文章目录
-
- 人工备注说明
- 一、项目简介
- 二、架构设计
-
- [2.1 flow-model --- 数据模型层](#2.1 flow-model — 数据模型层)
- [2.2 flow-client --- 可视化设计器](#2.2 flow-client — 可视化设计器)
- [2.3 flow-script --- Spark 执行引擎](#2.3 flow-script — Spark 执行引擎)
- [2.4 子进程通信协议](#2.4 子进程通信协议)
- 三、扩展机制
-
- [3.1 自定义 Map 函数](#3.1 自定义 Map 函数)
- [3.2 自定义 Filter 函数](#3.2 自定义 Filter 函数)
- 四、技术栈总览
- 五、设计亮点
- 六、总结
- 七、运行效果
-
- [7.1 使用的测试数据](#7.1 使用的测试数据)
- [7.2 配置文件数据源节点](#7.2 配置文件数据源节点)
- [7.3 配置Spark Map节点](#7.3 配置Spark Map节点)
- [7.4 配置Spark Filter节点](#7.4 配置Spark Filter节点)
- [7.5 配置Spark SQL节点](#7.5 配置Spark SQL节点)
- [7.6 配置DB导出节点](#7.6 配置DB导出节点)
- [7.7 执行完成后,数据表的数据](#7.7 执行完成后,数据表的数据)
人工备注说明
- 开发工具Claude Code + (火山方舟)glm-5.1/deepseek v4 pro;
- 这个项目完全使用Claude Code开发,大概2天左右完成;大概2小时完成70%代码,剩下30%代码经过多次测试和提示词进行微调完成。
- 这篇文章也是使用Claude Code编写;
