引言:
在上一篇文章中,我们封装了自己的静态库和动态库,模拟了用户从编译到运行的全过程。在这个过程中,我们反复提到了一些概念:
.o文件、.a归档文件、.so共享对象,以及编译、链接、加载这几个阶段。我们也遇到了经典的问题------动态库编译通过却运行失败。这些现象背后的底层机制是什么?
.o文件和可执行文件到底是什么格式?链接器到底做了什么?操作系统又是如何把一个可执行文件加载到内存中运行的?动态库为什么能在运行时被找到并加载?这篇文章和下一篇联合起来,从目标文件 讲起,深入 ELF 文件格式 ,梳理从源代码到可执行程序再到内存中运行的完整轮廓,帮你真正理解链接与加载的原理。
一、目标文件
1.1 编译与链接的回顾
编译和链接这两个步骤,在 Windows 下被 IDE 封装得非常完美,我们一般都是一键构建,非常方便。但一旦遇到错误,尤其是链接相关的错误,很多人就束手无策了。在 Linux 下,我们之前也学习过如何通过 gcc 编译器来完成这一系列操作。
回顾一下什么是编译?编译的过程,就是将我们程序的源代码翻译成 CPU 能够直接运行的机器代码。
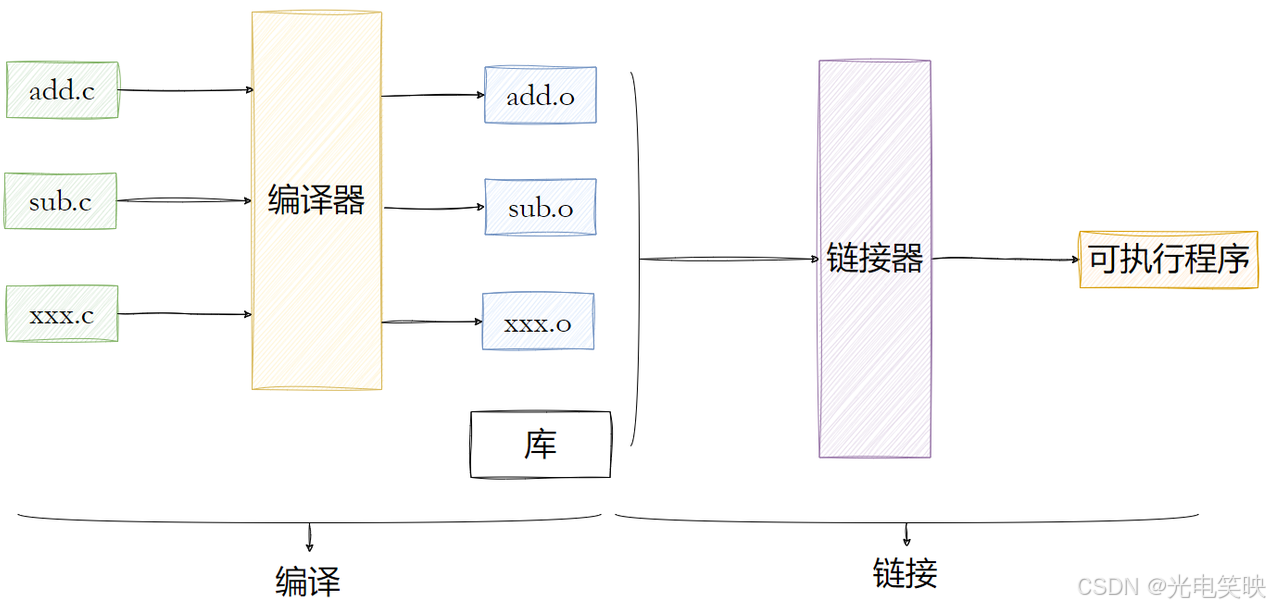
1.2 为什么需要目标文件?
我们之前的 mystring.c、mystdio.c 和 usercode.c 分别编译生成各自的 .o 文件。这样做的好处是:如果其中一个文件修改了,只需要单独对该文件重新编译生成新的 .o 文件,然后再与其他没有改变的 .o 文件重新链接,就能生成可执行程序,而不需要浪费时间重新编译整个工程。
这就是分离编译的意义------增量编译,节省时间。
1.3 目标文件是 ELF 格式
目标文件是一个二进制文件,文件的格式是 ELF(Executable and Linkable Format),本质上是对二进制代码的一种封装。
动静态库、可执行程序、.o 文件,都是 ELF 格式的。
bash
# .o 文件 → 可重定位文件
xqq@ubuntu-server:~/linux/module2/mkStaticLibrary$ file mystdio.o
mystdio.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
# .a 静态库 → 多个 .o 的归档
xqq@ubuntu-server:~/linux/module2/mkStaticLibrary$ readelf -a libmyc.a
File: libmyc.a(mystring.o)
ELF Header:
# ...
File: libmyc.a(mystdio.o)
ELF Header:
# ...(动态库也同理)
# 可执行程序
xqq@ubuntu-server:~/linux/module2/zhansan$ file usercode.exe
usercode.exe: ELF 64-bit LSB executable, x86-64, version 1 (GNU/Linux),
statically linked, BuildID[sha1]=..., for GNU/Linux 3.2.0, not stripped二、ELF⽂件
2.1 ELF 文件的四种类型
要理解编译链接的细节,我们不得不深入了解 ELF 文件。以下四种文件其实都是 ELF 文件: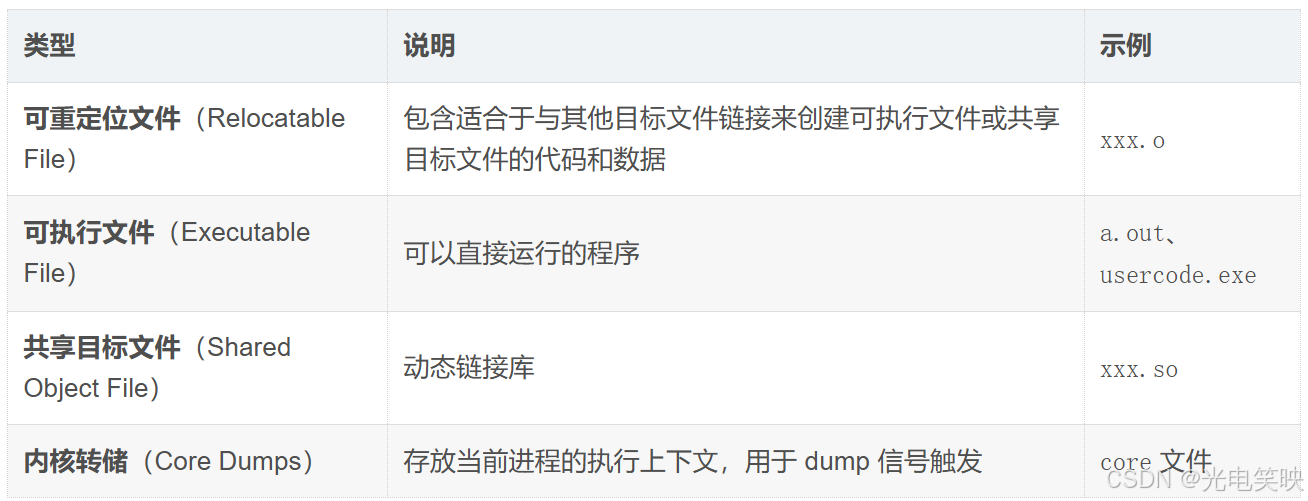
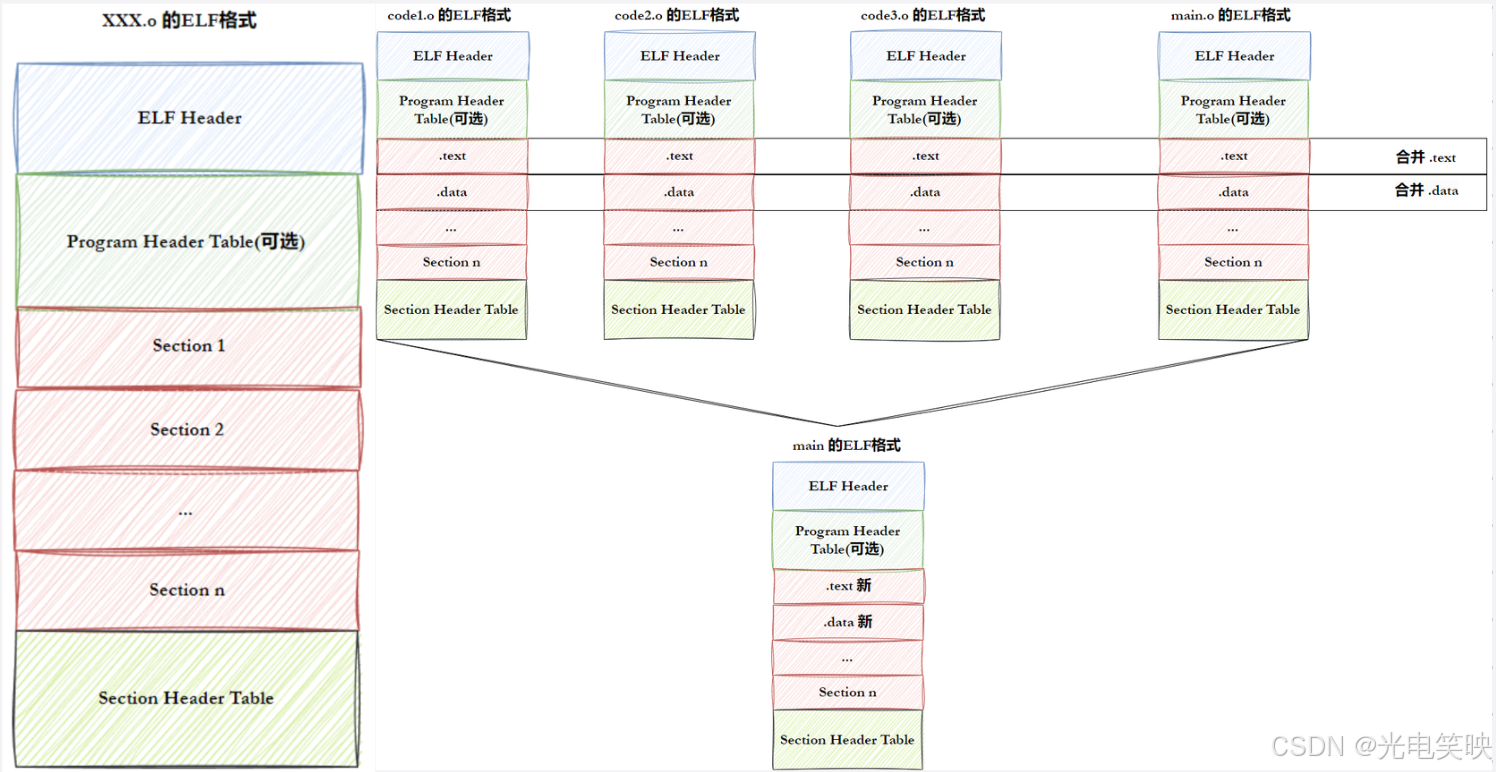
2.2 ELF 文件的组成
一个 ELF 文件由以下四部分组成:
可以这样理解:ELF 就是一个大文件,所谓的 Section 1 到 Section N,只需要知道相对于文件开头的偏移量以及长度,用起始偏移量加长度就可以确定一个 Section 的位置。
ELF Header 详解:
bash
用 readelf -h 可以查看 ELF 文件头信息,我们以可重定位文件和可执行文件为例:
# 查看目标文件(.o)
$ readelf -h hello.o
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 728 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 64 (bytes)
Number of section headers: 13
Section header string table index: 12各字段含义 :
2.3 最常见的 Section
用 readelf -S 可以查看所有 Section:
注意:为了减少篇幅,接下来大部分演示代码都有适当进行省略*。***
bash
xqq@ubuntu-server:~/linux/module2$ readelf -S /usr/bin/ls
There are 31 section headers, starting at offset 0x21428:
Section Headers:
[Nr] Name Type Address Offset Size Flags
[16] .text PROGBITS 0000000000004ce0 00004ce0 000123a2 AX # 代码段
[26] .data PROGBITS 00000000000022000 00021000 00000278 WA # 数据段
[27] .bss NOBITS 00000000000022280 00021278 000012c0 WA # 未初始化数据段
#查看 Linux 可执行文件(这里是 ls 命令)的内存段大小
xqq@ubuntu-server:~$ size /usr/bin/ls
text data bss dec hex filename
120338 4768 4800 129906 1fb72 /usr/bin/lsFlags 说明 :
A= Alloc(加载时分配内存),X= Execute(可执行),W= Write(可写)
2.4 特别关注:.bss 段
BSS 段用于存储未初始化或初始化为 0 的全局变量和静态变量。
程序的变量,从存储位置来看可以分为: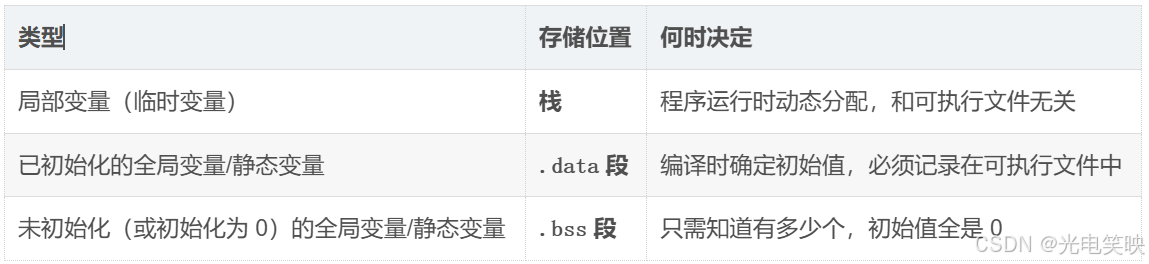
对于已初始化的全局变量:
cpp
int a = 100; // 初始值 100 必须存储在可执行文件中对于未初始化的全局变量:
cpp
int b; // 未初始化,默认值 0
int c; // 未初始化,默认值 0
static int d; // 未初始化,默认值 0如果每定义一个未初始化的全局变量,.data 段就要记录一个默认值 0,那 50 个这样的变量就要存 50 个 0,这完全是浪费磁盘空间。
.bss 的设计哲学:
磁盘上只存一个数字(比如 50),表示"有 50 个字节的未初始化全局变量"。加载到内存时,操作系统读取这个数字,在内存中开辟对应大小的空间,然后全部初始化为 0。
三、ELF 从形成到加载的轮廓
3.1 ELF 形成可执行程序
回顾静态库形成可执行程序的过程:
Step 1 :将多份 C/C++ 源代码,翻译成为目标 .o 文件
Step 2 :将多份 .o 文件的 Section 进行合并
