本篇目标:理解 Linux 如何在物理内存不足时回收页面。我们将深入 LRU 链表、kswapd 守护进程、直接回收(direct reclaim)以及 swap 机制,看内核如何在"内存紧张"与"系统响应"之间取得平衡。这些机制是理解 HMM 页面迁移的重要背景------设备内存(如 GPU VRAM)可以作为页面迁移的目标,类似于 swap 但性能更好。
1. 承上启下:分配与回收的平衡
前几篇我们建立了内存分配的完整链路:
- 第 1-3 篇:虚拟地址(VMA)→ 页表 → 物理页帧(PFN)
- 第 4 篇(缺页处理):首次访问时按需分配物理页
但有一个问题我们还没回答:物理内存是有限的 。如果进程不断分配内存,物理内存终将耗尽。此时,内核必须回收一些页面,腾出空间给新的分配请求,也就是swap功能。下面是加上了swap的内存的生命周期循环。
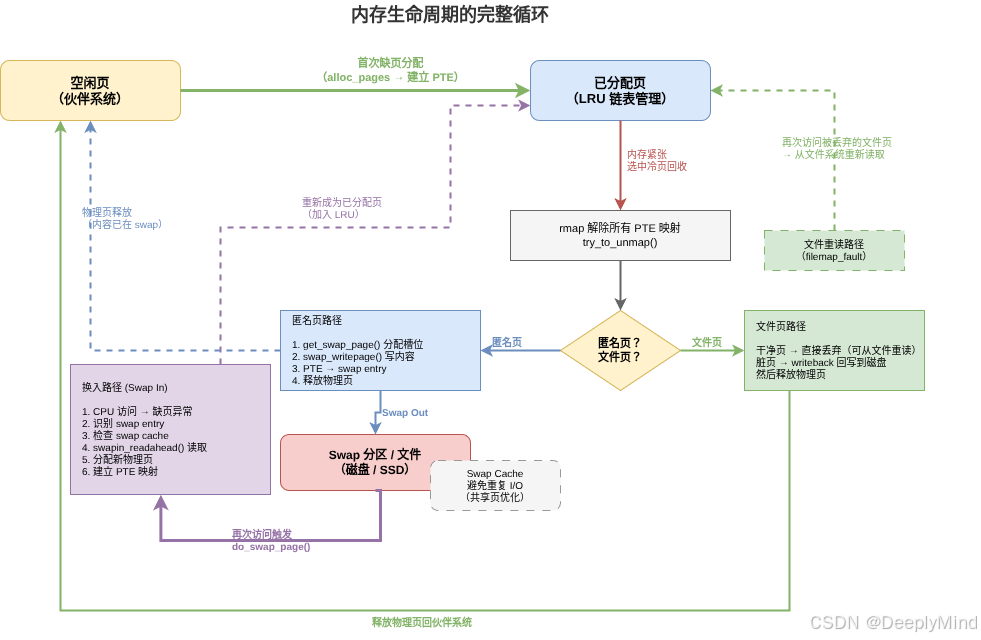
页面回收是内存管理中最复杂的部分之一,因为它需要:
- 选择牺牲品:哪些页面可以回收?哪些正在被使用?
- 处理脏页:修改过的页面需要先写回(swap 或文件系统)
- 保持响应性:不能让系统在回收时卡死
- 避免抖动:不能刚回收就又被访问,造成频繁换入换出
2. 选择牺牲品:哪些页面可以回收?
内存回收的第一步是找到合适的回收对象------哪些页面是"冷"的、可以安全回收?哪些正在被使用、必须保护?
