目录
[1 · 栈](#1 · 栈)
[1 - 1 · 栈的概念](#1 - 1 · 栈的概念)
[1 - 2 · 栈的结构](#1 - 2 · 栈的结构)
[1 - 3 · 栈的接口实现](#1 - 3 · 栈的接口实现)
[1 - 3 - 1 · 初始化](#1 - 3 - 1 · 初始化)
[1 - 3 - 2 · 销毁](#1 - 3 - 2 · 销毁)
[1 - 3 - 3 · 入栈](#1 - 3 - 3 · 入栈)
[1 - 3 - 4 · 出栈](#1 - 3 - 4 · 出栈)
[1 - 3 - 5 · 获取栈顶数据](#1 - 3 - 5 · 获取栈顶数据)
[1 - 3 - 6 · 判断栈是否空](#1 - 3 - 6 · 判断栈是否空)
[1 - 3 - 7 · 获取栈内有效元素个数](#1 - 3 - 7 · 获取栈内有效元素个数)
[1 - 3 - 8 · 简单测试](#1 - 3 - 8 · 简单测试)
[2 · 队列](#2 · 队列)
[2 - 1 · 队列的概念](#2 - 1 · 队列的概念)
[2 - 2 · 队列的结构](#2 - 2 · 队列的结构)
[2 - 3 · 队列的接口实现](#2 - 3 · 队列的接口实现)
[2 - 3 - 1 · 初始化](#2 - 3 - 1 · 初始化)
[2 - 3 - 2 · 销毁](#2 - 3 - 2 · 销毁)
[2 - 3 - 3 · 入队](#2 - 3 - 3 · 入队)
[2 - 3 - 4 · 出队](#2 - 3 - 4 · 出队)
[2 - 3 - 5 · 获取队列内有效元素个数](#2 - 3 - 5 · 获取队列内有效元素个数)
[2 - 3 - 6 · 获取队头元素](#2 - 3 - 6 · 获取队头元素)
[2 - 3 - 7 · 获取队尾元素](#2 - 3 - 7 · 获取队尾元素)
[2 - 3 - 8 · 判断队列是否为空](#2 - 3 - 8 · 判断队列是否为空)
[2 - 3 - 9 · 简单测试](#2 - 3 - 9 · 简单测试)
[3 · 循环队列](#3 · 循环队列)
[3 - 1 · 循环队列的概念](#3 - 1 · 循环队列的概念)
[3 - 2 · 循环队列的结构](#3 - 2 · 循环队列的结构)
[3 - 3 · 循环队列的实现](#3 - 3 · 循环队列的实现)
[4 · 用两个队列实现栈](#4 · 用两个队列实现栈)
[4 - 1 · 思路](#4 - 1 · 思路)
[4 - 2 · 代码实现](#4 - 2 · 代码实现)
[5 · 用两个栈实现队列](#5 · 用两个栈实现队列)
[5 - 1 · 思路](#5 - 1 · 思路)
[5 - 2 · 代码实现](#5 - 2 · 代码实现)
1 · 栈
1 - 1 · 栈的概念
栈是一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。
进行数据插入和删除操作的一端 **称为栈顶,另一端称为栈底。**栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则。
压栈:栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。
出栈:栈的删除操作叫做出栈。出数据也在栈顶。
这样看来,栈的结构其实与羽毛球筒是类似的。
我们画张图方便理解:
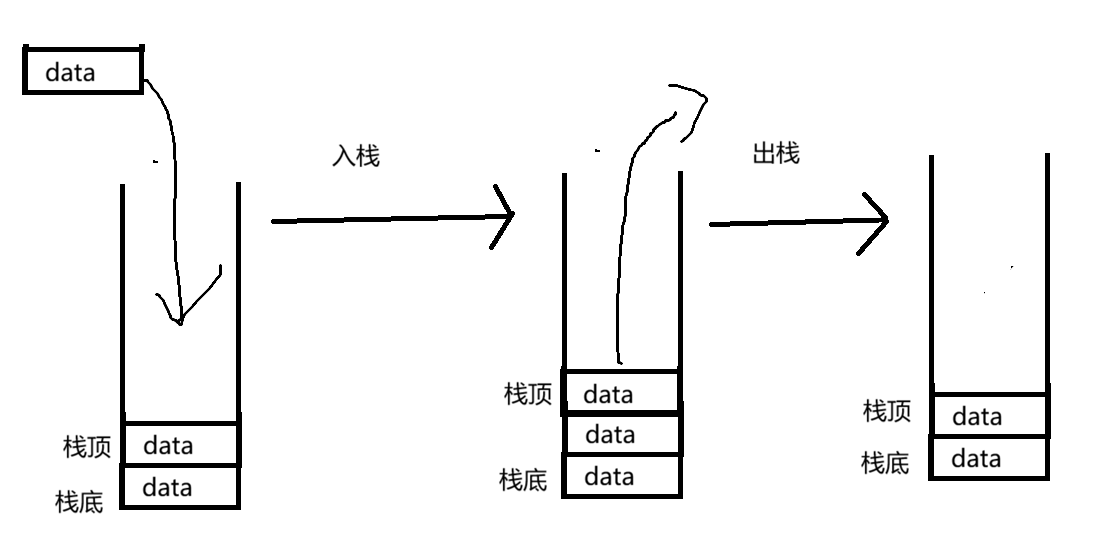
1 - 2 · 栈的结构
栈的实现一般可以使用数组或者链表实现,相对而言数组的结构实现更优一些。因为数组在尾上插入数据的代价比较小,并且缓存利用率高。
栈可分为静态栈与动态栈
静态栈的结构:
#define N 10
typedef int STDataType;
typedef struct Stack
{
STDataType _a[N];
int _top;//栈顶
}Stack;静态栈是定长的,在实际中一般不会使用。
因此本篇介绍的是动态栈,结构如下:
//动态栈
typedef int STDataType;
typedef struct Stack
{
STDataType* _a;
int _top; //栈顶
int _capacity;//容量
}Stack;1 - 3 · 栈的接口实现
1 - 3 - 1 · 初始化
代码如下:
void StackInit(Stack* ps)
{
assert(ps);
ps->_a = NULL;
ps->_capacity = 0;
//top指向栈顶的下一个位置
ps->_top = 0;
//top指向当前栈顶
//ps->_top = -1;
}对于栈顶 top 有两种给值方式:
一种是初始化为0,此时top就被认为是指向栈顶的下一个位置的下标。
另一种是初始化为-1,此时top就被认为指向的是栈顶元素的下标。
