一、线性回归
1、线性回归思想
定义:利用回归方程对一个或多个特征值和目标值之间关系进行建模的一种分析方式
回归方程:
w:weight 权重,b:bias 偏置
使用场景:解决回归问题(目标值是连续的),体重、股票价格、销售额、房价预测等
2、数学基础
标量:
概念:一个独立存在的数,数字4、5、6等
向量:
概念:一个向量表示一组有序排列的数。通过索引 可以确定每个单独的数。
向量的范数:用来衡量向量大小的一种度量方法
矩阵:
概念:矩阵是由多个向量按一定顺序排列组成, 通过行列索引可以确定每个单独的数。表述映射关系。
矩阵加法:两个矩阵必须具有完全相同的行数和列数(即维度完全一致),才能进行加减法运算
矩阵乘法:A为m×n矩阵,B为n×p矩阵,则A与B的乘积C是一个m×p矩阵。
A的列数和B的行数必须一致
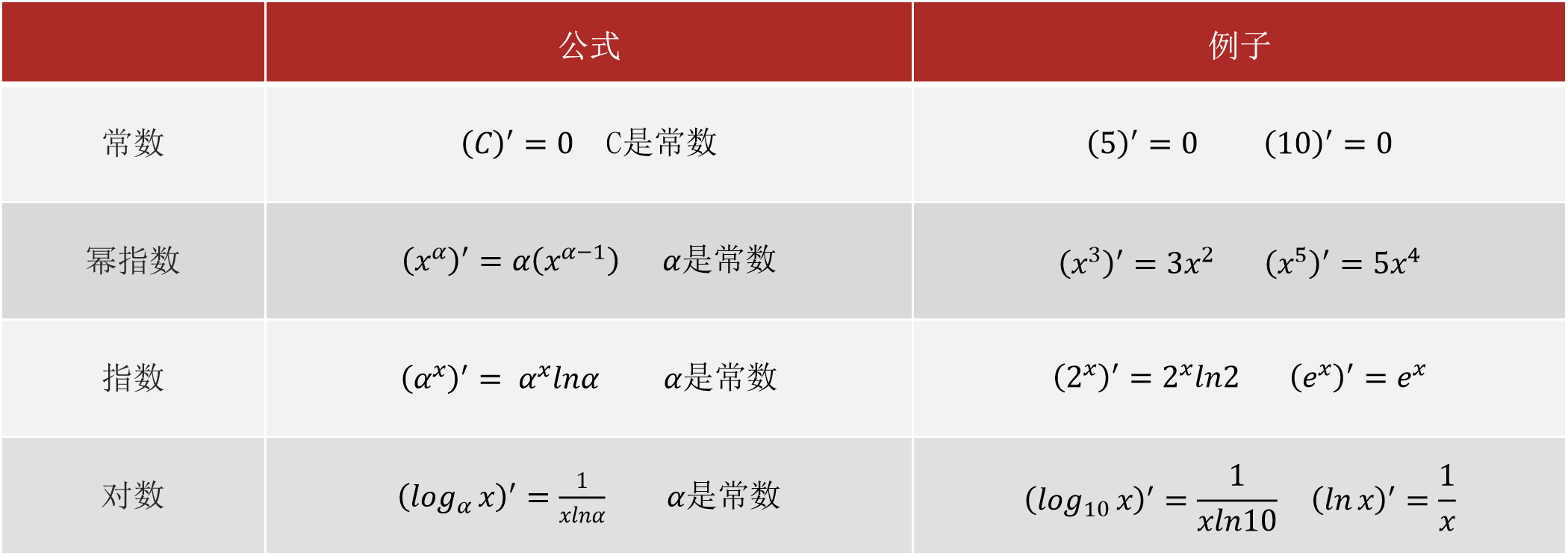
导数:
概念:函数在某点的切线的斜率
函数的极值点出现在什么位置?
