消息堆积不是 RabbitMQ 特有的问题,只要生产者发送速度长期大于消费者处理速度,队列里的消息就会越积越多。面试里问"100 万消息堆积怎么办",本质是在问:你能不能判断瓶颈在消费能力、业务耗时,还是队列容量。
一句话概括:RabbitMQ 消息堆积先看生产速度和消费速度是否失衡,再从增加消费者、优化消费者内部并发、扩大队列容积三个方向处理;惰性队列可以承接大量堆积,但会牺牲一定时效性。
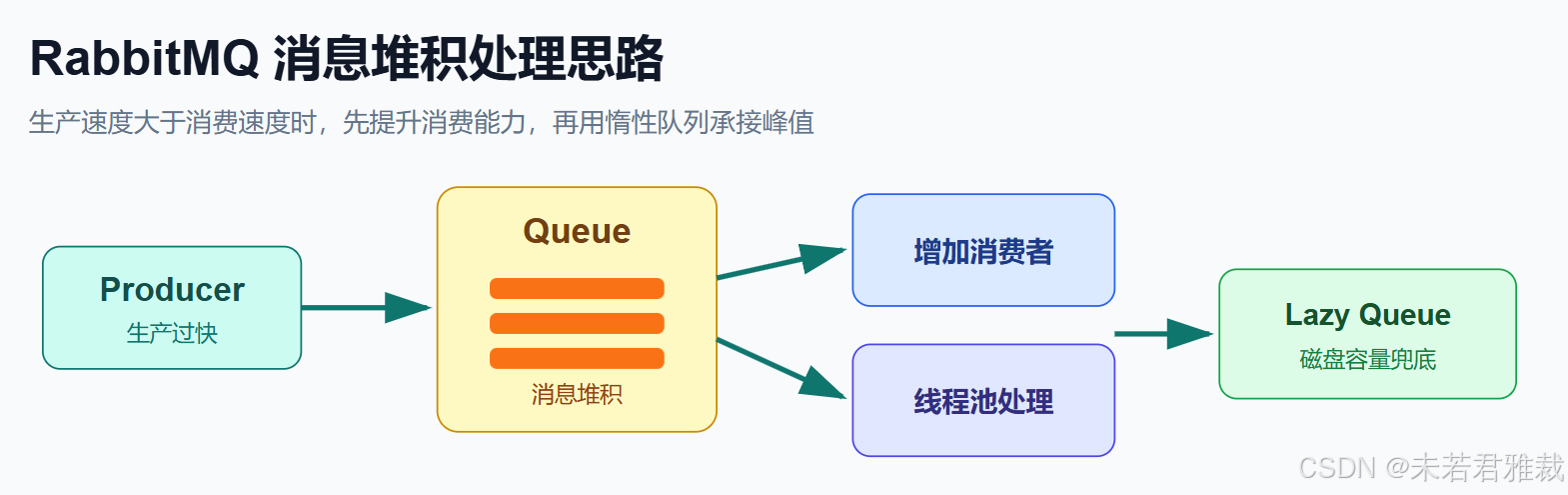
速度过快
处理过慢
生产者持续发送
Queue
消费者处理
消息堆积
增加消费者
消费者内线程池
惰性队列扩大容量
什么是消息堆积
消息堆积指的是:生产者发送消息的速度超过消费者处理消息的速度,队列中的消息持续增长。
每秒生产 5000 条
Queue
每秒消费 1000 条
每秒净增加 4000 条
消息持续堆积
如果队列设置了长度上限,堆积达到上限后,新消息可能被拒绝,也可能根据策略让旧消息变成死信。最终表现就是:延迟越来越高、业务处理滞后、甚至消息丢失。
先判断堆积原因
不要一上来就说"加机器"。先判断堆积发生在哪一层。
| 排查点 | 现象 | 可能原因 |
|---|---|---|
| 生产速度突然升高 | 活动流量、批量任务、上游重试 | 上游限流不足 |
| 消费速度下降 | 消费者 CPU、DB、外部接口变慢 | 业务处理瓶颈 |
| 队列容量不足 | 消息很快达到上限 | 队列模式和容量设计不合理 |
| 消费者频繁失败 | 重试很多、死信变多 | 业务异常或下游依赖故障 |
真正的处理顺序应该是:先止血,再扩容,再优化根因。
实际排查时,可以重点看这些指标:
| 指标 | 说明 | 常见判断 |
|---|---|---|
| 队列 ready 数 | 等待投递的消息数 | 持续增长说明消费能力不足 |
| unacked 数 | 已投递但未 ACK 的消息数 | 很高说明消费者处理慢或卡住 |
| publish rate | 生产速率 | 突然升高可能是活动流量或上游重试 |
| deliver/ack rate | 投递和确认速率 | 低于生产速率会形成堆积 |
| 消费失败率 | 重试、死信、异常日志 | 高失败率可能是毒丸消息或下游故障 |
| 下游耗时 | DB、Redis、第三方接口耗时 | 下游慢会直接拖慢消费速度 |
ready 高
unacked 高
发现队列堆积
ready 高还是 unacked 高
消费能力不足或生产突增
消费者处理慢或 ACK 卡住
扩消费者/限流/惰性队列
查业务耗时/线程池/下游依赖
方案一:增加更多消费者
最直接的方式是增加消费者数量,让多个消费者共同消费同一个队列。
Queue
Consumer 1
Consumer 2
Consumer 3
Consumer 4
这个方案适合业务可以并行处理的场景,比如短信发送、日志处理、缓存刷新。
但要注意两个前提:
