概述
-
本项目以 RHCE核心知识点为基础,结合硅基流动开源大模型 API,构建一套自动化 Linux 运维文档生成系统。
-
系统可定时采集 Linux 服务器的核心运维数据(系统配置、资源状态、服务运行情况、故障日志等),通过硅基流动大模型自动生成结构化、符合 RHCE 规范的 Markdown 格式运维日报,同时支持文档自动备份,全程无需人工干预。
-
核心价值:替代人工编写运维文档,提升运维效率;融合 Linux 系统管理与 AI 文本生成技术,贴合企业 "运维 + AI" 的技术落地需求。
系统需求
-
功能需求:
① 自动采集 Linux 服务器基础信息、硬件资源、服务状态、故障日志等运维数据;
② 调用硅基流动 API,将采集数据转化为结构化 Markdown 运维日报;
③ 配置定时任务,每日自动执行数据采集、文档生成、远程备份;
④ 保障系统安全,实现密钥隔离、文件权限管控、SELinux 策略加固。
RHCE 核心知识点
- 本项目核心复用 RHCE 以下关键技能,是系统落地的基础:
| 知识点 | 应用场景 |
|---|---|
| Shell 脚本编程 | 编写运维数据采集脚本,实现命令输出格式化、特殊字符处理 |
| Cron 定时任务 | 配置每日自动执行的任务调度,实现无人值守运行 |
| 文件权限 / SELinux 管理 | 管控运维数据、文档、脚本的访问权限,加固系统安全 |
| Rsync 远程备份 | 将生成的运维文档备份至远程服务器,防止数据丢失 |
| 防火墙配置 | 开放硅基流动 API 的网络访问权限,限制非法请求 |
硅基流动大模型 API
-
硅基流动(SiliconFlow)是开源大模型一站式部署 / 调用平台,支持 Qwen-2、DeepSeek、Llama 3 等主流开源模型,其 API 兼容 OpenAI 接口格式,无需复杂开发即可快速集成。
-
核心优势:
-
7B/9B 量级模型永久免费,满足中小企业 / 个人使用需求;
-
中文优化效果好,对 Linux 运维术语(如 SELinux、firewalld)适配性强;
-
API 调用流程简单,兼容 OpenAI SDK,开发成本低。
-
项目流程
第 1 步:写 Shell 脚本 → 采集 Linux 服务器信息
作用 :自动收集服务器的所有运维数据
- 干什么:
- 采集 CPU、内存、磁盘、网络、进程、端口、日志等信息
- 把信息整理成标准格式(JSON)
- 方便后面 AI 读取
第 2 步:写 Python 脚本 → 调用 AI 生成文档
作用 :把机器数据 → 变成人类能看懂的专业运维文档
- 干什么:
- 读取上一步采集的 JSON 数据
- 发给 AI 大模型(硅基流动 / OpenAI)
- AI 自动生成清晰、规范的 Markdown 运维报告
第 3 步:写总调度脚本 、配置自动备份 → 把前面两步串起来
作用 :**一键运行整套流程。**把文档同步到另一台机器
- 干什么:
- 先运行采集脚本
- 再运行 AI 生成文档脚本
- 自动保存生成好的文档
- 用
rsync把生成的文档传到备份服务器 - 确保数据多份留存
第 4 步:配置定时任务 → 让系统每天自动跑
作用 :真正实现 "全自动"
- 干什么:
- 用
cron设置每天 / 每周自动执行 - 不用人管,系统自己采集、生成、备份
- 用
项目实施
环境搭建
-
安装2台虚拟机及RHEL9.3系统
-
关闭selinux
vim /etc/selinux/config
-
关闭防火墙
[root@localhost ~]# systemctl status firewalld
-
修改主机名
报告采集机(192.168.88.131):
[root@localhost ~]# hostnamectl set-hostname server
[root@localhost ~]# bash备份机(192.168.88.132):
[root@localhost ~]# hostnamectl set-hostname backup
[root@localhost ~]# bash -
报告采集机: 下载所需软件
[root@server ~]# yum install vim tar tree net-tools openssh -y