静态链接 的本质,就是将各个 .o 文件的代码节(.text)和数据节(.data、.bss 等)抽取出来,合并到最终的 ELF 可执行文件中。
实际合并过程是在链接时进行的,但并不是简单的拼接,还涉及对库的合并、符号解析和重定位等复杂处理,此处不做过多展开。
关于静态库的链接 :静态库(.a)本质上是 .o 文件的归档。链接时,链接器会根据需要,从静态库中提取出被引用了符号的那些 .o 文件,然后和其他 .o 文件一起进行上述合并过程。未被引用的 .o 文件不会被链接进来。
3.2 ELF 可执行文件加载到内存(重点)
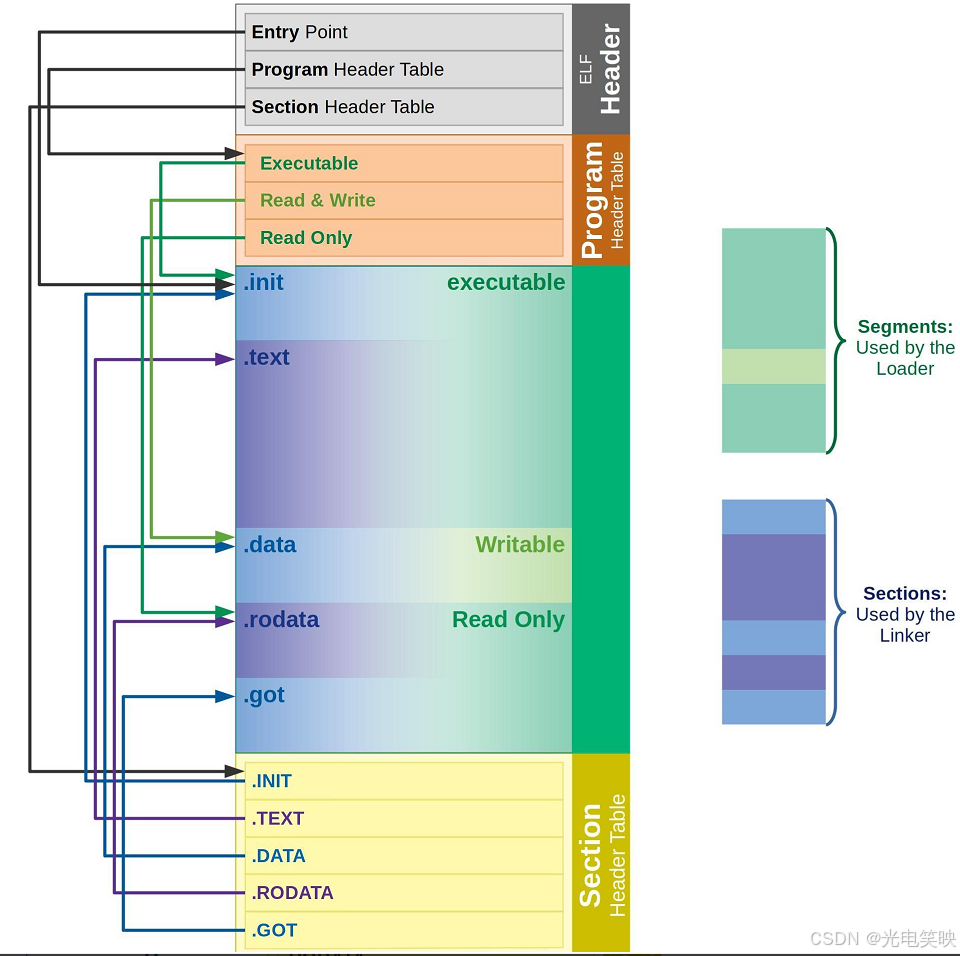
3.2.1 Section 合并为 Segment
一个 ELF 会有多种不同的 Section,在加载到内存的时候,会进行 Section 合并,形成 Segment。
为什么字符串常量是只读的?
在之前我们说字符串常量是只读的,其实就是因为 .rodata(字符常量区)和 .text(代码区)被合并到了同一个只读 Segment,由于代码区必须是只读的(防止程序意外修改自身指令),所以字符常量区也跟着只读了。这就是 Section 合并的结果。
Segment 的本质:
多个 Section 按权限合并 → 形成一个 Segment → 操作系统按 Segment 加载到内存
合并原则:
-
相同属性,比如:可读、可写、可执行
-
需要加载时申请空间的放在一起
这样,即便是不同的 Section,在加载到内存中时,会以 Segment 的形式加载到一起。
这个合并方式在形成 ELF 时就已经确定 ,具体合并规则被记录在 ELF 的**程序头表(Program Header Table)**中。
用 readelf -l 查看 Segment 合并情况:
bash
xqq@ubuntu-server:~/linux/module2$ readelf -l /usr/bin/ls
Elf file type is DYN (Position-Independent Executable file)
Entry point 0x6aa0
There are 13 program headers, starting at offset 64
Program Headers:
Type Offset VirtAddr PhysAddr
FileSiz MemSiz Flags Align
LOAD 0x0000000000000000 0x0000000000000000 0x0000000000000000
0x0000000000003458 0x0000000000003458 R 0x1000
LOAD 0x0000000000004000 0x0000000000004000 0x0000000000004000
0x0000000000013091 0x0000000000013091 R E 0x1000 ← 代码段(只读+执行)
LOAD 0x0000000000018000 0x0000000000018000 0x0000000000018000
0x0000000000007458 0x0000000000007458 R 0x1000
LOAD 0x000000000001ffd0 0x0000000000020fd0 0x0000000000020fd0
0x00000000000012a8 0x0000000000002570 RW 0x1000 ← 数据段(可读写)
Section to Segment mapping:
Segment Sections...(原本 30 个左右的 Section 合并成了 13 个 Segment)
