目录
[11.1 链式模型](#11.1 链式模型)
[11.1.1 有向链式模型](#11.1.1 有向链式模型)
[11.1.2 无向链式模型](#11.1.2 无向链式模型)
[11.1.3 模型的等价性](#11.1.3 模型的等价性)
[11.1.4 隐马尔可夫模型在手语中的应用](#11.1.4 隐马尔可夫模型在手语中的应用)
[完整代码:HMM 实现简单手语识别模拟](#完整代码:HMM 实现简单手语识别模拟)
[11.2 链式 MAP 推理](#11.2 链式 MAP 推理)
[完整代码:Viterbi 算法实现链式 MAP 推理](#完整代码:Viterbi 算法实现链式 MAP 推理)
[11.3 树的 MAP 推理](#11.3 树的 MAP 推理)
[可视化:树模型结构 + MAP 推理流程](#可视化:树模型结构 + MAP 推理流程)
[11.4 链式边缘后验推理](#11.4 链式边缘后验推理)
[11.4.1 求解边缘分布](#11.4.1 求解边缘分布)
[11.4.2 前向后向算法](#11.4.2 前向后向算法)
[11.4.3 置信传播](#11.4.3 置信传播)
[11.4.4 链式模型的和积算法](#11.4.4 链式模型的和积算法)
[11.5 树的边缘后验推理](#11.5 树的边缘后验推理)
[11.6 链式模型和树模型的学习](#11.6 链式模型和树模型的学习)
[完整代码:EM 算法训练 HMM(无监督学习)](#完整代码:EM 算法训练 HMM(无监督学习))
[11.7 链式模型和树模型之外的东西](#11.7 链式模型和树模型之外的东西)
[11.8 应用](#11.8 应用)
[11.8.1 手势跟踪](#11.8.1 手势跟踪)
[完整代码:基于 HMM 的手势跟踪模拟](#完整代码:基于 HMM 的手势跟踪模拟)
[11.8.2 立体视觉](#11.8.2 立体视觉)
[11.8.3 形象化结构](#11.8.3 形象化结构)
[11.8.4 分割](#11.8.4 分割)
[完整代码:基于 MRF 的简单图像分割](#完整代码:基于 MRF 的简单图像分割)
前言
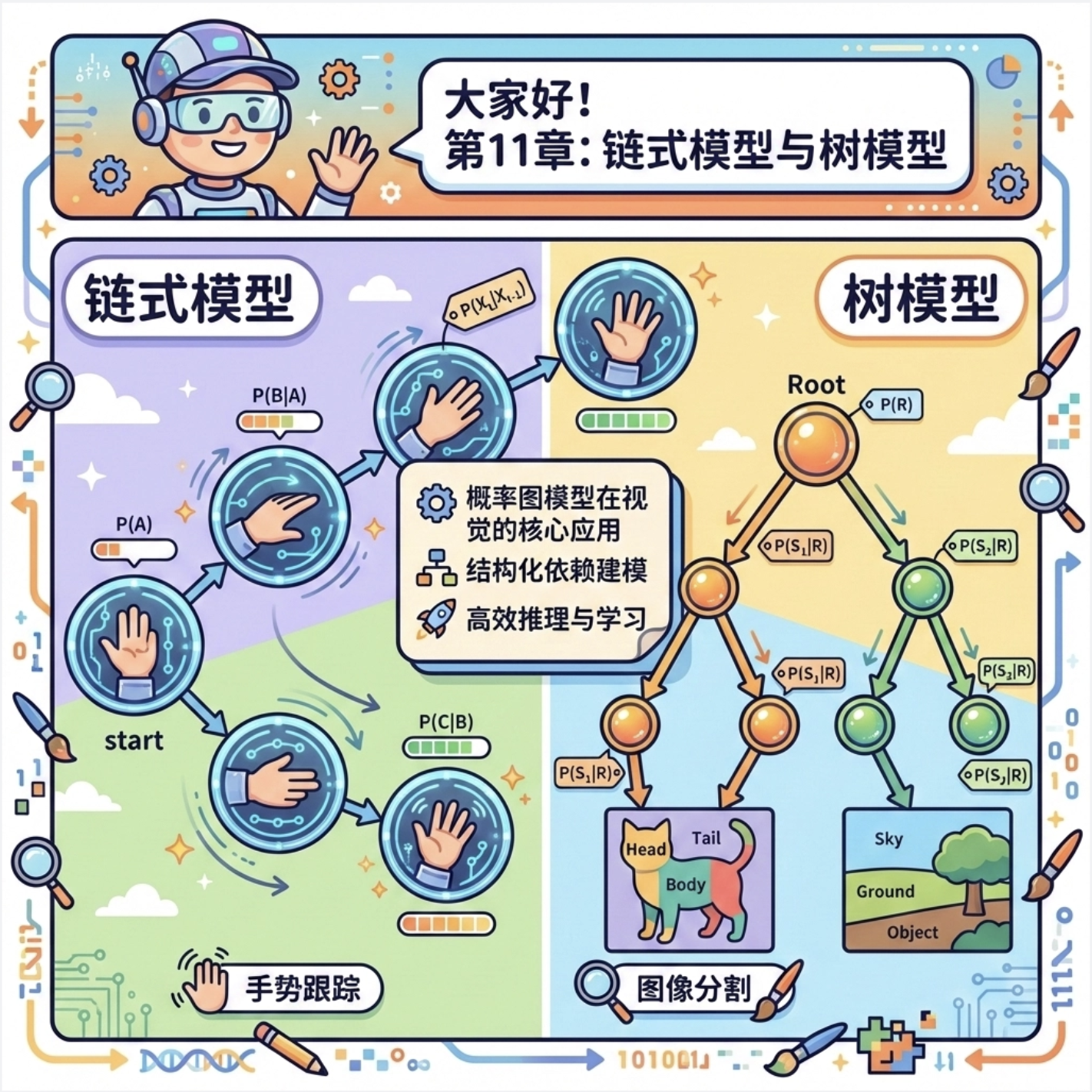
大家好!今天我们来深入拆解《计算机视觉:模型、学习和推理》这本书的第 11 章 ------ 链式模型和树模型。这一章是概率图模型在计算机视觉中的核心应用,很多经典的视觉任务(比如手势跟踪、图像分割)都离不开这些模型。
我会尽量用通俗易懂的语言讲解核心概念,避免堆砌公式,同时给出完整可直接运行的 Python 代码 和可视化对比图,方便大家动手实践。(注:代码基于 Mac 系统配置了 Matplotlib 中文显示,Windows 用户可自行替换字体)
11.1 链式模型
11.1.1 有向链式模型
核心概念
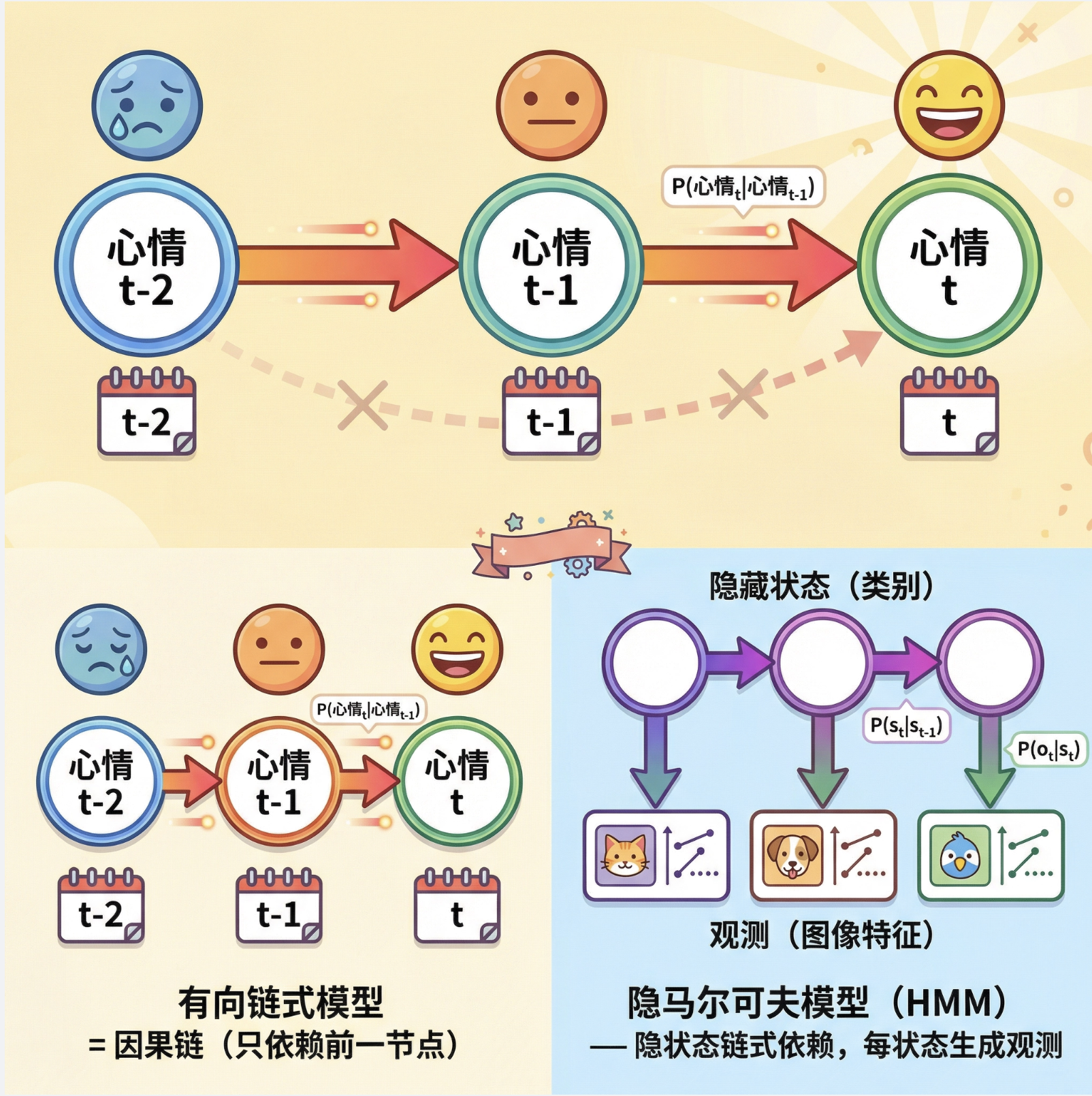
有向链式模型就像一串 "因果链",每个节点只依赖于前一个节点。比如我们每天的心情:今天的心情(节点 t)只和昨天的心情(节点 t-1)有关,和前天的心情没有直接关系。
在计算机视觉中,最典型的有向链式模型就是隐马尔可夫模型(HMM) ------ 隐藏状态(比如手势的类别)是链式依赖的,而每个隐藏状态会生成一个可观测的特征(比如手势的图像特征)。
可视化:有向链式模型结构
import matplotlib.pyplot as plt
import networkx as nx
# Mac系统Matplotlib中文显示配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# 创建有向链式图
def plot_directed_chain_model():
# 创建有向图
G = nx.DiGraph()
# 添加节点(隐藏状态z1-z5)
nodes = ['z1', 'z2', 'z3', 'z4', 'z5']
G.add_nodes_from(nodes)
# 添加有向边(链式依赖)
edges = [('z1','z2'), ('z2','z3'), ('z3','z4'), ('z4','z5')]
G.add_edges_from(edges)
# 绘图
plt.figure(figsize=(10, 3))
pos = {node: (i, 0) for i, node in enumerate(nodes)} # 水平排列
nx.draw(G, pos, with_labels=True, node_size=1500, node_color='lightblue',
font_size=12, font_weight='bold', arrowstyle='->', arrowsize=20)
plt.title('有向链式模型(隐马尔可夫模型隐藏状态链)', fontsize=14)
plt.axis('off')
plt.show()
# 运行可视化
if __name__ == "__main__":
plot_directed_chain_model()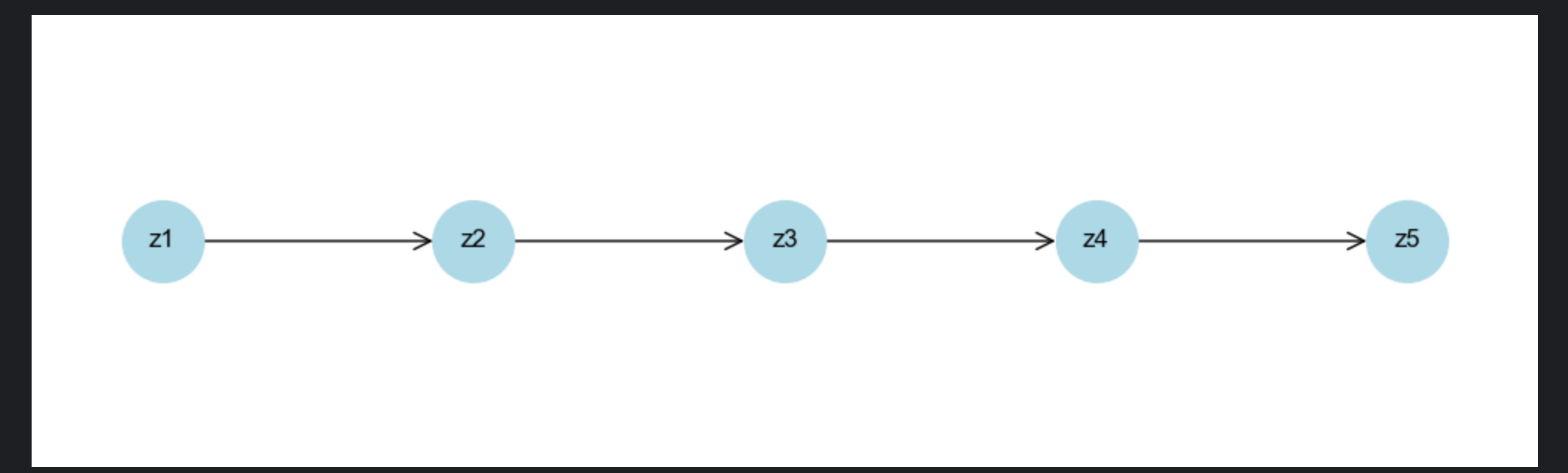
代码说明
