
大家好,我是若风。
这两天我花了 10 分钟看大模型价格,越看越觉得有意思,甚至有点焦虑。
一边是 DeepSeek 继续把价格往下打。官方文档里写得很直接:全模型输入缓存命中价格,从 2026 年 4 月 26 日 12:15 UTC 开始,降到发布价的 1/10;DeepSeek-V4-Pro 的 75% 折扣也不再只是促销,2026 年 5 月 31 日 15:59 UTC 结束后,会正式调整为原价的 1/4。
先看 DeepSeek-V4 刚发布时的价格:V4-Pro 的 Input(Cache Hit)是 0.145/1Mtokens,Input(CacheMiss)是1.74,Output 是 3.48;V4−Flash更便宜,分别是0.028、 0.14、0.28。两档模型都给到 1M 上下文窗口,一个主打更强能力,一个主打低价走量。
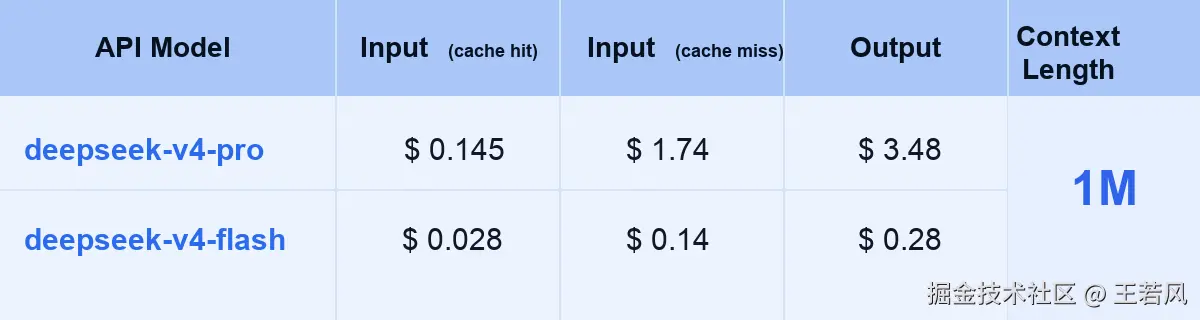
这张 DeepSeek-V4-Pro 降价图的信息很直白:75% OFF 从限时活动变成永久价格。折后 Input(Cache Hit)是 0.003625/1Mtokens,原价0.0145;Input(Cache Miss)是 0.435,原价1.74;Output 是 0.87,原价3.48。最关键的不是"便宜了多少",而是价格基准变了:原本大家以为 75% OFF 是促销,到期会涨回去,现在官方直接把它变成长期定价。

更有意思的是,DeepSeek 不是拿一个明显弱很多的模型去打价格战。官方 bench 对比图里,DeepSeek-V4-Pro-Max 被放在 Claude Opus 4.6 Max、GPT-5.4 xHigh、Gemini 3.1 Pro High 旁边比较。