函数极值点一般出现在导数为0的点处。
常见函数的导数:
导数的四则运算:
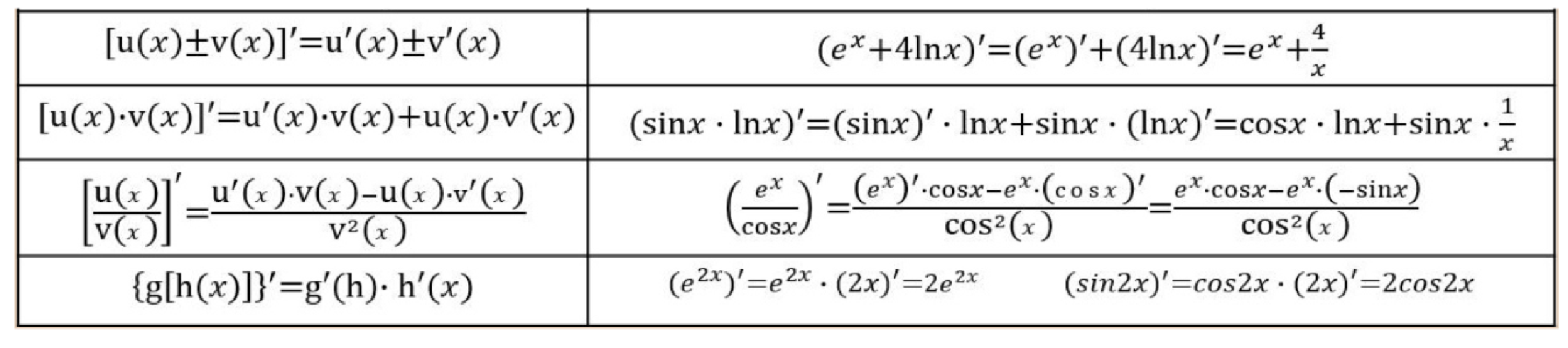
偏导数:
核心思想:对哪个变量求导,就将其他所有变量视为常数,然后使用一元函数的求导法则进行计算。
常用:
|--------------------------------------|-----------------------------------|-----------------------------------|
| 函数形式 f(x, y) | 对 x 的偏导数 (∂f/∂x) | 对 y 的偏导数 (∂f/∂y) |
| z = x² + 3xy + y³ | 2x + 3y | 3x + 3y² |
| z = f(u, v) (u=φ(x,y), v=ψ(x,y)) | (∂z/∂u)·(∂u/∂x) + (∂z/∂v)·(∂v/∂x) | (∂z/∂u)·(∂u/∂y) + (∂z/∂v)·(∂v/∂y) |
3、线性回归求解
3.1 损失函数
**定义:**损失函数用于度量模型的性能,即模型的预测值与真实值之间的差距。
**目标:**损失函数最小化,使模型更好的拟合数据
计算方法:
一元回归:
损失函数:
多元线性回归:
线性回归方程:y = XW
二元最小损失函数(最小二乘法):
3.2 正规方程法
正规方程法的思想:
求解损失函数的一阶导数,令其为零得到的最优解
实现正规方程法使用的工具包:
python
from sklearn.linear_model import LinearRegression正规方程法的优缺点:
优点:直接求解最优解,无超参数
缺点:计算复杂度高,只适合线性场景
代码实现:
python
from sklearn.linear_model import LinearRegression
import pandas as pd
# 数据获取
df = pd.read_csv(r'./data.csv')
x = df.iloc[:, :4].values
y = df.iloc[:, -1].values
# 特征处理
# 模型训练
estimator = LinearRegression()
estimator.fit(x, y)
# 模型评估
print(estimator.coef_) # w 权重
print(estimator.intercept_) # b 偏置
# 模型预测
print(estimator.predict([[1.76, 4, 5, 2]]))3.3 梯度下降法
概念:通过不断迭代,计算损失函数的梯度,并沿着负梯度方向更新算法参数,最小化损失函数得到最优解的方法
相关参数:
梯度:
单变量函数中,梯度就是某一点的导数
多变量函数中,梯度就是某一个点的偏导数
学习率α:
学习率不能太大, 也不能太小
机器学习中:0.001 ~ 0.01
算法流程:
一元梯度下降法:
一元线性回归的损失函数是, 该函数是抛物线。为了便于理解,我们将其简化成
,
其图像如下所示:
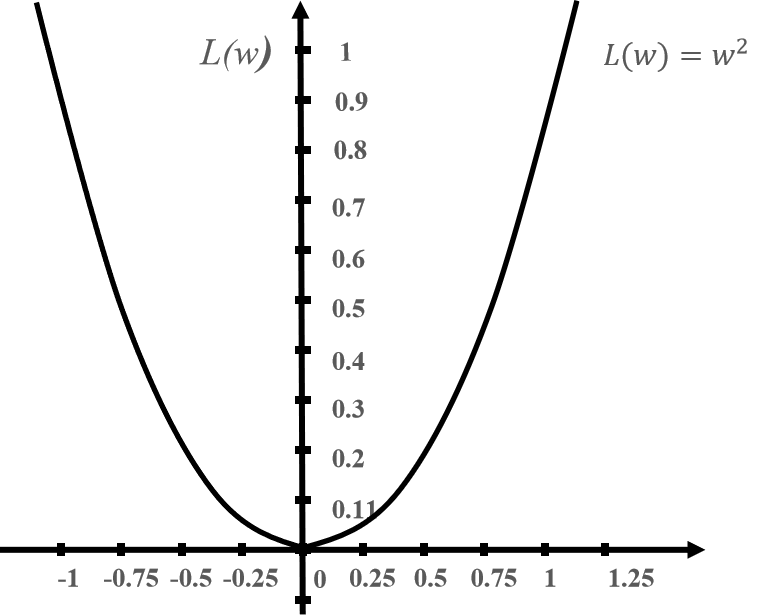
梯度下降算法的流程:
① 给定初始位置w 、学习率α
② 计算当前位置的损失L(w),梯度
③ 带入中,沿负梯度方向更新w
④ 重复 2-3 步骤,直至逼近最优解。
⑤ 终止条件:迭代次数 (可以自行设置)
注:无论在那个位置,都是朝着最优解方向靠近
初始:
,
