学习笔记:详述 RAG 系统中向量数据库的核心原理、ANN 索引算法、主流数据库对比以及工程实践
目录
- 为什么需要向量数据库
- [Embedding 算法演进](#Embedding 算法演进)
- 向量数据库核心概念
- [ANN 索引算法](#ANN 索引算法)
- [HNSW 算法](#HNSW 算法)
- [IVF 算法](#IVF 算法)
- [IVF-PQ 算法](#IVF-PQ 算法)
- 索引算法对比
- 向量量化压缩
- [标量量化 SQ8](#标量量化 SQ8)
- [乘积量化 PQ](#乘积量化 PQ)
- 量化方法对比
- 主流向量数据库对比
- 向量数据库工程实践
- 参考资料
为什么需要向量数据库
RAG 系统中,文档经过 Embedding 模型转化为高维向量后,需要一个专门的存储和检索系统。向量数据库的核心能力是近似最近邻搜索(ANN) ,能在百万甚至亿级向量中快速找到最相似的结果。
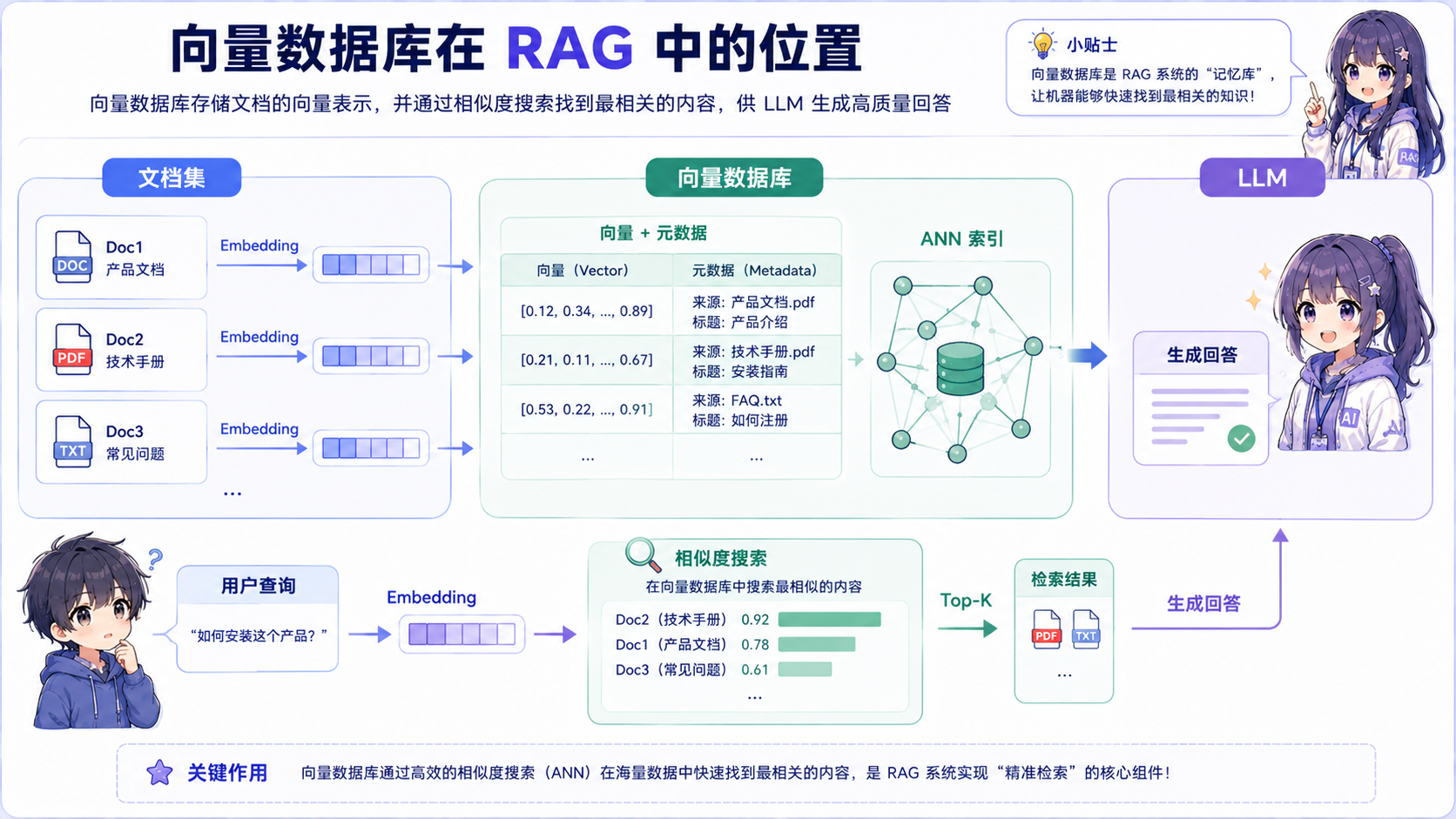
为什么不用传统数据库
传统关系型数据库(如 MySQL)依赖 B-tree 索引,擅长一维有序数据的精确匹配。但高维向量的"近似"是多维度的整体判断,B-tree 无法有效处理。暴力遍历计算所有向量的相似度在百万级数据上延迟不可接受。向量数据库通过专用索引结构(如 HNSW、IVF)将延迟降到毫秒级。
Embedding 算法演进
理解 Embedding 算法的演进有助于选择合适的模型。三代算法逐步解决了前一代的核心缺陷。
第一代:静态词向量(Word2Vec / GloVe / FastText)
每个词映射为一个固定向量,不随上下文变化。
| 模型 | 年份 | 核心思想 | 特点 |
|---|---|---|---|
| Word2Vec | 2013, Google | CBOW / Skip-gram | Skip-gram 更常用,对稀有词效果好 |
| GloVe | Stanford | 全局共现矩阵分解 | 利用全局统计信息,效果与 Word2Vec 相当 |
| FastText | 子词(n-gram)分解 | 解决未登录词(OOV)问题 |
经典特性 :国王 - 男人 + 女人 ≈ 女王
