目录
[2.1 为什么需要项目规范?](#2.1 为什么需要项目规范?)
[2.1.1 个人脚本 vs 企业项目的差异](#2.1.1 个人脚本 vs 企业项目的差异)
[2.1.2 规范带来的具体收益](#2.1.2 规范带来的具体收益)
[2.2 项目结构规范](#2.2 项目结构规范)
[2.2.1 经典 Python 项目目录结构](#2.2.1 经典 Python 项目目录结构)
[2.2.2 关键目录说明](#2.2.2 关键目录说明)
[2.2.3 init.py 的作用](#2.2.3 init.py 的作用)
[2.3 依赖管理与虚拟环境](#2.3 依赖管理与虚拟环境)
[2.3.1 为什么需要 Poetry?](#2.3.1 为什么需要 Poetry?)
[2.3.2 安装 Poetry](#2.3.2 安装 Poetry)
[2.3.3 使用 Poetry 初始化项目](#2.3.3 使用 Poetry 初始化项目)
[2.3.4 pyproject.toml 文件详解](#2.3.4 pyproject.toml 文件详解)
[2.3.5 安装依赖与虚拟环境管理](#2.3.5 安装依赖与虚拟环境管理)
[2.3.6 在虚拟环境中运行代码](#2.3.6 在虚拟环境中运行代码)
[2.3.7 锁定文件 poetry.lock 的重要性](#2.3.7 锁定文件 poetry.lock 的重要性)
[2.3.8 VS Code 集成 Poetry 虚拟环境](#2.3.8 VS Code 集成 Poetry 虚拟环境)
[2.3.9 实战:将之前的天气查询项目迁移到 Poetry](#2.3.9 实战:将之前的天气查询项目迁移到 Poetry)
[2.3.10 总结对比:传统方式 vs Poetry](#2.3.10 总结对比:传统方式 vs Poetry)
[2.4 代码风格规范(PEP 8)](#2.4 代码风格规范(PEP 8))
[2.4.1 命名规范](#2.4.1 命名规范)
[2.4.2 缩进与空格](#2.4.2 缩进与空格)
[2.4.3 导入规范](#2.4.3 导入规范)
[2.4.4 自动化格式检查工具](#2.4.4 自动化格式检查工具)
[2.5 类型注解与静态类型检查](#2.5 类型注解与静态类型检查)
[2.5.1 为什么需要类型注解?](#2.5.1 为什么需要类型注解?)
[2.4.2 基本类型注解语法](#2.4.2 基本类型注解语法)
[2.4.3 Pydantic:数据验证与类型安全的利器](#2.4.3 Pydantic:数据验证与类型安全的利器)
[2.4.4 静态类型检查工具:mypy](#2.4.4 静态类型检查工具:mypy)
[2.5 文档字符串规范](#2.5 文档字符串规范)
[2.5.1 为什么要写文档字符串?](#2.5.1 为什么要写文档字符串?)
[2.5.2 Google 风格文档字符串示例](#2.5.2 Google 风格文档字符串示例)
[2.6 配置管理规范](#2.6 配置管理规范)
[2.6.1 配置管理的核心原则](#2.6.1 配置管理的核心原则)
[2.6.2 项目结构与 Poetry 初始化](#2.6.2 项目结构与 Poetry 初始化)
[2.6.3 使用 Pydantic Settings 管理配置(详细指南)](#2.6.3 使用 Pydantic Settings 管理配置(详细指南))
[2.6.4 在代码中使用配置(最佳实践)](#2.6.4 在代码中使用配置(最佳实践))
[2.6.5 安全加强与运维提示](#2.6.5 安全加强与运维提示)
[2.6.6 常见配置错误与解决方案](#2.6.6 常见配置错误与解决方案)
[2.6.7 总结与推荐实践](#2.6.7 总结与推荐实践)
[2.7 日志记录规范](#2.7 日志记录规范)
[2.7.1 为什么需要规范的日志?](#2.7.1 为什么需要规范的日志?)
[2.7.2 Python logging 模块配置](#2.7.2 Python logging 模块配置)
[2.7.3 结构化日志(JSON 格式)](#2.7.3 结构化日志(JSON 格式))
[2.8 单元测试规范](#2.8 单元测试规范)
[2.8.1 测试的重要性](#2.8.1 测试的重要性)
[2.8.2 pytest 框架基础](#2.8.2 pytest 框架基础)
[2.8.3 测试覆盖率](#2.8.3 测试覆盖率)
[2.9 版本控制规范](#2.9 版本控制规范)
[2.9.1 Git 提交信息规范](#2.9.1 Git 提交信息规范)
[2.9.2 .gitignore 模板](#2.9.2 .gitignore 模板)
[2.10 完整实践案例:规范化 AI 问答服务](#2.10 完整实践案例:规范化 AI 问答服务)
[2.10.1 项目初始化](#2.10.1 项目初始化)
[2.12.2 项目结构调整](#2.12.2 项目结构调整)
[2.10.3 核心代码实现](#2.10.3 核心代码实现)
[2.10.4 单元测试](#2.10.4 单元测试)
[2.10.5 运行项目](#2.10.5 运行项目)
[2.11 本章小结](#2.11 本章小结)
[2.11.1 知识点回顾](#2.11.1 知识点回顾)
[2.11.2 从规范到习惯](#2.11.2 从规范到习惯)
[2.12 常见问题](#2.12 常见问题)
本章内容将帮助你从"写脚本"迈向"做工程",这是从学习编程到胜任企业开发岗位的关键一步。
2.1 为什么需要项目规范?
2.1.1 个人脚本 vs 企业项目的差异
| 维度 | 个人脚本 | 企业级项目 |
|---|---|---|
| 代码量 | 几十到几百行 | 数千到数万行 |
| 开发者 | 1 人 | 多人协作 |
| 生命周期 | 一次性使用 | 持续迭代维护 |
| 运行环境 | 个人电脑 | 服务器/容器/云平台 |
| 依赖管理 | 手动安装 | 精确锁定版本 |
| 部署方式 | 直接运行 | 自动化 CI/CD |
在 AI 大模型应用开发中,一个典型项目往往需要整合 API 调用、向量数据库、提示词管理、前端服务等多个组件,代码规模和复杂度远超个人练习。规范是多人协作和长期维护的基石。
问题:如何理解自动化 CI/CD 这个概念?
CI/CD 就是一套自动化流程:
(1) 持续集成 ( CI ) 会在你把代码推送到仓库时自动运行测试、检查代码风格,确保新代码不会破坏原有功能;
(2)持续部署(CD) 则在测试通过后自动将应用打包并部署到服务器,让你每次提交都能快速、安全地上线,减少人工操作失误。
2.1.2 规范带来的具体收益
-
降低沟通成本:统一的代码风格让团队成员能快速读懂彼此的代码
-
减少低级错误:类型注解和静态检查能在编码阶段发现潜在 bug
-
便于交接和接手:清晰的文档和注释让新人能迅速上手
-
保障生产稳定性:配置分离、日志记录、单元测试等机制确保系统可靠
-
提升开发效率:规范化工具链(如 Poetry、pre-commit)自动化繁琐的格式检查工作
2.2 项目结构规范
2.2.1 经典 Python 项目目录结构
一个规范的企业级 Python 项目通常采用以下布局:
bash
my-ai-project/
├── src/ # 主要源代码目录
│ └── my_project/ # 项目主包(名称与项目相关)
│ ├── __init__.py
│ ├── main.py # 程序入口
│ ├── api/ # API路由模块(如FastAPI)
│ │ ├── __init__.py
│ │ └── endpoints.py
│ ├── core/ # 核心配置和工具
│ │ ├── __init__.py
│ │ ├── config.py # 配置管理
│ │ └── logging.py # 日志配置
│ ├── models/ # 数据模型(Pydantic/SQLAlchemy)
│ │ ├── __init__.py
│ │ └── schemas.py
│ ├── services/ # 业务逻辑层
│ │ ├── __init__.py
│ │ └── ai_service.py # AI大模型调用服务
│ └── utils/ # 通用工具函数
│ ├── __init__.py
│ └── helpers.py
├── tests/ # 单元测试目录
│ ├── __init__.py
│ ├── conftest.py # pytest配置
│ ├── test_config.py
│ └── test_ai_service.py
├── scripts/ # 辅助脚本(数据迁移、部署等)
│ └── init_db.py
├── docs/ # 项目文档
│ └── api.md
├── .env.example # 环境变量模板
├── .gitignore # Git忽略文件配置
├── .pre-commit-config.yaml # pre-commit钩子配置
├── pyproject.toml # Poetry项目配置(依赖管理)
├── README.md # 项目说明文档
├── Makefile # 常用命令快捷方式(可选)
└── Dockerfile # Docker镜像构建文件(可选)2.2.2 关键目录说明
| 目录/文件 | 作用 |
|---|---|
src/ |
将源代码与配置文件、测试代码等分离,便于打包和部署 |
src/my_project/ |
以项目名命名的主包,所有业务代码都放在这里 |
tests/ |
与src同级,测试代码能方便地导入项目模块 |
.env.example |
环境变量模板,真实密钥绝不提交到 Git |
pyproject.toml |
Poetry 配置文件,统一管理项目依赖和元数据 |
2.2.3 __init__.py 的作用
每个包含**Python** 模块的目录下都需要一个__init__.py文件(Python 3.3+可以是空文件)。它标识该目录是一个**Python** 包,使得我们可以用from my_project.core import config这样的语法导入模块。在__init__.py中还可以定义包的公开接口。
python
# src/my_project/services/__init__.py
from .ai_service import AIService
__all__ = ["AIService"] # 控制 from services import * 的行为建议:从现在开始,所有 Python 项目(包括 AI 大模型相关)都使用 Poetry 进行依赖管理。它不仅能让你避免无数依赖冲突的烦恼,还能使项目更具可维护性和可复现性。
Poetry 介绍:
Poetry 是 Python 的现代化依赖管理和打包工具,它通过
pyproject.toml统一管理项目依赖(自动区分生产与开发环境),并能生成包含精确版本和哈希校验的poetry.lock锁定文件,确保团队和服务器环境完全一致;同时它内置虚拟环境管理,无需手动激活即可运行脚本,还能一键构建和发布项目,彻底解决了传统pip + requirements.txt在依赖冲突、环境隔离和可复现性方面的痛点。
2.3 依赖管理与虚拟环境
在前面的章节中,我们使用了 Python 自带的 venv 模块来创建虚拟环境,并通过 pip 手动安装依赖。这种方式虽然可行,但在实际项目开发中会暴露出许多问题。本章将引入 Poetry --- 目前 Python 社区最推荐的现代化依赖管理工具,它集**虚拟环境管理** 、依赖解析 、打包发布于一体,能够彻底解决传统工作流的痛点。
2.3.1 为什么需要 Poetry?