第一次:w1 = 1 - 0.4*(2*1) = 0.2
第二次:w2 = 0.2 - 0.4*(2*0.2) = 0.04
第三次:w3 = 0.04 - 0.4*(2*0.04) = 0.008
第四次:w4 = 0.008 - 0.4*(2*0.008) = 0.0016
多元梯度下降法:
多元线性回归的损失函数是。为了便于理解,将其简化成
,并且假设只有两个特征,这时损失函数可以写成
,最优解的位置(0,0)
图像如下所示:
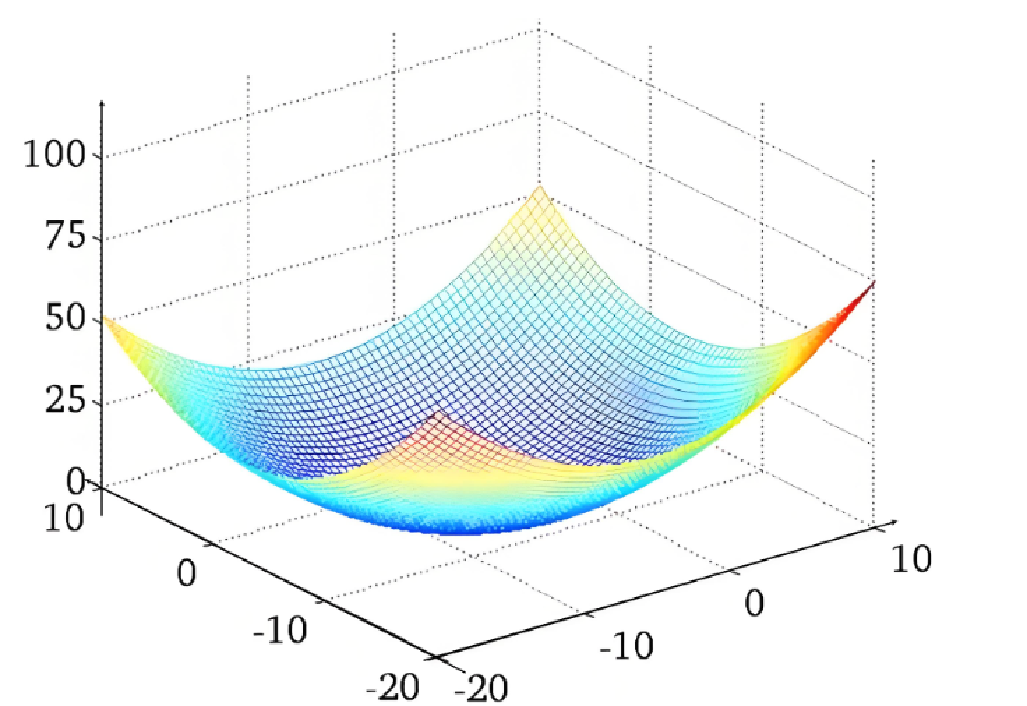
梯度下降算法的流程: 给定初始位置 、学习率α 计算当前位置的损失L(W),梯度
带入
中,更新w 重复 2-3 步 直至逼近最优解。
代码实现:
python
from sklearn.linear_model import SGDRegressor
import pandas as pd
# 数据获取
df = pd.read_csv(r'./data.csv')
x = df.iloc[:, :4].values
y = df.iloc[:, -1].values
# 特征处理
# 模型训练
estimator = SGDRegressor(learning_rate="constant",eta0=0.001,max_iter=200)
estimator.fit(x, y)
# 模型评估
print("权重:",estimator.coef_) # w 权重
print("偏置:",estimator.intercept_) # b 偏置
# 模型预测
print(estimator.predict([[1.76, 4, 5, 2]]))4、回归的评估:
作用:对回归模型的拟合程度和预测能力进行评估
**计算方式:**计算测试数据集中目标值的真实值与预测值之间的差
均方误差(MSE Mean Squared Error):
**概念:**模型的预测值与真实值之间的差的平方的均值
MSE的计算方法如下所示:
其中n表示样本数量,表示第i个样本的真实值,
表示模型对第i个样本的预测值
**结果判断:**MSE越小,说明模型的拟合能力越好。MSE能够放大大误差的数据对评估结果的影响, 对异常值比较敏感
代码使用:
python
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(y_true, y_predict)平均绝对误差(MAE Mean Absolute Error):
**概念:**模型的预测值与真实值之间的差的绝对值的平均值
MAE的计算方法如下所示:
其中,n表示样本数量, 表示第i个样本的真实值,
表示模型对第i个样本的预测值
结果判断:其中,n表示样本数量, 表示第i个样本的真实值,
表示模型对第i个样本的预测值
代码中使用:
python
from sklearn.metrics import mean_absolute_error
mae = mean_absolute_error(y_true, y_predict)代码实现MAE、MAE
python
from sklearn.metrics import mean_absolute_error,mean_squared_error
import numpy as np
y_true = np.array([56.5, 62, 60, 72, 82])
y_pred = np.array([56.3, 60.3, 61.7, 74.5, 83.2])