致命缺陷:每个词只有一个固定向量,无法处理多义词。"苹果" 在 "我吃了苹果" 和 "苹果手机" 中向量完全相同。
第二代:上下文向量(ELMo / BERT)
向量随上下文动态变化,同一词在不同句子中产生不同向量。
| 模型 | 年份 | 核心思想 | 特点 |
|---|---|---|---|
| ELMo | 2018, Allen NLP | 双向 LSTM | 第一个实用的上下文 Embedding |
| BERT | 2018, Google | Transformer + MLM | 全双向注意力,[CLS] 句向量 |
检索场景的致命缺陷:比较两个句子必须将它们拼接后输入 BERT。百万文档意味着百万次前向传播,每次数十毫秒,总计数小时------无法用于实时检索。
第三代:句级对比学习(SBERT / SimCSE / BGE)
专为句子相似度和语义检索设计,是 RAG 系统的标准选择。
| 模型 | 年份 | 核心思想 | 特点 |
|---|---|---|---|
| SBERT | 2019 | 双编码器架构 | 两句独立编码,速度提升数个数量级 |
| SimCSE | 2021, Princeton | 对比学习 + Dropout | 解决 BERT 向量各向异性问题 |
| BGE | BAAI | 大规模双语对比学习 | 中文 RAG 首选 |
| E5 | Microsoft | 指令微调 | 英文高精度 |
SBERT 的核心突破:
传统 BERT 检索:Doc1 + Query → BERT → 相似度 (每次都要拼接,慢)
SBERT 检索: Doc1 → BERT → Vec1 (预计算,存起来)
Query → BERT → VecQ (只算一次)
VecQ × Vec1 → 相似度 (毫秒级)文档向量可预计算存储,查询时只需编码查询文本,实现毫秒级检索。
最新趋势(2025-2026)
| 趋势 | 说明 |
|---|---|
| 指令感知 Embedding | 如 Qwen3-Embedding,同一文本在不同检索指令下产生不同向量 |
| Matryoshka 表示学习 | 前 N 维保留语义,支持灵活降维平衡精度与存储 |
| 多模态 Embedding | 单模型编码文本和图像,支持跨模态检索 |
三代算法对比:
| 代次 | 代表模型 | 核心特性 | 局限 | RAG 适用性 |
