一、决策树简介
1. 概述
决策树(Decision tree)是一种有监督学习算法,是一种树形结构的预测模型,用于分类任务或回归任务。每个内部节点表示一个特征(属性)的判断,每个分支代表判断的结果,而叶节点则代表最终的决策结果(类别或数值)。
核心思想:分而治之
决策树的目标是根据数据的多个特征,学习出一系列判断规则,从而对目标变量进行预测。
换句话说,它通过一系列"如果-那么"规则来分割数据,构建树状结构模拟人类决策过程。
举例
母亲要给女儿介绍男朋友,发生了以下对话:
女儿:多大年纪了?
母亲:26。
女儿:长得帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
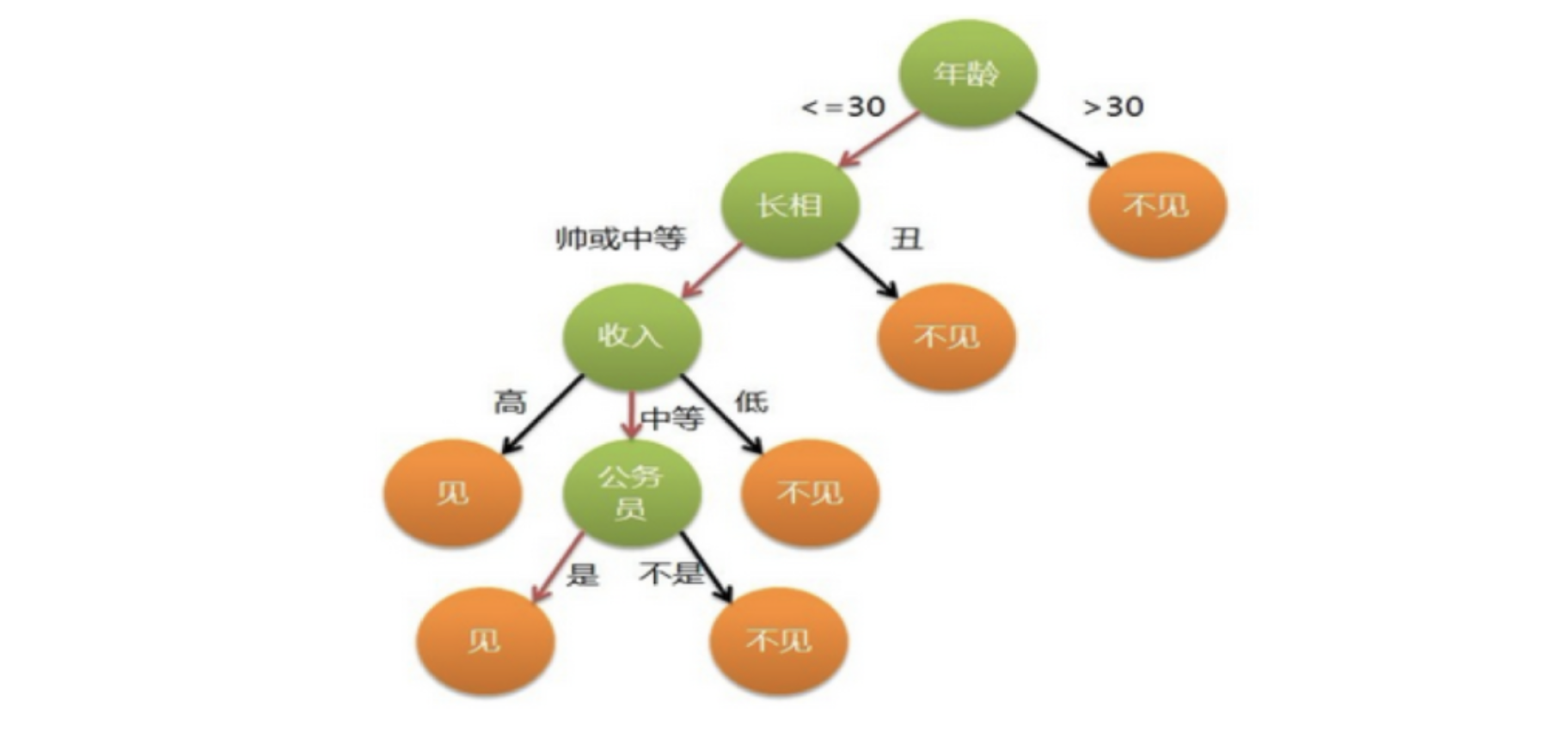
上述例子中的女孩的决策过程就是典型的分类树决策。相当于通过年龄、长相、收入和是否是公务员将男人分为两个类别:见和不见。
2. 决策树的建立过程
从根节点开始,反复选择有较强分类能力的分裂特征与分裂点对数据进行划分,直到每个子集中的数据足够"纯"或满足停止条件。
3. 决策树的构成
-
根节点 (Root Node):最顶层的节点,代表最初的问题或判断标准。比如上图中的"多大年纪了?"
-
内部节点 (Internal Node):中间层节点,代表后续的问题或判断。比如"长得帅不帅?"
