很多人刚开始设计数据库表时,最容易有一个想法:
字段能存进去就行。
但项目真正跑起来以后,问题往往就来了:
- 为什么表越来越大,查询越来越慢?
- 为什么明明加了索引,SQL 还是慢?
- 为什么手机号不能用数字类型?
- 为什么金额不能用 double?
- 为什么 limit 100000, 10 会这么慢?
- 为什么并发注册时,代码里判断了手机号不存在,还是插入了重复数据?
这些问题,表面看是 SQL 问题,背后其实是表结构、字段类型、索引设计和查询方式共同决定的。
这篇文章就围绕 MySQL 表设计和 SQL 优化,把常见高频知识点系统梳理一遍。
一、数据库表设计要考虑什么?
设计表时,不能只想着"能存就行",还要考虑后面的查询、扩展和性能。
常见需要考虑这些点:
| 设计点 | 说明 |
|---|---|
| 字段是否合理 | 是否真的符合业务实体 |
| 类型是否合适 | 能用小类型就不用大类型 |
| 是否需要索引 | 高频查询字段要考虑索引 |
| 是否需要唯一约束 | 手机号、订单号等天然唯一字段要兜底 |
| 是否方便查询 | 表结构要服务常见查询场景 |
| 是否方便扩展 | 后续业务变化时尽量少大改 |
比如一个用户表可以这样设计:
sql
create table user
(
id bigint primary key auto_increment,
username varchar(50) not null, phone varchar(20) not null,
password varchar(100) not null,
status tinyint not null default 1,
deleted tinyint not null default 0,
create_time datetime not null, update_time datetime not null,
unique key uk_phone (phone)
);面试时可以这样说:
我会根据业务查询场景设计字段和索引,不会脱离业务盲目建表。
二、为什么主键一般用 bigint?
很多项目里主键会这样设计:
id bigint primary key
主要原因是 int 的范围有限,大约 21 亿。
对于用户表、订单表、日志表、消息表这类长期增长的数据表,数据量可能越来越大,bigint 会更稳妥。
不过也不是所有表都必须用 bigint。
比如一些小型字典表、配置表,数据量很小,用 int 也可以。
可以简单总结:
| 场景 | 推荐 |
|---|---|
| 用户表、订单表、日志表 | bigint |
| 字典表、枚举表、小配置表 | int 也可以 |
| 分布式 ID | bigint 趋势递增 ID |
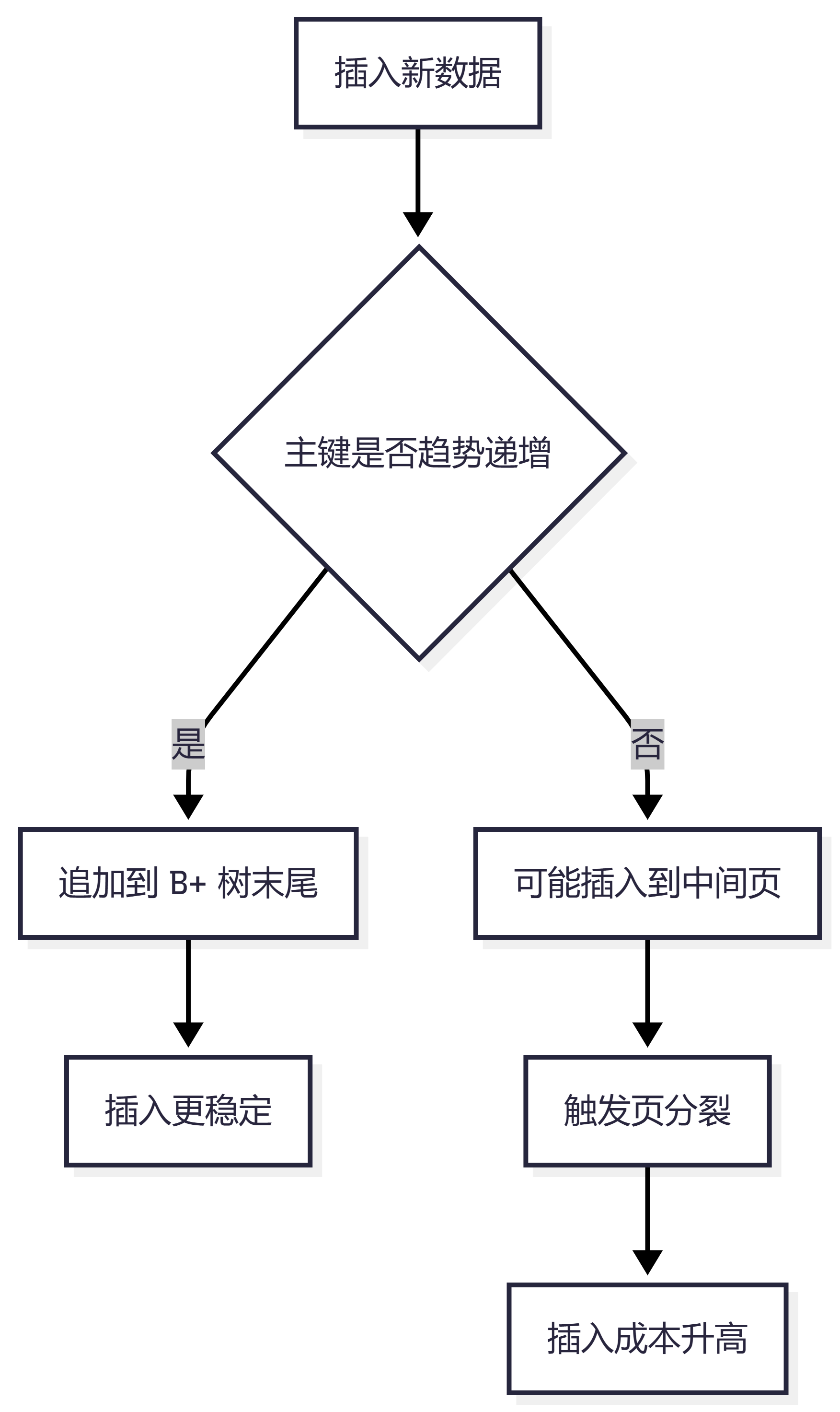
三、主键为什么建议自增或趋势递增?
InnoDB 的主键索引是聚簇索引,表数据会按照主键顺序组织。
如果主键是自增的,插入数据通常追加到末尾:
1 -> 2 -> 3 -> 4 -> 5
这种方式比较高效。
如果主键是完全随机的,比如 UUID:
9a... -> 1f... -> c3... -> 02...
新数据可能插入到 B+ 树中间,容易导致页分裂,影响插入性能。
流程可以这样理解:
面试答法:
InnoDB 表数据按主键索引组织,自增或趋势递增主键能减少页分裂,提高插入性能。
四、为什么不建议直接用 UUID 做主键?
UUID 的问题主要有三个:
| 问题 | 说明 |
|---|---|
| 太长 | UUID 通常比 bigint 更占空间 |
| 无序 | 容易导致 B+ 树页分裂 |
| 影响二级索引 | 二级索引叶子节点会存主键值 |
InnoDB 的二级索引叶子节点保存的是:
索引字段 + 主键值
所以主键越大,所有二级索引也会跟着变大。
如果业务需要分布式唯一 ID,更推荐使用雪花算法这类趋势递增 ID,而不是完全随机 UUID。
五、字段类型为什么要尽量小?
