一、为什么从深度学习开始重新理解 AI?
很多同学第一次接触人工智能时,会先听到"机器学习""深度学习""大模型""AIGC""RAG"这些词。它们看起来像一堆新概念,其实是有清晰层次的。
可以先用一条路线理解:
人工智能 -> 机器学习 -> 深度学习 -> 神经网络 -> CNN / RNN / Transformer -> BERT / GPT -> 大语言模型 -> Embedding / 向量数据库 / RAG -> AI 应用开发
人工智能是大目标:让机器具备某种智能能力。机器学习是实现 AI 的一种方法:让机器从数据中学习规律。深度学习是机器学习中的重要分支:使用多层神经网络自动学习复杂特征。现在的大语言模型,则是在深度学习、Transformer 架构、大规模数据和强算力共同推动下形成的结果。
深度学习真正厉害的地方,不只是"层数多",而是它可以自动学习数据的多层表示。传统机器学习往往需要人手工设计特征,比如判断一封邮件是不是垃圾邮件,我们可能要手动统计"优惠""中奖""点击链接"等关键词出现次数。深度学习更进一步,它可以在大量数据中自动学习更抽象的特征。图像任务中,前几层可能学到边缘、纹理,后面几层学到形状、部件和整体类别;文本任务中,模型可以逐步学习词语、短语、语法关系和上下文语义。
2015 年 LeCun、Bengio、Hinton 在 Nature 的综述《Deep learning》中总结过深度学习的价值:多层计算模型可以学习多层抽象表示,并推动语音识别、视觉识别、目标检测等领域进步。对于初学者来说,不需要一开始就把论文公式全部吃透,但要先理解一个核心思想:深度学习不是程序员把每条规则写进去,而是让模型通过数据和误差反馈自己调整内部参数。
二、神经网络到底是什么?
神经网络可以理解为一个由很多"小计算单元"组成的函数。这个函数接收输入,经过一层层计算,最后输出预测结果。
最经典的神经网络由三部分组成:
- 输入层:负责接收原始数据。
- 隐藏层:负责提取特征、组合特征、转换特征。
- 输出层:负责给出最终预测。
举一个房价预测的例子。假设我们想根据房屋面积、楼层、房龄、距离地铁距离、所在区域热度预测价格,那么输入层就可以有 5 个节点,每个节点代表一个特征。隐藏层会学习这些特征之间的复杂关系,比如"面积越大通常越贵""离地铁近通常更贵""房龄过老可能折价""热门区域会抬高价格"。输出层最后给出一个数字:预测房价。
再举一个手写数字识别的例子。如果图片大小是 28x28 像素,那么输入层可以有 784 个节点,每个节点对应一个像素灰度值。隐藏层会一步步提取图像特征,输出层有 10 个节点,分别代表数字 0 到 9 的概率。
可以把神经网络想象成一个"流水线":
原始输入 -> 第一层:提取低级特征 -> 第二层:组合成中级特征 -> 第三层:理解高级特征 -> 输出层:给出预测
这个流水线最重要的不是结构本身,而是每条连接上的参数。模型训练的过程,就是不断调整这些参数,让输出越来越接近正确答案。
三、一个神经元是怎么工作的?
神经网络里最基础的单元叫神经元。一个神经元做的事情可以分成三步:
- 接收多个输入。
- 给每个输入乘上权重,再加上偏置。
- 通过激活函数得到输出。
用公式表示就是:
z = x1 * w1 + x2 * w2 + x3 * w3 + b output = activation(z)
这里的 x 是输入特征,w 是权重,b 是偏置,activation 是激活函数。
如果还是觉得抽象,可以用"考试通过预测"来理解。假设影响通过概率的因素有三个:学习时长、刷题数量、睡眠质量。模型可能会学到不同权重:
- 学习时长权重大,说明它对结果影响更大。
- 睡眠质量权重中等,说明也有帮助。
- 某些无关因素权重接近 0,说明模型认为它不重要。
下面用纯 Python 写一个非常简单的神经元:
import math
def sigmoid(z):
return 1 / (1 + math.exp(-z))
def predict_pass(hours, exercises, sleep):
这几个参数是假设值,真实训练时应该由模型从数据中学习得到
w_hours = 0.8
w_exercises = 0.5
w_sleep = 0.3
bias = -6
z = hours * w_hours + exercises * w_exercises + sleep * w_sleep + bias
probability = sigmoid(z)
return probability
result = predict_pass(hours=5, exercises=6, sleep=7)
print(f"通过概率:{result:.2%}")
这个例子里,sigmoid 会把任意数字压缩到 0 到 1 之间,因此很适合表示概率。输出越接近 1,表示越可能通过;越接近 0,表示越不可能通过。
不过要注意,上面的权重是我们手动写的,真正的神经网络不会靠人拍脑袋写权重,而是通过训练数据自动学习权重。
四、激活函数:为什么神经网络不能只做线性计算?
如果神经网络每一层都只是加权求和,那么无论堆多少层,本质上仍然只是一个线性函数。线性函数能解决的问题很有限,比如一条直线能分开的数据还可以处理,但现实世界里很多关系是弯曲的、复杂的、非线性的。
激活函数就是为了给神经网络引入非线性能力。常见激活函数包括:
- Sigmoid:输出范围是 0 到 1,常用于二分类概率输出。
- Tanh:输出范围是 -1 到 1,比 Sigmoid 更居中。
- ReLU:小于 0 输出 0,大于 0 原样输出,训练深层网络时常用。
- Softmax:把多个输出转换成概率分布,常用于多分类任务。
ReLU 的代码非常简单:
def relu(x): return max(0, x) print(relu(-3)) # 0 print(relu(5)) # 5
虽然 ReLU 形式简单,但在深度学习历史中非常重要。它让深层神经网络训练更容易,也能缓解一些梯度消失问题。很多图像识别、文本处理模型的隐藏层都会使用 ReLU 或它的变体。
Softmax 常用于多分类。比如手写数字识别中,模型输出 10 个分数,分别代表 0 到 9。Softmax 会把这些分数转换成概率,所有概率加起来等于 1。

如果输出是 0.27, 0.11, 0.62,说明模型认为第三类最可能。
五、模型是怎么"学会"的?
很多初学者会问:模型到底是怎么学会的?它真的像人一样理解了吗?
从工程角度看,模型学习可以拆成四步:
- 前向传播:输入数据经过网络,一层层算出预测结果。
- 计算损失:把预测结果和真实答案比较,得到误差。
- 反向传播:根据误差计算每个参数应该往哪个方向调整。
- 参数更新:使用优化器调整权重和偏置。
这四步会重复很多轮。每重复一轮,模型就会尝试让损失更小。
举个例子,模型预测一套房子价格是 300 万,真实价格是 350 万,那么误差就是 50 万。模型会根据这个误差反推:是不是面积权重太低了?是不是地段权重不够?是不是偏置需要调整?下一次预测时,它就会稍微修正参数。
这个过程和学生做题有点像。学生先答题,老师批改,学生发现错在哪里,下次调整解题方法。神经网络也是这样,只不过它调整的是大量数字参数。
六、损失函数:模型错得有多离谱?