mse = mean_squared_error(y_true, y_pred)
mae = mean_absolute_error(y_true, y_pred)
print("mse", mse)
print("mae", mae)5、综合案例
案例:预测波士顿地区房价
python
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression,SGDRegressor
from sklearn.metrics import mean_absolute_error,mean_squared_error
# 数据处理
# 1.获取数据
df = pd.read_csv(r'./boston_housing.csv')
x = df.iloc[:, :-1].values
y = df.iloc[:, -1].values
# 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=22)
# 特征处理
transform = StandardScaler()
x_train = transform.fit_transform(x_train)
x_test = transform.transform(x_test)
# 模型训练
# 1、标准化
# estimator = LinearRegression()
# estimator.fit(x_train,y_train)
# 2、梯度下降
estimator = SGDRegressor()
estimator.fit(x_train,y_train)
# 模型评估
y_pred = estimator.predict(x_test)
# 1.mse:均值平方
mse = mean_squared_error(y_true=y_test, y_pred=y_pred)
print("mse:", mse)
# 2. mae:绝对值
mae = mean_absolute_error(y_true=y_test, y_pred=y_pred)
print("mae:", mae)二、决策树
1、决策树简介
1.1 决策树的思想
决策树是一种树形结构
树中每个内部节点表示一个特征上的判断,每个分支代表一个判断结果的输出,每个叶子节点代表一种分类结果
1.2 构建决策树
a.特征选择:选取有较强分类能力的特征。
b.决策树生成:根据选择的特征生成决策树。
c. 决策树也易过拟合,采用剪枝的方法缓解过拟合。
2、CART决策树介绍
CART决策树(Classification and Regression Tree)
2.1 CART决策树的概述
CART决策树是一种二叉树决策树模型,它即可以用于分类,也可以用于回归。
2.2 CART决策树的优缺点
优点: 简单易懂, 功能强大, 规则简洁, 鲁棒性好, 应用广泛.
缺点: 容易过拟合, 结果不稳定, 非全局最优解
2.2 CART 回归树和 CART 分类树的不同?
CART 分类树预测输出的是一个离散值,CART 回归树预测输出的是一个连续值
CART 分类树使用基尼指数作为划分、构建树的依据,CART 回归树使用平方损失
分类树使用叶子节点多数类别作为预测类别,回归树则采用叶子节点里均值作为预测输出
3、CRAT 分类决策树------离散、分离
3.1 怎么判断那个为根节点或那个更接近根节点?