03 .init .plt .plt.got .plt.sec .text .fini
04 .rodata .eh_frame_hdr .eh_frame
05 .init_array .fini_array .data.rel.ro .dynamic .got .data .bss
# .data 和 .bss 合并到同一个 Segment,加载时就一起加载了3.2.2 为什么要将 Section 合并为 Segment?
原因一:减少页面碎片,提高内存使用效率
操作系统以**页(Page,通常 4096 字节)**作为内存管理的基本单位。磁盘与内存的交互也是以 4KB 为单位进行的。
举个例子:
-
假设
.text部分为 4097 字节,.init部分为 512 字节 -
如果不合并,它们将占用 3 个页面(4097 占 2 页 + 512 占 1 页)
-
合并后,它们只需 2 个页面
我们之前讲的父子进程写时拷贝问题也是同理:虽然只修改了一个数据(比如 4 字节的 int),但操作系统要将这 4 字节所在的整个 4KB 页面全部拷贝过去。这就是空间换时间------将来如果要访问附近的数据,就不用再拷贝了。
原因二:实现不同的访问权限
操作系统在加载程序时,将具有相同属性的 Section 合并成一个大 Segment,从而设置统一的访问权限(只读、可读写、可执行),优化内存管理和权限访问控制。
3.2.3 ELF 如何转化为进程:虚拟地址、物理地址、逻辑地址的关系(重点)
当我们在 Shell 中输入 ./usercode.exe 时,操作系统通过 execve() 系统调用加载程序:
 三个地址概念:
三个地址概念:
| 概念 | 说明 |
|---|---|
| 逻辑地址 | 程序代码中使用的地址,在无分段机制下等同于虚拟地址 |
| 虚拟地址 | 每个进程看到的地址空间,ELF 文件中记录的所有地址都是虚拟地址 |
| 物理地址 | 实际内存条上的地址 |
映射关系 :
每个进程拥有独立的页表,因此:
-
进程 A 的虚拟地址
0x400000可能映射到物理地址0x1234000 -
进程 B 的虚拟地址
0x400000可能映射到物理地址0x5678000 -
两个进程互不干扰,这就是虚拟内存的核心价值
进程的本质 = 内核数据结构(PCB / task_struct)+ 独立的虚拟地址空间 + ELF 映射到内存中的代码和数据。
3.2.4 构建页表时设置权限
页表中不仅记录了虚拟地址到物理地址的映射,还记录了每个页面的访问权限。这些权限就是在加载 ELF 时,根据 Program Header Table 中每个 Segment 的 Flags 来设置的:
-
R E(只读+执行)→ 对应的页表项设置为可读可执行 -
RW(可读写)→ 对应的页表项设置为可读可写
段错误(Segmentation Fault)的"段" ,正是指 Segment 的权限保护------当你试图写入一个只读 Segment 时,MMU 检测到权限违规,向 CPU 发出异常信号,操作系统便向进程发送 SIGSEGV 信号。
3.3 两个视图:链接视图 vs 执行视图
ELF 文件提供了两个不同的视角来理解节头表和程序头表结构:
链接视图:
-
文件结构的粒度更细,将文件按功能模块的差异进行划分
-
静态链接时一般关注的是链接视图,能够理解 ELF 文件中包含的各个部分的信息
-
为了空间布局上的效率,链接器会把很多小的 Section 按权限合并,规整成只读段、可读写段等。合并后空间利用率就高了,否则很小的一个小段,物理内存页浪费太大(物理内存页分配一般都是整数倍,比如 4KB)
执行视图:
-
告诉操作系统,如何加载可执行文件,完成进程内存的初始化
-
一个可执行程序的格式中,一定有 Program Header Table
-
加载程序时,OS 读取 Program Header Table,根据描述找到加载文件的位置(起始、偏移量),按指定大小,把若干个数据节依次连续加载到内存
-
同时根据 Flags 设置页表权限:哪些分段可读可写,哪些分段只读,哪些分段可执行------构建页表时直接将权限写进去即可
readelf 命令速查
readelf 是查看 ELF 文件结构的专用工具,只适用于 ELF 格式的文件。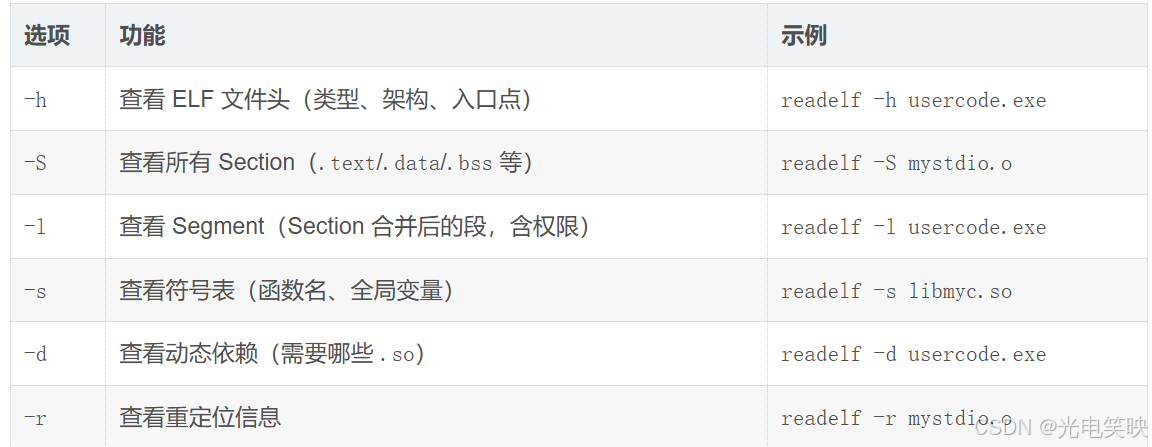
四、理解静态连接
在前面的章节中,我们了解了 ELF 的文件结构,以及 Section 如何合并为 Segment 加载到内存。这一节,我们深入到链接 和加载的具体过程,看看那些"未定义的符号"是如何被修正的,虚拟地址又是如何贯穿整个流程的。
4.1 理解静态链接
下面以这份代码为例:
cpp
// code.c
#include<stdio.h>
void run()
{
printf("running...\n");
}
// hello.c
#include<stdio.h>
void run(); // 函数声明可以不加 extern,编译器能区分定义和声明
// 但变量声明必须加 extern
int main()
{
printf("hello world!\n");
run();
return 0;
}无论是自己的 .o,还是静态库中的 .o,本质都是把 .o 文件进行连接的过程。所以研究静态链接,本质就是研究 .o 是如何链接的。
4.1.1 链接前:各 .o 彼此不认识
用 objdump -d 反汇编查看链接前的目标文件:
bash
xqq@ubuntu-server:~/linux/module3$ objdump -d code.o
code.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <run>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # f <run+0xf>
f: 48 89 c7 mov %rax,%rdi
12: e8 00 00 00 00 call 17 <run+0x17>
17: 90 nop
18: 5d pop %rbp
19: c3 ret
bash
xqq@ubuntu-server:~/linux/module3$ objdump -d hello.o
hello.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <main>:
0: f3 0f 1e fa endbr64
4: 55 push %rbp
5: 48 89 e5 mov %rsp,%rbp