字段类型越小,通常越有利于性能。
原因很简单:
字段越小 -> 一页能存的数据越多 -> 索引占用空间越小 -> 查询时磁盘 IO 越少 -> Buffer Pool 缓存命中率越高
比如状态字段:
status tinyint
就比下面这种更合适:
status varchar(20)
常见字段类型可以这样选:
| 字段 | 推荐类型 |
|---|---|
| 性别、状态、类型 | tinyint |
| 数量、积分 | int 或 bigint |
| 金额 | decimal |
| 手机号 | varchar |
| 创建时间、更新时间 | datetime |
| 逻辑删除 | tinyint |
当然,小不是唯一标准,语义正确也很重要。
六、金额为什么不用 float 或 double?
金额不建议用 float 或 double,因为它们是浮点数,可能存在精度误差。
比如在很多编程语言里:
0.1 + 0.2 可能不等于 0.3
金额这种数据对精度非常敏感,不能有误差。
数据库里常见做法是:
sql
amount decimal(10, 2)或者用整数存"分":
100.25 元 -> 10025 分
Java 后端中金额通常也会使用:
BigDecimal
简单记:
金额不要用 float/double,用 decimal 或整数分。
七、varchar 和 char 有什么区别?
char 是固定长度,varchar 是可变长度。
比如:
char(10)
即使只存 "abc",也会按固定长度处理。
而:
varchar(10)
存 "abc" 时,会按照实际长度加额外长度信息存储。
常见选择:
| 类型 | 适合场景 |
|---|---|
| char | 长度固定的短字段,比如固定编码 |
| varchar | 长度不固定的字段,比如用户名、标题、地址 |
手机号一般也建议用 varchar,不要用数字类型。
因为手机号不是拿来计算的,而且可能涉及前导 0、国际区号等情况。
phone varchar(20)
会比 bigint 更符合语义。
八、datetime 和 timestamp 怎么选?
常见建议:
| 类型 | 特点 |
|---|---|
| datetime | 范围大,不受时区转换影响 |
| timestamp | 范围相对小,会受时区影响 |
在很多 Java 项目中,创建时间和更新时间会这样设计:
sql
create_time datetime not null, update_time datetime not null然后后端用:
LocalDateTime
如果是业务时间,比如订单创建时间、支付时间、发货时间,使用 datetime 会比较直观。
九、为什么字段尽量设置 NOT NULL?
NULL 会让语义和查询逻辑变复杂。
比如:
sql
where age != 18这条 SQL 不会包含 age is null 的记录。
也就是说,NULL 不是等于某个值,也不是不等于某个值,它代表"未知"。
所以能确定默认值的字段,尽量设置 not null default:
sql
status tinyint not null default 1, deleted tinyint not null default 0不过也不要机械化。
如果业务上确实需要表达"未知",那使用 NULL 是可以的。
十、什么是逻辑删除?
逻辑删除不是直接 delete 数据,而是加一个删除标记字段:
deleted tinyint not null default 0
删除时执行:
update user set deleted = 1 where id = 1;
查询时带上:
where deleted = 0
逻辑删除的优点:
| 优点 | 说明 |
|---|---|
| 可恢复 | 删除后仍可以找回 |
| 方便审计 | 能保留历史数据 |
| 降低误删风险 | 不会直接物理删除 |
缺点也很明显:
表会越来越大; 所有查询都要记得带 deleted = 0; 唯一索引设计可能更复杂。
比如手机号唯一,如果用户被逻辑删除后还允许重新注册,就要额外考虑唯一索引怎么设计。
十一、唯一索引有什么用?
