翻译自 https://implicit-layers-tutorial.org/deep_equilibrium_models/
本章介绍另一类新兴的隐式层模型------深度平衡(Deep Equilibrium, DEQ)模型 [Bai et al., 2019](https://arxiv.org/abs/1909.01377)。这些模型最近在各类大规模视觉和 NLP 任务上展示了令人印象深刻的性能,通常与使用传统显式模型的最先进技术相比具有竞争力 [Bai et al., 2020](https://arxiv.org/abs/2006.08656)。然而,这种方法的核心思想,即定义一个寻找某种迭代过程不动点的层,可以追溯到循环反向传播的一些原始工作 [Almeida, 1987](https://www.semanticscholar.org/paper/A-learning-rule-for-asynchronous-perceptrons-with-a-Almeida/8be3f21ab796bd9811382b560507c1c679fae37f), [Pineda, 1987](https://papers.nips.cc/paper/1987/file/735b90b4568125ed6c3f678819b6e058-Paper.pdf)。因此,DEQ 模型在很大程度上是这些方法的"现代"变体,其概念上的新增内容包括:1) 使用现代深度架构扩展这些方法,目标是表达整个深度网络为一个平衡计算;2) 尝试直接通过寻根而非仅通过不动点迭代来寻找不动点。
本章将介绍 DEQ 模型背后的直觉,讨论该方法的一些理论方面,然后使用类似 ResNet 的卷积块在 CIFAR10 上实现中等规模的该方法。
深度网络与不动点方程
作为引入 DEQ 模型的起点,我们将从一个简单的深度网络公式开始,然后以此引出不动点迭代层的概念,就像我们在第1章中最初介绍的那样。
一个典型的 k k k 层深度网络 h : X → Y h : \mathcal{X} \rightarrow \mathcal{Y} h:X→Y 由一系列层堆叠定义,形式如下
z 1 = x z i + 1 = σ ( W i z i + b i ) , i = 1 , ... , k − 1 h ( x ) = W k z k + b k \begin{aligned} z_1 &= x \\ z_{i+1} &= \sigma(W_i z_i + b_i), \; i=1,\ldots,k-1 \\ h(x) &= W_k z_k + b_k \end{aligned} z1zi+1h(x)=x=σ(Wizi+bi),i=1,...,k−1=Wkzk+bk
需要说明的是,"真正的"深度网络形式与此相去甚远,它们包含卷积层、残差连接、归一化、注意力层等。但以这样一个简单网络作为起点仍然具有启发性。我们可以用下图来表示这个网络:
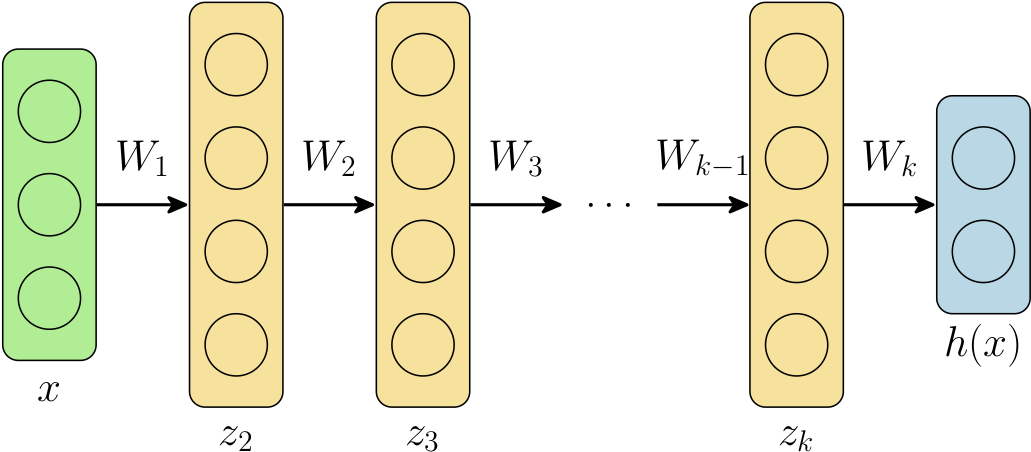
事实表明,或许有些令人惊讶(尽管我们将在下文从数学角度说明,这可能并不像乍听起来那么令人惊讶),我们可以在很大程度上将每一层的不同权重 W i W_i Wi 替换为相同的 权重 W W W(偏置 b b b 也类似),而深度网络在实践中仍能工作良好。这种权重绑定网络的概念(不是在 DEQ 语境中,而仅仅是作为一种在实践中改善网络性能的策略)在文献中有几个例子 [Bai et al., 2018](https://arxiv.org/abs/1810.06682), [Dehghani et al., 2018](https://arxiv.org/abs/1807.03819), [Lan et al., 2019](https://arxiv.org/abs/1909.11942)。出于一个将很快明确的原因,我们还希望在这些层中添加输入注入 ,它不仅将输入的(线性变换) U x Ux Ux 添加到第一层,而且添加到之后的每一层。换句话说,我们可以用以下方程描述这个新模型
z 1 = 0 z i + 1 = σ ( W z i + U x + b ) , i = 1 , ... , k − 1 h ( x ) = W k z k + b k \begin{aligned} z_1 &= 0 \\ z_{i+1} &= \sigma(W z_i + Ux + b), \; i=1,\ldots,k-1 \\ h(x) &= W_k z_k + b_k \end{aligned} z1zi+1h(x)=0=σ(Wzi+Ux+b),i=1,...,k−1=Wkzk+bk
由于输出 h ( x ) h(x) h(x) 可以具有与隐藏单元不同的大小,我们通常使用单独的权重来生成函数的最终输出。这可以用下图表示:
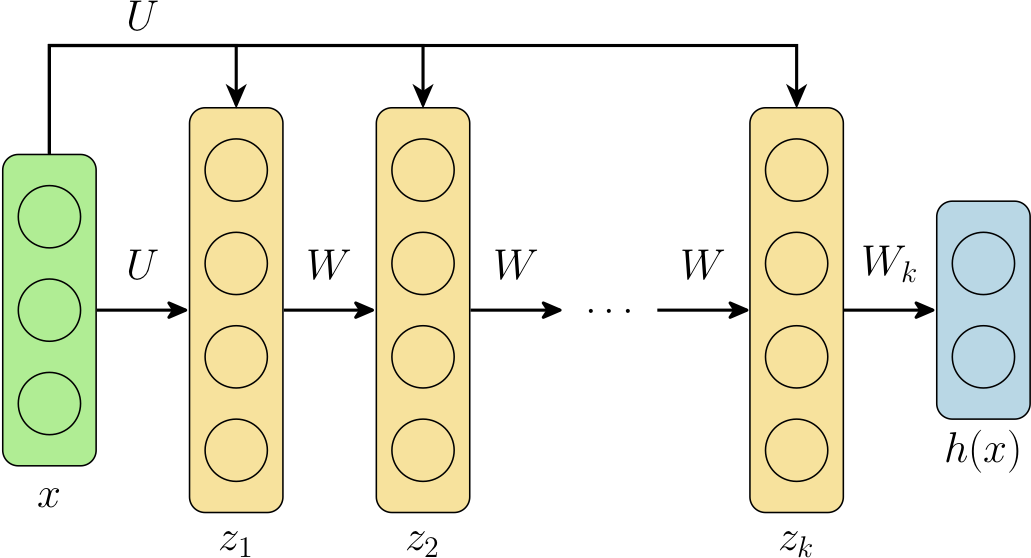
然而,现在出现了一些奇特的现象。深度网络的关键迭代是层
z i + 1 = σ ( W z i + U x + b ) . z_{i+1} = \sigma(W z_i + Ux + b). zi+1=σ(Wzi+Ux+b).