它在 MMLU-Pro 上是 87.5,SimpleQA Verified 是 57.9,Chinese-SimpleQA 是 84.4,LiveCodeBench 是 93.5,Codeforces Rating 是 3206;在 Agentic 类指标里,Terminal Bench 2.0 是 67.9,SWE Verified 是 80.6,BrowseComp 是 83.4,MCPAtlas Public 是 73.6。
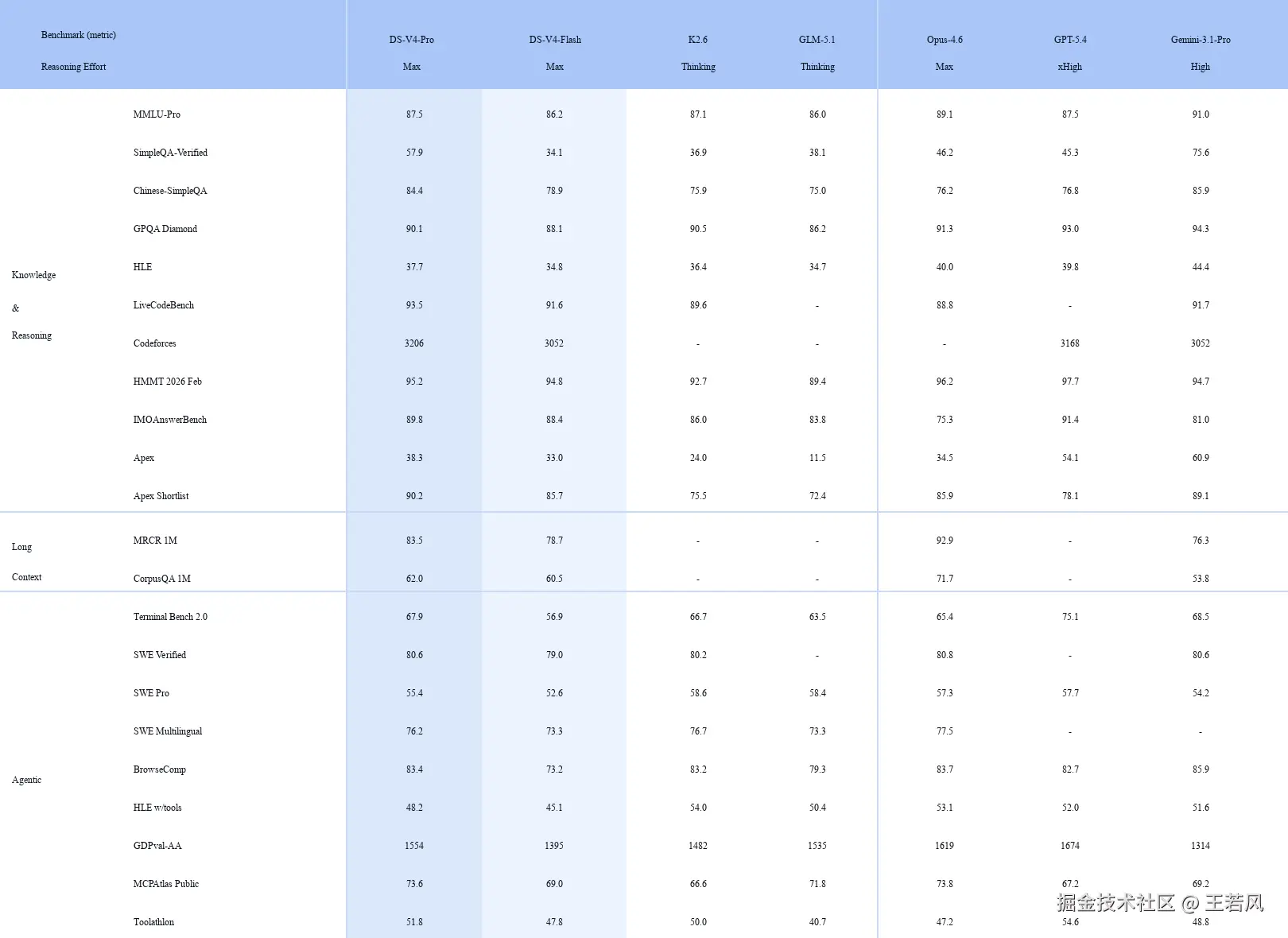
第二张柱状图把这个对比压得更直观:DeepSeek-V4-Pro-Max 在 Apex Shortlist 上是 90.2,高于 Claude Opus 4.6 的 85.9 和 GPT-5.4 的 78.1;Codeforces 是 3206,也高于 GPT-5.4 的 3168;SWE Verified 是 80.6,和 Claude Opus 4.6、Gemini 3.1 Pro 基本同一水平。它不是每一项都第一,比如 SimpleQA 和 HLE 上 Gemini 更强,Terminal Bench 2.0 上 GPT-5.4 更高,但整体看下来,DeepSeek 想传递的信息很明确:价格在往下打,能力没有退出第一梯队。
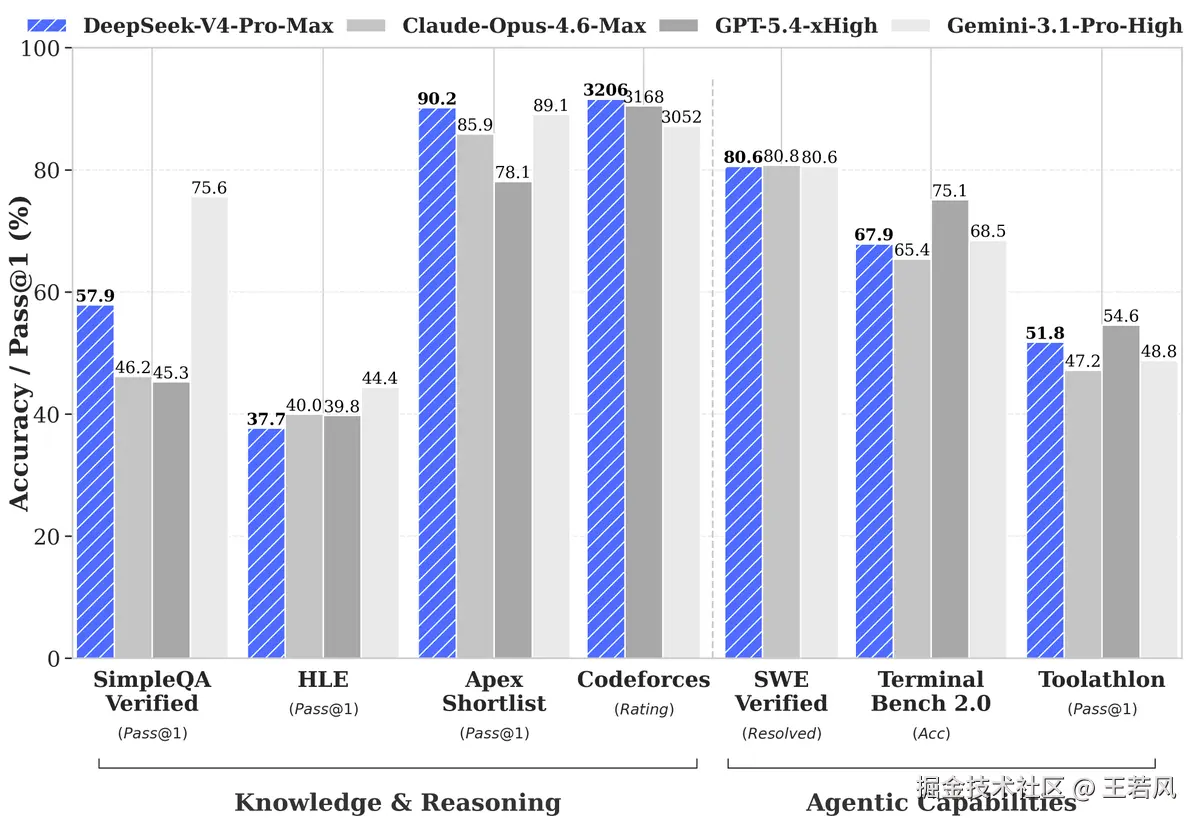
如果把时间线拉长一点看,DeepSeek 给其他厂商的压力,主要不在某一次降价,而在它"迭代快、降价也快"。
| 时间 | 动作 | 价格信号 | 对行业的压力 |
|---|---|---|---|