答:Cart分类生成树采用的基尼指数最小化策略。基尼指数值越小(cart),则说明优先选择该特征,该特征越靠近跟节点。
3.2 基尼系数计算流程:先求 基尼指数-> 基尼系数
基尼指数:
概念:基尼指数常被称为**基尼不纯度,**基尼不纯度的值越小,说明数据集越"纯"(即样本大多属于同一个类别)
计算:假设一个数据集 D 中包含 K 个类别,第 k 类样本所占的比例为 ,则该数据集的基尼值计算公式为:
相关参数:
① 数据集D:按指定特征值划分后子集。(例如:是否结婚中的 未婚子集)
② 数据D中各个样本的比例。(例如:未婚中 欠债 和 未欠债 各自占的比例)
基尼指数计算公式:
相关参数:
数据集,按特征值划分后的子集。(例如:是否结婚的 未婚子集、已婚子集)
重要特征:选择的特征,分支后的样本中的类别尽可能相同
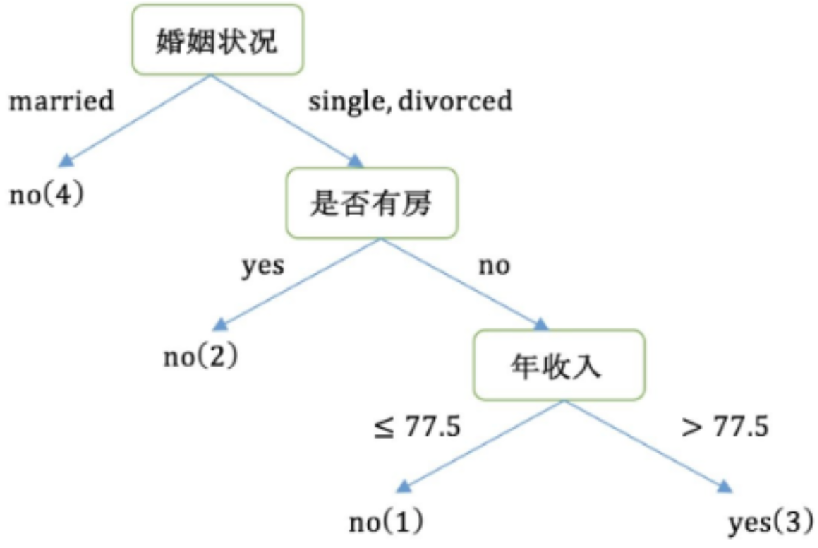
3.3 示例:根据拖欠贷款数据,计算各特征的基尼指数,构建决策树
数据如下:
第一轮:
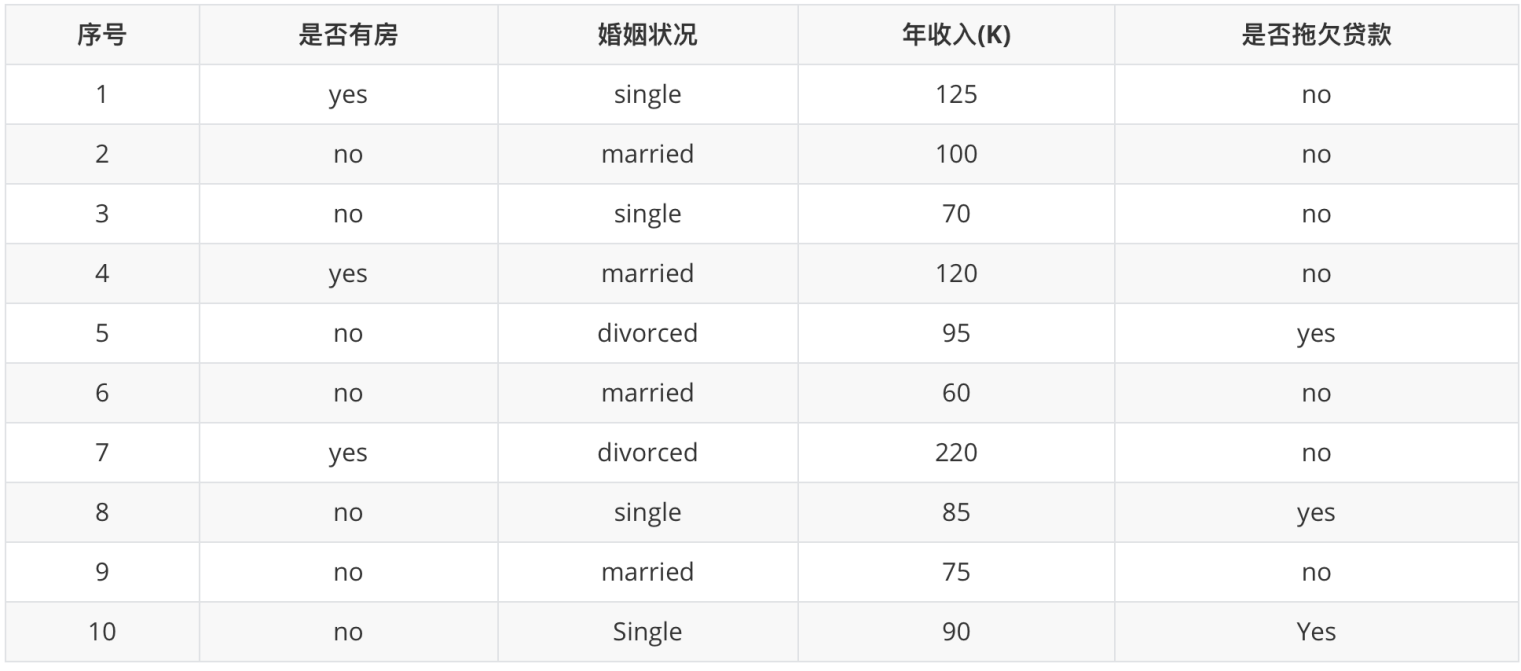
① 是否有房:
有房子的基尼值: 有房子有 1、4、7 共计三个样本,对应目标值:是否拖欠贷款:3个no、0个yes
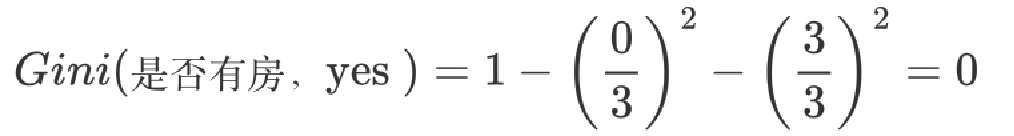
无房子的基尼值:无房子有 2、3、5、6、8、9、10 共七个样本,对应目标值:是否拖欠贷款:4个no、3个yes
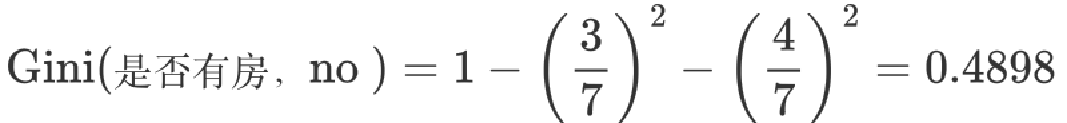
基尼系数:第一部分样本占了总样本的 3/10、第二部分样本占了总样本的 7/10:
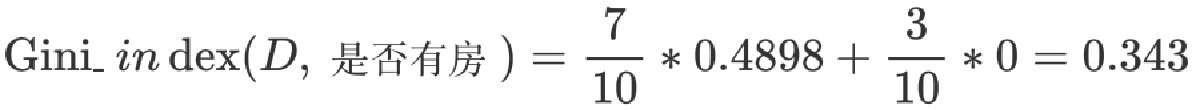
② 婚姻状况
1 计算 {married} 和 {single,divorced} 情况下的基尼指数
结婚的基尼值,有 2、4、6、9 共 4 个样本,并且对应目标值全部为 no:
不结婚的基尼值,有 1、3、5、7、8、10 共 6 个样本,并且对应 3 个 no,3 个 yes
以 married 作为分裂点的基尼指数:
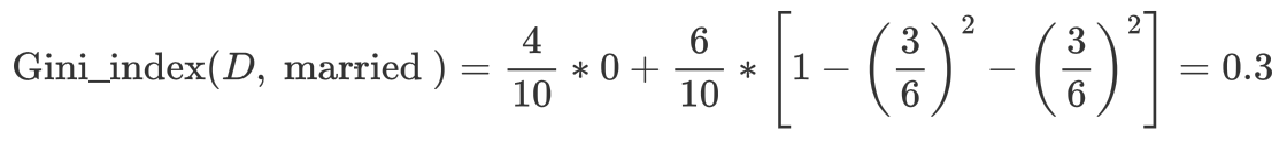