8: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # f <main+0xf>
f: 48 89 c7 mov %rax,%rdi
12: e8 00 00 00 00 call 17 <main+0x17>
17: b8 00 00 00 00 mov $0x0,%eax
1c: e8 00 00 00 00 call 21 <main+0x21>
21: b8 00 00 00 00 mov $0x0,%eax
26: 5d pop %rbp
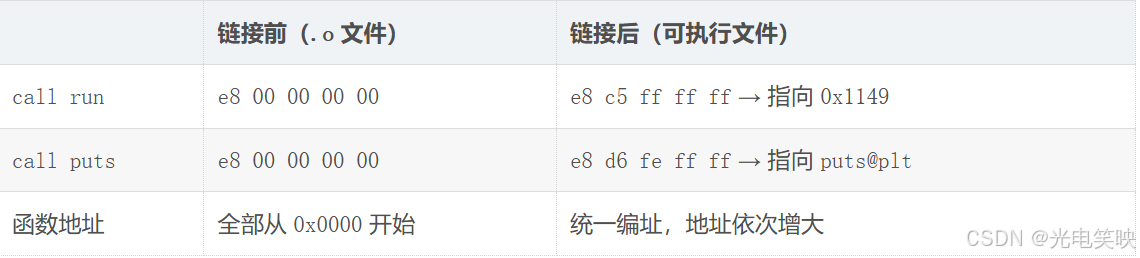
27: c3 ret关键发现 :call 指令的机器码是 e8,但后面的地址全是 00 00 00 00。也就是说,hello.o 中的 main 函数不认识 printf 和 run 函数------因为在编译 hello.c 的时候,编译器完全不知道这些函数的存在,不知道它们位于内存的哪个位置,代码长什么样。因此,编译器只能将这两个函数的跳转地址暂时设为 0。
即使代码中写一个从未出现过的
haha(),编译时也不会报错。 编译器只知道这是个函数调用,但不知道这个函数在哪里。
这就是我们之前的结论:多个 .o 彼此不知道对方的存在。
4.1.2 符号表:UND 的含义
用 readelf -s 查看符号表:
bash
xqq@ubuntu-server:~/linux/module3$ readelf -s code.o
Symbol table '.symtab' contains 6 entries:
Num: Value Size Type Bind Vis Ndx Name
4: 0000000000000000 26 FUNC GLOBAL DEFAULT 1 run
5: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND puts # 未定义
xqq@ubuntu-server:~/linux/module3$ readelf -s hello.o
Symbol table '.symtab' contains 7 entries:
Num: Value Size Type Bind Vis Ndx Name
4: 0000000000000000 40 FUNC GLOBAL DEFAULT 1 main
5: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND puts # 未定义
6: 0000000000000000 0 NOTYPE GLOBAL DEFAULT UND run # 未定义UND 就是 Undefined(未定义) ,表示这个符号在当前 .o 文件中找不到定义。puts 是 printf 的底层实现,run 是我们自己的函数------它们都在 hello.o 中显示为 UND。
链接时,链接器会去其他的 .o 文件或库中查找这些 UND 符号,把它们一一找到并建立联系。
4.1.3 链接后:符号找到了,地址修正了
查看最终可执行程序的符号表:
bash
xqq@ubuntu-server:~/linux/module3$ readelf -s main.exe
Symbol table '.symtab' contains 38 entries:
Num: Value Size Type Bind Vis Ndx Name
22: 0000000000000000 0 FUNC GLOBAL DEFAULT UND puts@GLIBC_2.2.5
24: 0000000000001149 26 FUNC GLOBAL DEFAULT 16 run # 找到了!
33: 0000000000001163 40 FUNC GLOBAL DEFAULT 16 main-
run:从UND变成了有具体地址0x1149,找到了。 -
puts:仍然是UND,因为它来自动态库,需要运行时由动态链接器解析(后面详细说明)。 -
16:代表run函数所在的 Section 索引。
验证 Section 索引:
bash
xqq@ubuntu-server:~/linux/module3$ readelf -S main.exe
There are 31 section headers, starting at offset 0x36d0:
Section Headers:
[16] .text PROGBITS 0000000000001060 00001060
000000000000012b 0000000000000000 AX 0 0 16索引 16 正是 .text 代码段 ------hello.o 和 code.o 的 .text 被合并到了 main.exe 的第 16 个 Section。
4.1.4 验证:call 后面的地址被修正了
用 objdump -d 反汇编最终的可执行程序:
bash
xqq@ubuntu-server:~/linux/module3$ objdump -d main.exe
Disassembly of section .text:
0000000000001149 <run>:
1149: f3 0f 1e fa endbr64
114d: 55 push %rbp
114e: 48 89 e5 mov %rsp,%rbp
1151: 48 8d 05 ac 0e 00 00 lea 0xeac(%rip),%rax
1158: 48 89 c7 mov %rax,%rdi
115b: e8 f0 fe ff ff call 1050 <puts@plt> # 有地址了!
1160: 90 nop
1161: 5d pop %rbp
1162: c3 ret
0000000000001163 <main>:
1163: f3 0f 1e fa endbr64
1167: 55 push %rbp
1168: 48 89 e5 mov %rsp,%rbp
116b: 48 8d 05 9d 0e 00 00 lea 0xe9d(%rip),%rax
1172: 48 89 c7 mov %rax,%rdi
1175: e8 d6 fe ff ff call 1050 <puts@plt> # puts 也找到了
117a: b8 00 00 00 00 mov $0x0,%eax
117f: e8 c5 ff ff ff call 1149 <run> # run 找到了!