| 2024-08-02 | 上线硬盘级 Context Caching | 通过缓存把价格再降一个数量级 | 价格战不是单纯补贴,而是从推理架构里抠成本 |
| 2024-12-26 至 2025-02-08 | DeepSeek-V3 API 限时折扣 | 缓存命中 0.07→0.014;缓存未命中 0.27→0.14;输出 1.10→0.28 | V3 一发布就用低价窗口抢开发者心智 |
| 2025-09-29 | DeepSeek-V3.2-Exp 发布,同时 API 降价 | 官方表述 API prices cut by 50%+ | Sparse Attention 降本开始被包装成产品价格优势 |
| 2026-04-24 | DeepSeek-V4 上线 API | V4-Pro 启动 75% OFF 促销,折后输出 $0.87 / 1M tokens | 旗舰模型直接按中低端 API 价格卖 |
| 2026-04-26 | 全系列缓存命中输入降价 | 全模型 cache hit 调到发布价 1/10 | 长上下文时代,输入 token 接近"白菜价" |
| 2026-04-29 | V4-Pro 75% OFF 促销延期 | 促销从 5 月 5 日延到 5 月 31 日 | 从短促销变成持续压价 |
| 2026-05-22 | V4-Pro 折扣永久化 | 75% 折扣结束后不恢复原价,正式变成原价 1/4 | 价格战从营销活动变成长期定价 |
这个节奏对同行很难受。因为你刚把价格表改完,DeepSeek 可能又发了新模型;你刚解释完"旗舰模型为什么不能便宜",它又把旗舰模型的促销价改成永久价。表面上看是 API 价格在下降,真正的压力是产品节奏被拉快了:模型能力、推理优化、开发者价格,三件事开始被绑在一起迭代。