损失函数用来衡量预测值和真实值之间的差距。损失越大,说明模型错得越多;损失越小,说明模型越接近正确答案。
不同任务常用不同损失函数:
- 回归任务:常用均方误差 MSE。
- 二分类任务:常用二元交叉熵。
- 多分类任务:常用交叉熵损失。
以房价预测为例,预测值和真实值都是数字,可以用均方误差:
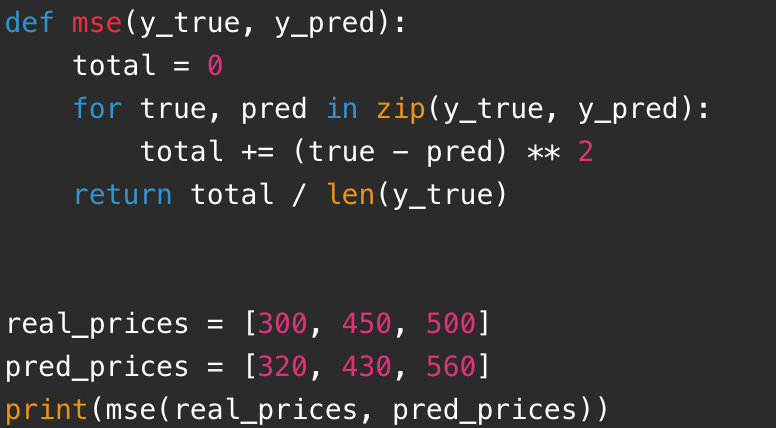
为什么要平方?一个原因是让正负误差都变成正数,另一个原因是让大误差受到更大惩罚。预测错 100 万比错 10 万严重得多,平方会放大这种差异。
分类任务中,交叉熵会惩罚"自信但错误"的预测。比如真实类别是数字 7,模型却非常自信地认为是数字 1,那么损失会很大;如果模型只是有点不确定,损失相对没那么夸张。
七、反向传播和梯度下降:神经网络训练的发动机
反向传播听起来很难,其实可以先理解成一句话:它负责告诉每个参数应该怎么改,才能让损失变小。
梯度下降则是具体的更新方法。梯度表示损失函数在当前参数位置上升最快的方向。既然我们想让损失下降,就沿着梯度的反方向走一小步。
这里的"一小步"由学习率控制:
- 学习率太大:每次走太远,可能越过最低点,训练不稳定。
- 学习率太小:每次走太慢,训练时间很长。
- 学习率合适:损失稳定下降,模型逐渐变好。
可以用爬山的反向过程理解。我们站在山坡上,目标是走到山谷最低处。每次观察当前位置哪个方向更低,就往那里走一小步。走太大容易错过山谷,走太小又太慢。
在真实深度学习框架中,我们通常不用手写反向传播。PyTorch、TensorFlow 都提供了自动求导能力。PyTorch 官方教程中也强调,神经网络由层或模块组成,torch.nn 提供了构建网络所需的组件;训练时可以通过自动微分计算梯度,再使用优化器更新参数。
八、训练神经网络的一次完整流程
把前面的内容合起来,一个神经网络训练流程大致如下:
1. 准备数据 2. 数据清洗和预处理 3. 划分训练集、验证集、测试集 4. 定义模型结构 5. 选择损失函数 6. 选择优化器 7. 前向传播得到预测 8. 计算损失 9. 反向传播计算梯度 10. 更新参数 11. 在验证集上观察效果 12. 调整模型结构和超参数 13. 在测试集上做最终评估 14. 保存模型并部署
这里有几个常见术语:
- epoch:把训练集完整训练一遍叫一个 epoch。
- batch:每次送入模型的一小批数据。
- batch size:每批数据数量。
- learning rate:学习率,控制参数更新步子大小。
- optimizer:优化器,例如 SGD、Adam。
- validation set:验证集,用来调参。
- test set:测试集,用来最终评估。
为什么要划分验证集和测试集?因为模型不能只在训练数据上表现好,还要在没见过的新数据上表现好。只看训练集分数,很容易被过拟合骗到。
九、案例一:用 sklearn 训练一个简单神经网络识别手写数字
下面这个案例使用 sklearn 自带的手写数字数据集。每张图片是 8x8 像素,目标是识别数字 0 到 9。这个数据集比真实项目小很多,但非常适合初学者理解完整流程。
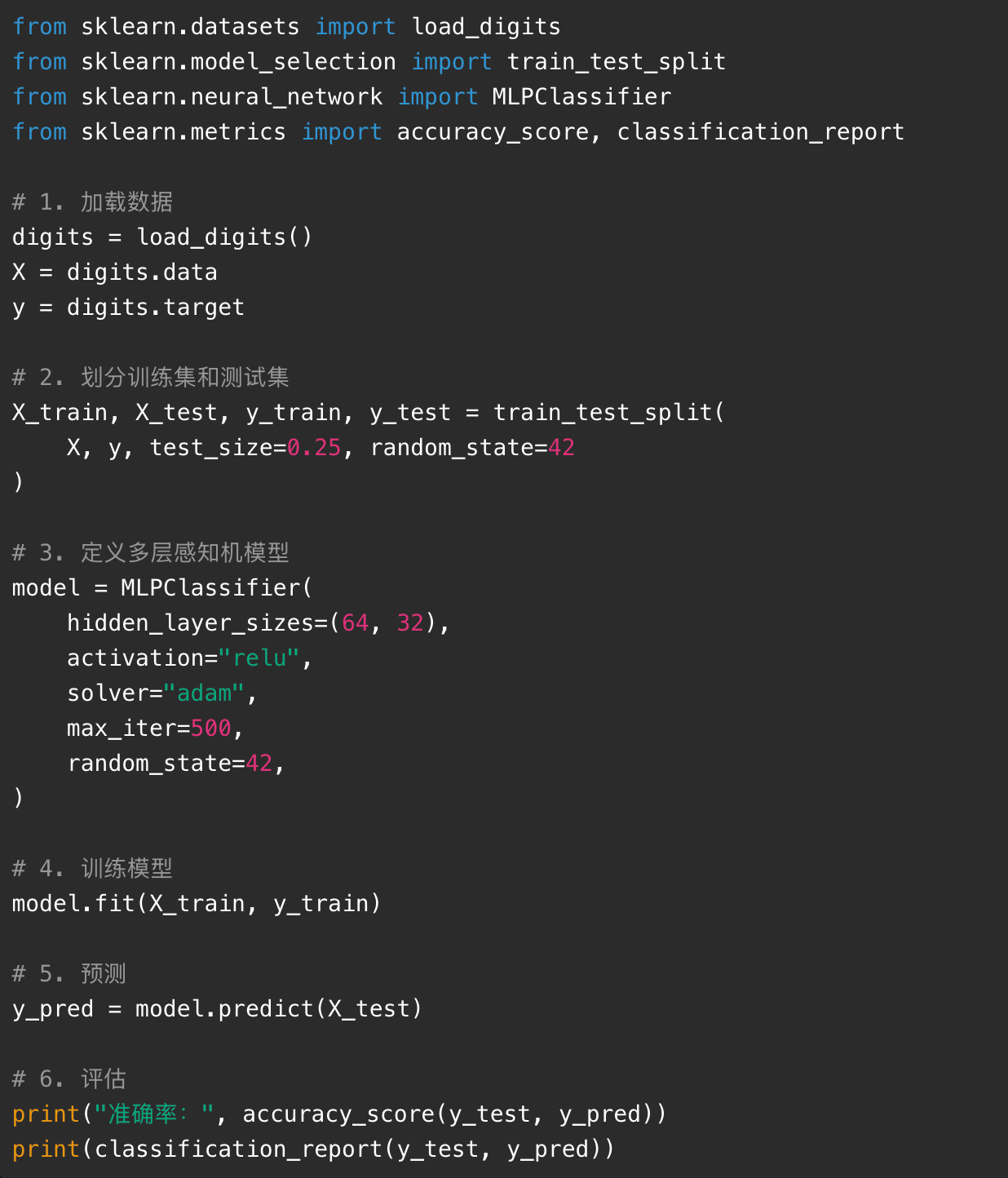
这里的 hidden_layer_sizes=(64, 32) 表示隐藏层有两层,第一层 64 个神经元,第二层 32 个神经元。activation="relu" 表示隐藏层使用 ReLU 激活函数。solver="adam" 表示使用 Adam 优化器。
这个模型虽然不算真正复杂的深度神经网络,但已经具备神经网络训练的基本流程:输入数据、隐藏层计算、输出预测、损失优化、迭代训练。
如果你刚开始学习,不要急着上来就训练大模型。先把这种小案例跑通,理解数据形状、训练集测试集、准确率、模型参数,后面再学 CNN、Transformer 会轻松很多。
十、CNN:为什么卷积神经网络适合图像?