[root@server ~]# yum install -y python3 python3-pip jq rsync -y
[root@server ~]# pip install requests python-dotenv openai
-
项目目录创建
报告采集机(192.168.88.131)
[root@server ~]# mkdir -p /opt/ai_ops_doc/{scripts,data,docs,backup}
[root@server ~]# tree /opt/ai_ops_doc
/opt/ai_ops_doc
├── backup
├── data
├── docs
└── scripts -
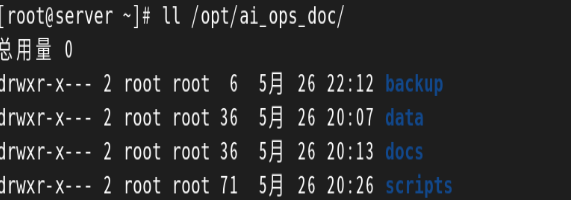
创建运维组并配置权限
[root@server ~]# groupadd ops
[root@server ~]# chown -R root:ops /opt/ai_ops_doc
[root@server ~]# chmod -R 750 /opt/ai_ops_doc
[root@server ~]# ll /opt/ai_ops_doc
报告备份机(192.168.88.132)
[root@backup ~]# mkdir /backup # 新建用于存储备份数据的目录-
报告采集机需要免密登录到备份机
定为报告采集机(192.168.88.131)
[root@server ~]# ssh-keygen -t rsa
一路回车
[root@server ~]# ssh-copy-id 192.168.88.132
第一次需要输入yes和132机子的root账户登录密码
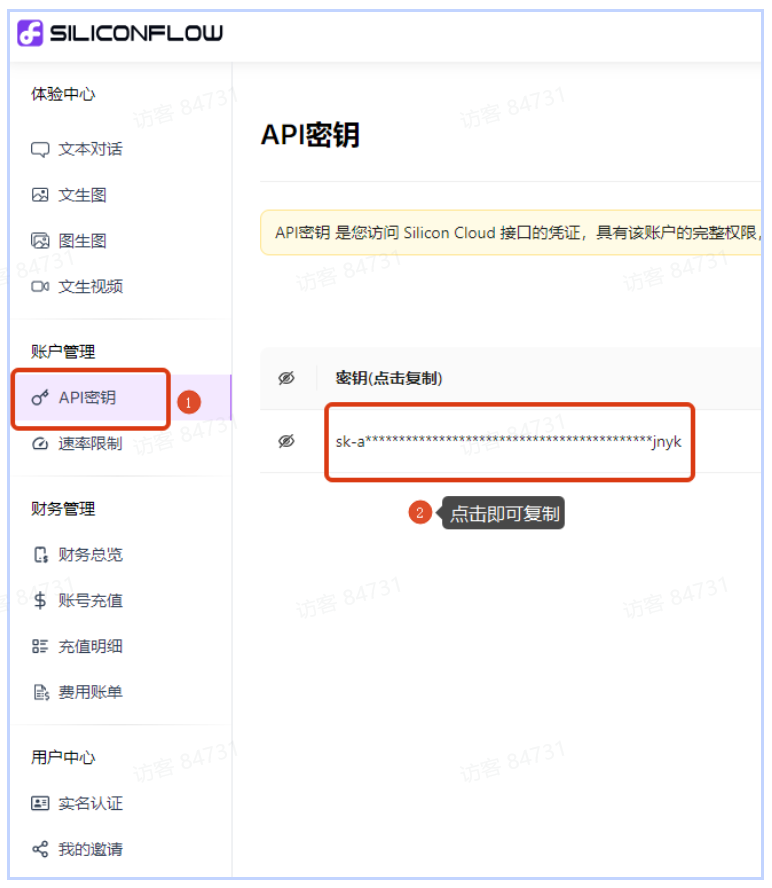
获取硅基流动 API Key
网址:
- 访问硅基流动官网(https://siliconflow.cn),手机号注册并完成实名认证
- 登录后进入 "API 密钥"→"新建 API 密钥",填写密钥名称并保存
配置环境变量存储密钥(避免硬编码)
[root@server ~]# echo "SILICONFLOW_API_KEY=你的硅基流动API密钥" > ~/.env
[root@server ~]# chmod 600 ~/.env # 仅当前用户可读
[root@server ~]# cat .env
OPENAI_API_KEY=sk-tcycgun.......xowmzacaaxpppzqkyiuppu第一步、编写 Shell 数据采集脚本
创建/opt/ai_ops_doc/scripts/collect_data.sh,实现运维数据采集与 JSON 格式化:
[root@server ~]# vim /opt/ai_ops_doc/scripts/collect_data.sh
#!/bin/bash
set -e # 遇到错误立即退出
DATA_DIR="/opt/ai_ops_doc/data"
DATA_FILE="${DATA_DIR}/ops_data_$(date +%Y%m%d).json"
# 确保数据目录存在
mkdir -p ${DATA_DIR}
# 安全采集函数:处理特殊字符与空值
safe_collect() {
local cmd="$1"
output=$(eval $cmd 2>/dev/null || echo "")
# 处理转义换行、制表符、双引号等特殊字符
echo "$output" | sed -e 's/\n/ /g' -e 's/\t/ /g' -e 's/"/\\"/g' -e 's/ */ /g' | xargs
}
# 生成合法JSON文件
cat > ${DATA_FILE} << EOF
{
"采集时间": "$(date +'%Y-%m-%d %H:%M:%S')",
"系统版本": "$(safe_collect 'cat /etc/redhat-release')",
"内核版本": "$(safe_collect 'uname -r')",
"主机名": "$(safe_collect 'hostname')",
"磁盘使用情况": "$(safe_collect 'df -h | grep -v tmpfs | grep -v loop')",