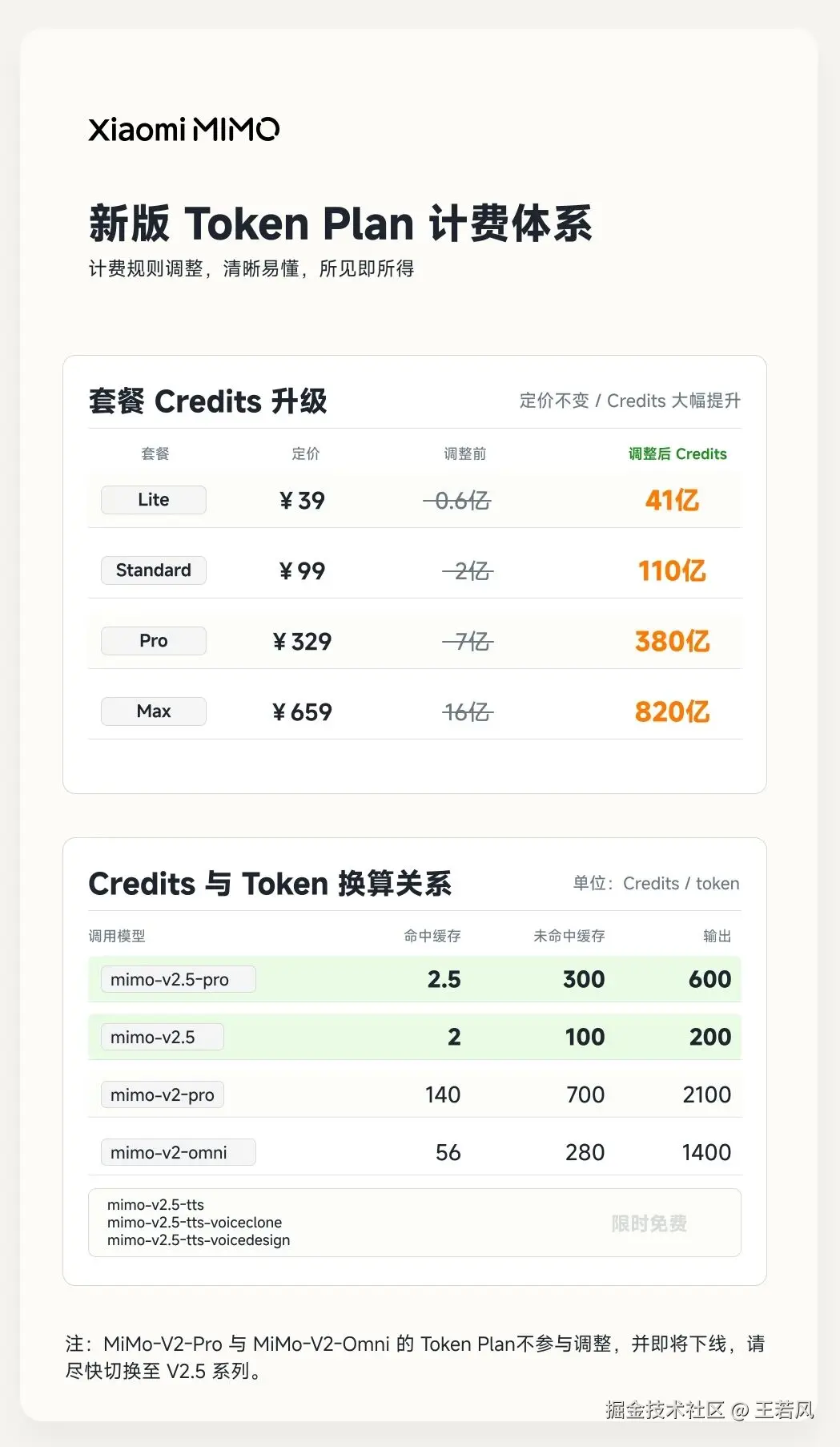
另一边,小米 MiMo-V2.5 也在降价。公告里说,API 永久降价,最高降幅可达 99%;Token Plan 的可用量提升到原来的 5-8 倍;背后靠的是推理系统优化,比如把 KV Cache 在 GPU、CPU、SSD 多级存储之间的数据搬运量降到接近原来的 1/7,可缓存 token 数量提升到接近 5 倍。
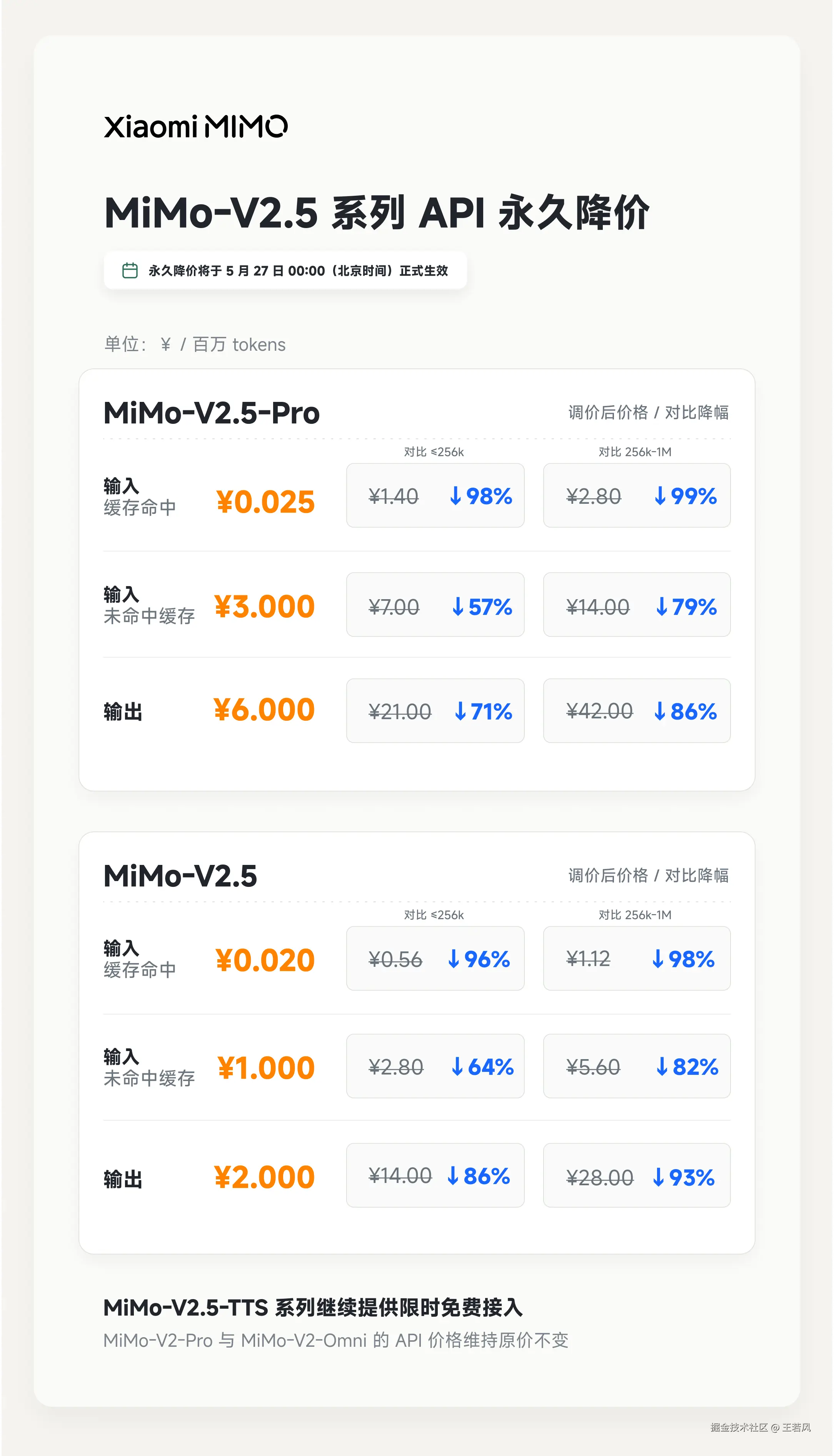
说实话,表面上看,这是好消息。
模型越来越便宜,开发者越来越幸福,AI 应用终于可以放开手脚跑了。
但几乎同一时间,另一个故事也在发生:很多公司开始发现,AI Coding 的账单正在失控。有报道提到,Uber 4 月就已经耗尽了全年 Claude Code 预算;微软也开始要求内部开发更多切到自家的 GitHub Copilot,本质上还是为了控成本。
这就很反直觉了。
为什么模型单价一直降,公司却反而快烧不起 Token 了?我倒是觉得,这里面藏着 AI Coding 接下来最关键的一道坎。
便宜的是单价,变贵的是用法
先说结论:今天 AI 成本的核心矛盾,不是"每 100 万 Token 多少钱",而是"你让模型以什么方式工作"。
过去我们用大模型,很多时候还是聊天。
问一个问题,等一个回答。写一段文案,改一段代码,解释一个报错。一次请求通常有明确边界,输入多少、输出多少,大概能估出来。
但 AI Coding 和 Agent 不一样。
它不是一次问答,而是一串动作:读代码、找文件、分析依赖、生成补丁、跑测试、看报错、再改一轮、再跑一轮。每一步都在消耗 Token,而且很多步骤还会带上大量上下文。
这时候 Token 单价再便宜,也架不住调用方式变了。