|---|---|---|---|---|
| 第一代 | Word2Vec, GloVe | 词级静态向量 | 无法处理多义词,词级非句级 | 不适用 |
| 第二代 | ELMo, BERT | 上下文动态向量 | 需拼接两句子才能比较,极慢 | 不适合实时检索 |
| 第三代 | SBERT, BGE, E5 | 句级双编码器 + 对比学习 | 精度略低于交叉编码器 | 标准选择 |
向量数据库核心概念
什么是向量数据库
向量数据库是专为存储和检索高维向量而设计的数据库,核心能力是近似最近邻搜索(ANN)。存储的向量是 Embedding 模型产生的浮点数数组(如 768 或 1024 维),每个向量代表源内容的语义信息------语义相似的内容向量距离更近。
与传统数据库的区别
| 方面 | MySQL 等关系型数据库 | 向量数据库 |
|---|---|---|
| 索引方式 | B-tree(一维精确匹配) | HNSW/IVF(多维近似匹配) |
| 查询语义 | 精确匹配(=, LIKE) |
语义相似("最像什么") |
| 数据类型 | 结构化字段 | 高维浮点向量 |
| 典型场景 | 按 ID 查用户、按日期筛选 | 按语义找相似文档 |
核心能力
1. 元数据过滤(混合检索)
每个向量可携带元数据字段(如部门、日期、来源)。检索时先用过滤条件缩小范围,再执行 ANN 搜索。先搜索再过滤会浪费检索槽位在不相关结果上。
2. 实时更新
主流向量数据库支持在线写入和增量索引构建------新数据到达后无需停止服务重建索引。
3. 关键词搜索集成
纯向量检索对精确术语(如产品型号、专有名词)效果差。部分数据库同时支持向量检索 + BM25 关键词搜索,实现混合召回。
ANN 索引算法
ANN(Approximate Nearest Neighbor)是向量数据库的核心搜索范式,通过牺牲少量精度换取大幅检索速度提升。
HNSW 算法(Hierarchical Navigable Small World)
核心原理 :基于跳表(Skip List)+ 小世界图(Small World Graph)的多层图结构。
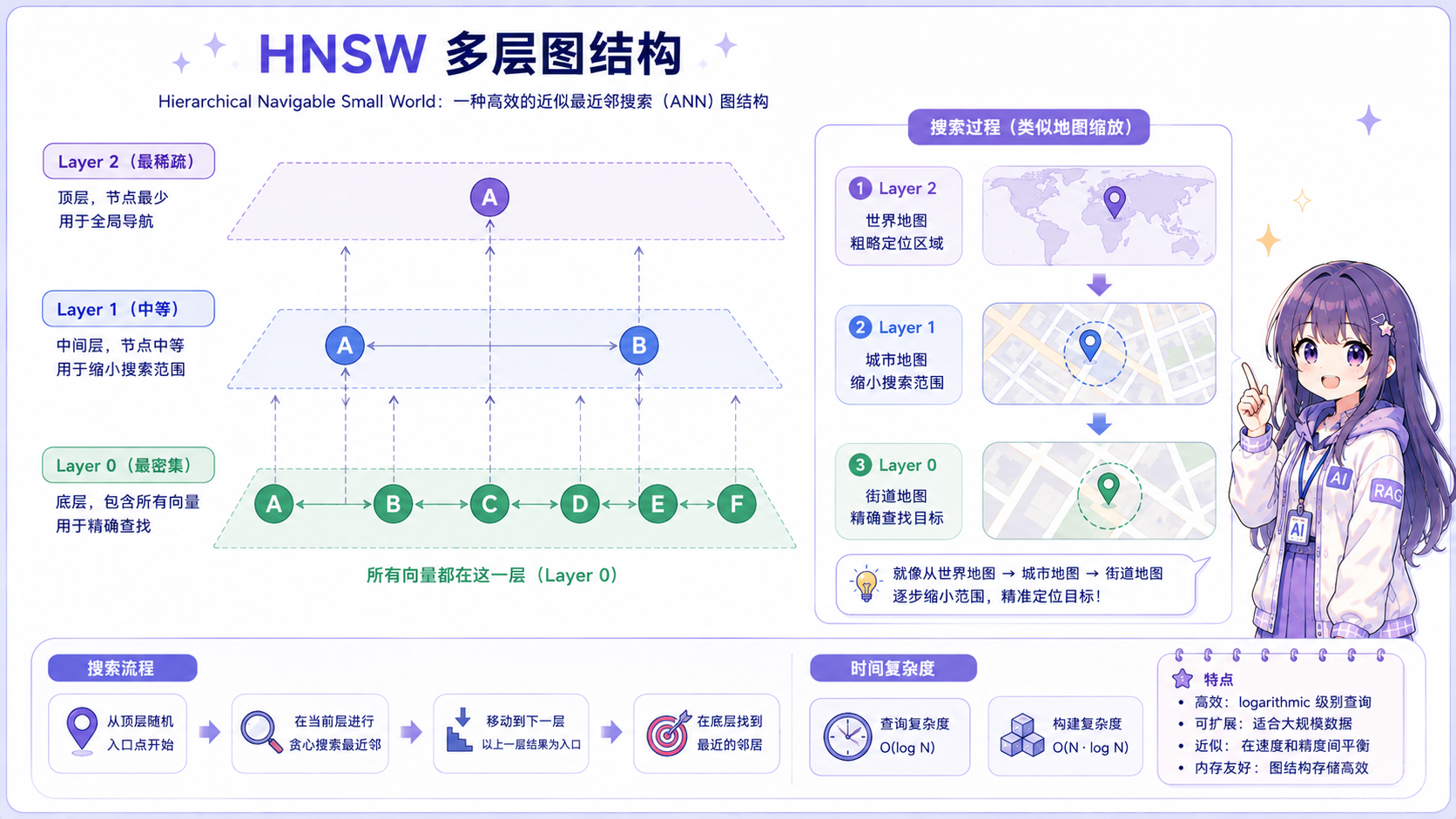
关键参数:
| 参数 | 说明 | 推荐值 |