CNN 的全称是 Convolutional Neural Network,中文叫卷积神经网络。它在图像处理领域非常经典,比如手写数字识别、人脸识别、医学影像识别、工业缺陷检测等。
为什么普通神经网络处理图像不够好?假设一张图片是 224x224 像素,并且有 RGB 三个通道,那么输入特征数量就是:
224 * 224 * 3 = 150528
如果直接把这些像素全部展平成一维向量,再连接到全连接层,参数量会非常大,而且会破坏图像的空间结构。图像里相邻像素之间有关系,比如边缘、角点、纹理都依赖局部区域。CNN 正是利用了这种局部结构。
CNN 有几个核心概念:
- 卷积核:一个小窗口,比如 3x3 或 5x5,用来扫描图像。
- 卷积操作:用卷积核在图片上滑动,提取局部特征。
- 特征图:卷积后得到的新图,表示某种特征出现的位置和强度。
- 池化:降低特征图尺寸,减少计算量,并增强一定的平移鲁棒性。
- 全连接层:在卷积提取特征后,做最终分类。
可以把 CNN 理解成一个分层识别系统:
原始像素 -> 第一层卷积:识别简单边缘 -> 第二层卷积:识别局部形状 -> 第三层卷积:识别复杂结构 -> 分类层:判断图片类别
TensorFlow 官方 CNN 教程中也使用了"卷积层 + 池化层 + 全连接层"的典型结构来做图像分类。对于小白来说,先记住一句话就够了:CNN 擅长从图片中自动提取局部到整体的层次特征。
十一、案例二:用 Keras 写一个 CNN 图片分类模型
下面是一个典型 CNN 模型结构示例。它不依赖你手写卷积公式,而是使用 Keras 提供的层。
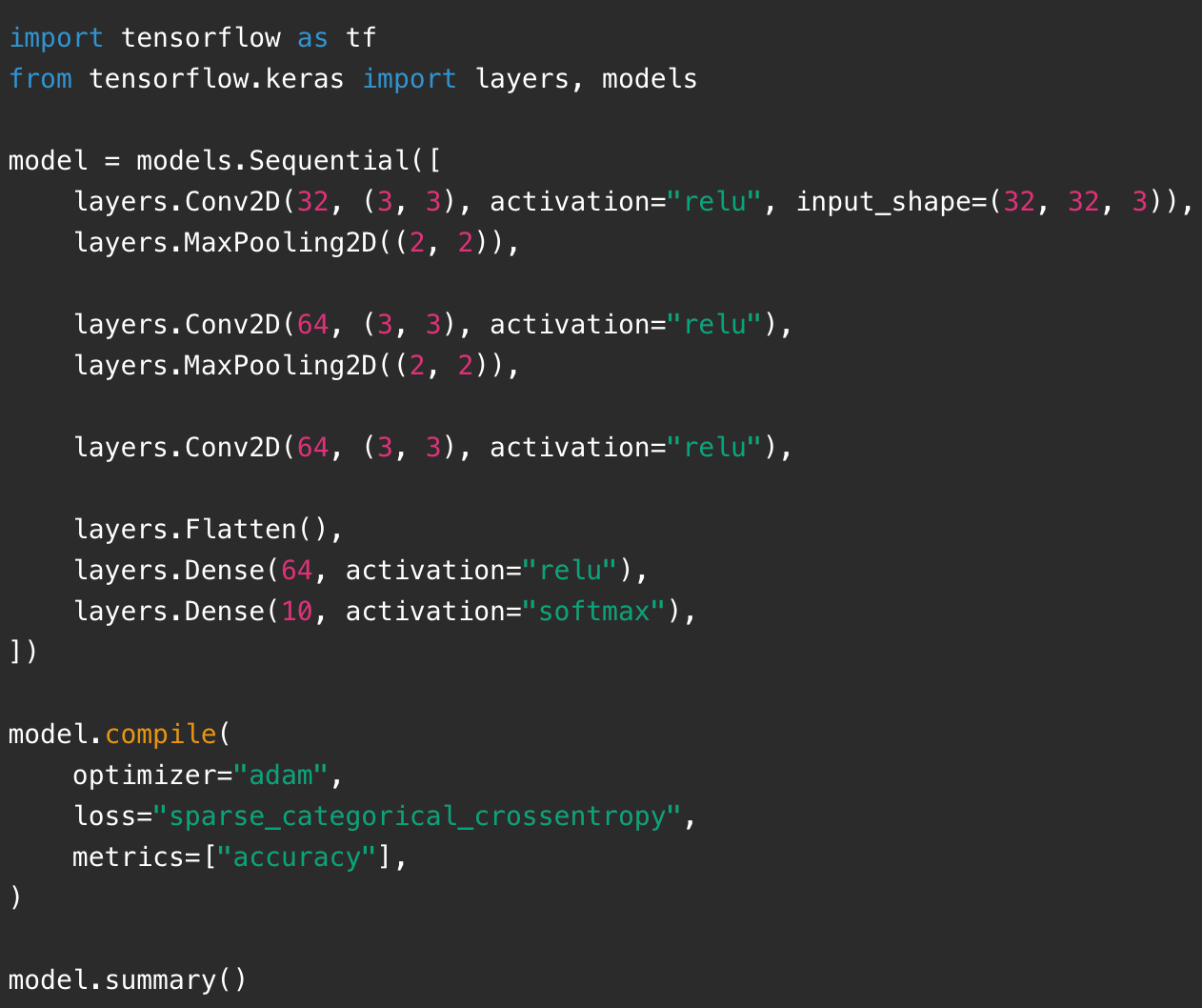
这段代码可以拆开理解:
- Conv2D(32, (3, 3)):使用 32 个 3x3 的卷积核提取特征。
- MaxPooling2D((2, 2)):对特征图降采样,让尺寸变小。
- Flatten():把多维特征图展平成一维向量。
- Dense(64):全连接层,进一步组合特征。
- Dense(10, softmax):输出 10 个类别的概率。
如果把它用于 CIFAR-10 数据集,那么 10 个类别就对应 10 种图片类别。真实项目中,图片数据需要进行归一化、数据增强、训练集验证集划分,还要观察训练曲线,防止过拟合。
CNN 的优势很明显:
- 比全连接网络更适合图像结构。
- 参数共享减少参数量。
- 局部感受野适合提取图像局部特征。
- 多层卷积可以形成从低级到高级的特征层次。
但 CNN 也不是万能的。对于长文本、长序列、复杂上下文关系,CNN 并不是最自然的选择,这就引出了 RNN 和 Transformer。
十二、RNN:处理序列数据的早期主力
RNN 的全称是 Recurrent Neural Network,中文叫循环神经网络。它适合处理序列数据,例如:
- 文本:一句话是词语序列。
- 语音:语音信号是时间序列。
- 股票价格:每天价格组成时间序列。
- 用户行为:浏览、点击、收藏、购买构成行为序列。
普通神经网络通常一次处理一个固定输入,而 RNN 会把前面的状态传到后面。也就是说,它在处理当前输入时,会参考之前的信息。
可以这样理解:
第一个词 -> RNN -> 状态1 第二个词 + 状态1 -> RNN -> 状态2 第三个词 + 状态2 -> RNN -> 状态3
假设句子是"我今天很开心",模型处理"开心"时,前面的"我今天很"会影响它对整句话的理解。
RNN 的问题是:当序列很长时,早期信息很难一直传到后面,容易出现梯度消失或梯度爆炸。为了解决这个问题,人们提出了 LSTM 和 GRU。
LSTM 引入了门控机制,决定哪些信息保留、哪些信息遗忘、哪些新信息写入。GRU 结构比 LSTM 简化一些,也能处理长期依赖问题。它们在机器翻译、语音识别、时间序列预测中曾经非常常用。
但 RNN 有一个天然限制:它通常按顺序一步步处理序列,不容易并行。文本越长,训练越慢。Transformer 正是为了解决这类问题而崛起。
十三、Transformer:大模型时代的核心架构
Transformer 是现代大语言模型的核心架构。2017 年论文《Attention Is All You Need》提出,模型可以完全基于注意力机制处理序列,不再依赖 RNN 的循环结构。
Transformer 重要在哪里?
