搜索引擎为什么能"秒搜"?把倒排索引拆给你看
「搜索底层认知」系列第 1 篇。 我在医药电商做搜索,每天跟 ES 的 match query、bool query、function score 打交道。两年来写了上千条 DSL,直到把 Lucene 的倒排索引从磁盘结构到内存缓存完整串了一遍,才觉得自己真的懂了。这一篇把我理解的过程写下来。
一、先死磕一个基础问题
搜"阿莫西林胶囊",你的直觉做法是什么?
java
// 最朴素的思路:正向索引------遍历所有文档
for (Document doc : allDocuments) {
if (doc.contains("阿莫西林") || doc.contains("胶囊")) {
results.add(doc);
}
}时间复杂度 O(N)。 100 万文档就要扫 100 万次。ES 的 match query 响应时间是毫秒级------它不是这么干的。
搜索引擎不扫描文档。它扫描词。
索引阶段,它提前建好了一张巨大的倒排表:
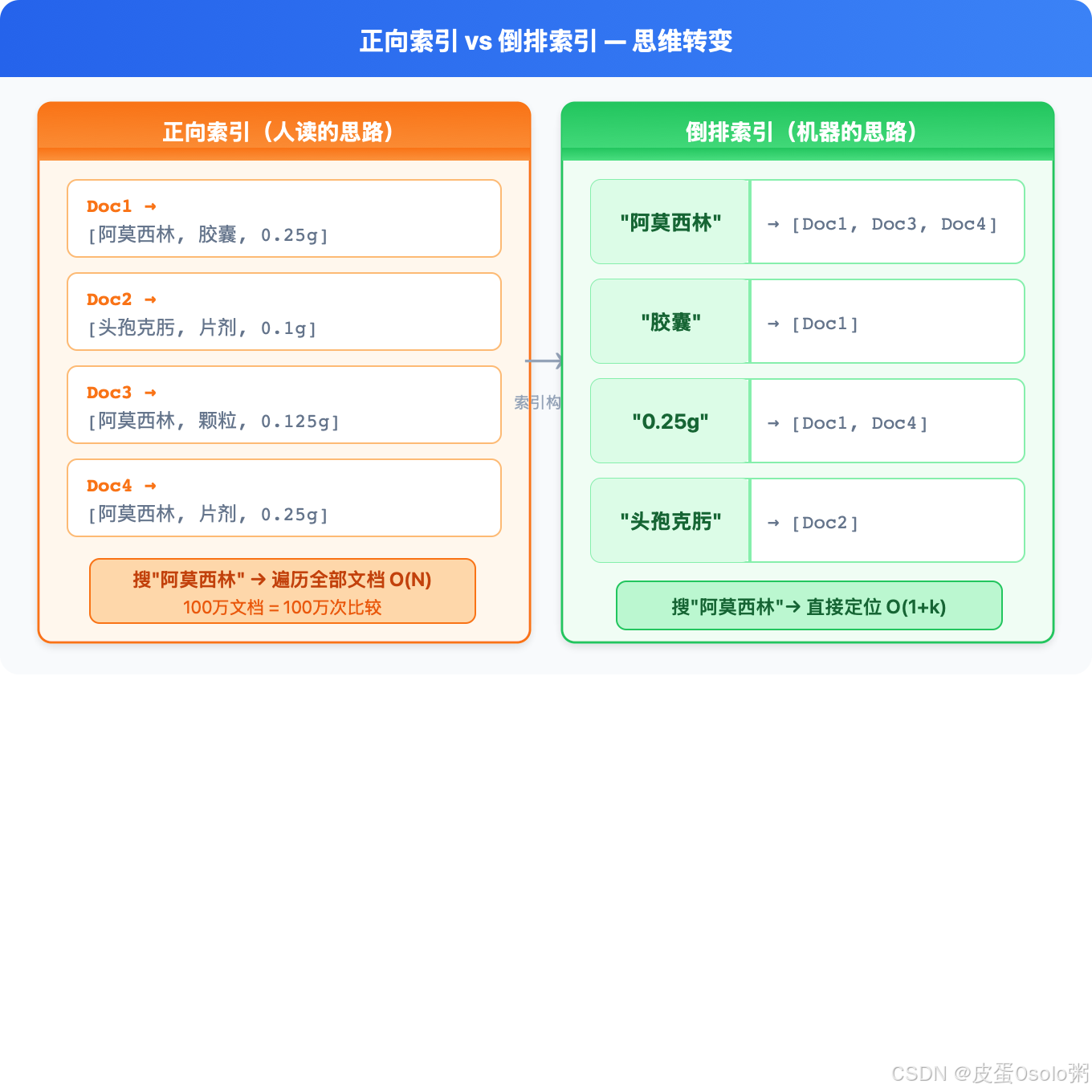
正向索引(人读的思路) 倒排索引(机器的思路)
===================== =====================
Doc1 → [阿莫西林, 胶囊, 0.25g] "阿莫西林" → [Doc1, Doc3, Doc7, Doc12]
Doc2 → [头孢克肟, 片剂, 0.1g] "胶囊" → [Doc1, Doc4, Doc12, Doc18]
Doc3 → [阿莫西林, 颗粒, 0.125g] "头孢克肟" → [Doc2, Doc5]
Doc4 → [阿莫西林, 片剂, 0.25g] "0.25g" → [Doc1, Doc4]搜索"阿莫西林"时,ES 做的事情是:
- 在倒排表里找到
"阿莫西林"这一行 - 直接拿到
[Doc1, Doc3, Doc7, Doc12] - 计算 BM25 分数
- 排序返回
从 O(N) 变成 O(1 + k),k 是命中文档数。 这就是倒排索引的核心价值。
二、倒排索引的骨架:三大组件
Lucene 的倒排索引不是一个 HashMap。它由三个精密配合的结构组成,每个都在解决一个具体的工程问题。
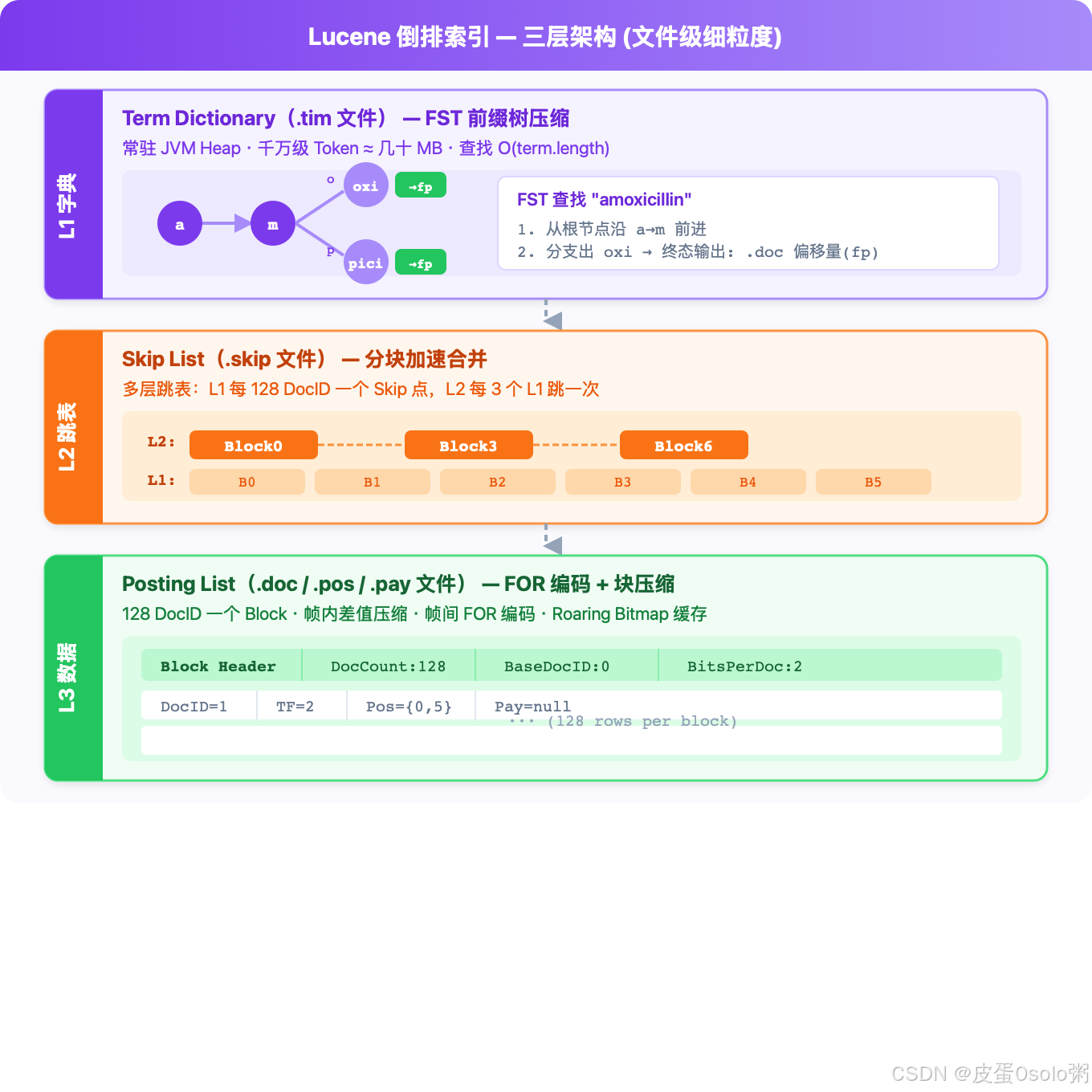
2.1 Term Dictionary & FST
存什么:索引中所有不重复的 Token,每个 Token 指向一个 Posting List 的磁盘位置。