2 计算 {single} | {married,divorced} 情况下基尼指数:
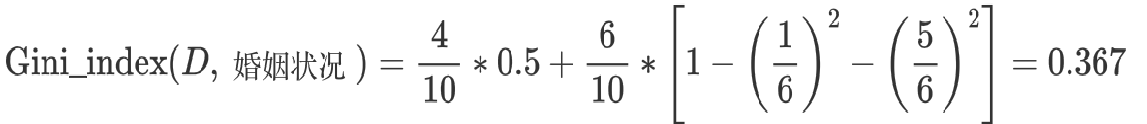
3 计算 {divorced} | {single,married} 情况下基尼指数:
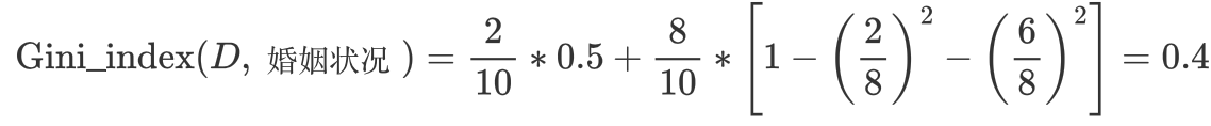
最终:该特征的基尼值为 0.3,并且预选分裂点为:{married} 和 {single,divorced}
③ 年收入
1 先将数值型属性升序排列,以相邻中间值作为待确定分裂点:
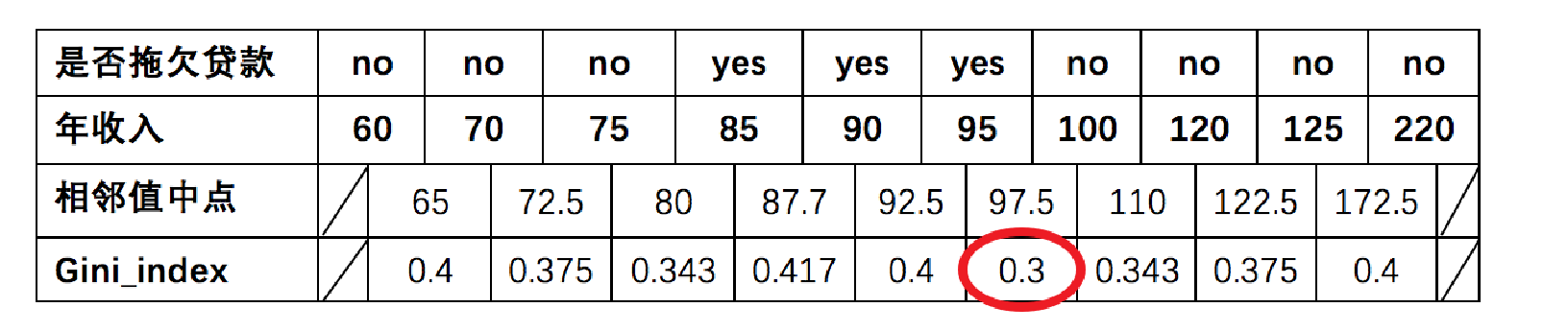
待确定的分裂点为:65、72.5、80、87.7、92.5、97.5、110、122.5、172.5
2 以年收入 65 将样本分为两部分,计算基尼指数:
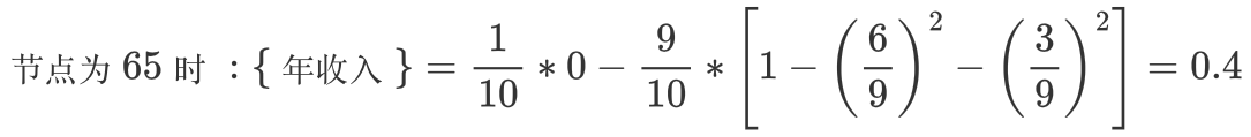
3 以此类推计算所有分割点的基尼指数,最小的基尼指数为 0.3
第1轮结果:
以是否有房作为分裂点的基尼指数为:0.343
以婚姻状况为分裂特征、以 married 作为分裂点的基尼指数为:0.3
以年收入作为分裂特征、以 97.5 作为分裂点的的基尼指数为:0.3
第二轮:
1 样本 2、4、6、9 样本的类别都是 no,已经达到最大纯度 所以,该节点不需要再继续分裂。
2 样本 1、3、5、7、8、10 样本中仍然包含 4 个 no,2 个 yes 该节点并未达到要求的纯度,需要继续划分。
3 右子树的数据集变为: 1、3、5、7、8、10,在该数据集中计算 不同特征的基尼指数,选择基尼指数最小的特征继续分裂。
重复上述过程,直到构建完成整个决策树
3.4 分类决策树API实现------泰坦尼克号是否幸存问题
python
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier,plot_tree
from sklearn.metrics import accuracy_score,classification_report
import matplotlib.pyplot as plt
import matplotlib
matplotlib.use("TkAgg")