1184: b8 00 00 00 00 mov $0x0,%eax
1189: 5d pop %rbp
118a: c3 ret对比链接前后的变化:
地址从上到下依次增大,这就是平坦模式(Flat Mode)的体现。
4.1.5 静态链接的本质总结
结论:
-
多个
.o的代码段合并到一起,进行了统一的编址。 -
链接时,会修正
.o中没有确定的函数地址 ------链接器根据重定位表找到那些需要被重定位的函数和全局变量,把call后面的00 00 00 00修正为最终地址。
静态链接就是 :将编译之后的所有目标文件连同用到的一些静态库、运行时库组合、拼装成一个独立的可执行文件。其中核心工作就是地址修正 ------根据 .o 文件或静态库中的重定位表,找到需要重定位的符号,修正它们的地址。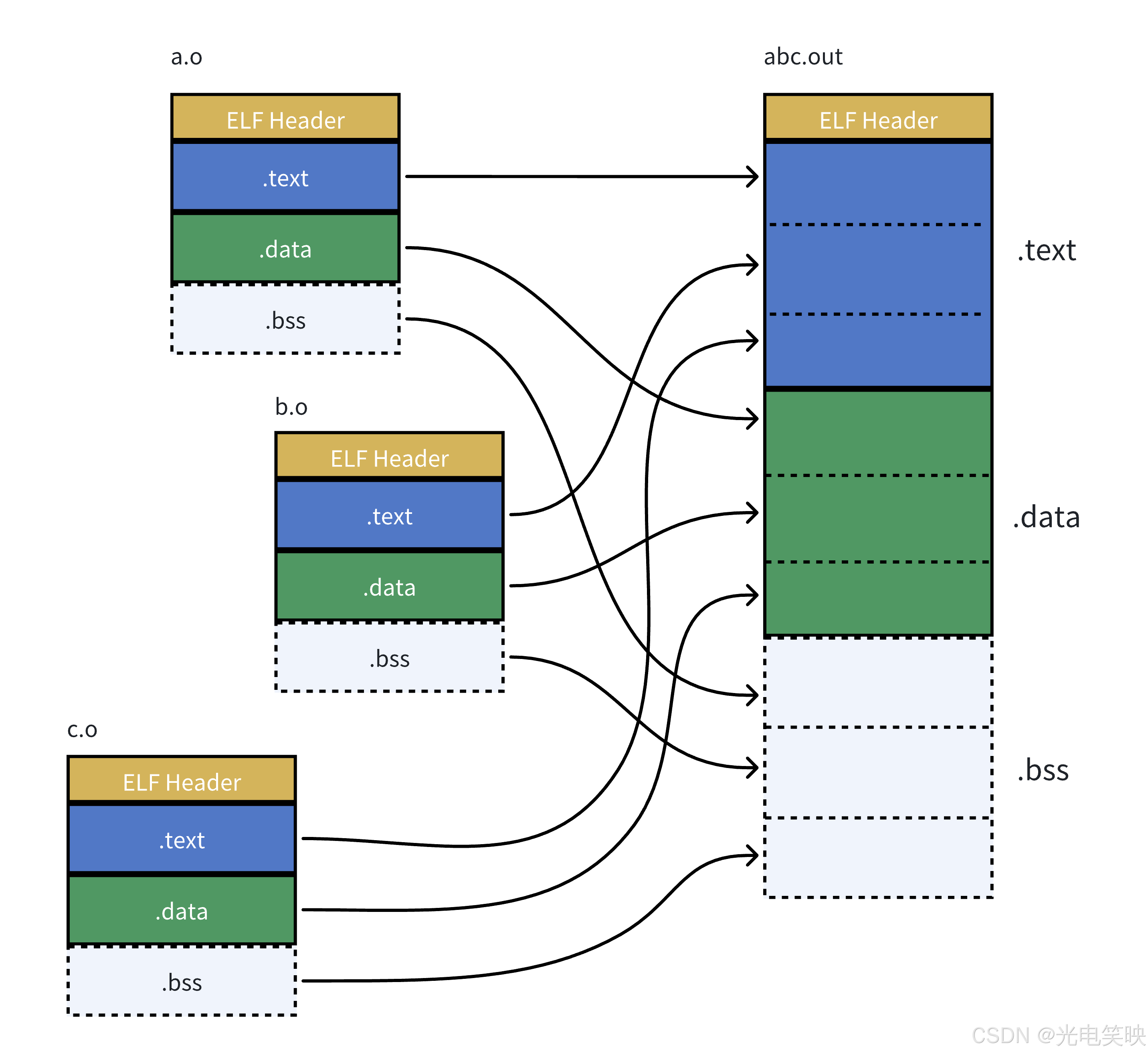
这也就解释了为什么
.o文件叫做"可重定位目标文件"(Relocatable File)------因为链接时它的地址会被修改(重定位)。
4.2 ELF 加载与进程地址空间
4.2.1 虚拟地址 / 逻辑地址
问题一:一个 ELF 程序,在没有被加载到内存的时候,有没有地址?
有! 当代计算机工作时都采用平坦模式 进行工作,所以也要求 ELF 对自己的代码和数据进行统一编址 。用 objdump -d 反汇编后,最左侧的那一列就是 ELF 的地址。
严格意义上应该叫做逻辑地址 (起始地址 + 偏移量),但我们可以认为起始地址是 0。也就是说,虚拟地址在程序还没有加载到内存的时候,就已经在可执行文件中编好了。
所有的可执行程序就是一个大的 Segment,所有的函数、变量编址都是从 0 开始的。后面使用某个函数或变量,就不在意函数名或变量名了,统一使用磁盘上编址的逻辑地址。
注意:虽然说是从 0 开始编址的,但 0 号地址不一定会被使用。系统中可执行程序有一部分地址专门用作其他用途,程序一定是从某个地址开始编的。
问题二:进程的 mm_struct、vm_area_struct 在进程刚刚创建的时候,初始化数据从哪里来?
从 ELF 的各个 Segment 来。 每个 Segment 有自己的起始地址和长度,用来初始化内核结构中的 [start, end] 等范围数据。另外,用详细地址填充页表。
加载程序时,OS 会读取 Program Headers,用可执行程序的虚拟地址直接来初始化 mm_struct、vm_area_struct,将各个区域联系起来。
所以之前所说的将各个 Section 合并为 Segment,其实就是方便对可执行程序统一编址。 于是我们的
main、run函数就有了一个虚拟地址,链接时将call后面的地址一填,可执行程序间的调用关系就产生了。
所以:虚拟地址机制,不光 OS 要支持,编译器也要支持。
4.2.2 硬币的正反面:逻辑地址 = 虚拟地址
之前我们在学习虚拟地址空间时谈到虚拟地址,不仅是进程看待内存的方式,也是磁盘上编址的逻辑地址。
逻辑地址和虚拟地址其实是同一个东西,只不过看待它的角度不同:
-
正面(逻辑地址):链接器在磁盘上统一对 ELF 可执行程序进行编址
-
反面(虚拟地址):进程在内存中运行时,这个地址就是进程看到的虚拟地址
就像看到一枚硬币,一个看到的是正面,一个是反面------本质是同一个东西。
4.2.3 重新理解进程虚拟地址空间
ELF 在被编译好之后,会把程序的入口地址 记录在 ELF Header 的 Entry point address 字段中:
bash
xqq@ubuntu-server:~/linux/module3$ readelf -h main.exe
ELF Header:
......
Entry point address: 0x1060
......
xqq@ubuntu-server:~/linux/module3$ readelf -h /usr/bin/ls
ELF Header:
......
Entry point address: 0x6aa0
......Entry point address 指向的是 _start,不是 main。
查看反汇编:
bash
xqq@ubuntu-server:~/linux/module3$ cat main.s
0000000000001060 <_start>:
1060: f3 0f 1e fa endbr64
......