|---|---|---|
M |
每个节点的最大连接数 | 16-64 |
ef_construction |
构建时的候选集大小 | 100-200 |
ef_search |
查询时的候选集大小 | 50-200 |
优势:查询速度极快(O(log N)),召回率高(>95%),支持增量插入。
劣势:内存占用大(图结构需全部加载到内存),构建时间较长。
默认使用 HNSW 的数据库:Qdrant、Milvus、Chroma、Weaviate。
IVF 算法(Inverted File Index,倒排文件索引)
核心原理 :先用 K-Means 聚类将向量空间划分为若干个 Voronoi 单元,查询时只在最近的几个聚类中搜索。
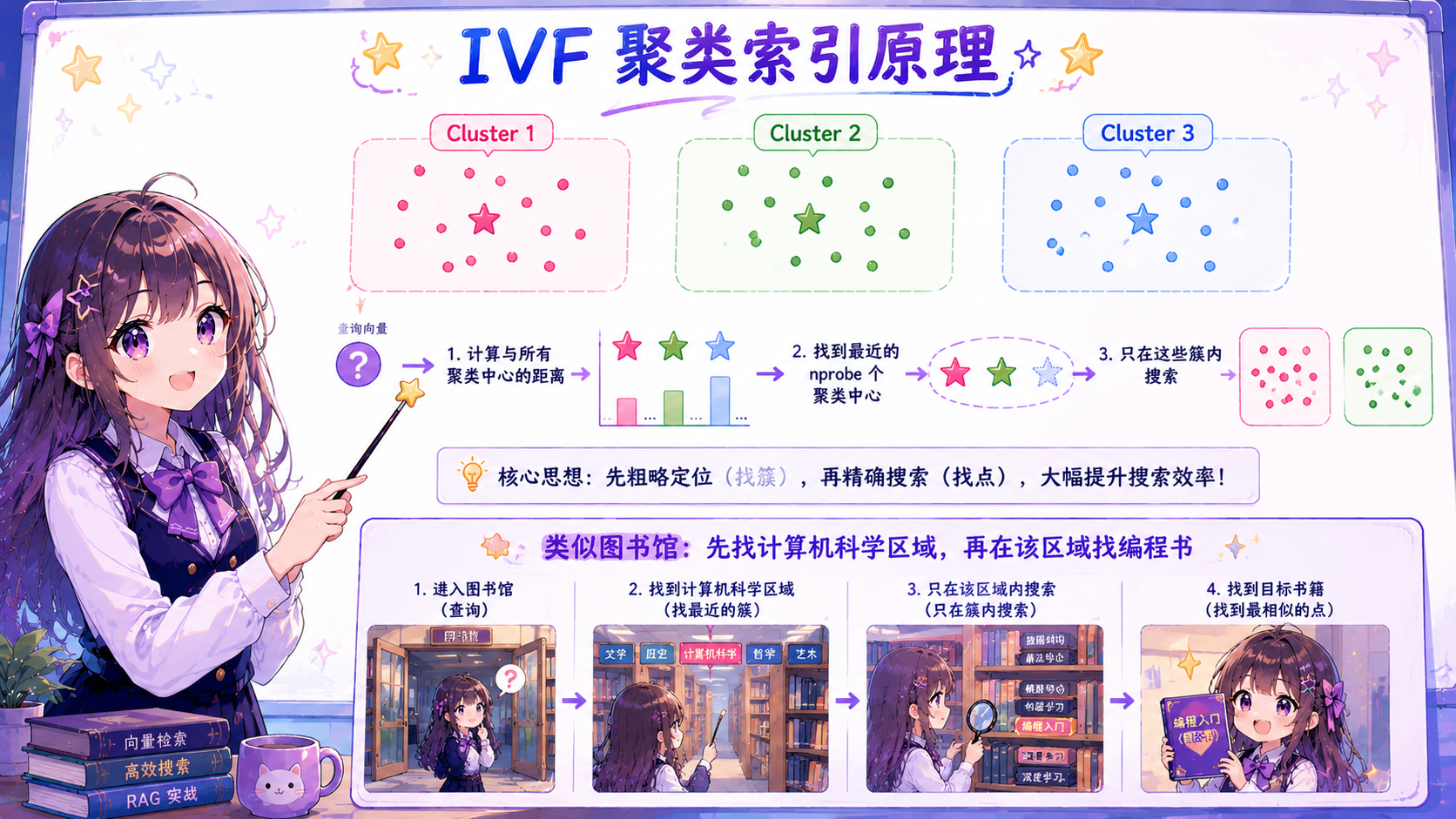
关键参数:
| 参数 | 说明 | 推荐值 |
|---|---|---|
nlist |
聚类中心数量 | 通常 √N |
nprobe |
查询时探查的聚类数 | 越大召回率越高,但速度越慢 |
优势:内存效率高,可与 PQ 乘积量化结合压缩存储,适合超大规模数据。
劣势:精度略低于 HNSW,边界附近的向量可能被遗漏。
使用 IVF 的场景:Milvus 在超大规模数据场景下使用 IVF 系列索引。
IVF-PQ 算法
将 IVF 聚类与 PQ 乘积量化结合:先用 IVF 聚类缩小搜索范围,再对每个聚类内的向量用 PQ 压缩存储。
流程:原始向量 → IVF 聚类分桶 → 每个桶内向量用 PQ 压缩 → 查询时先定位桶,再在桶内用 PQ 查表法计算近似距离。
适用场景:超大规模(亿级)、内存受限场景。
索引算法对比
| 算法 | 查询复杂度 | 内存需求 | 召回率 | 适用场景 |
|---|---|---|---|---|
| HNSW | O(log N) | 高 | ★★★★★ | 高精度、实时查询 |
| IVF | O(N/nlist·nprobe) | 中 | ★★★★ | 大规模数据、可调精度 |
| IVF-PQ | 低 | 低 | ★★★ | 超大规模、内存受限 |
| ScaNN | 低 | 中 | ★★★★ | Google 提出,各向异性优化 |
| DiskANN | O(log N) | 低 | ★★★★ | 超大规模、SSD 存储 |
