
计算 IP 的地理距离(简化:使用 ASN 前缀数量作为代理)
return {
"type": "geo_spread",
"severity": "high",
"confidence": 0.85,
"user_id": events\[0.user_id,
"description": f"2小时内从 {len(unique_ips)} 个不同 IP 调用",
"ip_list": list(unique_ips),
"suggested_action": "要求二次验证,暂时限制大额调用"
}]
return \[\]
def _detect_token_anomaly(self, events: ListBehaviorEvent) -> ListDict:
"""检测 Token 消耗异常"""
if not events:
return \[\]
token_counts = e.tokens_used for e in events if e.tokens_used \> 0
if not token_counts:
return \[\]
mean_tokens = np.mean(token_counts)
std_tokens = np.std(token_counts)
anomalies = \[\]
for event in events:
if event.tokens_used > mean_tokens + 3 * std_tokens:
anomalies.append({
"type": "token_burst",
"severity": "medium",
"confidence": 0.8,
"user_id": event.user_id,
"description": f"单次请求消耗 {event.tokens_used} Token,"
f"超出均值({mean_tokens:.0f}){std_tokens:.0f} 的3倍",
"model": event.model,
"suggested_action": "记录并通知用户,确认是否正常"
})
return anomalies
def _detect_cost_anomaly(self, events: ListBehaviorEvent) -> ListDict:
"""检测费用异常"""
if not events:
return \[\]
user_id = events0.user_id
today_cost = sum(e.cost for e in events
if e.timestamp.date() == datetime.now().date())
获取用户的日费用基线
baseline = self._get_user_baseline(user_id)
daily_cost_baseline = baseline.get("daily_cost_avg", 10.0)
daily_cost_limit = baseline.get("daily_cost_limit", 100.0)
anomalies = \[\]
if today_cost > daily_cost_limit:
anomalies.append({
"type": "cost_limit_breach",
"severity": "critical",
"confidence": 1.0,
"user_id": user_id,
"description": f"今日费用 {today_cost:.2f} 已超过限额 {daily_cost_limit:.2f}",
"suggested_action": "立即暂停服务,通知用户"
})
elif today_cost > daily_cost_baseline * 5:
anomalies.append({
"type": "cost_surge",
"severity": "high",
"confidence": 0.9,
"user_id": user_id,
"description": f"今日费用 {today_cost:.2f} 是基线({daily_cost_baseline:.2f})的"
f"{today_cost / daily_cost_baseline:.1f} 倍",
"suggested_action": "发送告警,要求用户确认"
})
return anomalies
def _detect_time_anomaly(self, events: ListBehaviorEvent) -> ListDict:
"""检测时段异常"""
anomalies = \[\]
for event in events:
hour = event.timestamp.hour
深夜时段(00:00-06:00)的大量调用
if 0 <= hour < 6:
recent_count = len(e for e in events
if 0 \<= e.timestamp.hour \< 6
and (event.timestamp - e.timestamp).seconds \< 3600)
if recent_count > 50: # 1小时内超过50次深夜调用
anomalies.append({
"type": "off_hours_usage",
"severity": "medium",
"confidence": 0.75,
"user_id": event.user_id,
"description": f"深夜时段({hour}:00)存在大量调用",
"suggested_action": "记录,是否正常取决于业务场景"
})
return anomalies
def _get_user_baseline(self, user_id: str) -> dict:
"""获取用户的历史基线数据(实际应从数据库查询)"""
简化实现:返回默认基线
return {
"hourly_avg": 10,
"daily_avg": 100,
"daily_cost_avg": 5.0,
"daily_cost_limit": 50.0
}
────────────────────────────────────────────────────────────
九、敏感数据脱敏与加密传输
9.1 敏感数据识别与分类
在大模型 API 调用场景中,敏感数据主要分为以下几类:
个人身份信息(PII):姓名、身份证号、护照号、手机号、电子邮件、家庭住址、出生日期等。这些信息一旦泄露,可能导致身份盗用、欺诈等严重后果。
金融账户信息:银行卡号、信用卡号、银行账户、支付密码、保险单号等。金融信息的泄露直接与财产损失挂钩。
健康医疗信息:病历记录、处方信息、体检报告、遗传信息等。健康信息的泄露可能带来歧视和就业歧视风险。
商业机密:财务报表、源代码、客户名单、定价策略、研发计划、内部通信等。商业机密泄露可能造成竞争优势的永久丧失。
认证凭证:用户名密码、API Key、Token、证书、私钥等。认证凭证的泄露意味着攻击者可以伪装成合法用户。
在实际的企业大模型应用中,敏感数据的识别不能仅仅依赖预定义的规则库,还需要结合上下文信息和业务语义进行综合判断。例如,同样是一串数字,在金融场景中可能是银行卡号,在医疗场景中可能是病历编号,在教育场景中可能是学生证号。因此,一个完善的敏感数据识别系统应该同时具备规则匹配和上下文感知两种能力。
