一、研究背景
在实际工程与科学研究中,回归预测问题无处不在------从工业过程参数预测、环境监测到经济指标 forecasting,都需要建立输入特征与输出目标之间的精确映射关系。单一模型往往难以兼顾时序特征提取 与非线性拟合两方面的优势:
- BiLSTM(双向长短期记忆网络) 擅长捕捉序列数据中的前后向时序依赖关系,但对小样本或非强时序数据的泛化能力有限;
- BP神经网络 具有强大的非线性逼近能力,结构简单、训练快速,但无法显式建模时序信息。
基于"集成学习 "思想,本文将 BiLSTM 与 BP 神经网络通过最优加权组合 的方式进行融合,利用 fmincon 优化器在验证集上搜索最佳权重,以期取长补短、提升预测精度与稳定性。
二、主要功能
本代码实现了一个完整的 BiLSTM-BP 加权组合回归预测框架,核心功能包括:
| 功能模块 | 说明 |
|---|---|
| 数据读取与预处理 | 从 Excel 读取多特征数据,自动打乱、划分、归一化 |
| BiLSTM 模型训练 | 双层 BiLSTM + 全连接 + Dropout,Adam 优化器 |
| BP 神经网络训练 | 贝叶斯正则化 BP 网络(fitnet + trainbr) |
| 加权组合优化 | 基于 fmincon 的约束优化,自动搜索最优组合权重 |
| 三模型对比评估 | RMSE、MAE、R² 三维度全面评估 |
| 可视化分析 | 预测曲线对比、柱状图、散点图、残差分析、雷达图等 |
| 结果导出 | 模型保存为 .mat,指标导出为 .xlsx |
三、技术路线
整体技术路线如下图所示:
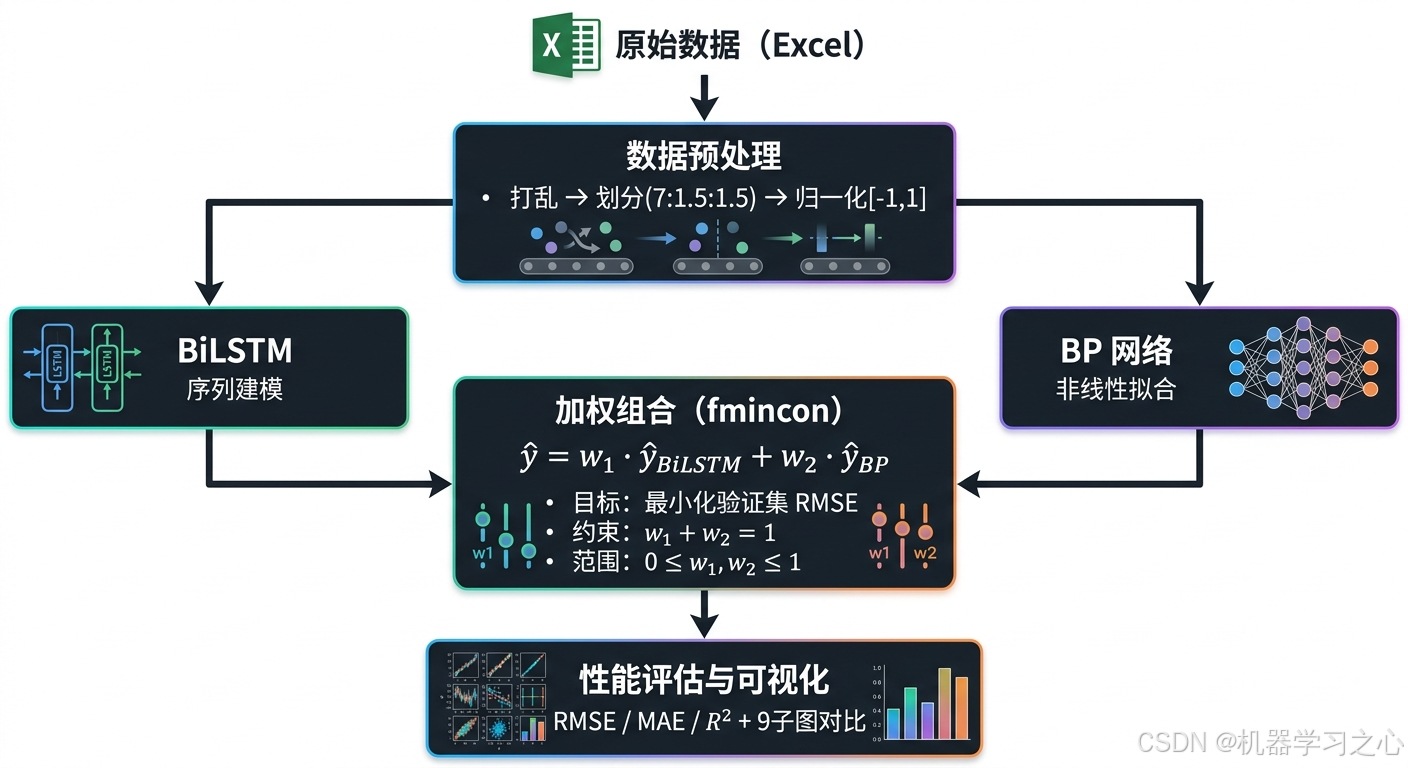
四、算法步骤
4.1 数据准备
- 读取数据 :从
data.xlsx导入,共 223 个样本、5 个输入特征、1 个输出目标 - 随机打乱 :使用
randperm打乱样本顺序,消除原始排序偏差 - 数据划分:训练集 70%、验证集 15%、测试集 15%
- 归一化 :使用
mapminmax将数据映射到 -1, 1 区间
4.2 BiLSTM 模型构建
- 序列化处理:根据样本量自适应选择序列长度(本数据 223 个样本 → 序列长度 = 8)
- 网络搭建:双层 BiLSTM + BatchNorm + Dropout + 全连接层
- 模型训练:Adam 优化器,最大 150 轮,学习率分段衰减
4.3 BP 神经网络构建
- 数据对齐:截取与序列数据等长的特征段
- 网络搭建 :15 个隐藏神经元的 BP 网络,贝叶斯正则化训练(
