
◆ 博主名称: 小此方-CSDN博客 大家好,欢迎来到小此方的博客。
⭐️Linux系列个人专栏: 【主题曲】Linux
⭐️此方的GitHub: github_此方
⭐️ Re系列专栏:我们思考 (Rethink) · 我们重建 (Rebuild) · 我们记录 (Record)
文章目录
- 概要&序論
- [一、 进程创建](#一、 进程创建)
-
- [1.1 fork 函数初识](#1.1 fork 函数初识)
-
- [1.1.1 fork 之后的执行流表现](#1.1.1 fork 之后的执行流表现)
- [1.3 写时拷贝](#1.3 写时拷贝)
-
- [1.3.1 写时拷贝是如何实现的](#1.3.1 写时拷贝是如何实现的)
- [1.3.2 为什么操作系统会发生写时拷贝?](#1.3.2 为什么操作系统会发生写时拷贝?)
- [1.3.3 为什么操作系统能够分辨出谁是数据段?](#1.3.3 为什么操作系统能够分辨出谁是数据段?)
- [1.3.4 查询页表的几种情况](#1.3.4 查询页表的几种情况)
- [1.3.5 为什么要写时拷贝?](#1.3.5 为什么要写时拷贝?)
- [1.3.6 读写权限的恢复注意事项](#1.3.6 读写权限的恢复注意事项)
- [1.4 fork 常见用法](#1.4 fork 常见用法)
- [1.5 fork 调用失败的原因](#1.5 fork 调用失败的原因)
- [二、 进程退出](#二、 进程退出)
-
- [2.1 进程退出场景](#2.1 进程退出场景)
- [2.2 进程常见退出方法与核心机制](#2.2 进程常见退出方法与核心机制)
-