9.2 自动脱敏引擎实现
import re
from typing import Callable, Dict, List, Optional
from dataclasses import dataclass
from enum import Enum
class SensitiveDataType(Enum):
CHINESE_ID = "chinese_id" # 身份证号
PHONE_CN = "phone_cn" # 中国手机号
EMAIL = "email" # 邮箱
BANK_CARD = "bank_card" # 银行卡号
CREDIT_CARD = "credit_card" # 信用卡号
IP_ADDRESS = "ip_address" # IP地址
PASSWORD = "password" # 密码
API_KEY = "api_key" # API密钥
NAME = "name" # 姓名
@dataclass
class MaskingRule:
"""脱敏规则"""
data_type: SensitiveDataType
pattern: str # 正则表达式
replacement: str # 替换模板,如 "***1234"
confidence: float # 识别置信度
class DataMasker:
"""
敏感数据自动识别与脱敏引擎
支持规则匹配和机器学习辅助识别
"""
预定义脱敏规则
MASKING_RULES: ListMaskingRule =
MaskingRule(
SensitiveDataType.CHINESE_ID,
r'\\b\[1-9\d{5}(19|20)\d{2}(01-9|10-2)(01-9|12\d|301)\d{3}\\dXx\b',
'**************\g<subscript>',
0.95
),
MaskingRule(
SensitiveDataType.PHONE_CN,
r'\b13-9\d{9}\b',
'\g<prefix>****\g<suffix>',
0.92
),
MaskingRule(
SensitiveDataType.EMAIL,
r'\bA-Za-z0-9._%+-+@A-Za-z0-9.-+\.A-Z\|a-z{2,}\b',
'\g<local>***@\g<domain>',
0.98
),
MaskingRule(
SensitiveDataType.BANK_CARD,
r'\b(1-9\d{15,20})\b',
'\g<prefix>****\g<suffix>',
0.88
),
MaskingRule(
SensitiveDataType.IP_ADDRESS,
r'\b(?:\d{1,3}\.){3}\d{1,3}\b',
'***.***.***',
0.99
),
MaskingRule(
SensitiveDataType.PASSWORD,
r'(?i)(password|passwd|pwd)\s*:=\s*\S+',
'\g<key>: ***',
1.0
),
MaskingRule(
SensitiveDataType.API_KEY,
r'(?i)(api_-?key|secret_-?key|access_-?token)\s*:=\s*\\w-{16,}',
'\g<key>: ***',
0.95
),
]
def init(self):
self.custom_rules: ListMaskingRule = \[\]
def mask(self, text: str, mask_char: str = '*') -> str:
"""
对文本中的敏感数据进行脱敏
Args:
text: 原始文本
mask_char: 脱敏字符
Returns:
脱敏后的文本
"""
if not text:
return text
result = text
for rule in self.MASKING_RULES + self.custom_rules:
result = self._apply_rule(result, rule, mask_char)
return result
def _apply_rule(self, text: str, rule: MaskingRule, mask_char: str) -> str:
"""应用单条脱敏规则"""
针对不同数据类型使用不同的脱敏策略
if rule.data_type == SensitiveDataType.CHINESE_ID:
身份证:保留前3后4位
def mask_id(m):
id_num = m.group()
return id_num:6 + '********' + id_num-4:
return re.sub(rule.pattern, mask_id, text)
elif rule.data_type == SensitiveDataType.PHONE_CN:
手机号:保留前3后4位
def mask_phone(m):
phone = m.group()
return phone:3 + '****' + phone-4:
return re.sub(rule.pattern, mask_phone, text)
elif rule.data_type == SensitiveDataType.EMAIL:
邮箱:保留前2字符和域名
def mask_email(m):
email = m.group()
at_idx = email.index('@')
local = email:at_idx
domain = emailat_idx:
masked_local = local:2 + '*' * (len(local) - 2) if len(local) > 2 else '*'
return masked_local + domain
return re.sub(rule.pattern, mask_email, text)
elif rule.data_type == SensitiveDataType.BANK_CARD:
银行卡:保留前6后4位(发卡行标识+卡种标识 + 持卡人标识)
def mask_card(m):
card = m.group()
return card:6 + '*' * (len(card) - 10) + card-4:
return re.sub(rule.pattern, mask_card, text)
elif rule.data_type == SensitiveDataType.PASSWORD:
密码:完全替换
def mask_pwd(m):
key = m.group(1)
return f"{key}: ***"
return re.sub(rule.pattern, mask_pwd, text, flags=re.IGNORECASE)
elif rule.data_type == SensitiveDataType.API_KEY:
API Key:保留前8后4
def mask_key(m):
key = m.group()
return key:8 + '*' * (len(key) - 16) + key-4: if len(key) > 16 else '***'
