本篇目标 :理解
ZONE_DEVICE为什么存在,以及它如何通过memremap_pages()给设备物理地址范围建立struct page/ vmemmap。我们会沿着源码看清楚三个问题:
struct page怎么表达设备内存ZONE_DEVICE为什么不是普通ZONE_NORMALMEMORY_DEVICE_PRIVATE、MEMORY_DEVICE_COHERENT、DAX、P2PDMA 这些类型分别表达什么语义。
1. 从"设备内存"到"设备页"
上一篇我们从异构计算的角度提出了一个核心需求:
设备内存不能只是驱动私有黑盒,也不能简单伪装成普通 RAM。它需要进入 Linux MM 的语义框架。
Linux MM 的语义框架有一个非常重要的入口:struct page。
在经典 MM 中,只要内核知道一个 PFN 对应的 struct page,很多通用机制就可以工作:
pfn_to_page()/page_to_pfn()可以在 PFN 和页面描述符之间转换- page refcount 可以表达页面是否还被使用
- rmap、migration、GUP、fault handler 可以围绕 page 做判断
- folio/page flags 可以表达页面状态
- 页面释放时可以走统一的生命周期回调
如果设备内存没有 struct page,驱动当然也能自己维护一套元数据,例如:
c
struct gpu_page {
u64 device_addr;
u64 size;
atomic_t refcnt;
void *driver_private;
};但这样做很快会遇到边界问题:
| MM 问题 | 只有驱动私有元数据时的困难 |
|---|---|
| 页面迁移 | migrate_vma 需要用 PFN/page 描述源页和目标页 |
| CPU 回访 | CPU fault handler 要知道这个 VA 背后是设备私有页 |
| GUP/Pin | 内核需要识别哪些页不能长期 pin |
| 生命周期 | 进程退出、VMA teardown、页表失效时需要统一回收 |
| 错误处理 | memory failure 需要能定位受影响 PFN/page |
| 子系统协作 | block、fs、mm、driver 之间需要共同语言 |
所以 HMM 的选择不是让每个设备驱动重新发明一套 page 模型,而是:
给设备物理地址范围也创建
struct page,但用新的 zone 和类型标记它不是普通 RAM。
这个新 zone 就是 ZONE_DEVICE。
2. ZONE_DEVICE 的定位:memmap 服务,不是 buddy 内存
Documentation/mm/memory-model.rst 对 ZONE_DEVICE 的定义非常精确:
ZONE_DEVICEbuilds uponSPARSEMEM_VMEMMAPto offerstruct pagemem_mapservices for device driver identified physical address ranges.
这句话有两个关键词。