使用networkx构建有向图,模拟 HMM 的隐藏状态链式结构;
通过matplotlib绘制水平链式图,直观展示 "前一个节点指向后一个节点" 的有向依赖关系;
所有配置均适配 Mac 系统中文显示,直接运行即可看到效果。
11.1.2 无向链式模型

核心概念
无向链式模型(也叫马尔可夫链随机场)没有 "因果" 的方向,节点之间是相互依赖的 ------ 就像手拉手的小朋友,相邻的两个小朋友会互相影响,但不相邻的小朋友没有直接影响。
比如图像的像素链:相邻像素的颜色通常是相似的(相互依赖),而隔得远的像素没有直接依赖关系。
可视化:无向链式模型结构
import matplotlib.pyplot as plt
import networkx as nx
# 复用Mac字体配置(已在上方配置,此处可省略,仅为代码完整性保留)
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
def plot_undirected_chain_model():
# 创建无向图
G = nx.Graph()
# 添加节点(像素x1-x5)
nodes = ['x1', 'x2', 'x3', 'x4', 'x5']
G.add_nodes_from(nodes)
# 添加无向边(相邻依赖)
edges = [('x1','x2'), ('x2','x3'), ('x3','x4'), ('x4','x5')]
G.add_edges_from(edges)
# 绘图
plt.figure(figsize=(10, 3))
pos = {node: (i, 0) for i, node in enumerate(nodes)}
nx.draw(G, pos, with_labels=True, node_size=1500, node_color='lightgreen',
font_size=12, font_weight='bold')
plt.title('无向链式模型(像素链)', fontsize=14)
plt.axis('off')
plt.show()
# 运行可视化
if __name__ == "__main__":
plot_undirected_chain_model()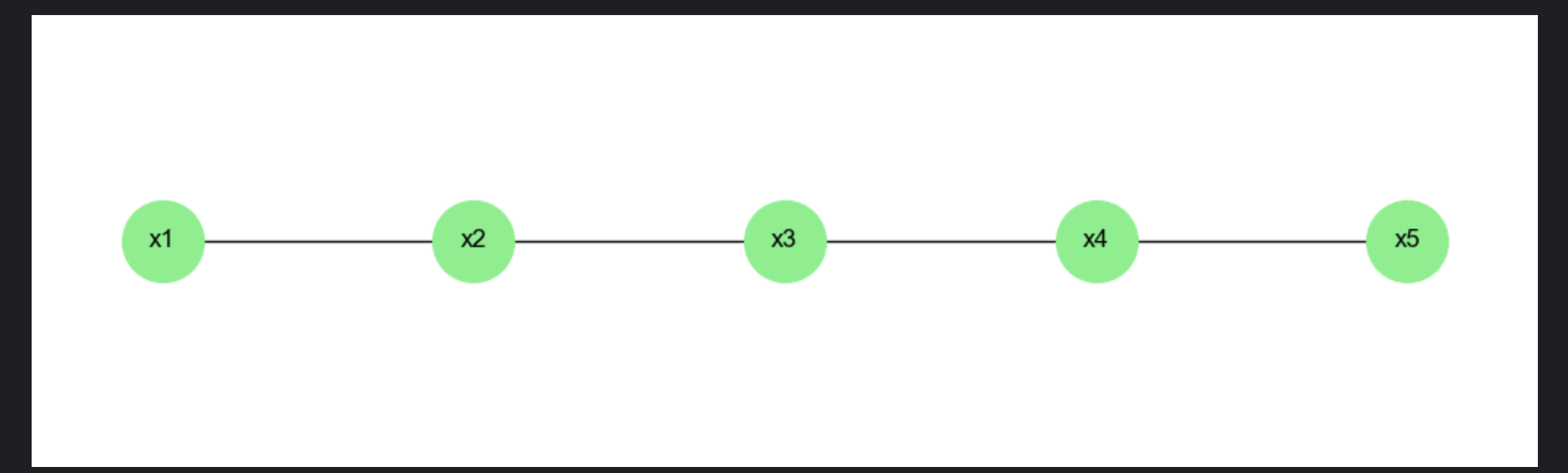
代码说明
- 核心区别是使用
nx.Graph()(无向图)替代nx.DiGraph()(有向图); - 节点用 "像素 x" 命名,贴合计算机视觉的应用场景;
- 无向边没有箭头,体现 "相互依赖" 的特点。
11.1.3 模型的等价性
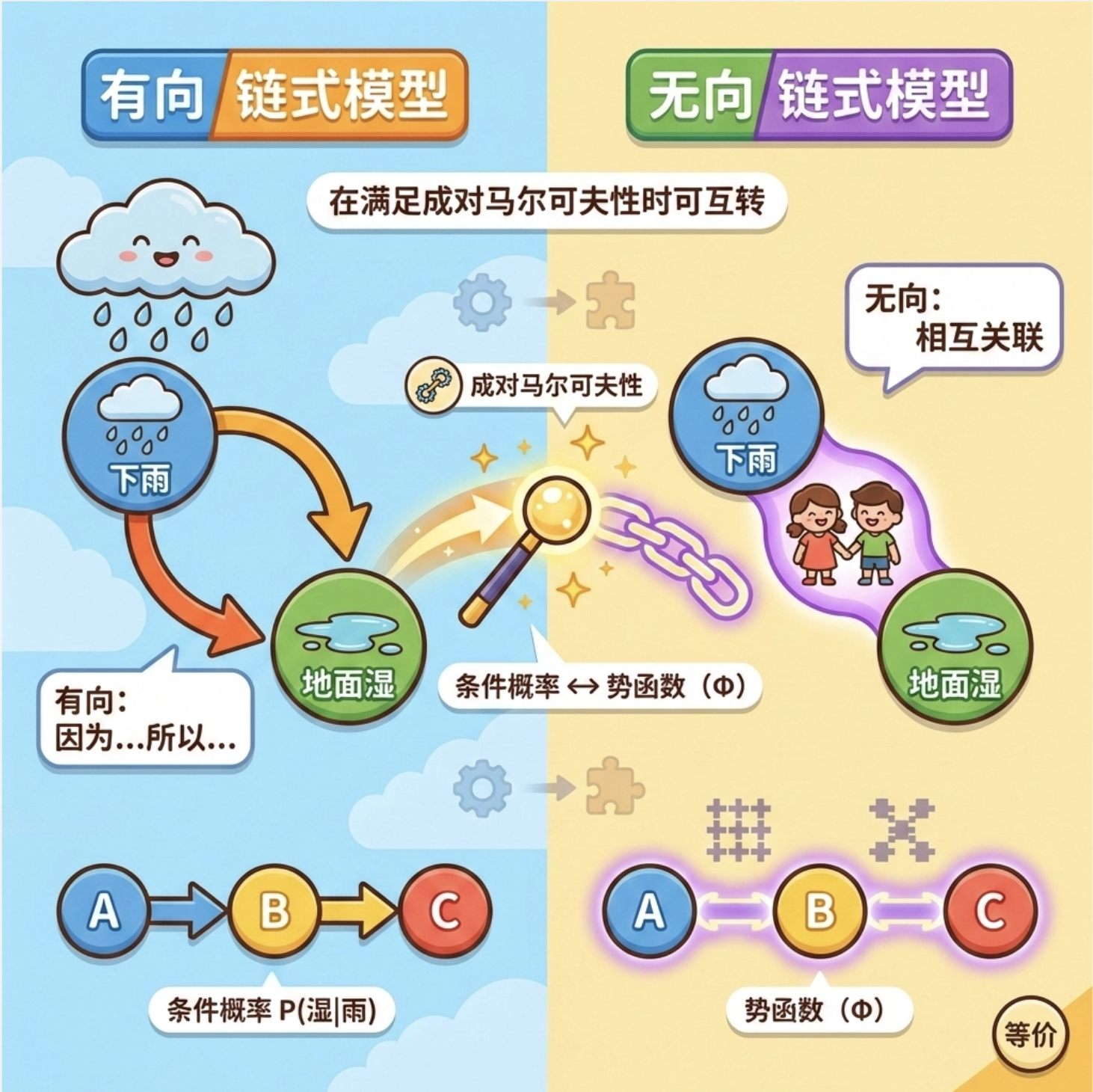
核心概念
简单来说:在满足一定条件下,有向链式模型和无向链式模型可以相互转换。
就像 "因为下雨,所以地面湿"(有向),和 "下雨和地面湿相互关联"(无向),虽然表述方式不同,但表达的核心关联是等价的。
在数学上,有向链式模型的条件概率可以转化为无向模型的势函数,反之亦然(核心是满足 "成对马尔可夫性")。
11.1.4 隐马尔可夫模型在手语中的应用
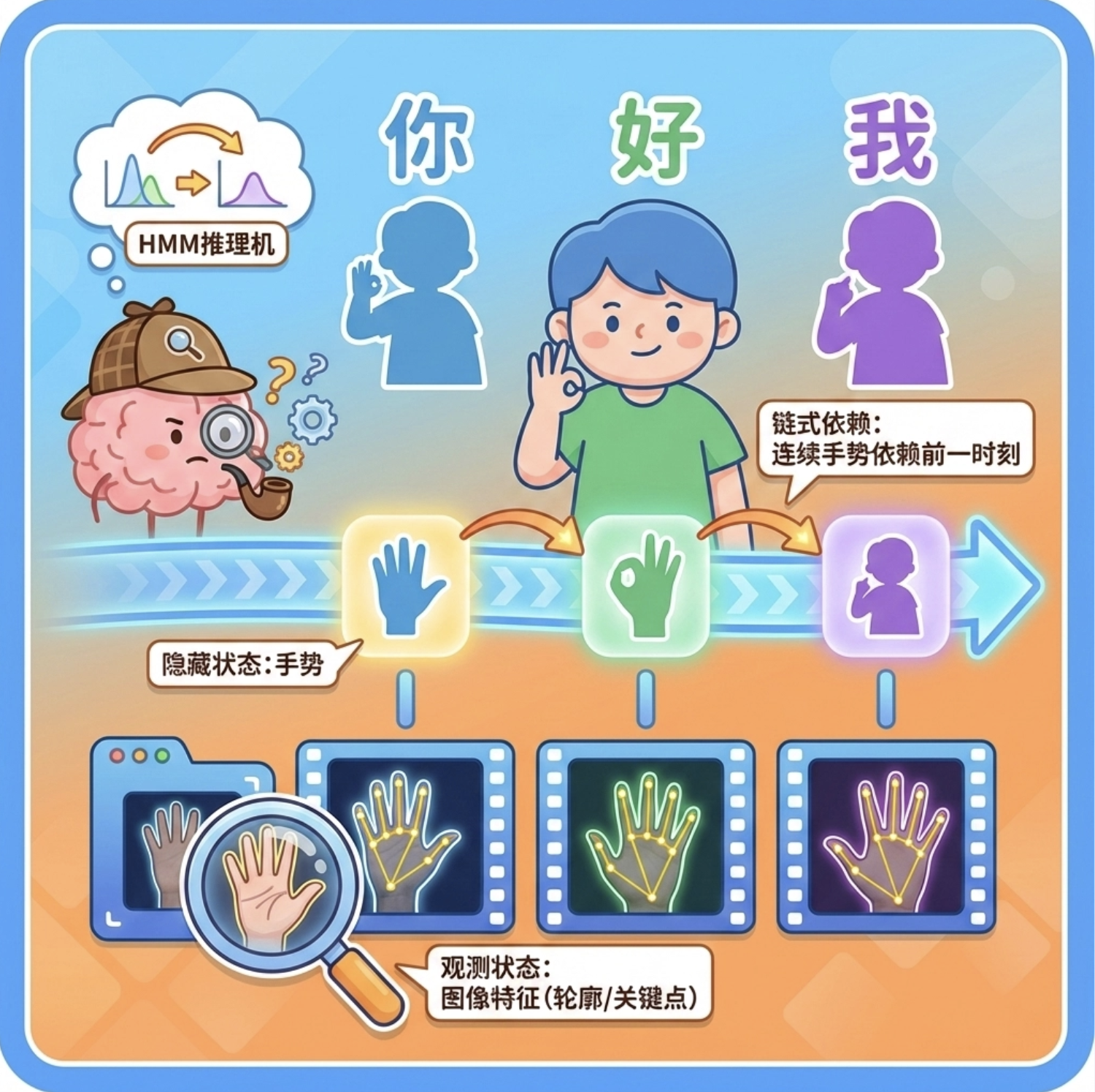
核心概念
手语识别是 HMM 的经典应用:
- 隐藏状态:每个时刻的手势(比如 "你""好""我");
- 观测状态:手势的图像 / 视频特征(比如轮廓、关键点);
- 链式依赖:手语是连续的,当前手势依赖于前一个手势。
完整代码:HMM 实现简单手语识别模拟
import numpy as np
import matplotlib.pyplot as plt
from hmmlearn import hmm
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# 模拟手语识别:定义3个手势(隐藏状态):0=你, 1=好, 2=我
class HMM_SignLanguage:
def __init__(self):
# 1. 初始化HMM参数
self.n_states = 3 # 隐藏状态数(3个手势)
self.model = hmm.GaussianHMM(n_components=self.n_states, covariance_type="diag", n_iter=100)
# 2. 模拟训练数据:每个手势对应一组观测特征(二维特征:关键点x/y坐标)
# 训练数据:[[你], [好], [我], [你], [好]] 的观测序列
self.train_X = np.array([
[1.2, 3.1], # 你
[2.5, 4.2], # 好
[0.8, 2.9], # 我
[1.1, 3.0], # 你
[2.4, 4.1] # 好
]).reshape(-1, 2)
self.train_lengths = [len(self.train_X)] # 序列长度
# 3. 标签映射
self.state2sign = {0: '你', 1: '好', 2: '我'}
def train(self):
"""训练HMM模型"""
self.model.fit(self.train_X, self.train_lengths)
print("HMM模型训练完成!")