-
分支 (Branch):从节点引出的箭头,代表该节点的判断结果(如"帅或中等"/"丑")。
-
叶节点 (Leaf Node):终端的节点,代表最终的决策或预测结果(如"见"/"不见")。
二、决策树的种类
1. 按任务类型分类
| 类型 | 预测目标 | 叶子节点输出 | 分裂指标 | 典型应用 |
|---|---|---|---|---|
| 分类树 | 离散值 | 选取多数类标签 | 信息增益、信息增益率、基尼指数 | 信用评分、疾病诊断 |
| 回归树 | 连续值 | 选取样本平均值 | 均方误差(MSE) | 房价预测、销量预测 |
2. 按算法分类
| 算法 | 提出年份 | 分裂指标 | 分支方式 | 特征类型 |
|---|---|---|---|---|
| ID3 | 1975 | 信息增益 | 多叉(每个值取一个分支) | 仅离散特征 |
| ID4.5 | 1993 | 信息增益率 | 多叉 | 离散 + 连续 |
| CART | 1984 | 基尼指数(分类)/ 均方误差(回归) | 二叉 | 离散 + 连续 |
三、ID3决策树
1. 概述
ID3(Iterative Dichotomiser 3)树的构建核心是"信息"。它是基于信息增益来决定如何分支构建决策树。
核心思想:在构建一颗树时,每一步都选择那个能让数据"信息纯度"提升最快的特征进行分支。
核心概念
-
信息熵 :这是一个衡量数据混乱程度(不确定程度)的指标。熵值越大,数据越混乱。主体是目标变量(或单一变量)。
- 公式:H=−∑i=1kpilog(pi)H = -\sum_{i=1}^{k} p_i \log(p_i)H=−i=1∑kpilog(pi)
-
条件熵 :这是衡量数据不确定程度的指标。当知道了另一个信息(相亲对象长相帅),对"是否见相亲对象"的不确定性会降低。这种剩余的不确定性,就是条件熵。条件熵越小,信息增益越大。主体是目标变量 Y 条件于特征 X。
- 对于随机变量X(特征)和Y(目标),Y关于X的条件熵定义为
- 公式:
H(D∣A)=∑v=1nDvDH(Dv)=−∑v=1nDvD∑k=1KCkvDvlog2CkvDv H(D \mid A) = \sum_{v=1}^{n} \frac{D^v}{D} H(D^v) = -\sum_{v=1}^{n} \frac{D^v}{D} \sum_{k=1}^{K} \frac{C^{kv}}{D^v} \log_2 \frac{C^{kv}}{D^v} H(D∣A)=v=1∑nDDvH(Dv)=−v=1∑nDDvk=1∑KDvCkvlog2DvCkv - 公式说明:

-
信息增益 :这是衡量一个特征能让数据集"变纯"多少的指标。信息增益越大,说明划分后的数据集纯度越高,该特征的分类效果越好。
- 公式:g(D,A)=H(D)−H(D∣A)\large g(D,A)=H(D)-H(D|A)g(D,A)=H(D)−H(D∣A)
说明:特征AAA对训练数据集D的信息增益g(D,A)g(D,A)g(D,A),定义为集合DDD的熵H(D)H(D)H(D)与特征A给定条件下D的熵H(D∣A)H(D|A)H(D∣A)之差。即:信息增益 = 信息熵(分裂前的熵) - 条件熵(分裂后的加权熵)。
2. 构建流程
- 计算每个特征的信息增益
- 使用信息增益最大的特征将数据集D拆分为子集
- 使用该特征(信息增益最大的特征)作为决策树的一个节点
- 使用剩余特征对子集重复上述(1,2,3)步骤
案例:
已知:某一个论坛客户流失率数据
需求:考察性别、活跃度特征哪一个特征对流失率的影响更大?
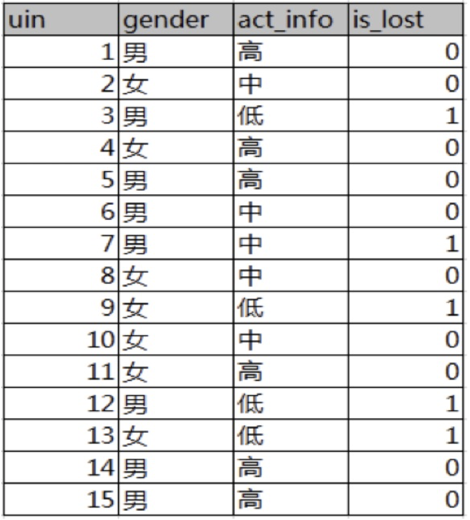
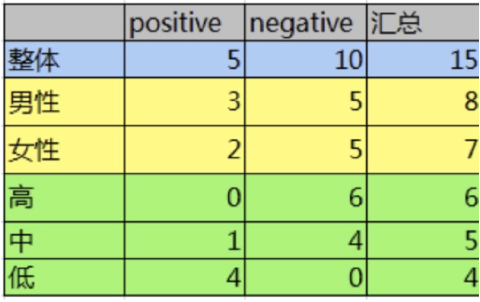
分析:
15条样本:5正样本、10个负样本
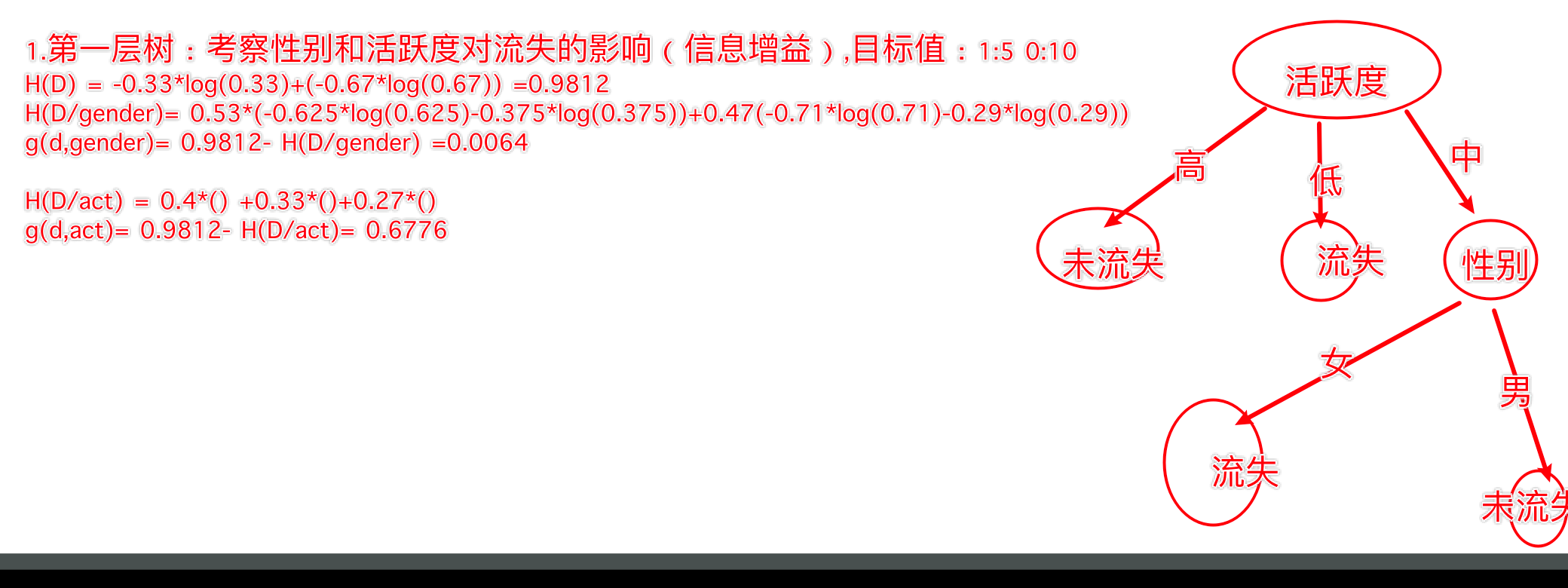
- 计算信息熵
- 计算性别信息增益
- 计算活跃度信息增益
- 比较两个特征的信息增益
计算步骤:
- 计算信息熵:
H(D)=(−515log2515)+(−1015log21015)=0.9183H(D) = \left(-\frac{5}{15}\log_2\frac{5}{15}\right) + \left(-\frac{10}{15}\log_2\frac{10}{15}\right) = 0.9183H(D)=(−155log2155)+(−1510log21510)=0.9183 - 计算性别条件熵(A="性别")
H(D,性别)=∑v=1nDvDH(Dv)=(815)(−38log238−58log258)+(715)(−27log227−57log257)H(D, 性别) = \sum_{v=1}^{n} \frac{D^v}{D} H(D^v) = \left(\frac{8}{15}\right)\left(-\frac{3}{8}\log_2\frac{3}{8} - \frac{5}{8}\log_2\frac{5}{8}\right) + \left(\frac{7}{15}\right)\left(-\frac{2}{7}\log_2\frac{2}{7} - \frac{5}{7}\log_2\frac{5}{7}\right)H(D,性别)=v=1∑nDDvH(Dv)=(158)(−83log283−85log285)+(157)(−72log272−75log275)- 计算性别信息增益(A="性别")