第一个是 SPARSEMEM_VMEMMAP。现代内核通常通过 vmemmap 为每个 PFN 建立 struct page 数组。普通 RAM 如此,ZONE_DEVICE 也是借这个机制,为设备 PFN 建立对应的 page 描述符。
第二个是 mem_map services。这意味着 ZONE_DEVICE 的核心不是"把设备内存加入 buddy allocator",而是提供 page 元数据服务:
c
pfn_to_page(device_pfn);
page_to_pfn(device_page);有了这层服务,内核可以把设备页放进已有的 MM 语义里讨论。但这不等于设备页会变成普通空闲页。
普通 RAM 的路径大致是:
text
System RAM
-> memory hotplug / bootmem init
-> ZONE_NORMAL / ZONE_MOVABLE
-> online
-> buddy allocator
-> alloc_pages()ZONE_DEVICE 的路径是:
text
Device physical address range
-> memremap_pages()
-> ZONE_DEVICE
-> vmemmap / struct page
-> driver-managed allocation and lifetime它只做"足够的 memory hotplug",让 pfn_to_page()、page_to_pfn() 等服务可用,但不会把这段内存 online 成普通系统内存。文档里说得很直接:ZONE_DEVICE 的 page objects are never marked online。
这就是理解 ZONE_DEVICE 的第一把钥匙:
ZONE_DEVICE 是让 MM 看见设备页,而不是让 buddy 分配设备页。
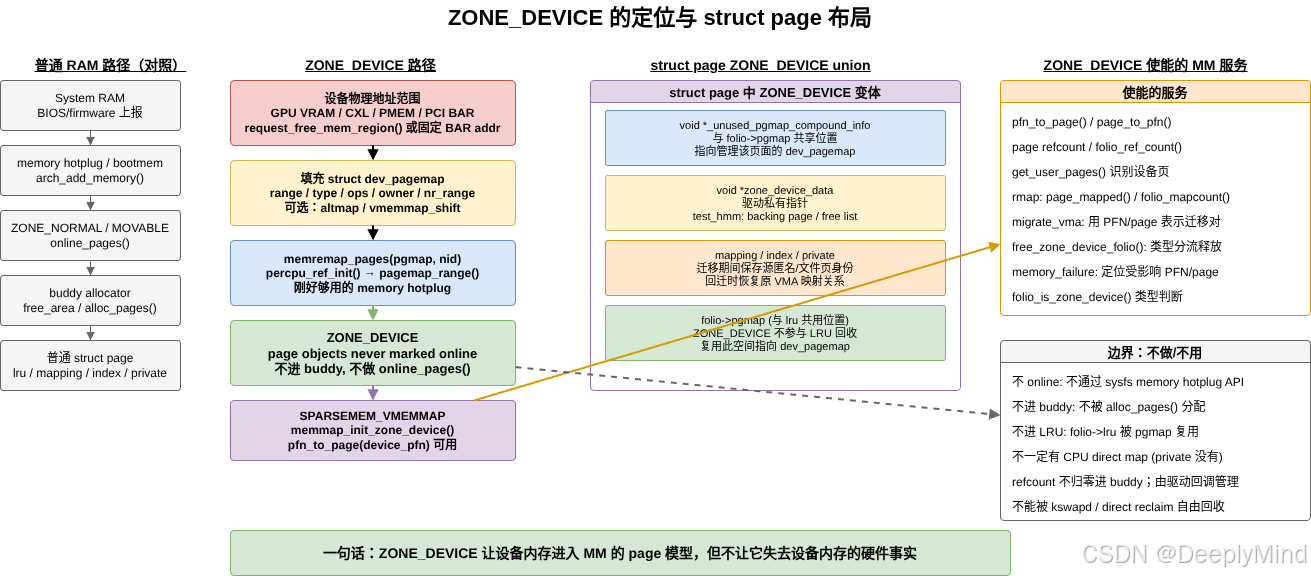
3. struct page 如何容纳 ZONE_DEVICE 页
include/linux/mm_types.h 里的 struct page 是一个大型 union。普通 page cache / anonymous page 会使用 lru、mapping、index、private 等字段。
ZONE_DEVICE 页则有自己的 union 变体:
c
struct { /* ZONE_DEVICE pages */
/*
* The first word is used for compound_info or folio pgmap
*/
void *_unused_pgmap_compound_info;
void *zone_device_data;
/*
* ZONE_DEVICE private pages are counted as being
* mapped so the next 3 words hold the mapping, index,
* and private fields from the source anonymous or
* page cache page while the page is migrated to device
* private memory.