2.1 LRU:近似最近最少使用
内核使用 LRU(Least Recently Used) 算法来判断页面的"冷热"程度:
- 热页面:最近被访问过,可能很快还会被访问
- 冷页面:很久没被访问,可以考虑回收
这基于一个假设:最近使用过的页面,在不久的将来更可能被再次使用(时间局部性)。
2.2 五条 LRU 链表
Linux 维护了 5 条 LRU 链表,定义在 include/linux/mmzone.h:
c
// include/linux/mmzone.h
enum lru_list {
LRU_INACTIVE_ANON = 0, // 不活跃匿名页(候选回收)
LRU_ACTIVE_ANON = 1, // 活跃匿名页(暂不回收)
LRU_INACTIVE_FILE = 2, // 不活跃文件页(候选回收)
LRU_ACTIVE_FILE = 3, // 活跃文件页(暂不回收)
LRU_UNEVICTABLE = 4, // 不可回收页(mlock 等)
NR_LRU_LISTS
};两个维度:
- 匿名页 vs 文件页:匿名页需要写入 swap,文件页可以丢弃(干净)或回写(脏)
- 活跃 vs 不活跃:活跃页暂时不回收,不活跃页是回收候选
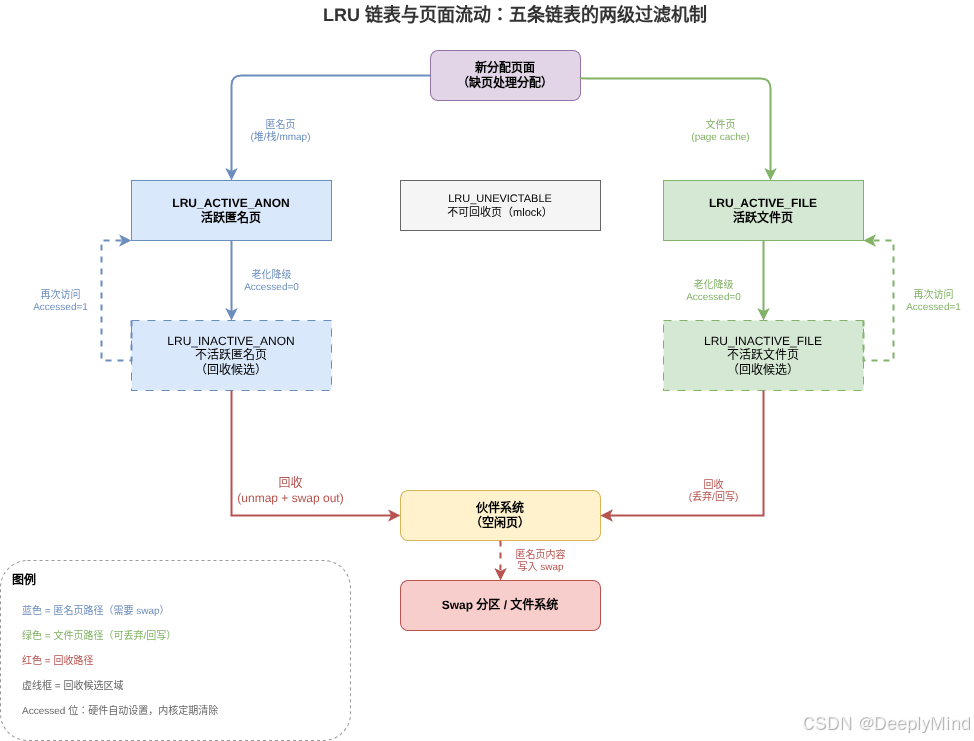
2.3 Accessed 位:追踪页面冷热
页面的"活跃度"由硬件的 Accessed 位(PTE 中)来追踪:
c
// 页面被访问时的流程
1. CPU 访问页面 → 硬件自动设置 PTE 的 Accessed 位
2. 内核定期扫描 → 检查 Accessed 位
3. 如果 Accessed=1:
- 清除 Accessed 位
- 页面保持在 Active 链表(或从 Inactive 提升到 Active)
4. 如果 Accessed=0:
- 页面从 Active 降级到 Inactive
- 如果已在 Inactive,成为回收候选💡 为什么不直接用访问时间戳? 每次访问都更新时间戳开销太大。用 Accessed 位是一种"近似 LRU"------定期采样而非精确记录。
2.4 反向映射(rmap):找到所有映射者
要回收一个页面,必须先解除所有指向它的 PTE。但内核只知道 struct page,如何找到所有映射它的 PTE?
答案是 rmap(Reverse Mapping) ------每个 struct page 记录了"谁在映射我":
c
// 反向映射的核心数据结构
struct folio {
struct address_space *mapping; // 文件页:所属文件
// 匿名页:指向 anon_vma
...