return re.sub(rule.pattern, mask_key, text, flags=re.IGNORECASE)
elif rule.data_type == SensitiveDataType.IP_ADDRESS:
return re.sub(rule.pattern, '***.***.***.***', text)
else:
默认:通用脱敏(保留前后各2字符)
def mask_default(m):
content = m.group()
if len(content) <= 4:
return '*' * len(content)
return content:2 + '*' * (len(content) - 4) + content-2:
return re.sub(rule.pattern, mask_default, text)
def extract_and_mask(
self,
text: str
) -> tuplestr, List\[Dict]:
"""
识别并脱敏,同时返回识别到的敏感信息摘要
Returns:
(脱敏后文本, 敏感信息列表)
"""
masked_text = self.mask(text)
findings = \[\]
记录识别结果
for rule in self.MASKING_RULES + self.custom_rules:
matches = re.finditer(rule.pattern, text, re.IGNORECASE)
for m in matches:
findings.append({
"type": rule.data_type.value,
"position": m.span(),
"masked_value": m.group():4 + '***', # 不记录完整值
"confidence": rule.confidence
})
return masked_text, findings
9.3 TLS 1.3 加密传输配置
Nginx TLS 1.3 配置示例
/etc/nginx/nginx.conf
http {
升级到 TLS 1.3
ssl_protocols TLSv1.3 TLSv1.2;
优先使用前向安全性(Forward Secrecy)的密码套件
ssl_ciphers 'TLS_AES_256_GCM_SHA384:TLS_CHACHA20_POLY1305_SHA256:ECDHE-RSA-AES256-GCM-SHA384';
ssl_prefer_server_ciphers on;
启用 OCSP Stapling(减少客户端到 CA 的查询)
ssl_stapling on;
ssl_stapling_verify on;
resolver 8.8.8.8 8.8.4.4 valid=300s;
resolver_timeout 5s;
启用 HSTS(HTTP Strict Transport Security)
add_header Strict-Transport-Security "max-age=31536000; includeSubDomains; preload" always;
禁用 SSL session ticket(避免会话恢复带来的安全风险)
ssl_session_tickets off;
SSL session 缓存
ssl_session_cache shared:SSL:10m;
ssl_session_timeout 1d;
上游服务(指向 Spring Boot 应用)也使用 TLS
upstream llm_backend {
server 127.0.0.1:8443;
}
server {
listen 443 ssl http2;
server_name api.your-llm-gateway.com;
ssl_certificate /etc/ssl/certs/your-cert.pem;
ssl_certificate_key /etc/ssl/private/your-key.pem;
安全请求头
add_header X-Frame-Options "SAMEORIGIN" always;
add_header X-Content-Type-Options "nosniff" always;
add_header X-XSS-Protection "1; mode=block" always;
add_header Referrer-Policy "strict-origin-when-cross-origin" always;
location / {
proxy_pass https://llm_backend;
proxy_set_header Host host;
proxy_set_header X-Real-IP remote_addr;
proxy_set_header X-Forwarded-For proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto scheme;
超时配置(大模型请求可能需要较长的时间)
proxy_connect_timeout 60s;
proxy_send_timeout 300s;
proxy_read_timeout 300s;
连接复用
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}
}
────────────────────────────────────────────────────────────
十、实战:企业级大模型网关鉴权方案
10.1 整体架构
一个完整的企业级大模型网关鉴权方案,应该包含以下核心组件:
流量入口层:由 Spring Cloud Gateway 或 Envoy 构成,提供统一的流量入口。负责 TLS 终止、请求路由、限流、熔断。
鉴权认证层:独立的鉴权服务(Authentication Service),处理用户登录、Token 签发、Token 刷新、API Key 管理。
权限控制层:策略决策点(Policy Decision Point,PDP),基于 RBAC/ABAC 混合模型进行细粒度授权。
LLM 调用层:负责与各大模型提供商(OpenAI、Claude、Azure OpenAI 等)的 API 对接,提供统一的接口抽象。
数据存储层:MySQL 存储用户、角色、权限、API Key 等元数据;Redis 存储 Token 黑名单、限流计数器、会话状态。
监控告警层:Grafana + Prometheus 提供实时监控和告警能力,ELK(Elasticsearch + Logstash + Kibana)提供日志分析和审计。
┌─────────────────────────────────────────────────┐
│ 外部请求 │
└────────────────────┬────────────────────────────┘
│
┌────────────────────▼────────────────────────────┐
│ Spring Cloud Gateway │
│ ┌─────────┬──────────┬──────────┬──────────┐ │
│ │TLS终止 │限流熔断 │请求签名 │路由分发 │ │
│ └─────────┴──────────┴──────────┴──────────┘ │