主流数据库的索引支持:
| 数据库 | 默认索引 | 其他支持 |
|---|---|---|
| Milvus | HNSW | IVF_FLAT, IVF_PQ, DiskANN |
| Weaviate | HNSW | Flat |
| Qdrant | HNSW | 标量量化 |
| FAISS | IVF | HNSW, PQ, OPQ |
向量量化压缩
向量量化是降低存储成本和提升检索效率的关键技术。核心思想是用更低精度的表示替代原始 float32 向量。
标量量化 SQ8(Scalar Quantization)
原理:将每个维度的 float32(4 字节)独立量化为 int8(1 字节)。
过程:
1. 对每个维度找到 min 和 max
2. 线性映射 [min, max] → [0, 255]
3. 查询时逆映射还原近似值
压缩率:float32 (32bit) → int8 (8bit),约 4 倍压缩类比:相当于把小数精度从 7 位降到 2 位------大部分语义信息存在于高位比特中。
效果:召回率下降不到 1 个百分点,是最具性价比的优化手段。
乘积量化 PQ(Product Quantization)
原理 :将高维向量切分为多个子空间,每个子空间独立聚类量化。

压缩率:float32 (d×32bit) → m×8bit,可达数十倍压缩。
优势:压缩率极高,支持高效 ANN 搜索(查表法)。
劣势:精度损失较大,需要训练码本(聚类中心)。
量化方法对比
| 方法 | 压缩率 | 精度 | 实现复杂度 | 适用场景 |
|---|---|---|---|---|
| SQ8 | ~4× | 较高 | 低 | 精度要求较高,中等规模 |
| PQ | ~32×+ | 中等 | 较高 | 大规模向量检索,内存受限 |
| OPQ | ~32×+ | 较高(优于 PQ) | 高 | 需要更高精度的大规模场景 |
| IVF-PQ | 高 | 中等 | 高 | 超大规模 + 内存受限 |
常见变体:
| 方法 | 说明 |
|---|---|
| OPQ | 正交旋转优化的 PQ,先做旋转再量化 |
| RQ | 残差量化,逐级量化残差 |
| IVF-PQ | 先 IVF 聚类,再对残差做 PQ |