- 消费逻辑必须是幂等的,因为扩容后重复消费和重试仍然可能发生。
- 下游资源要扛得住,比如数据库、Redis、第三方接口不能被消费者扩容反过来打垮。
方案二:消费者内部开启线程池
如果消费者实例数量暂时不能扩,或者单个消费者处理逻辑可以拆并发,可以在消费者内部用线程池提升处理速度。
消费者收到消息
提交到业务线程池
线程 1 处理
线程 2 处理
线程 3 处理
处理完成后 ACK
这里有一个容易踩坑的点:不要在线程池还没处理完时就提前 ACK。否则线程池里的业务失败了,MQ 已经把消息删除,消息就真的丢了。
更稳的做法是:业务处理成功后再 ACK;处理失败则 NACK、重试或投递到异常队列。
方案三:扩大队列容积,使用惰性队列
RabbitMQ 的惰性队列适合承接大量消息堆积。
惰性队列的特点:
| 特点 | 说明 |
|---|---|
| 直接写磁盘 | 接收消息后尽量存入磁盘,而不是长期放内存 |
| 消费时再加载 | 消费者需要时再从磁盘读入内存 |
| 容量更大 | 可以支持数百万级消息存储 |
| 时效性下降 | 受磁盘 IO 影响,消费延迟可能变高 |
声明队列时可以设置 x-queue-mode=lazy:
java
@Bean
public Queue lazyQueue() {
return QueueBuilder.durable("lazy.queue")
// 惰性队列适合承接大量堆积,但要接受磁盘 IO 带来的延迟。
.withArgument("x-queue-mode", "lazy")
.build();
}惰性队列不是性能优化,而是容量兜底。它让 MQ 在大堆积下更稳定,但不会让消费速度凭空变快。
三种方案怎么选
| 方案 | 解决的核心问题 | 风险 |
|---|---|---|
| 增加消费者 | 提高总体消费能力 | 下游被打满、顺序性被破坏 |
| 消费者线程池 | 提高单实例处理能力 | ACK 时机复杂,线程池积压 |
| 惰性队列 | 提高队列堆积上限 | 磁盘 IO 影响时效性 |
如果是临时流量洪峰,先扩消费者和限流。如果是长期处理慢,要优化业务 SQL、外部接口、批处理逻辑。如果是业务天然有大批量削峰需求,再考虑惰性队列做容量设计。
面试回答模板
可以这样答:
RabbitMQ 消息堆积说明生产速度超过了消费速度。我会先看堆积增长速度、消费者是否报错、下游数据库或接口是否变慢。处理上有三个方向:第一,增加消费者实例,提高消费并发;第二,在消费者内部开启线程池加快业务处理,但要注意处理成功后再 ACK,不能提前确认;第三,如果业务需要承接大量削峰消息,可以使用惰性队列,声明队列时设置
x-queue-mode=lazy,让消息更多落到磁盘,支持更大的堆积量。惰性队列能提高容量,但受磁盘 IO 影响,时效性会下降。
小结
消息堆积不是单靠 MQ 配置解决的问题。队列只是缓冲区,真正要解决的是生产和消费速度失衡。
限流控制生产
扩容提高消费
优化业务耗时
惰性队列容量兜底