唯一索引可以保证字段不重复。
比如手机号注册:
sql
create unique index uk_phone on user(phone);这样即使并发注册,同一个手机号也只能成功插入一次。
很多人会在代码里这样做:
先查手机号是否存在; 不存在再插入。
单线程下没问题,但并发下可能出现:
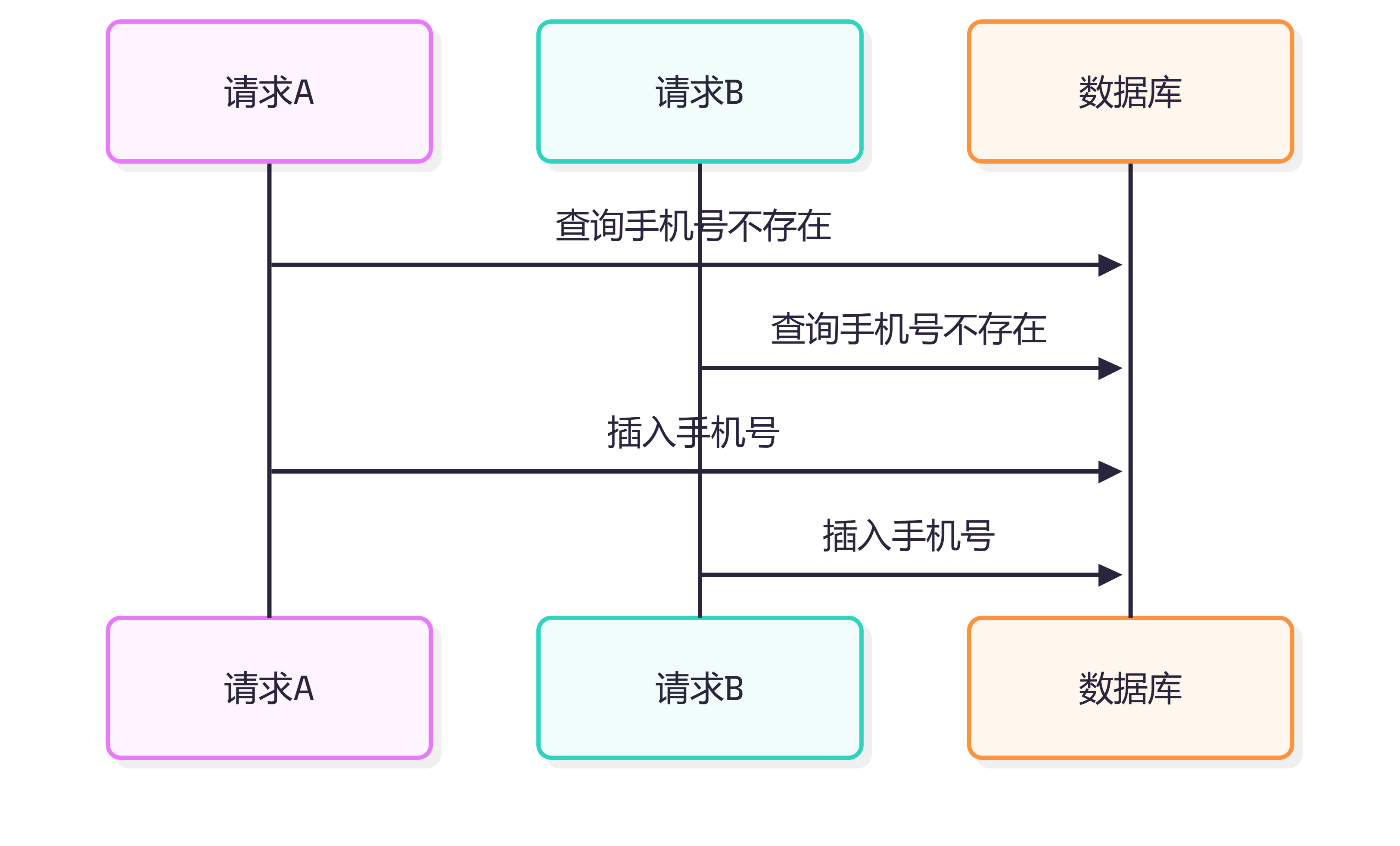
如果没有唯一索引,就可能插入重复数据。
所以业务唯一性不能只靠代码判断,最终要靠数据库唯一索引兜底。
十二、唯一索引和普通索引有什么区别?