传统 pip + venv + requirements.txt 的缺陷
| 问题 | 说明 |
|---|---|
| 依赖冲突 | 不同包对同一依赖的版本要求冲突时,pip 只会最后安装的版本生效,可能导致运行时错误 |
| 环境不隔离 | 需要手动激活/退出虚拟环境,忘记激活时会污染全局 Python 环境 |
| 锁文件不可靠 | requirements.txt 只记录顶层依赖的版本,不包含子依赖的精确版本,不同时间安装可能得到不同结果 |
| 无哈希校验 | 无法保证下载的包未被篡改,存在安全风险 |
| 生产/开发依赖混在一起 | 需要维护多个 requirements.txt(dev.txt, prod.txt),管理复杂 |
| 更新依赖困难 | 手动修改版本号然后 pip install -U,无法自动解决版本升级带来的冲突 |
Poetry 的核心优势
-
✅ 统一的依赖解析器:自动计算所有依赖的兼容版本,避免冲突
-
✅ 锁定文件(
poetry.lock):记录每个包的精确版本和哈希值,确保环境完全可重现 -
✅ 自动管理虚拟环境 :
poetry install自动创建/使用虚拟环境,无需手动source venv/bin/activate -
✅ 清晰的分组依赖 :通过
--group dev区分开发依赖(pytest, black 等)和生产依赖 -
✅ 简化的命令 :
poetry add requests自动添加并更新锁文件,一步到位 -
✅ 构建与发布:可直接将项目打包发布到 PyPI
目前主流的 AI 开源项目(如 LangChain、Transformers、llama-index)都使用 Poetry 或类似的工具(如 PDM、Rye)管理依赖。掌握 Poetry 已成为 Python 开发者的必备技能。
问题:为什么需要区分开发依赖和生产依赖,正常来看,不是应该开发和生产依赖一致才对嘛?
这是一个很好的问题。表面上看,开发和生产环境应该"一致"才最安全,但这里的"一致"指的是业务代码所依赖的核心库版本 (如
requests、openai)必须相同,而开发辅助工具 (如pytest、black、ruff、pre-commit)则完全不需要出现在生产环境中。区分它们的好处:(1)减小生产环境体积:生产服务器只安装运行应用所必需的库,避免安装几百 MB 的测试框架和代码检查工具,减少镜像大小和依赖冲突风险。
(2)提高安全性:开发工具可能引入额外的依赖或存在已知漏洞,它们不应该暴露在生产环境中。
(3)加快部署速度 :
pip install或poetry install --no-dev只安装核心依赖,能显著缩短构建和启动时间。实际上,生产依赖是开发依赖的子集 ------你在写代码时确实需要
pytest来测试,但服务器运行你的程序时根本不需要它。保持"开发和生产依赖版本一致"在核心库上是必须的(通过锁文件保证),但将开发工具混入生产环境反而是不专业的做法。
2.3.2 安装 Poetry
Windows(WSL 环境)
在 WSL 的 Ubuntu 终端中执行以下命令(推荐官方安装脚本):
python
curl -sSL https://install.python-poetry.org | python3 -安装完成后,脚本会自动将 Poetry 添加到 PATH(通常写入 ~/.local/bin)。你需要重启终端或执行:
python
source ~/.bashrc验证安装:
python
poetry --version配置 Poetry(重要)
为了避免后续下载包时出现网络问题,建议配置国内 PyPI 镜像(以清华源为例):
python
poetry config repositories.tuna https://pypi.tuna.tsinghua.edu.cn/simple另外,为了将虚拟环境创建在项目目录内部(便于 VS Code 识别和管理),可以修改 Poetry 配置:
python
poetry config virtualenvs.in-project true执行后,Poetry 会在项目根目录下创建 .venv 文件夹,与 venv 类似。
2.3.3 使用 Poetry 初始化项目
场景一:从零开始创建新项目
python
# 创建项目文件夹并进入
mkdir my-ai-service
cd my-ai-service
# 交互式初始化(推荐,可填写项目描述、作者等信息)
poetry initPoetry 会询问你一系列问题:
-
包名称(默认文件夹名)
-
版本(默认 0.1.0)
-
描述(可选)
-
作者(可选)
-
依赖的 Python 版本(默认
^3.10,表示兼容 Python ≥3.10, <4.0) -
是否添加初始依赖(如
openai,requests)
你也可以使用非交互模式 快速生成标准项目结构:
python
poetry new --src my-ai-service这会创建一个 my-ai-service 文件夹,内部包含:
python
my-ai-service/
├── src/
│ └── my_ai_service/
│ └── __init__.py
├── tests/
│ └── __init__.py
├── pyproject.toml
└── README.md场景二:为现有项目添加 Poetry 支持
如果你已经有一个项目(比如之前的 weather_app),只需在项目根目录执行:
python
cd ~/weather_app
poetry init然后根据提示填写信息。Poetry 会扫描当前目录中的 requirements.txt(如果存在)并自动导入依赖。
2.3.4 pyproject.toml 文件详解
Poetry 的核心配置文件是 pyproject.toml(TOML 格式)。以下是一个完整示例:
python
[project]
name = "my-ai-service"
version = "0.1.0"
description = ""
authors = [
{name = "tianpeng",email = "tianpengdataai@outlook.com"}
]
readme = "README.md"
requires-python = ">=3.12"
dependencies = [
]
[tool.poetry]
packages = [{include = "my_ai_service", from = "src"}]
[build-system]
requires = ["poetry-core>=2.0.0,<3.0.0"]
build-backend = "poetry.core.masonry.api"版本约束符号说明:
| 符号 | 含义 | 示例 |
|---|---|---|
^ |
兼容更新(默认) | ^1.2.3 等价于 >=1.2.3, <2.0.0 |
~ |
约等于 | ~1.2.3 等价于 >=1.2.3, <1.3.0 |
>= |
大于等于 | >=1.0.0 |
<= |
小于等于 | <=2.0.0 |
== |
精确匹配 | ==1.2.3 |
2.3.5 安装依赖与虚拟环境管理
第一次安装所有依赖
在项目根目录(包含 pyproject.toml)执行:
python
poetry installPoetry 会:
-
读取
pyproject.toml中的依赖 -
解析所有依赖的兼容版本
-
生成
poetry.lock锁定文件(如果不存在) -
自动创建一个虚拟环境(位置取决于配置,如
virtualenvs.in-project=true则在.venv内) -
安装所有依赖(包括开发依赖)
输出如下内容:
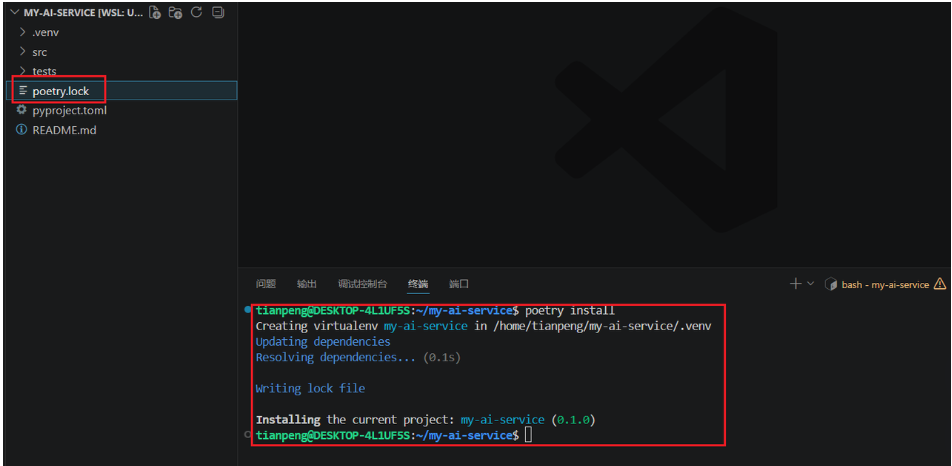
如果只想安装生产依赖(不安装 dev 组):
python
poetry install --no-dev添加新的依赖
python
# 添加生产依赖(添加到 [tool.poetry.dependencies])
# 注意在执行这个命令的时候可以会出现版本问题,使用AI解决这个问题。
# LangChain 是一个开源的 AI 框架
poetry add langchain
# 指定版本
poetry add "torch>=2.0.0"
# 添加开发依赖(添加到 [tool.poetry.group.dev.dependencies])
poetry add --group dev jupyter
# 添加一个可选依赖(不会默认安装,需要用户显式指定 extra)
poetry add --optional mysql-connector-python-
poetry add langchain:将 LangChain 框架作为生产依赖添加到项目中,自动解析并安装兼容版本。 -
poetry add "torch>=2.0.0":将 PyTorch 的 2.0.0 及以上版本添加为生产依赖。 -
poetry add --group dev jupyter:将 Jupyter 仅添加到开发依赖组,生产环境不会安装。 -
poetry add --optional mysql-connector-python:将 MySQL 连接器添加为可选依赖,只有用户显式安装对应 extra 特性时才会引入。
移除依赖
python
poetry remove openai更新依赖版本
python
# 根据 pyproject.toml 中的版本约束更新所有依赖到最新允许版本
poetry update
# 只更新某个特定包
poetry update openai查看当前已安装的依赖
python
# 以树形结构显示依赖关系
poetry show --tree
# 显示可更新的依赖
poetry show --outdated2.3.6 在虚拟环境中运行代码
Poetry 提供了两种方式在虚拟环境中执行 Python 命令:
方法一: poetry run
在任何位置,只要当前目录是项目根目录(或子目录),使用 poetry run 前缀:
python
# 在 Poetry 虚拟环境中执行指定的 Python 入口脚本。
poetry run python src/my_ai_service/main.py
# 在 Poetry 虚拟环境中运行 tests/ 目录下的所有 pytest 单元测试。
poetry run pytest tests/
# 在 Poetry 虚拟环境中启动 Jupyter Notebook 服务器,用于交互式开发和数据分析。
poetry run jupyter notebook方法二:激活虚拟环境 Shell
python
poetry shell之后你会进入一个嵌套的 shell,终端提示符前会显示虚拟环境名称(如 (my-ai-service-py3.10))。在此环境下,直接使用 python、pip、pytest 等命令都会在虚拟环境中执行。
退出虚拟环境:
python
exit推荐 :在日常开发中,建议直接使用
poetry run,避免忘记激活/退出环境的问题。VS Code 等 IDE 也支持自动识别 Poetry 虚拟环境(见 2.3.8 节)。
2.3.7 锁定文件 poetry.lock 的重要性
poetry.lock 文件记录了所有依赖(包括子依赖)的精确版本和哈希值。例如:
python
[[package]]
name = "openai"
version = "1.30.3"
description = "Python client library for the OpenAI API"
category = "main"
optional = false
python-versions = ">=3.7.1"
files = [
{file = "openai-1.30.3-py3-none-any.whl", hash = "sha256:..."},
{file = "openai-1.30.3.tar.gz", hash = "sha256:..."},
]必须将 poetry.lock 提交到 Git 仓库。这样做的好处:
-
所有开发者和 CI/CD 环境执行
poetry install时会安装完全相同的依赖版本,杜绝"在我机器上能运行"的问题。 -
哈希校验确保安装的包未被篡改,提升安全性。
