Mamba 会替代 Transformer 成为 AI 的下一代底层模型吗?
一、为什么 AI 选择了 Transformer?
2017 年之前,AI 处理序列的方式不是那么聪明------RNN 和 LSTM这两种神经网络,必须要一个字一个字读取,对于全文的意思理解不够。
然后,Google 发了篇论文叫《Attention is All You Need》,AI的起源。
核心就一句话:不要一个字一个字读了,可以同时看到其他所有的字。
这一个改动,训练速度快了 100 倍,效果还更好。
于是所有人都来了。ChatGPT、Opus、DeepSeek、Sora------全部基于 Transformer。它统一了语言、视觉、语音、视频,成了 AI 的"标准答案"。
二、Transformer 的缺点
大家都了解,计算复杂度是Transfer最大的软肋。Transformer 的注意力机制是 O(n²) 复杂度------序列长度翻倍,计算量翻四倍。
实际后果:
- 处理一本 10 万字小说?必须截断读取
- 4K 图像展平后序列超长,显存直接爆炸
- 视频理解?想都别想,计算成本高得离谱
大模型越来越"能聊",但也越来越"健忘"。
三、Mamba 的优点
2023 年底,一个叫 Mamba 的架构出来了。
核心创新就一点:让模型根据内容动态决定记什么、忘什么。
这很反直觉。传统模型对所有输入一视同仁,Mamba 不一样------它会挑重点。
就像你读论文,方法和结论细看,而过渡句扫一眼就行了。Mamba 让 AI 学会了这种"偷懒"。
结果就显而易见,在长序列任务上,Mamba 用更少的显存,达到接近 Transformer 的效果。而且复杂度是 O(n),序列再长也不怕。
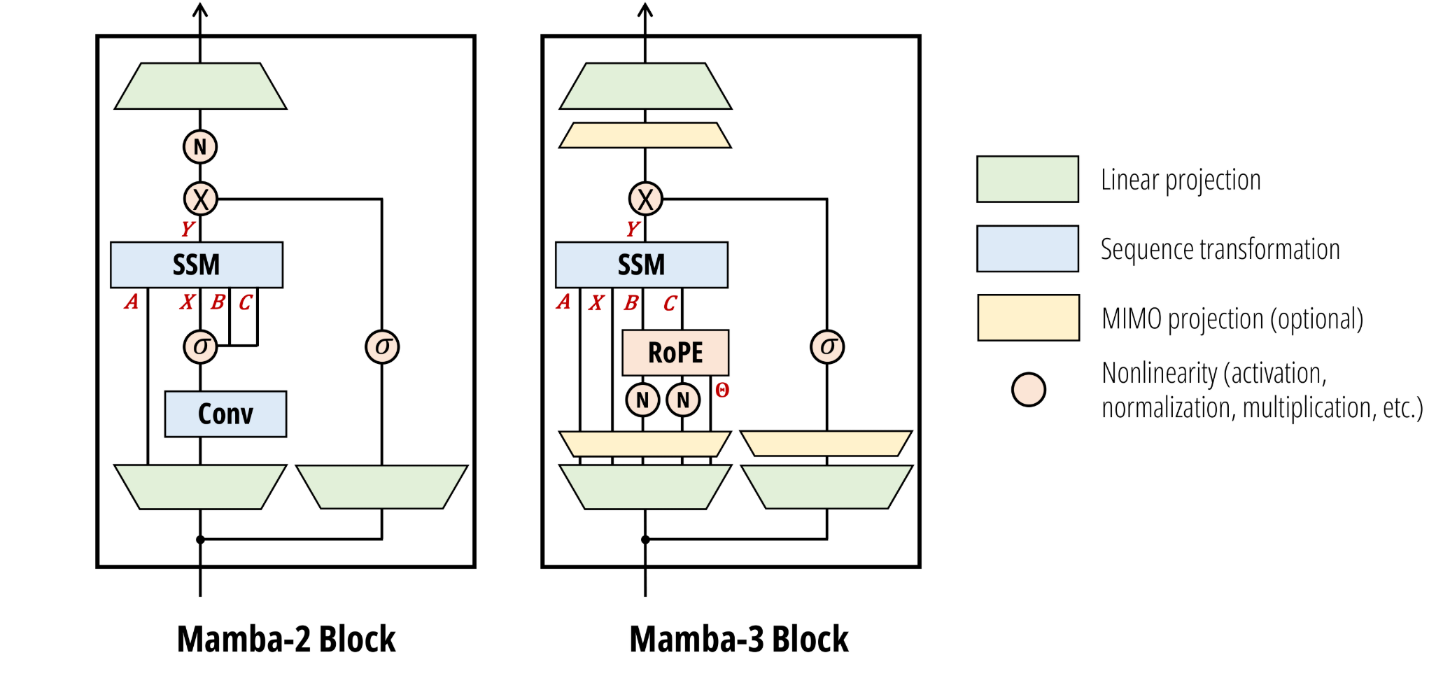
四、Mamba 对语言大模型意味着什么?
Jamba 是第一个 Mamba+Transformer 混合的语言模型,AI21 Labs 做的。256K 上下文窗口,推理速度比同规模 Transformer 快 3 倍,显存省 40%。
这说明什么?
具体来说:
- 减少"模型幻觉":状态持续更新,理论上可以记住无限长的上下文
- 更便宜:推理成本恒定,不会随长度飙升
- 更快:不用存储所有历史 token,只存一个状态向量
这对长文档、对话、代码补全这些场景,是质的飞跃。
五、三种未来
我判断有三种可能:
场景一:Mamba 取代 Transformer(15%)
需要 Mamba 在 100B+ 参数规模上证明自己,还要硬件厂商全面支持。目前看,很难。
场景二:融合共存(60%)
最可能的结果。短序列继续用 Transformer,长序列用 Mamba,混合架构成为主流。就像今天 CNN 和 Transformer 在视觉领域的共存。
场景三:Mamba 被遗忘(25%)
如果 Transformer 的优化(比如 Flash Attention)持续进步,Mamba 又在大规模训练中遇到瓶颈,可能退居学术研究。类似当年 Capsule Network 的命运。
六、谁该关注 Mamba?
高潜力场景:
- 长文档处理(序列 > 4K)
- 视频理解
- 基因组序列分析
- 实时推理系统
低潜力场景:
- 短文本任务,Transformer 已经够强
- 需要复杂推理的任务,Mamba 还差点意思
结语
Transformer 不是唯一的答案。AI 的底层架构还有很大探索空间。
技术人现在该做的:学原理,关注进展,在合适的场景尝试。但别押注它替代 Transformer------大概率是共存,不是替代。