关键约束:Term Dictionary 必须有序。因为查询时要做前缀匹配、fuzzy 查询、范围查询,有序才能二分查找 O(logN)。
根本问题:Term Dictionary 放在哪里?放内存?一个中大型索引可能有上千万个 Token,每个 Token 平均 6 字节,加上指针,内存轻松突破 GB 级。
Lucene 的解法:FST(Finite State Transducer)
FST 本质上是一个最小化的有向无环图,把共享前缀的 Token 压缩成一份。用拼音类比:
Token 列表(有序):
amoxicillin
ampicillin
azithromycin
普通存法: 29 字符
FST 存法: 共享 "a" 和 "m",只存差异部分,压缩率可达 50%~90%Lucene 的 FST 实现(org.apache.lucene.util.fst)更猛:
- 输出类型是
PositiveIntOutputs,存的是 Posting List 的磁盘偏移量 - 查找操作
Util.get(fst, new BytesRef("阿莫西林"))返回一个Long,直接跳转到.doc文件的对应位置 - 内存占用:千万级 Token 通常只需要几十 MB
这意味着什么:ES 把"字典"这个最大的内存负担,用 FST 压缩到了一个可接受的水平。Term Dictionary 常驻堆内存,查表不需要任何磁盘 IO。
2.2 Posting List 与压缩编码
这是倒排索引真正的"肉"------每个 Token 后面跟着的那个 DocID 列表。
Lucene 的 Posting List 不只是 DocID 列表,每个 DocID 条目还包含:
| 字段 | 含义 | 用途 |
|---|---|---|
| DocID | 文档编号 | 定位文档 |
| Term Frequency (TF) | Token 在文档中的出现次数 | BM25 词频计算 |
| Positions | Token 出现的所有位置(偏移量) | 短语查询、高亮 |
| Payloads (可选) | 自定义权重标签 | 特殊打分场景 |
| Offsets (可选) | 起止字符位置 | 高亮定位 |
一个完整的数据帧示例:
Token "阿莫西林" 的 Posting List (.doc 文件):
┌──────────────┬─────┬──────────────────────────┐
│ DocID = 1 │ TF=2│ Positions = {0, 5} │