重要的是,这是相同的 层被重复应用于隐藏单元。如果我们无限次重复这个更新,我们实质上将在建模一个无限深的上述形式网络。但在这个无限极限下会发生什么?实际上可能发生几种不同的事情:网络输出 z i z_i zi( i → ∞ i \rightarrow \infty i→∞)可能爆炸,发散到某个大值;或者输出可能在不同的值之间振荡,无论是周期性的还是混沌的;但在实践中,我们发现对于大多数"典型的"深度层,值实际上收敛到一个不动点 或平衡点 ,即一个点 z ⋆ z^\star z⋆,在该点进一步应用层不会改变其值,即
z ⋆ = σ ( W z ⋆ + U x + b ) . z^\star = \sigma(W z^\star + U x + b). z⋆=σ(Wz⋆+Ux+b).
换句话说,这个无限深的模型看起来完全像一个典型的不动点迭代,我们重复更新直到值保持不变。DEQ 模型的目标是直接找到这个平衡点 z ⋆ z^\star z⋆,而不一定执行前向迭代本身,而是直接尝试找到这个平衡方程的根。
然而,我们为什么认为这样的不动点确实存在呢?一个启发式论证是,这种收敛恰好刻画了常见深度网络的稳定性:既然我们已经开发了对于非常深的网络已经稳定的网络架构(否则我们无法训练它们),在某种意义上我们已经将设计偏向于倾向于稳定不动点的层。最近的工作研究了保证不动点存在且唯一的 DEQ 类别 [Winston and Kolter, 2020](https://arxiv.org/abs/2006.08591)。然而,出于本章的目的,我们基本上忽略关于保证存在的任何形式化说明,而将这种稳定性主要视为一个经验问题。
最后,这个公式也说明了为什么模型中需要输入注入 U x Ux Ux。因为平衡点不依赖于 z 1 z_1 z1 的任何"初始"值,如果我们没有输入注入,网络的输出实际上就不会依赖于其输入。因此,输入注入作为一种确保平衡点确实依赖于函数输入的方式,尽管网络是无限深的。
DEQ 的性质:表示能力和隐式微分
在定义了基本模型之后,现在我们将解决关于 DEQ 模型表示能力的一些基本问题,并讨论如何应用我们在前几章讨论过的隐函数定理来计算通过这些 DEQ 层的梯度以及传过它们的梯度。出于本节的目的,我们将推广之前所述的 DEQ 形式,直接记 DEQ 函数为 f ( z , x ) f(z,x) f(z,x)(即在我们之前的形式中 f ( z , x ) = σ ( W z + U x + b ) f(z,x) = \sigma(Wz + Ux + b) f(z,x)=σ(Wz+Ux+b)),我们试图找到一个不动点
z ⋆ = f ( z ⋆ , x ) . z^\star = f(z^\star,x). z⋆=f(z⋆,x).
DEQ 表示的能力
DEQ 表示有多强大?也许有些令人惊讶(尽管事后看来这个事实相当明显),我们可以非常精确地描述基于这种平衡计算的深度网络的表示能力。具体来说,任何深度网络(任意深度、任意连接方式)都可以表示为一个单层 DEQ 模型。 此外,这并不涉及单层通用函数逼近定理中常见的参数指数级增长:使用相同数量的参数,单层 DEQ 可以表示任何网络。
这个事实的证明相当简单。为了理解其直觉,考虑两个函数的传统组合 y = g 2 ( g 1 ( x ) ) y = g_2(g_1(x)) y=g2(g1(x))。我们可以通过简单地将这个函数的所有中间项连接成一个长向量,将其转换为单层 DEQ,
f ( z , x ) = f ( z 1 z 2 , x ) = g 1 ( x ) g 2 ( z 1 ) . f(z,x) = f\left (\left \\begin{array}{c}z_1 \\\\ z_2 \\end{array} \\right , x \right ) = \left \\begin{array}{c} g_1(x) \\\\ g_2(z_1) \\end{array} \\right . f(z,x)=f(z1z2,x)=g1(x)g2(z1).