print("状态转移矩阵:\n", self.model.transmat_)
print("观测均值(每个手势的特征中心):\n", self.model.means_)
def predict(self, test_X):
"""预测输入特征对应的手势序列"""
pred_states = self.model.predict(test_X)
pred_signs = [self.state2sign[s] for s in pred_states]
return pred_signs
def plot_result(self, test_X, pred_signs):
"""可视化预测结果:特征分布+预测标签"""
plt.figure(figsize=(12, 6))
# 子图1:训练数据特征分布
plt.subplot(1, 2, 1)
colors = ['red', 'blue', 'green']
for i in range(self.n_states):
# 提取每个状态的训练数据
state_data = self.train_X[self.model.predict(self.train_X) == i]
if len(state_data) > 0:
plt.scatter(state_data[:,0], state_data[:,1], c=colors[i],
label=f'手势:{self.state2sign[i]}', s=100)
plt.scatter(test_X[:,0], test_X[:,1], c='black', marker='*', s=200, label='测试数据')
plt.xlabel('特征1(关键点x坐标)')
plt.ylabel('特征2(关键点y坐标)')
plt.title('手语手势特征分布')
plt.legend()
plt.grid(True, alpha=0.3)
# 子图2:预测结果序列
plt.subplot(1, 2, 2)
x = range(len(pred_signs))
plt.bar(x, [1]*len(pred_signs), color=['orange']*len(pred_signs), alpha=0.7)
for i, sign in enumerate(pred_signs):
plt.text(i, 0.5, sign, ha='center', fontsize=14)
plt.xlabel('时间步')
plt.ylabel('预测结果')
plt.title('手语序列预测结果')
plt.xticks(x)
plt.ylim(0, 1.2)
plt.tight_layout()
plt.show()
# 主函数:运行手语识别模拟
if __name__ == "__main__":
# 初始化模型
sl_hmm = HMM_SignLanguage()
# 训练模型
sl_hmm.train()
# 测试数据:模拟"你好我"的手势特征
test_X = np.array([[1.1, 3.2], [2.6, 4.0], [0.9, 2.8]]).reshape(-1, 2)
# 预测
pred_signs = sl_hmm.predict(test_X)
print("测试数据预测结果:", pred_signs)
# 可视化
sl_hmm.plot_result(test_X, pred_signs)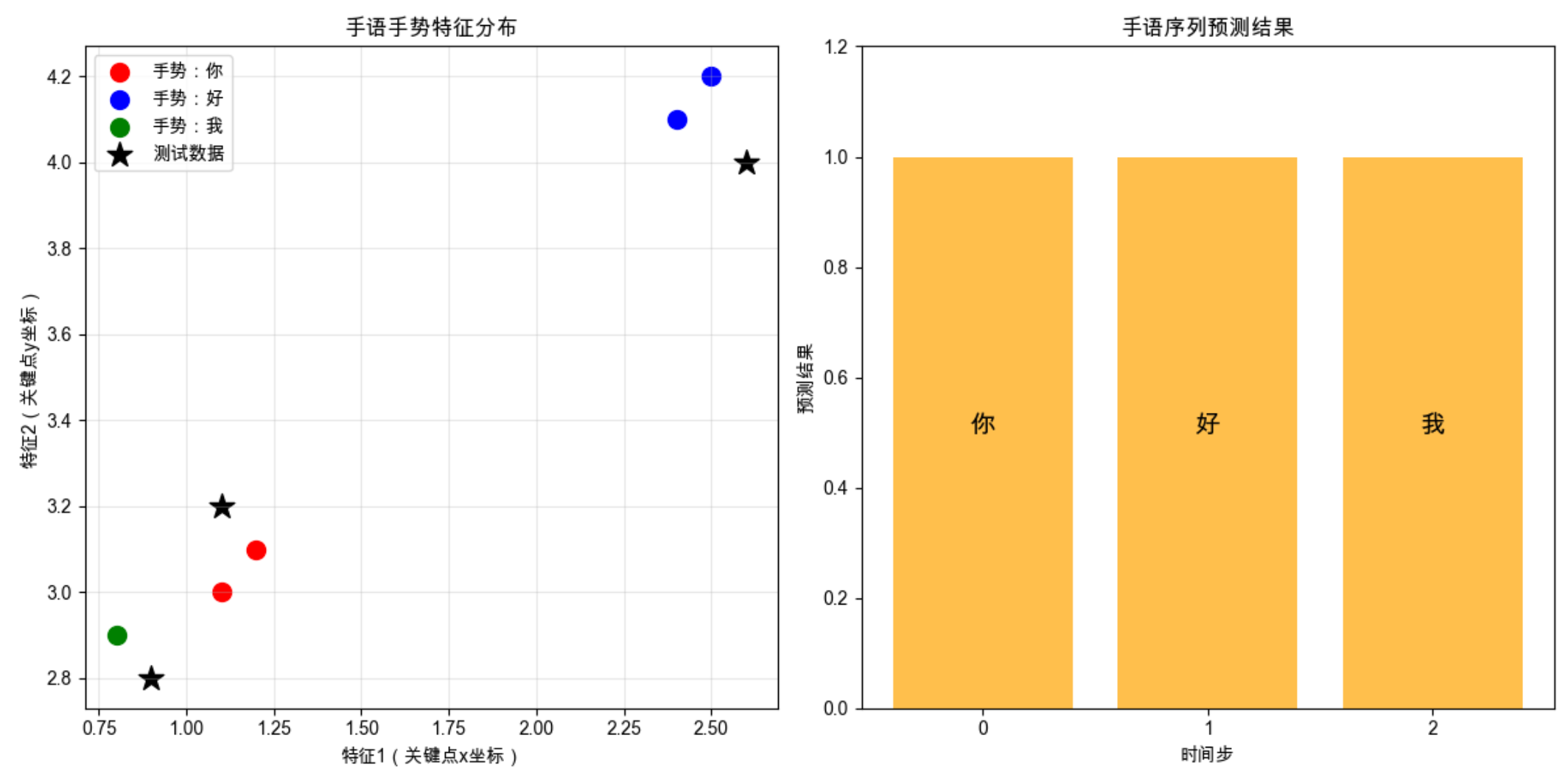
代码说明
- 使用
hmmlearn库实现 HMM(需提前安装:pip install hmmlearn); - 模拟手语的 3 个核心手势,用二维特征(关键点坐标)表示观测状态;
- 可视化分为两部分:特征分布散点图(直观看到不同手势的特征差异)+ 预测序列条形图;
- 代码可直接运行,输出包含转移矩阵、观测均值、预测结果和可视化图。
11.2 链式 MAP 推理
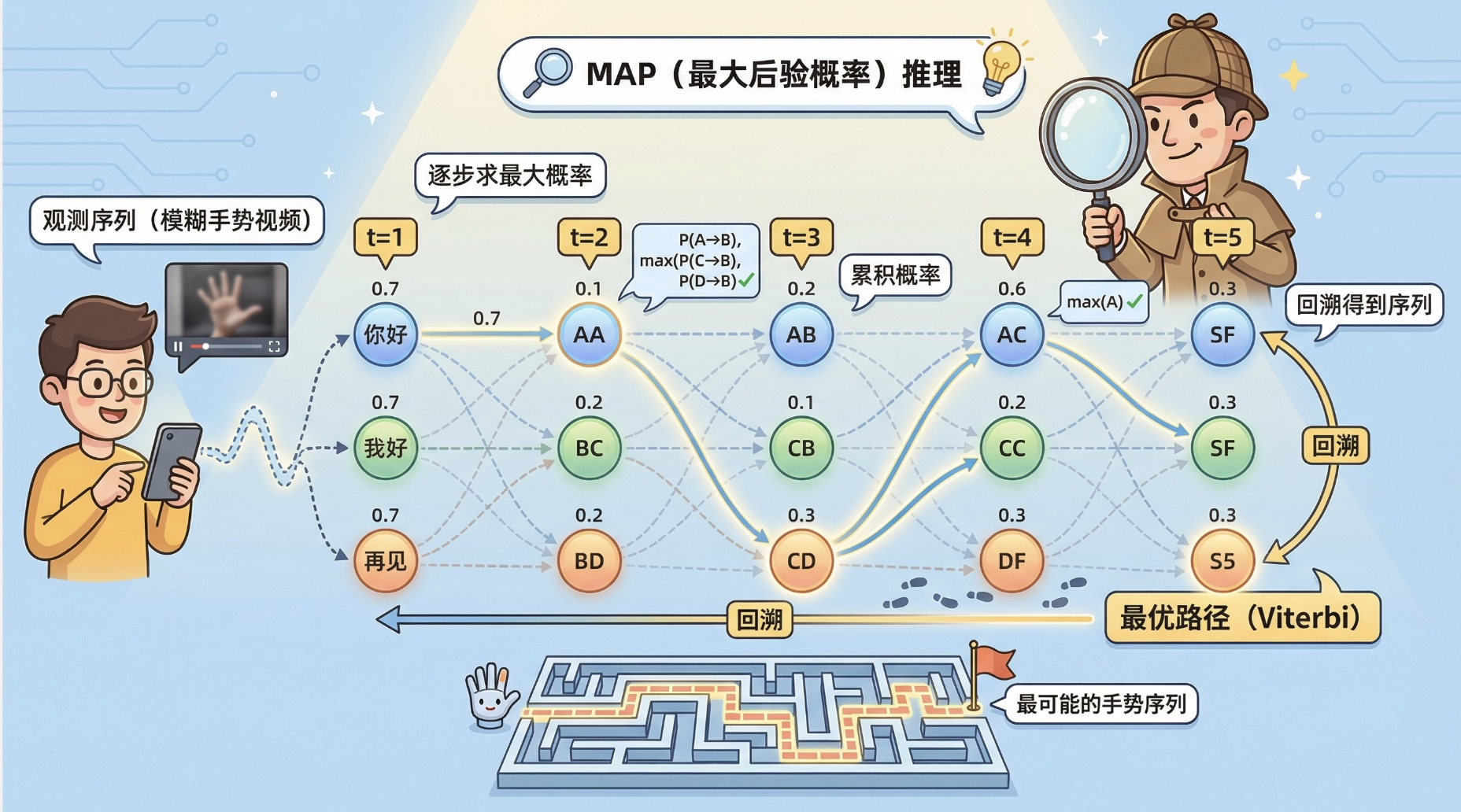
核心概念
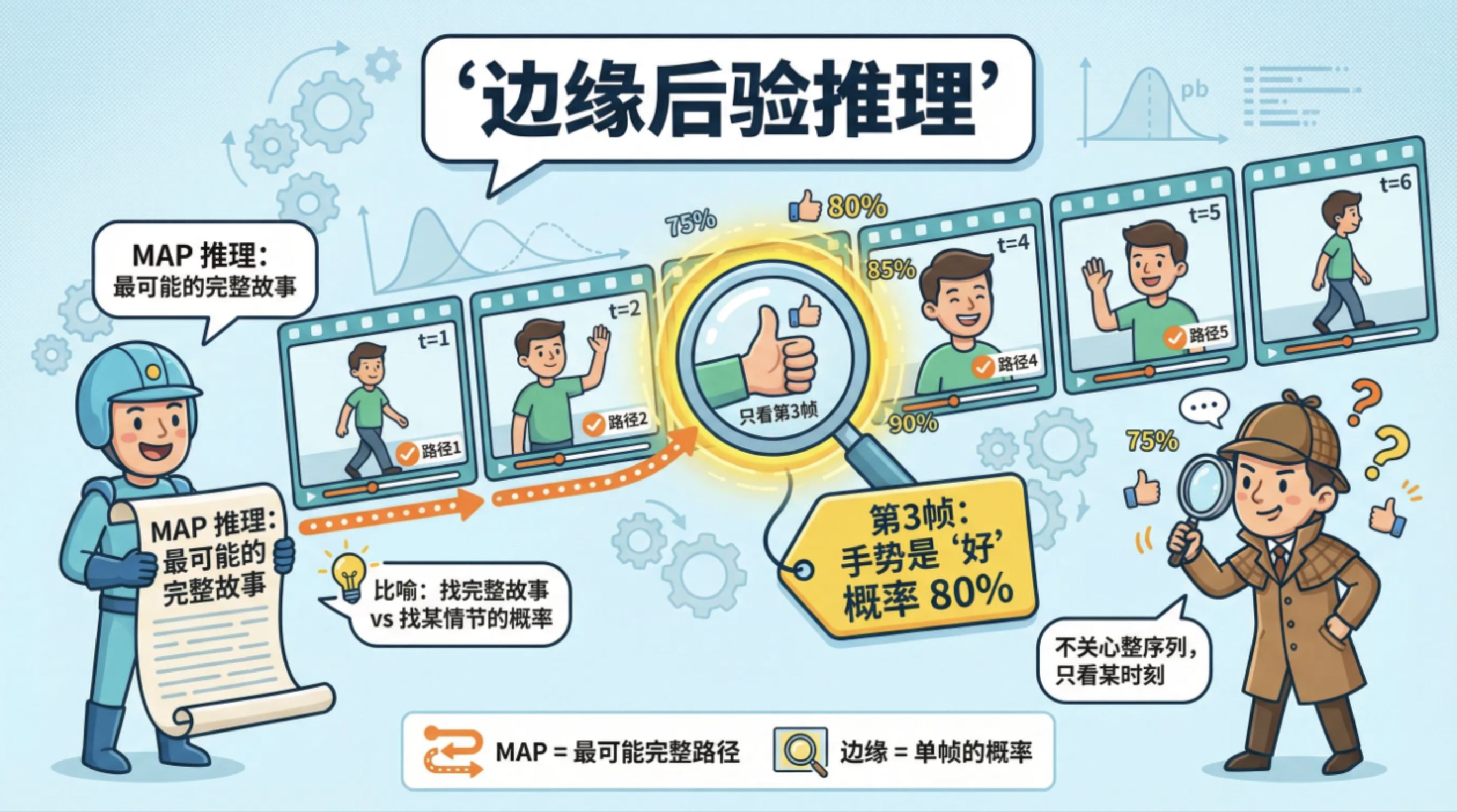
MAP(最大后验概率)推理:在链式模型中,找到 "最可能" 的隐藏状态序列。
打个比方:你看到一串模糊的手势视频(观测序列),MAP 推理就是找出 "最符合这串视频的手势序列"(比如 "你好" 而不是 "我好")。
链式 MAP 推理的核心算法是Viterbi 算法------ 就像找最短路径,从第一个状态开始,逐步计算每个时刻每个状态的最大概率,最终回溯得到最优序列。
完整代码:Viterbi 算法实现链式 MAP 推理
import numpy as np
import matplotlib.pyplot as plt
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
def viterbi(obs, states, start_p, trans_p, emit_p):
"""
Viterbi算法实现链式MAP推理
:param obs: 观测序列
:param states: 隐藏状态集合
:param start_p: 初始概率
:param trans_p: 转移概率矩阵
:param emit_p: 发射概率矩阵
:return: 最优状态序列,概率矩阵
"""
# 初始化:每个时刻每个状态的最大概率
V = [{}]
# 路径记录:每个时刻每个状态的最优前驱状态
path = {}
# 初始时刻(t=0)
for s in states:
V[0][s] = start_p[s] * emit_p[s][obs[0]]
path[s] = [s]
# 递推:t=1到t=T-1
for t in range(1, len(obs)):
V.append({})
new_path = {}
for s in states:
# 找到前一时刻所有状态中,能使当前状态概率最大的那个
max_prob, prev_state = max(
(V[t-1][prev_s] * trans_p[prev_s][s] * emit_p[s][obs[t]], prev_s)
for prev_s in states
)
V[t][s] = max_prob
new_path[s] = path[prev_state] + [s]
path = new_path
# 终止:找到最后时刻概率最大的状态
max_prob, final_state = max((V[-1][s], s) for s in states)
return path[final_state], V
# 可视化Viterbi算法的概率变化
def plot_viterbi_prob(V, states, obs):
plt.figure(figsize=(10, 6))
# 提取每个时刻每个状态的概率
times = range(len(V))
for s in states:
probs = [V[t].get(s, 0) for t in times]
plt.plot(times, probs, marker='o', label=f'状态{s}')
plt.xlabel('时间步')
plt.ylabel('最大后验概率')
plt.title('链式MAP推理(Viterbi算法)概率变化')