g(D,A)=H(D)−H(D∣A)=0.9183−((815)(−38log238−58log258)+(715)(−27log227−57log257))=0.0064g(D, A) = H(D) - H(D|A) = 0.9183 - \left( \left(\frac{8}{15}\right)\left(-\frac{3}{8}\log_2\frac{3}{8} - \frac{5}{8}\log_2\frac{5}{8}\right) + \left(\frac{7}{15}\right)\left(-\frac{2}{7}\log_2\frac{2}{7} - \frac{5}{7}\log_2\frac{5}{7}\right) \right)=0.0064g(D,A)=H(D)−H(D∣A)=0.9183−((158)(−83log283−85log285)+(157)(−72log272−75log275))=0.0064
- 计算性别信息增益(A="性别")
- 计算活跃度条件熵(A="活跃度")
H(D,活跃度)=∑v=1nDvDH(Dv)=(615)(0)+(515)(−15log215−45log245)+(415)(0)H(D, 活跃度) = \sum_{v=1}^{n} \frac{D^v}{D} H(D^v) = \left(\frac{6}{15}\right)(0) + \left(\frac{5}{15}\right)\left(-\frac{1}{5}\log_2\frac{1}{5} - \frac{4}{5}\log_2\frac{4}{5}\right) + \left(\frac{4}{15}\right)(0)H(D,活跃度)=v=1∑nDDvH(Dv)=(156)(0)+(155)(−51log251−54log254)+(154)(0)- 计算活跃度信息增益(A=活跃度")
g(D,A)=H(D)−H(D∣A)=0.9183−((615)(0)+(515)(−15log215−45log245)+(415)(0))=0.6776g(D, A) = H(D) - H(D|A) = 0.9183 - \left( \left(\frac{6}{15}\right)(0) + \left(\frac{5}{15}\right)\left(-\frac{1}{5}\log_2\frac{1}{5} - \frac{4}{5}\log_2\frac{4}{5}\right) + \left(\frac{4}{15}\right)(0) \right)=0.6776g(D,A)=H(D)−H(D∣A)=0.9183−((156)(0)+(155)(−51log251−54log254)+(154)(0))=0.6776
- 计算活跃度信息增益(A=活跃度")
结论 :活跃度的信息增益比性别的信息增益大,对用户流失的影响比性别大。
四、D4.5决策树
1. 概述
C4.5树是对ID3树的重要改进,它不仅继承了ID3使用信息论来构建决策树的思想,还弥补了后者在实践中的诸多不足。
- 公式:
Gain_Ratio(D,a)=Gain(D,a)IV(a) \text{Gain\Ratio}(D, a) = \frac{\text{Gain}(D, a)}{IV(a)} Gain_Ratio(D,a)=IV(a)Gain(D,a)
IV(a)=−∑v=1VDvDlogDvD IV(a) = -\sum{v=1}^{V} \frac{D^v}{D} \log \frac{D^v}{D} IV(a)=−v=1∑VDDvlogDDv - 公式说明
- 信息增益率(Gain Ratio) :这是 C4.5 决策树算法中使用的特征选择指标,用来解决 ID3 算法中信息增益倾向于选择取值多的特征的问题。它的核心思想是用特征自身的特征熵(IV)对信息增益进行归一化。信息增益率越大,说明划分后的数据集纯度越高,该特征的分类效果越好。
- 特征熵(Intrinsic Value, IV) :衡量了特征本身的不确定性。特征的取值越多,IV 值就越大,从而会拉低信息增益率,避免算法偏向这类特征。特征熵值越小,信息增益率越大。
信息增益率的本质: 就是在信息增益的基础之上乘一个惩罚系数。特征取值多时,惩罚系数较小;特征取值少时,惩罚系数较大。
2. 构建流程
- 计算每个特征的信息增益率
- 使用信息增益率最大的特征将数据集D拆分为子集
- 使用该特征(信息增益最大的特征)作为决策树的一个节点
- 使用剩余特征对子集重复上述(1,2,3)步骤
案例:
已知:有特征a和特征b,以及目标数据
需求:考察哪个特征对目标值影响大?