注意在该函数的不动点 z ⋆ z^\star z⋆ 处,我们有
z ⋆ = f ( z ⋆ , x ) ⟺ z 1 ⋆ = g 1 ( x ) , z 2 ⋆ = g 2 ( z 1 ⋆ ) = g 2 ( g 1 ( x ) ) z^\star = f(z^\star, x) \; \Longleftrightarrow \; z_1^\star = g_1(x), \; z_2^\star = g_2(z_1^\star) = g_2(g_1(x)) z⋆=f(z⋆,x)⟺z1⋆=g1(x),z2⋆=g2(z1⋆)=g2(g1(x))
即,如果我们计算该函数的不动点,那么第二个分量 z 2 ⋆ z^\star_2 z2⋆ 正是原始组合网络的输出。这个逻辑当然适用于任何计算图,我们可以将计算图的所有中间产物连接成向量 z z z,并令函数 f f f 为对每个元素应用图中的"下一个"计算的函数。
虽然这个构造在理论上展示了单层 DEQ 的能力,但我们应该强调这不是我们在实践中实际使用的构造。例如,在这个模型中使用标准的不动点迭代会比简单计算原始网络低效得多,而且我们无论如何都需要在内存中存储整个计算向量(这恰恰是我们试图避免的一点)。但希望这个构造确实能给出一些直觉,说明计算"单个"DEQ 层的不动点严格比单个显式层更强大。
一个(隐式)层就够了
对于那些熟悉深度学习理念的人,此刻你可能会想:"既然单层 DEQ 与任意堆叠的'显式'层一样强大,那么我们是否可以堆叠这些 DEQ 层来获得更强大的东西?"不幸的是(或者幸运的是?)答案是否定的。事实上,对于 DEQ 来说,单层 DEQ 同样可以对任意数量的'堆叠'DEQ 层建模。 这个事实的证明与前面的例子非常相似。假设我们有一个系统,首先计算函数 z 1 ⋆ = f 1 ( z 1 ⋆ , x ) z_1^\star = f_1(z_1^\star,x) z1⋆=f1(z1⋆,x) 的不动点,然后使用 z 1 ⋆ z_1^\star z1⋆ 作为输入计算第二个平衡,即 z 2 ⋆ = f ( z 2 ⋆ , z 1 ⋆ ) z_2^\star = f(z_2^\star, z_1^\star) z2⋆=f(z2⋆,z1⋆)。然而,同样可以将这个联合问题设置为单个平衡问题,即计算系统的平衡点
z ⋆ = z 1 ⋆ z 2 ⋆ = f 1 ( z ⋆ , x ) f 2 ( z 2 ⋆ , z 1 ⋆ ) = f ( z ⋆ , x ) z^\star = \left \\begin{array}{c} z\^\\star_1 \\\\ z\^\\star_2 \\end{array} \\right = \left \\begin{array}{c} f_1(z\^\\star, x) \\\\ f_2(z_2\^\\star, z_1\^\\star) \\end{array} \\right = f(z^\star, x) z⋆=z1⋆z2⋆=f1(z⋆,x)f2(z2⋆,z1⋆)=f(z⋆,x)
即,我们可以简单地将两个平衡解连接起来,得到两个解上的联合平衡问题的解。总的来说,这确实是平衡建模方法的一个关键优势:这种操作足以用单个平衡层描述传统计算图(任意深度)和平衡模型(任意"深度")。
平衡层的隐式微分
最后,我们推导特定于 DEQ 模型的隐式反向传播形式(实际上,也适用于任何不动点迭代层,但这里我们将主要关注 DEQ 模型的具体形式)。
如前几章所述,我们首先考虑不动点解
z ⋆ = f ( z ⋆ , x ) . z^\star = f(z^\star, x). z⋆=f(z⋆,x).
我们的目标是计算关于某个向量 y y y 的向量-Jacobian 积 ( ∂ z ⋆ ( ⋅ ) ∂ ( ⋅ ) ) T y \left (\frac{\partial z^\star(\cdot)}{\partial (\cdot)}\right)^T y (∂(⋅)∂z⋆(⋅))Ty, ( ⋅ ) (\cdot) (⋅) 代表我们想对不动点求导的任何量(即输入 x x x,或函数 f f f 的任何参数,这两者当然都会影响最终的不动点 z ⋆ z^\star z⋆)。由于这个向量-Jacobian 积是将这些 DEQ 层集成到反向传播中的关键,这样的例程允许我们将 DEQ 层嵌入到标准自动微分工具中。
向量-Jacobian 积的推导与前面几章基本一致,但为了完整性我们在此再次给出完整推导。对不动点解的两边求导,有
∂ z ⋆ ( ⋅ ) ∂ ( ⋅ ) = ∂ f ( z ⋆ ( ⋅ ) , x ) ∂ ( ⋅ ) = ∂ f ( z ⋆ , x ) ∂ z ⋆ ∂ z ⋆ ( ⋅ ) ∂ ( ⋅ ) + ∂ f ( z ⋆ , x ) ∂ ( ⋅ ) \frac{\partial z^\star(\cdot)}{\partial (\cdot)} = \frac{\partial f(z^\star(\cdot), x)}{\partial (\cdot)} = \frac{\partial f(z^\star, x)}{\partial z^\star} \frac{\partial z^\star(\cdot)}{\partial (\cdot)} + \frac{\partial f(z^\star, x)}{\partial (\cdot)} ∂(⋅)∂z⋆(⋅)=∂(⋅)∂f(z⋆(⋅),x)=∂z⋆∂f(z⋆,x)∂(⋅)∂z⋆(⋅)+∂(⋅)∂f(z⋆,x)
其中我们用 z ⋆ ( ⋅ ) z^\star(\cdot) z⋆(⋅) 表示 z ⋆ z^\star z⋆ 被视作关于求导量的隐函数的情况(例如关于 f f f 的参数或输入 x x x),而单独使用 z ⋆ z^\star z⋆ 时我们仅指平衡点处的值(例如在最后一个表达式中)。该行的第二个等式只是应用多元链式法则的结果。然后,重新排列项,得到 Jacobian 的显式表达式
∂ z ⋆ ( ⋅ ) ∂ ( ⋅ ) = ( I − ∂ f ( z ⋆ , x ) ∂ z ⋆ ) − 1 ∂ f ( z ⋆ , x ) ∂ ( ⋅ ) \frac{\partial z^\star(\cdot)}{\partial (\cdot)} = \left ( I - \frac{\partial f(z^\star, x)}{\partial z^\star} \right )^{-1} \frac{\partial f(z^\star, x)}{\partial (\cdot)} ∂(⋅)∂z⋆(⋅)=(I−∂z⋆∂f(z⋆,x))−1∂(⋅)∂f(z⋆,x)
其中右侧的所有项都可以使用"传统"自动微分计算。
最后,为了计算向量-Jacobian 积,我们有
( ∂ z ⋆ ( ⋅ ) ∂ ( ⋅ ) ) T y = ( ∂ f ( z ⋆ , x ) ∂ ( ⋅ ) ) T ( I − ∂ f ( z ⋆ , x ) ∂ z ⋆ ) − T y . \left (\frac{\partial z^\star(\cdot)}{\partial (\cdot)} \right)^T y = \left (\frac{\partial f(z^\star, x)}{\partial (\cdot)} \right )^T \left ( I - \frac{\partial f(z^\star, x)}{\partial z^\star} \right )^{-T} y. (∂(⋅)∂z⋆(⋅))Ty=(∂(⋅)∂f(z⋆,x))T(I−∂z⋆∂f(z⋆,x))−Ty.