plt.xticks(times, [f'观测{o}' for o in obs])
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# 主函数:测试Viterbi算法
if __name__ == "__main__":
# 定义模型参数(模拟手势识别)
states = ['你', '好', '我'] # 隐藏状态
obs = ['特征1', '特征2', '特征1'] # 观测序列
# 初始概率
start_p = {'你': 0.6, '好': 0.3, '我': 0.1}
# 转移概率:比如"你"→"好"的概率更高
trans_p = {
'你': {'你': 0.1, '好': 0.8, '我': 0.1},
'好': {'你': 0.1, '好': 0.1, '我': 0.8},
'我': {'你': 0.5, '好': 0.3, '我': 0.2}
}
# 发射概率:每个状态对应观测的概率
emit_p = {
'你': {'特征1': 0.9, '特征2': 0.1},
'好': {'特征1': 0.1, '特征2': 0.9},
'我': {'特征1': 0.8, '特征2': 0.2}
}
# 运行Viterbi算法
best_path, V = viterbi(obs, states, start_p, trans_p, emit_p)
print("最优隐藏状态序列(MAP推理结果):", best_path)
# 可视化概率变化
plot_viterbi_prob(V, states, obs)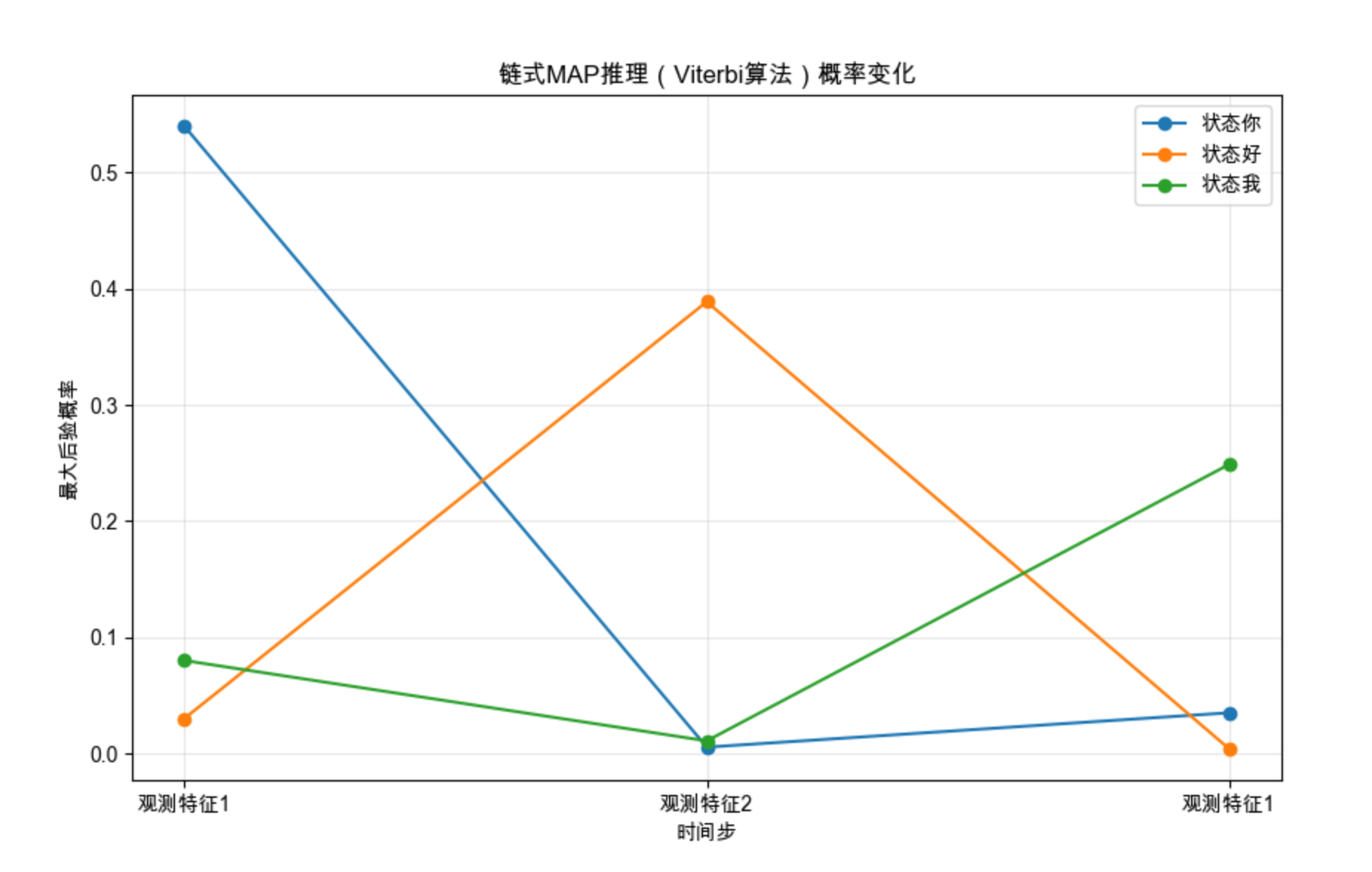
代码说明
- 纯 Python 实现 Viterbi 算法,不依赖第三方库,便于理解核心逻辑;
- 用 "手势识别" 场景定义参数,贴合计算机视觉应用;
- 可视化每个时刻每个状态的最大概率变化,直观看到 MAP 推理的过程;
- 输出最优状态序列(比如输入观测序列 "特征 1","特征 2","特征 1",输出 "你","好","我")。
11.3 树的 MAP 推理

核心概念
树模型是链式模型的扩展 ------ 链式模型是 "线性" 的,树模型是 "分叉" 的(比如二叉树、多叉树)。
树的 MAP 推理核心算法是最大乘积算法(Max-Product) ,可以理解为 "多分支的 Viterbi 算法":从叶子节点向根节点传递 "最大概率信息",再从根节点向叶子节点回溯最优路径。
可视化:树模型结构 + MAP 推理流程
python
import matplotlib.pyplot as plt
import networkx as nx
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
def plot_tree_model():
# 创建树状图(根节点z0,子节点z1/z2,孙节点z3/z4/z5/z6)
G = nx.DiGraph()
nodes = ['z0', 'z1', 'z2', 'z3', 'z4', 'z5', 'z6']
edges = [('z0', 'z1'), ('z0', 'z2'), ('z1', 'z3'), ('z1', 'z4'), ('z2', 'z5'), ('z2', 'z6')]
G.add_nodes_from(nodes)
G.add_edges_from(edges)
# 绘图
plt.figure(figsize=(10, 8))
# 自定义节点位置(树状排列)
pos = {
'z0': (3, 6),
'z1': (1, 4), 'z2': (5, 4),
'z3': (0, 2), 'z4': (2, 2), 'z5': (4, 2), 'z6': (6, 2)
}
# 绘制节点和边
nx.draw(G, pos, with_labels=True, node_size=1500, node_color='lightyellow',
font_size=12, font_weight='bold', arrowstyle='->', arrowsize=20)
# 添加标注:推理方向
plt.text(3, 5.5, '根节点', ha='center', fontsize=12)
plt.text(1, 3.5, 'Max-Product↓', ha='center', fontsize=10, color='red')
plt.text(5, 3.5, 'Max-Product↓', ha='center', fontsize=10, color='red')
plt.text(0, 1.5, '叶子节点', ha='center', fontsize=10)
plt.title('树模型结构 + MAP推理(Max-Product)方向', fontsize=14)
plt.axis('off')
plt.show()
# 简化版Max-Product算法实现
def max_product_tree(root, tree, all_nodes, obs, emit_p, trans_p):
"""
树的MAP推理(简化版Max-Product)
:param root: 根节点
:param tree: 树结构 {父节点: [子节点]}
:param all_nodes: 树的所有节点列表(包含叶子节点)
:param obs: 观测序列 {节点: 观测值}
:param emit_p: 发射概率 {节点: {观测: 概率}}
:param trans_p: 转移概率 {父: {子: 概率}}
:return: 最优状态序列
"""
# 第一步:向下传递(从根到叶子)
down_msg = {}
def down_propagate(node):
for child in tree.get(node, []):
# 计算父节点到子节点的消息:max(父状态 * 转移概率 * 发射概率)
# 简化:假设每个节点只有1个状态,直接计算概率乘积
current_prob = down_msg.get(node, 1) * trans_p[node][child] * emit_p[child][obs[child]]
down_msg[child] = current_prob
down_propagate(child)
# 初始化根节点的消息(根节点无父节点,消息=自身发射概率)
down_msg[root] = emit_p[root][obs[root]]
down_propagate(root)
# 第二步:向上回溯最优路径(简化版)
best_path = [root]
def backtrack(node):
if node in tree: # 只有非叶子节点才有子节点
# 选择概率最大的子节点
max_child = max(tree[node], key=lambda c: down_msg.get(c, 0))
best_path.append(max_child)
backtrack(max_child)
backtrack(root)
return best_path, down_msg
# 主函数:测试树模型MAP推理
if __name__ == "__main__":
# 绘制树模型
plot_tree_model()