普通索引只提高查询效率,不保证数据唯一。
唯一索引既能提高查询效率,也能保证唯一性。
| 对比 | 普通索引 | 唯一索引 |
|---|---|---|
| 是否加速查询 | 是 | 是 |
| 是否保证唯一 | 否 | 是 |
| 适合字段 | 普通查询条件 | 业务天然唯一字段 |
比如:
sql
phone varchar(20)如果业务要求手机号不能重复,就应该建唯一索引,而不是普通索引。
面试可以这样说:
对于业务上天然唯一的字段,比如手机号、订单号、用户名,我会使用唯一索引保证数据一致性。
十三、联合索引字段顺序怎么设计?
联合索引不是随便把字段放在一起就行,字段顺序很关键。
常见原则:
| 原则 | 说明 |
|---|---|
| 等值查询字段放前面 | 更容易连续匹配索引 |
| 区分度高的字段尽量靠前 | 过滤效果更好 |
| 范围查询字段一般放后面 | 避免影响后续字段使用索引 |
| 排序字段结合 order by 设计 | 有机会减少额外排序 |
比如经常查询订单:
where user_id = ? and status = ? order by create_time desc
可以考虑联合索引:
create index idx_user_status_time on order_info(user_id, status, create_time);
这样既能过滤用户和状态,也可能利用索引顺序减少排序成本。
十四、什么是区分度?
区分度就是字段能把数据分散开的能力。
举几个例子:
| 字段 | 区分度 |
|---|---|
| 手机号 | 高,几乎每个人不同 |
| 身份证号 | 高 |
| 性别 | 低,通常只有几种 |
| 状态 | 低,比如 0/1 |
| 是否删除 | 很低 |
区分度低的字段单独建索引,很多时候效果不好。
比如:
where gender = 1
如果一半数据都是 gender = 1,走索引可能还不如全表扫描。
所以建索引时,要看字段是否真的能过滤掉大量数据。
十五、为什么 order by 可能很慢?
如果排序字段没有合适索引,MySQL 可能需要额外排序,也就是执行计划里常见的:
Using filesort
比如:
select * from order_info order by create_time desc;
如果数据量很大,又没有 create_time 索引,排序就会比较慢。
优化思路:
1. 给排序字段建索引 2. 结合 where 条件设计联合索引 3. 避免一次排序大量数据
例如:
create index idx_user_status_time on order_info(user_id, status, create_time);
配合:
where user_id = ? and status = ? order by create_time desc
通常会比全表排序更好。
十六、group by 为什么可能很慢?
group by 需要对数据分组统计,数据量大时成本会比较高。
例如:
select user_id, count(*) from order_info group by user_id;
如果没有合适索引,可能出现:
Using temporary
表示可能使用了临时表。
优化方向:
| 方向 | 说明 |
|---|---|
| 给 group by 字段建索引 | 减少分组成本 |
| 先过滤再分组 | 减少参与分组的数据量 |
| 离线统计 | 报表类任务不要全压在线库 |
| 使用缓存 | 高频统计结果可以缓存 |
订单统计、报表统计、用户行为统计,都经常会遇到这个问题。
十七、limit 深分页为什么慢?