- 注意:这个应用只进行简单测试,未覆盖所有场景,可能存在异常的情况,文末提供源码供学习研究!
一、项目简介
FlowLoom 是一个可视化数据处理桌面工具,旨在让数据分析师和开发人员无需编写复杂的 Spark 代码,通过拖拽方式即可设计并执行数据处理流程。
核心工作流:用户通过 Swing GUI 设计数据处理流程图 → 保存为 XML 文件 → Apache Spark 引擎分布式执行。
支持的数据处理能力:
| 类别 | 节点类型 | 说明 |
|---|---|---|
| 数据源 | 文件数据源 | 支持 Excel / CSV / TXT 文件读取 |
| 数据源 | 数据库数据源 | 支持 MySQL、Oracle 等关系型数据库 |
| 转换 | Map 映射 | 通过自定义 Java 类实现字段级转换 |
| 转换 | Filter 过滤 | 按条件筛选数据行 |
| 转换 | SQL 查询 | 使用 SQL 语句进行数据查询与聚合 |
| 输出 | CSV 导出 | 结果导出为 CSV 文件 |
| 输出 | Excel 导出 | 结果导出为 Excel 文件 |
| 输出 | 数据库导出 | 结果写入 MySQL 等数据库表 |
二、架构设计
FlowLoom 采用 Maven 多模块架构,分为三个子模块,依赖关系清晰:
flow-model(共享数据模型,无 UI/Spark 依赖)
↑ ↑
flow-client flow-script
(Swing GUI) (Spark 引擎)2.1 flow-model --- 数据模型层
定义流程图的领域模型,是 client 和 script 之间唯一的共享契约。核心类包括:
- FlowGraph:流程图顶层容器,包含节点列表和边列表,内置拓扑排序算法
- FlowNode:流程节点,包含类型、坐标位置和属性键值对
- FlowEdge:有向边,连接源节点和目标节点