};
// 通过 anon_vma 可以找到所有映射这个匿名页的 VMA
// 通过 VMA 可以找到 mm_struct
// 通过 mm_struct 可以遍历页表找到 PTE💡 HMM 与 rmap :HMM 使用的 ZONE_DEVICE 页面也有
struct page,因此也能参与 rmap。这是 HMM 页面能被正确回收/迁移的基础。
2.5 swappiness:匿名页与文件页的取舍
内核需要决定回收匿名页还是文件页。swappiness 参数控制这个倾向:
bash
# 查看当前值(默认 60)
cat /proc/sys/vm/swappiness
# 范围 0-200
# 0:尽量不换出匿名页,优先回收文件页
# 100:匿名页和文件页同等对待
# 200:积极换出匿名页2.6 扫描强度:priority 控制搜索范围
struct scan_control 中的 priority 字段控制扫描强度:
c
// 优先级从 DEF_PRIORITY (12) 开始
// 每次扫描不成功就降低优先级
// 优先级越低,扫描范围越大
扫描页面数 = LRU 链表长度 >> priority
priority=12: 扫描 1/4096 的页面
priority=11: 扫描 1/2048 的页面
...
priority=0: 扫描全部页面2.7 OOM Killer:最后的手段
如果回收努力全部失败,内存仍然不足,OOM Killer 出手------选择一个进程杀掉:
c
// mm/oom_kill.c
// 选择"最该死"的进程
// 考虑因素:内存使用量、oom_score_adj、是否是 root 等
static int oom_badness(struct task_struct *p, ...)
{
// 计算进程的"罪恶值"
// 值越高越可能被杀
}⚠️ OOM Killer 是最后手段,到这一步说明系统内存严重不足。合理配置 swap 和监控内存使用可以避免 OOM。
3. 处理脏页:修改过的页面怎么办?
选中了要回收的页面后,下一个问题是:如果页面被修改过(脏页),内容怎么保存?
3.1 两类页面的不同归宿
| 页面类型 | 干净页 | 脏页 |
|---|---|---|
| 文件页 | 直接丢弃(可从文件重读) | 回写到文件系统 |
| 匿名页 | 不存在"干净匿名页"概念 | 必须写入 swap |
文件页有后备文件------干净页可以直接丢弃,脏页可以回写。但匿名页(堆、栈、mmap MAP_ANONYMOUS)没有后备文件,必须写到 swap。
3.2 Swap:匿名页的后备存储
匿名页回收流程:
┌─────────────┐
│ 匿名页 │
│ (在内存中) │
└─────────────┘
│
│ 回收时写入 swap
▼
┌─────────────┐
│ swap 分区 │ PTE 被设为 swap entry
│ (在磁盘上) │ 记录 swap 位置
└─────────────┘
│
│ 再次访问时换入
▼
┌─────────────┐
│ 新物理页 │ 从 swap 读取内容
│ (在内存中) │ 恢复 PTE 映射
└─────────────┘3.3 Swap Entry:记录页面去了哪里
当页面被换出到 swap 时,原来的 PTE 被替换为 swap entry:
c
// include/linux/swapops.h
// swap entry 的格式(Present=0)
// ┌─────────────────────────────────────────────────┐
// │ type (哪个 swap 设备) │ offset (设备内偏移) │ 0 │
// └─────────────────────────────────────────────────┘
// 创建 swap entry
static inline swp_entry_t swp_entry(unsigned long type, pgoff_t offset)
{
swp_entry_t ret;
ret.val = (type << SWP_TYPE_SHIFT) | (offset & SWP_OFFSET_MASK);
return ret;
}
// 从 swap entry 提取信息
static inline unsigned swp_type(swp_entry_t entry);
static inline pgoff_t swp_offset(swp_entry_t entry);swap entry 编码(我们在第 3 篇简要介绍过):
- type:标识是哪个 swap 设备(可以有多个 swap 分区)
- offset:在该 swap 设备中的页面偏移
3.4 换出流程(Swap Out)
c
// 简化的换出流程
1. 选中一个匿名页进行回收
2. 分配 swap 槽位:get_swap_page()
3. 将页面内容写入 swap:swap_writepage()
4. 通过 rmap 找到所有映射这个页的 PTE
5. 将每个 PTE 替换为 swap entry:
ptep_clear_flush()
set_pte_at(swp_entry_to_pte(entry))
6. 释放物理页面回伙伴系统3.5 换入流程(Swap In)
当 CPU 访问一个 swap entry 时,触发缺页异常,do_swap_page() 处理换入(我们在第 4 篇已详细介绍):
c
// 简化的换入流程(do_swap_page)
1. 识别 PTE 是 swap entry
2. 提取 swap 位置:swp_type(), swp_offset()
3. 检查 swap cache(可能已被其他进程换入)
4. 从 swap 读取页面内容:swapin_readahead()
5. 分配新物理页,填充内容
6. 建立新的 PTE 映射
7. 释放 swap 槽位(如果是最后一个引用)3.6 shrink_folio_list():回收执行的核心
不管是哪种触发方式,最终都会调用 shrink_folio_list() 逐个处理候选页面,其中脏页处理是关键步骤:
c
// mm/vmscan.c(简化)
static unsigned int shrink_folio_list(struct list_head *folio_list,
struct pglist_data *pgdat,
struct scan_control *sc, ...)