⚠️ 注意:对于库项目(要发布到 PyPI 供他人使用的),通常不提交
poetry.lock;但对于应用项目(Web 服务、脚本、AI 应用),必须提交。
2.3.8 VS Code 集成 Poetry 虚拟环境
在 VS Code 扩展市场搜索并安装 "Poetry" 扩展(作者:ms-python)。安装后,你可以在命令面板中执行 Poetry: Add Dependency、Poetry: Install 等操作,无需手动输入命令。
完成上面的安装,这就意味着 VS Code 已经具备了自动识别 Poetry 等虚拟环境的能力。
不过,为了让环境识别完全生效,建议你按以下步骤确认一下:
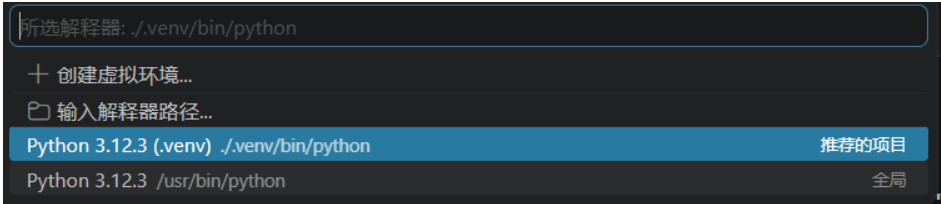
(1)打开命令面板: 按 Ctrl+Shift+P,输入并选择 Python: Select Interpreter。
**(2)查看环境列表:**在弹出的列表中,VS Code 会自动扫描并列出它发现的所有 Python 环境(包括 Poetry 创建的虚拟环境)。
(3)选择正确的解释器: 选择对应你项目的 Poetry 虚拟环境(通常路径类似 ./venv/bin/python 或 ~/.cache/pypoetry/virtualenvs/...)。
完成上述选择后,VS Code 就会记住该环境,并自动用于代码补全、调试和终端运行。简单来说:扩展已提供功能,你只需手动指定一次即可自动使用。
2.3.9 实战:将之前的天气查询项目迁移到 Poetry
新创建一个 weather.py 的文件,将下面的代码复制到文件中。
python
"""
一个简单的天气查询程序
使用 wttr.in 提供的免费公开API(无需注册)
"""
import requests
def get_weather(city):
"""根据城市名称获取天气信息"""
# wttr.in 是一个面向开发者的极简天气API
# 参数:?format=3 表示返回简洁的单行文本格式
url = f"https://wttr.in/{city}?format=3"
try:
response = requests.get(url, timeout=5)
# 检查HTTP状态码是否正常(200表示成功)
response.raise_for_status()
return response.text.strip()
except requests.exceptions.RequestException as e:
return f"查询失败:{e}"
def main():
print("=== 简易天气查询工具 ===")
city = input("请输入城市名称(英文或拼音,例如:Beijing):")
if not city.strip():
print("城市名不能为空!")
return
print(f"正在查询 {city} 的天气...")
weather_info = get_weather(city)
print("查询结果:", weather_info)
if __name__ == "__main__":
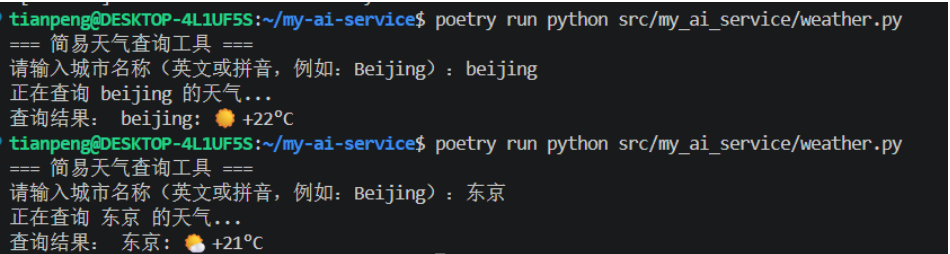
main()然后运行:
python
poetry run python src/my_ai_service/weather.py输出如下内容:
2.3.10 总结对比:传统方式 vs Poetry
| 功能 | pip + venv |
Poetry |
|---|---|---|
| 创建虚拟环境 | python -m venv venv(手动) |
poetry install(自动) |
| 激活虚拟环境 | source venv/bin/activate |
poetry shell 或 poetry run |
| 添加依赖 | pip install requests 然后手动更新 requirements.txt |
poetry add requests(自动更新 pyproject.toml 和 lock) |
| 锁定精确版本 | 需要 pip freeze > requirements.txt,但缺少哈希 |
poetry.lock 自动生成,包含哈希 |
| 分组依赖 | 需要多个 requirements-*.txt |
内置 --group dev 支持 |
| 依赖解析 | 线性解析,容易冲突 | 先进解析器,自动解决冲突 |
| 打包发布 | 需要 setuptools 和 setup.py |
内置 poetry build 和 poetry publish |
2.4 代码风格规范(PEP 8)
PEP 8 是 Python 官方的代码风格指南,企业项目普遍要求遵循。现代工具可以自动检查和格式化,但开发者仍需了解核心规则。
2.4.1 命名规范
| 类型 | 规范 | 示例 |
|---|---|---|
| 模块/包名 | 小写字母+下划线 | ai_service.py、my_project |
| 类名 | 驼峰命名法(首字母大写) | AIService、UserProfile |
| 函数/方法名 | 小写字母+下划线 | get_response()、calculate_score() |
| 变量名 | 小写字母+下划线 | user_name、total_count |
| 常量 | 全大写+下划线 | MAX_RETRIES、API_TIMEOUT |
| 私有属性/方法 | 单下划线开头(约定) | _internal_method()、_cache |
2.4.2 缩进与空格
-
使用4 个空格 缩进,禁止使用 Tab 键(VS Code 默认会将 Tab 转为空格)
-
每行代码不超过88 个字符(Black 工具默认,PEP 8 原建议 79 但较严格)
-
函数和类定义之间空两行 ,方法定义之间空一行
2.4.3 导入规范
python
# 1. 标准库导入
import os
import sys
from pathlib import Path
# 2. 第三方库导入
import openai
from pydantic import BaseModel
from dotenv import load_dotenv
# 3. 本地模块导入
from my_project.core.config import settings
from my_project.services.ai_service import AIService每个导入块之间空一行,避免使用from module import *。
2.4.4 自动化格式检查工具
手动遵守规范繁琐且容易遗漏,企业项目使用自动化工具链:
1. Black --- 无情的代码格式化工具
Black 是一款被称为"不妥协"的 Python 代码格式化工具,它会自动按照一致的风格规则(如缩进、换行、空格等)重新格式化代码,几乎不允许用户自定义配置,从而彻底消灭团队中关于代码风格的争论,让所有代码看起来像同一个人写的。
python
# 将 black 代码格式化工具添加为项目的开发依赖
poetry add --group dev black
# 使用它自动格式化 src/ 和 tests/ 目录下的所有 Python 代码。
# 命令只是一次性地扫描并格式化了 src/ 和 tests/ 目录下已经存在的所有文件。
poetry run black src/ tests/格式化代码是指按照预设的规则(如缩进、空格、换行、括号位置等)自动调整代码的书写风格,使其布局整齐、统一,但不改变代码的实际运行逻辑。使用格式化工具(如 black)可以帮你节省手动调整格式的时间,并确保整个项目的代码风格一致。
2. Ruff --- 极速的代码检查器(替代 Flake8、isort 等)
Ruff 是一个用 Rust 编写的极速 Python 代码检查(Linter)与格式化工具,能一站式替代 Flake8、isort、Black 等传统工具;它可以快速检测代码中的语法错误、风格违规、逻辑问题(如未使用的变量、导入),并自动修复大量可修复的问题,同时支持通过配置文件自定义规则,帮助团队维护统一且高质量的代码风格。
python
# 将 ruff 这款快速代码检查与格式化工具添加为项目的开发依赖。
poetry add --group dev ruff
# 对 src/ 和 tests/ 目录下的 Python 代码运行 Ruff 检查,报告语法、风格、逻辑等潜在问题。
poetry run ruff check src/ tests/
# 在检查的同时,自动修复 Ruff 能够安全处理的问题(如删除未使用的导入、调整格式等)。
poetry run ruff check --fix src/ tests/3. Pre-commit ------ Git 提交前自动检查
~注意这部分的内容需要安装好 git 后才能处理,如果没有安装的话 AI 解决~
Pre-commit 是一个用于管理 Git 预提交钩子的框架,它可以在开发者执行 git commit 时自动运行预先配置好的检查任务(如代码格式化、语法检测、安全扫描等),确保只有符合项目规范的代码才能被提交,从而在团队协作中自动化地保证代码质量和一致性。
在根目录下创建.pre-commit-config.yaml,并将下述的内容复制到文件中:
python
repos:
- repo: https://github.com/pre-commit/pre-commit-hooks
rev: v4.5.0
hooks:
- id: trailing-whitespace
- id: end-of-file-fixer
- id: check-yaml
- repo: https://github.com/astral-sh/ruff-pre-commit
rev: v0.3.0
hooks:
- id: ruff
args: [--fix]
- id: ruff-format安装钩子:
python
# 安装 pre-commit 作为开发依赖:
# 这个命令会将 pre-commit 安装到项目专属的虚拟环境中
poetry add --group dev pre-commit
# 初始化 Git 仓库(在项目根目录执行)
git init
# 添加所有 Python 文件到暂存区
git add src/ tests/
# 现在,pre-commit 已经在虚拟环境中了,可以重新运行安装钩子的命令:
poetry run pre-commit install
# 运行 pre-commit 检查
poetry run pre-commit run --all-files输出如下内容:
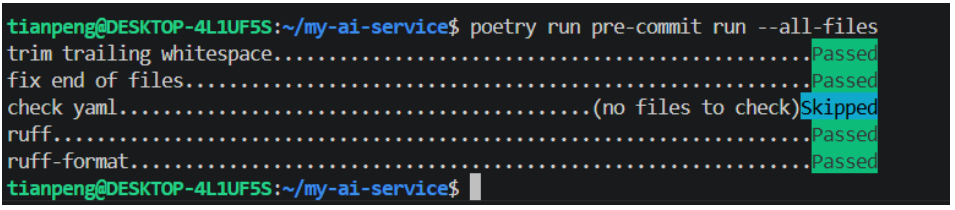
此后每次git commit都会自动执行检查,不符合规范的代码无法提交。
命令解析:
(1)一次性命令(只需执行一次)
-
poetry add --group dev black、ruff、pre-commit--- 安装开发依赖,一次即可。 -
git init--- 初始化仓库,仅一次。 -
poetry run pre-commit install--- 安装 Git 钩子,一次即可。
(2)需要重复执行的命令(随代码变更)
-
poetry run black src/ tests/--- 手动格式化代码,每次修改后想格式化就得重新运行(建议配合编辑器保存时自动格式化或 pre-commit)。 -
poetry run ruff check src/ tests/--- 手动检查代码问题,每次修改后需重新运行。 -
poetry run ruff check --fix src/ tests/--- 同上,并自动修复。 -
git add src/ tests/--- 每次提交前需将改动加入暂存区。
(3)自动触发(无需手动重复)
- pre-commit 钩子 :安装后,每次执行
git commit时会自动运行配置的检查(如 ruff、black),无需手动运行pre-commit run --all-files(该命令仅用于一次性检查所有文件)。
总结 :安装配置类命令一次就好;格式化和检查命令在代码修改后需要重新执行,但可通过设置编辑器保存时自动格式化或依赖 Git 钩子自动完成,从而减少手动操作。
2.5 类型注解与静态类型检查
2.5.1 为什么需要类型注解?
