大模型入门:面试必会 RoPE,从位置编码到旋转位置嵌入
一、Transformer 需要顺序信息
Self-Attention 的核心是:
text
Attention(Q, K, V) = softmax(QK^T / sqrt(d))V这个公式会计算 token 之间的相似度,但它本身不知道 token 出现在第几个位置。
自然语言的顺序又非常重要:
text
我喜欢你
你喜欢我所以大模型必须用某种方式把顺序信息注入到 Attention 里。
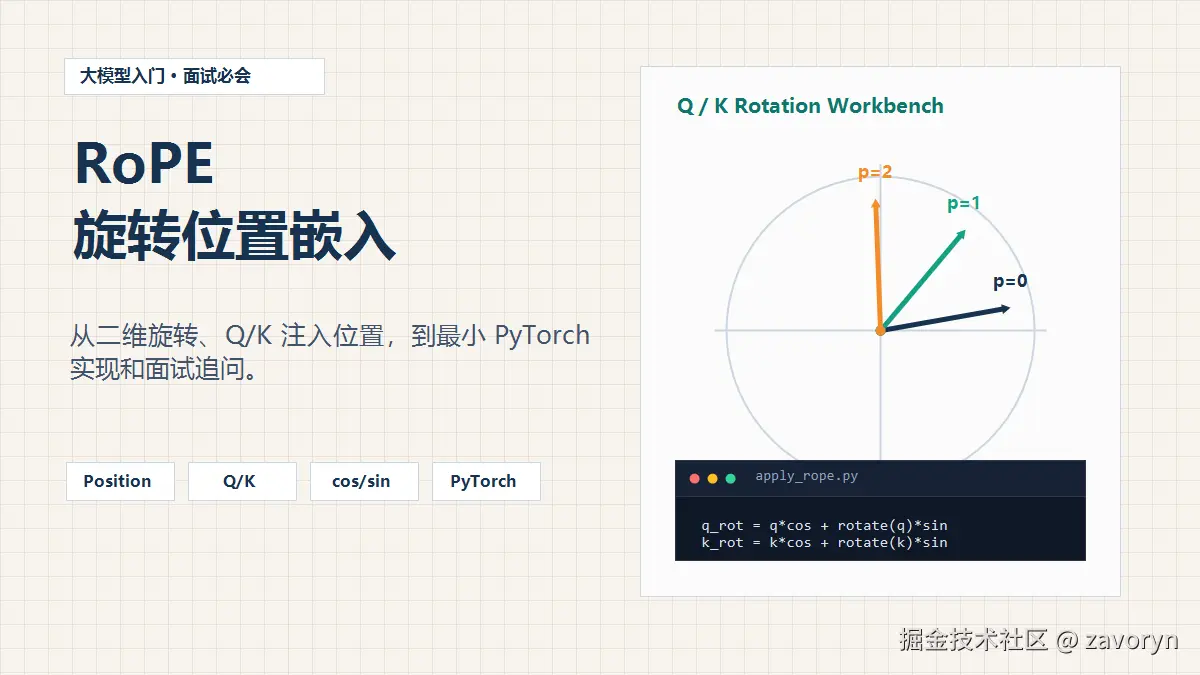
一句话理解 RoPE:
RoPE 把 position 变成 Query/Key 向量的旋转角度,让注意力分数在
Q @ K^T时自然携带相对位置。
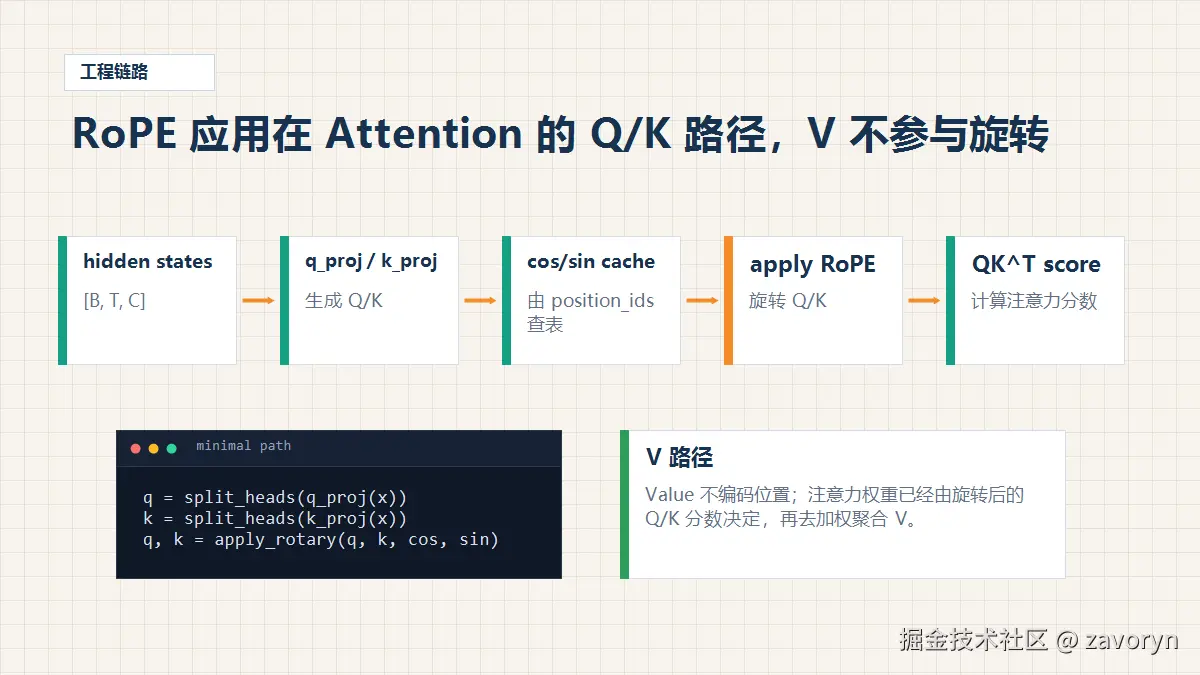
1. RoPE 在模型里的位置
传统绝对位置编码常见写法是:
python
x = token_embedding + position_embeddingRoPE 的典型路径更靠近 Attention 内部:
text
hidden states
-> q_proj / k_proj
-> 对 Q/K 应用 RoPE
-> 计算 QK^T
-> softmax
-> 聚合 V也就是说,RoPE 通常作用在 Query 和 Key 上。
V 一般不旋转,因为 V 是被注意力权重取出来的信息;位置关系已经通过旋转后的 Q/K 影响了权重。
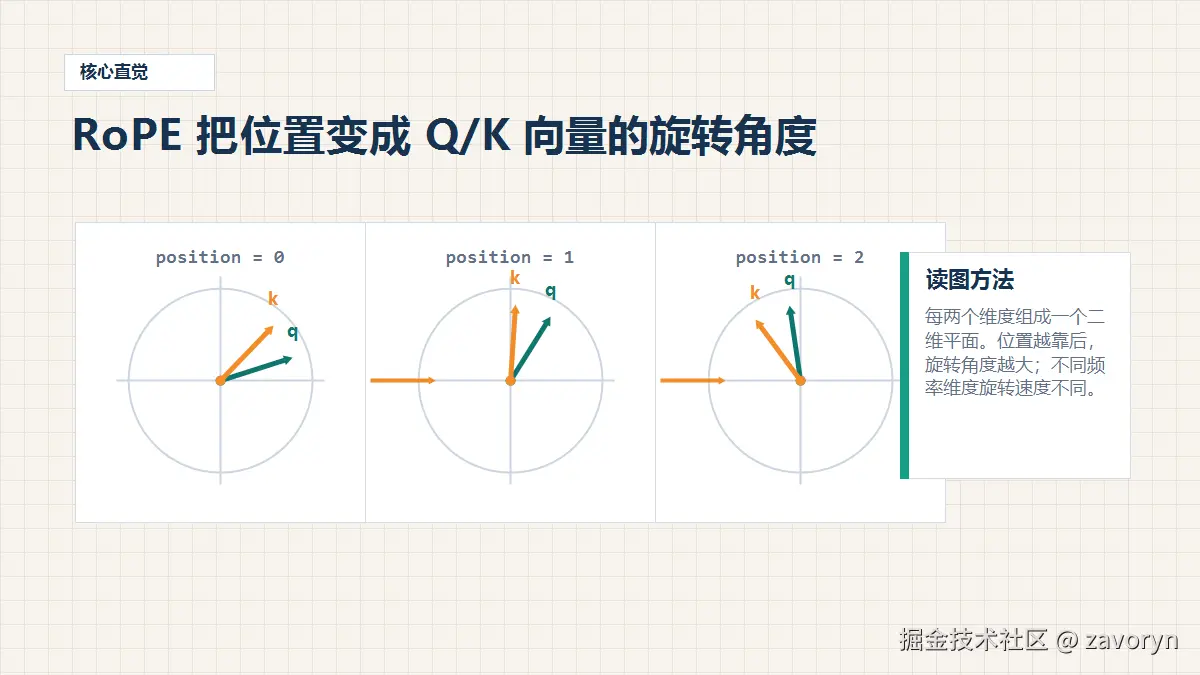
2. 用二维旋转建立直觉
二维向量:
text
v = [x, y]旋转角度 theta 后:
text
R(theta) = [[cos(theta), -sin(theta)],
[sin(theta), cos(theta)]]在 RoPE 里,head_dim 会被按两个维度一组拆成多个二维平面:
text
(x0, x1), (x2, x3), (x4, x5) ...每组二维平面使用一个频率。某个 token 的 position 越大,旋转角度越大。
这就是 RoPE 的核心直觉:
text
position -> angle -> rotate Q/K3. 相对位置如何进入 attention score
设原始 Query 是 q,原始 Key 是 k。
位置 m 的 Query:
text
q_m = R_m q位置 n 的 Key:
text
k_n = R_n k点积展开:
text
q_m^T k_n
= (R_m q)^T (R_n k)
= q^T R_m^T R_n k
= q^T R_(n-m) kn - m 就是两个 token 的相对距离。
这也是 RoPE 很适合放进 Attention 的原因:它用绝对位置旋转 Q/K,但在注意力分数里体现相对位置关系。