# 数据处理
# 1、读取
titanic_df = pd.read_csv(r'./train.csv')
# print(titanic_df.head())
# print(titanic_df.info())
x = titanic_df[["Pclass","Sex","Age"]]
y = titanic_df["Survived"]
# 将Age为空的替换为Age的平均数
x.fillna(x["Age"].mean(),inplace=True)
# print(x)
# 将pclass类别转换为one-hot编码
x = pd.get_dummies(x)
# print(x.values)
# print(x.head())
# print(x.info())
# 特征化处理
# 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=22)
# 模型训练
estimator = DecisionTreeClassifier()
estimator.fit(x_train, y_train)
# 模型评估
y_pred = estimator.predict(x_test)
result_score = accuracy_score(y_true=y_test,y_pred=y_pred)
print("评估结果:", result_score)
# 输出评估报告
evaluation_report = classification_report(y_true=y_test,y_pred=y_pred,target_names=['died', 'survived'])
print("evaluation report:\n",evaluation_report)
# 可视化
plt.figure(figsize=(20,30))
plot_tree(
estimator,
max_depth=3,
filled=True,
feature_names=['Pclass', 'Age', 'Sex_female', 'Sex_male'],
class_names=['died', 'survived']
)
plt.show()4、CRAT 回归决策树------连续
4.1 选择数据集中的哪些特征进行分裂,会更好?