| ScaNN | Google 提出的各向异性量化方法 |
主流向量数据库对比
Milvus
| 属性 | 说明 |
|---|---|
| 开发语言 | Go / C++ |
| 部署方式 | 单机 / 分布式 |
| 扩展性 | ★★★★★(支持百亿级向量) |
| 特色 | 水平扩展、读写分离、GPU 加速、丰富索引类型 |
核心概念:
- Collection:类似关系数据库的表
- Segment:内部数据管理单元,增量段 → 密封段(触发索引构建)
- Index:支持 HNSW、IVF_FLAT、IVF_PQ、DiskANN 等
适用场景:企业级生产环境,百万到亿级数据,需要分布式部署。
Qdrant
| 属性 | 说明 |
|---|---|
| 开发语言 | Rust |
| 部署方式 | 自托管 / 云服务(分布式) |
| 扩展性 ★★★★(十亿级) | |
| 特色 | 高性能、丰富过滤、gRPC + REST API |
适用场景:中大规模生产环境,需要强过滤能力和高性能。
Chroma
| 属性 | 说明 |
|---|---|
| 开发语言 | Python |
| 部署方式 | 嵌入式 / 客户端-服务器 / 云 |
| 扩展性 | ★★(中小规模) |
| 特色 | 零配置、上手极快、与 LLM 生态集成好 |
适用场景:原型开发、小规模应用、LLM 应用快速集成。
Weaviate
| 属性 | 说明 |
|---|---|
| 开发语言 | Go |
| 部署方式 | 自托管 / 云服务 |
| 扩展性 | ★★★★ |
| 特色 | 内置向量化模块、GraphQL API、混合搜索 |
适用场景:多模态搜索、需要内置向量化能力。
FAISS
| 属性 | 说明 |
|---|---|
| 开发语言 | C++ / Python |
| 类型 | 库(非完整数据库) |
| 特色 | 纯索引、GPU 加速、极高性能 |
注意:FAISS 是索引库,不是数据库------没有持久化、服务器、过滤、CRUD 等功能。
适用场景:算法研究、高性能离线处理、嵌入式使用。
pgvector
| 属性 | 说明 |
|---|---|
| 类型 | PostgreSQL 扩展 |
| 特色 | 无需新组件、SQL JOIN 业务数据、全文搜索融合 |