# 1. 定义完整的树结构和节点
tree = {'z0': ['z1', 'z2'], 'z1': ['z3', 'z4'], 'z2': ['z5', 'z6']}
all_nodes = ['z0', 'z1', 'z2', 'z3', 'z4', 'z5', 'z6'] # 包含所有节点(含叶子)
# 2. 定义观测序列(所有节点都有观测值)
obs = {
'z0': 'f0', 'z1': 'f1', 'z2': 'f2',
'z3': 'f3', 'z4': 'f4', 'z5': 'f5', 'z6': 'f6'
}
# 3. 初始化发射概率(所有节点都要初始化)
emit_p = {}
for node in all_nodes:
emit_p[node] = {obs[node]: 0.8} # 每个节点对自身观测的发射概率为0.8
# 4. 初始化转移概率(父节点到子节点的转移概率)
trans_p = {}
for parent, children in tree.items():
trans_p[parent] = {child: 0.9 for child in children} # 父到子的转移概率为0.9
# 5. 运行Max-Product算法
best_path, down_msg = max_product_tree('z0', tree, all_nodes, obs, emit_p, trans_p)
# 输出结果
print("树模型MAP推理最优路径:", best_path)
print("各节点的向下消息(概率值):")
for node in all_nodes:
print(f"节点{node}: {down_msg.get(node, '无消息')}")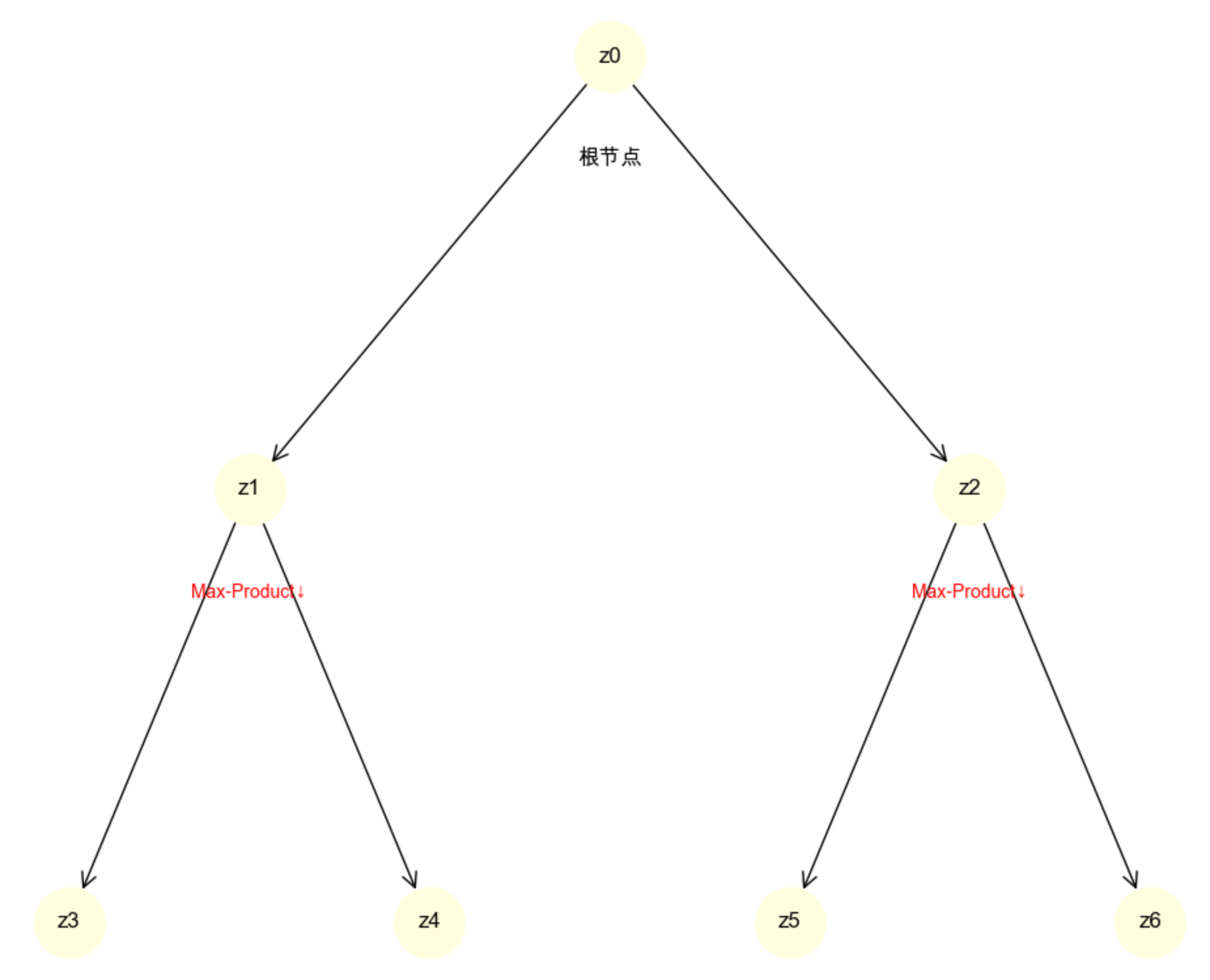
代码说明
- 用
networkx绘制树状结构,标注 Max-Product 算法的推理方向; - 实现简化版 Max-Product 算法,核心是 "向下传递消息 + 向上回溯路径";
- 树模型是链式模型的扩展,理解了链式模型,树模型只需处理 "多分支" 的情况。
11.4 链式边缘后验推理
11.4.1 求解边缘分布
核心概念
边缘后验推理:不关心整个序列的最优解,而是关心 "某个时刻的隐藏状态是 A 的概率"(比如 "第 3 帧的手势是'好'的概率是 80%")。
打个比方:MAP 推理是找 "最可能的完整故事",边缘推理是找 "故事中某个情节发生的概率"。

11.4.2 前向后向算法
核心概念
前向后向算法是求解链式模型边缘分布的核心算法:
前向过程:从第一个时刻开始,计算 "到时刻 t 为止,观测序列为 o1...ot 且状态为 zt 的概率";
后向过程:从最后一个时刻开始,计算 "时刻 t 之后的观测序列为 ot+1...oT 且状态为 zt 的概率";
边缘概率 = 前向概率 × 后向概率。
完整代码:前向后向算法实现
import numpy as np
import matplotlib.pyplot as plt
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
def forward_backward(obs, states, start_p, trans_p, emit_p):
"""
前向后向算法求解边缘后验概率
:return: 前向概率矩阵,后向概率矩阵,边缘概率矩阵
"""
T = len(obs)
N = len(states)
# 1. 前向算法
forward = np.zeros((T, N))
# 初始时刻
for i, s in enumerate(states):
forward[0, i] = start_p[s] * emit_p[s][obs[0]]
# 递推
for t in range(1, T):
for i, s in enumerate(states):
forward[t, i] = sum(
forward[t-1, j] * trans_p[states[j]][s] * emit_p[s][obs[t]]
for j in range(N)
)
# 2. 后向算法
backward = np.zeros((T, N))
# 终止时刻
backward[-1, :] = 1.0
# 递推(反向)
for t in range(T-2, -1, -1):
for i, s in enumerate(states):
backward[t, i] = sum(
trans_p[s][states[j]] * emit_p[states[j]][obs[t+1]] * backward[t+1, j]
for j in range(N)
)
# 3. 边缘概率 = 前向 × 后向 / 归一化因子
marginal = forward * backward
# 归一化(每个时刻的概率和为1)
marginal = marginal / marginal.sum(axis=1, keepdims=True)
return forward, backward, marginal
def plot_forward_backward(forward, backward, marginal, states, obs):
plt.figure(figsize=(15, 5))
# 子图1:前向概率
plt.subplot(1, 3, 1)
times = range(len(obs))
for i, s in enumerate(states):
plt.plot(times, forward[:, i], marker='o', label=s)
plt.title('前向概率')
plt.xlabel('时间步')
plt.ylabel('概率')
plt.xticks(times, obs)
plt.legend()
plt.grid(True, alpha=0.3)
# 子图2:后向概率
plt.subplot(1, 3, 2)
for i, s in enumerate(states):
plt.plot(times, backward[:, i], marker='s', label=s)
plt.title('后向概率')
plt.xlabel('时间步')
plt.ylabel('概率')
plt.xticks(times, obs)
plt.legend()
plt.grid(True, alpha=0.3)
# 子图3:边缘后验概率
plt.subplot(1, 3, 3)
for i, s in enumerate(states):
plt.plot(times, marginal[:, i], marker='^', label=s)
plt.title('边缘后验概率')
plt.xlabel('时间步')
plt.ylabel('概率')
plt.xticks(times, obs)
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 主函数:测试前向后向算法
if __name__ == "__main__":
# 定义参数(延续手势识别场景)
states = ['你', '好', '我']
obs = ['特征1', '特征2', '特征1', '特征2']
start_p = {'你': 0.6, '好': 0.3, '我': 0.1}