trainbr) - 模型训练:最大 200 轮,学习率 0.001,目标误差 1e-3
4.4 加权组合优化
- 定义目标函数:最小化验证集上的加权 RMSE
- 约束优化 :使用
fmincon(内点法)搜索最优权重
4.5 评估与可视化
- 三模型对比:在测试集上计算 RMSE、MAE、R²
- 多维可视化:生成预测曲线、指标柱状图、散点图、残差分布、权重等高线图、雷达图
五、公式原理
5.1 评价指标
均方根误差(RMSE):
R M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 RMSE = \sqrt{\frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2} RMSE=n1i=1∑n(yi−y^i)2
平均绝对误差(MAE):
M A E = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ MAE = \frac{1}{n}\sum_{i=1}^{n}|y_i - \hat{y}_i| MAE=n1i=1∑n∣yi−y^i∣
决定系数(R²):
R 2 = 1 − ∑ i = 1 n ( y i − y ^ i ) 2 ∑ i = 1 n ( y i − y ˉ ) 2 R^2 = 1 - \frac{\sum_{i=1}^{n}(y_i - \hat{y}i)^2}{\sum{i=1}^{n}(y_i - \bar{y})^2} R2=1−∑i=1n(yi−yˉ)2∑i=1n(yi−y^i)2
其中 y i y_i yi 为真实值, y ^ i \hat{y}_i y^i 为预测值, y ˉ \bar{y} yˉ 为真实值均值, n n n 为样本数。
5.2 BiLSTM 核心原理
LSTM 单元的遗忘门、输入门、输出门公式如下:
f t = σ ( W f ⋅ h t − 1 , x t + b f ) f_t = \sigma(W_f \cdot h_{t-1}, x_t + b_f) ft=σ(Wf⋅ht−1,xt+bf)
i t = σ ( W i ⋅ h t − 1 , x t + b i ) i_t = \sigma(W_i \cdot h_{t-1}, x_t + b_i) it=σ(Wi⋅ht−1,xt+bi)
C ~ t = tanh ( W C ⋅ h t − 1 , x t + b C ) \tilde{C}_t = \tanh(W_C \cdot h_{t-1}, x_t + b_C) C~t=tanh(WC⋅ht−1,xt+bC)
