从向量到矩阵,从随机数到AI数据库------数学是编程的隐形骨架。
👋 你好,我是 Evan,一名计算机专业的学长,也是《大一突围》专栏的作者。大一时我总觉得线性代数没用,矩阵乘法除了考试还能干嘛?后来学到机器学习、向量数据库,才发现线性代数就是AI的"普通话"。今天我就带你用Python亲手实现向量和矩阵运算,并聊聊它们如何连接随机数、AI和向量数据库。你会发现:数学从未如此有用。
欢迎来到 《大一突围》 专栏。

一、为什么线性代数对程序员越来越重要?
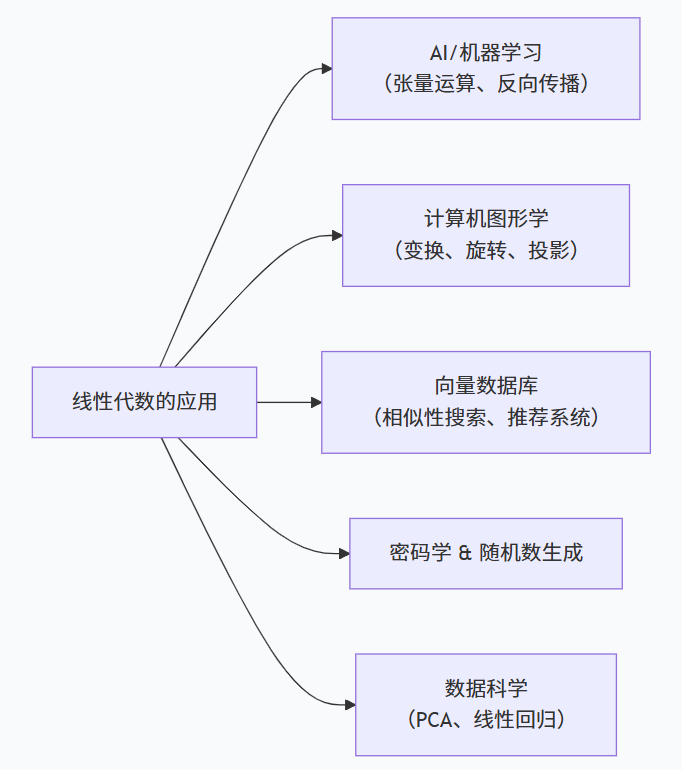
-
你写的每一行
import numpy as np,底层都是线性代数。 -
你用的 ChatGPT、Stable Diffusion,核心计算全是矩阵乘法。
-
你听说的"向量数据库"(如 Milvus、Pinecone),本质就是存储和检索高维向量,依赖向量相似度计算(余弦相似度、欧氏距离)。
结论:线性代数不是可选项,而是AI时代的必备内功。
二、向量:从几何意义到Python表示
2.1 什么是向量?
-
几何视角:空间中的一个箭头,有方向有长度。
-
代数视角 :一组有序的数字列表,例如
(3, 4)表示x=3, y=4。
2.2 向量的基本运算
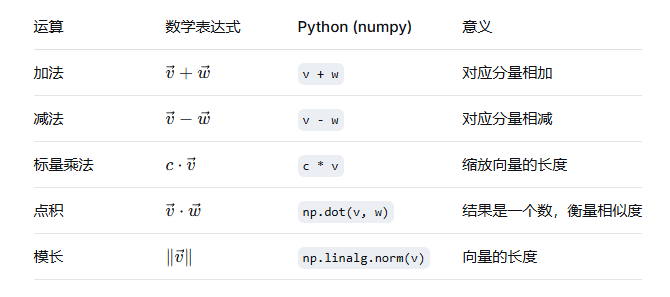
2.3 Python代码示例:从零开始(纯列表)与numpy实现
python
# 纯Python实现向量加法
def vector_add(v, w):
return [v_i + w_i for v_i, w_i in zip(v, w)]
v = [1, 2, 3]
w = [4, 5, 6]
print(vector_add(v, w)) # [5, 7, 9]
# 推荐使用 numpy(性能高,代码简洁)
import numpy as np
v = np.array([1, 2, 3])
w = np.array([4, 5, 6])
print(v + w) # [5 7 9]
print(np.dot(v, w)) # 32 (1*4 + 2*5 + 3*6)
print(np.linalg.norm(v)) # 3.741...2.4 向量在AI中的应用:余弦相似度
两个向量的余弦相似度公式:
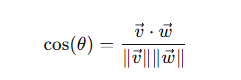
值越接近1,两个向量越相似。这正是向量数据库查找相似项的核心。
python
def cosine_similarity(v, w):
return np.dot(v, w) / (np.linalg.norm(v) * np.linalg.norm(w))
v1 = np.array([1, 0, 0]) # 代表"猫"
v2 = np.array([0.9, 0.1, 0]) # 相似向量
v3 = np.array([0, 0, 1]) # 代表"狗"
print(cosine_similarity(v1, v2)) # 0.99 很相似
print(cosine_similarity(v1, v3)) # 0.0 完全不同三、矩阵:批量处理向量的利器
3.1 什么是矩阵?
一个二维数组,可以看作一组行向量或列向量的集合。
3.2 矩阵的基本运算