1078: 48 8d 3d e4 00 00 00 lea 0xe4(%rip),%rdi # 1163 <main>
107f: ff 15 53 2f 00 00 call *0x2f53(%rip) # 3fd8 <__libc_start_main@GLIBC_2.34>
......真正的启动流程:
Entry point address 是 _start 的入口,_start 会去调用 main,中间隔了 _start 和 __libc_start_main 两层。
4.3程序加载与 CPU 调度流程
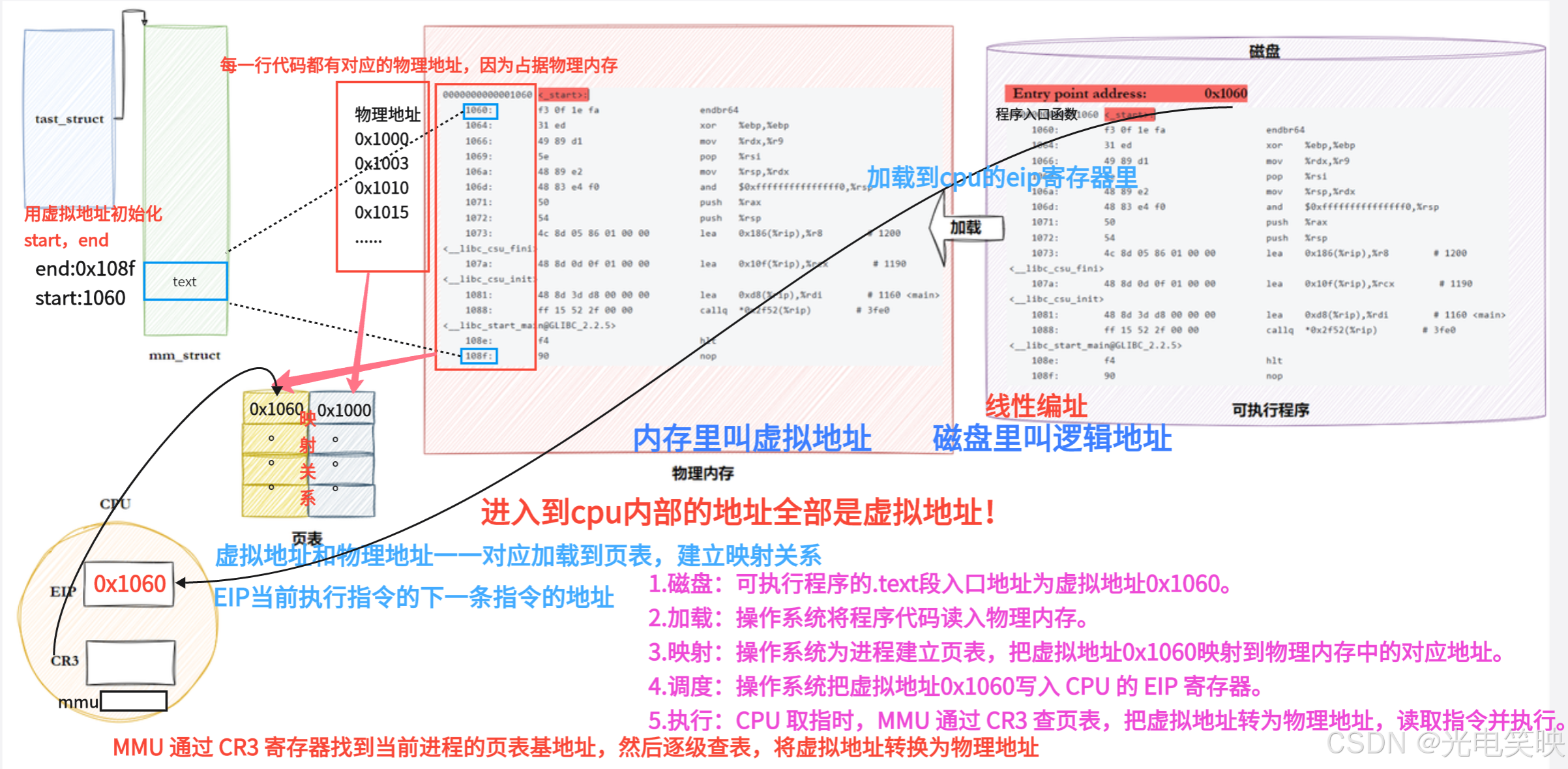
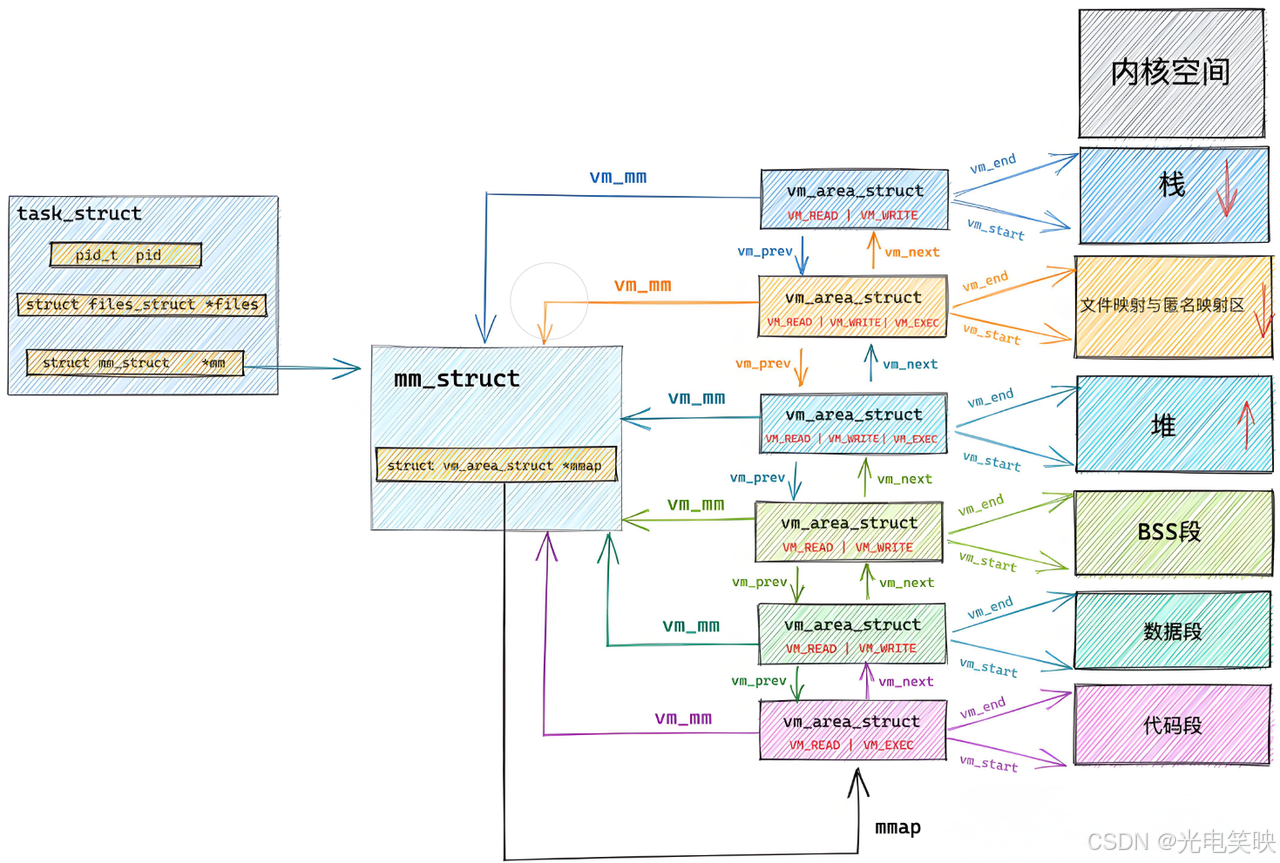
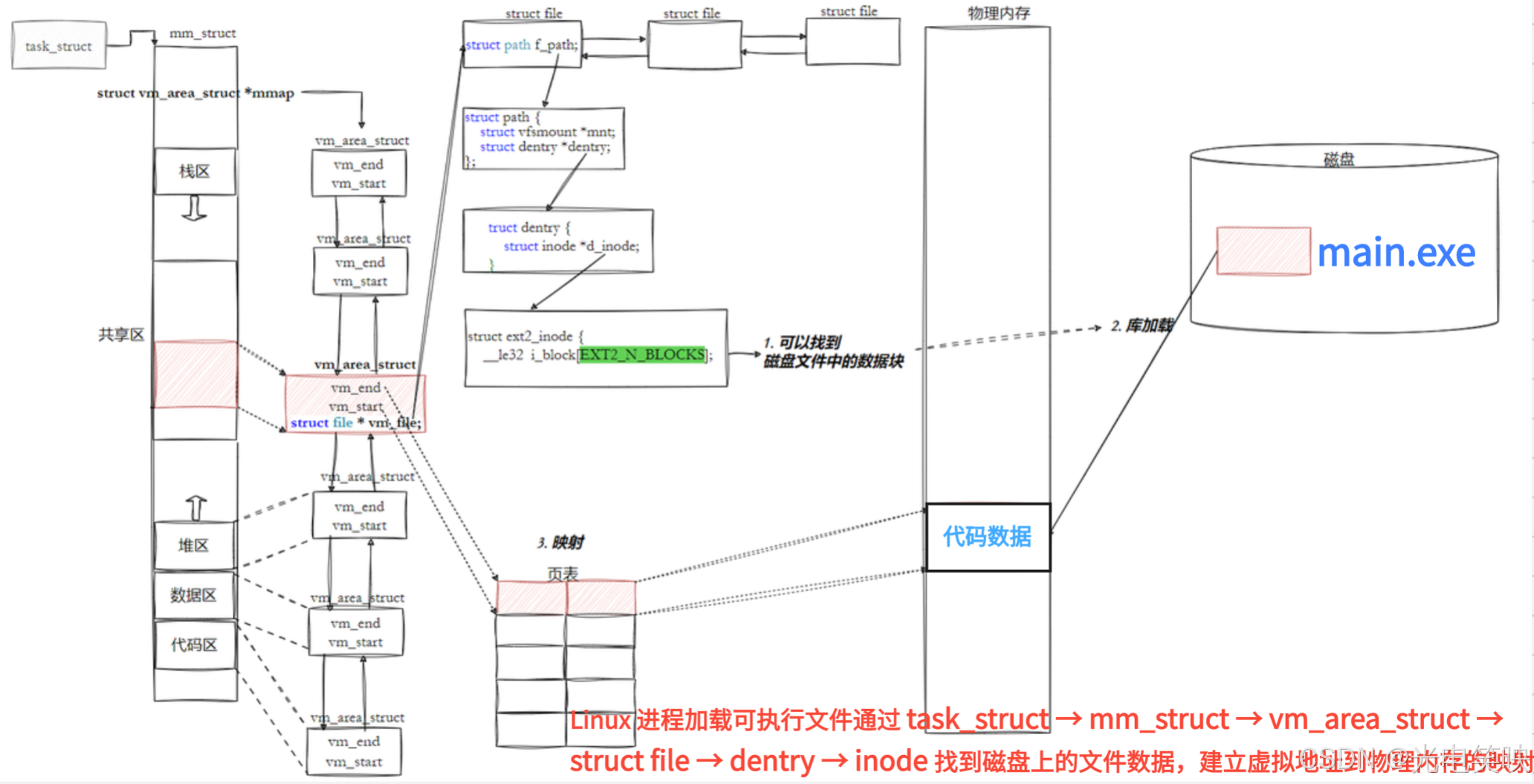
4.4 总结
-
静态链接的本质 :多个
.o合并 → 统一编址 → 修正call地址 → 生成可执行文件 -
.o文件中的UND:表示符号在外部,链接时去其他.o或库中查找 -
逻辑地址 = 虚拟地址:同一枚硬币的正反面,链接器分配的就是加载后的虚拟地址
-
虚拟地址贯穿全过程:编译器支持、链接器分配、操作系统加载使用
-
Entry point :
_start是真正入口,会调用__libc_start_main,最终才到main
注意 :本节中