*/
};这段设计有几个要点。
3.1 page->pgmap:设备页回指 dev_pagemap
在 folio 视角里,folio->pgmap 指向管理这段设备内存的 struct dev_pagemap。它告诉内核:
- 这页属于哪一类设备内存
- 对应的 owner 是谁
- 页面释放时调用哪个
folio_free() - CPU fault 访问 private 页时调用哪个
migrate_to_ram() - 这个 PFN 是否属于合法的 pgmap range
zone_device_page_init() 中有一行非常关键:
c
new_folio->pgmap = pgmap;这相当于把每个设备 page 和它的控制面绑定起来。
3.2 zone_device_data:驱动私有指针
zone_device_data 是留给驱动的私有字段。lib/test_hmm.c 里就用它保存模拟设备页和 backing page 的关系。
例如设备私有页释放时,dmirror_devmem_free() 会把页面放回 test_hmm 的空闲链表:
c
page->zone_device_data = mdevice->free_pages;
mdevice->free_pages = page;CPU 访问 device private 页触发 fault 时,dmirror_devmem_fault() 又会通过:
c
rpage = folio_zone_device_data(page_folio(vmf->page));找到对应的 backing page,再走 migrate_vma_*() 把内容迁回 RAM。
这说明 struct page 没有抹平设备差异。它只是提供通用外壳,而真正的设备语义仍由 pgmap 和驱动私有数据决定。
3.3 mapping/index/private:迁移期间保存源页语义
注释里还提到:device private pages are counted as being mapped,所以后面 3 个 word 会保存源匿名页或 page cache 页的 mapping、index、private 字段。
这很重要。页面迁到设备私有内存后,CPU PTE 不再指向普通 RAM 页,而是变成 device private entry。可从 MM 语义上看,这个 VA 仍然属于原来的匿名映射或文件映射。
因此设备页需要携带一部分源页身份,方便后续回迁、fault、rmap 等路径保持一致。
4. dev_pagemap:设备内存区域的控制面
下一篇会专门展开 dev_pagemap,这里先把它放在 ZONE_DEVICE 的主线上看。
include/linux/memremap.h 中的定义如下:
c
struct dev_pagemap {
struct vmem_altmap altmap;
struct percpu_ref ref;
struct completion done;
enum memory_type type;
unsigned int flags;
unsigned long vmemmap_shift;
const struct dev_pagemap_ops *ops;
void *owner;
int nr_range;
union {
struct range range;
DECLARE_FLEX_ARRAY(struct range, ranges);
};
};先抓住几个核心字段:
| 字段 | 作用 |
|---|---|
type |
区分 private、coherent、DAX、P2PDMA 等设备内存语义 |
ops |
页面释放、CPU 回迁、memory failure、folio split 等回调 |
owner |
标识哪个设备/驱动管理这段内存,防止误用 foreign memory |
range/ranges |
设备物理地址范围 |
ref/done |
pgmap 生命周期引用计数 |
altmap |
可选:用设备内存自身为 vmemmap 元数据供给空间 |
vmemmap_shift |
可选:用更大粒度组织 vmemmap page metadata |
dev_pagemap 是 ZONE_DEVICE 的控制面。ZONE_DEVICE 让 PFN 有 page,dev_pagemap 告诉内核这批 page 怎么被管理。
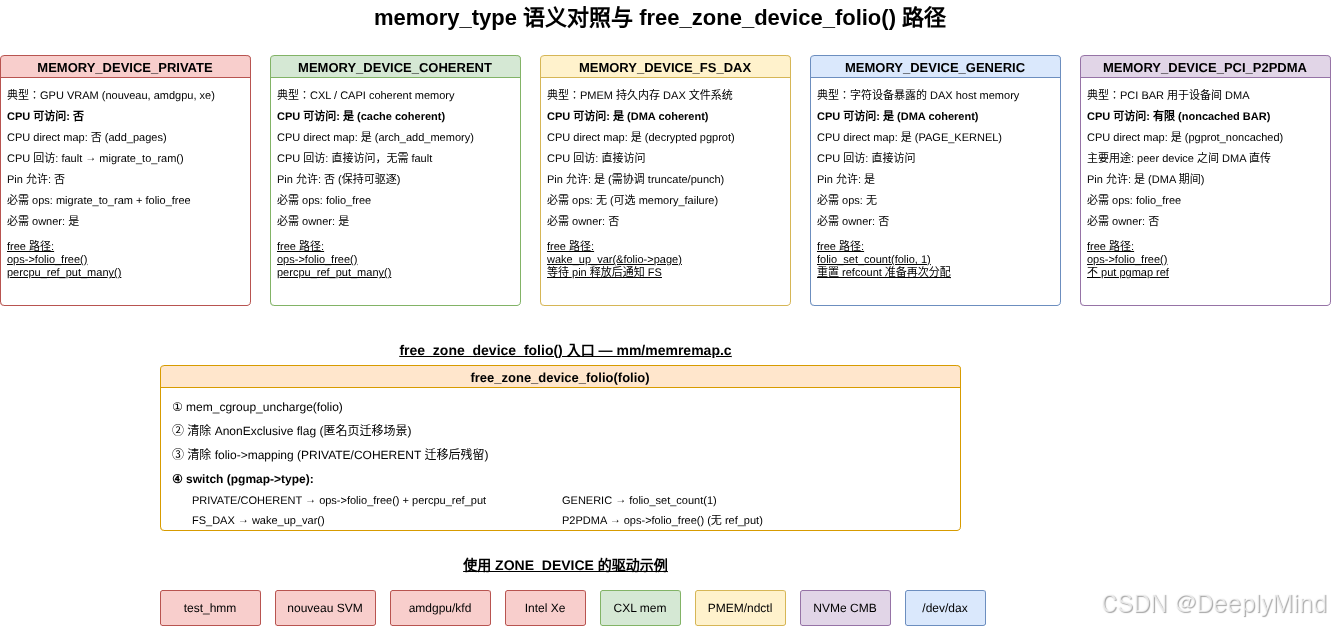
5. memory_type:同样是 ZONE_DEVICE,语义并不相同
ZONE_DEVICE 不是一种单一内存。它下面通过 enum memory_type 继续细分:
c
enum memory_type {
MEMORY_DEVICE_PRIVATE = 1,
MEMORY_DEVICE_COHERENT,
MEMORY_DEVICE_FS_DAX,
MEMORY_DEVICE_GENERIC,
MEMORY_DEVICE_PCI_P2PDMA,
};这些类型共享一个事实:它们都需要 struct page / memmap 服务。但它们对 CPU 可访问性、pin 语义、fault 行为和驱动回调的要求不同。
5.1 MEMORY_DEVICE_PRIVATE
MEMORY_DEVICE_PRIVATE 表示 CPU 不能直接读写的设备私有内存,典型例子是 GPU VRAM。
memremap_pages() 对 private 类型有严格检查:
c
case MEMORY_DEVICE_PRIVATE:
if (!IS_ENABLED(CONFIG_DEVICE_PRIVATE))
return ERR_PTR(-EINVAL);
if (!pgmap->ops || !pgmap->ops->migrate_to_ram)
return ERR_PTR(-EINVAL);
if (!pgmap->ops->folio_free)
return ERR_PTR(-EINVAL);
if (!pgmap->owner)
return ERR_PTR(-EINVAL);
break;为什么必须有 migrate_to_ram()?因为 CPU 访问 private 页时不能直接 load/store,fault handler 必须让驱动把内容搬回 CPU 可访问内存。
这类页最像 HMM 里的"真正设备私有页"。它的关键语义是:
text
页面可被进程 VA 引用
页面内容位于设备私有内存
CPU 访问时 fault
驱动 migrate_to_ram() 负责回迁5.2 MEMORY_DEVICE_COHERENT
MEMORY_DEVICE_COHERENT 表示 CPU 和设备都能 cache coherent 访问的设备内存,常见背景是 CAPI/CXL 这类一致性互连。
它比 private 更接近普通 RAM,但仍然不是完全普通的 ZONE_NORMAL。注释里强调:
Any page of a process can be migrated to such memory. However no one should be allowed to pin such memory so that it can always be evicted.
也就是说,这类内存可以被 CPU 直接访问,但仍然需要保留可驱逐、可迁移的设备内存语义。长期 pin 会破坏它作为可迁移设备内存的前提。
5.3 MEMORY_DEVICE_FS_DAX
MEMORY_DEVICE_FS_DAX 主要用于持久内存文件系统 DAX。它的访问语义更接近系统 RAM:DMA coherent,并支持 page pinning。
但 DAX 关心另一个问题:文件 truncate、hole punch、坏块处理等文件系统操作如何与 pinned page 协调。所以 FS DAX 的 page idle / wakeup 语义和 HMM private 页不同。
5.4 MEMORY_DEVICE_GENERIC
MEMORY_DEVICE_GENERIC 也是 host memory 语义,类似 System RAM,可以 DMA coherent,也支持 pinning。它常用于通过字符设备暴露的 DAX 类设备内存。
5.5 MEMORY_DEVICE_PCI_P2PDMA
MEMORY_DEVICE_PCI_P2PDMA 表示 PCI BAR 中用于 peer-to-peer DMA 的设备内存。它的目标不是让 CPU 频繁访问,而是让两个 PCIe 设备之间直接传输,绕开系统内存。
memremap_pages() 会把它的 pgprot 设置为 noncached:
c
case MEMORY_DEVICE_PCI_P2PDMA:
params.pgprot = pgprot_noncached(params.pgprot);
break;这体现了同样的设计原则:都叫 ZONE_DEVICE,但每种类型必须保留自己的硬件语义。
接下来我们要分析整个初始化流程,这里先给出一个流程图。
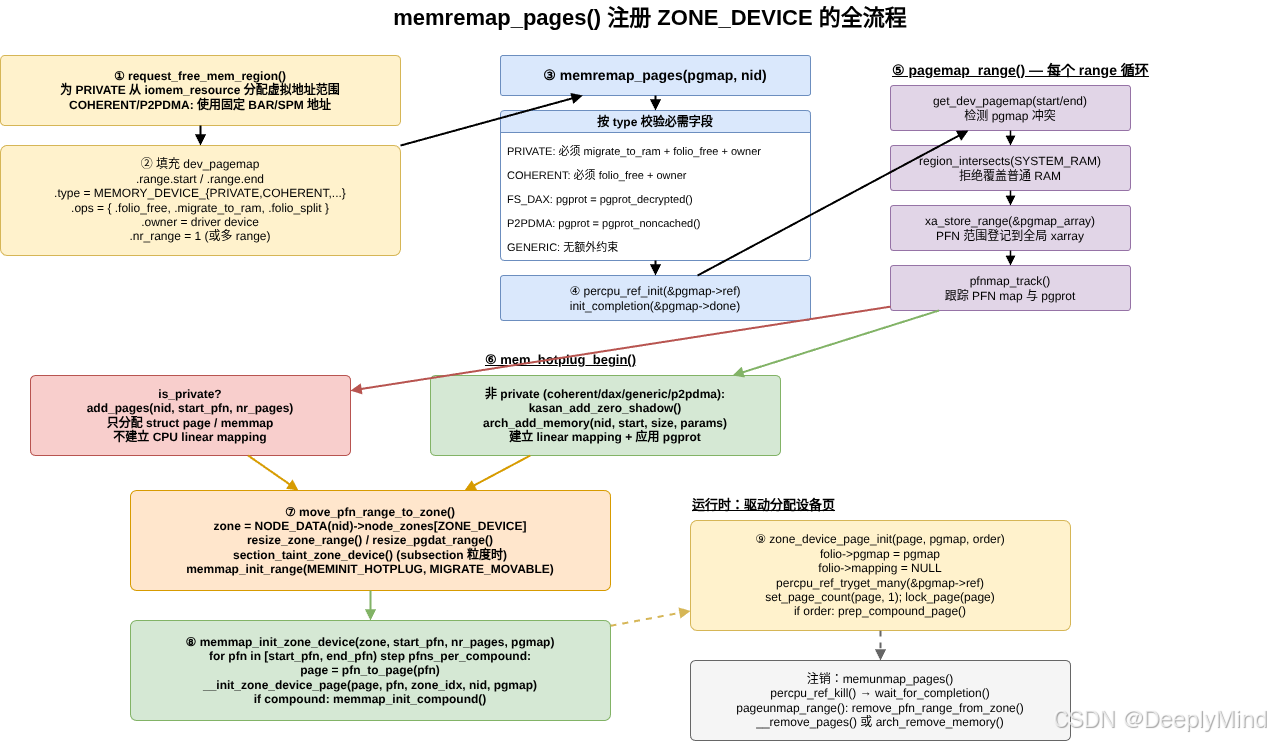
6. memremap_pages():注册设备 PFN 的主入口
设备驱动通常先准备 dev_pagemap,再调用:
c