- [2.2.1 return 机制与返回值编码原理](#2.2.1 return 机制与返回值编码原理)
- [2.2.2 exit 与 _exit 的底层区别](#2.2.2 exit 与 _exit 的底层区别)
- [2.2.3 深度解剖:我们谈论的缓冲区](#2.2.3 深度解剖:我们谈论的缓冲区)
- [2.3 退出码的回收与访问](#2.3 退出码的回收与访问)
概要&序論
Hello大家好,我是此方,本篇博客的核心技术要点如下:
- 进程创建 : fork 函数的使用与双返回值机制;写时拷贝 (COW)的内存优化原理;fork 的常规用法及调用失败的根本原因。
- 进程终止 : 正常退出与异常崩溃 等三种退出场景;return、exit 与 _exit 等退出方法的调用区别与底层资源回收机制。
一、 进程创建
1.1 fork 函数初识
在 Linux 中 fork 是非常重要的函数,它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程。
c
#include <unistd.h>
pid_t fork(void);
// 返回值:子进程中返回 0,父进程中返回子进程 id,出错返回 -1。 进程调用 fork 后,内核会执行以下操作:
- 分配新的内存块和内核数据结构(如 PCB/
task_struct)给子进程。 - 将父进程内核数据结构内容拷贝至子进程。
- 添加子进程到系统进程列表当中。
fork返回,开始由调度器进行调度。
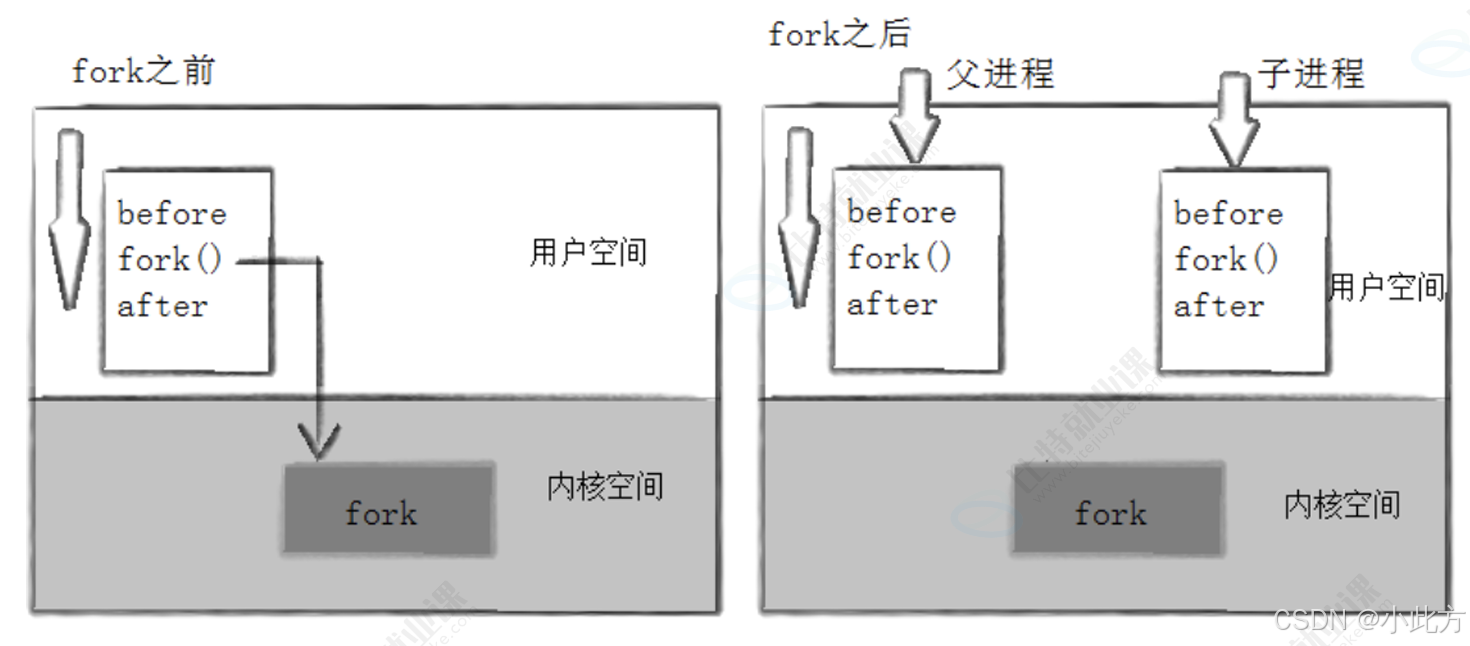
1.1.1 fork 之后的执行流表现
代码和结论参考前面的文章 :Re:Linux系统篇(十七)进程篇·二:深入浅出 进程概念与进程父子关系:从底层原理到实战应用