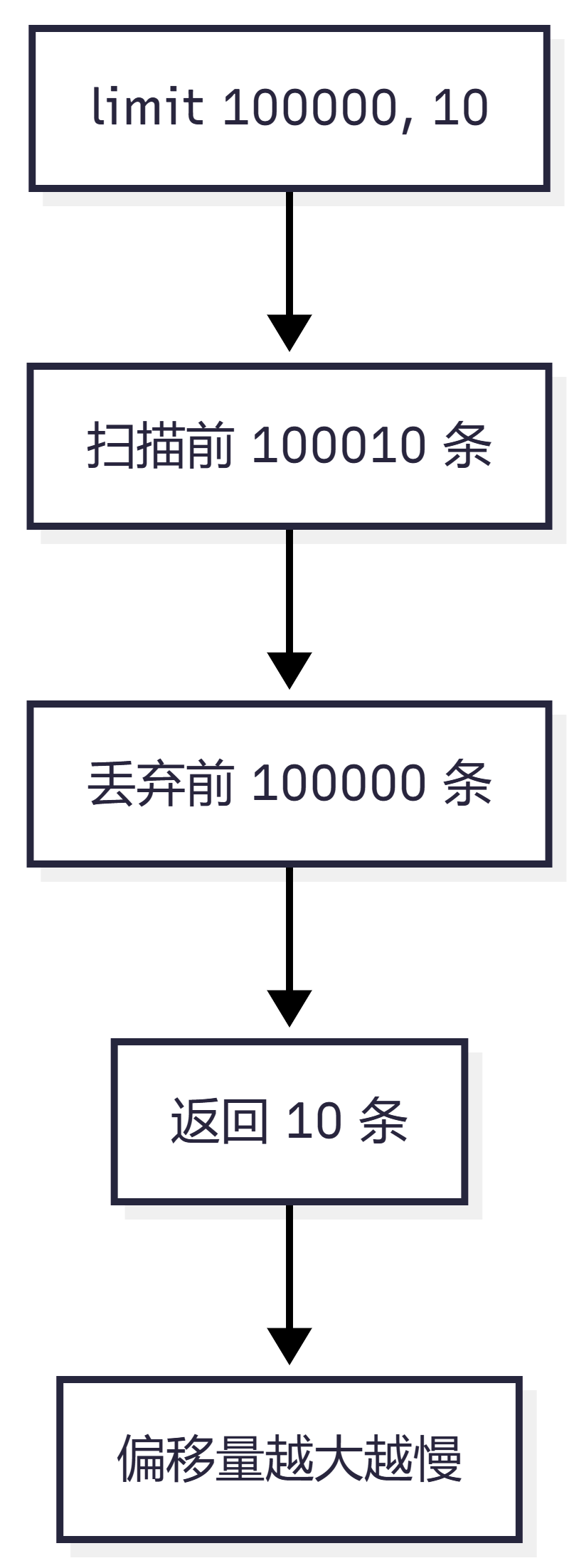
比如这条 SQL:
select * from order_info order by id limit 100000, 10;
MySQL 不是直接跳到第 100000 行返回 10 条。
它通常要先找到前 100010 条记录,然后丢掉前 100000 条,只返回最后 10 条。
可以理解为:
找到 100010 条 丢掉 100000 条 返回 10 条
偏移量越大,扫描和丢弃的数据就越多,所以深分页会越来越慢。
流程图如下:
十八、深分页怎么优化?
常见优化方式有三种。
1. 游标分页
如果按主键递增分页:
sql
select * from order_info where id > 100000 order by id limit 10;这样可以利用主键索引继续往后扫,不需要丢弃大量数据。
如果按时间倒序:
sql
select * from order_info where create_time < ? order by create_time desc limit 10;这种方式适合"下一页"场景。
2. 延迟关联
先用索引查出 id,再回表查完整数据:
sql
select o.* from order_info o
join
( select id from order_info order by id limit 100000, 10 ) t on o.id = t.id;这样可以减少直接查询完整行带来的回表和排序成本。
3. 限制最大页数
很多业务其实不需要无限翻页。
比如搜索结果、订单列表、日志列表,可以限制最多查询前多少页,超过后提示缩小查询条件。
十九、count(*)、count(1)、count(字段) 有什么区别?
常见结论:
| 写法 | 含义 |
|---|---|
| count(*) | 统计行数,包括 NULL |
| count(1) | 统计行数,包括 NULL |
| count(字段) | 统计该字段不为 NULL 的行数 |
例如:
select count(*) from user;
统计的是总行数。
而:
select count(name) from user;
如果 name 有 NULL,这些 NULL 行不会被统计。
在 InnoDB 中,统计总行数通常推荐写:
select count(*) from user;
MySQL 会对它做优化,语义也最清楚。
二十、项目里怎么解释自己的表和索引设计?