└────────────────────┬────────────────────────────┘
│
┌─────────────────────────────┼─────────────────────────────┐
│ │ │
┌──────────▼──────────┐ ┌─────────────▼─────────────┐ ┌──────────▼──────────┐
│ Auth Service │ │ LLM Gateway Service │ │ Admin Portal │
│ ┌───────────────┐ │ │ ┌──────────┬──────────┐ │ │ ┌────────────────┐ │
│ │登录/注册/Token │ │ │ │权限校验 │ABAC引擎 │ │ │ │用户管理/Key管理│ │
│ │API Key管理 │ │ │ │Token验证 │配额检查 │ │ │ │日志查看/报表 │ │
│ │OAuth2/OIDC │ │ │ │限流检查 │审计日志 │ │ │ │角色配置/告警 │ │
│ └───────────────┘ │ │ └──────────┴──────────┘ │ │ └────────────────┘ │
└──────────┬──────────┘ └─────────────┬─────────────┘ └──────────┬──────────┘
│ │ │
└──────────────┬──────────────┴─────────────────────────────┘
│
┌───────────▼───────────┐
│ MySQL + Redis │
│ 用户/角色/权限/Token │
└─────────────────────┘
│
┌───────────▼───────────┐
│ LLM Provider APIs │
│ OpenAI/Claude/Azure │
└───────────────────────┘
上述架构图清晰展示了一个企业级大模型网关鉴权系统的完整分层结构。外部请求首先到达 Spring Cloud Gateway,这一层承担着流量的第一道防线的职责。在这一层完成 TLS 终止(SSL Offloading),确保所有外部通信都经过加密;接着执行限流检查和熔断逻辑,防止异常流量打爆后端服务;请求签名验证确保请求的完整性和真实性未被篡改;最后根据请求路径将流量路由到相应的后端服务。
流量入口层的核心职责可以进一步细化为以下几个关键能力。首先是 TLS 终止,Gateway 需要配置有效的 SSL 证书,建议使用 Let's Encrypt 的免费证书或者企业采购的商业证书,并配置证书自动续期机制,避免证书过期导致服务中断。限流策略的配置需要结合业务实际情况,通常建议设置多个维度的限制:全局限流保护后端服务不被冲垮,用户级限流防止个别用户过度消耗资源,模型级限流保护高成本模型不被滥用。熔断机制推荐使用 Resilience4j 或者 Sentinel 实现,当某个下游服务(如特定的 LLM 提供商)出现响应超时或者错误率上升时,熔断器会在一定时间内快速失败(Fail Fast),避免大量请求堆积导致线程池耗尽。
鉴权认证层是整个系统的信任根。Authentication Service 负责用户注册、登录、Token 签发和刷新、API Key 的全生命周期管理。在设计这一层时,需要特别注意用户密码的存储安全------必须使用 bcrypt 或者 Argon2 等专业的密码哈希算法,绝对不能使用 MD5 或者 SHA-1 等通用哈希算法,因为这些算法对于现代攻击者来说太容易被破解。JWT Token 的签名密钥应该至少为 256 位,并且应该存储在 KMS 中而不是配置文件里。
LLM 调用层需要对多个大模型提供商进行统一的接口抽象和适配。每个提供商都有自己独特的 API 规范和认证方式:OpenAI 使用 Bearer Token 认证,Anthropic 使用 x-api-key Header,Azure OpenAI 使用 Azure AD 令牌认证。在这一层通过适配器模式(Adapter Pattern)将各个提供商的差异屏蔽掉,为上层提供统一的调用接口。同时,这层还负责请求的重试、超时处理、以及在多个模型之间的负载均衡。
10.2 核心配置类
package com.example.llmgateway.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.config.annotation.method.configuration.EnableMethodSecurity;
import org.springframework.security.config.annotation.web.builders.HttpSecurity;
import org.springframework.security.config.annotation.web.configuration.EnableWebSecurity;
import org.springframework.security.config.http.SessionCreationPolicy;
import org.springframework.security.oauth2.server.resource.authentication.JwtAuthenticationConverter;
import org.springframework.security.oauth2.server.resource.authentication.JwtGrantedAuthoritiesConverter;
import org.springframework.security.web.SecurityFilterChain;
@Configuration
@EnableWebSecurity
@EnableMethodSecurity(prePostEnabled = true)
public class GatewaySecurityConfig {
@Bean
public SecurityFilterChain gatewaySecurityFilterChain(HttpSecurity http) throws Exception {
http
.csrf(csrf -> csrf.disable())
.sessionManagement(session ->
session.sessionCreationPolicy(SessionCreationPolicy.STATELESS))
.authorizeHttpRequests(auth -> auth
.requestMatchers(
"/api/auth/**",
"/api/health",
"/actuator/health"
).permitAll()
.requestMatchers("/api/admin/**").hasRole("ADMIN")
.anyRequest().authenticated()
)
.oauth2ResourceServer(oauth2 -> oauth2
.jwt(jwt -> jwt
.jwtAuthenticationConverter(jwtAuthenticationConverter())