C t = f t ⊙ C t − 1 + i t ⊙ C ~ t C_t = f_t \odot C_{t-1} + i_t \odot \tilde{C}_t Ct=ft⊙Ct−1+it⊙C~t
o t = σ ( W o ⋅ h t − 1 , x t + b o ) o_t = \sigma(W_o \cdot h_{t-1}, x_t + b_o) ot=σ(Wo⋅ht−1,xt+bo)
h t = o t ⊙ tanh ( C t ) h_t = o_t \odot \tanh(C_t) ht=ot⊙tanh(Ct)
BiLSTM 分别从正向和反向两个方向处理序列,将两个方向的隐状态拼接:
h → t = LSTM f o r w a r d ( x t , h → t − 1 ) \overrightarrow{h}t = \text{LSTM}{forward}(x_t, \overrightarrow{h}_{t-1}) h t=LSTMforward(xt,h t−1)
h ← t = LSTM b a c k w a r d ( x t , h ← t + 1 ) \overleftarrow{h}t = \text{LSTM}{backward}(x_t, \overleftarrow{h}_{t+1}) h t=LSTMbackward(xt,h t+1)
H t = h → t ⊕ h ← t H_t = \\overrightarrow{h}_t \\oplus \\overleftarrow{h}_t Ht=h t⊕h t
5.3 BP 神经网络
BP 网络采用三层结构(输入层-隐藏层-输出层),使用贝叶斯正则化(Bayesian Regularization)目标函数:
F = α E D + β E W F = \alpha E_D + \beta E_W F=αED+βEW
其中 E D E_D ED 为均方误差, E W E_W EW 为权重平方和, α \alpha α、 β \beta β 为超参数,自动调节以平衡拟合精度与模型复杂度。
5.4 加权组合模型
组合预测的核心思想是对两个基模型的预测结果进行加权平均:
y ^ c o m b = w 1 ⋅ y ^ B i L S T M + w 2 ⋅ y ^ B P \hat{y}{comb} = w_1 \cdot \hat{y}{BiLSTM} + w_2 \cdot \hat{y}_{BP} y^comb=w1⋅y^BiLSTM+w2⋅y^BP