- FlowProperty:节点属性的键值对模型
- NodeType:枚举所有节点类型,分为 SOURCE / TRANSFORM / SINK 三大类别
所有模型类使用 Jackson XML 注解进行序列化,生成的 XML 文件兼具可读性和可移植性:
xml
<flow name="数据处理流程" type="FILE" version="1.0">
<nodes>
<node id="n1" type="FILE_SOURCE" x="70" y="110">
<property name="filePath" value="data/input.csv"/>
<property name="fileType" value="CSV"/>
</node>
<node id="n2" type="FILTER" x="270" y="110">
<property name="filterClass" value="TestFilter"/>
</node>
<node id="n3" type="CSV_EXPORT" x="470" y="110">
<property name="filePath" value="data/output.csv"/>
</node>
</nodes>
<edges>
<edge id="e1" source="n1" target="n2"/>
<edge id="e2" source="n2" target="n3"/>
</edges>
</flow>2.2 flow-client --- 可视化设计器
基于 Java Swing 构建的桌面应用,技术选型精巧:
- FlatLaf:现代化 Swing 主题,提供原生感的界面体验
- JGraphX (mxGraph):流程图绘制引擎,支持拖拽、连线、缩放等交互
- RSyntaxTextArea:代码编辑器组件,用于 SQL 和自定义代码编辑
- zt-exec:子进程管理库,用于启动 flow-script 执行引擎
界面布局采用经典的分割面板设计:
MainFrame
├── FlowMenuBar(菜单栏)
├── TaskListPanel(左侧任务列表)
└── JTabbedPane(右侧多标签页编辑器)
└── TaskTabPanel(单个任务编辑器)
├── NodeToolbarPanel / ActionToolbarPanel(工具栏)
├── FlowCanvasPanel(流程画布)
│ ├── FlowGraphAdapter(模型桥接层)
│ ├── FlowGraphComponent(mxGraph 组件)
│ └── FlowGraphStyles(样式定义)
├── PropertiesPanel(属性面板,CardLayout 切换)
│ ├── FileSourcePropertiesPanel
│ ├── MapPropertiesPanel
│ ├── FilterPropertiesPanel
│ ├── SqlPropertiesPanel
│ ├── CsvExportPropertiesPanel
│ ├── ExcelExportPropertiesPanel
│ └── DbExportPropertiesPanel
└── ExecutionLogPanel(运行日志面板)其中 FlowGraphAdapter 是关键的桥接层,负责将 FlowGraph 模型对象与 mxGraph 可视化组件进行双向同步------用户在画布上的拖拽、连线、属性编辑操作都会实时反映到模型中,反之亦然。
2.3 flow-script --- Spark 执行引擎
执行引擎是整个平台的计算核心,采用经典的管道(Pipeline)模式:
MainSparkFlow
→ FlowParser(解析 XML 为 FlowGraph)
→ PipelinePlan(拓扑排序,生成执行计划)
→ PipelineExecutor(遍历执行计划)
→ FlowOperator(算子分发执行)FlowParser 负责验证并解析 XML 流程文件,生成 FlowGraph 领域对象。
PipelinePlan 对 FlowGraph 执行拓扑排序,计算出无环依赖的执行顺序。如果流程图中存在循环依赖,会直接抛出异常阻止执行。
PipelineContext 作为运行时上下文,持有 SparkSession 和各节点输出的 DataFrame,节点间通过 context 传递数据。
PipelineExecutor 内部维护一个 EnumMap<NodeType, FlowOperator> 的算子注册表,按执行顺序依次调用对应算子:
java
public class PipelineExecutor {
private final Map<NodeType, FlowOperator> operators = new EnumMap<>(NodeType.class);
public PipelineExecutor() {
registerOperator(new FileSourceOperator());
registerOperator(new DbSourceOperator());
registerOperator(new MapOperator());
registerOperator(new FilterOperator());
registerOperator(new SqlOperator());
registerOperator(new CsvExportOperator());
registerOperator(new ExcelExportOperator());
registerOperator(new DbExportOperator());
}
public void execute(PipelinePlan plan, PipelineContext ctx) throws Exception {
for (FlowNode node : plan.getExecutionOrder()) {
FlowOperator operator = operators.get(node.getType());
operator.execute(ctx, node);
}
}
}所有算子实现统一的 FlowOperator 接口------仅两个方法:getSupportedType() 声明支持的节点类型,execute() 执行具体逻辑。这种设计使得新增算子类型只需实现接口并注册即可,完全符合开闭原则。
2.4 子进程通信协议
flow-client 通过 ProcessBuilder 启动 flow-script 作为子进程执行。两者通过 stdout 的按行文本协议进行通信:
| 协议消息 | 含义 |
|---|---|
[LOG] message |
普通日志消息 |
[ERROR] message |
错误消息 |
[PROGRESS] nodeId percent |
节点执行进度 |
[COMPLETE] |
流程执行成功 |
[FAILED] message |
流程执行失败 |
flow-script 的 Log4j2 配置中专门设置了 Protocol appender,使用 %msg%n 格式确保协议消息不带时间戳前缀地输出到 stdout,供 flow-client 的 ProcessOutputConsumer 解析并展示在日志面板中。
三、扩展机制
3.1 自定义 Map 函数