这两种初始化会导致后续代码有所差异,本文使用的 top 是指向栈顶的下一个位置。
1 - 3 - 2 · 销毁
代码如下:
void StackDestroy(Stack* ps)
{
assert(ps);
free(ps->_a);
ps->_a = NULL;
ps->_capacity = 0;
ps->_top = 0;
}类似于顺序表,将所开空间进行释放,然后置空与置0。
1 - 3 - 3 · 入栈
代码如下:
void StackPush(Stack* ps, STDataType x)
{
assert(ps);
//判断栈是否满
if (ps->_top == ps->_capacity)
{
//扩容
int newcapacity = ps->_capacity == 0 ? 4 : ps->_capacity * 2;
STDataType* ptr = (STDataType*)realloc(ps->_a, sizeof(STDataType) * newcapacity);
if (ptr == NULL)
{
perror("realloc");
exit(1);
}
ps->_a = ptr;
ps->_capacity = newcapacity;
}
//插入数据
ps->_a[ps->_top] = x;
++ps->_top;
}由于栈是一种受限的线性表,插入的方式只有一种。
先判断栈是否满,如果栈满就扩容,然后插入数据,与顺序表的尾插类似。
1 - 3 - 4 · 出栈
代码如下:
void StackPop(Stack* ps)
{
assert(ps);
//空栈不能删
assert(ps->_top > 0);
--ps->_top;
}由于栈是一种受限的线性表,删除的方式只有一种。
空栈不能删,可以用断言,也可以提前返回。
遵循后进先出的原则,类似于顺序表的尾删。
1 - 3 - 5 · 获取栈顶数据
代码如下:
STDataType StackTop(Stack* ps)
{
assert(ps);
//不能为空栈
assert(ps->_top > 0);
return ps->_a[ps->_top - 1];
}空栈自然取不到数据,可以用断言,也可以提前返回。
除去断言,其实我们这个接口只有一行代码,但是在使用时还是建议用接口而不是直接对栈的结构体用成员访问操作符,因为top可能是不同的,但接口是一定正确的。其余接口同理。
1 - 3 - 6 · 判断栈是否空
代码如下:
bool StackEmpty(Stack* ps)
{
assert(ps);
//if (ps->_top == 0)
//{
// return true;
//}
//else
//{
// return false;
//}
//更简单的写法
return ps->_top == 0;
}可以用 if......else,也有一种更简单的写法,通过top来判断。
1 - 3 - 7 · 获取栈内有效元素个数
代码如下:
int StackSize(Stack* ps)
{
assert(ps);
return ps->_top;
}这个简单,不过多赘述。
1 - 3 - 8 · 简单测试
我们测试一下:
#include "Stack.h"
int main()
{
Stack s;
StackInit(&s);
StackPush(&s, 1);
StackPush(&s, 2);
StackPush(&s, 3);
StackPush(&s, 4);
printf("共有%d个元素\n", StackSize(&s));
//访问栈
while (!StackEmpty(&s))
{
printf("%d ", StackTop(&s));
StackPop(&s);
}
StackDestroy(&s);
return 0;
}运行一下:

2 · 队列
2 - 1 · 队列的概念
队列是只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表。
队列具有先进先出FIFO(First In First Out) 的原则
入队:进行插入操作的一端称为队尾
出队:进行删除操作的一端称为队头
方便理解,我们画张图
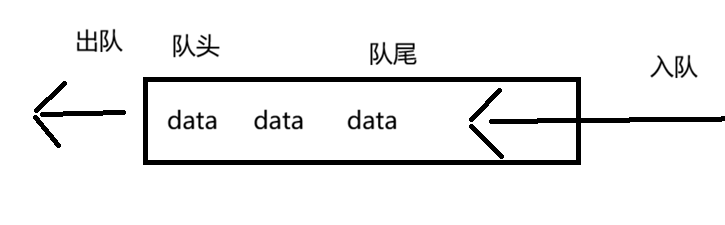
2 - 2 · 队列的结构
队列遵循先进先出的原则,那么就类似于尾插和头删,那么使用顺序结构,显然是很难做好的,避免不了要移动数据,从而有较大的消耗。
所以对队列的实现,我们选择链式结构。
那么应该选择单链表还是双向链表呢?其实不难发现,双向链表无论怎样都是要比单链表方便的,但是我们其实应该优先考虑一下单链表能否实现。
原因也很简单,单链表省内存。
下面我们用单链表来实现:
结构定义如下:
typedef int QDataType;