{
while (!list_empty(folio_list)) {
struct folio *folio = lru_to_folio(folio_list);
// 1. 尝试锁定页面
if (!folio_trylock(folio))
goto keep; // 锁不到,跳过
// 2. 检查是否可回收
if (!folio_evictable(folio))
goto activate_locked; // mlock 的页面不能回收
// 3. 检查是否被映射
if (!sc->may_unmap && folio_mapped(folio))
goto keep_locked; // 不允许 unmap,跳过
// 4. 处理脏页(核心!)
if (folio_test_dirty(folio)) {
// 文件页:启动回写
// 匿名页:写入 swap
...
}
// 5. 解除所有页表映射(通过 rmap)
if (folio_mapped(folio)) {
try_to_unmap(folio, ...);
}
// 6. 真正释放页面
if (folio可以释放) {
free_unref_folios(...);
nr_reclaimed++;
}
}
return nr_reclaimed;
}回收决策总结:
| 因素 | 处理方式 |
|---|---|
| 被映射 | 需要先通过 rmap 解除所有 PTE 映射 |
| 脏页 | 匿名页写入 swap;文件页回写到磁盘 |
| 正在写回 | 等待或跳过 |
| 被锁定 | 跳过(稍后重试) |
| mlock | 不可回收,移到 UNEVICTABLE 链表 |
4. 保持响应性:不让系统在回收时卡死
脏页需要写磁盘、swap 需要 I/O------这些都很慢。如何在回收的同时保持系统响应性?答案是分层设计:后台异步回收为主,阻塞式直接回收为最后防线。
4.1 kswapd:后台异步回收
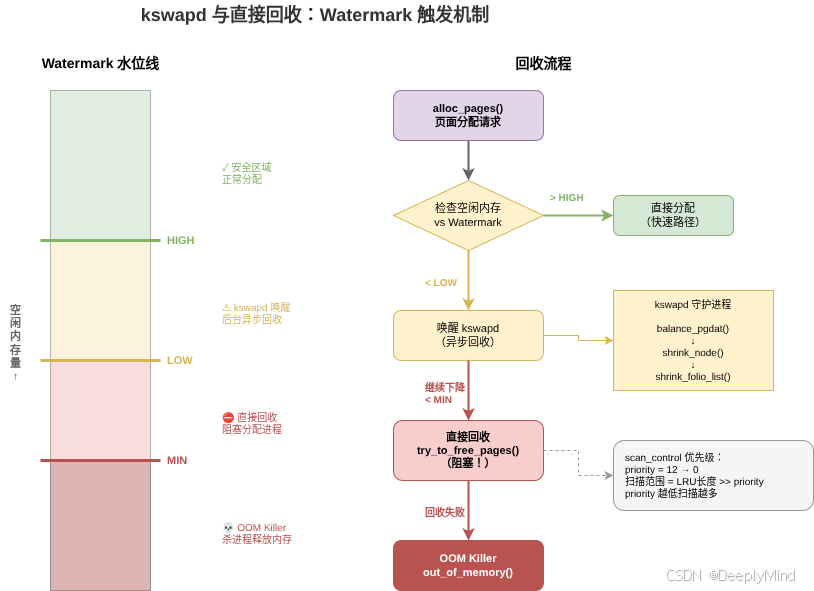
每个 NUMA 节点有一个 kswapd 守护进程,在后台默默工作:
c
// mm/vmscan.c
static int kswapd(void *p)
{
pg_data_t *pgdat = (pg_data_t *)p;
tsk->flags |= PF_MEMALLOC | PF_KSWAPD; // 特殊标记
for ( ; ; ) {
// 睡眠,等待被唤醒
kswapd_try_to_sleep(pgdat, ...);
// 被唤醒后,开始回收
reclaim_order = balance_pgdat(pgdat, alloc_order, highest_zoneidx);
}
}kswapd 在后台运行,不阻塞任何用户进程。它提前回收页面,维持一个"安全库存"。
4.2 Watermark:三条水位线的调度艺术
见上图。其设计精髓:
- high → low 之间:系统正常,kswapd 睡眠
- low 以下:kswapd 被唤醒,后台异步回收(用户无感知)
- min 以下:紧急状态,触发直接回收(用户可能感知到卡顿)
大部分情况下 kswapd 能在 low 和 high 之间维持平衡,用户无感知。
4.3 直接回收(Direct Reclaim):不得已的阻塞