以前你是在买一杯咖啡。现在你是在给一整层办公室接无限续杯。
DeepSeek 和 MiMo 降价,降的是推理的"单位成本"
DeepSeek 和小米这轮降价,真正值得关注的地方,不只是价格表上的数字,而是它们都在围绕同一个方向发力:把推理成本压下去。
DeepSeek 的关键动作是缓存命中价格。对长上下文、重复前缀、固定系统提示词、Agent 工作流来说,缓存命中非常重要。因为很多请求不是从零开始的,系统提示词、工具说明、项目背景、代码上下文,经常会反复出现。
如果这些内容可以被缓存,输入 Token 的成本就会变得非常低。
从 DeepSeek-V4-Pro 的价格图也能看出来,它最狠的一刀砍在缓存命中输入上:$0.003625 / 1M tokens,已经低到几乎像是在鼓励开发者把稳定上下文尽量缓存起来。对普通聊天来说,这只是一个便宜价格;但对 Agent 来说,这其实是在重写成本结构,因为 Agent 最常重复消耗的,恰恰就是系统提示词、工具定义、项目背景和长上下文前缀。
小米 MiMo 的逻辑也类似。它在公告里讲到 SGLang HiCache、多级 KV Cache、Sliding Window Attention、专家并行、输入长度分桶。这些词看起来很工程,但落到成本上,其实就是一句话:
把模型每处理一个 Token 所需要付出的真实计算和搬运成本降下来。
这里可以稍微展开一下。
MiMo 这次降价里,降幅最大的是 Input(Cache Hit),最高到 99%。原因不是简单"补贴开发者",而是推理框架已经支持针对 SWA(Sliding Window Attention)的分层 KV Cache 优化。按照素材里的说法,生产推理引擎测试中,这个优化把缓存 Token 容量提升了 5 倍,相当于缓存成本降低了 80%。