)
);
return http.build();
}
@Bean
public JwtAuthenticationConverter jwtAuthenticationConverter() {
JwtGrantedAuthoritiesConverter grantedAuthoritiesConverter =
new JwtGrantedAuthoritiesConverter();
grantedAuthoritiesConverter.setAuthoritiesClaimName("roles");
grantedAuthoritiesConverter.setAuthorityPrefix("ROLE_");
JwtAuthenticationConverter jwtAuthenticationConverter =
new JwtAuthenticationConverter();
jwtAuthenticationConverter.setJwtGrantedAuthoritiesConverter(
grantedAuthoritiesConverter);
return jwtAuthenticationConverter;
}
}
统一异常处理是保障系统健壮性的关键环节。在生产环境中,任何未被捕获的异常都可能导致服务崩溃或者返回难以理解的错误信息给调用方。一个良好的异常处理体系应该做到以下几点:对外部调用者返回友好的错误信息(不能泄露内部实现细节);对内部日志记录完整的异常堆栈和上下文信息;根据异常类型返回正确的 HTTP 状态码(如 401 表示认证失败、429 表示限流、403 表示权限不足、500 表示内部错误);为每一次错误生成唯一的 errorId,方便在日志中追溯;关键错误触发告警通知运维人员。
10.3 统一异常处理
package com.example.llmgateway.exception;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.security.access.AccessDeniedException;
import org.springframework.security.oauth2.server.resource.InvalidBearerTokenException;
import org.springframework.validation.FieldError;
import org.springframework.web.bind.MethodArgumentNotValidException;
import org.springframework.web.bind.annotation.ExceptionHandler;
import org.springframework.web.bind.annotation.RestControllerAdvice;
import java.util.HashMap;
import java.util.Map;
import java.util.UUID;
@RestControllerAdvice
public class GlobalExceptionHandler {
private static final Logger log = LoggerFactory.getLogger(
GlobalExceptionHandler.class);
@ExceptionHandler(AccessDeniedException.class)
public ResponseEntity<Map<String, Object>> handleAccessDenied(
AccessDeniedException e) {
return ResponseEntity.status(HttpStatus.FORBIDDEN).body(
buildErrorResponse("access_denied", e.getMessage(), HttpStatus.FORBIDDEN)
);
}
@ExceptionHandler(InvalidBearerTokenException.class)
public ResponseEntity<Map<String, Object>> handleInvalidToken(
InvalidBearerTokenException e) {
return ResponseEntity.status(HttpStatus.UNAUTHORIZED).body(
buildErrorResponse("invalid_token", "Token 已过期或无效",
HttpStatus.UNAUTHORIZED)
);
}
@ExceptionHandler(RateLimitExceededException.class)
public ResponseEntity<Map<String, Object>> handleRateLimit(
RateLimitExceededException e) {
Map<String, Object> body = buildErrorResponse(
"rate_limit_exceeded",
e.getMessage(),
HttpStatus.TOO_MANY_REQUESTS
);
body.put("retryAfter", e.getRetryAfterSeconds());
body.put("limit", e.getLimit());
return ResponseEntity.status(HttpStatus.TOO_MANY_REQUESTS)
.header("Retry-After", String.valueOf(e.getRetryAfterSeconds()))
.body(body);
}
@ExceptionHandler(QuotaExceededException.class)
public ResponseEntity<Map<String, Object>> handleQuotaExceeded(
QuotaExceededException e) {
return ResponseEntity.status(HttpStatus.FORBIDDEN).body(
buildErrorResponse("quota_exceeded", e.getMessage(), HttpStatus.FORBIDDEN)
);
}
@ExceptionHandler(MethodArgumentNotValidException.class)
public ResponseEntity<Map<String, Object>> handleValidationErrors(
MethodArgumentNotValidException e) {
Map<String, String> fieldErrors = new HashMap<>();
for (FieldError error : e.getBindingResult().getFieldErrors()) {
fieldErrors.put(error.getField(), error.getDefaultMessage());
}
Map<String, Object> body = buildErrorResponse(