void *memremap_pages(struct dev_pagemap *pgmap, int nid);lib/test_hmm.c 是最短示例。
private 设备内存路径:
c
res = request_free_mem_region(&iomem_resource, DEVMEM_CHUNK_SIZE,
"hmm_dmirror");
devmem->pagemap.range.start = res->start;
devmem->pagemap.range.end = res->end;
devmem->pagemap.type = MEMORY_DEVICE_PRIVATE;coherent 设备内存路径:
c
devmem->pagemap.range.start = spm_addr_dev0;
devmem->pagemap.range.end = devmem->pagemap.range.start +
DEVMEM_CHUNK_SIZE - 1;
devmem->pagemap.type = MEMORY_DEVICE_COHERENT;然后统一设置:
c
devmem->pagemap.nr_range = 1;
devmem->pagemap.ops = &dmirror_devmem_ops;
devmem->pagemap.owner = mdevice;
ptr = memremap_pages(&devmem->pagemap, numa_node_id());dmirror_devmem_ops 提供回调:
c
static const struct dev_pagemap_ops dmirror_devmem_ops = {
.folio_free = dmirror_devmem_free,
.migrate_to_ram = dmirror_devmem_fault,
.folio_split = dmirror_devmem_folio_split,
};这就是设备页注册的基本模板:
text
设备物理地址范围
-> dev_pagemap(range, type, ops, owner)
-> memremap_pages()
-> ZONE_DEVICE + vmemmap
-> pfn_to_page(device_pfn) 可用7. pagemap_range():刚好够用的 memory hotplug
memremap_pages() 会对每个 range 调用内部函数 pagemap_range()。这是理解 ZONE_DEVICE 的关键函数。
它先做几类安全检查:
- 不能和已有 pgmap 冲突
- 不能覆盖 System RAM
- 把 PFN 范围放进
pgmap_array - 调用
pfnmap_track()跟踪 PFN map - 检查 memory hotplug 范围是否允许
核心差异在这段注释:
c
/*
* For device private memory we call add_pages() as we only need to
* allocate and initialize struct page for the device memory. More-
* over the device memory is un-accessible thus we do not want to
* create a linear mapping for the memory like arch_add_memory()
* would do.
*
* For all other device memory types, which are accessible by
* the CPU, we do want the linear mapping and thus use
* arch_add_memory().
*/
if (is_private) {
error = add_pages(nid, PHYS_PFN(range->start),
PHYS_PFN(range_len(range)), params);
} else {
error = arch_add_memory(nid, range->start, range_len(range),
params);
}这一段把 private 和 non-private 的本质差异说透了。
7.1 private:只要 struct page,不要 direct map
MEMORY_DEVICE_PRIVATE 的内存 CPU 不能直接访问,因此内核不能给它建立普通线性映射。它只需要为 PFN 创建 struct page。