让我们考虑在实践中如何计算这个量。这里关键的项是线性系统的解(我们简写为 g g g)
g = ( I − ∂ f ( z ⋆ , x ) ∂ z ⋆ ) − T y g = \left (I - \frac{\partial f(z^\star, x)}{\partial z^\star} \right )^{-T} y g=(I−∂z⋆∂f(z⋆,x))−Ty
可以重新排列为
g = ( ∂ f ( z ⋆ , x ) ∂ z ⋆ ) T g + y . g = \left(\frac{\partial f(z^\star, x)}{\partial z^\star} \right )^T g + y. g=(∂z⋆∂f(z⋆,x))Tg+y.
这里的关键点是,这个表达式实际上也是 一个(线性)不动点方程,这里是关于量 g g g 的。这里朴素前向迭代的收敛性要求 Jacobian ∂ f ( z ⋆ , x ) ∂ z ⋆ \frac{\partial f(z^\star, x)}{\partial z^\star} ∂z⋆∂f(z⋆,x) 是稳定矩阵(最大特征值的幅值小于1),这也是前向迭代在其收敛点处局部稳定的条件。但我们这里不深入讨论这一点,仅基于前向迭代中的事实,即这些迭代在实践中通常是稳定的。
因此,为 DEQ 层推导向量-Jacobian 积的过程可以简化为两个步骤。
-
解如下的不动点方程,可以通过直接求逆或(更可能地)通过某种仅需要乘以 ( ∂ f ( z ⋆ , x ) ∂ z ⋆ ) T \left(\frac{\partial f(z^\star, x)}{\partial z^\star} \right )^T (∂z⋆∂f(z⋆,x))T 的迭代过程(这本身可以通过典型的自动微分完成,因为它本身就是一个向量-Jacobian 积)。
g = ( ∂ f ( z ⋆ , x ) ∂ z ⋆ ) T g + y g = \left(\frac{\partial f(z^\star, x)}{\partial z^\star} \right )^T g + y g=(∂z⋆∂f(z⋆,x))Tg+y
-
计算最终的 Jacobian-向量积,同样,这个积本身就是一个向量-Jacobian 积,可以通过常规的自动微分计算。
( ∂ z ⋆ ( ⋅ ) ∂ ( ⋅ ) ) T y = ( ∂ f ( z ⋆ , x ) ∂ ( ⋅ ) ) T g \left (\frac{\partial z^\star(\cdot)}{\partial (\cdot)} \right)^T y = \left (\frac{\partial f(z^\star, x)}{\partial (\cdot)} \right )^T g (∂(⋅)∂z⋆(⋅))Ty=(∂(⋅)∂f(z⋆,x))Tg
DEQ 模型的实现
在讨论了更多的算法和理论方面之后,本章的剩余部分将讨论如何实现和训练 DEQ 模型,并提供一个完整示例,将在 CIFAR10 基准上训练一个卷积 DEQ 模型(达到 81.6% 的准确率,这当然并不出众,但这是针对一个非常小的基础模型,约 20 万参数,当然更复杂的 DEQ 方法可以做得更好)。
设计层 f f f
由于 DEQ 模型最终找到的是单个函数 z ⋆ = f ( z ⋆ , x ) z^\star = f(z^\star, x) z⋆=f(z⋆,x) 的平衡点, f f f 的选择当然将主要决定最终模型的性能。虽然我们在简单的全连接层语境中介绍了原始 DEQ 模型
f ( z , x ) = σ ( W z + U x + b ) f(z,x) = \sigma(Wz + Ux + b) f(z,x)=σ(Wz+Ux+b)
但在实践中,我们希望在该层中融入一些额外的结构,而不仅仅是这种通用的全连接模型。因此,DEQ 模型的"层"应该更多地被视为一个"单元"而非传统意义上的单层。由于在深度学习模型中有大量关于设计实用单元结构的工作(例如,视觉网络中的残差单元,许多语言任务中的 transformer 单元等),DEQ 函数 f f f 的一个自然选择同样是这些传统单元之一。
此外,尽管我们将函数 f f f 写为网络实际输入 x x x 的函数,但在实践中我们可以预计算应用于输入的任何变换,即预计算 x ˉ = U x + b \bar{x} = Ux + b xˉ=Ux+b,然后将 DEQ 函数视为 f ( z , x ˉ ) f(z,\bar{x}) f(z,xˉ),这消除了重复将相同操作应用于输入的需要。不过,为了保持符号的一致性,我们仍然将 DEQ 函数称为 f ( z , x ) f(z,x) f(z,x),即使最终 x x x 将是输入的某个(通常只是线性的)函数。
在本章中,由于我们关注的是视觉任务,我们将考虑一个残差单元作为我们的函数。具体来说,我们考虑如下形式

其功能可以写作
f ( z , x ) = n o r m ( R e L U ( z + n o r m ( x + W 2 ∗ ( n o r m ( R e L U ( W 1 ∗ z ) ) ) ) ) ) f(z,x) = \mathrm{norm}(\mathrm{ReLU}(z + \mathrm{norm}(x + W_2*(\mathrm{norm}(\mathrm{ReLU}(W_1 * z)))))) f(z,x)=norm(ReLU(z+norm(x+W2∗(norm(ReLU(W1∗z))))))
其中 ∗ * ∗ 表示与滤波器 W 1 W_1 W1 或 W 2 W_2 W2 的卷积, n o r m \mathrm{norm} norm 表示某种归一化操作(在我们的示例中使用 GroupNorm)。
DEQ 模型的一个额外奇特之处在于,这些卷积算子的权重通常需要比传统网络中的层使用更小的值初始化。为简单起见,我们初始化层中所有权重为 N ( 0 , 0.01 ) \mathcal{N}(0, 0.01) N(0,0.01) 的随机样本,尽管方差项的精确理想缩放比例仍未得到充分理解(尽管一个相当宽范围的较小方差初始化都能良好工作)。