│ DocID = 3 │ TF=1│ Positions = {0} │
│ DocID = 7 │ TF=1│ Positions = {2} │
│ DocID = 12 │ TF=3│ Positions = {0, 3, 8} │
│ ... │ ... │ ... │
└──────────────┴─────┴──────────────────────────┘压缩是关键。 一个高频词(比如医药场景的"胶囊")可能出现在几十万个文档中。如果 DocID 列表不压缩,一个 Token 的 Posting 就要几 MB。Lucene 用了两种压缩策略:
FOR(Frame of Reference)编码:
原始 DocID: [108, 110, 112, 114, 116]
↓ 做差值
差值列表: [108, 2, 2, 2, 2]
↓ 分块(block),每个块用最小值 + 位压缩
编码结果: 每 128 个 DocID 一个 block,block 内只需要 2 bit/DocIDRoaring Bitmap(ES 5.0+ 的默认 DocValues 编码):
把 DocID 空间切成 65536 一桶:
桶 0 (0 ~ 65535): DocID 列表长 → 用数组,内存紧凑
桶 128 (65536 ~ 131071): DocID 列表短 → 用 bitset,交集运算用位运算两种策略互补:FOR 适合紧凑的顺序存储(.doc 文件),Roaring Bitmap 适合内存中的集合运算(filter 缓存)。
2.3 Skip List & Block 结构
倒排索引不是一个扁平的列表。Lucene 把 Posting List 组织成分块 + 跳表的结构:
.skip 文件结构(L1 跳表 + L2 跳表):
Level 2 (跳表第二层): [Block0] ───────────── [Block3] ───────────── [Block6]
│ │ │
Level 1 (跳表第一层): [Block0] ── [Block1] ── [Block2] ── [Block3] ── [Block4] ── [Block5]
│ │ │ │ │ │
.doc 文件: DocIDs 0-127 128-255 256-383 384-511 512-639 640-767每个 Skip 条目记录三样东西:
- 跳到的 DocID(例如跳到 DocID=384)
- 跳到的
.doc文件偏移量 - 跳到的
.pos文件偏移量(Position 信息在另一个文件里)
为什么要分块?