面试官很喜欢问:
你这个项目数据库表是怎么设计的?索引怎么建的?
可以按这个模板回答:
我先根据业务实体设计表,比如用户表、订单表、商品表。 每张表都有主键 id、创建时间、更新时间,必要时加逻辑删除字段。 字段类型会尽量选择合适且较小的类型,比如状态用 tinyint,金额用 decimal,手机号用 varchar。 对于高频查询条件建立索引,比如用户手机号、订单 user_id、create_time。 对于业务唯一字段加唯一索引,比如手机号、订单号。 对于组合查询使用联合索引,并考虑最左前缀、字段区分度和排序字段。 同时避免索引过多,因为索引会占空间,也会影响写入性能。
最好结合自己的项目替换表名和查询场景,这样会更自然。
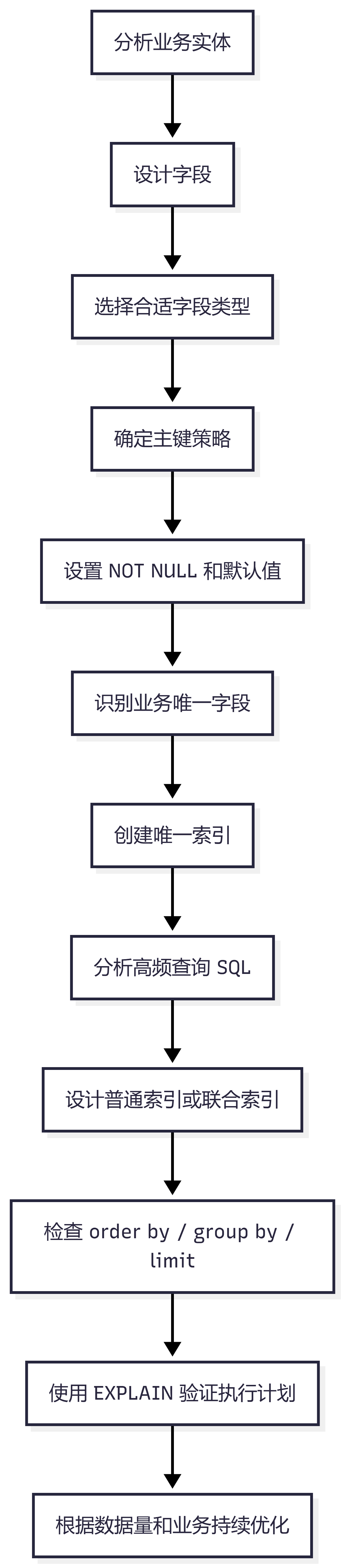
总体流程图:表设计到 SQL 优化
总结
这组知识可以按一条线来记:
表设计先看业务实体; 主键尽量使用自增或趋势递增; 字段类型尽量小且语义清楚; 金额用 decimal,状态用 tinyint,手机号用 varchar; 关键字段尽量设置 NOT NULL 和默认值; 业务唯一字段用唯一索引兜底; 联合索引要结合查询条件设计; order by、group by、limit 都可能成为慢 SQL; 深分页可以用游标分页或延迟关联优化。
MySQL 表设计和 SQL 优化不是互相独立的。
表结构设计得好,SQL 优化会轻松很多;反过来,如果表设计一开始就很随意,后面再补索引、改 SQL,成本往往会越来越高。
所以建表时多想一步,线上排查时就能少熬一晚。
📌 码字不易,技术干货深度复盘!
如果这篇文章帮你看清了 MyBatis-Plus 查询的底层底细,别忘了 点赞、关注、收藏 三连走一波!支持作者不迷路,更多底层源码干货持续输出中!🚀