1.3 写时拷贝
通常情况下,父子进程的代码共享;在没有对数据进行写入时,数据也是共享的。当任意一方试图对共享数据进行修改(写入)时,操作系统便会以写时拷贝 的方式各自配置一份副本。
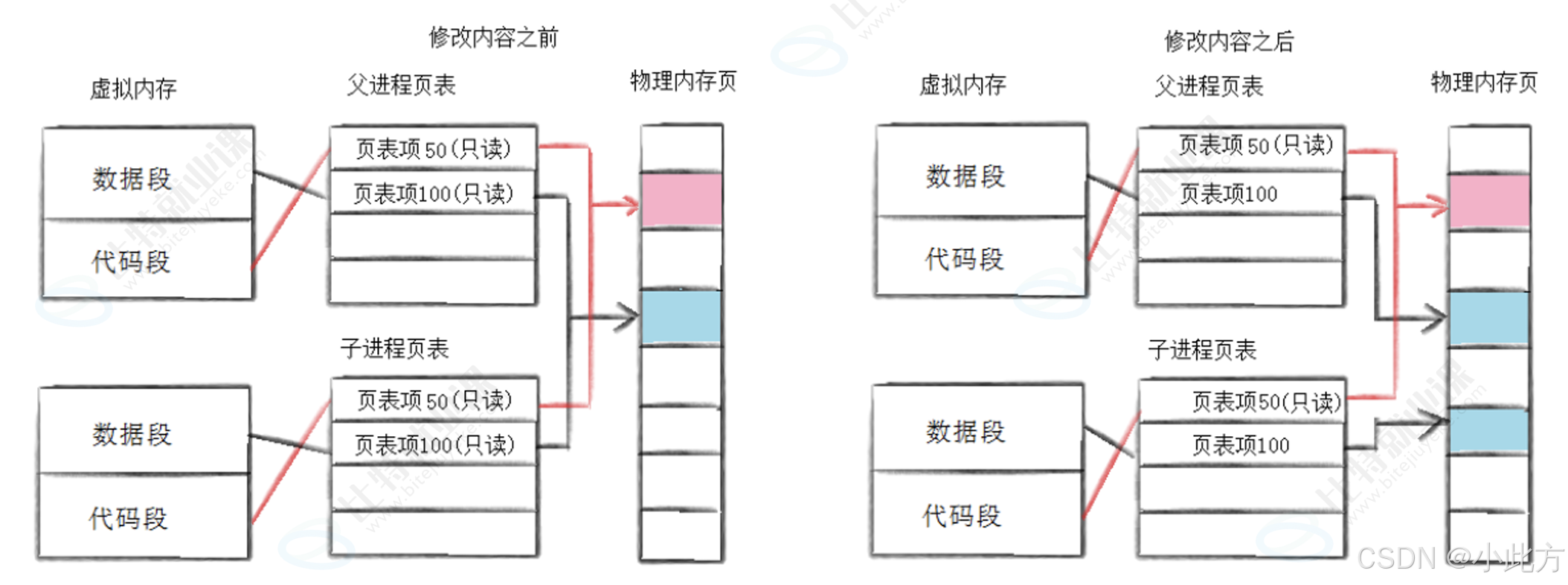
1.3.1 写时拷贝是如何实现的
- 初始只读设置 :子进程被创建以后,物理内存在父子间共享。父子页表中的数据段 和代码段 都会被操作系统故意设置成只读 权,(父进程的数据段页表项也同样被同步设置成只读。)
- 触发"报错" :当用户程序尝试去访问并修改这些只读的数据段时(即发生写操作),由于硬件权限拦截,会发生报错(不是真的报错)。
- 识别并触发写时拷贝 :此处的报错并不是真正的程序非法报错。操作系统接收到报错后,会引发缺页中断。
父子进程通过写时拷贝实现互不干扰互相独立,但是如果一个进程运行起来它的代码是一个操作系统,这就是内核级别的虚拟机的原理。 每一个虚拟机之间互不干扰。
1.3.2 为什么操作系统会发生写时拷贝?
因为这是操作系统对堆数据段等虚拟内存区域设定的特殊控制机制。
1.3.3 为什么操作系统能够分辨出谁是数据段?
答案是:vm_area_struct 。内核通过检查进程的 vm_area_struct 结构体,可以得知该区域原本是否具备读写权限,从而精确分辨出这是写时拷贝引起的异常,而不是非法的内存越界。
1.3.4 查询页表的几种情况
- 正常查询:正常进行权限检查与地址转换。
- 查不到 / 报错:权限不匹配或页表项不存在。
- 缺页中断:由此触发物理内存申请、物理页拷贝以及页表重映射。
1.3.5 为什么要写时拷贝?