如果 kswapd 来不及回收,空闲内存降到 min watermark 以下,分配请求会触发直接回收:
c
// mm/vmscan.c
unsigned long try_to_free_pages(struct zonelist *zonelist, int order,
gfp_t gfp_mask, nodemask_t *nodemask)
{
struct scan_control sc = {
.nr_to_reclaim = SWAP_CLUSTER_MAX, // 至少回收这么多
.gfp_mask = gfp_mask,
.may_writepage = 1,
.may_unmap = 1,
.may_swap = 1,
};
// 同步回收,会阻塞当前进程!
nr_reclaimed = do_try_to_free_pages(zonelist, &sc);
return nr_reclaimed;
}直接回收的问题:
- 阻塞:分配请求被挂起,等待回收完成
- 延迟:如果需要写脏页,延迟可能很长
- 级联:多个进程同时触发直接回收,系统变慢
💡 这就是为什么内存压力大时系统会"卡"------进程在等待直接回收完成。Watermark 的设计目标就是让系统尽量停留在 kswapd 异步回收阶段,避免走到直接回收。
5. 避免抖动:防止频繁换入换出
即使选对了牺牲品、正确写回了脏页、保持了响应性,还有一个陷阱:刚回收的页面马上又被访问,导致频繁换入换出(thrashing)。内核通过两个机制来避免这个问题。
5.1 Active/Inactive 两级过滤
为什么不用简单的单一 LRU 链表?考虑"扫描攻击"场景:
单一 LRU 的问题:
假设一次 `find /` 扫描了大量文件
→ 产生大量文件页,涌入 LRU
→ 把真正的热页面(如数据库缓存)挤到链表尾部
→ 热页面被回收 → 马上又被访问 → 抖动!两级链表的保护机制:
Active/Inactive 的防护:
find / 产生的文件页 → 进入 Inactive 链表
(因为只被访问一次,Accessed 位只被设置一次)
数据库热页面 → 保持在 Active 链表
(持续被访问,Accessed 位反复被设置)
结果:扫描产生的"一次性"页面优先被回收
真正的热页面得到保护关键规则 :页面需要在 Inactive 链表中再次被访问才会提升到 Active。仅被访问一次的页面会被优先回收------这正是避免抖动的核心设计。
5.2 Swap Cache:避免重复磁盘 I/O
考虑 fork 后的场景:
c
pid_t pid = fork();
// 此时父子进程共享所有页面(COW)
// 假设某个共享页被换出到 swap
// 父子进程的 PTE 都变成同一个 swap entry
// 现在父进程访问这个页,触发换入
// 紧接着子进程也访问这个页
// 问题:需要从 swap 读两次吗?Swap Cache 解决了这个问题------保存最近换入/换出的页面,避免重复 I/O:
Swap Cache 机制:
父进程换入:
1. 分配物理页
2. 从 swap 读取内容
3. 将页面加入 swap cache(key = swap entry)
4. 建立父进程的 PTE 映射
子进程换入:
1. 检查 swap cache:找到了!