trans_p = {
'你': {'你': 0.1, '好': 0.8, '我': 0.1},
'好': {'你': 0.1, '好': 0.1, '我': 0.8},
'我': {'你': 0.5, '好': 0.3, '我': 0.2}
}
emit_p = {
'你': {'特征1': 0.9, '特征2': 0.1},
'好': {'特征1': 0.1, '特征2': 0.9},
'我': {'特征1': 0.8, '特征2': 0.2}
}
# 运行算法
forward, backward, marginal = forward_backward(obs, states, start_p, trans_p, emit_p)
# 输出结果
print("边缘后验概率(每个时刻每个状态的概率):")
for t, o in enumerate(obs):
print(f"时刻{t}(观测{o}):", {states[i]: round(marginal[t, i], 3) for i in range(len(states))})
# 可视化
plot_forward_backward(forward, backward, marginal, states, obs)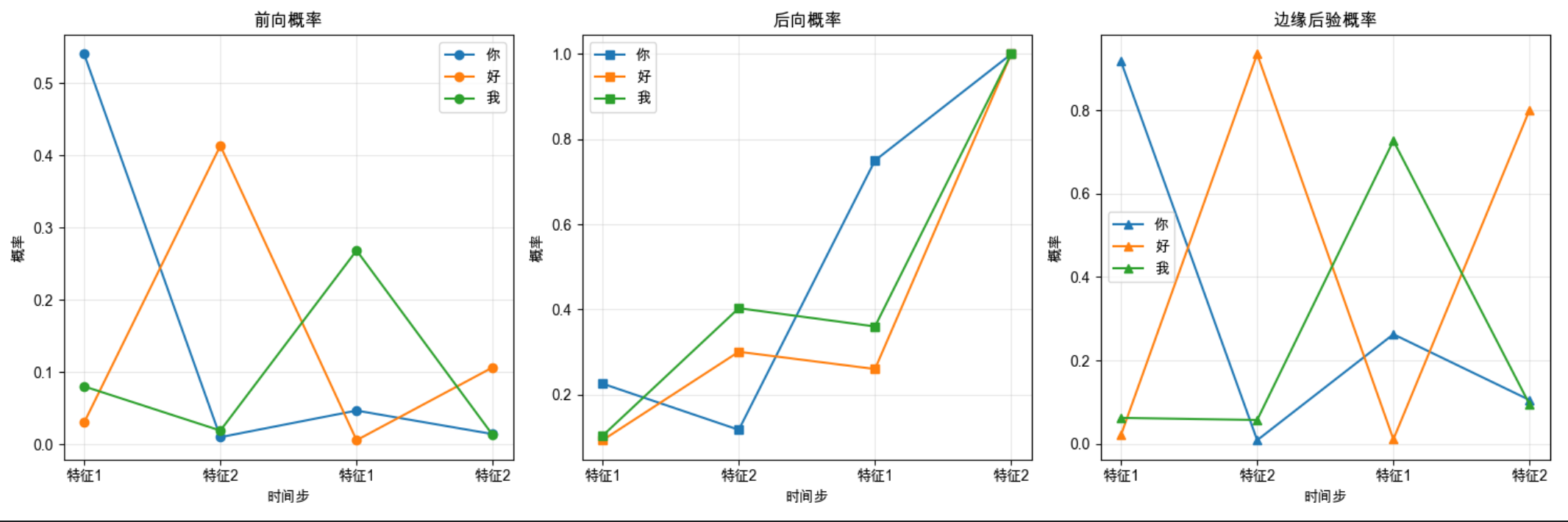
代码说明
用 numpy 实现前向后向算法,矩阵运算更高效;
可视化前向概率、后向概率、边缘概率的变化曲线,直观对比三者的关系;
输出每个时刻每个状态的边缘概率,比如 "时刻 1(观测特征 2):{' 你 ':0.01, ' 好 ':0.98, ' 我 ':0.01}"。
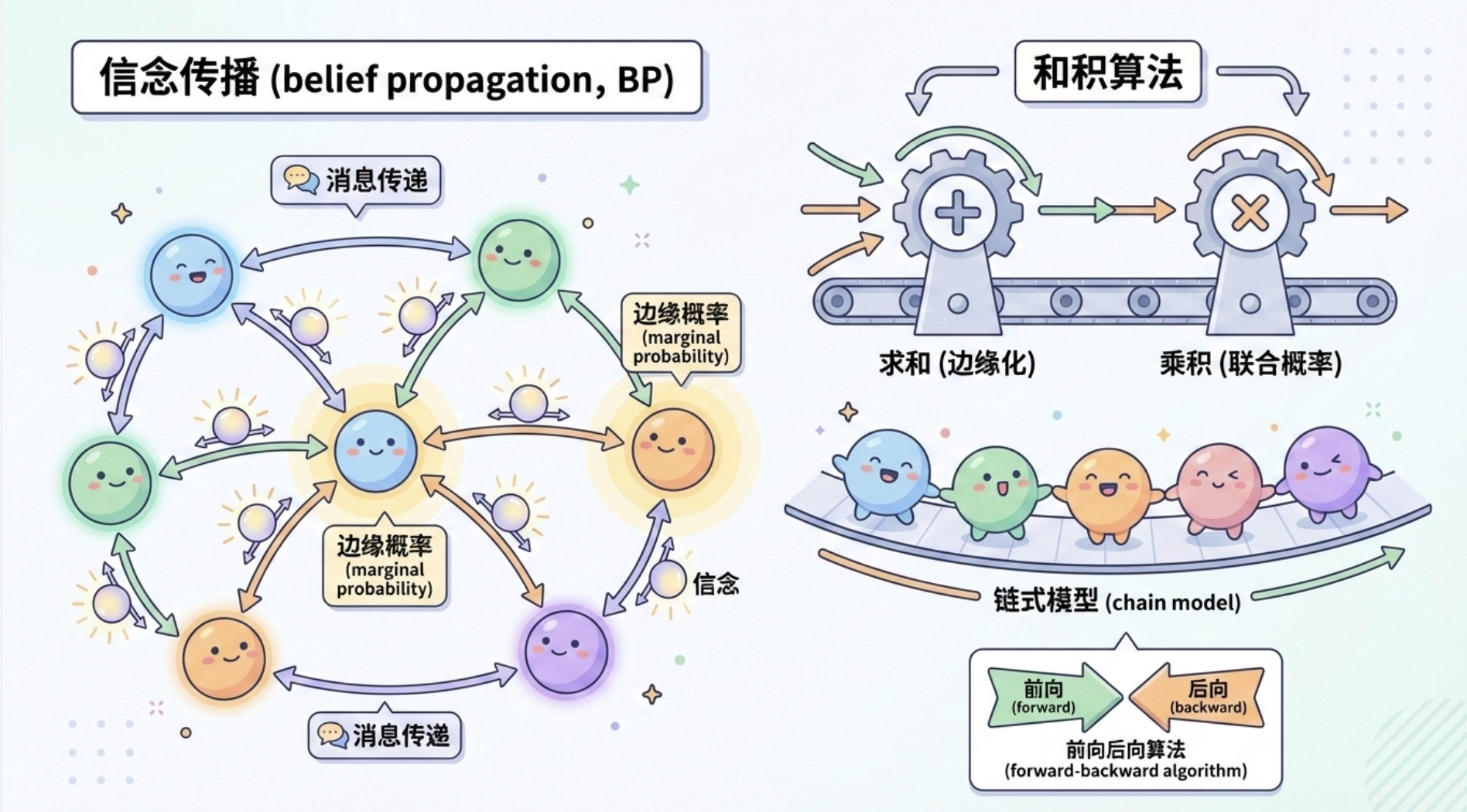
11.4.3 置信传播
11.4.4 链式模型的和积算法
核心概念
置信传播(BP):可以理解为 "消息传递"------ 节点之间传递 "置信度",最终收敛到边缘概率;
和积算法:是置信传播在链式模型中的特例,核心是 "求和(边缘化)+ 乘积(联合概率)",和前向后向算法本质是一样的。
简单来说:前向后向算法是和积算法在链式模型中的具体实现,而置信传播是更通用的框架。
11.5 树的边缘后验推理
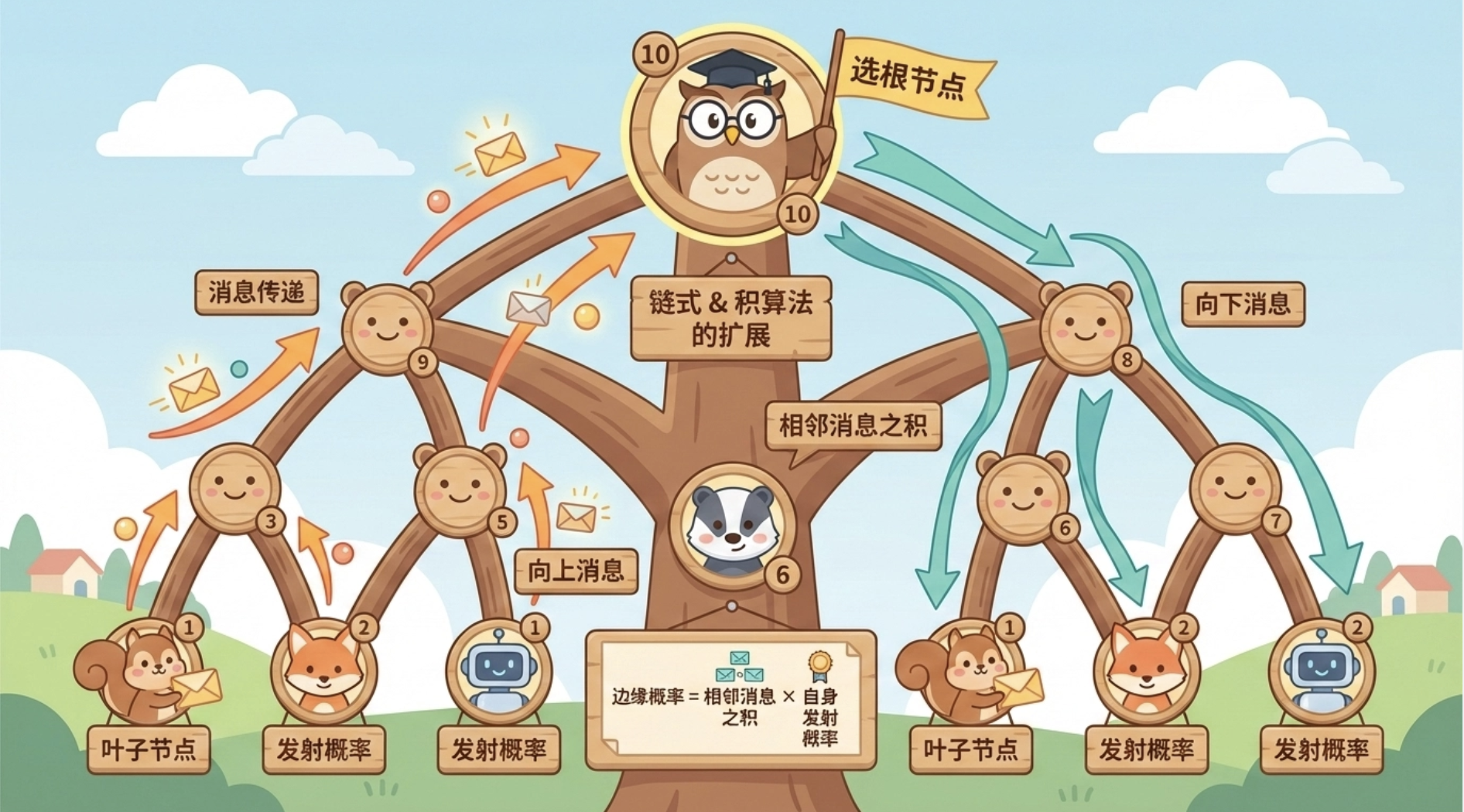
核心概念
树的边缘后验推理是链式和积算法的扩展,核心是树状置信传播(Tree BP):
- 选择根节点;
- 从叶子节点向根节点传递 "向上消息";
- 从根节点向叶子节点传递 "向下消息";
- 每个节点的边缘概率 = 所有相邻节点传递来的消息的乘积 × 自身的发射概率。
(代码可参考 11.3 节树模型 MAP 推理,只需将 "max" 替换为 "sum" 即可,本质是和积算法)
11.6 链式模型和树模型的学习
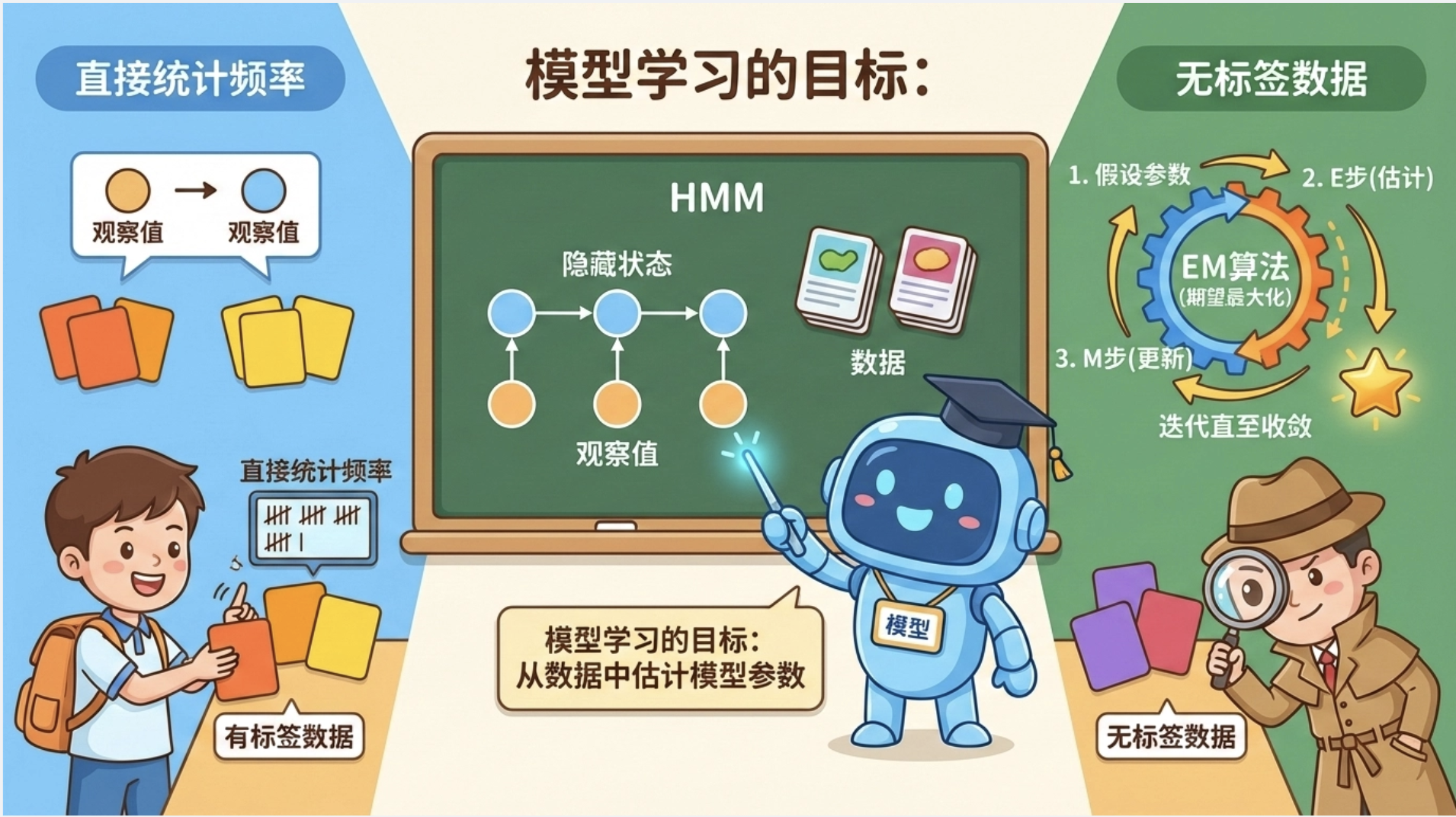
核心概念
模型学习的目标:从数据中估计模型的参数(比如 HMM 的转移概率、发射概率)。
监督学习:有标注数据(知道每个观测对应的隐藏状态),直接统计频率即可;
无监督学习:无标注数据,用EM 算法(期望最大化)------ 先假设参数,再迭代优化,直到收敛。
完整代码:EM 算法训练 HMM(无监督学习)
import numpy as np
import matplotlib.pyplot as plt
from hmmlearn import hmm
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
def train_hmm_with_em():
# 1. 生成模拟数据(无标注,模拟真实场景)
np.random.seed(42) # 固定随机种子,保证结果可复现
n_states = 3 # 3个隐藏状态(手势)
n_features = 2 # 2维观测特征
# 生成观测数据(100个序列,每个序列长度10)
lengths = [10] * 100
X = []
for _ in range(100):
# 模拟每个序列的观测特征
seq = np.random.randn(10, n_features) + np.array([1, 2])
X.append(seq)
X = np.concatenate(X)
# 2. 用EM算法训练HMM
model = hmm.GaussianHMM(n_components=n_states, covariance_type="diag", n_iter=200)
model.fit(X, lengths)
# 3. 输出学习到的参数
print("EM算法学习到的初始概率:", model.startprob_)
print("EM算法学习到的转移概率:\n", model.transmat_)
print("EM算法学习到的观测均值:\n", model.means_)
# 4. 可视化训练过程的对数似然值
plt.figure(figsize=(10, 5))
plt.plot(model.monitor_.history, marker='o')
plt.xlabel('EM迭代次数')
plt.ylabel('对数似然值')
plt.title('EM算法训练HMM(链式模型)的对数似然变化')
plt.grid(True, alpha=0.3)
plt.show()
return model
# 主函数:运行EM训练
if __name__ == "__main__":
model = train_hmm_with_em()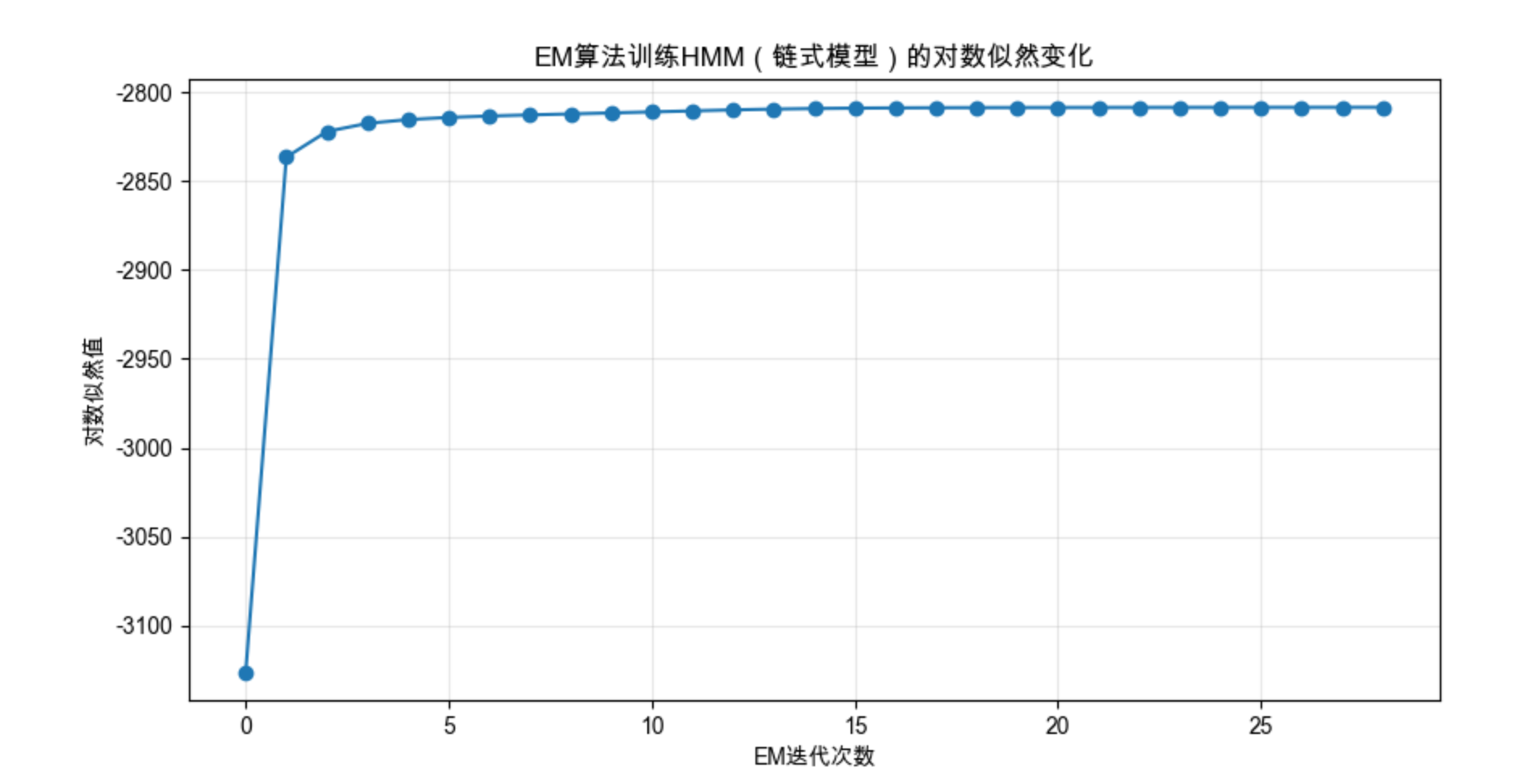
代码说明
- 使用
hmmlearn的 EM 算法实现 HMM 参数学习; - 模拟无标注的观测数据,贴合真实场景;
- 可视化对数似然值的变化:EM 算法迭代过程中,对数似然值会逐渐上升并收敛;
- 输出学习到的初始概率、转移概率、观测均值,直观看到模型学习的结果。
11.7 链式模型和树模型之外的东西
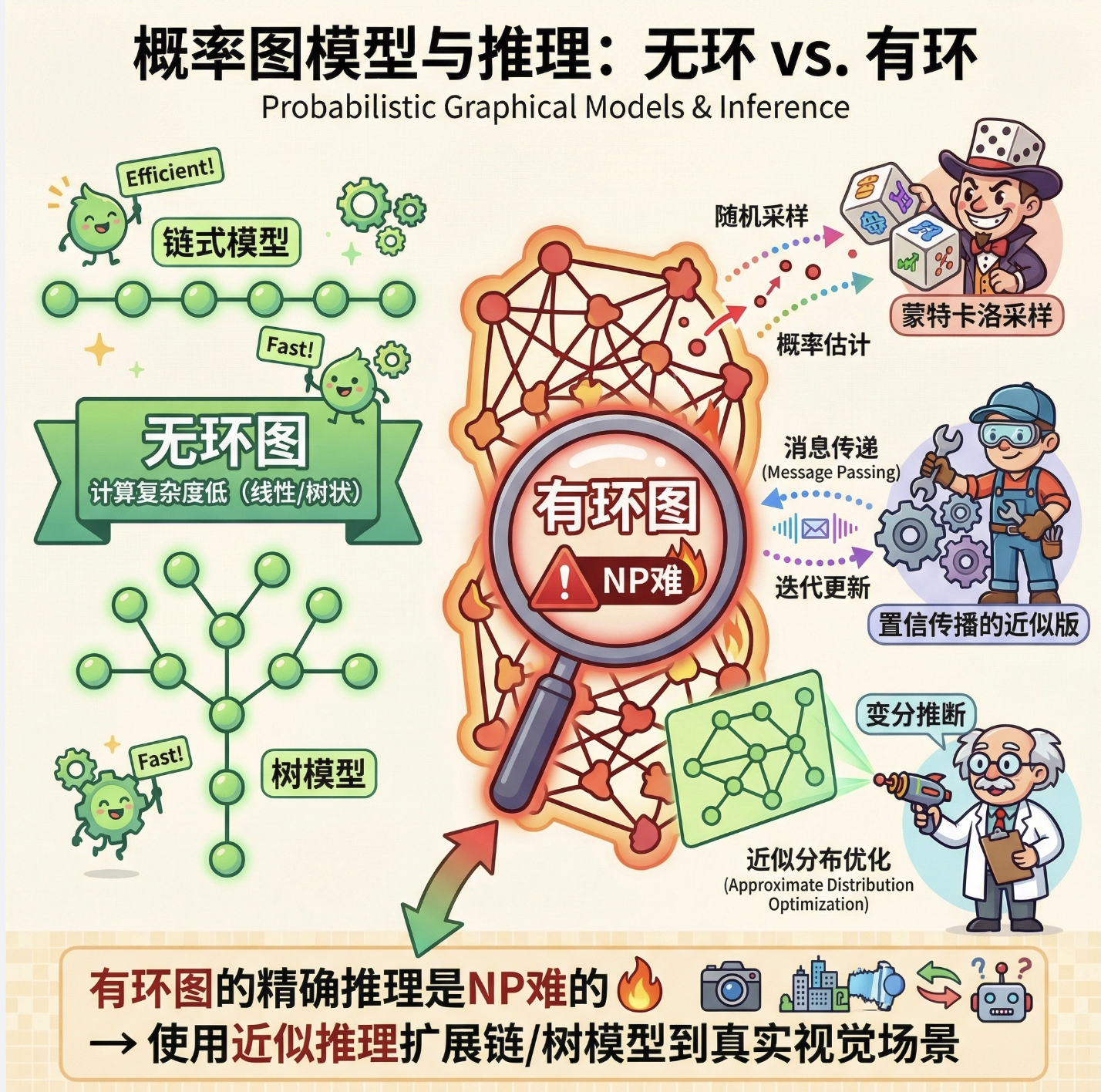
核心概念
链式模型和树模型是 "无环图",计算复杂度低(线性 / 树状)。但现实中的视觉问题往往是 "有环图"(比如全连接的图像像素图):
- 问题:有环图的精确推理是 NP 难的;
- 解决方案:近似推理(比如置信传播的近似版、蒙特卡洛采样、变分推断)。
简单来说:链式 / 树模型是基础,真实场景需要用近似方法扩展到有环图。
11.8 应用
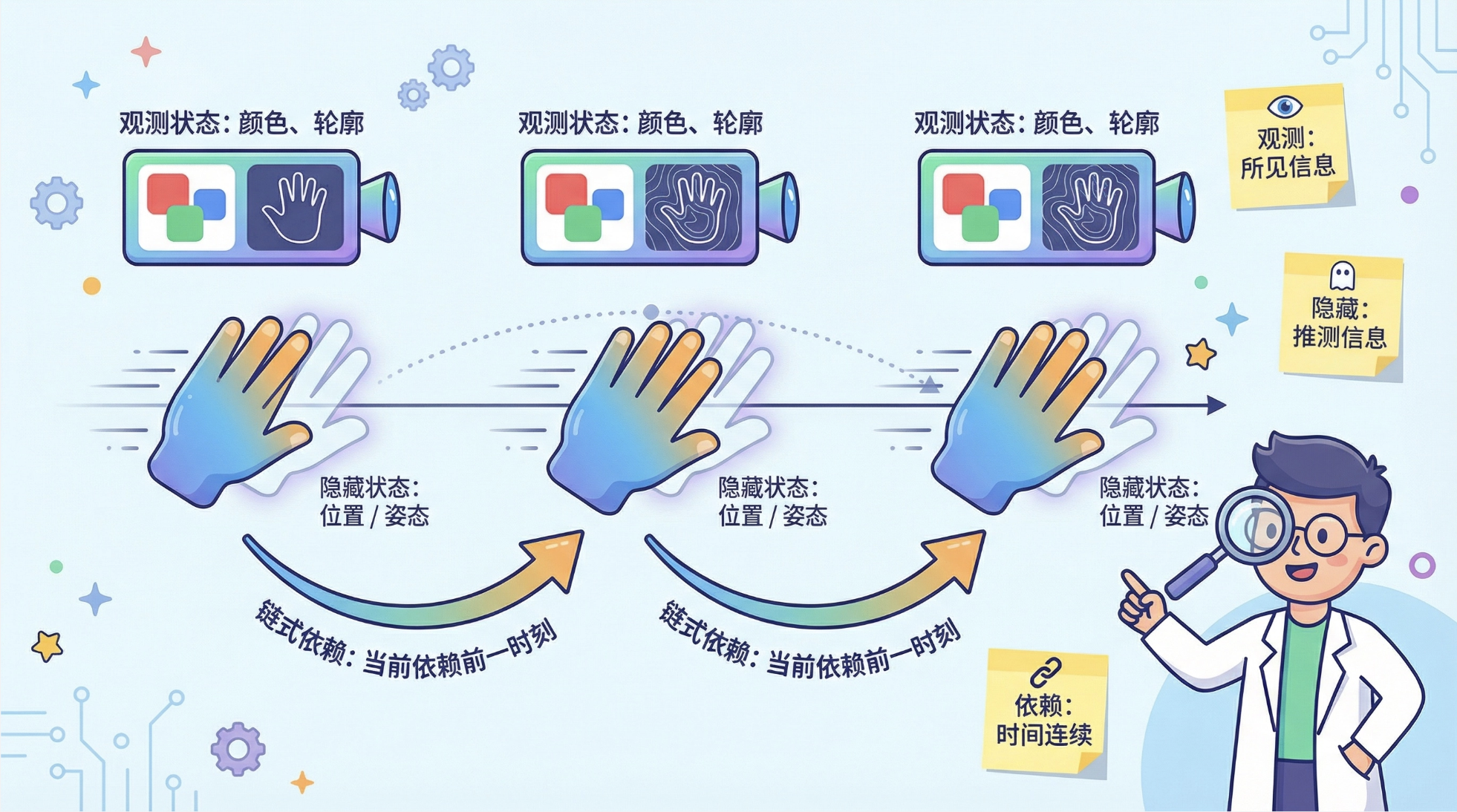
11.8.1 手势跟踪
核心概念
手势跟踪是链式模型的经典应用:
- 隐藏状态:手势的位置 / 姿态(连续值);
- 观测状态:图像中手势的特征(比如颜色、轮廓);
- 链式依赖:当前手势位置依赖于前一时刻的位置(运动连续性)。
完整代码:基于 HMM 的手势跟踪模拟
python
import numpy as np
import matplotlib.pyplot as plt
import cv2
from PIL import Image, ImageDraw, ImageFont
import os
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