计算步骤:
-
特征a的信息增益率:
- 信息增益:
1-0.5408520829727552=0.46 - 特征熵:
-4/6 * math.log(4/6, 2) -2/6 * math.log(2/6, 2)=0.9182958340544896 - 信息增益率:
信息增益/分裂信息=0.46/0.9182958340544896=0.5
- 信息增益:
-
特征b的信息增益率:
- 信息增益:1
- 特征熵:
-1/6*math.log(1/6, 2) * 6=2.584962500721156 - 信息增益率:
信息增益/信息熵=1/2.584962500721156=0.38685280723454163
由计算结果可见,特征a的信息增益率大于特征b的信息增益率,根据信息增益率,我们应该选择特征a作为分裂特征。
五、CART决策树
1. 概述
CART(Classification and Regression Trees)是一棵二叉树,既可做分类也可做回归。它也是目前工业界最常用、集成学习(随机森林、XGBoost)默认的基学习器。
2. 分类决策树
CART分类决策树输出的是一个离散值,用于解决分类问题,采用基尼指数最小化作为模型的最优化策略。使用叶子节点里出现次数多的类别作为预测类别。
- 公式:
Gini(D)=1−∑k=1Kpk2 \text{Gini}(D) = 1 - \sum_{k=1}^{K} p_k^2 Gini(D)=1−k=1∑Kpk2
Gini_index(D,a)=∑v=1VDvDGini(Dv) \text{Gini\index}(D, a) = \sum{v=1}^{V} \frac{D^v}{D} \text{Gini}(D^v) Gini_index(D,a)=v=1∑VDDvGini(Dv)
- 公式说明
- 基尼系数(Gini) :衡量数据集纯度的指标,是 CART 决策树算法的核心特征选择标准。它的取值范围是 0, 1:
Gini(D)=0:数据集 D 中的样本全部属于同一类别,纯度最高。
Gini(D) 越接近 1:数据集的类别分布越混乱,不确定性越高。 - 基尼指数(Gini Index) :衡量使用特征a划分数据集后,各子集基尼系数的加权平均值。基尼指数越小,说明划分后的数据集纯度越高,该特征的分类效果越好。
- 基尼系数(Gini) :衡量数据集纯度的指标,是 CART 决策树算法的核心特征选择标准。它的取值范围是 0, 1:
举例
需求:根据以下数据,分别计算特征列的基尼值。
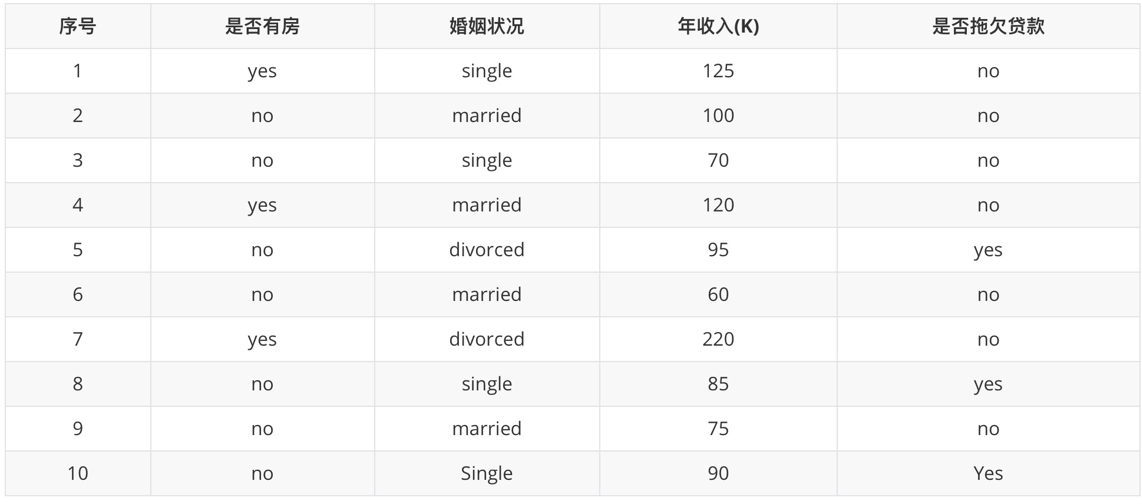
是否有房
计算过程如下:根据是否有房将目标值划分为两部分:
-
计算有房子的基尼值: 有房子有 1、4、7 共计三个样本,对应:3个no、0个yes
Gini(是否有房,yes )=1−(03)2−(33)2=0G i n i(\text {是否有房,yes })=1-\left(\frac{0}{3}\right)^{2}-\left(\frac{3}{3}\right)^{2}=0Gini(是否有房,yes )=1−(30)2−(33)2=0
-
计算无房子的基尼值:无房子有 2、3、5、6、8、9、10 共七个样本,对应:4个no、3个yes
Gini(是否有房,no )=1−(37)2−(47)2=0.4898\operatorname{Gini}(\text {是否有房,no })=1-\left(\frac{3}{7}\right)^{2}-\left(\frac{4}{7}\right)^{2}=0.4898Gini(是否有房,no )=1−(73)2−(74)2=0.4898
-