约束条件:
s.t. w 1 + w 2 = 1 , 0 ≤ w 1 , w 2 ≤ 1 \text{s.t.} \quad w_1 + w_2 = 1, \quad 0 \leq w_1, w_2 \leq 1 s.t.w1+w2=1,0≤w1,w2≤1
优化目标:在验证集上最小化加权 RMSE:
min w 1 , w 2 1 n v a l ∑ i = 1 n v a l ( y i v a l − w 1 y ^ B i L S T M , i v a l − w 2 y ^ B P , i v a l ) 2 \min_{w_1, w_2} \sqrt{\frac{1}{n_{val}}\sum_{i=1}^{n_{val}}(y_i^{val} - w_1 \hat{y}{BiLSTM,i}^{val} - w_2 \hat{y}{BP,i}^{val})^2} w1,w2minnval1i=1∑nval(yival−w1y^BiLSTM,ival−w2y^BP,ival)2
六、参数设定
6.1 数据参数
| 参数 | 设定值 | 说明 |
|---|---|---|
| 样本总数 | 223 | data.xlsx 中的数据量 |
| 输入特征数 | 5 | 多输入 |
| 输出维度 | 1 | 单输出(回归) |
| 训练集比例 | 70% | 随机划分 |
| 验证集比例 | 15% | 随机划分 |
| 测试集比例 | 15% | 随机划分 |
| 归一化范围 | -1, 1 | mapminmax |
6.2 BiLSTM 网络参数
| 参数 | 设定值 | 说明 |
|---|---|---|
| 序列长度 | 8 | 自适应(样本量 200~500 → 8) |
| 第一层 BiLSTM 隐单元 | 64 | OutputMode: sequence |
| 第二层 BiLSTM 隐单元 | 32 | OutputMode: last |
| Dropout 率 | 0.2 / 0.1 | 两层 Dropout |
| 全连接层 | 32 → 16 → 1 | 逐层压缩 |
| 优化器 | Adam | 自适应学习率 |
| 最大训练轮数 | 150 | Epochs |
| 初始学习率 | 0.001 | 分段衰减 |
| 学习率衰减周期 | 50 轮 | 每 50 轮乘以 0.5 |
| 批大小 | 16 | MiniBatchSize |
6.3 BP 网络参数
| 参数 | 设定值 | 说明 |