适用场景:已有 PostgreSQL 的团队,不想引入新基础设施。
Pinecone
| 属性 | 说明 |
|---|---|
| 类型 | 全托管云服务 |
| 特色 | 零运维、开箱即用 |
注意:费用较高,需关注数据驻留和合规问题。
选型指南
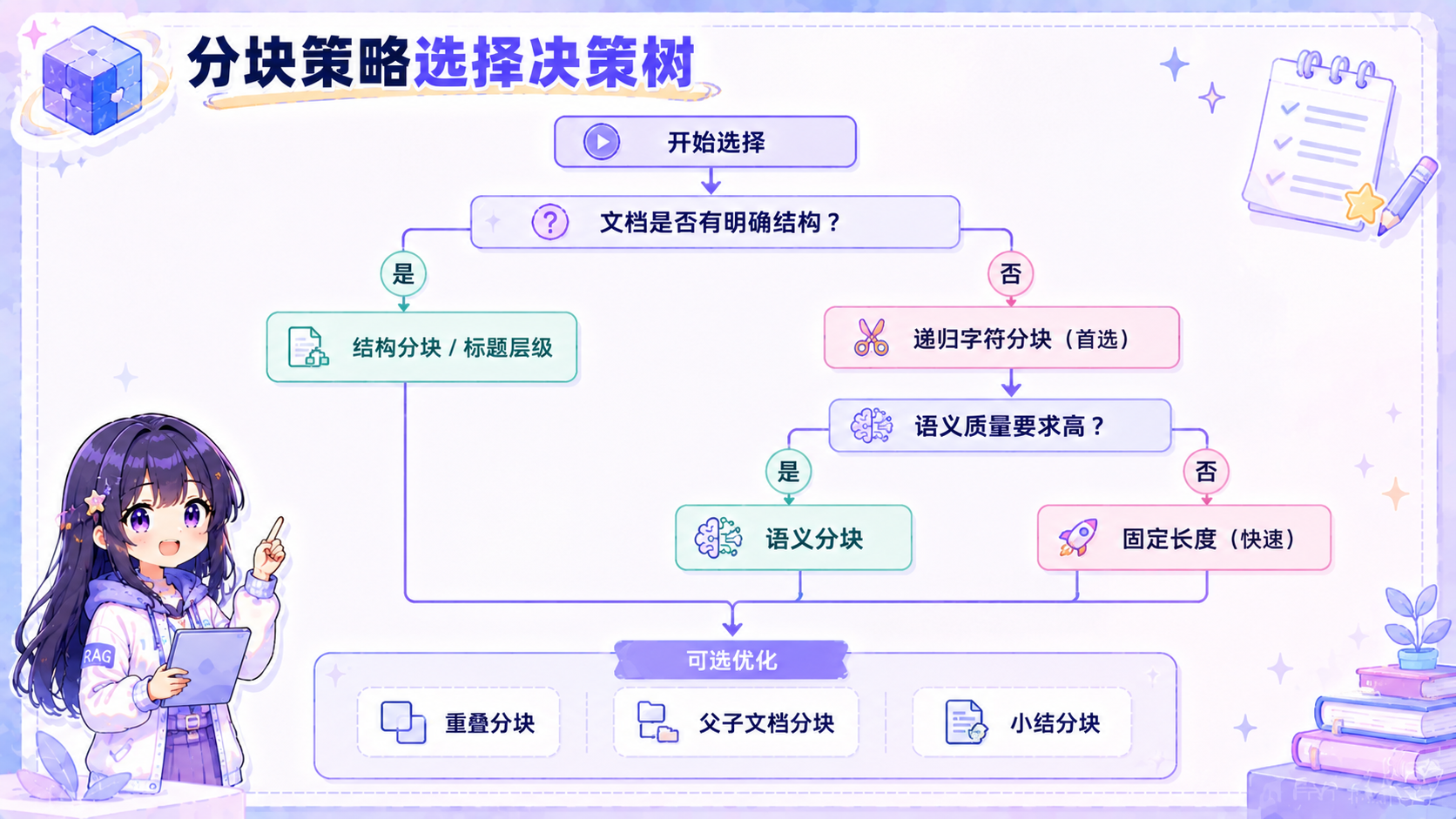
综合对比:
| 数据库 | 扩展性 | 易用性 | 混合搜索 | 过滤 | GPU | 最佳场景 |
|---|---|---|---|---|---|---|
| Milvus | ★★★★★ | ★★★ | ✓ | ✓ | ✓ | 大规模生产 |
| Qdrant | ★★★★ | ★★★★ | ✓ | ✓★ | ✗ | 均衡性能+功能 |
| Chroma | ★★ | ★★★★★ | ✗ | ✓ | ✗ | 原型/LLM 应用 |
| Weaviate | ★★★★ | ★★★★ | ✓ | ✓ | ✗ | 多模态搜索 |
| FAISS | ★★ | ★★ | ✗ | ✗ | ✓ | 研究/离线 |
| pgvector | ★★ | ★★★★ | ✓ | ✓ | ✗ | 已有 PG |
典型迁移路径:Chroma(原型)→ Qdrant(生产)→ Milvus(大规模)
向量数据库工程实践
Milvus 生产实践案例
场景 :知识库检索系统,约 150 万条 chunk ,每条为 1024 维向量(BGE-large-zh 生成),HNSW 索引(M=16, ef_construction=128)。
选型理由:
- 数据量超过单机承载能力,需要分布式部署
- 知识库每日增量更新,需要读写分离
性能指标(单机,16 核,32GB RAM,千兆局域网,HNSW 内存模式,ef=100):
| 指标 | 数值 |
|---|---|
| P50 延迟 | ~20ms |
| P99 延迟 | ~60ms |
| 并发吞吐 | 100 QPS 稳定 |
内存计算与优化
原始向量内存 :150 万 × 1024 维 × 4 字节(float32)≈ 6GB(仅向量数据)
Milvus 实际占用 :约 10-12GB(额外 4-6GB 用于 HNSW 图结构、元数据、管理开销、OS 缓存)
SQ8 量化优化:
| 状态 | 内存占用 | 召回率变化 |