综合以上所有内容,我们可以使用以下代码在 PyTorch 中实现 f f f 函数。
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class ResNetLayer(nn.Module):
def __init__(self, n_channels, n_inner_channels, kernel_size=3, num_groups=8):
super().__init__()
self.conv1 = nn.Conv2d(n_channels, n_inner_channels, kernel_size, padding=kernel_size//2, bias=False)
self.conv2 = nn.Conv2d(n_inner_channels, n_channels, kernel_size, padding=kernel_size//2, bias=False)
self.norm1 = nn.GroupNorm(num_groups, n_inner_channels)
self.norm2 = nn.GroupNorm(num_groups, n_channels)
self.norm3 = nn.GroupNorm(num_groups, n_channels)
self.conv1.weight.data.normal_(0, 0.01)
self.conv2.weight.data.normal_(0, 0.01)
def forward(self, z, x):
y = self.norm1(F.relu(self.conv1(z)))
return self.norm3(F.relu(z + self.norm2(x + self.conv2(y))))在本节中还有一点值得一提。通常,对于大多数 DEQ 应用,我们选择上述层中的 n_channels 小于 n_inner_channels。这是因为,为了找到 DEQ 的平衡点,我们希望在一个相对"小"的隐藏单元上计算平衡;但另一方面,为了增加网络的表示能力,我们需要相对大数量的参数。实现这一点的一种方式是让残差单元"内部"的隐藏层比暴露给 DEQ 模型的隐藏单元更大。这类似于许多深度架构中常见的"瓶颈"结构(包括更大的 ResNet),但额外需要注意的是,我们通常希望针对较小的隐藏单元求解不动点,因为这使得平衡点计算更简单(且更节省内存)。
前向传播的实现
DEQ 层的"前向"传播需要实际计算上述函数 f f f(或任何其他单个单元)的不动点
z ⋆ = f ( z ⋆ , x ) z^\star = f(z^\star, x) z⋆=f(z⋆,x)
虽然在许多情况下可以通过简单地迭代前向迭代来实现
z k + 1 = f ( z k , x ) z^{k+1} = f(z^k,x) zk+1=f(zk,x)
但实际上存在更高效的不动点迭代方法,其性能显著优于朴素前向迭代,通常有一些额外的内存开销(但通常仍然不高)。
一种更常见的不动点加速方法是 Anderson 加速 [Walker and Ni, 2011](https://users.wpi.edu/~walker/Papers/Walker-Ni,SINUM,V49,1715-1735.pdf)。我们将直接陈述算法而不做完整推导,但其基本方法相当简单:不直接将 z k + 1 z^{k+1} zk+1 计算为 f ( z k , x ) f(z^k,x) f(zk,x)(即函数 f f f 应用于上次迭代的值),而是将其更新为 f f f 应用于前 m m m 次迭代的某种线性组合
z k + 1 = ∑ i = 1 m α i f ( z k − i + 1 , x ) z^{k+1} = \sum_{i=1}^m \alpha_i f(z^{k-i+1},x) zk+1=i=1∑mαif(zk−i+1,x)
其中 α \alpha α 是满足 ∑ i = 1 m α i = 1 \sum_{i=1}^m \alpha_i = 1 ∑i=1mαi=1 的一组系数(尽管某些 α \alpha α 项也可能为负), m m m 是决定更新"记忆"的常数(对于前 m m m 次迭代,当然只对迄今为止的每次迭代有系数)。为了计算 α \alpha α,我们求解优化问题
min α ∥ G α ∥ 2 2 , subject to 1 T α = 1 \min_\alpha \|G \alpha\|_2^2, \;\; \text{subject to} \;\; \mathbf{1}^T \alpha = 1 αmin∥Gα∥22,subject to1Tα=1
其中
G = f ( z k , x ) − z k ⋯ f ( z k − m + 1 , x ) − z k − m + 1 . G = \left \\begin{array}{ccc} f(z\^{k},x) - z\^k \& \\cdots \& f(z\^{k-m+1},x) - z\^{k-m+1} \\end {array} \\right . G=f(zk,x)−zk⋯f(zk−m+1,x)−zk−m+1.
这可以通过求解线性系统解析地得到
0 1 T 1 G T G ν α = 1 0 . \left \\begin{array} {cc} 0 \& \\mathbf{1}\^T \\\\ \\mathbf{1} \& G\^T G \\end{array} \\right \left \\begin{array}{c} \\nu \\\\ \\alpha \\end{array} \\right = \left \\begin{array}{c} \\mathbf{1} \\\\ 0 \\end{array} \\right . 011TGTGνα=10.