- 加速子进程的创建速度:避免了在创建初期盲目拷贝大量物理内存造成的耗时。
- 减少内存中的冗余代码与数据:只有在需要修改时才分配新内存,极大地节省了物理内存空间。
依靠写时拷贝技术,父子进程在物理层面上做到了充分隔离,完成了进程独立性的技术保证,同时极大地减少了对物理内存的使用率。
1.3.6 读写权限的恢复注意事项
- 子进程 :在发生写时拷贝、被映射到全新物理页之后,子进程的该页表项权限立即恢复为读写。
- 父进程 :完成写时拷贝后,父进程原有的数据段并不会马上变回读写。只有当所有的子进程全部发生了写时拷贝(彻底脱离共享物理页)之后,父进程的代码/数据段才会恢复读写。
1.4 fork 常见用法
- 一个父进程希望复制自己,使父子进程同时执行不同的代码段。例如:父进程作为服务器常驻并等待客户端请求,当请求到来时,生成子进程来处理该请求,父进程则继续等待。
- 一个进程要执行一个完全不同的程序。例如:子进程从
fork返回后,立即调用exec族函数,加载并替换掉当前的进程空间。
1.5 fork 调用失败的原因
- 系统中有太多的进程(超出了系统允许的进程最大上限)。
- 实际用户的进程数超过了给该用户分配的限制。
当内存空间不够时,直接导致:
- 进程 PCB(
task_struct)创建失败。- 无法成功加载代码与数据。
二、 进程退出
上文我们介绍了进程创建,现在我们来聊一聊进程退出。
2.1 进程退出场景
2.1.1进程退出三种场景
当一个子进程被父进程创建出来并执行完毕,或者在中途由于外力终止时,子进程执行的结果究竟如何?
main函数返回值和程序执行情况挂钩 ,就是进程退出时的退出码。
- 代码运行完毕,结果正确
- 代码运行完毕,结果不正确 :程序虽然安全地运行到了结束,没有发生崩溃,但运行结果未达到预期。此时通常表现为
main函数返回了一个非 0 值 (如1, 2, 3...)。不同的值,表明不同的出错原因,这些数值在系统层面上被称为进程退出码。 - 代码异常终止 :程序在运行过程中触发了底层的致命错误(例如野指针越界访问、除以 0 等)。此时,进程一旦出现异常,一般是进程收到了信号 被操作系统强制杀死。在这种场景下,进程的代码根本没有执行完,其退出码已经毫无意义。
返回返回给谁? 子进程返回给父进程,main函数返回给调用main函数的函数。
2.1.2退出码有哪些
| 退出码 | 解释 |
|---|---|
| 0 | 命令成功执行 |
| 1 | 通用错误代码 |
| 2 | 命令(或参数)使用不当 |
| 126 | 权限被拒绝(或)无法执行 |
| 127 | 未找到命令,或 PATH 错误 |
| 128+n | 命令被信号从外部终止,或遇到致命错误 |
| 130 | 通过 Ctrl+C 或 SIGINT 终止(终止代码 2 或键盘中断) |
| 143 | 通过 SIGTERM 终止(默认终止) |
| 255/* | 退出码超过了 0-255 的范围,因此重新计算(LCTT 译注:超过 255 后,用退出码对 256 取模) |
- 退出码 0 表示命令执行无误,这是完成命令的理想状态。
- 退出码 1 我们也可以将其解释为"不被允许的操作"。例如在没有 sudo 权限的情况下使用 yum;再例如除以 0 等操作也会返回错误码 1,对应的命令为 let a=1/0
- 130( SIGINT 或 ^C )和 143( SIGTERM )等终止信号是非常典型的,它们属于 128+n 信号,其中 n 代表终止码。
2.2 进程常见退出方法与核心机制
控制进程退出主要有三种手段:在 main 函数中调用 return、在任意位置调用 C 标准库的 exit()、或者调用 Linux 的系统调用 _exit()。
还有一种,异常退出 :ctrl+c或者是kill -9 进程pid都可以触发。
2.2.1 return 机制与返回值编码原理
在语言层面上,main 函数的返回值通常表明了你整套程序的执行情况。但你是否思考过 ,这个返回值是如何从一个函数(或进程)传递给另一个函数(或父进程)的?