**Python**是动态类型语言,变量类型在运行时确定,这虽然灵活但带来隐患:
-
函数参数期望整数但传入了字符串,程序可能跑到一半才报错
-
大型项目中阅读代码时难以快速判断变量类型
-
IDE 无法提供准确的代码补全
类型注解(Type Hints)在 Python 3.5+引入,它不改变运行时行为,但能配合静态检查工具(如 mypy、Pyright)在编码阶段发现类型错误。
2.4.2 基本类型注解语法
python
# 变量注解
name: str = "张三"
age: int = 25
scores: list[int] = [85, 92, 78]
user_data: dict[str, str] = {"name": "张三", "city": "北京"}
# 函数注解
def greet(name: str, age: int) -> str:
return f"{name}今年{age}岁"
# 可选类型(可能为None)
from typing import Optional
def find_user(user_id: int) -> Optional[dict]:
# 查找用户,未找到返回None
pass
# 联合类型(Python 3.10+)
def process(data: int | str) -> str:
return str(data)
# 复杂类型
from typing import List, Dict, Tuple, Union
def process_items(items: List[str]) -> Dict[str, int]:
counts = {}
for item in items:
counts[item] = counts.get(item, 0) + 1
return counts2.4.3 Pydantic:数据验证与类型安全的利器
在 AI 大模型开发中,我们频繁处理 JSON 数据(API 请求响应、配置文件、模型输出解析等)。传统的做法是用字典来传递数据,但字典没有结构约束------你不知道某个字段是否存在、类型是否正确、取值范围是否合法。一旦数据结构出错,往往要到运行时才发现,排查成本极高。
Pydantic 就是一个专门解决这类问题的库。它使用 Python 的类型注解来定义数据模型,能自动完成数据校验、类型转换、默认值填充和 JSON 序列化。在 FastAPI、LangChain、AutoGen 等主流 AI 框架中,Pydantic 都是底层的数据模型标准。
(1)安装
python
# 推荐做法:始终在虚拟环境中安装,确保项目级别的隔离。
poetry add pydantic如果你还需要校验邮箱、URL 等复杂格式,可以安装附加依赖:
python
poetry add "pydantic[email]"(2)基础用法:从字典到强类型模型
无 Pydantic 的痛点写法:
python
# 原始做法:用字典,没有任何保障
msg = {"role": "user", "content": "你好"}
# 万一有人写错了键名或类型,只能在运行时才发现
msg["contnet"] # KeyError: 'content'使用 Pydantic 后的写法:
python
from pydantic import BaseModel
from datetime import datetime
class ChatMessage(BaseModel):
role: str
content: str
timestamp: datetime = None # 可选字段,默认值为None
# 正确数据:自动校验通过
msg = ChatMessage(role="user", content="什么是Python?")
print(msg.role) # user
print(msg.content) # 什么是Python?
# 错误数据:在实例化时就抛出清晰的 ValidationError
try:
bad_msg = ChatMessage(role="admin", content=12345)
except Exception as e:
print(f"数据校验失败:{e}")输出如下内容:
python
tianpeng@DESKTOP-4L1UF5S:~/my-ai-service$ poetry run python src/my_ai_service/ChatMessage.py
user
什么是Python?
数据校验失败:1 validation error for ChatMessage
content
Input should be a valid string [type=string_type, input_value=12345, input_type=int]
For further information visit https://errors.pydantic.dev/2.13/v/string_typePydantic 会在你创建实例的瞬间就完成所有校验,错误会立刻暴露,不会留到后续业务逻辑中。
(3)字段约束:Field() 的使用
Field() 函数可以为字段添加额外约束,比如长度限制、数值范围、默认值等。这是定义数据"合法边界"的核心手段。
python
from pydantic import BaseModel, Field
class ProductSchema(BaseModel):
name: str = Field(..., min_length=1, max_length=100, description="产品名称")
price: float = Field(..., ge=0.01, le=999999.99, description="价格")
tags: list[str] = Field(default=[], max_length=10, description="标签列表")
in_stock: bool = Field(default=True)
# 合法数据
prod = ProductSchema(name="蓝牙耳机", price=299.00)
print(prod.model_dump()) # {'name': '蓝牙耳机', 'price': 299.0, 'tags': [], 'in_stock': True}
# 价格超出范围
try:
ProductSchema(name="测试", price=-1)
except Exception as e:
print(f"校验失败:{e}")输出如下内容:
python
tianpeng@DESKTOP-4L1UF5S:~/my-ai-service$ poetry run python src/my_ai_service/ChatMessage.py
{'name': '蓝牙耳机', 'price': 299.0, 'tags': [], 'in_stock': True}
校验失败:1 validation error for ProductSchema
price
Input should be greater than or equal to 0.01 [type=greater_than_equal, input_value=-1, input_type=int]
For further information visit https://errors.pydantic.dev/2.13/v/greater_than_equalField() 常用参数一览:
| 参数 | 含义 | 示例 |
|---|---|---|
... |
必填字段 | Field(...) |
default |
默认值 | Field(default=0) |
min_length / max_length |
字符串长度限制 | Field(min_length=1, max_length=100) |
ge / le / gt / lt |
数值范围限制 | Field(ge=0, le=100) |
description |
字段描述(生成 JSON Schema 时使用) | Field(description="用户名") |
pattern |
正则表达式匹配 | Field(pattern=r"^\d{11}$") |
(4)自定义验证器:field_validator
当内置约束不够用时,可以用 @field_validator 自定义校验逻辑。
python
from pydantic import BaseModel, Field, field_validator
class ChatMessage(BaseModel):
"""聊天消息模型"""
role: str = Field(..., description="角色:user/assistant/system")
content: str = Field(..., min_length=1, max_length=10000, description="消息内容")
temperature: float = Field(0.7, ge=0.0, le=2.0)
@field_validator('role')
@classmethod
def validate_role(cls, v: str) -> str:
"""校验role字段,只允许三种合法值"""
if v not in {'user', 'assistant', 'system'}:
raise ValueError(f'role必须为user、assistant或system,当前值:{v}')
return v
@field_validator('content')
@classmethod
def validate_content(cls, v: str) -> str:
"""校验content不能为空或纯空白字符"""
if not v.strip():
raise ValueError('content不能为空或纯空白字符')
return v
# 正常通过
msg = ChatMessage(role="user", content="你好,请介绍一下Python")
print(msg.model_dump())
# 非法role:触发validate_role
try:
ChatMessage(role="admin", content="你好")
except Exception as e:
print(f"校验失败:{e}")
# 空content:触发validate_content
try:
ChatMessage(role="user", content=" ")
except Exception as e:
print(f"校验失败:{e}")输出如下内容:
python
tianpeng@DESKTOP-4L1UF5S:~/my-ai-service$ /home/tianpeng/my-ai-service/.venv/bin/python /home/tianpeng/my-ai-service/src/my_ai_service/ChatMessage.py
{'role': 'user', 'content': '你好,请介绍一下Python', 'temperature': 0.7}
校验失败:1 validation error for ChatMessage
role
Value error, role必须为user、assistant或system,当前值:admin [type=value_error, input_value='admin', input_type=str]
For further information visit https://errors.pydantic.dev/2.13/v/value_error
校验失败:1 validation error for ChatMessage
content
Value error, content不能为空或纯空白字符 [type=value_error, input_value=' ', input_type=str]
For further information visit https://errors.pydantic.dev/2.13/v/value_error
tianpeng@DESKTOP-4L1UF5S:~/my-ai-service$ @field_validator 的关键点:
-
必须是
@classmethod(类方法) -
第一个参数是
cls,第二个参数v是被校验的字段值 -
返回值会替换原来的字段值,所以即使不做修改也必须
return v -
可以在校验器中做字段值的清洗转换(如去空格、统一大小写等)
(5)嵌套模型:构建复杂数据结构
真实项目中,数据结构往往是嵌套的。Pydantic 支持模型嵌套,把一个模型作为另一个模型的字段类型。
python
from pydantic import BaseModel, Field
from typing import Optional, List
from datetime import datetime