3.3 Python代码示例
python
import numpy as np
A = np.array([[1, 2], [3, 4]])
B = np.array([[5, 6], [7, 8]])
# 矩阵乘法
print(A @ B)
# 输出:
# [[19 22]
# [43 50]]
# 转置
print(A.T)
# [[1 3]
# [2 4]]
# 单位矩阵
I = np.eye(2)
print(I) # [[1. 0.] [0. 1.]]3.4 矩阵在AI中的核心作用:神经网络的一层
一个全连接神经网络层:
输出 = 激活函数(输入 × 权重矩阵 + 偏置)
其中 输入 是向量,权重矩阵 负责将输入映射到输出空间。成千上万个这样的矩阵乘法构成了深度学习。
python
# 模拟一个简单层:3维输入 -> 2维输出
input_vec = np.array([1.0, 2.0, 3.0]) # 假设一个样本
weight_matrix = np.random.randn(3, 2) # 3x2 权重矩阵
bias = np.array([0.1, -0.1])
output = input_vec @ weight_matrix + bias
print(output) # 2维输出四、向量数据库:线性代数落地的明星
4.1 为什么需要向量数据库?
-
传统数据库按精确值查询(
where name = '张三')。 -
AI应用需要语义搜索:输入"猫",找出图像库中所有包含猫的图片。这需要将图片转化为向量,然后查找与"猫"向量最相似的项。
4.2 向量数据库的工作流程

4.3 用numpy模拟一个简单的向量数据库
python
import numpy as np
# 假设我们有3个文档向量(5维)
documents = np.array([
[0.9, 0.1, 0.0, 0.4, 0.2],
[0.1, 0.8, 0.3, 0.1, 0.5],
[0.2, 0.2, 0.9, 0.1, 0.1]
])
# 查询向量
query = np.array([0.85, 0.15, 0.05, 0.35, 0.25])
# 计算余弦相似度
def cos_sim(a, b):
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
similarities = [cos_sim(query, doc) for doc in documents]
# 找出最相似的文档索引
best_idx = np.argmax(similarities)
print(f"最相似的文档索引: {best_idx}, 相似度: {similarities[best_idx]:.4f}")这就是推荐系统、搜索引擎的底层原理。
五、数学无处不在:从Java的Random到线性同余生成器
5.1 伪随机数生成器的数学公式
你每天用的 java.util.Random 或 Python 的 random.random(),其核心就是一个线性同余生成器(LCG):
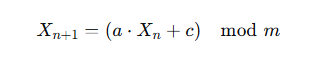
-
X0X0 是种子
-
a,c,ma,c,m 是精心选择的常数
这不就是线性代数中的一次线性变换加上取模运算吗?
5.2 Python模拟Java的Random
python
class SimpleRandom:
def __init__(self, seed=1):
self.state = seed
self.a = 1103515245
self.c = 12345
self.m = 2**31
def next_int(self):
self.state = (self.a * self.state + self.c) % self.m
return self.state
def next_double(self):
return self.next_int() / self.m
rand = SimpleRandom(42)
for _ in range(5):
print(rand.next_double())输出5个"随机"小数。虽然是确定的,但看起来随机。整个现代密码学、蒙特卡洛模拟都依赖这样的数学公式。
六、总结与资源推荐
-
编程 :善用
numpy进行向量/矩阵运算,效率比纯Python高几十倍。 -
数学:推荐阅读《线性代数及其应用》(Lay)、《程序员数学》(中村)。
-
AI方向 :学习
PyTorch/TensorFlow,它们本质就是自动求导的矩阵运算库。 -
向量数据库:了解 Milvus、Faiss、Chroma 等工具。
📌 Evan 说:线性代数不是枯燥的考试,它是你打开AI世界大门的钥匙。花一周时间把矩阵乘法、点积、范数搞透,后面的机器学习会顺畅很多。
❓ 问题:你在学习线性代数时有没有"这有什么用"的困惑?现在有没有某个应用让你突然理解了它的价值?或者你用过向量数据库吗?欢迎在评论区分享,我会选出 3 位同学,送出《线性代数+Python 实战练习册》和《向量数据库入门指南》。
📌 如果本文帮你连接了数学与编程,请点 👍 赞 + 关注 ,本专栏 《大一突围》 持续输出编程与数学结合的硬核干货。
收藏本文,下次写AI代码时回看,理解每一行矩阵运算背后的意义。