所以 private 路径使用 add_pages():
text
add_pages()
-> 初始化 memmap/page metadata
-> 不建立 CPU direct map7.2 coherent/DAX/P2PDMA:需要 CPU 映射属性
其他类型在某种程度上 CPU 可访问,或者至少需要体系结构层面的内存映射属性。因此走 arch_add_memory():
text
arch_add_memory()
-> 架构层建立映射
-> 初始化 memmap/page metadata
-> 应用 pgprot 属性例如 P2PDMA 会用 noncached pgprot,FS DAX 会用 decrypted pgprot。
7.3 move_pfn_range_to_zone()
成功添加 PFN 后,pagemap_range() 会把这段 PFN 移到 ZONE_DEVICE:
c
zone = &NODE_DATA(nid)->node_zones[ZONE_DEVICE];
move_pfn_range_to_zone(zone, PHYS_PFN(range->start),
PHYS_PFN(range_len(range)), params->altmap,
MIGRATE_MOVABLE, false);move_pfn_range_to_zone() 会扩展 zone / node 的 PFN 范围,并调用:
c
memmap_init_range(..., zone_idx(zone), ..., MEMINIT_HOTPLUG, ...);如果是 subsection 粒度的 ZONE_DEVICE,它还会标记 section_taint_zone_device(),让 pfn_to_online_page() 这类路径在混合 section 中走更谨慎的判断。
7.4 memmap_init_zone_device()
最后,pagemap_range() 调用:
c
memmap_init_zone_device(&NODE_DATA(nid)->node_zones[ZONE_DEVICE],
PHYS_PFN(range->start),
PHYS_PFN(range_len(range)), pgmap);memmap_init_zone_device() 会遍历这段 PFN,对每个设备 page 执行初始化:
c
for (pfn = start_pfn; pfn < end_pfn; pfn += pfns_per_compound) {
struct page *page = pfn_to_page(pfn);
__init_zone_device_page(page, pfn, zone_idx, nid, pgmap);
if (pfns_per_compound != 1)
memmap_init_compound(page, pfn, zone_idx, nid, pgmap,
compound_nr_pages(altmap, pgmap));
}这一步之后,设备 PFN 就真正拥有了 struct page 身份。
8. zone_device_page_init():设备页被分配给驱动时的初始化
memmap_init_zone_device() 是批量建立 memmap。驱动真正从自己的设备内存池里拿出一个设备页使用时,还会涉及 zone_device_page_init()。
源码中它会做几件事:
c
new_folio->mapping = NULL;
new_folio->pgmap = pgmap;
new_folio->share = 0;
VM_WARN_ON_FOLIO(folio_ref_count(new_folio), new_folio);
VM_WARN_ON_FOLIO(!folio_is_zone_device(new_folio), new_folio);然后拿 pgmap 引用,设置 page refcount,并锁住页面:
c
WARN_ON_ONCE(!percpu_ref_tryget_many(&page_pgmap(page)->ref,
1 << order));
set_page_count(page, 1);
lock_page(page);
if (order)
prep_compound_page(page, order);这说明 ZONE_DEVICE page 不是 buddy 分配器随手返回的普通页。它通常由设备驱动自己的 allocator 管理,驱动在需要时初始化它,并在释放时通过 folio_free() 回调放回设备内存池。