"内存使用情况": "$(safe_collect 'free -h')",
"CPU负载": "$(safe_collect 'uptime | awk "{print \$8,\$9,\$10}"')",
"关键服务状态": "$(safe_collect 'systemctl list-units --type=service --state=running | grep -E "sshd|httpd|nginx|firewalld|crond"')",
"防火墙规则": "$(safe_collect 'firewall-cmd --list-all --zone=public')",
"近24小时故障日志": "$(safe_collect 'journalctl --since "24 hours ago" --priority=err | head -20')"
}
EOF
# 权限配置
chmod 640 ${DATA_FILE}
chown root:ops ${DATA_FILE}
# 验证JSON格式
if jq . ${DATA_FILE} &>/dev/null; then
echo "JSON数据采集成功:${DATA_FILE}"
else
echo "JSON格式错误,文件内容:"
cat ${DATA_FILE}
exit 1
fi-
执行
[root@server ~]# chmod 750 /opt/ai_ops_doc/scripts/collect_data.sh
[root@server ~]# bash /opt/ai_ops_doc/scripts/collect_data.sh
JSON数据采集成功:/opt/ai_ops_doc/data/ops_data_20260126.json -
查看采集内容
[root@server ~]# cat /opt/ai_ops_doc/data/ops_data_20260126.json
{
"采集时间": "2026-01-26 14:12:39",
"系统版本": "Red Hat Enterprise Linux release 9.3 (Plow)",
"内核版本": "5.14.0-362.8.1.el9_3.x86_64",
"主机名": "server",
"磁盘使用情况": "文件系统 容量 已用 可用 已用% 挂载点 /dev/mapper/rhel-root 15G 6.1G 8.6G 42% / /dev/sda2 960M 260M 701M 27% /boot /dev/sda1 300M 7.0M 293M 3% /boot/efi /dev/sr0 9.9G 9.9G 0 100% /run/media/root/RHEL-9-3-0-BaseOS-x86_64",
"内存使用情况": "total used free shared buff/cache available Mem: 1.9Gi 1.1Gi 76Mi 15Mi 841Mi 752Mi Swap: 4.0Gi 677Mi 3.3Gi",
"CPU负载": "average: 0.00, 0.03,",
"关键服务状态": "crond.service loaded active running Command Scheduler firewalld.service loaded active running firewalld - dynamic firewall daemon sshd.service loaded active running OpenSSH server daemon",
"防火墙规则": "public (active) target: default icmp-block-inversion: no interfaces: ens160 sources: services: cockpit dhcpv6-client ssh ports: protocols: forward: yes masquerade: no forward-ports: source-ports: icmp-blocks: rich rules:",
"近24小时故障日志": ......