计算基尼指数:第一部分样本数量占了总样本的 3/10、第二部分样本数量占了总样本的 7/10:
Gini−index(D, 是否有房 )=710∗0.4898+310∗0=0.343\operatorname{Gini_{-}} i n \operatorname{dex}(D, \text { 是否有房 })=\frac{7}{10} * 0.4898+\frac{3}{10} * 0=0.343Gini−index(D, 是否有房 )=107∗0.4898+103∗0=0.343
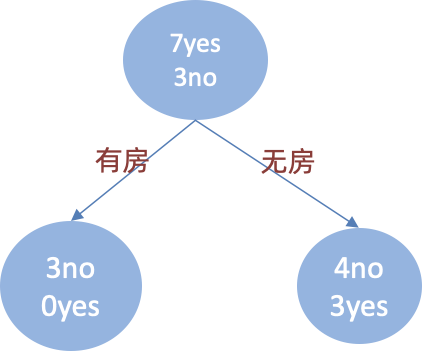
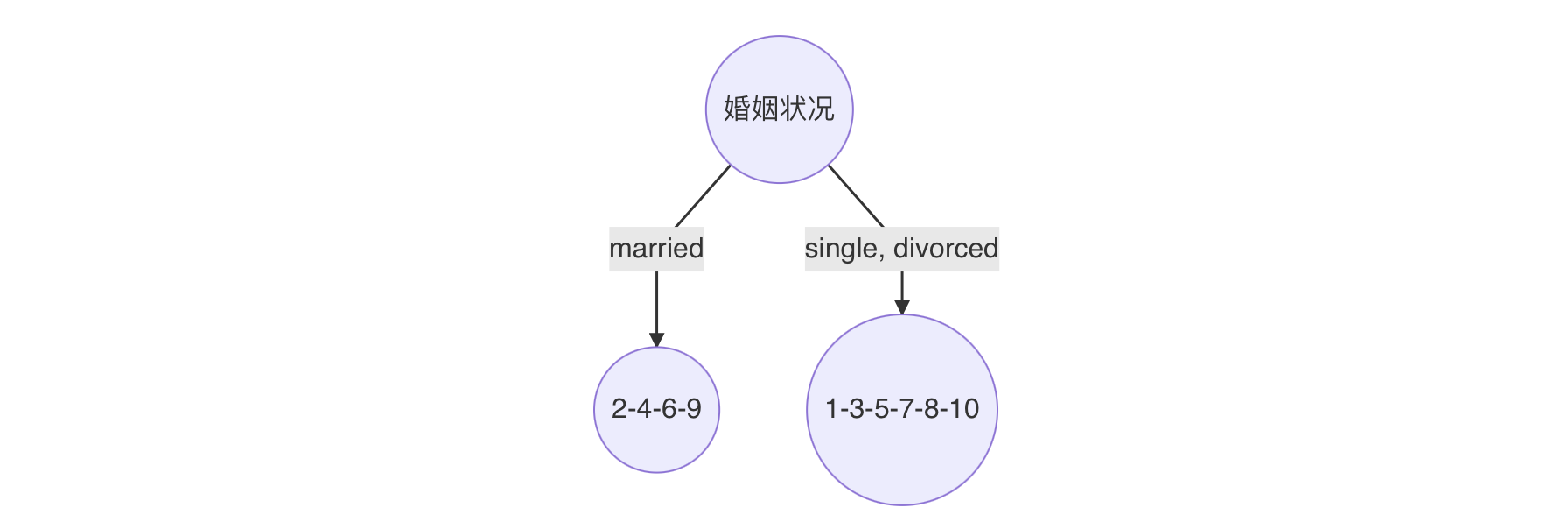
婚姻状况 -
计算 {married} 和 {single,divorced} 情况下的基尼指数:
结婚的基尼值,有 2、4、6、9 共 4 个样本,并且对应目标值全部为 no:
Gini_index(D,married)=0\operatorname{Gini\_index}(D,\text{{married}})=0Gini_index(D,married)=0
不结婚的基尼值,有 1、3、5、7、8、10 共 6 个样本,并且对应 3 个 no,3 个 yes:
Gini_index(D, single,divorced )=1−(36)2−(36)2=0.5\operatorname{Gini\_index}(D, \text { {single,divorced} })=1-\left(\frac{3}{6}\right)^{2}-\left(\frac{3}{6}\right)^{2}=0.5Gini_index(D, single,divorced )=1−(63)2−(63)2=0.5
以 married 作为分裂点的基尼指数:
Gini_index(D, married )=410∗0+610∗1−(36)2−(36)2=0.3\operatorname{Gini\_index}(D, \text { married })=\frac{4}{10} * 0+\frac{6}{10} *\left1-\\left(\\frac{3}{6}\\right)\^{2}-\\left(\\frac{3}{6}\\right)\^{2}\\right=0.3Gini_index(D, married )=104∗0+106∗1−(63)2−(63)2=0.3
-
计算 {single} | {married,divorced} 情况下的基尼指数
Gini_index(D,婚姻状况)=410∗0.5+610∗1−(16)2−(56)2=0.367\operatorname{Gini\_index}(D,\text{婚姻状况})=\frac{4}{10} * 0.5+\frac{6}{10} *\left1-\\left(\\frac{1}{6}\\right)\^{2}-\\left(\\frac{5}{6}\\right)\^{2}\\right=0.367Gini_index(D,婚姻状况)=104∗0.5+106∗1−(61)2−(65)2=0.367
-
计算 {divorced} | {single,married} 情况下基尼指数
Gini_index(D, 婚姻状况 )=210∗0.5+810∗1−(28)2−(68)2=0.4\operatorname{Gini\_index}(D, \text { 婚姻状况 })=\frac{2}{10} * 0.5+\frac{8}{10} *\left1-\\left(\\frac{2}{8}\\right)\^{2}-\\left(\\frac{6}{8}\\right)\^{2}\\right=0.4Gini_index(D, 婚姻状况 )=102∗0.5+108∗1−(82)2−(86)2=0.4