"validation_error",
"请求参数校验失败",
HttpStatus.BAD_REQUEST
);
body.put("fieldErrors", fieldErrors);
return ResponseEntity.badRequest().body(body);
}
@ExceptionHandler(Exception.class)
public ResponseEntity<Map<String, Object>> handleGenericException(Exception e) {
String errorId = UUID.randomUUID().toString();
log.error("Unhandled exception errorId={}", errorId, e);
Map<String, Object> body = buildErrorResponse(
"internal_error",
"系统内部错误,请联系管理员并提供错误ID: " + errorId,
HttpStatus.INTERNAL_SERVER_ERROR
);
return ResponseEntity.status(HttpStatus.INTERNAL_SERVER_ERROR).body(body);
}
private Map<String, Object> buildErrorResponse(
String errorCode,
String message,
HttpStatus status
) {
Map<String, Object> body = new HashMap<>();
body.put("error", errorCode);
body.put("message", message);
body.put("status", status.value());
body.put("timestamp", System.currentTimeMillis());
return body;
}
}
// 自定义异常类
public class RateLimitExceededException extends RuntimeException {
private final int retryAfterSeconds;
private final int limit;
public RateLimitExceededException(String message, int retryAfterSeconds, int limit) {
super(message);
this.retryAfterSeconds = retryAfterSeconds;
this.limit = limit;
}
public int getRetryAfterSeconds() { return retryAfterSeconds; }
public int getLimit() { return limit; }
}
public class QuotaExceededException extends RuntimeException {
public QuotaExceededException(String message) {
super(message);
}
}
在大模型网关系统中,健康检查和弹性熔断是保障服务高可用性的核心技术手段。健康检查不仅需要关注应用自身的存活状态,还需要对下游的大模型提供商服务进行探测,及时发现某个提供商不可用的情况。当健康检查发现某个 LLM 提供商的 API 不可达时,应该自动将该提供商从路由池中移除,并将流量切换到其他可用的提供商。同时,熔断机制应该在检测到某个模型或提供商持续出错时自动触发,防止大量请求堆积导致服务彻底崩溃。熔断恢复后,应该采用渐进式恢复策略,逐步增加对该提供商的流量分配,观察其稳定性,确保不会再触发熔断后再完全恢复。
10.4 健康检查与弹性熔断
package com.example.llmgateway.health;
import org.springframework.boot.actuate.health.Health;
import org.springframework.boot.actuate.health.HealthIndicator;
import org.springframework.stereotype.Component;
import org.springframework.web.client.RestTemplate;
import java.util.Map;
@Component
public class LLMProviderHealthIndicator implements HealthIndicator {
private final RestTemplate restTemplate;
private final Map<String, String> providerEndpoints;
public LLMProviderHealthIndicator() {
this.restTemplate = new RestTemplate();
this.providerEndpoints = Map.of(
"openai", "https://api.openai.com/v1/models",
"anthropic", "https://api.anthropic.com/v1/models",
"azure", "https://your-resource.openai.azure.com/.well-known/openai-configuration"
);
}
@Override
public Health health() {
int totalProviders = providerEndpoints.size();
int healthyProviders = 0;
Map<String, String> unhealthyProviders = new java.util.HashMap<>();
for (Map.Entry<String, String> entry : providerEndpoints.entrySet()) {
String provider = entry.getKey();
String endpoint = entry.getValue();
try {
// 简化检查:实际应该 HEAD 请求检查可用性
// 这里仅检查连通性
if (isEndpointReachable(endpoint)) {
healthyProviders++;
} else {
unhealthyProviders.put(provider, "unreachable");
}
} catch (Exception e) {
unhealthyProviders.put(provider, e.getMessage());
}
}
Health.Builder builder = healthyProviders == totalProviders
? Health.up()
: Health.down();
return builder
.withDetail("healthyProviders", healthyProviders)