2. 直接使用 cache 中的页面
3. 建立子进程的 PTE 映射
4. 无需再次读取 swap好处:
- 避免同一页面被多次从 swap 读取(减少 I/O,降低抖动)
- 写入 swap 时也先进 cache,异步写入磁盘(减少写延迟)
6. 实验:观察页面回收
6.1 查看内存和 swap 状态
bash
# 查看内存概况
free -h
# 查看详细内存统计
cat /proc/meminfo
# 关键指标:
# - MemFree: 完全空闲的内存
# - Buffers/Cached: 可回收的缓存
# - SwapTotal/SwapFree: swap 使用情况
# - Active/Inactive: LRU 链表统计6.2 查看 kswapd 活动
bash
# 查看 vmstat,观察 swap 活动
vmstat 1
# 关键列:
# si: swap in(每秒换入页数)
# so: swap out(每秒换出页数)
# 如果 si/so 持续很高,说明内存压力大
# 查看 kswapd 进程
ps aux | grep kswapd6.3 模拟内存压力
c
// stress_memory.c - 简单的内存压力测试
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
int main(int argc, char *argv[])
{
size_t size = 100 * 1024 * 1024; // 100MB
if (argc > 1)
size = atol(argv[1]) * 1024 * 1024;
printf("分配 %zu MB 内存...\n", size / (1024 * 1024));
char *buf = malloc(size);
if (!buf) {
perror("malloc");
return 1;
}
// 触碰所有页面,防止被优化掉
printf("触碰所有页面...\n");
memset(buf, 'A', size);
printf("完成,按 Enter 释放...\n");
getchar();
free(buf);
return 0;
}
bash
# 编译并运行
gcc -o stress_memory stress_memory.c
# 在另一个终端观察 vmstat
vmstat 1
# 分配大量内存,观察 swap 活动
./stress_memory 500 # 分配 500MB
./stress_memory 2000 # 分配 2GB(如果物理内存不够,会触发 swap)7. 与 HMM 的联系
页面回收机制是 HMM 的重要背景:
7.1 设备内存作为"高级 Swap"
HMM 允许将页面迁移到 GPU VRAM。从某种角度看,这类似于 swap------都是把页面从 CPU 内存移走:
| 方面 | Swap | HMM 设备迁移 |
|---|---|---|
| 目标 | 磁盘(慢) | GPU VRAM(快) |
| PTE 编码 | swap entry | device_private_entry |
| 回迁触发 | CPU 访问 | CPU 访问 |
| 回迁速度 | 毫秒级(磁盘 I/O) | 微秒级(PCIe DMA) |
7.2 Device Private Entry vs Swap Entry
c
// 两种"页面不在 CPU 内存"的编码