java
// 搜索 "阿莫西林 胶囊",两个 Posting List 合并
// "阿莫西林" → [1, 3, 7, 12, ..., 100000]
// "胶囊" → [1, 4, 12, ..., 200000]两个列表做交集。普通做法:双指针从头走到尾,O(m+n)。
如果加上 Skip List:发现"胶囊"的当前 Block 最大 DocID < 当前 "阿莫西林" 的 DocID,直接跳整个 Block。在高频低频词混合查询中,跳表能减少 60%~90% 的无效比较。
三、一次 match query,Lucene 内部发生了什么

设用户搜索 "阿莫西林 0.25g",执行的是:
json
{
"query": {
"match": {
"generic_name": {
"query": "阿莫西林 0.25g",
"operator": "and"
}
}
}
}Step 1: Analysis(分词链路)
输入文本: "阿莫西林 0.25g"
↓
Character Filters: 无特殊处理(如果有 HTML,这层会 strip 标签)
↓
Tokenizer: ik_smart
↓
Token Stream: ["阿莫西林_TOKEN", "0.25g_TOKEN"]
↓
Token Filters:
- LowercaseFilter: "阿莫西林_TOKEN" → "阿莫西林_token"(中文无影响)
- StopFilter: 无停用词命中
↓
最终 Token: ["阿莫西林", "0.25g"]最关键的一步就是分词------Token 的粒度直接决定召回。我们真实踩过的坑:
| 分词器 | "阿莫西林胶囊0.25g" 的结果 | 问题 |
|---|---|---|
ik_max_word |
["阿莫西林", "西林", "胶囊", "0.25", "g"] |
"西林"是无意义噪音,召回青霉素类无关药品 |
ik_smart |
["阿莫西林", "胶囊", "0.25g"] |
基本正确,但 "0.25g" 作为一个 Token 限制了召回 |
| 自定义 + 医药词典 | ["阿莫西林", "胶囊", "0.25", "g"] |
最佳------添加"0.25"为单位词典词 |
引申 :为什么我们后来要走 NER 抽取的路?因为像 "0.25g×24胶囊/盒" 这种规格串,分词器不可能完美切割。正确做法是 NER 把规格拆成基准量/包装数/剂型三个字段分别索引,而不是让分词器猜你的业务语义。
Step 2: Term 查找
java
// Lucene 内部的大致逻辑(简化)
for (Term term : queryTerms) {
// FST 查找:O(term.length())
long fp = termsDict.lookup(term.bytes());
// 如果 Term 不存在,直接跳过
if (fp == -1) continue;
// 用返回的偏移量读取 Posting List
PostingsEnum postings = termsEnum.postings(postingsEnum);
// ...
}FST 查找 "阿莫西林" 的过程:
- 从根节点开始,按
BytesRef逐字节走 FST 边 - 走到终态时,FST 返回累积的
output(Long 类型的文件偏移量) - 拿着这个偏移量去
.doc文件 seek
这一步不涉及任何磁盘随机 IO ------FST 在堆内存里,只有一个 .doc 文件的 seek 操作。这也是为什么 ES 需要足够大的 heap:要装得下 FST。
Step 3: Posting List 合并
两个 Token 各有自己的 Posting List。operator: "and" 意味着要取交集:
"阿莫西林" → Posting Enum: DocID 指针 = 1
"0.25g" → Posting Enum: DocID 指针 = 3
合并循环(伪代码):
while (两个 Enum 都读到头) {
if (阿莫西林.docID < 0.25g.docID) {
阿莫西林.nextDoc(); // 也可能是 skipTo(0.25g.docID)
} else if (阿莫西林.docID > 0.25g.docID) {
0.25g.nextDoc();
} else {
命中!加入结果集
两个同时 nextDoc();
}
}Skip List 的加速体现在哪里?