}
第二步、编写 Python AI 文档生成脚本
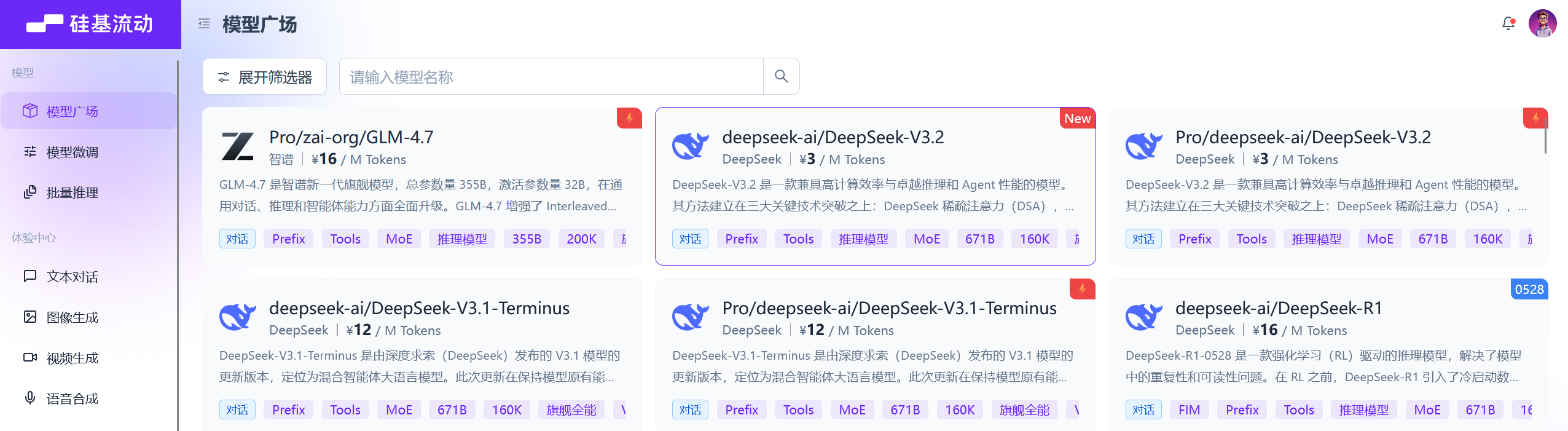
在硅基流动网站选择合适的模型
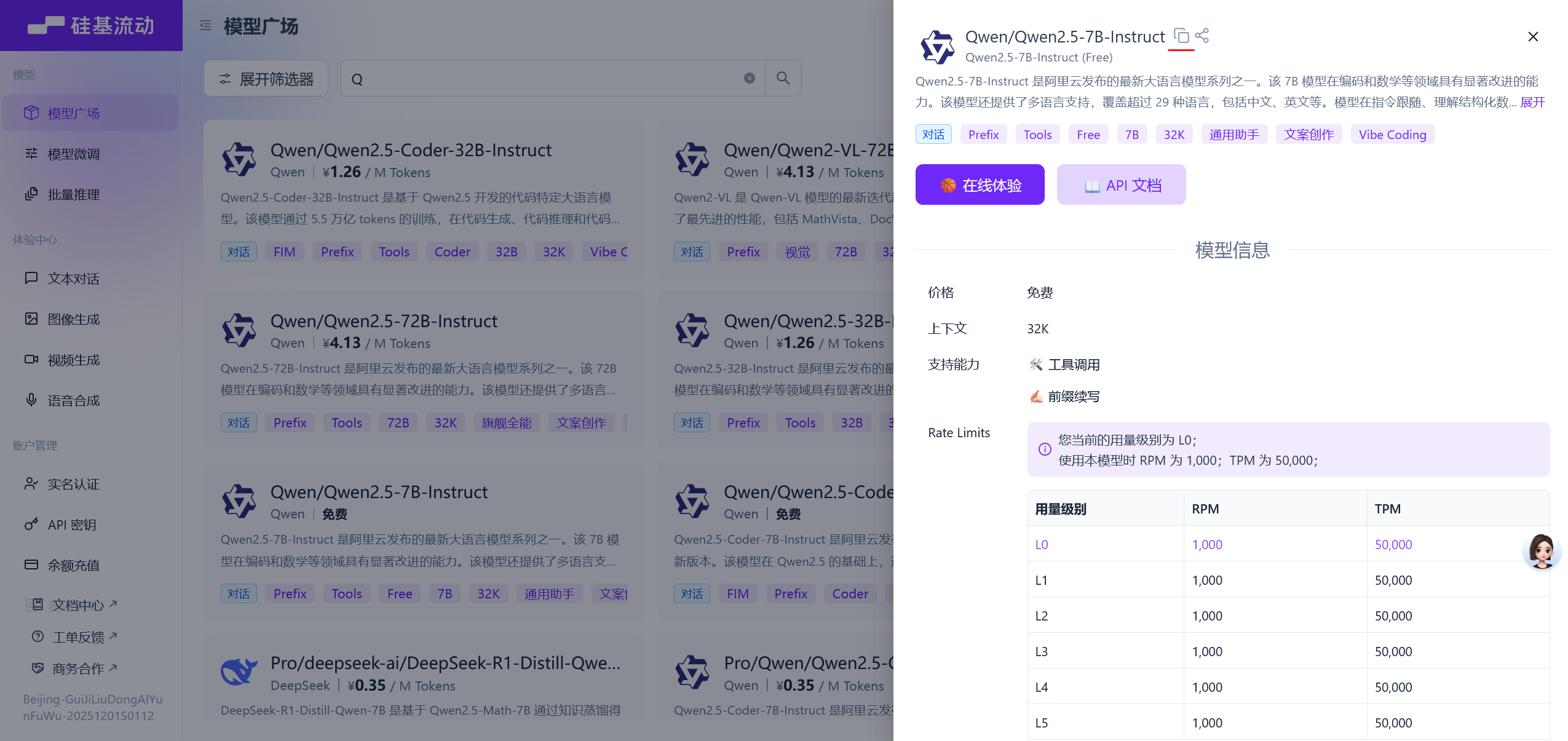
-
创建
/opt/ai_ops_doc/scripts/generate_doc.py,调用硅基流动 API 生成运维文档:[root@server ~]# vim /opt/ai_ops_doc/scripts/generate_doc.py
import os
import json
import grp
from dotenv import load_dotenv
from datetime import datetime
from openai import OpenAI加载硅基流动配置
load_dotenv("/root/.env")
SILICONFLOW_API_KEY = os.getenv("SILICONFLOW_API_KEY")
SILICONFLOW_BASE_URL = "https://api.siliconflow.cn/v1"
MODEL_NAME = "deepseek-ai/DeepSeek-R1"def load_ops_data():
"""加载运维数据"""
data_date = datetime.now().strftime("%Y%m%d")
data_file = f"/opt/ai_ops_doc/data/ops_data_{data_date}.json"if not os.path.exists(data_file): return {"error": f"数据文件不存在:{data_file}"} if os.path.getsize(data_file) == 0: return {"error": "数据文件为空,请重新执行采集脚本"} try: with open(data_file, "r", encoding="utf-8") as f: return json.load(f) except json.JSONDecodeError as e: return {"error": f"JSON解析失败:{str(e)}"} except Exception as e: return {"error": f"读取文件失败:{str(e)}"}def generate_prompt(ops_data):
"""生RHCE运维日报提示词"""
if "error" in ops_data:
prompt = f"""请以资深RHCE工程师身份,根据以下错误信息生成故障排查文档(Markdown格式)。要求内容专业严谨、语言简洁规范,除必要Linux命令外均用中文,包含"错误描述""原因分析""具体解决过程""验证方法"四部分,解决过程步骤清晰、符合RHCE运维逻辑,可直接落地执行。错误内容:{ops_data['error']}"""
else:
prompt = f"""请以资深RHCE工程师身份,基于以下Linux服务器采集数据,生成一份结构化运维日报,格式为Markdown。要求内容专业严谨、语言简洁规范,除必要的Linux命令外,其余表述全部使用中文,问题分析需附带具体解决过程,完全贴合企业RHCE运维标准。核心要求
1. 文档结构
严格包含五大模块,顺序不可调整:
- 标题:格式为"Linux服务器运维日报 - 采集日期"(采集日期取自数据中的"采集时间"字段);
- 采集信息:汇总服务器基础信息(主机名、系统版本、内核版本)及采集时间,清晰罗列;
- 系统状态总结:整体评估服务器运行状态(正常/存在风险/异常),概括核心资源(磁盘、内存、CPU)占用情况及关键服务运行状态;
- 问题分析:从故障日志及资源状态中提取所有关键问题,每个问题需包含"问题描述""风险等级"(低/中/高)"具体解决过程"三部分,解决过程需步骤清晰、可落地,符合RHCE运维逻辑;
- 优化建议:基于RHCE规范,针对服务器当前状态给出可执行建议,覆盖磁盘清理、服务调优、防火墙规则优化、安全加固等维度,建议需对应实际场景,不空洞。
2. 问题分析细则
- 风险等级判定标准:高风险(影响业务运行、服务器稳定性,需立即处理)、中风险(不影响核心业务,但存在潜在隐患,需24小时内处理)、低风险(仅为优化项,不影响服务器运行,可定期处理);
- 解决过程需包含"问题定位步骤→操作命令→验证方法",命令需标注用途,操作逻辑符合RHCE故障排查流程(如先排查日志、再定位原因、最后执行修复并验证)。
3. 内容规范
语言简洁无冗余,避免口语化表述,专业术语使用准确(如"防火墙"统一指firewalld,"SELinux"不简写),Markdown格式排版整齐(标题层级分明、列表有序,关键信息可加粗)。
服务器采集数据
{json.dumps(ops_data, ensure_ascii=False, indent=2)}"""
return promptdef call_siliconflow_api(prompt):
"""调用硅基流动API"""
try:
client = OpenAI(
api_key=SILICONFLOW_API_KEY,
base_url=SILICONFLOW_BASE_URL
)
response = client.chat.completions.create(