|---|---|---|
| float32 原始 | ~10GB | 基准 |
| SQ8 量化后 | ~3GB | 下降 <1% |
额外优化 :Milvus 支持 mmap 将原始向量存储在磁盘,只在内存中保留索引。原始向量仅在精排阶段读取,对查询延迟影响很小。
性能瓶颈与解决方案
瓶颈 1:内存压力导致查询延迟飙升
| 项目 | 说明 |
|---|---|
| 现象 | P50 延迟从 20ms 飙升到 2 秒以上 |
| 原因 | 内存不足,OS 频繁 swap 到磁盘 |
| 解决 | SQ8 量化将内存从 10GB 降到 3GB,消除 swap;辅以 mmap 将原始向量存磁盘 |
瓶颈 2:批量写入触发 Segment 合并导致查询抖动
| 项目 | 说明 |
|---|---|
| 现象 | 每日增量更新时 P99 从 60ms 飙升到 300ms+ |
| 原因 | 大量新记录触发后台 Segment 合并(合并小段 + 构建索引),CPU 和磁盘 I/O 密集 |
| 解决 1 | 低峰期调度:将批量写入移到凌晨低峰期 |
| 解决 2 | 分批写入:每批限制 500-1000 条,间隔数秒,将一次大冲击转为多次小冲击 |
分批写入示例:
python
# ❌ 一次性写入 50 万条 → 触发大合并,查询抖动
collection.insert(all_data)
# ✅ 分批写入,每批 1000 条,间隔 3 秒
for i in range(0, len(data), 1000):
batch = data[i:i+1000]
collection.insert(batch)
time.sleep(3)参考资料
-
HNSW 论文:Efficient and Robust Approximate Nearest Neighbor Search using HNSW Graphs
-
FAISS 文档(Facebook AI Similarity Search)
-
Milvus 官方文档
-
Qdrant 文档
-
Chroma 文档
-
Weaviate 文档
-
ANN Benchmarks(索引算法性能对比)
-
Product Quantization for Nearest Neighbor Search(经典论文)