puts的地址仍然是puts@plt,涉及动态链接。动态库的链接过程更加复杂,我们将在下一节详细讲解------包括 GOT、PLT 机制以及动态库如何被加载到进程地址空间。
总结
1. 静态库是如何形成可执行程序的
编译
.c→.o
ar打包.o→.a链接:把
main.o+libmyc.a中的相关.o提取出来 → 符号解析 + 重定位 → 可执行程序静态库本质是
.o的归档,链接器按需从中提取目标文件2. ELF 程序是怎么加载到内存的(重点)
可执行程序的 ELF 结构:Program Header Table 定义了多个 Segment
操作系统
execve()→ 读取 ELF 文件头 → 解析 Program Headers → 按 Segment 权限映射到虚拟地址空间延迟加载(页错误机制):不是一次性全部加载,而是用到哪页加载哪页
3. ELF 是怎么转化为进程的(逻辑、物理、虚拟地址的关系)(重点)
虚拟地址:每个进程看到的地址空间,ELF 中的地址都是虚拟地址
物理地址:实际内存条的地址
逻辑地址:程序使用的地址(在无分段的情况下 = 虚拟地址)
MMU + 页表 → 虚拟地址 → 物理地址的映射
进程 = 内核数据结构(PCB/task_struct)+ 独立的虚拟地址空间 + ELF 映射到内存的代码和数据
Page Fault → 缺页中断 → 从磁盘加载到物理内存 → 更新页表