- 它可以并行处理序列中的多个位置。
- 它更擅长捕捉长距离依赖关系。
- 它可以扩展到很大的模型规模。
- 它成为 BERT、GPT 等模型的基础。
理解 Transformer,重点先抓住四个词:
- Self-Attention:自注意力。
- Multi-Head Attention:多头注意力。
- Positional Encoding:位置编码。
- Feed Forward Network:前馈网络。
1. 自注意力:一句话里每个词都看看其他词
自注意力的核心思想是:当模型理解一个词时,不只看这个词本身,还要看它和句子中其他词的关系。
例如句子:
用户提交订单后没有收到物流信息,他希望客服帮忙查询。
模型理解"他"时,需要知道"他"指的是"用户"。理解"查询"时,需要关注"订单""物流信息""客服"等词。自注意力就是让模型为不同词分配不同关注度。
在注意力机制里,有三个重要向量:
- Query:我当前想查什么。
- Key:每个词能提供什么线索。
- Value:每个词真正携带的信息。
通俗理解就是:当前词拿着 Query 去和其他词的 Key 做匹配,匹配度高的词就获得更高权重,然后把对应 Value 加权汇总,得到新的表示。
2. 多头注意力:从多个角度理解一句话
一句话的关系不止一种。模型可能需要同时关注:
- 主谓宾关系。
- 指代关系。
- 时间关系。
- 因果关系。
- 情感倾向。
- 领域关键词。
多头注意力就是让模型用多个"注意力头"从不同角度观察文本。一个头可能更关注语法,一个头可能更关注实体关系,另一个头可能更关注上下文指代。最后把多个头的结果拼接起来,得到更丰富的语义表示。
3. 位置编码:告诉模型词语顺序
Transformer 不像 RNN 那样天然按顺序处理文本,所以它需要额外知道词语位置。位置编码就是给每个词加入位置信息。
比如:
我喜欢学习 AI AI 喜欢学习我
这两句话包含的词很相似,但顺序不同,意思完全不同。位置编码让模型知道词的先后顺序,避免只看到一袋词。
4. 前馈网络:对每个位置的表示继续加工
注意力层负责汇总上下文信息,前馈网络负责进一步变换每个位置的表示。可以把它理解成"每个词拿到上下文信息后,再经过一小段神经网络加工"。
一个 Transformer Block 通常包含:
输入 -> 多头自注意力 -> 残差连接和归一化 -> 前馈网络 -> 残差连接和归一化 -> 输出
多个 Block 堆叠起来,就形成了更深、更强的模型。
十四、BERT:更擅长理解文本的模型
BERT 的全称是 Bidirectional Encoder Representations from Transformers。它基于 Transformer 的 Encoder 部分,特点是双向理解上下文。
什么叫双向?过去很多语言模型是从左到右读文本,只能根据前文预测后文。BERT 在理解一个词时,可以同时看左边和右边的上下文。
比如:
我用银行卡去银行办理业务。 河边有一家银行。
"银行"在两句话里都出现了,但含义不同。BERT 通过上下文可以判断它是金融机构还是河岸区域。它的优势不是单独记住某个词,而是根据上下文理解词义。
BERT 经典预训练任务包括:
- MLM:Masked Language Model,遮蔽语言模型。
- NSP:Next Sentence Prediction,下一句预测。
MLM 的思路是把句子中的某些词遮住,让模型预测被遮住的词。例如:
我今天去 [MASK] 办理银行卡。
模型要根据上下文预测 MASK 可能是"银行"。这个任务能迫使模型学习上下文语义。
BERT 常见应用包括:
- 文本分类。
- 情感分析。
- 命名实体识别。
- 问答系统。
- 句子相似度。
- 搜索排序。
如果业务重点是"理解文本",例如判断用户评论是好评还是差评、判断两句话是否表达同一个意思、从文本中抽取姓名和地址,BERT 类模型往往很有用。
十五、GPT:更擅长生成文本的模型
GPT 的全称是 Generative Pre-trained Transformer,中文通常叫生成式预训练 Transformer。它更擅长根据上文继续生成下文。
GPT 的基本训练目标可以理解为:
给定前面的词,预测下一个词。
比如:
深度学习是一种使用多层神经网络从数据中学习特征的
模型可能继续生成"机器学习方法"。这个过程看起来简单,但当模型在海量文本上训练后,它会学到非常丰富的语言模式、知识关联、推理样式和表达方式。
GPT 能做很多事情:
- 回答问题。
- 生成文章。
- 翻译文本。
- 总结材料。
- 改写文案。
- 生成代码。
- 解释报错。
- 做多轮对话。
GPT 和 BERT 的区别可以简单记:
BERT:偏理解,常用于分类、抽取、匹配。 GPT:偏生成,常用于问答、写作、对话、代码。
当然,现在很多大模型已经不再只是单纯的"生成模型"或"理解模型",它们通常具备更综合的能力。但从学习角度看,先理解 BERT 和 GPT 的差异,可以帮助我们建立清晰框架。
十六、大语言模型为什么看起来这么聪明?