当 "0.25g" 是一个低频词(Posting List 短),而 "阿莫西林" 是高频词(Posting List 长)时:
- 传统双指针:
"阿莫西林"的指针逐个往前挪,大部分都是无效比较 - 加跳表后:
"阿莫西林"的skipTo(0.25g的下一级目标),直接跳过中间的无效区间
Lucene 的 BoolQuery 内部用的就是这种 Scorer + TwoPhaseIterator 的组合------先快速推进 DocID 找到候选集,再回头做精确匹配(位置、Payload),这就是 Two Phase Iterator 名字的由来。
Step 4: BM25 打分
每一个命中的文档,Lucene 会计算 BM25 分数。公式没人会手算,但理解每部分的直觉才是关键:
BM25(D, Q) = Σ IDF(qi) × [ f(qi, D) × (k1 + 1) ] / [ f(qi, D) + k1 × (1 − b + b × |D| / avgdl) ]
参数拆解:
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
IDF(qi) = log((N − n(qi) + 0.5) / (n(qi) + 0.5) + 1)
↑ 稀有词的抓分权重。越稀有→IDF越高
f(qi, D) = Term 在本文档的出现次数
↑ 出现越多→分数越高,但有饱和(k1 控制)
|D| / avgdl = 本文档长度 / 平均文档长度
↑ 短文档相对"浓缩",有加分;长文档有惩罚
k1 (默认1.2) = 词频饱和速度。越大 → 词频增长时分数涨得越快
b (默认0.75) = 长度归一化强度。0 = 不管长度,1 = 完全按比例惩罚
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━手算一组真实感的数,建立直觉:
环境设定:
总文档数 N = 500,000(医药商品库规模)
"阿莫西林" 在 5,000 个文档中出现 → n = 5000
"0.25g" 在 50,000 个文档中出现 → n = 50000
平均文档长度 avgdl = 15 tokens
当前文档:
Doc ID = 12345(阿莫西林胶囊,0.25g×24粒)
文档长度 |D| = 12 tokens
f("阿莫西林") = 2 次
f("0.25g") = 1 次
━━━━ 计算 "阿莫西林" 对本文档的贡献 ━━━━
IDF = log((500000 − 5000 + 0.5) / (5000 + 0.5) + 1)
= log(99.0 + 1) = log(100) ≈ 4.605
分子 = 2 × (1.2 + 1) = 2 × 2.2 = 4.4
分母 = 2 + 1.2 × (1 − 0.75 + 0.75 × 12/15)
= 2 + 1.2 × (0.25 + 0.6)
= 2 + 1.2 × 0.85
= 2 + 1.02 = 3.02
"阿莫西林"贡献 = 4.605 × 4.4 / 3.02 ≈ 6.71
━━━━ 计算 "0.25g" 对本文档的贡献 ━━━━
IDF = log((500000 − 50000 + 0.5) / (50000 + 0.5) + 1)
= log(9.0 + 1) = log(10) ≈ 2.303
分子 = 1 × 2.2 = 2.2
分母 = 1 + 1.2 × 0.85 = 1 + 1.02 = 2.02
"0.25g"贡献 = 2.303 × 2.2 / 2.02 ≈ 2.51
━━━━ 总分数 = 6.71 + 2.51 = 9.22 ━━━━从这几组数能得出三个核心直觉:
-
IDF 差距 2 倍 ≠ 分数差距 2 倍。 "阿莫西林"IDF=4.605,"0.25g"IDF=2.303,但因为 TF 也不同(2 vs 1),最终贡献是 6.71 vs 2.51,差约 2.7 倍。稀有词的实际影响力比 IDF 比值更大。
-
短文档天然吃亏少。 Doc12345 长度为 12,低于平均 15,分母从理论最大值 3.22 降到 3.02,分数略高。b=0.75 是经验值------完全不调(b=0)太激进,完全惩罚(b=1)太激进。
-
TF 不会无限增长。 词频从 1→2 贡献增加约 60%,但从 10→11 贡献增加不到 5%。这就是饱和效应(k1=1.2 时),解释了很多人的困惑:"为什么复制粘贴关键词不能刷排名?"