我们可以通过函数调用的汇编编码 原理来窥探其底层的流转过程:函数调用到返回值接收一共三步:
- func1()调用func2(),func1 call func2调用。
- func2 将返回值ret 1交给寄存器mov eax 1; ret
- func1接收func2的返回值(寄存器内部值返回给func1内部变量)mov 0x11223344\[\] eax
补充要点:关于默认返回值
函数返回值在语言层面有时可以不写。例如定义了
int func()但内部没有写return语句,一些编译器在编译时会给出警告。由于在底层的汇编链路上缺少了显式写入寄存器的指令(上面的第二步) ,程序在执行mov转移时,就会将eax寄存器的 默认值 0** 进行转移**,func1那边的变量受到默认值,从而导致默认返回 0。main函数同样遵循这一底层机制。C语言里面默认一个函数的返回值是int,所以以int为返回值类型的函数实际上不写返回值也可以。
2.2.2 exit 与 _exit 的底层区别
除了 main 函数结束表示进程结束之外,在代码的任何地方调用 exit 或 _exit,都表示进程直接结束 ,并将状态码返回给父进程。(他们两个的参数等价于退出码)
cpp
int main(){
exit(200);//退出码就是200
return 0;
} 然而,作为 C 库函数的 exit(status) 与作为系统调用的 _exit(status) 在对待缓冲区的处理上有着天壤之别:
用户进程调用 exit() ────> 刷新库缓冲区(如\n等) ────> 调用内核 _exit() ────> 进程彻底终止
用户进程调用 _exit() ───────────────────────────────> 调用内核 _exit() ────> 进程彻底终止(数据丢失)- 进程如果通过
exit()退出 :进程退出的时候,会进行缓冲区的刷新,确保所有滞留在内存中的标准输出数据被安全推送到显示器或文件中。 - 进程如果通过
_exit()退出 :进程退出的时候,不会进行缓冲区的刷新,尚未冲刷的数据将直接丢失。
cpp
int main(){
printf("hello");
exit(0);
}
//运⾏结果:
//[root@localhost linux]# ./a.out
//hello[root@localhost linux]#
int main(){
printf("hello");
_exit(0);
}
//运⾏结果:
//[root@localhost linux]# ./a.out
//[root@localhost linux]#所以exit内部进程了这些操作:
- 执行用户通过 atexit或on_exit定义的清理函数。
- 关闭所有打开的流,所有的缓存数据均被写入
- 调用_exit
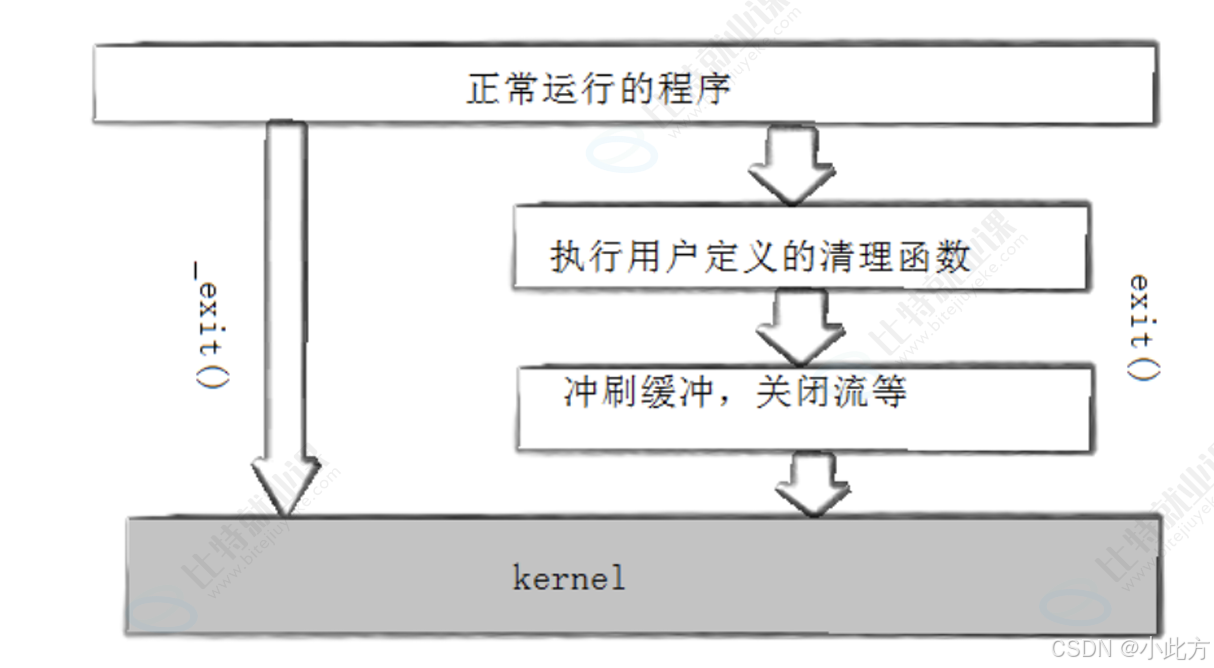
2.2.3 深度解剖:我们谈论的缓冲区