大语言模型的能力来自多个因素叠加:
- Transformer 架构能高效建模长文本关系。
- 参数规模足够大,模型容量更强。
- 训练数据覆盖范围广。
- 预训练让模型掌握通用语言能力。
- 指令微调让模型更会按照人类要求回答。
- 人类反馈或偏好优化让模型更符合对话习惯。
- 工具调用、检索增强、多模态能力扩展了模型边界。
这里要纠正一个误区:大模型不是数据库。它不是把训练数据逐字存进去,然后原样查出来。它更像是学习了语言和知识之间的统计关系,能够根据上下文生成高概率、合理的回答。
这也解释了为什么大模型有时会"胡说"。如果问题需要最新数据、企业内部资料或非常精确的事实,而模型上下文里没有这些信息,它可能会根据已有模式生成看似合理但不准确的内容。
所以真实应用中,不能只靠大模型本身,还需要结合:
- Prompt 设计。
- 函数调用或工具调用。
- 外部数据库。
- 搜索引擎。
- 向量数据库。
- RAG 检索增强生成。
- 人工审核和权限控制。
十七、Prompt:和大模型沟通的输入说明书
Prompt 可以理解为你给模型的任务说明。一个好的 Prompt 通常包含:
- 角色:你希望模型扮演谁。
- 背景:模型需要知道什么上下文。
- 任务:模型要完成什么。
- 约束:不能做什么,格式是什么。
- 示例:希望模型模仿什么风格。
- 输出格式:用 Markdown、JSON、表格还是普通文本。
例如一个差的 Prompt:
写个介绍。
模型不知道介绍什么、写给谁看、写多长、什么风格。
一个更好的 Prompt:
你是一名 Python 讲师。请用小白能看懂的语言,写一段 300 字左右的介绍,解释什么是神经网络。要求包含输入层、隐藏层、输出层三个概念,并举一个房价预测的例子。
这个 Prompt 明确了角色、受众、长度、主题、概念和案例,模型输出通常会更稳定。
在生产环境中,Prompt 不是随便写一句话,而是应用逻辑的一部分。客服系统、文档总结、代码助手、知识库问答,都需要精心设计 Prompt。
十八、调用大模型 API:一个智能客服案例
现在开发大模型应用,常见方式是通过 API 调用模型。下面以 OpenAI Responses API 风格写一个智能客服示例。
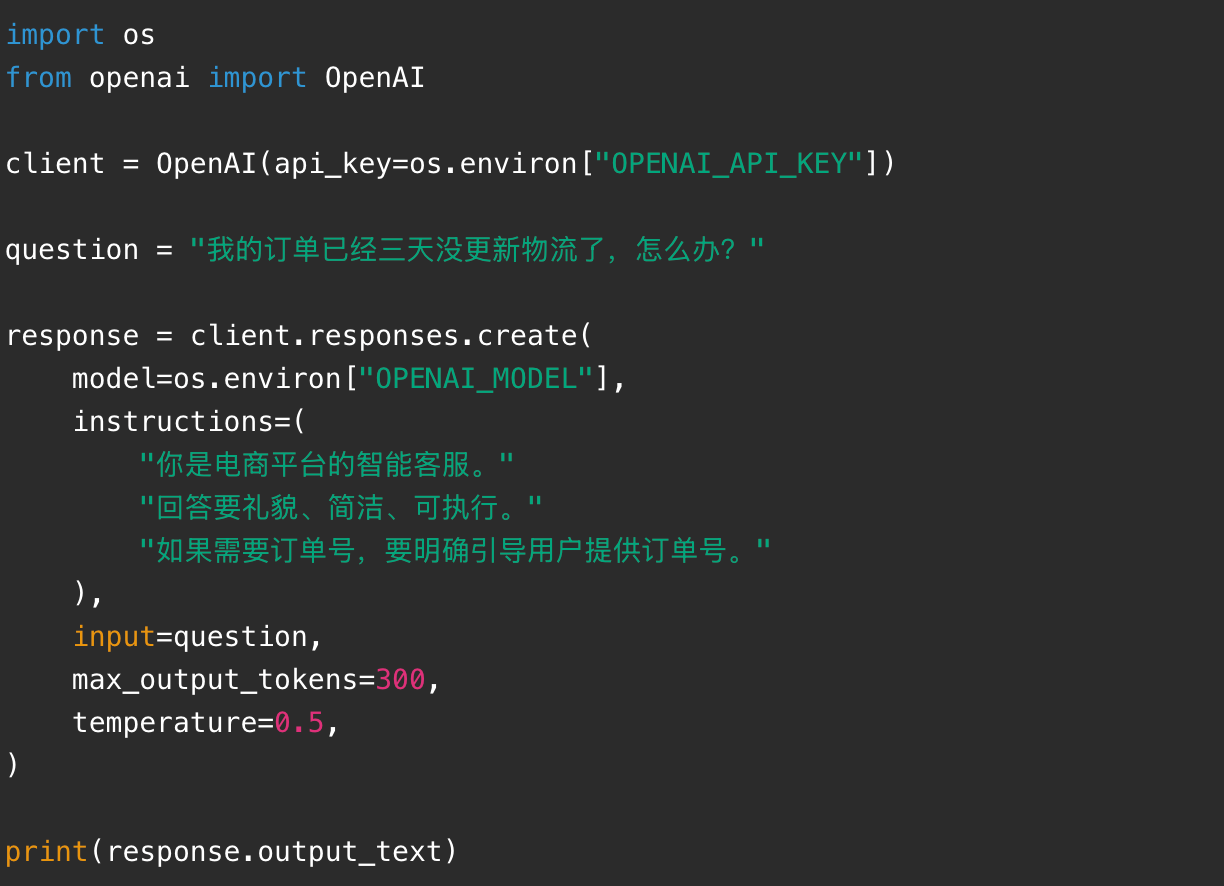
参数解释:
- model:使用的模型名称。
- instructions:系统级指令,告诉模型角色和规则。
- input:用户输入。
- max_output_tokens:限制输出长度。
- temperature:控制随机性,客服场景一般不要太高。
如果是客服、合同审查、知识库问答这类场景,通常希望模型稳定、准确,所以 temperature 可以低一些。如果是广告文案、故事创作、头脑风暴,可以适当提高随机性。
十九、Embedding:把文本变成向量
如果说 GPT 负责"生成",Embedding 就负责"表示"。Embedding 的作用是把文本、图片、音频等数据转换成向量,也就是一串数字。
为什么要把文本变成向量?因为计算机很难直接理解自然语言,但很擅长处理数字。把文本转成向量后,就可以计算相似度。
比如下面几句话:
订单物流在哪里查看? 我的快递到哪里了? 如何申请开发票? 怎么退货退款?