typedef struct QueueNode
{
QDataType _val;
struct QueueNode* _next;
}QueueNode;但是这样写,我们接口的参数列表部分会很复杂,因为我们需要一个指向头结点的指针和一个指向尾结点的指针,并且代码中我们可能需要对这两个结点进行更改,比如当队列为空时入队。
这样的话我们入队的接口就应该这样声明:
void QueuePush(QueueNode** pphead, QueueNode** pptail, QDataType x);显然是很麻烦的,因此我们再多定义一个结构体:
typedef struct Queue
{
QueueNode* _phead;//头指针
QueueNode* _ptail;//尾指针
int _size;//元素个数,方便实现QueueSize接口
}Queue;那么我们的声明就可以这么写:
void QueuePush(Queue* pq, QDataType x);2 - 3 · 队列的接口实现
2 - 3 - 1 · 初始化
代码如下:
void QueueInit(Queue* pq)
{
assert(pq);
pq->_phead = NULL;
pq->_ptail = NULL;
pq->_size = 0;
}2 - 3 - 2 · 销毁
代码如下:
void QueueDestroy(Queue* pq)
{
assert(pq);
QueueNode* pcur = pq->_phead;
while (pcur)
{
QueueNode* next = pcur->_next;
free(pcur);
pcur = next;
}
pq->_phead = NULL;
pq->_ptail = NULL;
pq->_size = 0;
}类似于单链表销毁,遍历同时释放。
2 - 3 - 3 · 入队
代码如下:
void QueuePush(Queue* pq, QDataType x)
{
assert(pq);
QueueNode* newnode = (QueueNode*)malloc(sizeof(QueueNode));
if (newnode == NULL)
{
perror("malloc");
exit(1);
}
newnode->_next = NULL;
newnode->_val = x;
//尾插
if (pq->_phead == NULL)
{
pq->_phead = pq->_ptail = newnode;
}
else
{
pq->_ptail->_next = newnode;
pq->_ptail = newnode;
}
++pq->_size;
}新建结点,然后尾插,如果是空队列入队,要改变指向头结点的指针 和 指向尾结点的指针
2 - 3 - 4 · 出队
代码如下:
void QueuePop(Queue* pq)
{
assert(pq);
//空队不能出队
assert(pq->_size > 0);
//头删
//
//一个结点
if (pq->_phead->_next == NULL)
{
free(pq->_phead);
pq->_phead = pq->_ptail = NULL;
}
else//多个结点
{
QueueNode* next = pq->_phead->_next;
free(pq->_phead);
pq->_phead = next;
}
--pq->_size;
}类似于链表头删,需要注意的是,当出队出掉了队列中的最后一个元素,需要对尾指针进行修改。
2 - 3 - 5 · 获取队列内有效元素个数
代码如下:
int QueueSize(Queue* pq)
{
assert(pq);
return pq->_size;
}我们在 Queue 结构体中定义了成员变量 _size 就是为了方便实现这个接口。
2 - 3 - 6 · 获取队头元素
代码如下:
QDataType QueueFront(Queue* pq)
{
assert(pq);
//队列为空不能取
assert(pq->_phead);
return pq->_phead->_val;
}2 - 3 - 7 · 获取队尾元素
代码如下:
QDataType QueueBack(Queue* pq)
{
assert(pq);
//对尾为空不能取
assert(pq->_ptail);
return pq->_ptail->_val;
}2 - 3 - 8 · 判断队列是否为空
代码如下:
bool QueueEmpty(Queue* pq)
{
assert(pq);
return pq->_size == 0;
}可以用 size 来判断,也可以用 指向头结点的指针 和 指向尾结点的指针 来判断。
2 - 3 - 9 · 简单测试
我们简单测试一下:
#include "Queue.h"