9. 为什么 page refcount 不像普通页一样归零
文档里提到一个容易忽略的点:ZONE_DEVICE 页面引用计数不会像普通空闲页那样降到 0 并进入 buddy。它需要持有设备/pgmap 引用,确保页面被使用时,对应的设备内存映射还活着。
free_zone_device_folio() 展示了释放路径的分流:
c
switch (pgmap->type) {
case MEMORY_DEVICE_PRIVATE:
case MEMORY_DEVICE_COHERENT:
pgmap->ops->folio_free(folio);
percpu_ref_put_many(&pgmap->ref, nr);
break;
case MEMORY_DEVICE_GENERIC:
folio_set_count(folio, 1);
break;
case MEMORY_DEVICE_FS_DAX:
wake_up_var(&folio->page);
break;
case MEMORY_DEVICE_PCI_P2PDMA:
pgmap->ops->folio_free(folio);
break;
}不同类型释放动作不同:
- private/coherent:调用驱动
folio_free(),归还 pgmap 引用 - generic:把 refcount 重置为 1,准备再次 handing out
- FS DAX:唤醒等待 page idle 的路径
- P2PDMA:调用驱动释放回调
这再次说明:ZONE_DEVICE 提供统一 page 外壳,但并不抹掉各类设备内存的生命周期差异。
10. 为什么不 online 成普通内存
很多人第一次看到 memremap_pages() 和 memory hotplug 会问:既然都 hotplug 了,为什么不直接 online 成普通内存?
答案是:ZONE_DEVICE 只借用了 hotplug 的上半部分能力,用来建立 memmap 和 zone 归属。它没有把这些 page 放进普通 allocator。
原因至少有四个。
10.1 CPU 可访问性不满足
对 MEMORY_DEVICE_PRIVATE 来说,CPU 根本不能直接访问。把它 online 成普通内存会让内核在任意地方对它执行 load/store、memset、copy、atomic 操作,这在硬件上不成立。
10.2 生命周期由设备驱动管理
设备内存的分配、释放、错误恢复通常由驱动控制。buddy allocator 不知道设备页背后的硬件队列、VRAM 分区、BAR、firmware 状态,也不知道释放时该通知谁。
10.3 迁移/回迁语义特殊
private 页被 CPU 访问时需要 migrate_to_ram()。coherent 页虽然 CPU 可访问,也常常需要保持可驱逐,避免被长期 pin。
普通 ZONE_NORMAL 没有这些约束。
10.4 不同设备类型语义差别太大
DAX、P2PDMA、GPU VRAM、CXL coherent memory 都可能需要 struct page,但它们对 cache、pin、fault、DMA、错误处理的要求完全不同。把它们压扁成普通 RAM,反而会丢失重要信息。
所以正确的抽象是:
text
有 struct page
但不一定是普通 RAM
能进入 MM 语义
但保留设备类型差异这正是 ZONE_DEVICE + dev_pagemap + memory_type 的组合价值。
11. ZONE_DEVICE 与 HMM 后续机制的关系
ZONE_DEVICE 是第三篇章后续几篇的地基。
| 后续机制 | 依赖 ZONE_DEVICE 的地方 |
|---|---|
dev_pagemap |
描述设备 PFN range、类型、回调、owner |
| device private entry | PTE 中记录"页面不在 RAM,而在设备 private memory" |
migrate_vma |
迁移目标页可以是 ZONE_DEVICE page |
migrate_to_ram() |
CPU fault 访问 private page 时回迁 |
HMM hmm_range_fault() |
读取 CPU 页表时识别普通 PFN、device private entry、权限状态 |
| 驱动 SVM | 用 pgmap owner 区分自己的设备内存和 foreign device memory |
也就是说,ZONE_DEVICE 本身还不是完整 HMM。它只是先解决一个前提问题:
设备物理内存如何成为 Linux MM 能够引用、识别、迁移和回调的 page?