答:Cart回归树使用平方误差最小化策略,选择出最小平方损失的划分点,作为当前树的分裂点。以此计算其他特征的最优划分点、以及该划分点对应的损失值。
CART 回归树的平方损失计算公式:
4.2 示例:根据平方损失,构建CART 回归树
已知:数据集只有 1 个特征 x, 目标值值为 y

① 先将特征 x 的值排序,并取相邻元素均值作为待划分点,如下图所示:

② 计算每一个划分点的平方损失,例如:划分点1.5 的平方损失计算过程为

③ 以此方式计算 2.5、3.5... 等划分点的平方损失,结果如下所示:

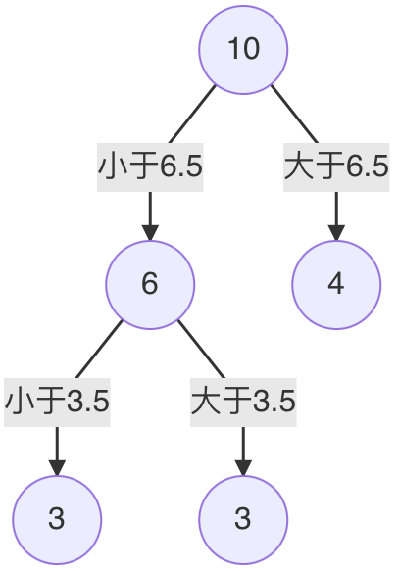
④ 当划分点 s=6.5时,m(s) 最小。所以第1个划分变量:特征为 X, 切分点为 6.5
⑤ 对左子树的 6 个节点计算每个划分点的平方式损失,找出最优划分点

分别计算左侧均值c1和右侧均值c2:

计算对应的平方损失:

⑥ s=3.5时,m(s) 最小,所以左子树继续以 3.5 进行分裂
⑦ 假设在生成3个区域之后停止划分,以下就是最终回归树。
每一个叶子节点的输出为:挂在该节点上的所有样本均值。
4.3 CART 回归树构建过程小结:
① 选择一个特征,将该特征的值进行排序,取相邻点计算均值作为待划分点
② 根据所有划分点,将数据集分成两部分:R1、R2
③ R1 和 R2 两部分的平方损失相加作为该切分点平方损失
④ 取最小的平方损失的划分点,作为当前特征的划分点
⑤ 以此计算其他特征的最优划分点、以及该划分点对应的损失值
⑥ 在所有的特征的划分点中,选择出最小平方损失的划分点,作为当前树的分裂点
4.4 调用API,代码实现预测波士顿房价
python
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression,SGDRegressor
from sklearn.metrics import mean_absolute_error,mean_squared_error
from sklearn.tree import DecisionTreeRegressor
import math
# 数据处理
# 1.获取数据
df = pd.read_csv(r'./boston_housing.csv')
x = df.iloc[:, :-1].values
y = df.iloc[:, -1].values
# print(x)
# 数据集划分
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=22)
# 特征处理
transform = StandardScaler()
x_train = transform.fit_transform(x_train)
x_test = transform.transform(x_test)
# 模型训练
# 1、标准化
# estimator = LinearRegression()
# estimator.fit(x_train,y_train)
# 2、梯度下降
# estimator = SGDRegressor()
# 3、决策树
estimator = DecisionTreeRegressor()
estimator.fit(x_train,y_train)
# 模型评估
y_pred = estimator.predict(x_test)
# 1.mse:均值平方
mse = mean_squared_error(y_true=y_test, y_pred=y_pred)
rmse = math.sqrt(mse)
print("mse:", mse)
print("rmse:",rmse)
# 2. mae:绝对值
mae = mean_absolute_error(y_true=y_test, y_pred=y_pred)
print("mae:", mae)5、决策树剪枝------减少模型复杂度
为什么要剪枝?
决策树剪枝是一种防止决策树过拟合的一种正则化方法;提高其泛化能力
剪枝方法:
**预剪枝:**指在决策树生成过程中,对每个节点在划分前先进行估计,若当前节点的划分不能带来决策树泛化性能提升,则停止划分并将当前节点标记为叶节点;
后剪枝(一般不用) :是先从训练集生成一棵完整的决策树,然后自底向上地对非叶节点进行考察,若将该节点对应的子树替换为叶节点能带来决策树泛化性能提升,则将该子树替换为叶节点。