4. PyTorch 最小实现
先写 rotate_half:
python
import torch
def rotate_half(x: torch.Tensor) -> torch.Tensor:
# x: [..., head_dim]
x_even = x[..., 0::2]
x_odd = x[..., 1::2]
rotated = torch.stack((-x_odd, x_even), dim=-1)
return rotated.flatten(-2)构造 cos/sin cache:
python
def build_rope_cache(
seq_len: int,
head_dim: int,
base: float = 10000.0,
device=None,
dtype=torch.float32,
):
assert head_dim % 2 == 0
inv_freq = 1.0 / (
base
** (torch.arange(0, head_dim, 2, device=device, dtype=dtype) / head_dim)
)
positions = torch.arange(seq_len, device=device, dtype=dtype)
freqs = torch.einsum("t,d->td", positions, inv_freq)
emb = torch.repeat_interleave(freqs, repeats=2, dim=-1)
cos = emb.cos()[None, None, :, :] # [1, 1, T, D]
sin = emb.sin()[None, None, :, :] # [1, 1, T, D]
return cos, sin应用到 Q/K:
python
def apply_rotary_pos_emb(q, k, cos, sin, position_ids=None):
# q/k: [B, H, T, D]
if position_ids is None:
cos = cos[:, :, : q.size(-2), :]
sin = sin[:, :, : q.size(-2), :]
else:
cos_table = cos.squeeze(0).squeeze(0)
sin_table = sin.squeeze(0).squeeze(0)
cos = cos_table[position_ids].unsqueeze(1) # [B, 1, T, D]
sin = sin_table[position_ids].unsqueeze(1)
q_embed = q * cos + rotate_half(q) * sin
k_embed = k * cos + rotate_half(k) * sin
return q_embed, k_embed测试:
python
B, H, T, D = 2, 8, 5, 64
q = torch.randn(B, H, T, D)
k = torch.randn(B, H, T, D)
cos, sin = build_rope_cache(seq_len=128, head_dim=D)
position_ids = torch.arange(T).unsqueeze(0).expand(B, T)
q_rot, k_rot = apply_rotary_pos_emb(q, k, cos, sin, position_ids)
print(q_rot.shape) # [2, 8, 5, 64]
print(k_rot.shape) # [2, 8, 5, 64]RoPE 不改变 Q/K 的 shape,只改变向量方向。
5. KV Cache 下最容易错的是 position_ids
prefill 阶段输入完整 prompt:
text
position_ids = [0, 1, 2, 3, 4]decode 阶段每一步可能只输入一个新 token。
如果 prompt 长度是 5,那么下一步新 token 的位置是:
text
position_ids = [5]再下一步是:
text
position_ids = [6]如果每次 decode 都从 0 开始,旋转角度就错了。
源码里通常要一起看:
text
position_ids
cache_position
past_key_values这也是 RoPE 和 KV Cache 放在一起考时最容易踩坑的地方。
6. 长上下文扩展怎么理解
Hugging Face 的 RoPE 工具文档里可以看到多种 rope_type:
text
default
linear
dynamic
yarn
longrope
llama3这些策略都在处理一个问题:模型预训练长度有限,推理时想用更长上下文,位置频率应该怎么调整。
但不要把它理解成只要改 rope_theta 就能稳定扩窗。
更稳妥的说法是:
RoPE 提供了可调的位置频率结构,长上下文扩展需要结合模型训练长度、配置、推理实现和评估结果一起判断。
7. 常见坑

| 坑点 | 说明 |
|---|---|
| head_dim 没有两两配对 | RoPE 要在二维平面里旋转 |
rotate_half 顺序混用 |
奇偶交错和前后半拆分都存在,不能随便混 |
| cos/sin shape 不清楚 | 要确认能正确广播到 [B,H,T,D] |
| decode 从 position 0 开始 | KV Cache 下新 token 要接着历史长度走 |
随便改 rope_theta |
长上下文 scaling 需要匹配模型配置 |
| 只背概念不看路径 | 面试要能讲 Q/K、cos/sin、position_ids 和 cache |