int main()
{
Queue q;
QueueInit(&q);
QueuePush(&q, 1);
QueuePush(&q, 2);
QueuePush(&q, 3);
QueuePush(&q, 4);
printf("队列中共有%d个\n", QueueSize(&q));
//访问队列
while (!QueueEmpty(&q))
{
printf("%d ", QueueFront(&q));
QueuePop(&q);
}
QueueDestroy(&q);
return 0;
}运行一下:

3 · 循环队列
3 - 1 · 循环队列的概念
循环队列是一种线性数据结构,他的空间大小是确定的
其操作表现基于 FIFO(先进先出)原则并且队尾被连接在队首之后以形成一个循环。
它也被称为"环形缓冲器"。
循环队列的一个好处是我们可以利用这个队列之前用过的空间。
在一个普通队列里,一旦一个队列满了,我们就不能插入下一个元素,即使在队列前面仍有空间。
但是使用循环队列,我们能使用这些空间去存储新的值。
我们画张图方便理解:
3 - 2 · 循环队列的结构
虽然前文中我们提到了用顺序结构很难实现队列,但是对于循环队列其实是可以使用顺序存储的。
当然,毕竟是循环队列,我们肯定要让他能够循环。
对于链式存储,我们可以用循环链表。
对于顺序存储,我们可以用模运算来循环。
都是可行的,下面我将用顺序存储来实现。
但是还有一个问题需要解决:对于循环队列判空,和判满。
简单画图可以得知,循环队列判空的条件是 队头与队尾指向同一个,判满的条件同样是 队头和队尾指向同一个,这就造成了假溢出。
解决方法有二:
-
结构体中新增一个 size成员来记录队列中元素个数。
-
开空间时额外多开一个空间,整体使用时少使用一个空间。
我们下面的实现将使用第一种解决方法。
3 - 3 · 循环队列的实现
一共包含以下接口:
//构造器,设置队列长度为 k 。
MyCircularQueue(k)
//从队首获取元素。如果队列为空,返回 - 1 。
Front
//获取队尾元素。如果队列为空,返回 - 1 。
Rear
//向循环队列插入一个元素。如果成功插入则返回真。
enQueue(value)
//从循环队列中删除一个元素。如果成功删除则返回真。
deQueue()
//检查循环队列是否为空。
isEmpty()
//检查循环队列是否已满。
isFull() 实现如下:
typedef struct {
int* a;
int head;//队头下标
int tail;//队尾的下一个的下标
int size;//对内元素个数
int capacity;//队容量
} MyCircularQueue;
bool myCircularQueueIsEmpty(MyCircularQueue* obj);
bool myCircularQueueIsFull(MyCircularQueue* obj);
MyCircularQueue* myCircularQueueCreate(int k)
{
MyCircularQueue* cq = (MyCircularQueue*)malloc(sizeof(MyCircularQueue));
cq->a = (int*)malloc(sizeof(int) * k);
cq->head = cq->tail = 0;
cq->size = 0;
cq->capacity = k;
return cq;
}
bool myCircularQueueEnQueue(MyCircularQueue* obj, int value)
{
if (myCircularQueueIsFull(obj))
{
return false;
}
obj->a[obj->tail] = value;
obj->tail = (obj->tail + 1) % obj->capacity;
++obj->size;
return true;
}
bool myCircularQueueDeQueue(MyCircularQueue* obj)
{
if (myCircularQueueIsEmpty(obj))
{
return false;
}
obj->head = (obj->head + 1) % obj->capacity;
--obj->size;
return true;
}
int myCircularQueueFront(MyCircularQueue* obj)
{
if (myCircularQueueIsEmpty(obj))
{
return -1;
}
else
{
return obj->a[obj->head];
}
}
int myCircularQueueRear(MyCircularQueue* obj)
{
if (myCircularQueueIsEmpty(obj))
{
return -1;