更关键的是,MiMo-V2.5-Pro 的架构里有一个很激进的稀疏设计:Full Attention 和 SWA 的比例接近 1:7。换成人话讲,70 层 MiMo-V2.5-Pro 的 prefill 计算量,大约相当于一个 10 层的 GQA 模型。Input(Cache Miss)和 Output 能降 60%-80%,靠的就是这种模型结构和推理引擎一起省下来的成本。
这也是为什么小米敢说,按新 API 价格跑,生产推理引擎接近满负荷运转,但仍然基本能保持收支平衡。
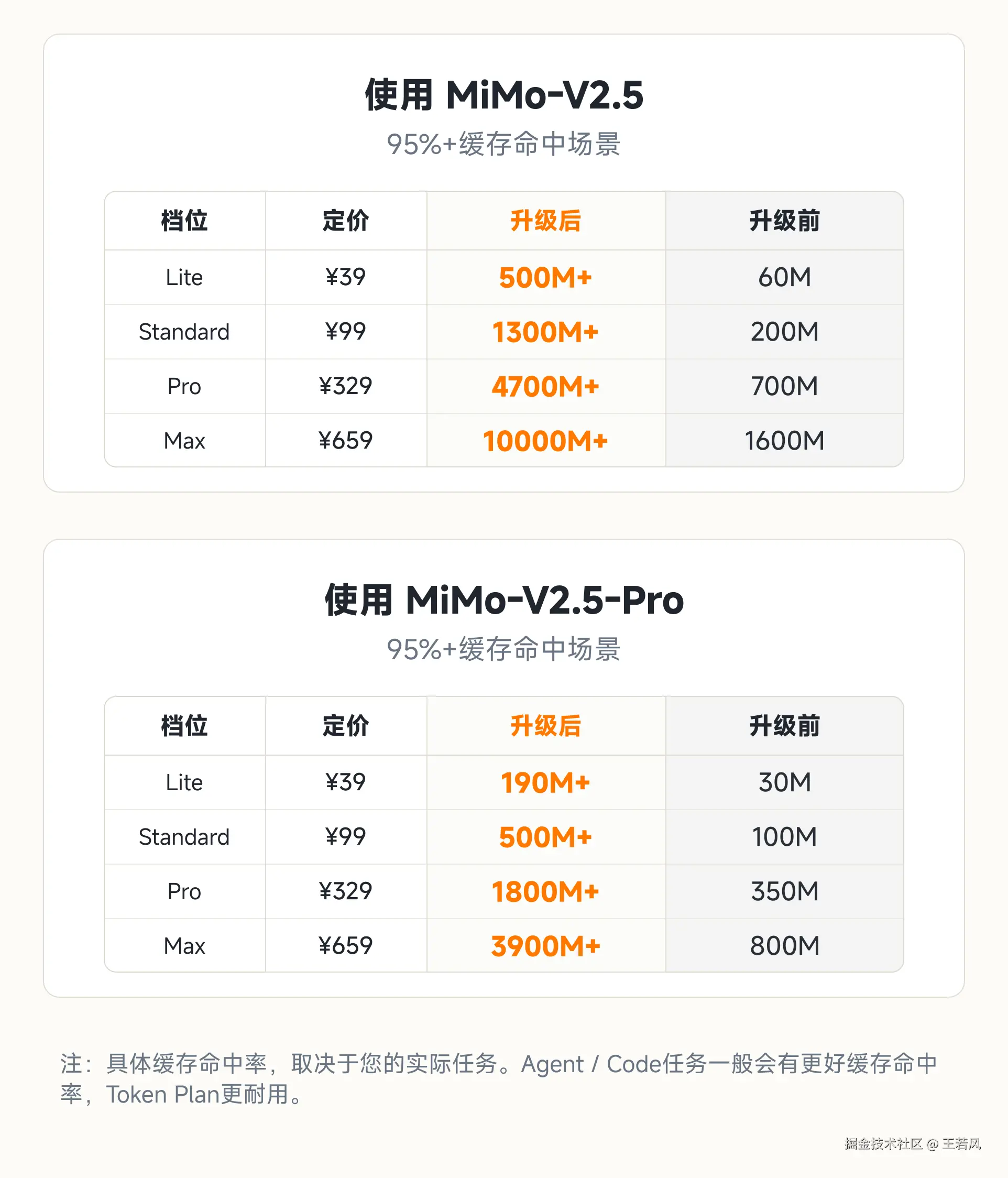
这也是为什么它们敢降价。
价格战的背后,不只是营销补贴,而是推理基础设施在进步。
但 AI Coding 烧钱,烧在"循环"
问题在于,AI Coding 最贵的地方,往往不是单次调用。
而是循环。
一个人类程序员写代码,贵在工资、经验和时间。但他不会 24 小时不停地读取整个仓库、反复生成方案、跑失败的测试、把错误日志重新喂给模型,再继续下一轮。
Agent 会。
这里有两个很典型的例子。Uber 早在 4 月就耗尽了 2026 年全年的 Claude Code 预算,甚至不得不重新评估招聘节奏;微软也开始把内部开发从 Claude Code 切回自家的 GitHub Copilot,本质上不是因为不想用 AI,而是预算需要被重新关进笼子里。
这两个案例有意思的地方在于,它们都不是"小团队不懂成本控制"。Uber 和微软这种公司,采购、预算、工程平台都很成熟,依然会被 AI Coding 的消耗速度吓到。说明问题不只是某个工具贵,而是 AI Coding 的使用模式天然容易把成本放大。