Map 节点通过 mapClass 属性指定自定义转换类。用户只需继承 MapFormat 基类并实现转换逻辑:
java
public class DateFormatMap extends MapFormat {
@Override
public Row map(Row row) {
// 对每一行数据进行自定义转换
return row;
}
}运行时通过反射实例化 com.penngo.flowloom.script.map.{className},实现了插件化的扩展机制。
3.2 自定义 Filter 函数
类似 Map,Filter 节点通过 filterClass 属性指定过滤类,继承 FilterFormat 或使用模板类 TemplateFilter,在 GUI 中直接编写过滤表达式。
四、技术栈总览
| 技术 | 版本 | 用途 |
|---|---|---|
| Java | 17 | 主语言 |
| Apache Spark | 4.1.1 | 分布式计算引擎 |
| Jackson XML | 2.20.0 | XML 序列化 |
| Apache POI | 5.4.1 | Excel 读写 |
| FlatLaf | --- | Swing 现代化主题 |
| JGraphX | --- | 流程图可视化 |
| Log4j2 | 2.20.0 | 日志框架 |
| Lombok | 1.18.42 | 减少样板代码 |
| MySQL Connector | 8.3.0 | 数据库连接 |
| Hutool | 5.8.44 | 通用工具库 |
| LangChain4j | 1.12.2 | AI 能力集成(预留) |
五、设计亮点
-
模型驱动架构:flow-model 作为单一数据源,GUI 和引擎共享同一套模型定义,避免了数据不一致问题
-
算子插件化 :通过