// Swap entry:页面在磁盘
// ┌─────────────────────────────────────┐
// │ swap type │ swap offset │ flags │ 0 │
// └─────────────────────────────────────┘
// Device private entry:页面在设备内存
// ┌─────────────────────────────────────┐
// │ SWP_DEVICE_* │ PFN │ flags │ 0 │
// └─────────────────────────────────────┘7.3 为什么 HMM 页面也需要参与 LRU
ZONE_DEVICE 页面(设备内存的 struct page)也可以加入 LRU 链表:
- 追踪活跃度:哪些设备页面是"热"的
- 迁移决策:冷的设备页面可以考虑迁回 CPU
- 统一框架:复用内核现有的回收基础设施
7.4 Memory Tiering:内存分层
现代系统有多种内存层次:
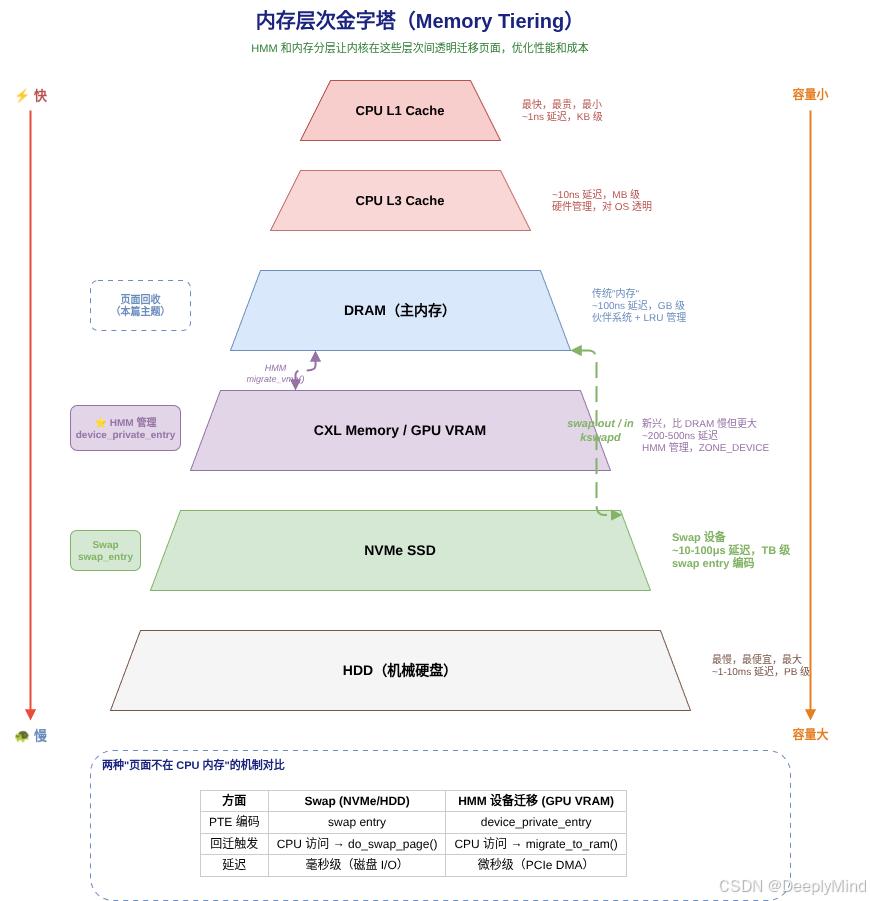
HMM 和内存分层(Memory Tiering)让内核可以在这些层次间透明迁移页面,优化性能和成本。
8. 本篇关键代码路径
| 文件 | 核心内容 |
|---|---|
mm/vmscan.c |
页面回收核心(shrink_folio_list, kswapd, try_to_free_pages) |
mm/swap_state.c |
Swap cache 管理 |
mm/swapfile.c |
Swap 分区/文件管理 |
mm/swap.c |
LRU 链表操作 |
mm/rmap.c |
反向映射(try_to_unmap) |
include/linux/mmzone.h |
enum lru_list、watermark 定义 |
include/linux/swap.h |
swap entry 类型定义 |
9. 下篇预告
页表遍历框架------walk_page_range() 的设计哲学
前几篇我们多次提到"遍历页表"------从虚拟地址找到 PTE,从 PTE 提取 PFN。内核为此提供了一个通用框架:walk_page_range()。
下一篇我们将深入这个框架,理解 mm_walk_ops 回调表的设计,看内核如何让不同子系统(内存回收、/proc/pid/pagemap、HMM)复用同一套页表遍历逻辑。这个框架是 hmm_range_fault() 的基础。
10. 思考题
-
为什么 Linux 使用"双链表"(Active/Inactive)而不是简单的单一 LRU 链表?这种设计如何防止"扫描攻击"(一次大量读取把热页面挤出去)?
-
如果一个页面同时被父子进程映射(fork 后的 COW 页面),回收时需要解除几个 PTE 映射?rmap 如何找到所有这些映射?
-
swappiness=0是否意味着永远不会发生 swap?在什么情况下即使swappiness=0也会换出匿名页? -
为什么 swap cache 很重要?如果没有 swap cache,共享页面的换入会有什么问题?
-
HMM 的 device_private_entry 和 swap entry 都是 Present=0 的 PTE。内核如何区分它们?(提示:看 swap type 字段)