我们还可以进一步将迭代推广为广义更新
z k + 1 = ( 1 − β ) ∑ i = 1 m α i z k − i + 1 + β ∑ i = 1 m α i f ( z k − i + 1 , x ) z^{k+1} = (1-\beta) \sum_{i=1}^m \alpha_i z^{k-i+1} + \beta \sum_{i=1}^m \alpha_i f(z^{k-i+1},x) zk+1=(1−β)i=1∑mαizk−i+1+βi=1∑mαif(zk−i+1,x)
其中 β > 0 \beta > 0 β>0。当 β < 1 \beta < 1 β<1 时,这对应 Anderson 更新的"阻尼"版本,但当 β > 1 \beta > 1 β>1 时,这对应"过度投影"版本(即对前次迭代具有负权重),但实际上可能收敛更快。
由于我们通常同时处理一批样本,我们通常需要以"批处理"版本运行 Anderson 加速,以便为批次中的每个样本分别计算不动点。该函数可以用以下 PyTorch 代码实现(并不需要完全理解这段代码,但它只是实现了上述显式求解,以找到批次中所有示例的 α \alpha α 的解)。
python
def anderson(f, x0, m=5, lam=1e-4, max_iter=50, tol=1e-2, beta = 1.0):
""" Anderson acceleration for fixed point iteration. """
bsz, d, H, W = x0.shape
X = torch.zeros(bsz, m, d*H*W, dtype=x0.dtype, device=x0.device)
F = torch.zeros(bsz, m, d*H*W, dtype=x0.dtype, device=x0.device)
X[:,0], F[:,0] = x0.view(bsz, -1), f(x0).view(bsz, -1)
X[:,1], F[:,1] = F[:,0], f(F[:,0].view_as(x0)).view(bsz, -1)
H = torch.zeros(bsz, m+1, m+1, dtype=x0.dtype, device=x0.device)
H[:,0,1:] = H[:,1:,0] = 1
y = torch.zeros(bsz, m+1, 1, dtype=x0.dtype, device=x0.device)
y[:,0] = 1
res = []
for k in range(2, max_iter):
n = min(k, m)
G = F[:,:n]-X[:,:n]
H[:,1:n+1,1:n+1] = torch.bmm(G,G.transpose(1,2)) + lam*torch.eye(n, dtype=x0.dtype,device=x0.device)[None]
alpha = torch.solve(y[:,:n+1], H[:,:n+1,:n+1])[0][:, 1:n+1, 0] # (bsz x n)
X[:,k%m] = beta * (alpha[:,None] @ F[:,:n])[:,0] + (1-beta)*(alpha[:,None] @ X[:,:n])[:,0]
F[:,k%m] = f(X[:,k%m].view_as(x0)).view(bsz, -1)
res.append((F[:,k%m] - X[:,k%m]).norm().item()/(1e-5 + F[:,k%m].norm().item()))
if (res[-1] < tol):
break
return X[:,k%m].view_as(x0), res让我们看看这在实践中是什么样子。我们可以尝试对某些随机输入 x x x 评估不动点迭代,绘制所有批次上的平均(相对)残差
∥ f ( z k , x ) − z k ∥ 2 ∥ f ( z k , x ) ∥ 2 \frac{\|f(z^k,x) - z^k\|_2}{\|f(z^k,x)\|_2} ∥f(zk,x)∥2∥f(zk,x)−zk∥2
对于每次迭代。
python
import matplotlib.pyplot as plt
X = torch.randn(10,64,32,32)
f = ResNetLayer(64,128)
Z, res = anderson(lambda Z : f(Z,X), torch.zeros_like(X), tol=1e-4, beta=1.0)
plt.semilogy(res)
plt.xlabel("Iteration")
plt.ylabel("Relative residual")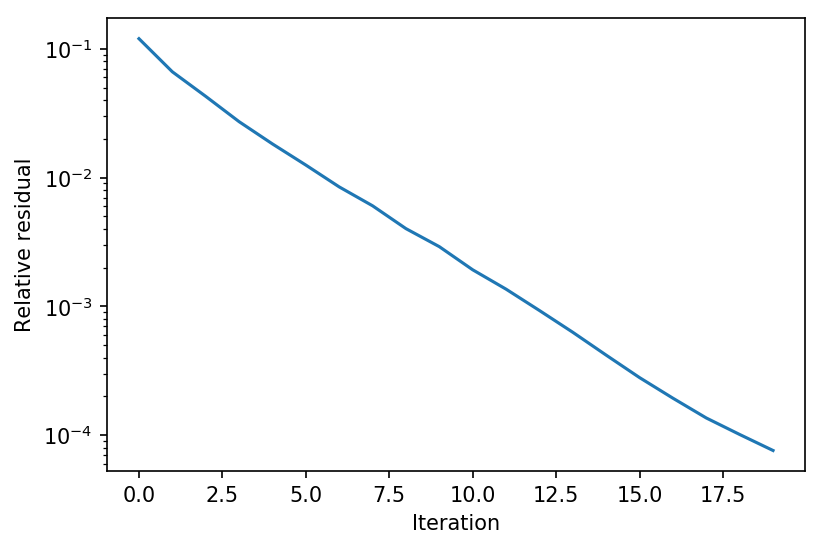
我们可以将其与朴素前向迭代进行比较,以了解 Anderson 加速的一些优势。由于这个系统相对稳定,差异(2倍迭代次数)并不那么显著,但随着完整 DEQ 模型训练的进行,Anderson 加速与简单前向迭代之间的差异变得更加明显。
python
def forward_iteration(f, x0, max_iter=50, tol=1e-2):
f0 = f(x0)
res = []
for k in range(max_iter):
x = f0
f0 = f(x)
res.append((f0 - x).norm().item() / (1e-5 + f0.norm().item()))
if (res[-1] < tol):
break
return f0, res
Z, res = forward_iteration(lambda Z : f(Z,X), torch.zeros_like(X), tol=1e-4)
plt.semilogy(res)
plt.xlabel("Iteration")
plt.ylabel("Relative residual")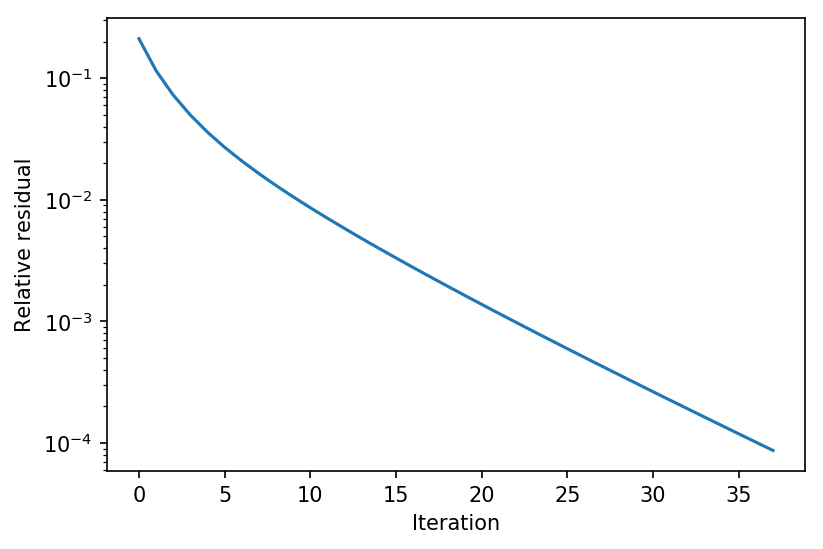
实现反向传播
如前所述,反向传播要求我们首先找到线性不动点方程的解
g = ( ∂ f ( z ⋆ , x ) ∂ z ⋆ ) T g + y . g = \left(\frac{\partial f(z^\star, x)}{\partial z^\star} \right )^T g + y. g=(∂z⋆∂f(z⋆,x))Tg+y.