而且 Agent 很容易进入一种"看起来很努力,实际上很费钱"的状态:它会为了一个小问题读很多文件,为了一个不确定的假设跑很多轮验证,为了补一个边界条件生成大量中间推理和上下文。
尤其当团队开始让 AI Agent 7x24 小时运行时,成本结构就变了。过去一个程序员下班了,任务会自然停下来;现在 Agent 可以一直排队处理 issue、扫代码、改测试、跑 CI、复盘日志。每一轮看起来都很小,合起来就是一张持续滚动的 Token 账单。
更麻烦的是,AI 生成代码并不是"写完就结束"。如果它写出隐藏缺陷,后面还要人工 Review、补测试、回滚、重构,甚至让另一个模型再来检查一遍。表面上省下的是写代码时间,真正增加的可能是验证、返工和治理成本。
这就是为什么很多公司会突然发现,AI 工具不是简单替代人力成本,而是新增了一种高频、自动化、难以被业务方直观看见的云账单。
它不像人类员工那样有自然的疲劳边界。只要权限开着,预算就会继续流。坦白讲,这才是很多团队真正崩的地方:不是模型回答得不够快,而是它太能干活,也太能花钱。
真正贵的不是 Token,而是不受控的 Agent
所以我觉得,这轮价格变化里最值得写给创作者和开发者的一句话是:
Token 正在变便宜,但"让 AI 自己干活"正在变贵。
这不是矛盾。
因为前者讲的是单位价格,后者讲的是系统行为。
就像电费单价下降,不代表你开一座数据中心就便宜;高速公路收费降了,不代表物流公司可以让车空跑;模型 API 降价,也不代表 Agent 可以无限循环。
真正决定成本的,是三件事:
- 每次任务带多少上下文;
- 一个任务要调用多少轮模型;
- 失败、回滚、重试、验证这些隐藏步骤有没有上限。
AI Coding 的账单,很多时候就藏在第三项里。
接下来会发生什么?
我倾向于判断,模型价格还会继续往下走。