前两句话表达的意思比较接近,向量距离应该更近;后两句话和物流查询关系不大,向量距离应该更远。
OpenAI Embeddings 文档中也把 Embedding 解释为对文本等对象的向量表示,它可用于搜索、聚类、推荐、异常检测、分类等场景。
Embedding 的常见应用:
- 语义搜索:不只按关键词匹配,而是按意思匹配。
- 文本聚类:把相似文本自动分组。
- 推荐系统:根据相似向量推荐内容。
- 知识库问答:先找相关资料,再让大模型回答。
- 去重检测:判断两段文本是否表达相似意思。
二十、案例三:不用大模型,先用纯 Python 理解向量相似度
真实 Embedding 需要调用模型生成高维向量。为了让小白先理解原理,我们先用字频向量做一个简化版语义检索。
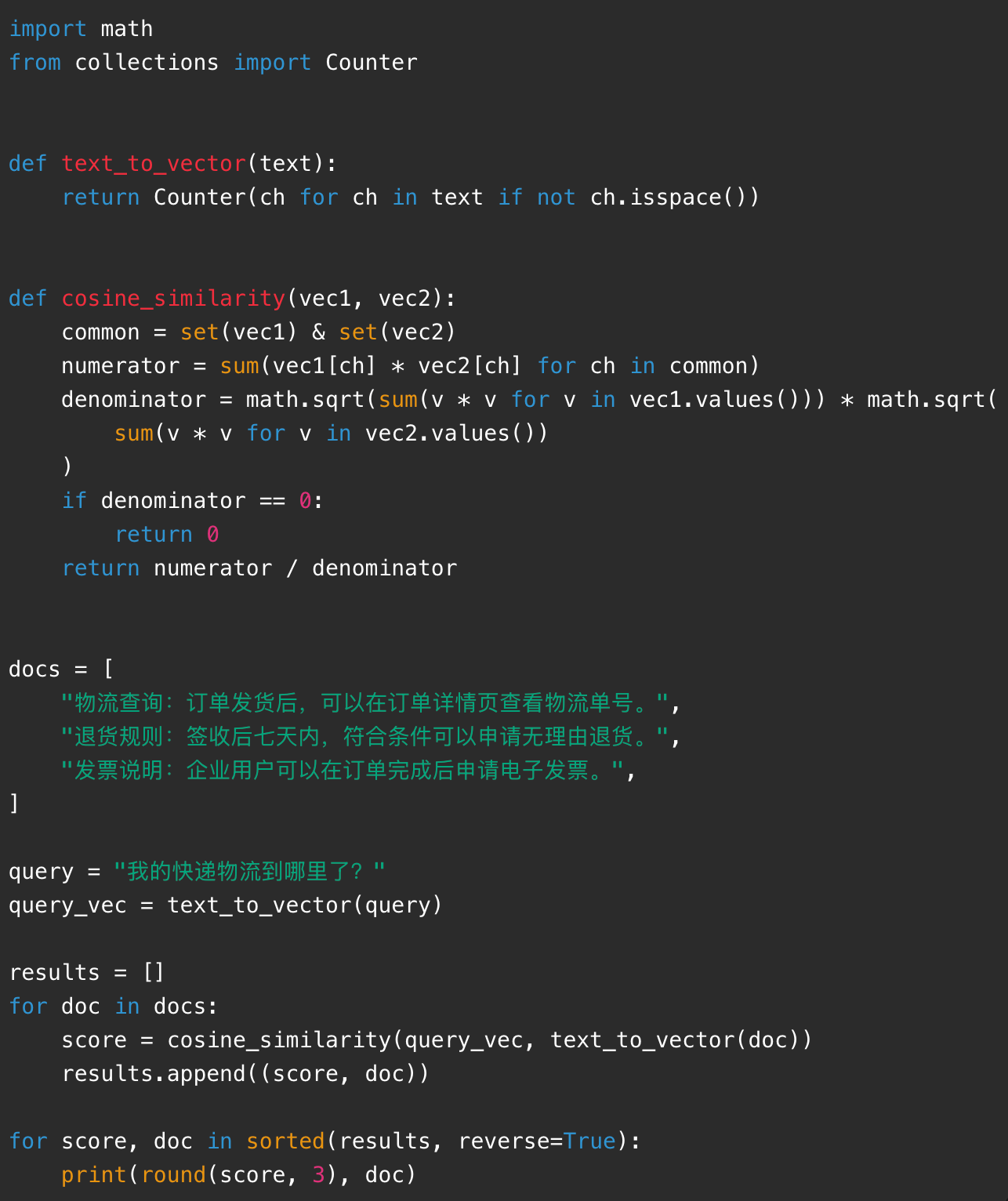
这个例子虽然简单,但核心思路和真实向量检索很像:
文本 -> 向量 -> 计算相似度 -> 找最接近的文档
区别在于,真实 Embedding 不是简单统计字频,而是由模型生成语义向量。它能理解更多语义关系,比如"快递"和"物流"接近,"退款"和"退货"接近。
二十一、向量数据库:为什么不能只用普通数据库?
普通数据库擅长精确查询。例如:
select * from orders where order_id = 1001;
但向量检索的问题是:
请帮我找出和这句话语义最接近的 5 段文档。
这不是传统的等值查询,而是相似度查询。向量通常有几百维、上千维甚至更多,如果数据量很大,用普通方式逐条计算相似度会很慢。向量数据库就是为这种场景设计的。
向量数据库通常提供:
- 向量存储。
- 相似度检索。
- 索引加速。
- 元数据过滤。
- 动态插入和更新。
- 分布式扩展。
Milvus 文档中介绍,Milvus 是面向向量相似度搜索和 AI 应用的开源向量数据库,适合管理海量非结构化数据的向量表示。类似工具还有 FAISS、pgvector、Weaviate、Qdrant 等。
常见业务场景:
- 企业知识库问答。
- 电商相似商品搜索。
- 以图搜图。
- 推荐系统召回。
- 文档去重。
- 客服语义匹配。
二十二、RAG:让大模型先查资料再回答
RAG 的全称是 Retrieval-Augmented Generation,中文常叫检索增强生成。它解决的是大模型应用中的一个核心问题:模型本身不知道你的私有资料,也不一定知道最新信息。
一个典型 RAG 系统流程如下:
离线阶段: 1. 收集文档:PDF、Word、网页、数据库记录 2. 文档清洗:去掉无用格式、广告、乱码 3. 文档切分:把长文档切成多个小段 4. 生成 Embedding:每段文本转成向量 5. 写入向量数据库:保存文本、向量、来源、标题等元数据 在线阶段: 1. 用户提问 2. 把问题转成向量 3. 到向量数据库中检索相似文档片段 4. 把检索结果和用户问题一起放进 Prompt 5. 大模型基于资料生成答案 6. 返回答案,并可附带引用来源
RAG 的关键价值:
- 让模型基于企业资料回答。
- 减少胡编乱造。
- 更新知识时不一定要重新训练模型。
- 可以给出引用来源,方便审核。
- 适合客服、法务、培训、运维、内部知识库等场景。
一个简单的 RAG Prompt 可能长这样:
你是企业知识库助手。请只根据下面的资料回答用户问题。 如果资料中没有答案,请回答"资料中没有找到相关信息",不要编造。 资料: {retrieved_context} 用户问题: {user_question}
这段 Prompt 的重点是限制模型只基于检索资料回答。真实项目中还会加入更多规则,比如回答格式、引用编号、权限控制和敏感信息处理。
二十三、案例四:用伪代码理解一个 RAG 知识库
下面是一段接近真实项目逻辑的伪代码。它省略了具体向量数据库 SDK,但展示了完整链路。
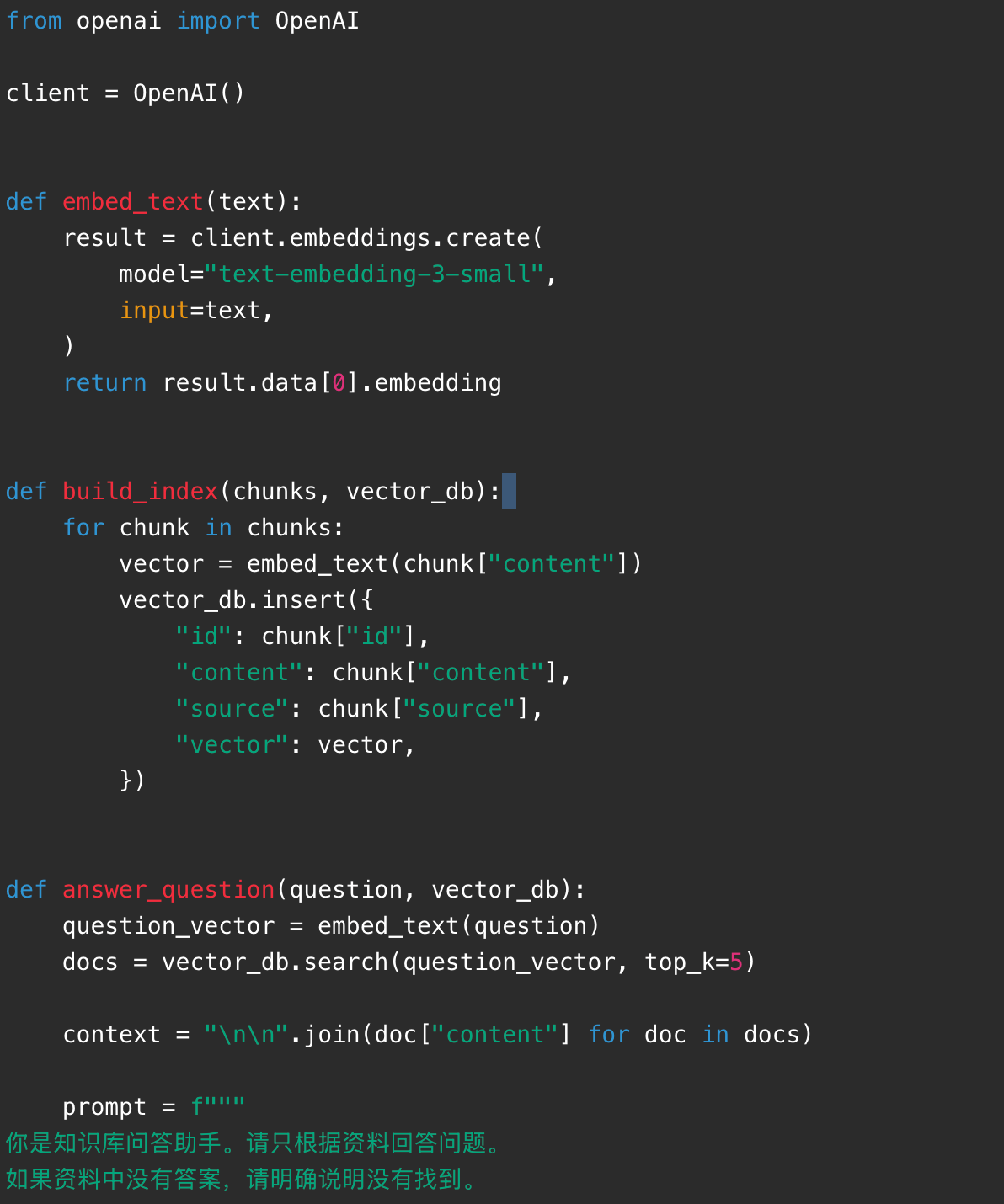
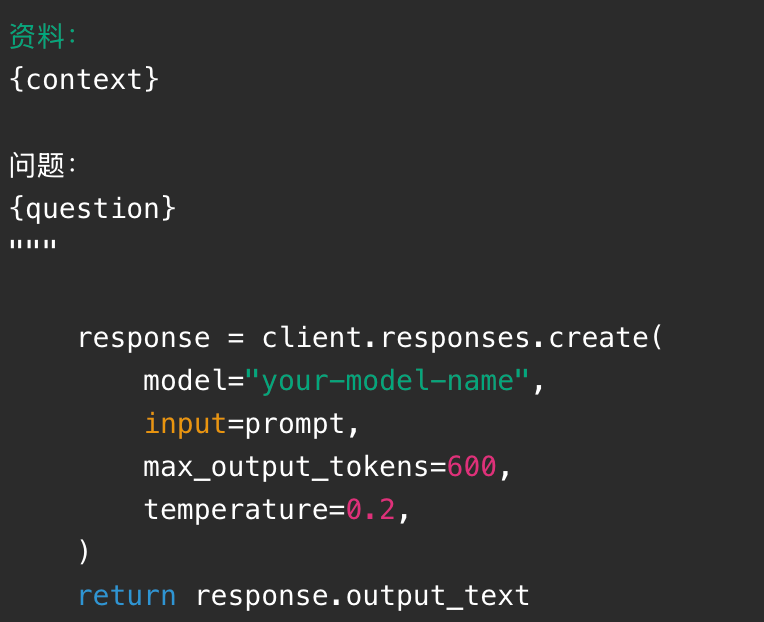
真实项目中需要注意:
- 文档切分不能太长,也不能太短。
- 检索结果要去重。
- 要保存文档来源,方便引用。
- 用户权限要过滤,不能检索无权查看的资料。
- 对模型回答做安全和事实性检查。
- 对高风险场景加人工审核。
RAG 不是简单地"向量数据库 + 大模型"拼起来就完事。好用的 RAG 系统需要处理文档质量、切分策略、Embedding 模型选择、检索召回、重排序、Prompt 设计、答案评估等很多细节。
二十四、微调、Prompt、RAG:什么时候用哪个?
很多人一听到模型效果不好,就想"是不是要微调"。其实不一定。
可以先按这个顺序判断:
问题是输出格式不好 -> 优先改 Prompt 问题是缺少企业知识 -> 优先做 RAG 问题是固定任务风格不稳定 -> 考虑少量样例或微调 问题是领域能力长期不足 -> 再考虑更系统的微调或模型训练
Prompt 适合解决:
- 输出格式。
- 角色语气。
- 回答步骤。
- 约束规则。
- 少量示例模仿。
RAG 适合解决:
- 企业内部文档问答。
- 最新知识更新。
- 大量资料检索。
- 需要引用来源。
- 不想重新训练模型。
微调适合解决:
- 固定任务模式。
- 特定输出风格。
- 大量标注样本可用。
- 需要模型长期学习某种行为。
对初学者来说,建议先学 Prompt 和 RAG,因为它们更接近应用开发,也更容易落地。微调需要数据、算力、评估体系和成本控制,不适合一开始就硬上。
二十五、从神经网络到大模型的完整类比
为了把全文串起来,我们用一个企业智能客服系统做类比。
早期规则系统:
如果用户说"退货",就回复退货流程。 如果用户说"发票",就回复发票流程。
问题是用户表达方式很多,规则写不完。
传统机器学习:
收集用户问题 -> 标注意图 -> 训练分类器 -> 判断用户想问物流、退货还是发票
比规则强,但依赖特征和标注。
深度学习:
用神经网络自动学习文本特征 -> 识别用户意图
减少手工特征工程。
BERT 类模型:
更好理解用户句子语义 -> 判断意图、抽取订单号、识别关键实体
适合理解任务。
GPT 类模型:
根据用户问题和上下文 -> 生成自然语言回复
适合对话和生成。
Embedding + 向量数据库:
把知识库文档转成向量 -> 根据用户问题检索相关资料
适合找资料。
RAG:
先检索企业资料 -> 再让大模型基于资料回答
这是现在企业知识库问答的常见路线。
最终,一个可落地的智能客服系统可能是:
用户问题 -> 意图识别 -> 权限判断 -> 向量检索相关文档 -> 大模型生成回答 -> 安全审核 -> 返回用户
这就是从神经网络走向大模型应用开发的一条真实路径。
二十六、学习建议:小白应该怎么学?