8. 面试速记
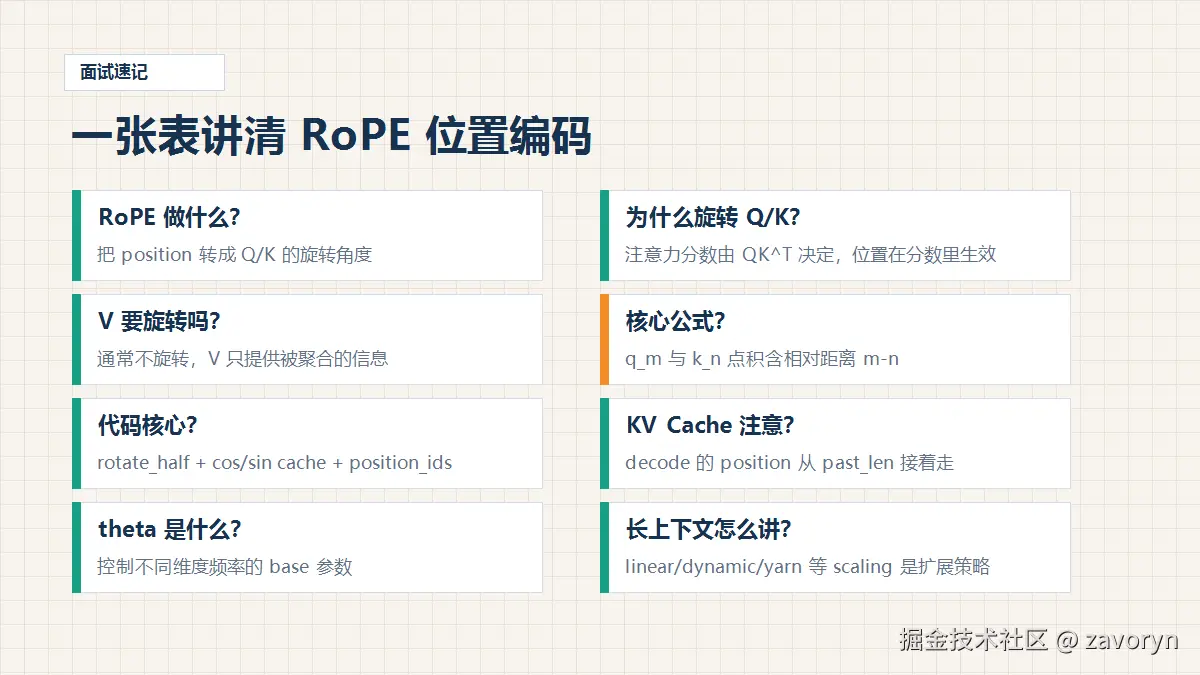
| 问题 | 关键回答 |
|---|---|
| RoPE 解决什么? | 给 Attention 注入顺序和相对距离信息 |
| 作用在哪? | Query 和 Key |
| Value 要处理吗? | 通常不处理 |
| 为什么有相对位置? | R_m^T R_n = R_(n-m) |
| 代码核心? | rotate_half、cos/sin cache、position_ids |
| KV Cache 关键点? | decode 的 position 从 past_len 继续 |
rope_theta 是什么? |
控制频率基底 |
| 长上下文扩展? | linear、dynamic、YaRN 等 RoPE scaling 策略 |
如果面试官问 RoPE 是什么,可以这样答:
RoPE 是旋转位置嵌入。它把 token 的位置转成旋转角度,作用在 Attention 的 Query 和 Key 上。Q/K 做点积时,会因为旋转矩阵的性质自然得到相对位置关系。
如果继续追问公式:
位置 m 的 Query 是
R_m q,位置 n 的 Key 是R_n k,点积展开后是q^T R_m^T R_n k = q^T R_(n-m) k,所以 attention score 依赖相对距离。
总结
RoPE 最值得记住的是这条链路:
text
position -> rotation -> Q/K -> QK^T -> relative distance讲清楚这条线,RoPE 就能从一个抽象名词变成可解释、可实现、可看源码的知识点。
参考资料
- RoFormer: Enhanced Transformer with Rotary Position Embedding
arxiv.org/abs/2104.09... - Hugging Face Transformers:Utilities for Rotary Embedding
huggingface.co/docs/transf... - Hugging Face Transformers:RoFormer
huggingface.co/docs/transf... - Hugging Face Transformers:Llama implementation
github.com/huggingface... - Extending Context Window of Large Language Models via Positional Interpolation
arxiv.org/abs/2306.15... - YaRN: Efficient Context Window Extension of Large Language Models
arxiv.org/abs/2309.00...