.withDetail("totalProviders", totalProviders)
.withDetail("unhealthyProviders", unhealthyProviders)
.build();
}
private boolean isEndpointReachable(String url) {
try {
// 超时设置为3秒
restTemplate.getForObject(url, String.class);
return true;
} catch (Exception e) {
return false;
}
}
}
────────────────────────────────────────────────────────────
十一、总结与最佳实践
大模型接口鉴权与访问控制是一项系统工程,需要从多个层面构建防御体系。任何一个单一的安全措施都无法应对所有潜在威胁,只有通过多层次、多维度的纵深防御体系,才能在面对不断演进的安全威胁时保持足够的抵御能力。
11.1 纵深防御体系构建
纵深防御(Defense in Depth)是一种古老而有效的安全理念,其核心思想是通过在信息系统的不同层面部署多重安全控制措施,使得即使攻击者突破了某一层防御,仍然会被后续的防御层拦截和检测。在大模型 API 安全场景中,纵深防御应该覆盖以下七个层面:
第一层:网络层安全。这一层主要解决"谁能访问系统"的基础问题。应该部署 Web 应用防火墙(WAF)来防御常见的 Web 攻击(如 SQL 注入、XSS、路径穿越等);配置抗 DDoS 服务来应对大规模流量攻击;使用 API 网关或负载均衡器对外部流量进行初步筛选;配置严格的防火墙规则,只允许必要的端口和服务对外开放。对于企业内网环境,应该划分独立的安全区域(VLAN),将大模型网关部署在受保护的内部网络中,通过 DMZ(隔离区)与外部网络隔离。
第二层:传输层安全。所有大模型 API 通信必须强制使用 TLS 1.3 加密,确保数据在传输过程中不会被窃听或篡改。服务器端应该启用严格的密码套件配置,禁用已知存在安全漏洞的加密算法(如 TLS 1.0、TLS 1.1、3DES、RC4 等)。对于极高敏感场景,还应该在应用层实现端到端加密,即在数据离开应用之前就已经加密,只有目标服务才能解密。即使网络层被攻破,攻击者截获的也只是密文。
第三层:认证层安全。这是"你是谁"的关键防线。推荐采用多因素认证(MFA)来增强用户登录安全性;对于 API 访问,采用 API Key + 请求签名的双因子认证机制,使得即使 API Key 泄露,攻击者仍然无法伪造有效的请求签名。JWT Token 的有效期应该设置在 15-60 分钟之间,配合 Refresh Token 实现无感知的自动刷新。对于高敏感操作,可以要求额外的认证步骤,如短信验证码、邮件确认或者硬件令牌的二次验证。
第四层:授权层安全。这是"你能做什么"的核心控制。基于 RBAC 模型构建权限管理体系,但同时需要结合 ABAC 的灵活性来实现细粒度的动态授权。权限的授予应该遵循最小权限原则------只授予完成特定任务所必需的最小权限集合,不进行过度授权。对于敏感操作(如删除数据、修改权限配置、大额调用等),应该实施操作审批流程,重要操作需要多人复核。
第五层:限流与配额层安全。这一层防止资源被过度消耗。应该在 API 网关层面部署多维度的限流策略,包括但不限于:基于用户 ID 的请求频率限制(RPM)、基于模型维度的 Token 消耗限制(TPM)、基于 IP 地址的访问频率限制、基于时间窗口的配额管理等。当检测到异常流量模式时(如短时间内请求量突增 10 倍以上),系统应该自动触发熔断机制,暂停对该用户或 IP 的服务,并发送告警通知。
第六层:监控与检测层安全。这一层的核心目标是"及时发现正在发生的攻击"。全链路审计日志应该记录每一次 API 调用的完整轨迹,包括调用者身份、调用时间、调用的模型、输入输出 Token 数、响应时间、异常信息等。基于统计和规则构建异常行为检测引擎,对以下场景进行实时检测:调用频率突增、跨地域访问、短时间内大量消耗配额、异常的时间段使用等。检测到可疑行为后,应该在秒级触发告警,并通过自动化的响应机制(如暂时冻结账户、撤销所有 Token、阻止进一步调用)来遏制威胁。
第七层:数据安全层。这一层关注的是"敏感数据的保护"。对存储在数据库中的敏感数据(如 API Key、用户个人信息等)应该使用 AES-256-GCM 进行加密存储;日志中不应该出现任何明文的敏感信息;对脱敏的合规性应该进行定期审计;数据备份应该与生产环境同样严格的安全管控。
11.2 密钥管理与轮换策略
密钥是大模型 API 安全的核心要素。密钥管理的安全性直接决定了整个安全体系的可靠性。
密钥的分类管理是首要原则。在一个完整的大模型网关系统中,通常存在多种不同用途的密钥:用于签发 JWT 的签名密钥(Signing Key)、用于加密敏感数据的加密密钥(Encryption Key)、用于对接大模型提供商的第三方 API Key、用于内部服务间通信的服务密钥等。这些密钥应该分开管理,不能混用。特别是第三方 API Key,绝对不能存储在代码仓库中或硬编码在程序里。
密钥存储应该依托专业的密钥管理服务(KMS)。云服务商(如 AWS KMS、Azure Key Vault、Google Cloud KMS)提供了硬件安全模块(HSM)支持的密钥管理服务,密钥在 HSM 中生成并存储,即使云服务商内部人员也无法直接访问密钥明文。如果在私有化部署环境中,应该考虑使用 HashiCorp Vault 等开源密钥管理系统,通过访问控制策略(ACL)来严格限制谁可以在什么条件下访问哪些密钥。
密钥轮换是防止密钥长期使用带来安全风险的重要手段。JWT 签名密钥建议每 3-6 个月轮换一次;数据加密密钥的轮换周期可以更长(如 1-2 年),但每次轮换时需要配合数据重加密操作;API Key 的轮换周期则应该根据使用场景灵活调整------对于高敏感场景,可以设置为每月甚至每周自动轮换。密钥轮换应该实现自动化,避免人工干预带来的错误和延迟。
密钥的撤销与应急响应同样重要。当发现密钥可能泄露时,必须能够在最短时间内撤销所有受影响密钥,阻止攻击者继续使用。应该建立标准化的密钥撤销流程,并定期进行演练,确保在真正的安全事件发生时能够快速响应。
11.3 监控指标体系与告警策略
一个完善的安全监控体系需要同时关注业务指标和安全指标两大类。
业务指标主要反映大模型 API 的使用情况和健康状态。核心指标包括:API 调用总量和增长率(按用户、按模型、按时间维度)、Token 消耗量和费用趋势、API 响应时间和超时率、各模型的调用分布情况、用户活跃度和留存率、Top N 用户的用量排行等。这些指标帮助运营团队了解大模型服务的实际使用情况,为容量规划和成本优化提供数据支撑。
安全指标则专注于检测和响应安全威胁。核心指标包括:认证失败率(登录失败、Token 验证失败、签名验证失败等)、限流触发次数和涉及的账户数量、异常行为检测引擎的告警数量和处理情况、敏感数据脱敏的覆盖率、审计日志的完整性(日志丢失率、延迟等)、密钥轮换的及时性等。
告警策略的设计同样需要精心考量。告警过少会导致真实威胁被遗漏,告警过多则会导致告警疲劳,安全人员对所有告警都麻木。推荐采用分级告警机制:将告警分为 P0(紧急,需立即处理)、P1(重要,需在 1 小时内处理)、P2(一般,需在 24 小时内处理)、P3(提示,仅记录)四个级别。P0 级别的告警应该同时触发多种通知渠道(短信、电话、即时通讯工具),确保在第一时间通知到值班人员。