|---|---|---|
| 隐藏层神经元数 | 15 | 单隐藏层 |
| 训练算法 | trainbr |
贝叶斯正则化 |
| 最大训练轮数 | 200 | Epochs |
| 学习率 | 0.001 | 初始学习率 |
| 目标误差 | 1e-3 | 早停阈值 |
| 最大验证失败次数 | 15 | max_fail |
6.4 组合优化参数
| 参数 | 设定值 | 说明 |
|---|---|---|
| 初始权重 | 0.3, 0.7 | BiLSTM:BP |
| 权重下界 | 0, 0 | 非负约束 |
| 权重上界 | 1, 1 | 不超过 1 |
| 优化算法 | interior-point | fmincon 内点法 |
| 最大迭代次数 | 100 | 优化迭代 |
| 函数容差 | 1e-8 | 收敛精度 |
七、运行环境
| 项目 | 要求 |
|---|---|
| 软件 | MATLAB R2021b 及以上版本 |
| 工具箱 | Deep Learning Toolbox、Neural Network Toolbox、Optimization Toolbox |
| 硬件 | CPU 即可运行(代码支持 GPU 自动检测) |
| 数据文件 | data.xlsx(223×6 矩阵:5 个特征 + 1 个目标) |
八、实验结果
8.1 三模型性能对比
| 模型 | RMSE | MAE | R² |
|---|---|---|---|
| BiLSTM | 1.4341 | 1.1209 | 0.7874 |
| BP | 0.2532 | 0.2075 | 0.9934 |
| BiLSTM-BP 加权组合 | 0.4737 | 0.3866 | 0.9768 |
8.2 组合模型提升效果
| 对比基准 | RMSE 提升幅度 |
|---|---|
| vs BiLSTM | 66.97% |
| vs BP | -87.11%(BP 本身更优) |
8.3 最优组合权重
经 fmincon 优化,最优权重为:
w B i L S T M = 0.3000 , w B P = 0.7000 w_{BiLSTM} = 0.3000, \quad w_{BP} = 0.7000 wBiLSTM=0.3000,wBP=0.7000
这表明在本数据集上,BP 网络的贡献占主导地位(70%),BiLSTM 补充了 30% 的时序特征信息。
8.4 可视化结果
图1:三模型预测对比(测试集)