-
最终:该特征的基尼值为 0.3,并且预选分裂点为:{married} 和 {single,divorced}
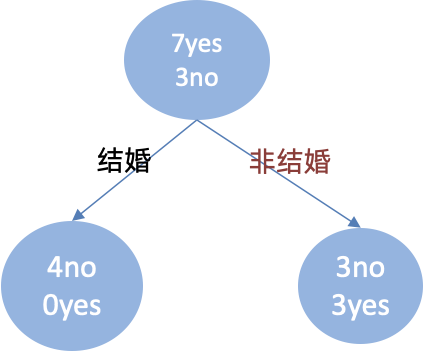
年收入
先将数值型属性升序排列,以相邻中间值作为待确定分裂点:
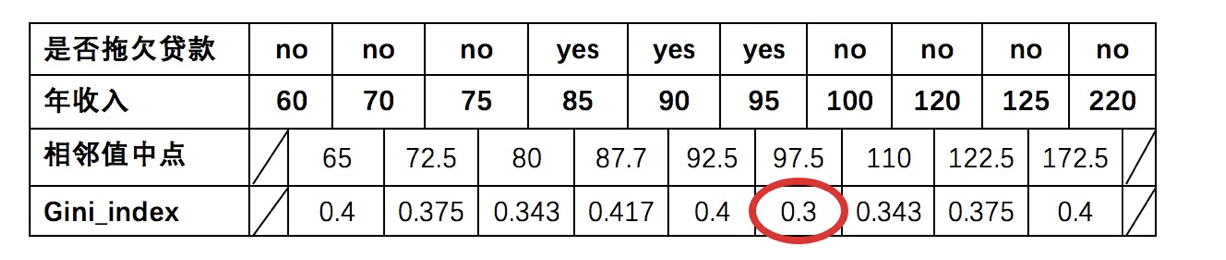
以年收入 65 将样本分为两部分,计算基尼指数:
节点为65时:年收入=110∗0+910∗1−(69)2−(39)2=0.4节点为65时:{年收入}=\frac{1}{10} * 0 + \frac{9}{10} *\left1-\\left(\\frac{6}{9}\\right)\^{2}-\\left(\\frac{3}{9}\\right)\^{2}\\right=0.4节点为65时:年收入=101∗0+109∗1−(96)2−(93)2=0.4
以此类推计算所有分割点的基尼指数,我们发现最小的基尼指数为 0.3。
此时,我们发现:
- 以是否有房作为分裂点的基尼指数为:0.343
- 以婚姻状况为分裂特征、以 married 作为分裂点的基尼指数为:0.3
- 以年收入作为分裂特征、以 97.5 作为分裂点的的基尼指数为:0.3
最小基尼指数有两个分裂点,我们随机选择一个即可,假设婚姻状况,则可确定决策树如下:
重复上面步骤,直到每个叶子节点纯度达到最高.
3. 回归决策树
CART回归决策树输出的是一个连续值,用于解决回归问题,采用平方误差(均方误差)最小化作为模型的最优化策略。使用叶子节点里均值作为预测类别。
- 公式:
Loss(y,f(x))=(f(x)−y)2 \text{Loss}(y, f(x)) = \left(f(x) - y\right)^2 Loss(y,f(x))=(f(x)−y)2
举例
假设:数据集只有 1 个特征 x, 目标值值为 y,如下图所示:
| x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| y | 5.56 | 5.7 | 5.91 | 6.4 | 6.8 | 7.05 | 8.9 | 8.7 | 9 | 9.05 |
由于只有 1 个特征,所以只需要选择该特征的最优划分点,并不需要计算其他特征。
-
先将特征 x 的值排序,并取相邻元素均值作为待划分点,如下图所示:
s 1.5 2.5 3.5 4.5 5.5 6.5 7.5 8.5 9.5 -
计算每一个划分点的平方损失,例如:1.5 的平方损失计算过程为:
R1 为 小于 1.5 的样本个数,样本数量为:1,其输出值为:5.56
R1=5.56R_1 =5.56R1=5.56
R2 为 大于 1.5 的样本个数,样本数量为:9 ,其输出值为:
R2=(5.7+5.91+6.4+6.8+7.05+8.9+8.7+9+9.05)/9=7.50R_2=(5.7+5.91+6.4+6.8+7.05+8.9+8.7+9+9.05) / 9=7.50R2=(5.7+5.91+6.4+6.8+7.05+8.9+8.7+9+9.05)/9=7.50
该划分点的平方损失:
L(1.5)=(5.56−5.56)2+(5.7−7.5)2+(5.91−7.5)2+...+(9.05−7.5)2=0+15.72=15.72L(1.5)=(5.56-5.56)^{2}+\left(5.7-7.5)\^{2}+(5.91-7.5)\^{2}+\\ldots+(9.05-7.5)\^{2}\\right=0+15.72=15.72L(1.5)=(5.56−5.56)2+(5.7−7.5)2+(5.91−7.5)2+...+(9.05−7.5)2=0+15.72=15.72