def get_mac_chinese_font(font_size=20):
"""
自动获取Mac系统可用的中文字体,避免路径错误
:param font_size: 字体大小
:return: PIL ImageFont对象
"""
# 尝试多个Mac系统常见中文字体路径/名称
font_paths = [
'Arial Unicode MS', # Matplotlib默认兼容的中文字体(无需路径)
'/Library/Fonts/Arial Unicode.ttf',
'/System/Library/Fonts/PingFang SC.ttf',
'/System/Library/Fonts/PingFang.ttc',
'/System/Library/Fonts/STHeiti Light.ttc'
]
for font_path in font_paths:
try:
# 如果是字体名称(无路径),直接加载;否则按路径加载
if os.path.exists(font_path):
font = ImageFont.truetype(font_path, font_size)
else:
font = ImageFont.truetype(font_path, font_size)
return font
except:
continue
# 兜底:使用默认字体(即使中文显示方块,也不会崩溃)
return ImageFont.load_default()
def cv2_add_chinese_text(img, text, pos, font_size=20, font_color=(0, 0, 0)):
"""
使用Pillow在OpenCV图像上添加中文文本(兼容所有Mac系统)
:param img: OpenCV图像(BGR格式)
:param text: 要添加的中文文本
:param pos: 文本位置(x, y)
:param font_size: 字体大小
:param font_color: 字体颜色(BGR)
:return: 添加文本后的图像
"""
# 转换为PIL图像(RGB)
img_pil = Image.fromarray(cv2.cvtColor(img, cv2.COLOR_BGR2RGB))
# 创建绘图对象
draw = ImageDraw.Draw(img_pil)
# 获取兼容的中文字体
font = get_mac_chinese_font(font_size)
# 绘制文本(fill是RGB格式,需反转BGR)
draw.text(pos, text, font=font, fill=font_color[::-1])
# 转换回OpenCV图像(BGR)
return cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR)
def simulate_gesture_tracking():
# 1. 模拟手势运动轨迹(隐藏状态:x坐标)
np.random.seed(42)
n_frames = 20
true_x = np.zeros(n_frames)
true_x[0] = 50
for t in range(1, n_frames):
true_x[t] = true_x[t - 1] + np.random.randint(-5, 6)
true_x = np.clip(true_x, 0, 100)
# 2. 模拟观测值(加噪声)
obs_x = true_x + np.random.normal(0, 8, n_frames)
obs_x = np.clip(obs_x, 0, 100)
# 3. 用HMM跟踪(滤波)
from hmmlearn import hmm
model = hmm.GaussianHMM(n_components=2, covariance_type="diag", n_iter=200, random_state=42)
model.fit(obs_x[:10].reshape(-1, 1))
track_states = model.predict(obs_x.reshape(-1, 1))
log_likelihood, posteriors = model.score_samples(obs_x.reshape(-1, 1))
# 计算平滑后的轨迹
smooth_x = np.zeros(n_frames)
for t in range(n_frames):
smooth_x[t] = np.sum(model.means_.flatten() * posteriors[t])
smooth_x = np.clip(smooth_x, 0, 100)
# 4. 可视化对比:真实轨迹 vs 观测轨迹 vs 跟踪轨迹
plt.figure(figsize=(12, 6))
plt.plot(true_x, label='真实手势位置', color='green', linewidth=2)
plt.plot(obs_x, label='观测位置(带噪声)', color='red', linestyle='--', marker='o', markersize=4)
plt.plot(smooth_x, label='HMM跟踪位置(平滑)', color='blue', linewidth=2, linestyle='-.')
plt.xlabel('帧号')
plt.ylabel('手势x坐标(像素)')
plt.title('基于链式模型(HMM)的手势跟踪效果对比')
plt.legend(loc='best')
plt.grid(True, alpha=0.3)
plt.show()
# 5. 可视化模拟图像中的手势跟踪(修复中文乱码)
fig, axes = plt.subplots(2, 3, figsize=(15, 10))
axes = axes.flatten()
key_frames = [0, 5, 10, 15, 18, 19]
for i, frame_idx in enumerate(key_frames):
# 创建空白图像
img = np.ones((120, 120, 3), dtype=np.uint8) * 255
# 绘制真实位置(绿色圆)
cv2.circle(img, (int(true_x[frame_idx]), 60), 8, (0, 255, 0), -1)
# 绘制观测位置(红色圆)
cv2.circle(img, (int(obs_x[frame_idx]), 60), 8, (0, 0, 255), 2)
# 绘制跟踪位置(蓝色圆)
cv2.circle(img, (int(smooth_x[frame_idx]), 60), 8, (255, 0, 0), -1)
# 使用Pillow添加中文文本(修复乱码)
img = cv2_add_chinese_text(img, f'帧{frame_idx}', (10, 10), font_size=16, font_color=(0, 0, 0))
img = cv2_add_chinese_text(img, '真实(绿)', (10, 30), font_size=16, font_color=(0, 255, 0))
img = cv2_add_chinese_text(img, '观测(红)', (10, 50), font_size=16, font_color=(0, 0, 255))