后面篇章会继续把这块地基往上搭:
c
ZONE_DEVICE
-> dev_pagemap 控制面
-> device private/exclusive entry
-> migrate_vma 三阶段迁移
-> HMM range fault / driver SVM12. 本篇小结:ZONE_DEVICE 的设计边界
ZONE_DEVICE 的设计非常克制。
它没有把设备内存假装成完全普通的 ZONE_NORMAL,也没有让设备驱动在 MM 之外维护一套完全私有的 page 世界。它走的是中间路线:
- 用
SPARSEMEM_VMEMMAP为设备 PFN 创建struct page - 用
memremap_pages()做刚好够用的 memory hotplug - 用
ZONE_DEVICE标识这些 page 不是普通 RAM - 用
dev_pagemap记录类型、范围、回调和 owner - 用
memory_type保留 private、coherent、DAX、P2PDMA 的语义差异 - 用驱动回调处理释放、回迁、错误和 folio split
一句话总结:
ZONE_DEVICE 让设备内存进入 MM 的 page 模型,但不让它失去设备内存的硬件事实。
这正是 HMM 能复用 Linux MM,而不是重写一套异构内存管理器的基础。
13. 本篇关键代码路径
| 文件 | 核心内容 |
|---|---|
Documentation/mm/memory-model.rst |
ZONE_DEVICE 基于 SPARSEMEM_VMEMMAP 提供 struct page mem_map 服务 |
Documentation/mm/physical_memory.rst |
zone 分类中对 ZONE_DEVICE 的定位 |
include/linux/mm_types.h |
struct page 中 ZONE_DEVICE 专用 union 字段、zone_device_data |
include/linux/memremap.h |
memory_type、dev_pagemap、dev_pagemap_ops、memremap_pages() 声明 |
mm/memremap.c |
memremap_pages()、pagemap_range()、free_zone_device_folio()、zone_device_page_init() |
mm/mm_init.c |
memmap_init_zone_device() 初始化设备 PFN 的 struct page |
mm/memory_hotplug.c |
move_pfn_range_to_zone() 将 PFN 范围归入 ZONE_DEVICE |
lib/test_hmm.c |
test_hmm 注册 private/coherent 设备内存的最小示例 |
14. 下篇预告
dev_pagemap:设备内存区域的控制面 :本篇我们把 ZONE_DEVICE 看成"给设备 PFN 创建 struct page"的基础设施。下一篇会把镜头推近到 dev_pagemap:它如何描述一段设备内存的 range、type、owner 和 ops,dev_pagemap_ops 的 migrate_to_ram() / folio_free() / memory_failure() 分别在什么路径被调用,pgmap 引用计数如何保证设备内存注销时没有悬挂 page。
15. 思考题
-
为什么设备内存需要
struct page,但又不能简单进入 buddy allocator? -
MEMORY_DEVICE_PRIVATE为什么只需要建立struct page,而不应该建立 CPU direct map? -
MEMORY_DEVICE_COHERENT可以被 CPU 访问,为什么仍然不等同于普通ZONE_NORMAL? -
dev_pagemap->owner在多设备、多驱动共享同一个进程地址空间时有什么意义? -
如果没有
ZONE_DEVICE,migrate_vma想把页面迁到设备内存,需要额外解决哪些问题?