-
以此方式计算 2.5、3.5... 等划分点的平方损失,结果如下所示:
s 1.5 2.5 3.5 4.5 5.5 6.5 7.5 8.5 9.5 m(s) 15.72 12.07 8.36 5.78 3.91 1.93 8.01 11.73 15.74 -
当划分点 s=6.5 时,m(s) 最小。因此,第一个划分变量:特征为 X, 切分点为 6.5,即:j=x, s=6.5
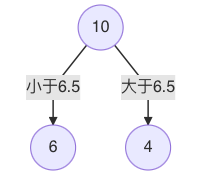
-
对左子树的 6 个节点计算每个划分点的平方式损失,找出最优划分点:
x 1 2 3 4 5 6 y 5.56 5.7 5.91 6.4 6.8 7.05 s 1.5 2.5 3.5 4.5 5.5 c1 5.56 5.63 5.72 5.89 6.07 c2 6.37 6.54 6.75 6.93 7.05 s 1.5 2.5 3.5 4.5 5.5 m(s) 1.3087 0.754 0.2771 0.4368 1.0644 -
s=3.5时,m(s) 最小,所以左子树继续以 3.5 进行分裂:
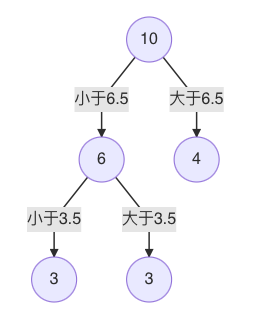
-
假设在生成3个区域 之后停止划分,以上就是回归树。每一个叶子节点的输出为:挂在该节点上的所有样本均值。
| x | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| y | 5.56 | 5.7 | 5.91 | 6.4 | 6.8 | 7.05 | 8.9 | 8.7 | 9 | 9.05 |
1号样本真实值 5.56 预测结果:5.72
2号样本真实值是 5.7 预测结果:5.72
3 号样本真实值是 5.91 预测结果 5.72
CART 回归树构建过程如下:
- 选择第一个特征,将该特征的值进行排序,取相邻点计算均值作为待划分点
- 根据所有划分点,将数据集分成两部分:R1、R2
- R1 和 R2 两部分的平方损失相加作为该切分点平方损失
- 取最小的平方损失的划分点,作为当前特征的划分点
- 以此计算其他特征的最优划分点、以及该划分点对应的损失值
- 在所有的特征的划分点中,选择出最小平方损失的划分点,作为当前树的分裂点
【实践】回归决策树实践
已知数据:

分别训练线性回归、回归决策树模型,并预测对比
训练模型,并使用1000个0.0, 10之间的数据,让模型预测,画出预测值图线
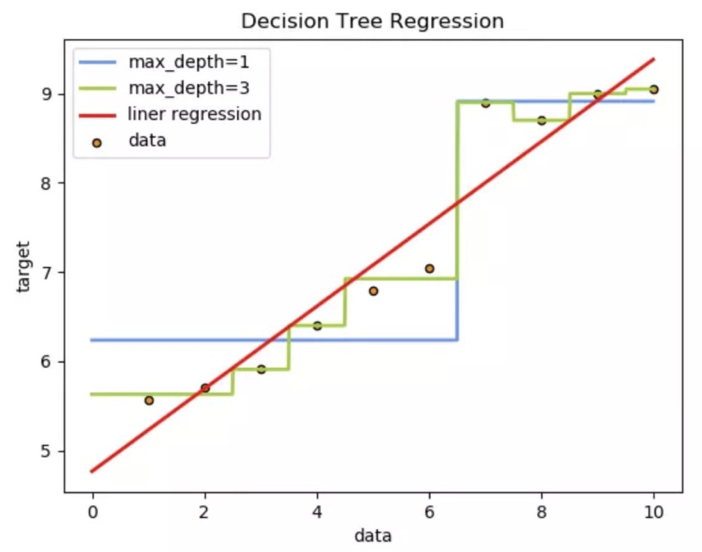
从预测效果来看:
1、线性回归是一条直线
2、决策树是曲线
3、树的拟合能力是很强的,容易过拟合
六、ID3、C4.5、CART决策树对比
1. 不同种类决策树对比
| 名称 | 提出年份 | 分裂指标 | 特点 |
|---|---|---|---|
| ID3 | 1975 | 信息增益 | 1. ID3只能对离散属性的数据集构成决策树 2. 倾向于选择值较多的属性 |
| ID4.5 | 1993 | 信息增益率 | 1. 缓解了ID3分支过程中总喜欢偏向选择值较多的属性 2. 可处理连续数值型属性,也增加了对缺失值的处理方法 3. 只适合于能够驻留于内存的数据集,大数据集无能为力 |
| CART | 1984 | 基尼指数(分类)/ 均方误差(回归) | 1. 可以进行分类和回归,可处理离散属性,也可以处理连续属性 2. 采用基尼指数,计算量减小 3. 一定是二叉树 |
七、决策树剪枝
1. 概述
剪枝 (pruning)是决策树学习算法处理过拟合 的主要手段。
2. 为什么需要剪枝?