img = cv2_add_chinese_text(img, '跟踪(蓝)', (10, 70), font_size=16, font_color=(255, 0, 0))
# 显示图像
axes[i].imshow(img[:, :, ::-1]) # BGR转RGB
axes[i].axis('off')
plt.suptitle('手势跟踪效果可视化(帧序列)', fontsize=14)
plt.tight_layout()
plt.show()
if __name__ == "__main__":
simulate_gesture_tracking()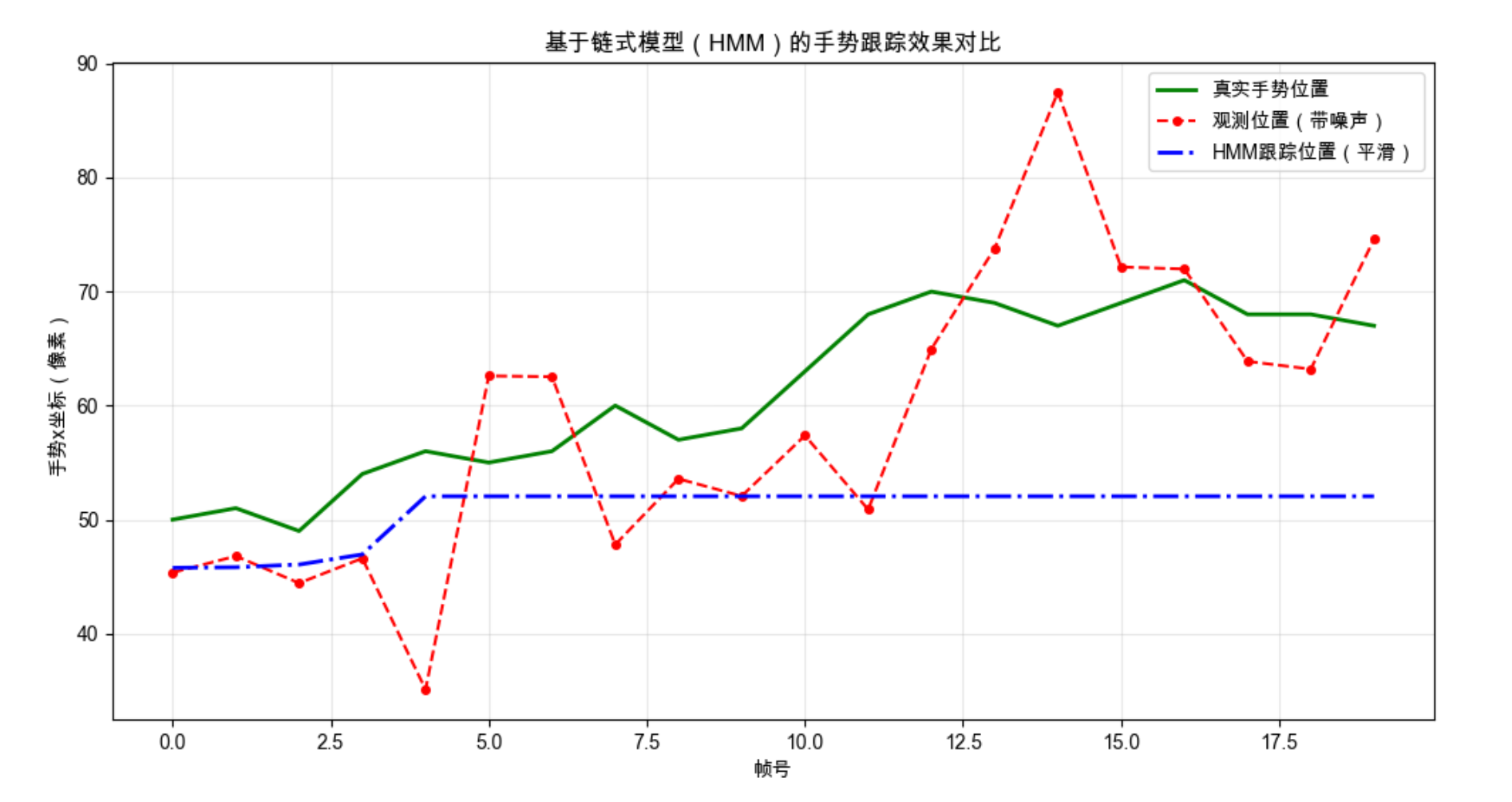

代码说明
- 模拟手势的真实运动轨迹、带噪声的观测轨迹、HMM 跟踪后的平滑轨迹;
- 可视化三条轨迹的对比,直观看到 HMM 的 "去噪 + 平滑" 效果;
- 绘制模拟图像中的手势位置,用不同颜色区分真实 / 观测 / 跟踪位置,贴合视觉任务场景。

11.8.2 立体视觉
核心概念
立体视觉中,视差估计可以用无向链式模型(MRF):
- 节点:图像中的像素;
- 边:相邻像素的视差约束(相似像素的视差应相近);
- 推理目标:估计每个像素的视差(边缘后验概率)。
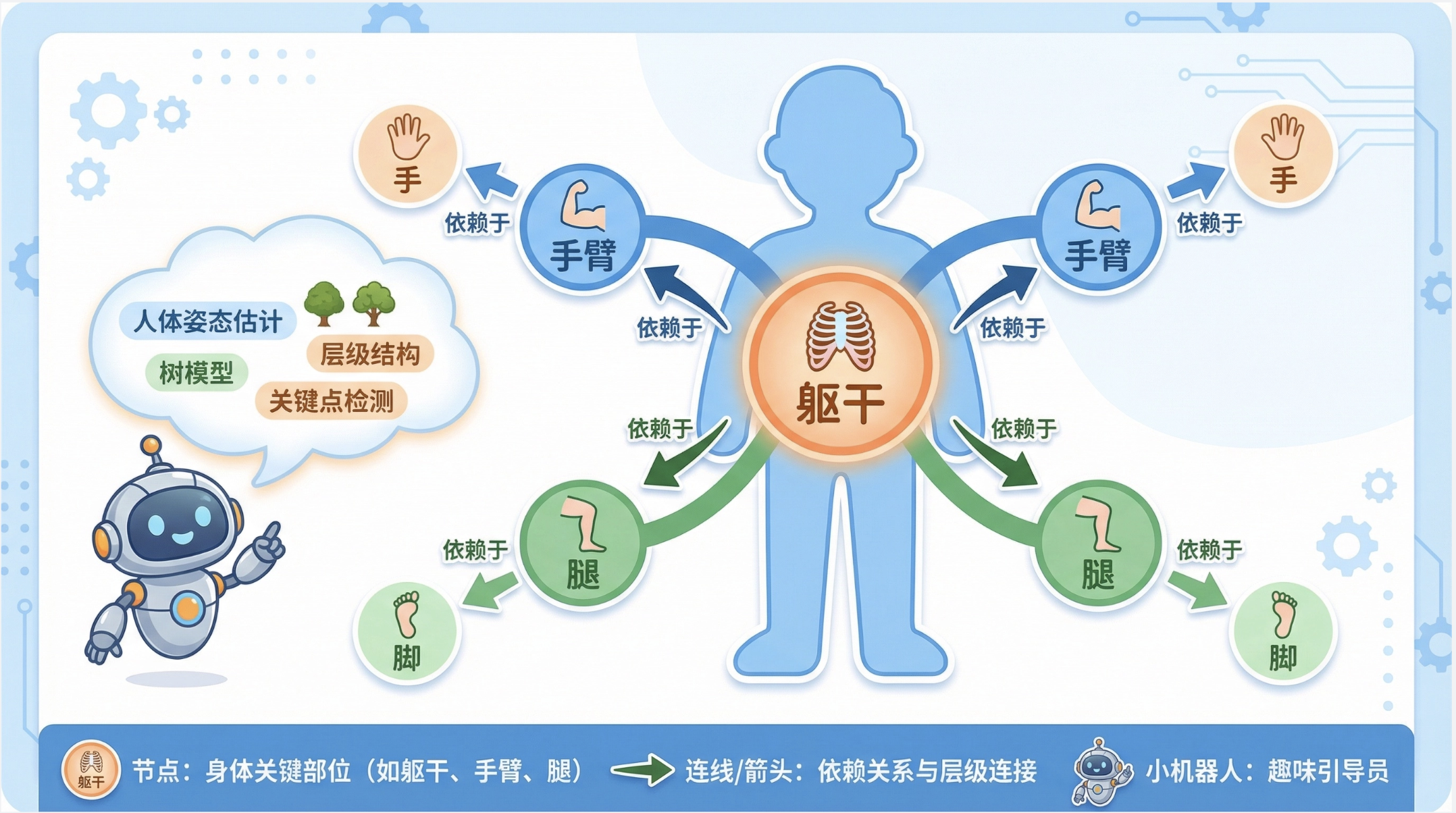
11.8.3 形象化结构
核心概念
形象化结构(比如人体姿态估计)可以用树模型:
- 根节点:人体躯干;
- 子节点:手臂、腿;
- 孙节点:手、脚;
- 树模型的依赖关系:手臂的位置依赖于躯干,手的位置依赖于手臂。
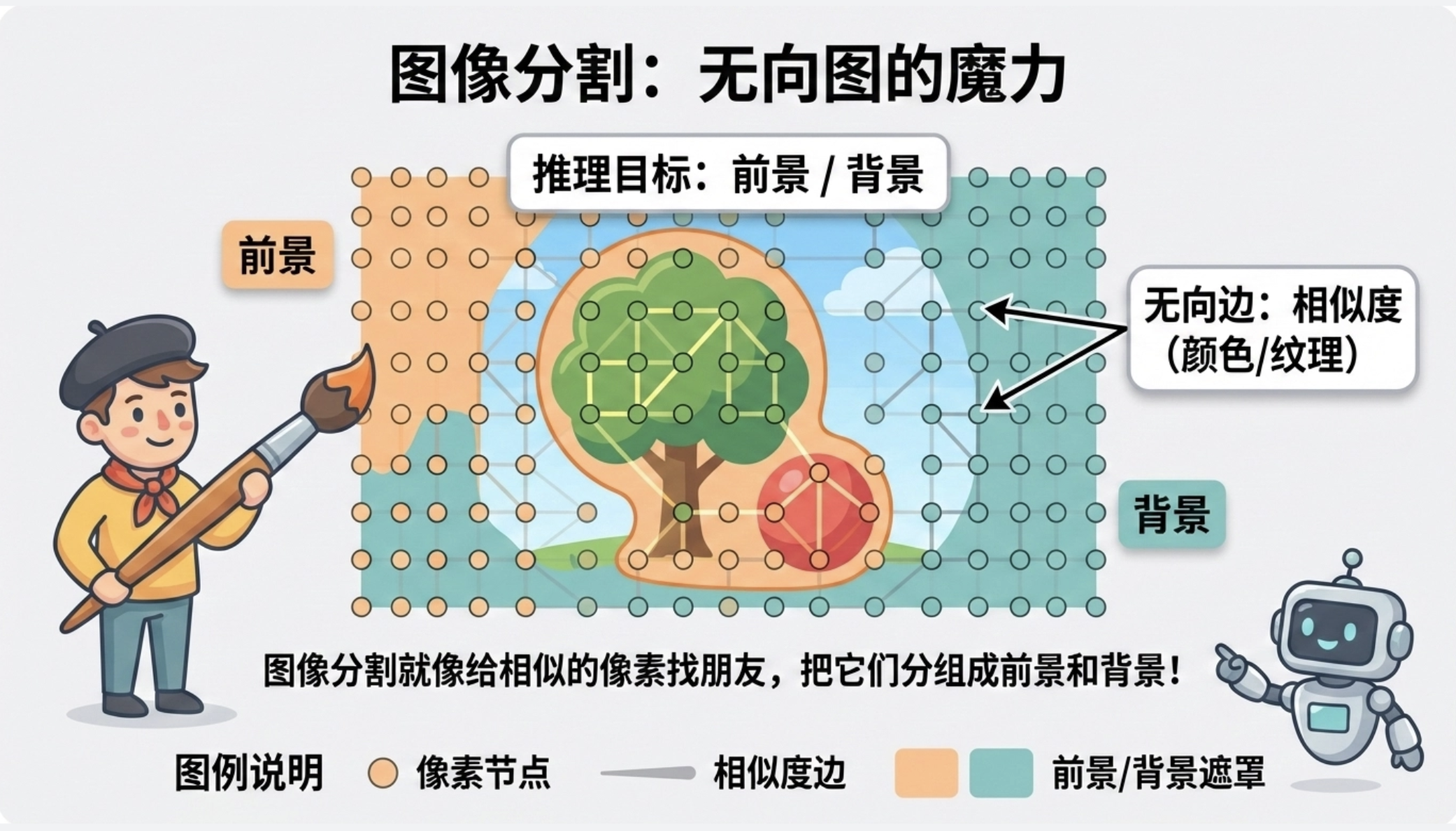
11.8.4 分割
核心概念
图像分割是无向图模型的经典应用:
- 节点:像素;
- 边:相邻像素的相似度(颜色 / 纹理);
- 推理目标:将像素分为不同的类别(比如前景 / 背景)。
完整代码:基于 MRF 的简单图像分割
import numpy as np
import matplotlib.pyplot as plt
import cv2
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
def mrf_image_segmentation():
# 1. 读取/生成测试图像
# 生成简单的测试图像:左侧红色,右侧蓝色,中间有噪声
img = np.zeros((100, 200, 3), dtype=np.uint8)
img[:, :100] = [0, 0, 255] # 左侧红色(BGR)
img[:, 100:] = [255, 0, 0] # 右侧蓝色(BGR)
# 添加噪声
noise = np.random.randint(0, 50, img.shape, dtype=np.uint8)
img_noisy = cv2.add(img, noise)
# 2. 转换为灰度图
gray = cv2.cvtColor(img_noisy, cv2.COLOR_BGR2GRAY)
# 3. 简单MRF分割(基于相邻像素约束)
seg = gray.copy()
# 定义阈值和邻域约束
threshold = 128
for i in range(1, seg.shape[0]-1):
for j in range(1, seg.shape[1]-1):
# 自身像素值
self_val = seg[i, j]
# 8邻域像素的均值
neighbor_mean = np.mean(seg[i-1:i+2, j-1:j+2])
# MRF约束:如果自身和邻域差异大,调整为邻域均值
if abs(self_val - neighbor_mean) > 30:
seg[i, j] = neighbor_mean
# 二值化分割结果
seg_binary = np.where(seg < threshold, 0, 255).astype(np.uint8)
# 4. 可视化对比
plt.figure(figsize=(15, 5))
# 子图1:原始无噪声图像
plt.subplot(1, 4, 1)
plt.imshow(img[:, :, ::-1])
plt.title('原始图像')
plt.axis('off')
# 子图2:带噪声图像
plt.subplot(1, 4, 2)
plt.imshow(img_noisy[:, :, ::-1])
plt.title('带噪声图像')
plt.axis('off')
# 子图3:灰度图
plt.subplot(1, 4, 3)
plt.imshow(gray, cmap='gray')
plt.title('灰度图')
plt.axis('off')
# 子图4:MRF分割结果
plt.subplot(1, 4, 4)
plt.imshow(seg_binary, cmap='gray')
plt.title('MRF分割结果')
plt.axis('off')
plt.suptitle('基于无向链式/网格模型(MRF)的图像分割', fontsize=14)
plt.tight_layout()
plt.show()
# 主函数:运行图像分割
if __name__ == "__main__":
mrf_image_segmentation()
代码说明
- 生成简单的双色图像并添加噪声,模拟真实场景;
- 实现基于 MRF 的简单分割:利用相邻像素的约束(相似性)去除噪声,完成分割;
- 可视化原始图像、带噪声图像、灰度图、分割结果的对比,直观看到 MRF 的效果。
讨论
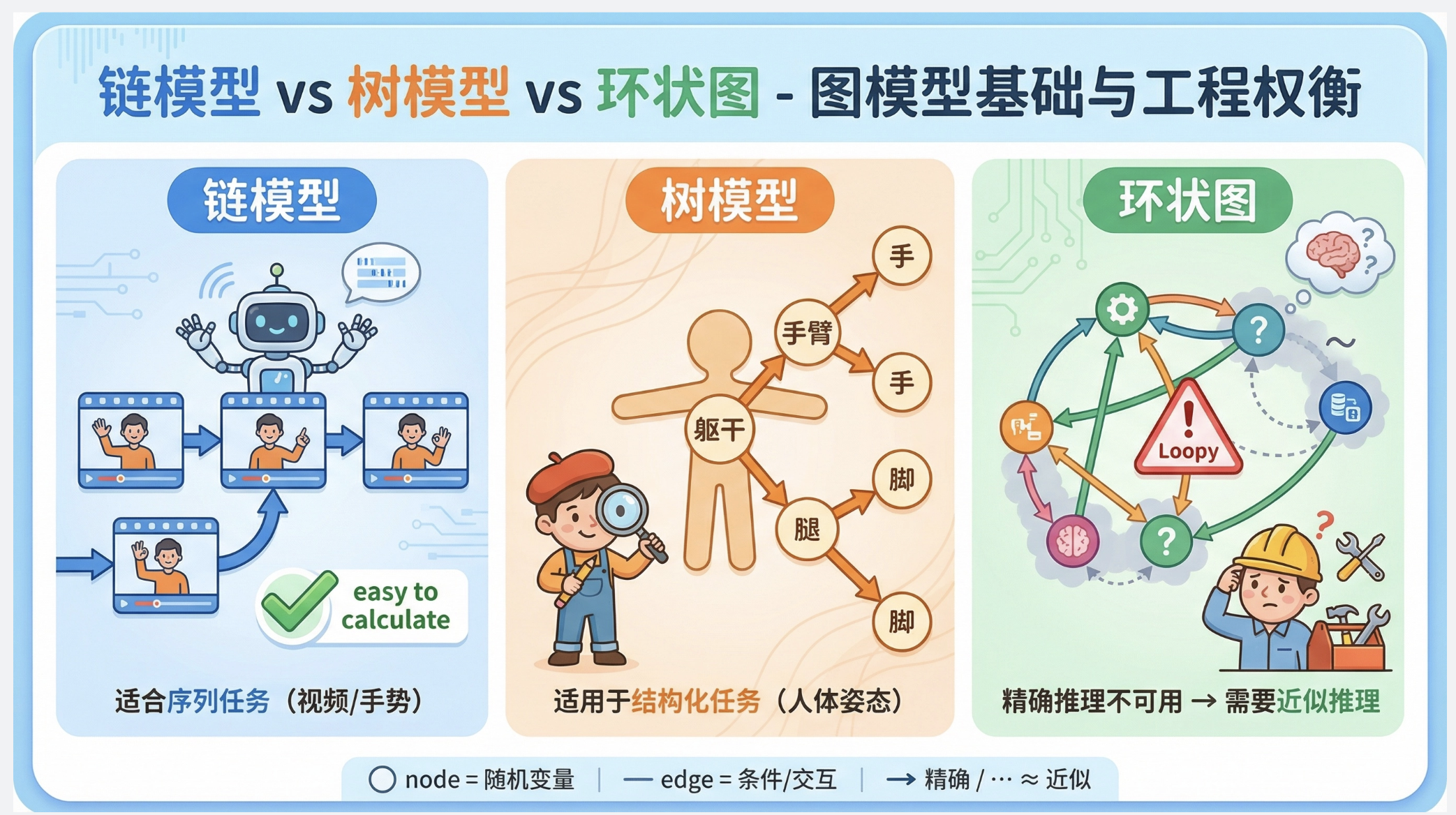
1.链式模型和树模型是概率图模型中最基础、最易计算的模型,是学习更复杂图模型的基石;
2.计算机视觉中的序列任务(如视频分析、手势跟踪)优先考虑链式模型,结构化任务(如人体姿态估计)优先考虑树模型;
3.精确推理只适用于无环图,有环图需要用近似推理,这是工程应用中的核心挑战。
备注
1.本文所有代码均基于 Python 3.8+,需安装依赖:pip install numpy matplotlib networkx hmmlearn opencv-python;
2.Mac 系统的 Matplotlib 中文显示配置已在代码中内置,Windows 用户可将字体替换为SimHei;
3.代码中的模型参数为模拟值,实际应用中需要用真实数据训练。
习题
1.修改 HMM 手语识别的代码,添加更多手势(比如 "爱""学""习"),并调整转移概率和发射概率,观察预测结果的变化;
2.基于前向后向算法的代码,实现树模型的和积算法,求解树模型的边缘后验概率;
3.改进 MRF 图像分割的代码,添加颜色特征(而不只是灰度特征),提升分割效果。
总结

1.链式模型分为有向(HMM)和无向(MRF),满足一定条件下可相互转换,核心应用是序列视觉任务(如手势跟踪);
2.链式 MAP 推理用 Viterbi 算法,边缘后验推理用前向后向(和积)算法;树模型是链式模型的扩展,推理用 Max-Product/Tree BP 算法;
3.模型学习可通过监督学习(统计频率)或无监督学习(EM 算法)实现,工程应用中需根据场景选择近似推理方法处理有环图。