model=MODEL_NAME,
messages=[{"role": "user", "content": prompt}],
temperature=0.3,
max_tokens=2000
)
return response.choices[0].message.content
except Exception as e:
return f"API调用失败:{str(e)}"def save_doc(content):
"""保存Markdown文档(修复组GID获取逻辑)"""
doc_date = datetime.now().strftime("%Y%m%d")
doc_file = f"/opt/ai_ops_doc/docs/ops_report_{doc_date}.md"# 写入文档内容 with open(doc_file, "w", encoding="utf-8") as f: f.write(content) # 设置文件权限(只读给组,仅root可写) os.chmod(doc_file, 0o640) # 修复:获取ops组GID(增加容错) try: # 使用grp模块获取组信息(标准方法) ops_gid = grp.getgrnam("ops").gr_gid except KeyError: # 若ops组不存在,默认使用root组(GID=0) ops_gid = 0 print(f"警告:未找到ops组,文档文件将归属root组(GID=0)") # 设置文件属主和属组(root:ops 或 root:root) os.chown(doc_file, 0, ops_gid) return doc_fileif name == "main":
ops_data = load_ops_data()
prompt = generate_prompt(ops_data)
doc_content = call_siliconflow_api(prompt)
doc_path = save_doc(doc_content)
print(f"文档生成成功:{doc_path}")
print(f"文档预览:{doc_content[:100]}...") -
执行结果
[root@server ~]# python3 /opt/ai_ops_doc/scripts/generate_doc.py
文档生成成功:/opt/ai_ops_doc/docs/ops_report_20260126.md
文档预览:```markdownLinux服务器运维日报 - 2026-01-26
采集信息
- 采集时间: 2026-01-26 14:12:39
- 系统版本: Red Hat...