在实际运营中,建议建立安全运营中心(SOC)的概念,对安全告警进行 7x24 小时的监控和响应。对于中低级别的告警,可以在工作时间内由安全运营团队统一处理;对于高级别的告警,必须确保有值班人员在任何时间都能在 5 分钟内响应。在每次告警处理完毕后,应该进行简短的复盘(Post-incident Review),分析告警产生的原因、响应是否及时有效、是否存在改进空间,持续优化告警规则和响应流程。
在选择监控工具链时,推荐使用 Prometheus + Grafana 的组合来收集和可视化业务与安全指标。Prometheus 的 Pull 模型非常适合微服务架构,可以自动发现并抓取各个服务暴露的 metrics 端点。对于日志分析,ELK Stack(Elasticsearch、Logstash、Kibana)提供了强大的全文搜索和聚合分析能力,可以支持复杂的安全分析查询。对于链路追踪,Jaeger 或 Zipkin 可以帮助追踪分布式请求的完整调用链,在排查性能问题或者安全事件时提供有力支持。
11.4 合规性考量与数据保护
在设计和实现大模型 API 鉴权体系时,合规性是一个不可忽视的重要维度。
数据本地化与跨境传输是首要考量因素。不同国家和地区对数据存储和传输有不同的法律要求。中国《个人信息保护法》要求关键信息基础设施运营者将在中国境内收集和产生的个人信息存储在境内,确需向境外提供的应当通过国家网信部门组织的安全评估。欧盟的 GDPR 对个人数据的跨境传输有严格的限制,只允许在特定条件下向被认为具有充分数据保护水平的国家或通过标准合同条款(SCC)等方式传输数据。如果企业的用户分布在全球多个地区,大模型 API 网关的架构设计必须考虑数据路由的合规性。
数据最小化收集是隐私保护的基本原则。在设计审计日志和监控系统的字段时,应该只收集实际需要的数据,避免过度收集。例如,审计日志中记录请求体时应该进行脱敏处理,只记录必要的信息(模型名称、Token 数量、响应状态等),而不应该记录完整的用户输入和输出内容。
数据留存策略需要平衡安全分析和存储成本。审计日志的留存周期通常应该不少于 6 个月,以满足大多数合规审计的要求。对于涉及敏感操作的日志,留存周期可能需要延长至 1-3 年。超过留存周期的数据应该进行安全销毁,不能简单删除文件了事。
安全审计与渗透测试是验证安全体系有效性的必要手段。应该至少每年进行一次由专业安全团队实施的安全审计和渗透测试,及时发现和修复潜在的安全漏洞。对于高风险系统(如处理金融数据、医疗数据的系统),审计频率应该更高。
11.5 成本优化与资源管理
大模型 API 的调用成本是企业必须认真对待的问题。合理的成本优化策略可以在保证安全性的同时,显著降低运营成本。
模型选型优化是最直接的成本控制手段。不同模型的定价差异巨大------GPT-4 的价格可能是 GPT-3.5 的数十倍甚至是上百倍。在实际应用中,应该建立模型分级使用制度:简单问答和日常任务使用轻量级模型(如 GPT-4o-mini、Claude-3-Haiku),复杂推理和专业任务使用高级模型(如 GPT-4、Claude-3.5)。通过在网关层面强制执行模型权限和提示词优化指导,可以引导用户在合适的场景使用合适的模型。
缓存机制可以显著减少重复调用带来的成本。对于具有相同或相似输入的请求,可以通过语义相似度匹配在缓存中查找已有结果,避免重复调用大模型API。缓存命中率每提升 10%,就意味着约 10% 的成本节约。
用量预警与自动熔断可以防止意外的大额账单。当用户的日用量或月用量达到预设的阈值(如 80%)时,系统应该自动发送告警通知用户。当用量超过 100% 时,可以自动触发熔断机制,暂停该用户的大模型 API 服务,防止费用继续累积。
成本分摊与预算控制是企业在多人共用一个大模型网关时必须考虑的问题。通过为不同的团队或者项目设置独立的配额配额池,可以实现成本的精细化管理。当某个配额池接近用尽时,系统自动通知对应的负责人,而不是等到完全用尽导致服务中断。对于超额使用的情况,可以选择允许超额使用并在下个计费周期结算,或者直接暂停服务------这取决于组织的财务政策和优先级。
容错与降级策略也是成本优化的一部分。当某个高成本模型出现大量超时或者错误时,系统应该自动将流量切换到成本更低的替代模型,而不是一直重试导致费用浪费。这种降级策略需要提前定义好降级路径,比如 GPT-4 超时后自动降级到 GPT-4o-mini,同时向用户返回降级提示。
批量处理与异步调用也是降低成本的另一个有效手段。对于非实时性的任务(如批量文本分析、批量内容生成等),可以将请求放入队列中,异步处理并批量调用大模型 API。很多大模型提供商对批量请求有折扣价格(通常是实时 API 的 50% 左右),对于非即时性需求来说,这是一个非常显著的成本节约。以日均处理 10 万条数据为例,如果每条数据调用一次 API,批量处理相比实时处理可能节省 40-60% 的费用。
11.6 团队协作与安全文化建设
技术手段只是安全体系的一部分,团队的安全意识和协作能力同样重要。
安全编码规范应该在团队中全面推行。所有涉及密钥、Token、用户数据的代码必须经过安全评审,确保没有硬编码密钥、日志泄露、明文传输等安全问题。对于新加入团队的开发者,应该进行安全编码规范的培训并通过考核。
安全事件响应流程应该事先定义清楚。当安全事件发生时,团队应该知道谁牵头响应、如何隔离问题、如何保全证据、如何与用户沟通、如何进行事后复盘。安全事件响应不是某个单一角色的职责,而是需要开发、运维、安全、合规、法务等多个团队协作完成。
定期安全演练可以检验安全体系的有效性和团队的响应能力。演练场景可以包括:模拟 API Key 泄露后的应急响应、模拟大规模 DDoS 攻击下的服务降级、模拟内部数据泄露的调查取证等。演练不应该只是走过场,每次演练都应该有明确的评估指标,如响应时间、遏制有效性、沟通效率等,并在演练后形成改进项跟踪落实。
安全文化的建设是一个长期过程,不可能一蹴而就。安全不应该是安全团队的独角戏,而应该是整个组织的共同意识。可以通过定期的安全意识培训、钓鱼邮件测试、安全月活动等方式,持续提升全员的安全意识。特别是对于开发团队,应该建立"安全左移"的理念------即在软件开发的早期阶段就将安全纳入考量,而不是等到上线前才进行安全测试。
大模型 API 的安全是一场持续的战斗,没有银弹。攻击者的手段在不断升级,防御体系也需要持续演进。唯有保持警惕,持续投入,才能在这场博弈中保持主动。通过技术手段、管理制度和团队文化的综合发力,才能构建真正稳固的大模型 API 安全防线。
────────────────────────────────────────────────────────────
洛水石
附:配套技术图解
图1:接口鉴权体系架构图
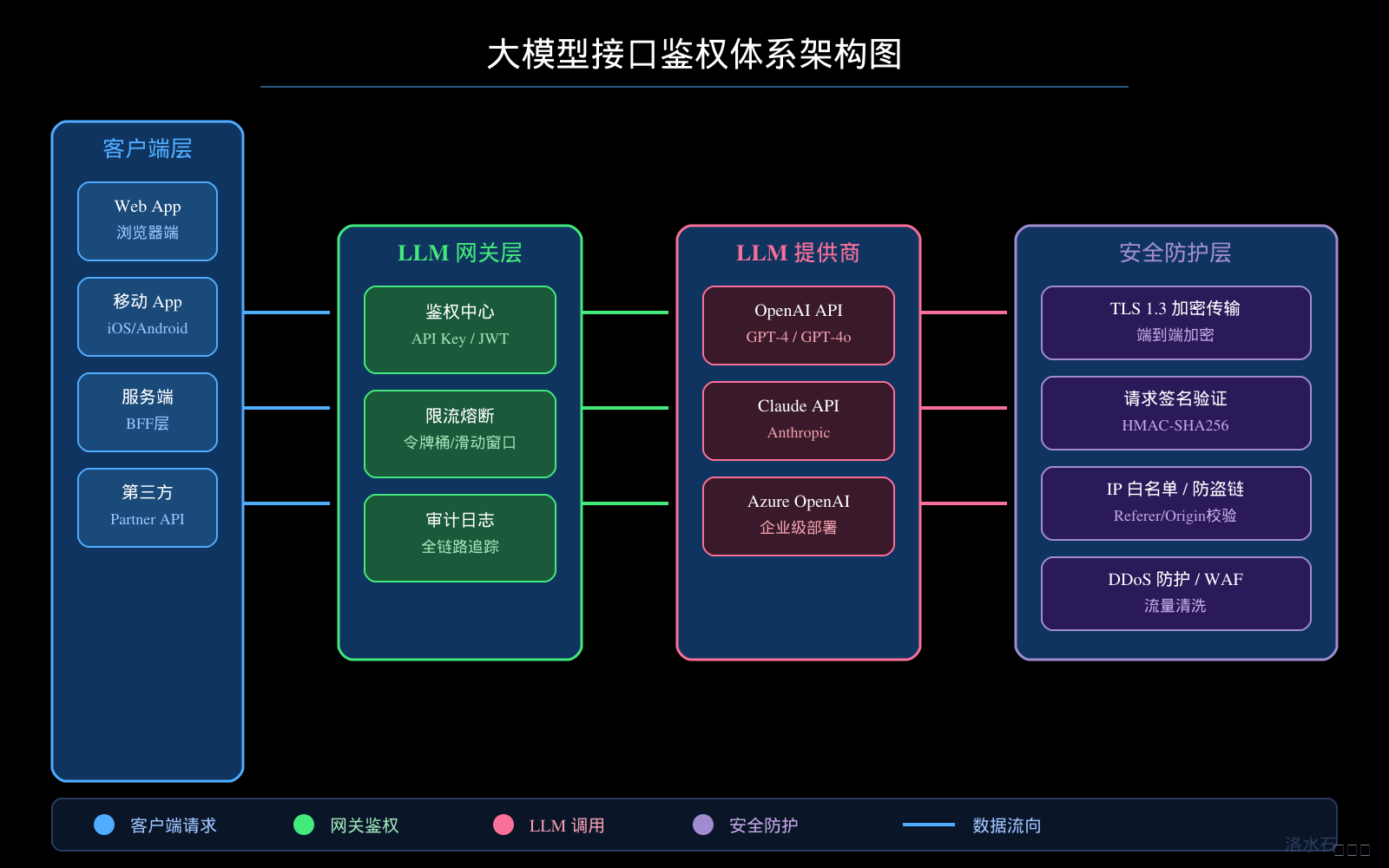
图1:大模型接口鉴权体系架构图
图2:Token 生成与验证流程图
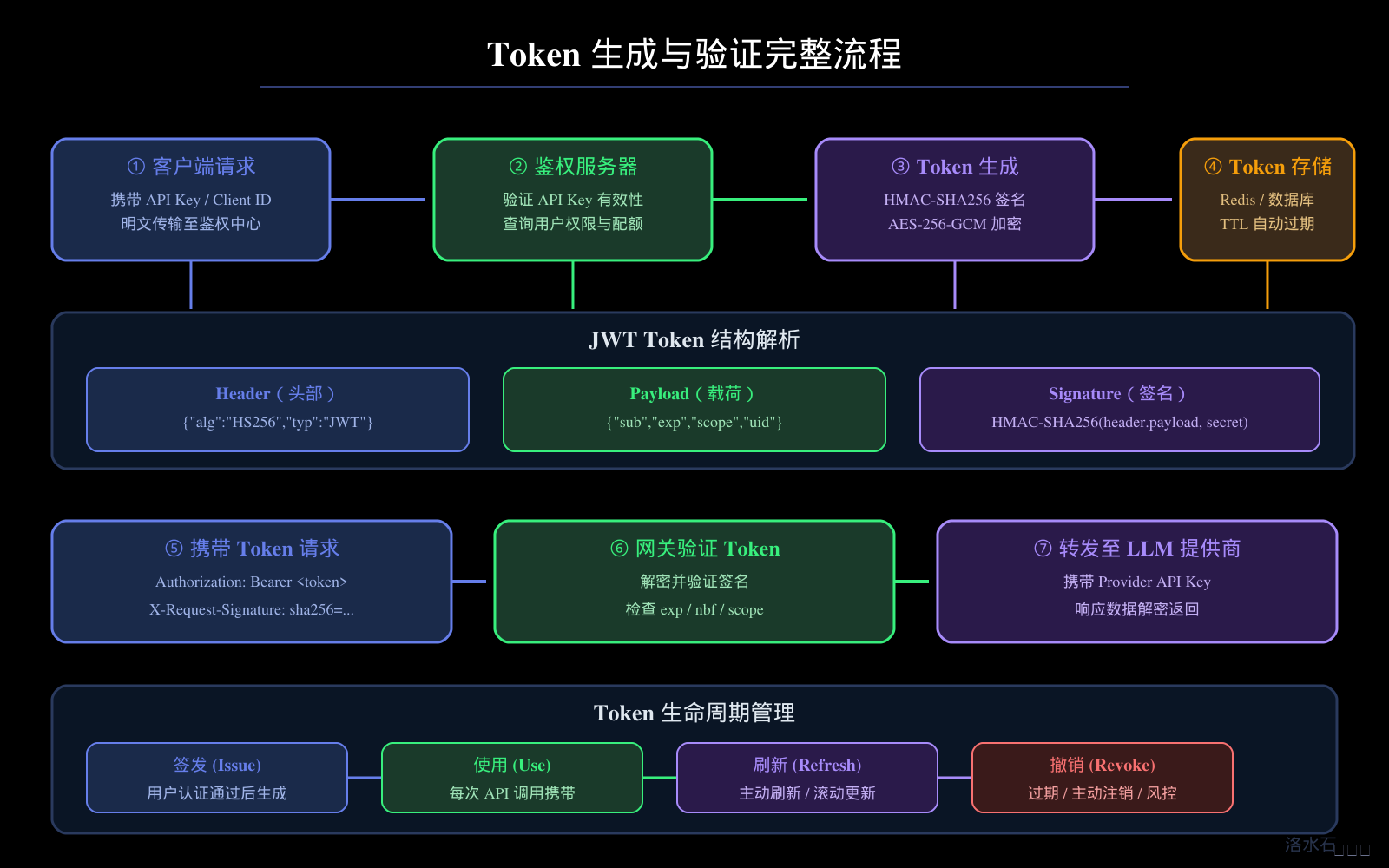
图2:Token 生成与验证完整流程
图3:RBAC 权限模型图
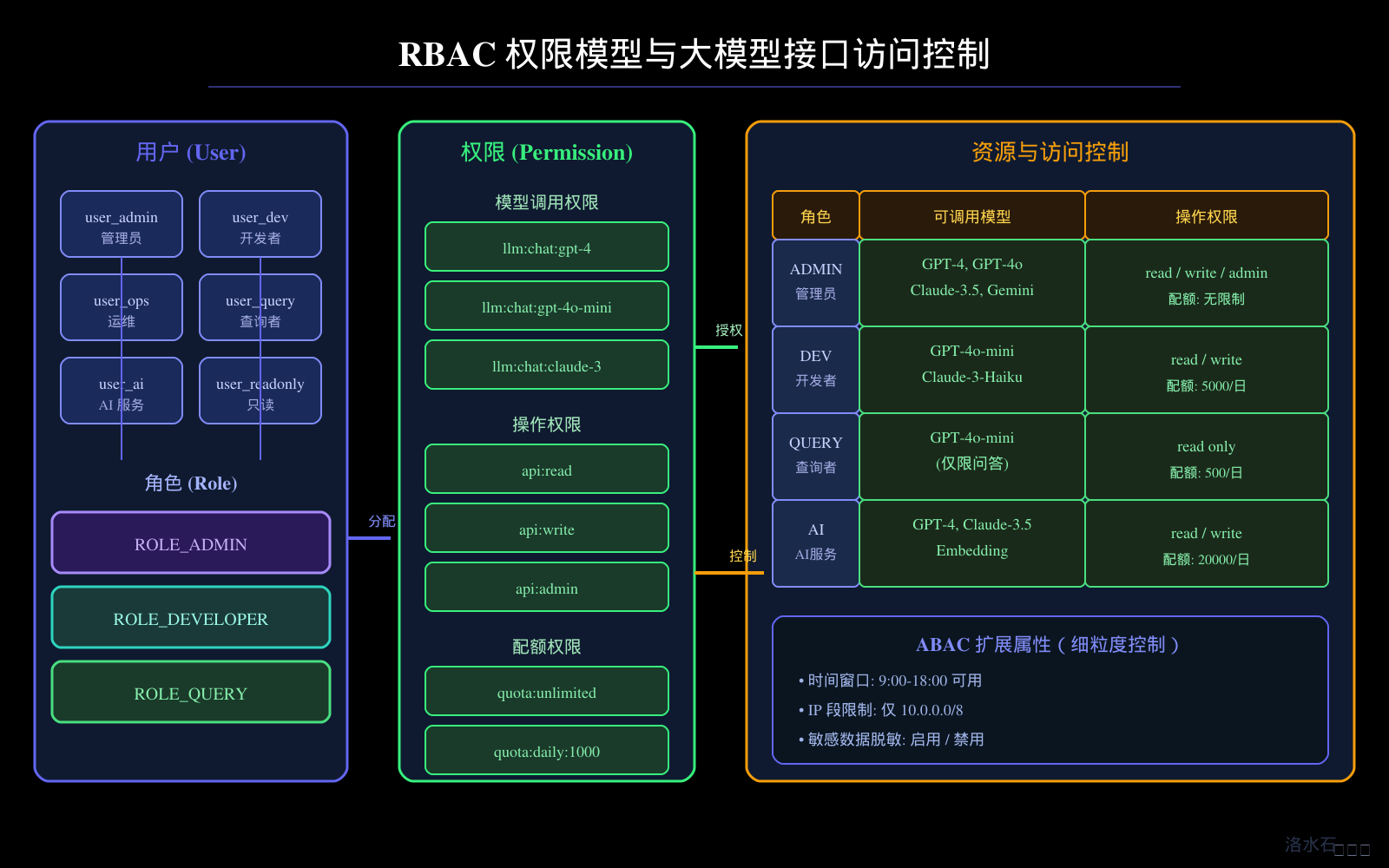
图3:RBAC 权限模型与大模型接口访问控制
图4:API 安全防护体系图
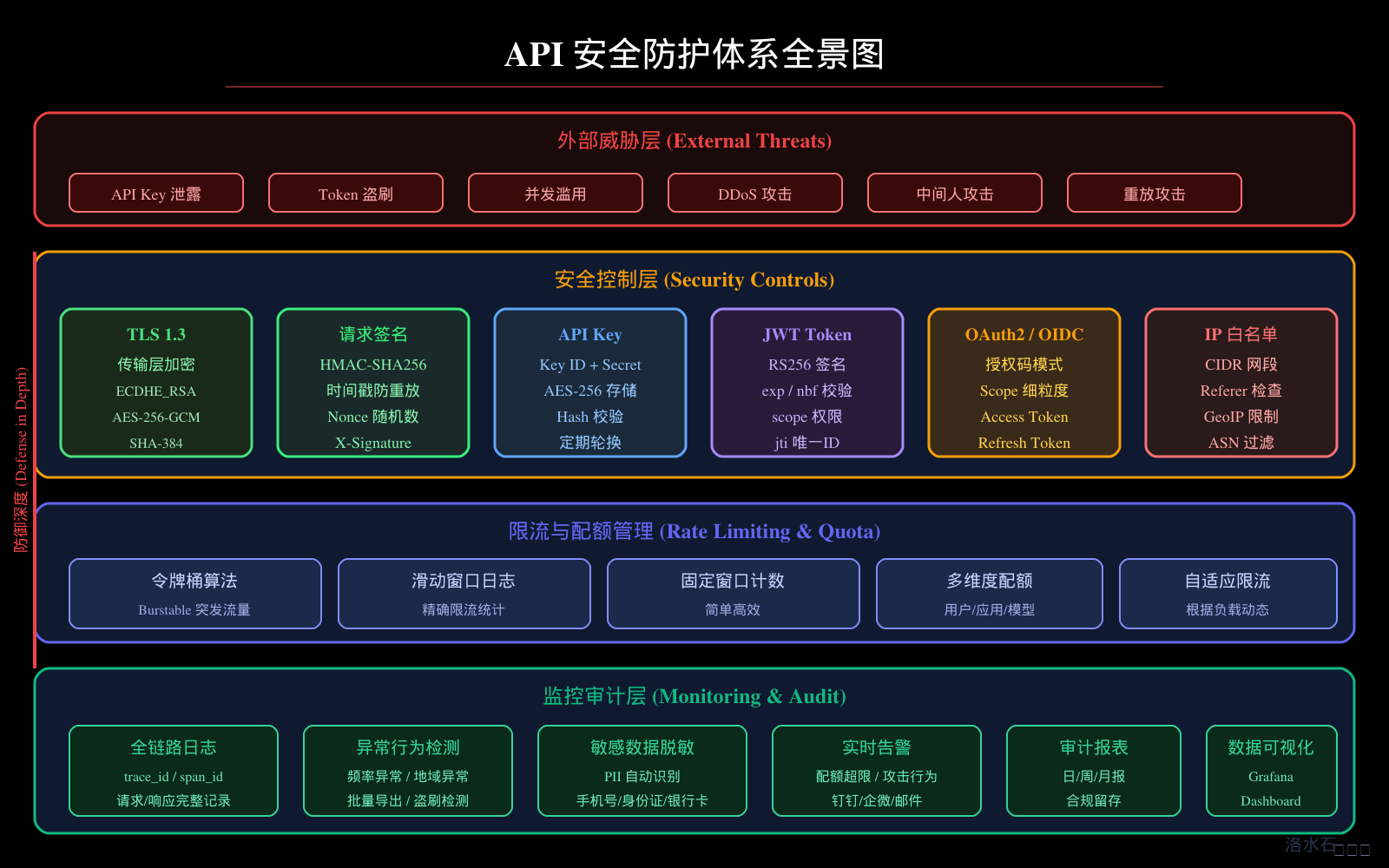
图4:API 安全防护体系全景图