# 首先定义 ChatMessage,因为 ChatRequest 需要依赖它
class ChatMessage(BaseModel):
role: str = Field(..., description="角色:user/assistant/system")
content: str = Field(..., min_length=1, max_length=10000)
timestamp: datetime = Field(default_factory=datetime.now)
# 然后定义 ChatRequest
class ChatRequest(BaseModel):
messages: List[ChatMessage] # 嵌套 ChatMessage 列表
model: str = "gpt-4o"
temperature: float = Field(0.7, ge=0.0, le=2.0)
max_tokens: Optional[int] = Field(None, gt=0, le=4096)
# 使用示例
request = ChatRequest(
messages=[
{"role": "system", "content": "你是一个Python专家"},
{"role": "user", "content": "什么是装饰器?"}
],
temperature=0.8
)
print(request.model_dump())输出如下内容:
python
tianpeng@DESKTOP-4L1UF5S:~/my-ai-service$ poetry run python src/my_ai_service/ChatMessage.py
{'messages': [{'role': 'system', 'content': '你是一个Python专家', 'timestamp': datetime.datetime(2026, 5, 27, 15, 30, 14, 815681)}, {'role': 'user', 'content': '什么是装饰器?', 'timestamp': datetime.datetime(2026, 5, 27, 15, 30, 14, 815698)}], 'model': 'gpt-4o', 'temperature': 0.8, 'max_tokens': None}
tianpeng@DESKTOP-4L1UF5S:~/my-ai-service$ Pydantic 会自动将 messages 列表中的每个字典递归转换为 ChatMessage 实例并校验。如果其中任何一个字典不符合 ChatMessage 的约束,整个请求都会校验失败。
(6)序列化:把模型导出为字典或 JSON
在 AI 开发中,模型对象经常需要转换为字典传给 API,或序列化为 JSON 存入数据库。
python
from pydantic import BaseModel, Field
from typing import Optional, List
from datetime import datetime
# 首先定义 ChatMessage,因为 ChatRequest 需要依赖它
class ChatMessage(BaseModel):
role: str = Field(..., description="角色:user/assistant/system")
content: str = Field(..., min_length=1, max_length=10000)
timestamp: datetime = Field(default_factory=datetime.now)
# 然后定义 ChatRequest
class ChatRequest(BaseModel):
messages: List[ChatMessage] # 嵌套 ChatMessage 列表
model: str = "gpt-4o"
temperature: float = Field(0.7, ge=0.0, le=2.0)
max_tokens: Optional[int] = Field(None, gt=0, le=4096)
# 使用示例
request = ChatRequest(
messages=[
{"role": "system", "content": "你是一个Python专家"},
{"role": "user", "content": "什么是装饰器?"}
],
temperature=0.8
)
print(request.model_dump())
# 导出为字典
data_dict = request.model_dump()
print(data_dict)
# 导出为JSON字符串
data_json = request.model_dump_json(indent=2)
print(data_json)
# 排除未设置的字段(只导出实际赋值的字段)
compact_json = request.model_dump_json(exclude_unset=True)
print(compact_json)输出如下内容:
python
tianpeng@DESKTOP-4L1UF5S:~/my-ai-service$ poetry run python src/my_ai_service/ChatMessage.py
{'messages': [{'role': 'system', 'content': '你是一个Python专家', 'timestamp': datetime.datetime(2026, 5, 27, 15, 32, 45, 456151)}, {'role': 'user', 'content': '什么是装饰器?', 'timestamp': datetime.datetime(2026, 5, 27, 15, 32, 45, 456189)}], 'model': 'gpt-4o', 'temperature': 0.8, 'max_tokens': None}
{'messages': [{'role': 'system', 'content': '你是一个Python专家', 'timestamp': datetime.datetime(2026, 5, 27, 15, 32, 45, 456151)}, {'role': 'user', 'content': '什么是装饰器?', 'timestamp': datetime.datetime(2026, 5, 27, 15, 32, 45, 456189)}], 'model': 'gpt-4o', 'temperature': 0.8, 'max_tokens': None}
{
"messages": [
{
"role": "system",
"content": "你是一个Python专家",
"timestamp": "2026-05-27T15:32:45.456151"
},
{
"role": "user",
"content": "什么是装饰器?",
"timestamp": "2026-05-27T15:32:45.456189"
}
],
"model": "gpt-4o",
"temperature": 0.8,
"max_tokens": null
}
{"messages":[{"role":"system","content":"你是一个Python专家"},{"role":"user","content":"什么是装饰器?"}],"temperature":0.8}
tianpeng@DESKTOP-4L1UF5S:~/my-ai-service$ (7)从 JSON/字典反向创建模型
Pydantic 也支持从外部数据源(如 API 响应、数据库查询结果)反向构建模型实例,同时自动完成校验。
python
# 1. 先把所有依赖的类定义好(这是上面所有"缺"的那部分)
from pydantic import BaseModel, Field
from typing import Optional, List
from datetime import datetime
class ChatMessage(BaseModel):
role: str = Field(..., description="角色:user/assistant/system")
content: str = Field(..., min_length=1, max_length=10000)
timestamp: datetime = Field(default_factory=datetime.now)
class ChatRequest(BaseModel):
messages: List[ChatMessage]
model: str = "gpt-4o"
temperature: float = Field(0.7, ge=0.0, le=2.0)
max_tokens: Optional[int] = Field(None, gt=0, le=4096)
# 2. 然后再使用刚刚定义的类(这是刚才你问的那段代码)
# 从字典创建(带校验)
raw_data = {
"messages": [
{"role": "user", "content": "帮我写一段代码"}
],
"model": "gpt-4o",
"temperature": 0.9
}
request = ChatRequest.model_validate(raw_data)
# 从JSON字符串创建
import json
json_str = json.dumps(raw_data)
request = ChatRequest.model_validate_json(json_str)
print(request.model_dump())输出如下内容:
python
tianpeng@DESKTOP-4L1UF5S:~/my-ai-service$ poetry run python src/my_ai_service/ChatMessage.py
{'messages': [{'role': 'user', 'content': '帮我写一段代码', 'timestamp': datetime.datetime(2026, 5, 27, 15, 35, 2, 209461)}], 'model': 'gpt-4o', 'temperature': 0.9, 'max_tokens': None}
tianpeng@DESKTOP-4L1UF5S:~/my-ai-service$model_validate() vs 直接构造 :两者效果相同,但 model_validate() 更明确地表达了"这是从外部数据反序列化"的意图,在框架集成中更常见。
(8)Pydantic 在 AI 大模型开发中的核心价值
对比:dict vs Pydantic
| 场景 | 传统 dict | Pydantic |
|---|---|---|
| 字段类型校验 | 手写 if 判断,容易遗漏 | 自动校验,类型不匹配立刻报错 |
| 嵌套结构校验 | 逐层手写校验逻辑 | 嵌套模型递归自动校验 |
| JSON Schema 生成 | 需手动编写 | model_json_schema() 自动生成 |
| IDE 提示 | 无类型提示,全靠记忆 | 完整的类型注解和自动补全 |
| 数据序列化 | json.dumps() 手动处理 |
model_dump_json() 一行搞定 |
(9)常用 Pydantic 类型速查
| Python 类型 | Pydantic 用法 | 说明 |
|---|---|---|
str |
name: str |
字符串 |
int |
age: int |
整数 |
float |
price: float |
浮点数 |
bool |
active: bool |
布尔值 |
datetime |
created: datetime |
日期时间 |
Optional[str] |
nickname: Optional[str] = None |
可选字段 |
List[str] |
tags: List[str] |
字符串列表 |
Dict[str, int] |
scores: Dict[str, int] |
字典 |
Literal["a", "b"] |
status: Literal["on", "off"] |
限定可选值(需 from typing import Literal) |
EmailStr |
email: EmailStr |
邮箱格式校验(需 pip install pydantic[email]) |
AnyUrl |
url: AnyUrl |
URL 格式校验 |
掌握了**Pydantic** ,你就能在 AI 项目中用强类型模型替代散乱的字典,让数据处理更安全、更清晰。核心记住三点:用 BaseModel 定义结构,用 Field 加约束,用 field_validator 自定义逻辑。这套范式在 FastAPI、LangChain 等主流框架中无处不在,是现代化 Python 项目的标配。
2.4.4 静态类型检查工具:mypy
(1)什么是静态类型检查?