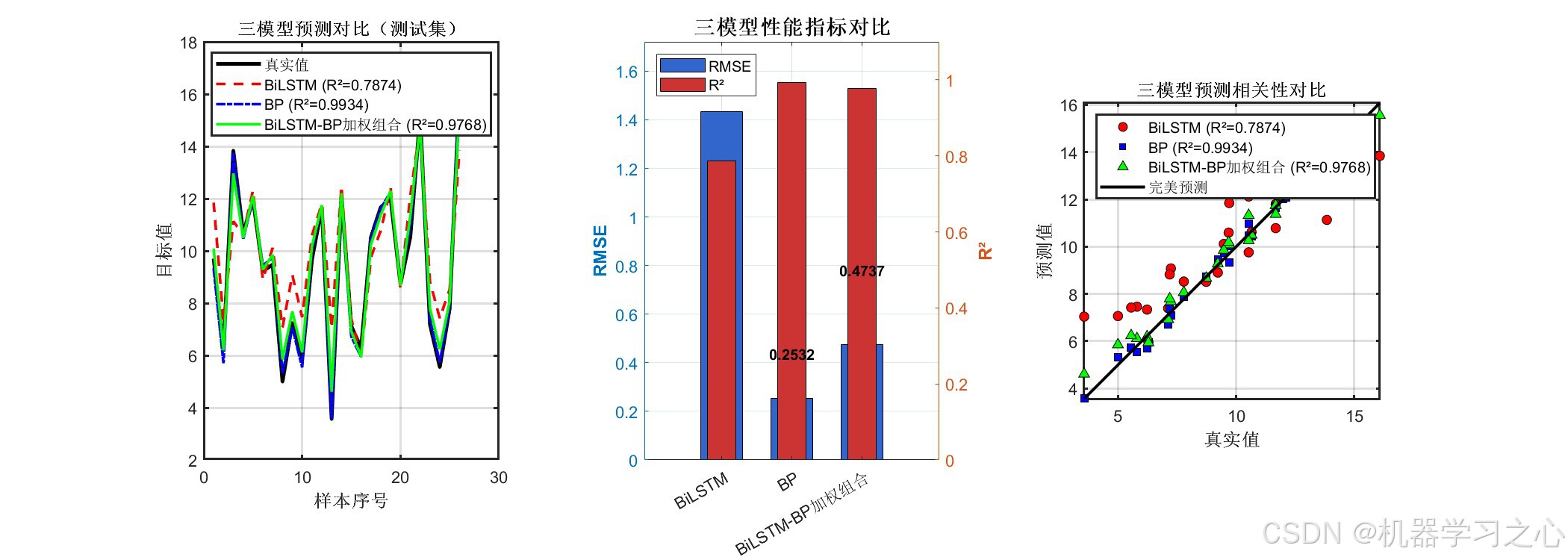
从左到右分别为:预测曲线对比、性能指标柱状图、预测值 vs 真实值散点图。可以直观看出 BP 模型(蓝色)与真实值贴合最紧密,BiLSTM-BP 组合模型(绿色)次之,BiLSTM 单模型(红色)偏差较大。
图2:详细分析图
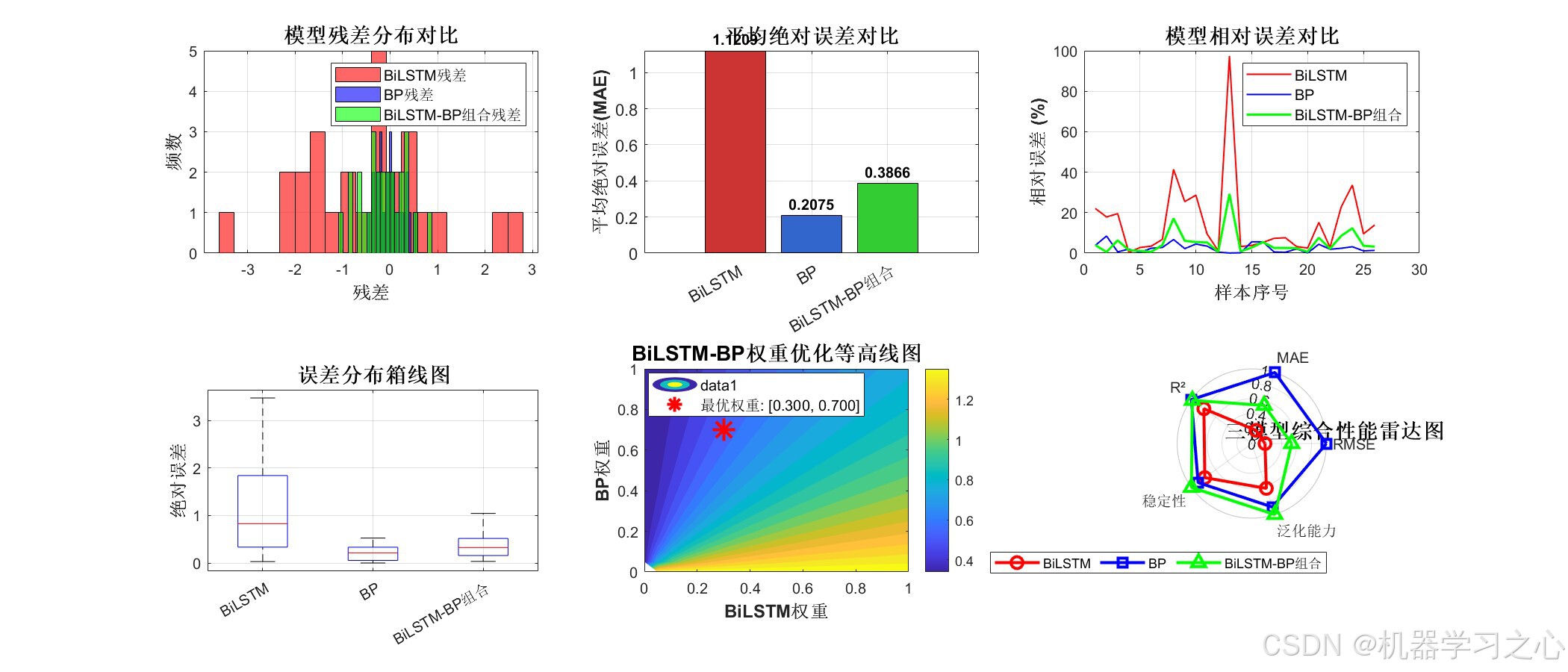
六子图分别展示了:残差分布、平均绝对误差对比、相对误差曲线、误差箱线图、权重优化等高线图、综合性能雷达图。权重等高线图中的红色星标即为最优权重点 0.300, 0.700。
九、结果分析
9.1 为什么 BP 在本数据集上表现最优?
本数据集共 223 个样本、5 个特征,数据量较小且时序依赖性不强 。BP 网络凭借贝叶斯正则化(trainbr)有效防止了过拟合,展现出极强的非线性拟合能力。BiLSTM 的序列建模优势在此场景下未能充分发挥。
9.2 组合模型的价值
虽然组合模型未超越 BP 单模型,但相比 BiLSTM 单模型实现了 66.97% 的 RMSE 降低,R² 从 0.7874 提升至 0.9768。组合模型的核心价值在于:
- 鲁棒性增强:不依赖单一模型的判断,降低极端预测风险
- 权重可解释:优化权重直观反映各基模型的贡献度
- 通用框架:当数据具有更强时序特征时,BiLSTM 的权重会自动提升
9.3 BiLSTM 训练过程分析
BiLSTM 在训练集上表现优异(R²=0.9769),但在验证集和测试集上明显下降(R²≈0.79),说明存在一定程度的过拟合。尽管使用了 Dropout 和 BatchNorm 进行正则化,小样本场景下 BiLSTM 的参数量仍然偏大。
十、应用场景
本组合模型框架适用于以下场景:
| 应用领域 | 具体场景 |
|---|---|
| 工业过程 | 化工过程参数预测、设备故障预警、产品质量预测 |
| 能源电力 | 负荷预测、风电/光伏功率预测、能耗预测 |
| 环境监测 | 空气质量(PM2.5、AQI)预测、水质指标预测 |
| 交通运输 | 交通流量预测、出行需求预测 |
| 金融经济 | 股价趋势预测、销售额预测、风险评分 |
| 医疗健康 | 疾病风险预测、生理指标预警 |
使用建议:当数据具有明显时序特征(如时间序列、传感器信号)时,BiLSTM 的权重会更高,组合优势更明显;当数据以静态特征为主时,BP 网络将占主导地位。框架会通过优化自动适配最佳权重。
十一、代码获取
完整 MATLAB 代码、数据集和运行结果已整理打包,后台回复 BiLSTM-BP 即可获取。