}
else
{
int truetail = (obj->tail + obj->capacity - 1) % obj->capacity;
return obj->a[truetail];
}
}
bool myCircularQueueIsEmpty(MyCircularQueue* obj)
{
return obj->size == 0;
}
bool myCircularQueueIsFull(MyCircularQueue* obj)
{
return obj->size == obj->capacity;
}
void myCircularQueueFree(MyCircularQueue* obj)
{
free(obj->a);
obj->a = NULL;
obj->head = obj->tail = 0;
obj->size = 0;
obj->capacity = 0;
}在入队和出队后,对 head 和 tail 的调整需要考虑到循环的情况,所以进行了取模。
需要注意的是,tail 我们给的是队尾的下一个的下标,所以在取队尾元素的时候需要考虑到
tail == 0 的情况,对负数取模仍会为负数,所以我们先加上了容量,再-1,最后取模。
4 · 用两个队列实现栈
4 - 1 · 思路
用两个队列来实现 后进先出的栈。
其实这个没有什么实际意义。
大致思路是通过两个队列倒数据来模拟栈。
我们入栈,就对队列中有元素的队列进行入队操作,如果都为空队列则随意入队。
当需要出栈的时候,有元素的队列先进行出队,并将出队的元素给到另一个栈,最后剩下一个未出队的元素,这个元素就是我们模拟的栈的栈顶。
4 - 2 · 代码实现
我们一共实现四个接口:
//将元素 x 压入栈顶。
void push(int x)
//移除并返回栈顶元素。
int pop()
//返回栈顶元素。
int top()
//如果栈是空的,返回 true ;否则,返回 false 。
bool empty() 代码如下:
typedef struct
{
Queue q1;
Queue q2;
} MyStack;
MyStack* myStackCreate()
{
MyStack* ps = (MyStack*)malloc(sizeof(MyStack));
QueueInit(&(ps->q1));
QueueInit(&(ps->q2));
return ps;
}
void myStackPush(MyStack* obj, int x)
{
//往有数据的队列入数据
if (!QueueEmpty(&(obj->q1)))
{
QueuePush(&(obj->q1), x);
}
else
{
QueuePush(&(obj->q2), x);
}
}
int myStackPop(MyStack* obj)
{
//有数据的先倒给另一个队列,再出
Queue* q_data = &(obj->q1);
Queue* q_nodata = &(obj->q2);
if (QueueEmpty(&(obj->q1)))
{
q_data = &(obj->q2);
q_nodata = &(obj->q1);
}
while (QueueSize(q_data) > 1)
{
QueuePush(q_nodata, QueueFront(q_data));
QueuePop(q_data);
}
//出队
int res = QueueFront(q_data);
QueuePop(q_data);
return res;
}
int myStackTop(MyStack* obj)
{
if (!QueueEmpty(&(obj->q1)))
{
return QueueBack(&(obj->q1));
}
else
{
return QueueBack(&(obj->q2));
}
}
bool myStackEmpty(MyStack* obj)
{
return QueueEmpty(&(obj->q1)) && QueueEmpty(&(obj->q2));
}
void myStackFree(MyStack* obj)
{
QueueDestroy(&(obj->q1));
QueueDestroy(&(obj->q2));
free(obj);
obj = NULL;
}5 · 用两个栈实现队列
5 - 1 · 思路
用两个栈来实现 先进先出的队列。
这个其实也没什么实际意义。
有两种思路:
-
保持第一个栈始终存有数据,入数据时往第一个栈入,当需要使用队列的操作时,第一个栈出栈给第二个栈,执行完操作之后,为了保证后续的顺序,第二个栈出栈给回第一个栈。
-
一个栈专门用来入数据,另一个栈专门用来出数据,当用来出数据的栈空了,再从存数据的栈出栈给出数据的栈。
5 - 2 · 代码实现
第一种思路:
//方法1 数据给s1入栈,每次出栈或取顶时先倒给s2,然后操作完后s2倒回s1
typedef struct
{
Stack s1;
Stack s2;
} MyQueue;
MyQueue* myQueueCreate()
{
MyQueue* q = (MyQueue*)malloc(sizeof(MyQueue));
StackInit(&(q->s1));
StackInit(&(q->s2));
return q;
}
void myQueuePush(MyQueue* obj, int x)
{
StackPush(&(obj->s1), x);
}
int myQueuePop(MyQueue* obj)
{
//s1倒给s2
while (!StackEmpty(&(obj->s1)))
{
StackPush(&(obj->s2), StackTop(&(obj->s1)));
StackPop(&(obj->s1));
}
//删除
int top = StackTop(&(obj->s2));
StackPop(&(obj->s2));
//s2倒回s1
while (!StackEmpty(&(obj->s2)))
{
StackPush(&(obj->s1), StackTop(&(obj->s2)));
StackPop(&(obj->s2));
}
return top;
}
int myQueuePeek(MyQueue* obj)
{
//s1倒给s2
while (!StackEmpty(&(obj->s1)))
{
StackPush(&(obj->s2), StackTop(&(obj->s1)));
StackPop(&(obj->s1));
}
int top = StackTop(&(obj->s2));
//s2倒回s1
while (!StackEmpty(&(obj->s2)))
{
StackPush(&(obj->s1), StackTop(&(obj->s2)));
StackPop(&(obj->s2));
}
return top;
}
bool myQueueEmpty(MyQueue* obj)
{
return StackEmpty(&(obj->s1));
}
void myQueueFree(MyQueue* obj)
{
StackDestroy(&(obj->s1));
StackDestroy(&(obj->s2));
free(obj);
obj = NULL;
}第二种思路:
//方法2 s1专门用来入栈,s2专门用来出栈,当s2为空时再从s1倒过来
typedef struct
{
Stack s1;
Stack s2;
} MyQueue;
MyQueue* myQueueCreate()
{
MyQueue* q = (MyQueue*)malloc(sizeof(MyQueue));
StackInit(&(q->s1));
StackInit(&(q->s2));
return q;
}
void myQueuePush(MyQueue* obj, int x)
{
StackPush(&(obj->s1), x);
}
int myQueuePop(MyQueue* obj)
{
//如果s2为空,s1倒给s2
if (StackEmpty(&(obj->s2)))
{
while (!StackEmpty(&(obj->s1)))
{
StackPush(&(obj->s2), StackTop(&(obj->s1)));
StackPop(&(obj->s1));
}
}
//删除
int top = StackTop(&(obj->s2));
StackPop(&(obj->s2));
return top;
}
int myQueuePeek(MyQueue* obj)
{
//如果s2为空,s1倒给s2
if (StackEmpty(&(obj->s2)))
{
while (!StackEmpty(&(obj->s1)))
{
StackPush(&(obj->s2), StackTop(&(obj->s1)));
StackPop(&(obj->s1));
}
}
return StackTop(&(obj->s2));
}
bool myQueueEmpty(MyQueue* obj)
{
return StackEmpty(&(obj->s1)) && StackEmpty(&(obj->s2));
}
void myQueueFree(MyQueue* obj)
{
StackDestroy(&(obj->s1));
StackDestroy(&(obj->s2));
free(obj);
obj = NULL;
}总结
以上简单介绍了栈和队列有关内容,关于数据结构其余内容,请期待后续更新。
以上内容如有错误或不准确之处,欢迎指出,或者你有更好的想法,也欢迎交流。