Step 5: Collector 收集 TopN
BM25 算完分数后,不是全量排序------那太慢了(百万文档)。Lucene 用的是堆排序的 Collector:
java
// PriorityQueue 维护 TopN
// 新文档分数 > 堆顶(当前第 N 名)→ 入堆
// 新文档分数 ≤ 堆顶 → 丢弃
// 复杂度:全量文档 × O(log N) 而不是 O(NlogN)四、回到医药搜索:一个真实 DSL 的逐层解析
我们给医药商品做对码搜索时,典型查询是这样的:
json
GET drug_index/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"generic_name": {
"query": "阿莫西林",
"boost": 3.0
}
}
},
{
"match": {
"specification": {
"query": "0.25g 24粒",
"boost": 2.0
}
}
}
],
"minimum_should_match": 1
}
}
}这条 DSL 执行时,Lucene 内部做的事按顺序拆开:
━━ 子查询1: match generic_name = "阿莫西林" ━━
分词: ["阿莫西林"](ik_smart + 医药词典,不会切出"西林")
FST查表 → Posting List = [D1, D3, D7, D12, ...]
每个 Doc 计算 BM25("阿莫西林") 的原始分
乘 boost 3.0 → finalScore1
━━ 子查询2: match specification = "0.25g 24粒" ━━
分词: ["0.25g", "24", "粒"](注意 "24粒" 被切成两个 Token)
FST查表 → 三个 Posting List 分别查询
取并集(match 默认的 OR 语义)
每个 Doc 计算三个 Token 的 BM25 之和 → finalScore2 × 2.0
━━ Bool 合并 ━━
should + minimum_should_match=1
两个子查询的结果做并集
最终分数 = finalScore1 + finalScore2这里暴露了一个关键问题:specification 字段是字符串全文索引,分词器把 "24粒" 切成了 "24", "粒"。如果另一个商品规格是 "24片",token 是 "24", "片","粒"和"片"不匹配,导致召回丢失。
这就是为什么我们在规格对码场景里走了 NER 抽取的路------把规格串拆成结构化字段:
json
// 索引里的实际 mapping
{
"specification": { "type": "text", "analyzer": "ik_smart" },
"dosage_form": { "type": "keyword" }, // "胶囊" / "片剂" / "颗粒"
"base_amount": { "type": "float" }, // 0.25
"base_unit": { "type": "keyword" }, // "g"
"pack_count": { "type": "integer" }, // 24
"pack_unit": { "type": "keyword" } // "粒" / "片" / "支"
}这样"粒"和"片"走 keyword 精确匹配,不会丢召回。分词器的边界,就是你必须做 NER 的起点。
五、三条实践建议(拿来就能用)
1. 调试召回问题,第一步永远看分词
bash
GET drug_index/_analyze
{
"analyzer": "ik_smart",
"text": "阿莫西林胶囊0.25g×24粒/盒"
}跑完看 token 列表,跟你的预期对一下。80% 的召回问题出在分词,不是 query 写法的问题。
2. 高频词走 filter,别走 must
json
// 不要这样(算分 + 读 Posting List)
{ "must": [{ "term": { "category": "抗生素" } }] }
// 应该这样(走 bitset cache,不算分)
{ "filter": [{ "term": { "category": "抗生素" } }] }"抗生素"这种类别标签,在几十万文档里出现,Posting List 极长。放到 filter 里,ES 会用 Roaring Bitmap 缓存,后续查询直接位运算,零 IO。
3. 用小索引理解 Lucene 内部结构
bash
# 检查索引文件结构------直接看哪些文件最大
ls -lhS /path/to/es/data/nodes/0/indices/drug_index/0/index/
# 典型输出:
# _0.tim 48M ← Term Dictionary (FST + 元数据)
# _0.doc 120M ← Posting List(DocID + TF)
# _0.pos 280M ← Positions(位置信息,phrase query 要用)
# _0.pay 15M ← Payloads有直观感受:如果你的查询不需要 phrase 检索和高亮,position 信息就是纯内存和磁盘开销 。"index_options": "freqs" 可以不存 positions,能省 30%~50% 的索引体积。
下期预告
第一篇建立了倒排索引的物理结构认知。下一篇聊 Analyzer------中文分词器怎么选、ik 分词器内部机制、同义词在索引和查询阶段的不同行为,以及医药领域的分词器定制实战。
「搜索底层认知」系列,我在医药电商做搜索工程师的输出笔记。日常跟 ES、向量检索、Agent 打交道。写这些是为了把散落的知识点串成体系,欢迎讨论。