FlowOperator接口 +EnumMap注册表实现算子的热插拔,新增节点类型无需修改执行器核心代码 -
拓扑排序执行:自动计算 DAG 的执行顺序并检测循环依赖,保证流程的正确性
-
进程隔离执行:GUI 与 Spark 引擎运行在不同 JVM 进程中,通过文本协议通信,避免了 Spark 依赖污染 GUI 进程,也便于资源隔离和崩溃恢复
-
编码兼容处理:针对 Spark CSV 不支持 GBK 的问题,FileSourceOperator 会自动检测编码并进行转码
-
属性泛化设计 :节点属性以
List<FlowProperty>键值对存储而非强类型字段,保证 XML 格式的向前兼容性和可扩展性
六、总结
FlowLoom 是一个设计精巧的数据处理平台,它巧妙地将低代码可视化 理念与 Apache Spark 分布式计算能力结合起来。通过清晰的模块划分、插件化的算子体系和简洁的子进程通信协议,在保持架构灵活性的同时降低了使用门槛。
无论是日常的数据 ETL 任务,还是需要快速搭建数据处理管道的场景,FlowLoom 都能提供一个直观高效的解决方案。
七、运行效果
7.1 使用的测试数据

7.2 配置文件数据源节点
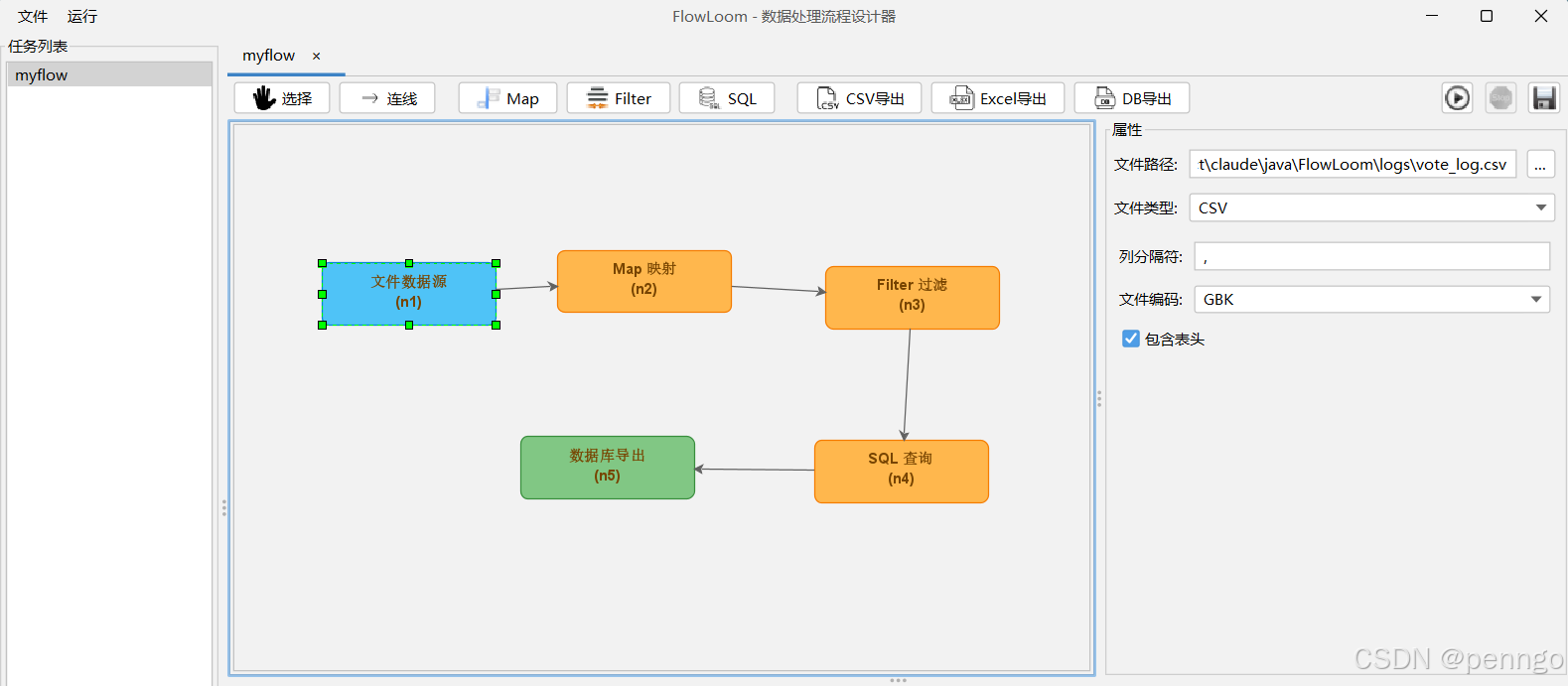
7.3 配置Spark Map节点
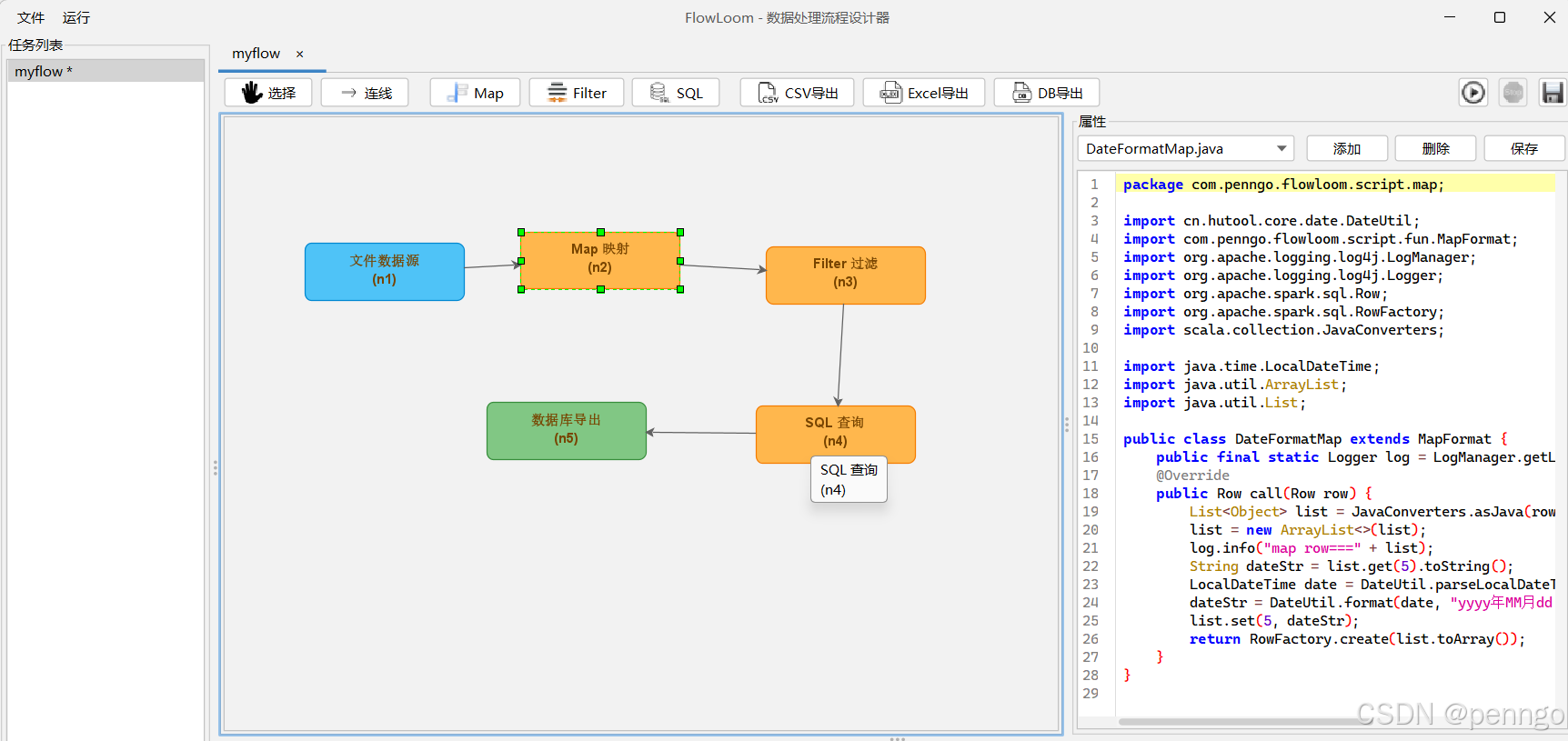
7.4 配置Spark Filter节点
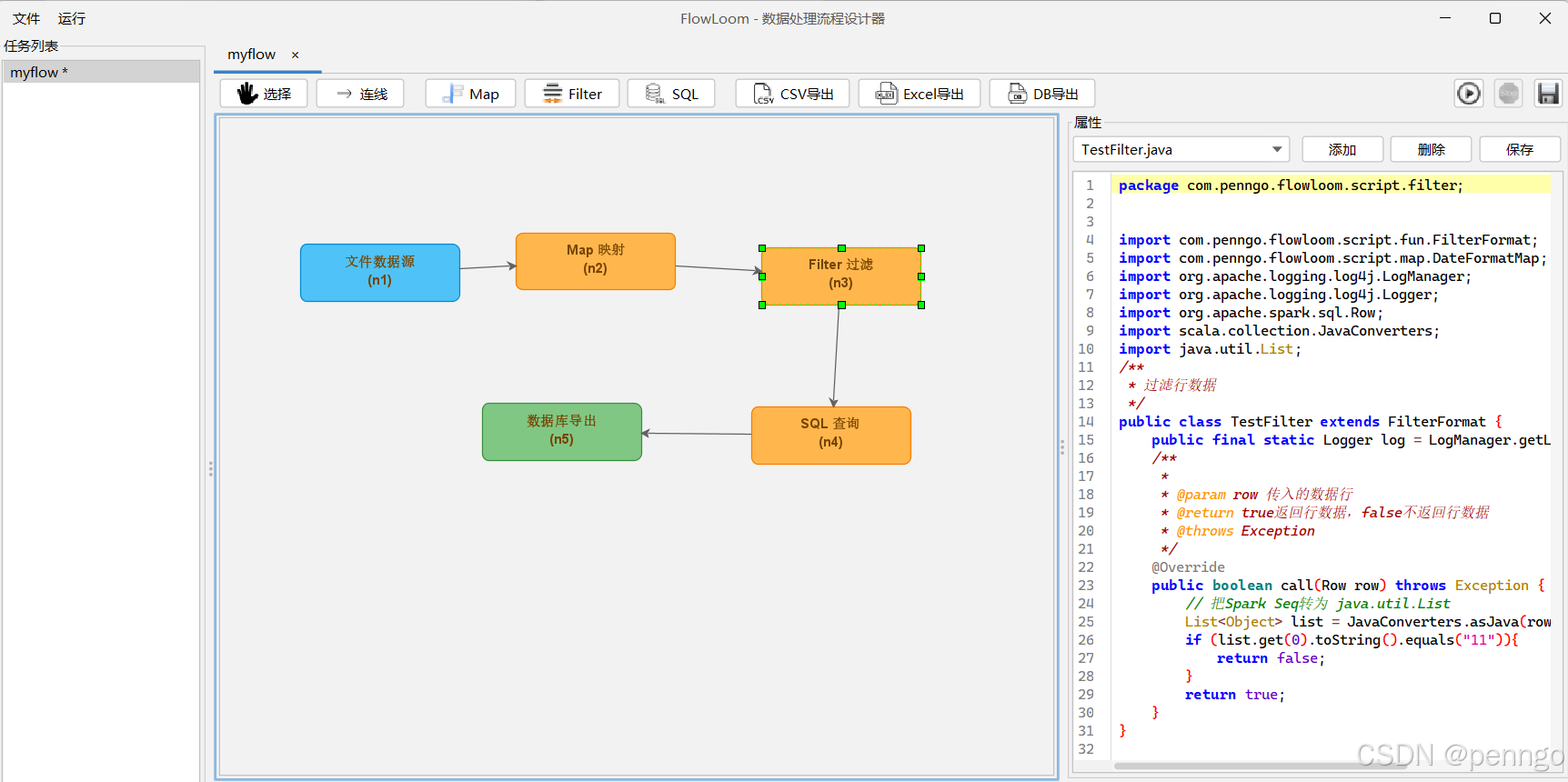
7.5 配置Spark SQL节点
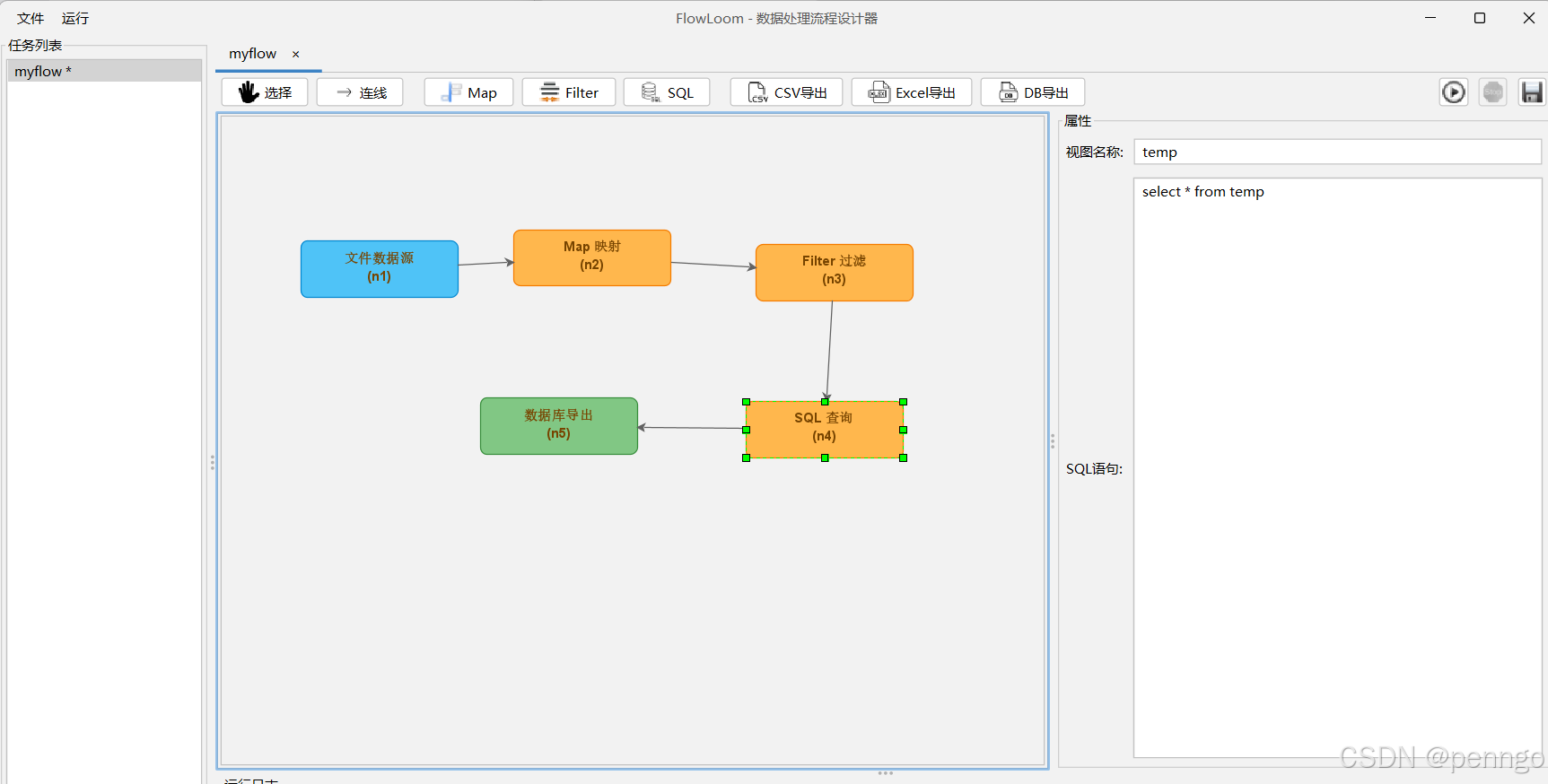
7.6 配置DB导出节点
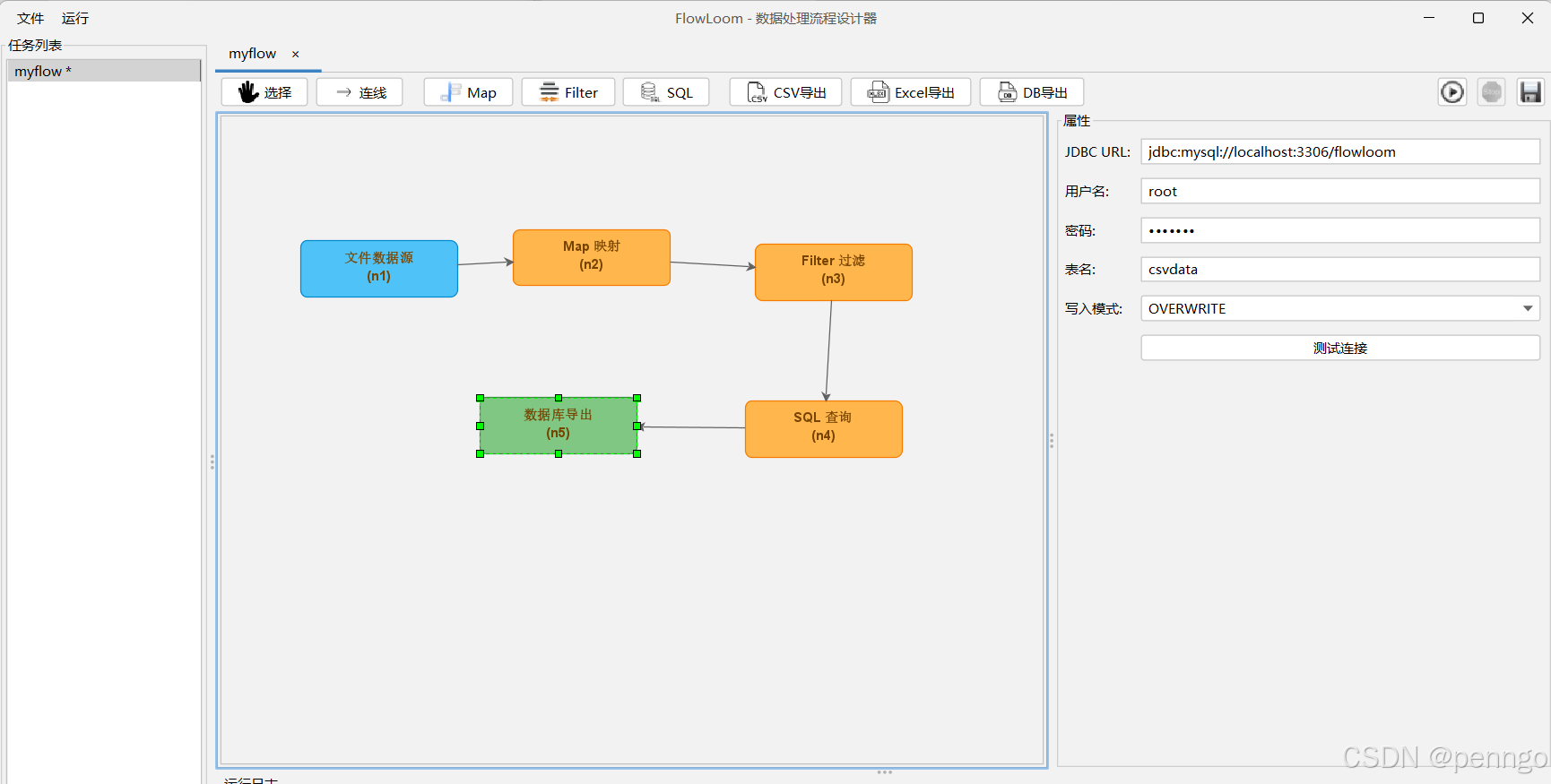
7.7 执行完成后,数据表的数据