然后计算最终的 Jacobian-向量积为
( ∂ z ⋆ ( ⋅ ) ∂ ( ⋅ ) ) T y = ( ∂ f ( z ⋆ , x ) ∂ ( ⋅ ) ) T g . \left (\frac{\partial z^\star(\cdot)}{\partial (\cdot)} \right)^T y = \left (\frac{\partial f(z^\star, x)}{\partial (\cdot)} \right )^T g. (∂(⋅)∂z⋆(⋅))Ty=(∂(⋅)∂f(z⋆,x))Tg.
这两个项中的向量-Jacobian 积 ( ∂ f ( z ⋆ , x ) ∂ z ⋆ ) T g \left(\frac{\partial f(z^\star, x)}{\partial z^\star} \right )^T g (∂z⋆∂f(z⋆,x))Tg 和 ( ∂ f ( z ⋆ , x ) ∂ ( ⋅ ) ) T g \left (\frac{\partial f(z^\star, x)}{\partial (\cdot)} \right )^T g (∂(⋅)∂f(z⋆,x))Tg 都是"标准"的向量-Jacobian 积,可以使用现有的自动微分工具计算。
这意味着在像 PyTorch 这样的库中实现一个通用的、可使用任何函数 f f f 的 DEQ 层实际上非常简单。所有工作都可以在标准的 nn.Module 类内完成(而不是例如需要单独实现前向/反向传播的 autograd.Function 类),利用内置的自动微分工具计算所有需要的导数。它基本上涉及三个步骤,我们在第1章中以不太通用(也不那么优雅,因为我们显式计算了 Jacobian)的形式描述过,但现在再次强调。
- 计算不动点 z ⋆ = f ( z ⋆ , x ) z^\star = f(z^\star,x) z⋆=f(z⋆,x)(例如使用 Anderson 加速),在自动微分带之外 (在 PyTorch 中,这意味着在
with torch.no_grad():块内运行)。 - 通过在平衡点处调用 z : = f ( z , x ) z := f(z,x) z:=f(z,x) 一次 来重新接合自动微分带。这会利用现有的自动微分库来计算 ( ∂ f ( z ⋆ , x ) ∂ ( ⋅ ) ) T \left (\frac{\partial f(z^\star, x)}{\partial (\cdot)} \right )^T (∂(⋅)∂f(z⋆,x))T 乘法。
- 添加一个后向钩子,接收传入的反向梯度 y y y 并使用例如 Anderson 加速再次求解不动点方程 g = ( ∂ f ( z ⋆ , x ) ∂ z ⋆ ) T g + y g = \left(\frac{\partial f(z^\star, x)}{\partial z^\star} \right )^T g + y g=(∂z⋆∂f(z⋆,x))Tg+y。
总的来说,代码相当简短,如下所示。
python
import torch.autograd as autograd
class DEQFixedPoint(nn.Module):
def __init__(self, f, solver, **kwargs):
super().__init__()
self.f = f
self.solver = solver
self.kwargs = kwargs
def forward(self, x):
# 计算前向传播并重新接合自动微分带
with torch.no_grad():
z, self.forward_res = self.solver(lambda z : self.f(z, x), torch.zeros_like(x), **self.kwargs)
z = self.f(z,x)
# 设置 Jacobian-向量积(无需额外的前向调用)
z0 = z.clone().detach().requires_grad_()
f0 = self.f(z0,x)
def backward_hook(grad):
g, self.backward_res = self.solver(lambda y : autograd.grad(f0, z0, y, retain_graph=True)[0] + grad,
grad, **self.kwargs)
return g
z.register_hook(backward_hook)
return z对于那些熟悉 PyTorch 的人,你可能会注意到我们更倾向于直接调用 autograd.grad(而不是高阶函数如 autograd.functional.vjp 等),因为它允许我们重复乘以这个 Jacobian 而无需重新运行前向传播。这种简洁性的一个小缺点是,它确实需要比严格必要的多两次对 f f f 的调用:一次是如上述步骤2所述重新接合梯度带,一次是设置 f0 变量(需要与 z 分开)。然而,考虑到我们通常需要多次调用 f f f 来进行前向求解本身,这增加了相对较少的计算开销。
为了验证这个层是否正确计算了梯度,我们可以使用 gradcheck 函数来验证解析梯度与数值计算的梯度是否匹配。注意,由于我们以这种稍微非标准的方式使用了 nn.Module(而不是 autograd.Function 类),这将只测试关于层输入 x x x 的梯度(而不测试关于参数的梯度),不过如果需要,我们也可以通过设置单独的函数来验证这些。我们还应该强调,上述函数不支持双重反向传播,不过如果需要,可以通过一些额外的努力来解决。
python
from torch.autograd import gradcheck
# 使用双精度运行一个非常小的网络,迭代到高精度
f = ResNetLayer(2,2, num_groups=2).double()
deq = DEQFixedPoint(f, anderson, tol=1e-10, max_iter=500).double()
gradcheck(deq, torch.randn(1,2,3,3).double().requires_grad_(), check_undefined_grad=False)True最后,让我们看看使用上述层计算前向和反向传播,并查看前向和反向迭代的相对残差。
python
f = ResNetLayer(64,128)
deq = DEQFixedPoint(f, anderson, tol=1e-4, max_iter=100, beta=2.0)
X = torch.randn(10,64,32,32)
out = deq(X)