决策树在训练时,如果不加限制,会不断分裂直到每个叶子节点都"纯"或者没有特征可用。这会导致:
- 过拟合:模型过度记忆训练数据中的噪声和异常值,在新数据上表现差。
- 模型复杂:树过于庞大,可解释性下降。
剪枝通过移除对泛化误差贡献不大的分支,在模型复杂度与预测准确率之间取得平衡。
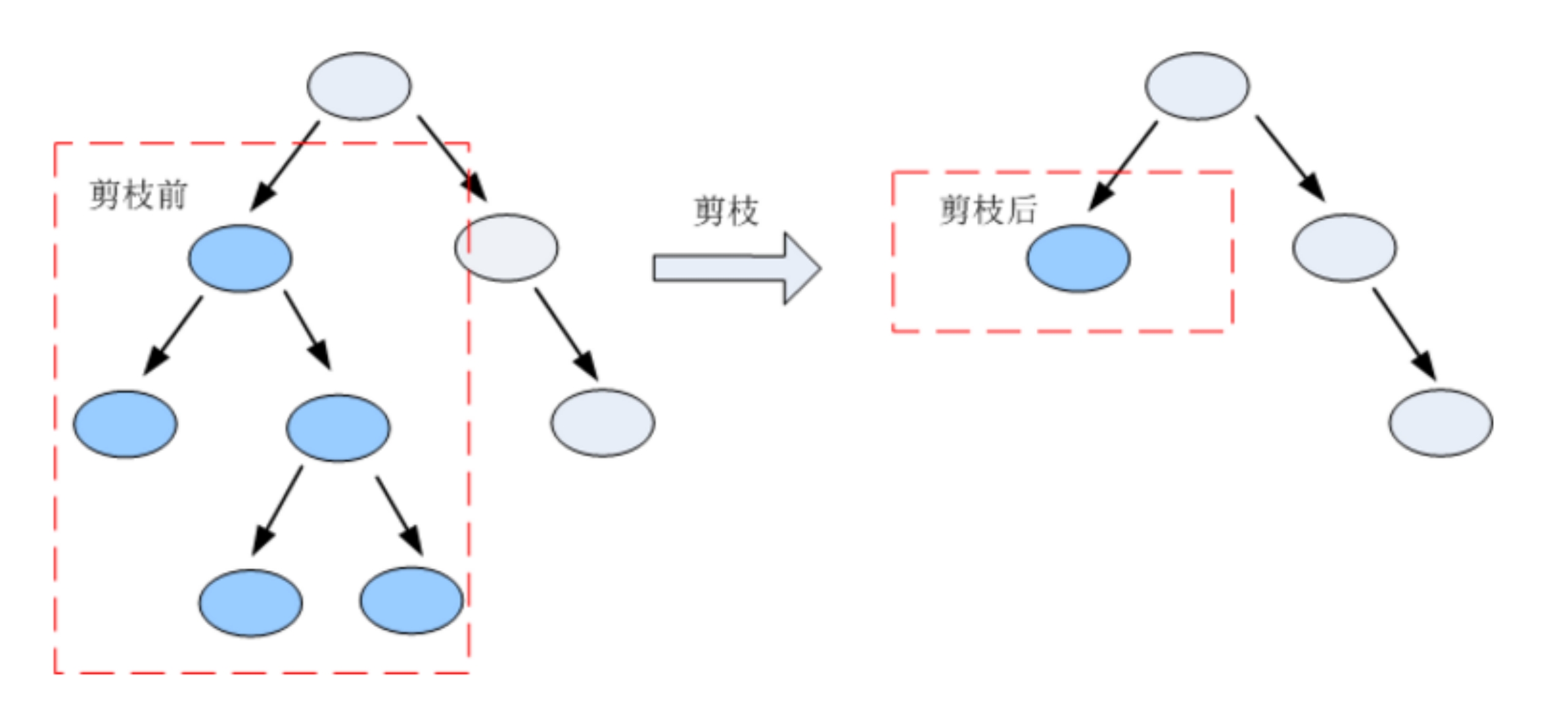
3. 剪枝策略
-
预剪枝:指在决策树生成过程中,对每个节点在划分前先进行估计,若当前节点的划分不能带来决策树泛化性能提升,则停止划分并将当前节点标记为叶节点。
- 常用停止条件:
- 最大深度(max_depth)
- 节点最小样本数(min_samples_split)
- 叶节点最小样本数(min_samples_leaf)
- 最小不纯度下降阈值(min_impurity_decrease)
- 优点:
- 预剪枝使决策树的很多分支没有展开,不单降低了过拟合风险,还显著提高了决策树的训练、测试的时间开销
- 缺点:
- 有些分支的当前划分虽不能提升泛化性能,甚至导致泛化性能降低,但其基础上进行的后续划分却有可能导致性能的显著提高
- 预剪枝决策树也带来了欠拟合的风险
- 常用停止条件:
-
后剪枝:先从训练集生成一棵完整的决策树,然后自底向上地对非叶节点进行考察,若将该节点对应的子树替换为叶节点能带来决策树泛化性能提升,则将该子树替换为叶节点。
- 经典后剪枝算法:
- 代价复杂度剪枝(CCP, Cost-Complexity Pruning)------ CART 使用
- 悲观剪枝(Pessimistic Pruning)------ C4.5 使用
- 错误率降低剪枝(REP, Reduced Error Pruning)
- 优点:
- 比预剪枝保留了更多的分支。一般情况下,后剪枝决策树的欠拟合风险小,泛化性能往往优于预剪枝
- 缺点:
- 但后剪枝过程是在生成完全决策树之后进行的,并且要自底向上地对树中所有非叶子节点进行逐一考察,因此训练时间开销比预剪枝的决策树要大得多
- 经典后剪枝算法:
4. 实际应用建议
- 大数据集:通常用预剪枝(设置合理的max_depth,min_samples_split)快速生成树,再配合小的ccp_alpha后剪枝微调。
- 小数据集:直接使用后剪枝(如CART的CCP和C4.5的悲观剪枝)。
- 集成学习:随机森林、XGBoost内部使用弱决策树(通常深度很小,已通过预剪枝高度限制),不需要额外后剪枝。