Python 是动态类型语言,变量类型在运行时才确定。这带来灵活性,但也容易隐藏 bug:
python
# 这段代码在写的时候没有任何提示,但运行就会崩溃
def add_numbers(a, b):
return a + b
result = add_numbers(5, "10") # TypeError: unsupported operand type(s)静态类型检查 就是在不运行代码的情况下,提前发现这类类型错误。mypy 就是这个领域最主流的工具------它读取你代码中的类型注解,然后"推理"每个变量的类型是否正确。
安装 mypy
使用 Poetry 将 mypy 安装到开发依赖中:
python
poetry add --group dev mypy执行后,pyproject.toml 中会多出一段:
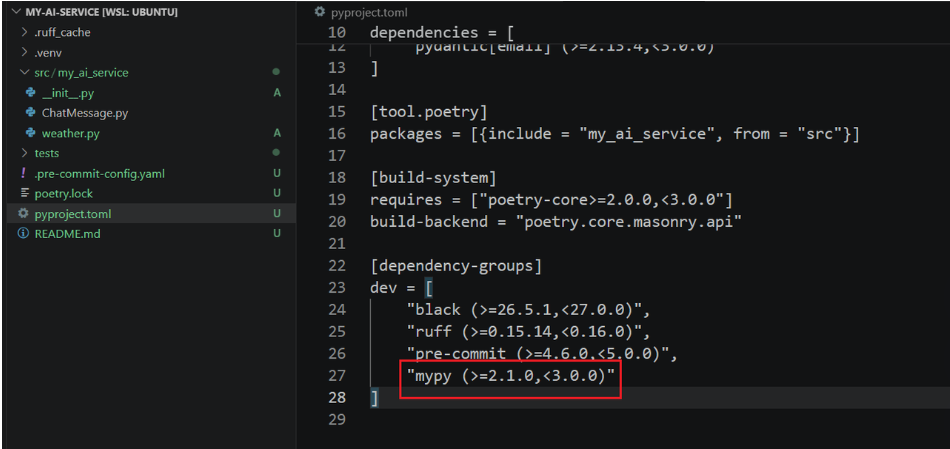
运行 mypy
python
poetry run mypy src/ --ignore-missing-imports命令拆解:
-
poetry run:在 Poetry 管理的虚拟环境中执行后续命令 -
mypy:启动 mypy 检查器 -
src/:检查src/目录下的所有 Python 文件 -
--ignore-missing-imports:如果第三方库没有类型注解(比如pydantic的部分子模块),不要报错
(2)完整示例:从零开始体验 mypy
假设项目结构如下:
python
my_project/
├── src/
│ └── main.py
├── pyproject.toml
└── ...步骤一:创建 src/main.py
python
# src/main.py
from typing import Optional
def calculate_discount(price: float, rate: Optional[float]) -> float:
if rate is None:
return price
return price * (1 - rate)
# 正确调用
final_price = calculate_discount(100.0, 0.2)
print(f"折扣后价格:{final_price}")
# 错误调用:传了字符串而不是数字
bug_price = calculate_discount(100.0, "0.2") # mypy 会在这里报错步骤二:运行 mypy 检查
python
poetry run mypy src/my_ai_service/ main.pymypy 的输出:
python
tianpeng@DESKTOP-4L1UF5S:~/my-ai-service$ poetry run mypy src/my_ai_service/main.py
src/my_ai_service/main.py:14: error: Argument 2 to "calculate_discount" has incompatible type "str"; expected "float | None" [arg-type]
Found 1 error in 1 file (checked 1 source file)
tianpeng@DESKTOP-4L1UF5S:~/my-ai-service$错误解读:
-
src/my_ai_service/main.py:14:文件名和第 14 行 -
Argument 2 to "calculate_discount":第二个参数出问题 -
has incompatible type "str":实际传的是str类型 -
expected "float | None":期望的是float或None
你不需要运行代码,mypy 已经帮你找到了这个类型错误。
(3)与 VS Code Pylance 的配合
Pylance 是 VS Code 默认的 Python 语言服务器,它在你写代码的瞬间 就会实时分析类型。当你在编辑器中输入 calculate_discount(100.0, "0.2") 时,"0.2" 下方会立刻出现红色波浪线,鼠标悬停就能看到和 mypy 一样的错误提示。
安装完成后,需要确保它被正确启用和配置。
-
确认语言服务器已设置为 Pylance:打开 VS Code 设置 (
Ctrl + ,),搜索python.languageServer,确保它的值设置为Pylance。 -
启用类型检查模式:为了让 Pylance 实时高亮显示类型错误,在设置中搜索
Type Checking Mode,将其值从off改为basic或strict。推荐从basic开始,对大型项目或追求更高质量时选用strict。
- 选择正确的 Python 解释器:按
Ctrl+Shift+P打开命令面板,输入并选择Python: Select Interpreter,然后选择你项目对应的 Python 环境(例如,你通过 Poetry 创建的虚拟环境)。
设置成功后,代码自动完成标亮
mypy 和 Pylance 的分工:
-
Pylance:实时反馈,写代码时立刻看到错误
-
mypy:可以在 CI/CD 流程中强制执行,作为代码质量的"门禁"
两者可以共用一个 pyproject.toml 配置文件,保持检查规则一致。在 pyproject.toml 中添加以下内容,mypy 和 Pylance 会自动读取:
python
[tool.mypy]
python_version = "3.11"
strict = false
ignore_missing_imports = true配置项说明:
-
python_version:声明你项目使用的 Python 版本 -
strict = false:不开启完全严格模式(初学者不建议开启) -
ignore_missing_imports = true:等同于命令行的--ignore-missing-imports
核心记住 :mypy 是一个不运行代码也能发现 bug的工具。结合编辑器中的 Pylance 实时提示,类型错误在开发阶段就能被拦截,而不是等到线上崩溃。
2.5 文档字符串规范
2.5.1 为什么要写文档字符串?
-
帮助其他开发者(包括三个月后的你自己)理解代码意图
-
配合工具(如 Sphinx)自动生成 API 文档
-
IDE 能在鼠标悬停时显示函数说明
2.5.2 Google 风格文档字符串示例
Google 风格是目前最流行的 Python 文档字符串格式,清晰易读。
python
def call_llm(
prompt: str,
model: str = "gpt-4",
temperature: float = 0.7,
max_tokens: int = 1024
) -> str:
"""调用大语言模型获取回答。
Args:
prompt: 用户输入的提示词。
model: 使用的模型名称,默认为"gpt-4"。
temperature: 采样温度,范围0.0-2.0,值越高回答越随机。
max_tokens: 生成的最大token数量。
Returns:
模型返回的文本回答。
Raises:
ValueError: 当temperature不在有效范围时抛出。
ConnectionError: 当API调用网络失败时抛出。
Example:
>>> response = call_llm("什么是Python?", model="gpt-3.5-turbo")
>>> print(response)
Python是一种解释型、面向对象的高级编程语言...
"""
if not 0.0 <= temperature <= 2.0:
raise ValueError("temperature必须在0.0到2.0之间")
# 实际API调用逻辑...
return "模型返回的内容"模块级文档字符串(放在文件开头):
python
"""AI大模型调用服务模块。
本模块封装了对OpenAI API的调用,提供:
- 单轮对话
- 多轮对话上下文管理
- 流式输出
"""类文档字符串:
python
class AIService:
"""AI服务类,负责与大模型API交互。
Attributes:
api_key: API密钥。
base_url: API基础URL。
default_model: 默认使用的模型名称。
"""
def __init__(self, api_key: str, base_url: str, default_model: str = "gpt-4"):
"""初始化AI服务。
Args:
api_key: API密钥。
base_url: API基础URL。
default_model: 默认模型。
"""
self.api_key = api_key
self.base_url = base_url
self.default_model = default_model2.6 配置管理规范
2.6.1 配置管理的核心原则
良好的配置管理是构建稳定、安全、可维护应用的基础。以下是必须遵守的四大原则:
| 原则 | 说明 | 反例(错误) | 正确做法 |
|---|---|---|---|
| 代码与配置严格分离 | 配置(尤其是环境相关的值)不应硬编码在源代码中。 | API_KEY = "sk-123456" 写在代码里 |
通过环境变量或配置文件注入 |
| 环境差异化 | 开发、测试、预发布、生产环境应有各自独立的配置,互不影响。 | 开发环境直连生产数据库 | 使用 dev.env, test.env, .env.production 等 |
| 安全优先 | 敏感信息(密钥、密码、证书)绝不能提交到版本控制系统(Git)。 | 将 .env 提交到仓库 |
将 .env 加入 .gitignore,仅提交 .env.example 模板 |
| 配置即代码 | 使用类型校验、默认值、描述元数据,让配置可被程序理解和验证。 | 在代码中随意 os.getenv 且不校验类型 |
使用配置管理库(如 Pydantic Settings)并定义字段类型 |
重要:永远不要在代码注释、日志或错误消息中泄露敏感配置。
2.6.2 项目结构与 Poetry 初始化
为了规范化配置管理,我们首先需要搭建一个标准 Python 项目结构,并通过 Poetry 管理依赖。
(1)创建项目文件夹结构
以下是在本规范中根目录下创建的所有文件夹和文件清单:
python
my_project/ # 项目根目录
├── .env # 本地开发环境配置(不提交到 Git)
├── .env.example # 配置模板(提交到 Git)
├── .env.production # 生产环境配置(服务器手动放置)
├── .gitignore # Git 忽略文件(2)配置 。gitignore
在项目根目录创建 .gitignore,至少包含以下内容:
python
# Poetry
poetry.lock # 如果你希望锁文件也提交,请删除此行;推荐提交锁文件,但此处示例可忽略
# 注意:官方推荐 poetry.lock 应提交到版本控制,此处仅作演示;实际项目建议保留锁文件
# 配置文件(包含敏感信息)
.env
.env.local
.env.*.local
*.key
*.pem
secrets/
# Python 缓存
__pycache__/
*.pyc
.pytest_cache/
.mypy_cache/
.ruff_cache/
# IDE
.vscode/
.idea/
*.swp建议 :
poetry.lock应当提交到版本控制系统,以确保所有环境依赖一致。上述.gitignore仅为示例,如需要可移除poetry.lock行。
2.6.3 使用 Pydantic Settings 管理配置(详细指南)
pydantic-settings 是 Pydantic 官方提供的配置管理库,它结合了类型注解、环境变量加载、.env 文件支持、数据验证等功能。
(1)编写核心配置模块
在src/my_ai_service/下创建 core 文件夹,在 core 文件夹中创建 config.py文件,并在文件中编写以下完整代码:
python
# src/my_project/core/config.py
from typing import Optional, List
from pydantic import Field, SecretStr, field_validator
from pydantic_settings import BaseSettings, SettingsConfigDict
class Settings(BaseSettings):