DeepSeek 和 MiMo 这类玩家会持续把推理成本做成武器。尤其是缓存、长上下文、MoE 推理、多级存储这些方向,只要工程优化还能继续挤水分,API 单价就还有下降空间。
但企业侧不会因此"无脑多用 AI"。
相反,下一阶段大家会越来越关心 AI 使用的治理能力:谁能调用模型,什么任务可以用高价模型,Agent 最多跑几轮,单个任务最大预算是多少,失败后什么时候必须停下来交给人。
这才是 AI Coding 进入生产环境后真正要补的一课。
不是会不会写代码。是会不会花钱。
给开发者和团队的几个判断
如果你正在做 AI Coding 或 Agent 产品,我觉得有几个点可以提前放进设计里。
第一,尽量让上下文稳定,吃到缓存红利。系统提示词、工具说明、项目规则、固定文档,应该放在稳定前缀里,不要每次都随机重组。
第二,给 Agent 设置预算边界。比如单任务最大 Token、最大工具调用次数、最大重试次数、最大测试轮数。没有边界的 Agent,很容易把"自动化"跑成"自动烧钱"。
第三,把成本展示给用户。不要只告诉用户"AI 正在思考",最好告诉他这次任务大概消耗了多少轮、多少 Token、多少钱。成本不可见,滥用就不可避免。
第四,便宜模型和强模型要分层。不是所有任务都需要最强模型。读文件、分类、提取、格式化、简单修复,可以走低成本模型;架构判断、复杂调试、安全风险,再交给更强模型。
最后,也是最重要的一点:不要把"Token 降价"误读成"AI 免费"。
降价会让更多应用成立,但不会自动让所有应用赚钱。
模型公司正在努力把单位推理成本打下来;应用公司要解决的,是如何让每一次推理都值得。
写在最后。
这可能才是 AI Coding 成熟的标志。
不是它能写出多少代码,而是它终于学会了控制账单。