-
查看AI反馈的日报结果和运维建议
[root@server docs]# cat /opt/ai_ops_doc/docs/ops_report_20260126.md
markdown# Linux服务器运维日报 - 2026-01-26 ## 采集信息 - **采集时间**: 2026-01-26 14:12:39 - **系统版本**: Red Hat Enterprise Linux release 9.3 (Plow) - **内核版本**: 5.14.0-362.8.1.el9_3.x86_64 - **主机名**: server - **磁盘使用情况**: ........................
第三步、编写自动化调度脚本
创建/opt/ai_ops_doc/scripts/auto_run.sh,整合采集、生成、备份逻辑:
[root@server ~]# vim /opt/ai_ops_doc/scripts/auto_run.sh
#!/bin/bash
# 日志文件
LOG_FILE="/var/log/ai_ops_doc.log"
# 远程备份配置(替换为实际服务器信息)
REMOTE_IP="192.168.88.132"
REMOTE_DIR="/backup/ops_docs"
# 日志函数
log() {
echo "[$(date +'%Y-%m-%d %H:%M:%S')] $1" >> ${LOG_FILE}
}
log "开始执行自动化任务"
# 1. 数据采集
if /opt/ai_ops_doc/scripts/collect_data.sh; then
log "数据采集成功"
else
log "数据采集失败"
exit 1
fi
# 2. 文档生成
if python3 /opt/ai_ops_doc/scripts/generate_doc.py; then
log "文档生成成功"
else
log "文档生成失败"
exit 1
fi
# 3. 远程备份
DOC_FILE="/opt/ai_ops_doc/docs/ops_report_$(date +%Y%m%d).md"
if [ -f ${DOC_FILE} ]; then
rsync -avz ${DOC_FILE} root@${REMOTE_IP}:${REMOTE_DIR} >> ${LOG_FILE} 2>&1
if [ $? -eq 0 ]; then
log "文档备份成功"
else
log "文档备份失败"
fi
else
log "备份失败:文档文件不存在"
fi
log "自动化任务执行完成"-
给予可执行权限
[root@server ~]# chmod +x /opt/ai_ops_doc/scripts/auto_run.sh
-
执行
[root@server ~]# bash /opt/ai_ops_doc/scripts/auto_run.sh
JSON数据采集成功:/opt/ai_ops_doc/data/ops_data_20260126.json
文档生成成功:/opt/ai_ops_doc/docs/ops_report_20260126.md
文档预览:```markdownLinux服务器运维日报 - 2026-01-26
采集信息
- 采集时间: 2026-01-26 15:16:40
- 系统版本: Red Hat...
查看日志
[root@server ~]# cat /var/log/ai_ops_doc.log
[2026-01-26 15:19:46] 开始执行自动化任务
[2026-01-26 15:19:46] 数据采集成功
[2026-01-26 15:20:07] 文档生成成功
sending incremental file list
ops_report_20260126.mdsent 2,293 bytes received 59 bytes 1,568.00 bytes/sec
total size is 4,199 speedup is 1.79
[2026-01-26 15:20:08] 文档备份成功
[2026-01-26 15:20:08] 自动化任务执行完成查看备份机的备份内容
[root@backup ~]# ls /backup
ops_docs
第四步、配置定时任务
-
配置 定时任务,每日凌晨 2 点执行:
[root@server ~]# crontab -e
添加以下内容
0 2 * * * /opt/ai_ops_doc/scripts/auto_run.sh >> /var/log/ai_ops_doc.log 2>&1
[root@server ~]# crontab -l
0 2 * * * /opt/ai_ops_doc/scripts/auto_run.sh >> /var/log/ai_ops_doc.log 2>&1[root@server ~]# tail -f /var/log/ai_ops_doc.log
项目测试
[root@server ~]# tree /opt/
/opt/
└── ai_ops_doc
├── backup
├── data
│ └── ops_data_20260126.json
├── docs
│ └── ops_report_20260126.md
└── scripts
├── auto_run.sh
├── collect_data.sh
└── generate_doc.py
5 directories, 5 files