"""应用配置类,自动从环境变量和 .env 文件加载。
加载顺序(后者覆盖前者):
1. .env 文件中定义的值
2. 系统环境变量
3. 类属性中定义的默认值
"""
# 配置模型行为
model_config = SettingsConfigDict(
env_file=".env", # 默认加载的 .env 文件路径
env_file_encoding="utf-8", # 文件编码
case_sensitive=False, # 环境变量名不区分大小写
extra="ignore", # 忽略未定义的额外环境变量
validate_default=True, # 校验默认值
)
# ---------- 基础应用配置 ----------
app_name: str = Field(
default="AI Assistant",
alias="APP_NAME",
description="应用名称"
)
debug: bool = Field(
default=False,
alias="DEBUG",
description="是否开启调试模式,生产环境务必为 False"
)
secret_key: SecretStr = Field(
default=...,
alias="SECRET_KEY",
description="应用签名密钥,必须设置"
)
# ---------- API 服务配置 ----------
api_host: str = Field(
default="0.0.0.0",
alias="API_HOST"
)
api_port: int = Field(
default=8000,
alias="API_PORT",
ge=1, le=65535
)
allowed_origins: List[str] = Field(
default=["http://localhost:3000"],
alias="ALLOWED_ORIGINS",
description="CORS 允许的源,逗号分隔"
)
# ---------- 数据库配置 ----------
database_url: Optional[str] = Field(
default=None,
alias="DATABASE_URL"
)
db_pool_size: int = Field(
default=10,
alias="DB_POOL_SIZE",
ge=1
)
# ---------- AI 模型配置 ----------
openai_api_key: SecretStr = Field(
default=...,
alias="OPENAI_API_KEY"
)
openai_base_url: str = Field(
default="https://api.openai.com/v1",
alias="OPENAI_BASE_URL"
)
default_model: str = Field(
default="gpt-4",
alias="DEFAULT_MODEL"
)
max_tokens: int = Field(
default=1024,
alias="MAX_TOKENS",
ge=1
)
temperature: float = Field(
default=0.7,
alias="TEMPERATURE",
ge=0.0, le=2.0
)
max_retries: int = Field(
default=3,
alias="MAX_RETRIES",
ge=0
)
# ---------- 自定义校验 ----------
@field_validator("allowed_origins", mode="before")
@classmethod
def parse_origins(cls, v):
if isinstance(v, str):
return [origin.strip() for origin in v.split(",") if origin.strip()]
return v
@field_validator("database_url")
@classmethod
def validate_database_url(cls, v):
if v is not None and not v.startswith("postgresql://"):
raise ValueError("DATABASE_URL 必须以 postgresql:// 开头")
return v
def model_post_init(self, __context):
"""配置加载后自动执行"""
if self.debug:
print("⚠️ 调试模式已开启,生产环境请关闭 DEBUG")
# 创建全局单例配置实例,供整个应用导入
settings = Settings()使用如下的命令下载:
python
# 打开终端,确保你已经激活了 Poetry 的虚拟环境。
# 运行安装命令并确认安装成功:
poetry add pydantic-settings
# poetry show | grep pydantic-settings
poetry show | grep pydantic-settings下载完成后输出如下的内容:
python
tianpeng@DESKTOP-4L1UF5S:~/my-ai-service$ poetry show | grep pydantic-settings
pydantic-settings 2.14.1 Settings management using Pydantic
tianpeng@DESKTOP-4L1UF5S:~/my-ai-service$ (2)创建环境变量文件
在项目根目录下创建**.env** 文件(开发环境,不提交):
python
APP_NAME=AI助手开发版
DEBUG=true
SECRET_KEY=dev-secret-key-32char
API_PORT=8001
ALLOWED_ORIGINS=http://localhost:3000,http://localhost:8080
DATABASE_URL=postgresql://dev_user:dev_pass@localhost:5432/ai_dev
OPENAI_API_KEY=sk-proj-example
OPENAI_BASE_URL=https://api.deepseek.com/v1
DEFAULT_MODEL=deepseek-chat
MAX_TOKENS=2048
TEMPERATURE=0.8在跟目录下创建**.env.example** 文件(提交到 Git):
python
# .env.example - 复制为 .env 并填入真实值
APP_NAME=AI Assistant
DEBUG=false
SECRET_KEY=change-this-to-strong-secret-key
API_HOST=0.0.0.0
API_PORT=8000
ALLOWED_ORIGINS=http://localhost:3000
DATABASE_URL=postgresql://user:password@host:5432/dbname
OPENAI_API_KEY=your-openai-api-key
OPENAI_BASE_URL=https://api.openai.com/v1
DEFAULT_MODEL=gpt-4
MAX_TOKENS=1024
TEMPERATURE=0.7
MAX_RETRIES=3(3) 多环境支持(开发/测试/生产)
通过 ENV_STATE 环境变量加载不同的配置文件。在 config.py 中增加以下方法:
python
# 在 Settings 类中添加
@classmethod
def load(cls):
"""根据 ENV_STATE 加载不同环境的覆盖配置"""
env_state = os.getenv("ENV_STATE", "development")
env_file = f".env.{env_state}"
if os.path.exists(env_file):
return cls(_env_file=env_file)
return cls()然后创建对应的环境文件:
-
.env.development(开发) -
.env.test(测试) -
.env.production(生产)
启动时通过 export ENV_STATE=production 切换。
2.6.4 在代码中使用配置(最佳实践)
(1)直接导入全局实例
python
# src/my_project/main.py
from my_project.core.config import settings
def main():
print(f"启动 {settings.app_name} 于 {settings.api_host}:{settings.api_port}")
if settings.debug:
print("调试模式开启")
# 使用敏感配置时调用 .get_secret_value()
api_key = settings.openai_api_key.get_secret_value()
# ... 后续逻辑(2)依赖注入(FastAPI 示例)
python
from fastapi import Depends
from my_project.core.config import Settings, settings as global_settings
def get_settings() -> Settings:
return global_settings
@app.get("/config")
def read_config(settings: Settings = Depends(get_settings)):
return {"app_name": settings.app_name, "debug": settings.debug}(3)单元测试中覆写配置
python
# tests/test_config.py
from my_project.core.config import Settings
def test_override():
test_settings = Settings(DEBUG=True, APP_NAME="TestApp")
assert test_settings.debug == True2.6.5 安全加强与运维提示
| 安全措施 | 说明 |
|---|---|
| 文件权限 | chmod 600 .env,仅当前用户可读写 |
| 密钥轮换 | 敏感配置定期更换,使用 SecretStr 保护 |
| 配置校验 | field_validator 提前发现错误 |
| 禁止日志输出配置 | 避免打印 SecretStr 值 |
| 使用配置中心(生产级) | 大型系统建议 HashiCorp Vault / AWS Secrets Manager |
| 容器环境 | Docker/K8s 直接使用环境变量注入,不挂载 .env 文件 |
2.6.6 常见配置错误与解决方案
| 错误现象 | 可能原因 | 解决办法 |
|---|---|---|
ValidationError: field required |
未设置必需的环境变量 | 检查 .env 或系统环境 |
| 配置值始终使用默认值 | 环境变量名与 alias 不匹配 |
确认 alias 正确或开启大小写敏感 |
.env 未生效 |
路径错误或未自动加载 | 显式传递 _env_file='.env' |
| 敏感信息出现在日志中 | 未使用 SecretStr |
改为 SecretStr 类型 |
| 多环境配置混乱 | 共用同一 .env |
使用 ENV_STATE 分离文件 |
2.6.7 总结与推荐实践
-
项目结构:严格按照上述文件夹结构组织,确保配置模块独立。
-
依赖管理 :使用
poetry init初始化,poetry add添加依赖。 -
配置类 :继承
BaseSettings,使用Field定义元数据,SecretStr保护敏感值。 -
文件安全 :
.env加入.gitignore,提交.env.example。 -
环境隔离 :通过
ENV_STATE或不同文件实现开发/测试/生产配置分离。 -
校验 :利用
field_validator和ge/le等约束提前捕获错误。 -
启动检查 :在
model_post_init中打印警告或必要检查。
遵循以上规范,配置管理将变得安全、可靠、易于维护。
2.7 日志记录规范
2.7.1 为什么需要规范的日志?