基于 exit() 和 _exit() 的行为差异,我们可以得出一个极其重要的结论:
这个设计证明了:我们之前谈论的输出缓冲区,一定不是操作系统内部的缓冲区!!
如果这个缓冲区是建立在操作系统内核内部的,那么无论是通过库函数 exit() 退出,还是通过系统调用 _exit() 退出,操作系统必然会统一刷新内核缓冲区。
事实真相 :实际情况是 _exit() 作为系统调用,根本不理会这个缓冲区。这说明 exit() 内部其实是封装了 _exit(),同时在调用 _exit() 之前,额外封装了刷新缓冲区的代码。
那么那个缓冲区究竟在哪里?我现在还不能讲,等我们讲文件IO的时候再仔细讲。
2.3 退出码的回收与访问
2.3.1子进程退出码获取
当进程通过上述某种方式退出,并传递了 status 退出状态后:
- 写入内核对象 :子进程的退出码会被写到你的进程的
task_struct内部!在内核的进程控制块中,有一个专门的退出变量用于接收并保存该数值。 - 父进程回收 :子进程在退出后会进入僵尸状态(Zombie),直到其被父进程回收获得该变量。
2.3.2退出码的访问
日常开发中,父进程通常是 Bash。当我们运行程序 ./proc 后,它作为 Bash 的子进程运行。如果想要查看它最后的执行结果,可以:
bash
[whb@bite-alicloud lesson16]$ ./proc
[whb@bite-alicloud lesson16]$ echo $?
1 其中,$? 是 Shell 中的一个特殊变量,专门存储上一个前台进程退出时的状态码。 子进程的父进程是bash,自然可以被拿到。
特殊的: 虽然status是int,但是仅有低8位可以被父进程所用。所以_exit(-1)时,在终端执行$?发现返回值是255。什么低八位什么的我们在进程等待的时候讲,你现在知道有这么种情况就好了。
errno 是 C 标准库提供的一个全局变量(定义在 <errno.h> 中),你把它当成错误码就行。
cpp
int Func02()
{
FILE* fp =fopen("log.txt","r");
if(fp==NULL) return errno;
fclose(fp);
return 0;
}2.3.3退出码可以转化为错误信息
cpp
#include <string.h>
char *strerror(int errnum); //将错误码转化为错误码描述我们打印看看有多少种错误码对应的错误信息。
cpp
#include<cstdio>
#include <string.h>
using namespace std;
void Func01(){
for(int i = 0;i<133;i++)
printf("%d->%s\n",i,strerror(i));}
int main(){
Func01();
return 0;
}好的本期内容就到这里,如果对你有帮助,还不要忘记点赞三联支持。我是此方,我们下期再见。bye!