(out*torch.randn_like(out)).sum().backward()
python
plt.semilogy(deq.forward_res)
plt.semilogy(deq.backward_res)
plt.legend(['Forward', 'Backward'])
plt.xlabel("Iteration")
plt.ylabel("Residual")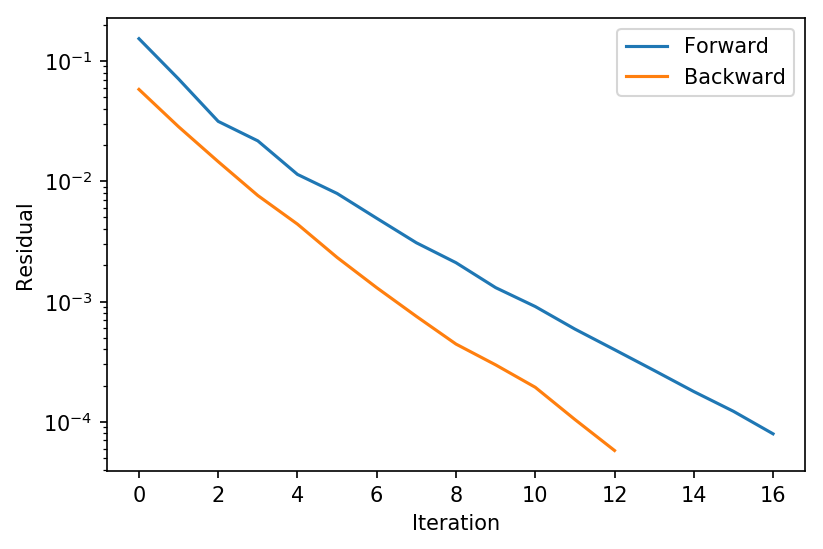
这里我们看到(可能并不太令人惊讶,因为它在求解线性而非非线性系统),反向传播通常比前向传播收敛得稍快一些;然而,在实践中这并不总是如此,事实上我们在下面会看到,在训练之后,反向传播通常收敛到的精度实际上低于前向传播。
训练你的 DEQ
最后,让我们将所有内容组合起来,在 CIFAR10 上实际训练一个卷积 DEQ 模型。以下代码在单个 GPU 上需要几个小时才能运行完毕,对于一个只能达到略高于 80% 准确率的模型来说,这似乎有些过分,不过我们有以下几点说明:
- 我们在 CIFAR10 上实际上运行了一个全卷积网络,它在整个 32x32 图像上保持了相当大的通道数,没有下采样。大多数合理的网络在有任何高通道数层之前都会进行大量下采样,虽然我们当然也可以为 DEQ 这样做,但我们希望强调一个仅在原始输入尺度上执行卷积的模型的简洁性。
- 该模型非常小,参数不到 10 万。这种规模的 ResNet 也能达到相当的准确率水平。
- 我们没有使用数据增强(尽管对于这么小的模型,添加数据增强只带来相对较小的收益)。
解决上述两点,并融入一个整合多尺度信息的单元 f f f,可以获得与最先进技术相竞争的结果 [Bai et al., 2020](https://arxiv.org/abs/2006.08656)(尽管应该强调的是,其运行时间确实仍然比具有相同参数数量的前馈模型慢)。
下面的模型展示了我们考虑的全部 DEQ 模型,其中包含一个应用于上述残差单元的 DEQ 层、一个卷积输入注入,以及在 DEQ 输出平均池化之后应用的一个线性层。在实践中,在 DEQ 层之前和之后应用某种形式的归一化也很重要:这里我们简单地使用 Batch Norm,它可以很好地"标准化"不动点迭代所看到的输入大小。
python
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
torch.manual_seed(0)
chan = 48
f = ResNetLayer(chan, 64, kernel_size=3)
model = nn.Sequential(nn.Conv2d(3,chan, kernel_size=3, bias=True, padding=1),
nn.BatchNorm2d(chan),
DEQFixedPoint(f, anderson, tol=1e-2, max_iter=25, m=5),
nn.BatchNorm2d(chan),
nn.AvgPool2d(8,8),
nn.Flatten(),
nn.Linear(chan*4*4,10)).to(device)现在让我们包含样板数据加载器和训练代码。这里没有什么特别的:没有数据增强,使用余弦退火学习率调度,使用 Adam 优化器训练 50 个 epoch(这些元素很可能都可以进一步改进)。
python
# CIFAR10 data loader
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
cifar10_train = datasets.CIFAR10(".", train=True, download=True, transform=transforms.ToTensor())
cifar10_test = datasets.CIFAR10(".", train=False, download=True, transform=transforms.ToTensor())
train_loader = DataLoader(cifar10_train, batch_size = 100, shuffle=True, num_workers=8)
test_loader = DataLoader(cifar10_test, batch_size = 100, shuffle=False, num_workers=8)
python
# 标准训练或评估循环
def epoch(loader, model, opt=None, lr_scheduler=None):
total_loss, total_err = 0.,0.
model.eval() if opt is None else model.train()
for X,y in loader:
X,y = X.to(device), y.to(device)
yp = model(X)
loss = nn.CrossEntropyLoss()(yp,y)
if opt:
opt.zero_grad()
loss.backward()
opt.step()
lr_scheduler.step()
total_err += (yp.max(dim=1)[1] != y).sum().item()
total_loss += loss.item() * X.shape[0]
return total_err / len(loader.dataset), total_loss / len(loader.dataset)以下代码现在将训练一个模型在 50 个 epoch 内达到约 81% 的准确率。再次强调,这段代码在单个 GPU 上需要几个小时才能运行完毕(在 Colab 上可能需要更长时间),但它希望能让你对构建这些中等规模的 DEQ 模型的相对容易程度有所了解。
python
import torch.optim as optim
opt = optim.Adam(model.parameters(), lr=1e-3)
print("# Parameters: ", sum(a.numel() for a in model.parameters()))
max_epochs = 50
scheduler = optim.lr_scheduler.CosineAnnealingLR(opt, max_epochs*len(train_loader), eta_min=1e-6)
for i in range(50):
print(epoch(train_loader, model, opt, scheduler))
print(epoch(test_loader, model))