-
print()仅在开发时方便,无法区分日志级别 -
生产环境需要将日志写入文件、发送到日志中心
-
结构化日志便于检索和分析
2.7.2 Python logging 模块配置
python
# src/my_project/core/logging.py
import logging
import sys
from pathlib import Path
def setup_logging(log_level: str = "INFO", log_file: str = None):
"""配置全局日志系统。
Args:
log_level: 日志级别 (DEBUG, INFO, WARNING, ERROR, CRITICAL)
log_file: 日志文件路径,为None时仅输出到控制台
"""
# 创建根日志器
logger = logging.getLogger()
logger.setLevel(getattr(logging, log_level.upper()))
# 日志格式
formatter = logging.Formatter(
fmt="%(asctime)s | %(levelname)-8s | %(name)s:%(lineno)d | %(message)s",
datefmt="%Y-%m-%d %H:%M:%S"
)
# 控制台处理器
console_handler = logging.StreamHandler(sys.stdout)
console_handler.setFormatter(formatter)
logger.addHandler(console_handler)
# 文件处理器(可选)
if log_file:
log_path = Path(log_file)
log_path.parent.mkdir(parents=True, exist_ok=True)
file_handler = logging.FileHandler(log_file, encoding="utf-8")
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
# 降低第三方库的日志噪音
logging.getLogger("httpx").setLevel(logging.WARNING)
logging.getLogger("openai").setLevel(logging.WARNING)
return logger
# 获取模块级日志器(推荐用法)
logger = logging.getLogger(__name__)使用示例:
python
from my_project.core.logging import setup_logging, logger
# 在程序入口调用一次
setup_logging(log_level="INFO", log_file="logs/app.log")
def some_function():
logger.debug("这是调试信息,默认不显示")
logger.info("用户请求了模型调用")
logger.warning("API响应时间超过预期")
logger.error("调用失败,正在重试...")2.7.3 结构化日志(JSON 格式)
在微服务架构中,常使用 JSON 格式日志便于日志平台(如 ELK)解析:
python
import json_logging
# 配置JSON格式日志,此处省略,可按需学习2.8 单元测试规范
2.8.1 测试的重要性
-
确保代码修改不会破坏已有功能
-
测试本身就是一份代码行为文档
-
提高重构信心,降低生产事故风险
2.8.2 pytest 框架基础
pytest 是 Python 最流行的测试框架,简洁强大。
python
# tests/test_ai_service.py
import pytest
from unittest.mock import patch, MagicMock
from my_project.services.ai_service import AIService
from my_project.core.config import Settings
class TestAIService:
"""AIService类的单元测试"""
@pytest.fixture
def ai_service(self):
"""测试夹具:提供一个配置好的AIService实例"""
settings = Settings(
openai_api_key="test-key",
openai_base_url="https://test.api.com"
)
return AIService(settings)
def test_initialization(self, ai_service):
"""测试服务初始化"""
assert ai_service.api_key == "test-key"
assert ai_service.base_url == "https://test.api.com"
@patch("my_project.services.ai_service.OpenAI")
def test_call_llm_success(self, mock_openai, ai_service):
"""测试正常调用大模型"""
# 模拟API响应
mock_client = MagicMock()
mock_openai.return_value = mock_client
mock_client.chat.completions.create.return_value.choices = [
MagicMock(message=MagicMock(content="测试回复"))
]
response = ai_service.call_llm("测试问题")
assert response == "测试回复"
mock_client.chat.completions.create.assert_called_once()
def test_invalid_temperature(self, ai_service):
"""测试无效temperature参数"""
with pytest.raises(ValueError, match="temperature必须在0.0到2.0之间"):
ai_service.call_llm("test", temperature=3.0)运行测试:
python
poetry run pytest tests/ -v2.8.3 测试覆盖率
python
poetry add --group dev pytest-cov
poetry run pytest --cov=src/my_project tests/ --cov-report=html2.9 版本控制规范
2.9.1 Git 提交信息规范
采用 Conventional Commits 规范,提交信息格式:
python
<type>(<scope>): <subject>
[optional body]
[optional footer]常用 type:
-
feat: 新功能 -
fix: Bug 修复 -
docs: 文档更新 -
style: 代码格式(不影响功能) -
refactor: 重构 -
test: 测试相关 -
chore: 构建/工具链更新
示例:
python
feat(ai_service): 添加流式输出支持
- 实现stream参数处理
- 添加生成器函数yield逐块返回
Closes #422.9.2 .gitignore 模板
python
# Python
__pycache__/
*.py[cod]
*.so
.Python
env/
venv/
.env
.venv
*.egg-info/
dist/
build/
# IDE
.vscode/
.idea/
# 测试
.pytest_cache/
.coverage
htmlcov/
# 日志
logs/
*.log
# 本地配置
.env
.env.local2.10 完整实践案例:规范化 AI 问答服务
下面我们运用所学规范,构建一个简单的 AI 问答命令行工具。
2.10.1 项目初始化
python
poetry new --src ai-qa-cli
cd ai-qa-cli
poetry add openai pydantic-settings python-dotenv
poetry add --group dev black ruff mypy pytest pytest-cov pre-commit2.12.2 项目结构调整
按规范创建以下文件结构:
python
ai-qa-cli/
├── src/
│ └── ai_qa_cli/
│ ├── __init__.py
│ ├── main.py
│ ├── core/
│ │ ├── __init__.py
│ │ ├── config.py
│ │ └── logging.py
│ └── services/
│ ├── __init__.py
│ └── ai_service.py
├── tests/
│ ├── __init__.py
│ └── test_ai_service.py
├── .env.example
├── .gitignore
├── .pre-commit-config.yaml
├── pyproject.toml
└── README.md2.10.3 核心代码实现
src/ai_qa_cli/core/config.py:
python
"""配置管理模块。"""
from pydantic_settings import BaseSettings, SettingsConfigDict
class Settings(BaseSettings):
"""应用配置,从.env文件和环境变量加载。"""
model_config = SettingsConfigDict(
env_file=".env",
env_file_encoding="utf-8",
extra="ignore"
)
# API配置
openai_api_key: str
openai_base_url: str = "https://api.deepseek.com"
default_model: str = "deepseek-chat"
# 应用配置
app_name: str = "AI问答工具"
debug: bool = False
max_tokens: int = 2048
temperature: float = 0.7
settings = Settings()src/ai_qa_cli/core/logging.py:
python
"""日志配置模块。"""
import logging
import sys
def setup_logging(debug: bool = False) -> None:
"""配置全局日志。
Args:
debug: 是否开启调试模式。
"""
level = logging.DEBUG if debug else logging.INFO
logging.basicConfig(
level=level,
format="%(asctime)s | %(levelname)-8s | %(name)s | %(message)s",
datefmt="%H:%M:%S",
stream=sys.stdout
)
# 降低第三方库日志噪音
logging.getLogger("httpx").setLevel(logging.WARNING)
logging.getLogger("openai").setLevel(logging.WARNING)src/ai_qa_cli/services/ai_service.py:
python
"""AI大模型调用服务模块。"""
import logging
from typing import Optional
from openai import OpenAI
from ai_qa_cli.core.config import settings
logger = logging.getLogger(__name__)
class AIService:
"""AI服务类,封装大模型API调用。"""
def __init__(self) -> None:
"""初始化AI服务客户端。"""
self.client = OpenAI(
api_key=settings.openai_api_key,
base_url=settings.openai_base_url
)
self.model = settings.default_model
logger.info("AI服务初始化完成,模型:%s", self.model)
def ask(
self,
question: str,
temperature: Optional[float] = None,
max_tokens: Optional[int] = None
) -> str:
"""向大模型提问并获取回答。
Args:
question: 用户问题。
temperature: 采样温度,范围0.0-2.0。
max_tokens: 最大生成token数。
Returns:
模型的回答文本。
Raises:
ValueError: 参数不合法时抛出。
"""
temp = temperature if temperature is not None else settings.temperature
if not 0.0 <= temp <= 2.0:
raise ValueError(f"temperature必须在0.0-2.0之间,当前值:{temp}")
max_tok = max_tokens if max_tokens is not None else settings.max_tokens
logger.info("收到问题:%s", question[:50] + "..." if len(question) > 50 else question)
try:
response = self.client.chat.completions.create(
model=self.model,
messages=[{"role": "user", "content": question}],
temperature=temp,
max_tokens=max_tok
)
answer = response.choices[0].message.content
logger.info("成功获取回答,消耗tokens:%d", response.usage.total_tokens)
return answer
except Exception as e:
logger.error("API调用失败:%s", str(e))
raisesrc/ai_qa_cli/main.py:
python
"""程序入口模块。"""
import sys
import logging
from ai_qa_cli.core.config import settings
from ai_qa_cli.core.logging import setup_logging
from ai_qa_cli.services.ai_service import AIService
logger = logging.getLogger(__name__)
def main() -> None:
"""主函数。"""
# 配置日志
setup_logging(debug=settings.debug)
logger.info("%s 启动", settings.app_name)
# 初始化AI服务
try:
ai_service = AIService()
except Exception as e:
logger.error("初始化失败:%s", e)
sys.exit(1)
print(f"\n🤖 {settings.app_name}")
print("输入你的问题(输入 'quit' 退出)\n")
while True:
try:
question = input("💬 你:").strip()
if question.lower() in ("quit", "exit", "q"):
print("👋 再见!")
break
if not question:
continue
print("⏳ AI思考中...", end="", flush=True)
answer = ai_service.ask(question)
print(f"\r🤖 AI:{answer}\n")
except KeyboardInterrupt:
print("\n👋 再见!")
break
except Exception as e:
logger.error("运行出错:%s", e)
print(f"❌ 出错了:{e}\n")
if __name__ == "__main__":
main()2.10.4 单元测试
tests/test_ai_service.py:
python
"""AI服务模块单元测试。"""
import pytest
from unittest.mock import patch, MagicMock
from ai_qa_cli.services.ai_service import AIService
class TestAIService:
"""AIService测试类。"""
@patch("ai_qa_cli.services.ai_service.OpenAI")
def test_ask_success(self, mock_openai):
"""测试正常问答。"""
# 模拟API响应
mock_client = MagicMock()
mock_openai.return_value = mock_client
mock_choice = MagicMock()
mock_choice.message.content = "Python是一种编程语言"
mock_usage = MagicMock(total_tokens=50)
mock_client.chat.completions.create.return_value = MagicMock(
choices=[mock_choice],
usage=mock_usage
)
service = AIService()
answer = service.ask("什么是Python?")
assert answer == "Python是一种编程语言"
mock_client.chat.completions.create.assert_called_once()
@patch("ai_qa_cli.services.ai_service.OpenAI")
def test_ask_invalid_temperature(self, mock_openai):
"""测试无效temperature参数。"""
service = AIService()
with pytest.raises(ValueError, match="temperature必须在0.0到2.0之间"):
service.ask("测试", temperature=3.0)2.10.5 运行项目
(1)复制.env.example为.env,填入你的 API 密钥
(2)执行:
python
poetry install
poetry run python src/ai_qa_cli/main.py2.11 本章小结
2.11.1 知识点回顾
| 规范类别 | 核心内容 | 工具支撑 |
|---|---|---|
| 项目结构 | src-layout、包组织 | Poetry |
| 依赖管理 | 虚拟环境、版本锁定 | Poetry |
| 代码风格 | PEP 8、命名规范 | Black、Ruff、Pre-commit |
| 类型安全 | 类型注解、数据验证 | Pydantic、mypy |
| 文档 | 文档字符串 | Google 风格 |
| 配置管理 | 环境变量分离 | Pydantic Settings |
| 日志 | 分级日志、结构化 | logging 模块 |
| 测试 | 单元测试、覆盖率 | pytest |
| 版本控制 | 提交规范、。gitignore | Git |
2.11.2 从规范到习惯
规范的价值不在于死记硬背,而在于将其融入日常开发习惯。建议:
-
每次新建项目时,使用 Poetry 初始化,建立规范的目录结构
-
配置 pre-commit 钩子,让工具自动保证代码质量
-
写函数时先写文档字符串,再写实现
-
敏感信息一律走环境变量,
.env绝不提交
2.12 常见问题
| 问题 | 解决方案 |
|---|---|
| Poetry 安装后命令无法识别 | 将%APPDATA%\Python\Scripts(Windows)或~/.local/bin(Linux/macOS)添加到 PATH |
| Pre-commit 钩子未生效 | 确认已执行pre-commit install,检查.pre-commit-config.yaml语法 |
| Pydantic Settings 无法读取。env | 确保.env文件位于运行目录,或指定env_file绝对路径 |
| pytest 找不到模块 | 确保在项目根目录运行,或配置pythonpath |
规范是团队协作的润滑剂,也是代码长期可维护的保障。掌握本章内容,你的 Python 项目将具备企业级的专业水准。