如果你是 Python 初学者,不建议一上来就啃大模型源码。更稳的路线是:
第一阶段:基础机器学习
- 学会 numpy、pandas、matplotlib。
- 会用 sklearn 跑分类、回归、聚类。
- 理解训练集、测试集、准确率、召回率、过拟合。
第二阶段:神经网络基础
- 理解神经元、权重、偏置。
- 理解激活函数、损失函数。
- 理解前向传播、反向传播、梯度下降。
- 跑通 MLP 手写数字识别案例。
第三阶段:深度学习框架
- 学 PyTorch 或 TensorFlow 其中一个。
- 跑通图片分类 CNN。
- 理解数据加载、模型定义、训练循环、保存模型。
第四阶段:NLP 和 Transformer
- 理解词向量、Token、Attention。
- 理解 Transformer 的 Encoder 和 Decoder。
- 区分 BERT 和 GPT。
第五阶段:大模型应用
- 学会调用大模型 API。
- 学会写 Prompt。
- 学会 Embedding。
- 学会使用向量数据库。
- 做一个 RAG 知识库问答 Demo。
这条路线不要求一步登天,但每一步都能做出可运行的小项目。学习 AI 最怕只看概念不写代码,也怕一上来就陷进复杂论文。对小白来说,"概念 + 小案例 + 项目串联"是最舒服的节奏。
二十七、常见误区
误区一:深度学习就是层数越多越好。
层数更多不一定更好。模型太小可能欠拟合,模型太大可能过拟合,也可能训练成本太高。结构要和任务、数据量、算力匹配。
误区二:准确率高就说明模型好。
如果数据类别不平衡,准确率可能骗人。比如 1000 条数据里 990 条是正常样本,模型全部预测正常,也有 99% 准确率,但它完全识别不出异常样本。
误区三:大模型什么都知道。
大模型不等于数据库。它可能不知道最新信息,也不知道企业内部资料,还可能生成错误内容。需要 RAG、工具调用、人工审核来提高可靠性。
误区四:RAG 一定能解决幻觉。
RAG 能显著改善事实性,但不是万能。检索不到、检索错、资料本身错、Prompt 约束弱,都可能导致错误回答。
误区五:学 AI 必须先精通所有数学。
数学很重要,但小白可以先通过案例建立直觉,再逐步补线性代数、概率论、微积分和优化方法。先跑起来,再深入理解,往往更容易坚持。
二十八、项目实战:设计一个迷你 RAG 客服知识库
前面讲了很多概念,现在把它们落到一个小项目里。假设我们要做一个"电商客服知识库助手",用户可以问物流、退货、发票、售后等问题,系统根据公司已有规则文档回答,而不是让大模型凭空发挥。
这个项目不一定一开始就接入复杂框架,可以先用最小版本理解整体链路:
准备知识库文本 -> 文本切分 -> 生成向量 -> 存储向量和原文 -> 用户提问 -> 检索相关文本 -> 拼接 Prompt -> 大模型生成答案
第一步是准备知识库。比如我们有三段资料:
documents = [ { "title": "物流查询规则", "content": "订单发货后,用户可以在订单详情页查看物流单号。如果物流超过三天没有更新,可以联系人工客服核实快递状态。" }, { "title": "退货规则", "content": "商品签收后七天内,符合无理由退货条件的订单可以申请退货。定制商品、生鲜商品和已拆封影响二次销售的商品不支持无理由退货。" }, { "title": "发票规则", "content": "订单完成后,用户可以在发票中心申请电子发票。企业用户需要填写正确的抬头和税号。" }, ]
第二步是文本切分。真实项目中文档可能很长,不能整篇塞给模型。切分的目的,是让检索更精准。比如一份售后手册有 5 万字,如果用户只问"发票怎么开",我们只需要找发票相关片段,不需要把整本手册都发给模型。
一个最简单的切分函数可以这样写:
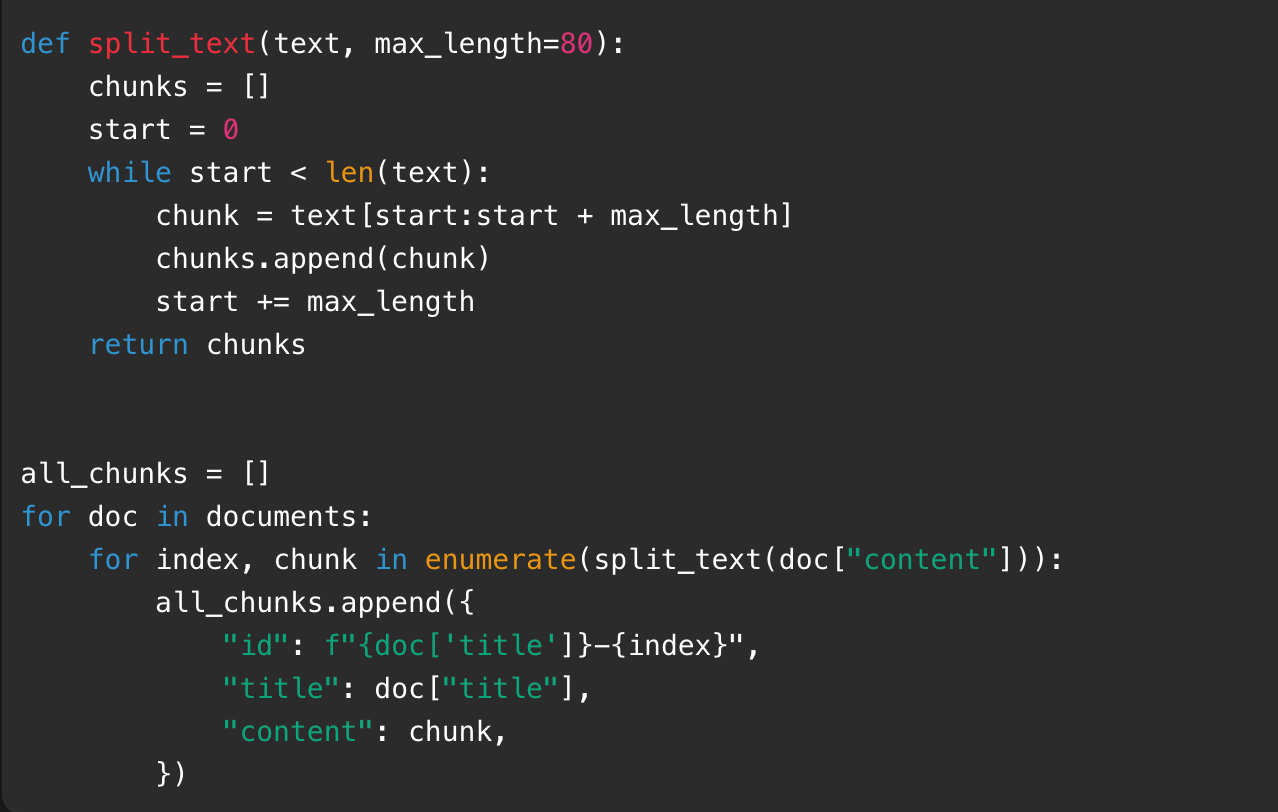
这个切分方式很粗糙,但适合演示。真实项目中会按标题、段落、句子边界切分,还会设置重叠窗口。所谓重叠窗口,就是相邻片段之间保留一部分重复内容,避免一句重要信息被硬切成两半。
第三步是生成向量。真实系统会调用 embedding 模型,这里先写成伪代码:
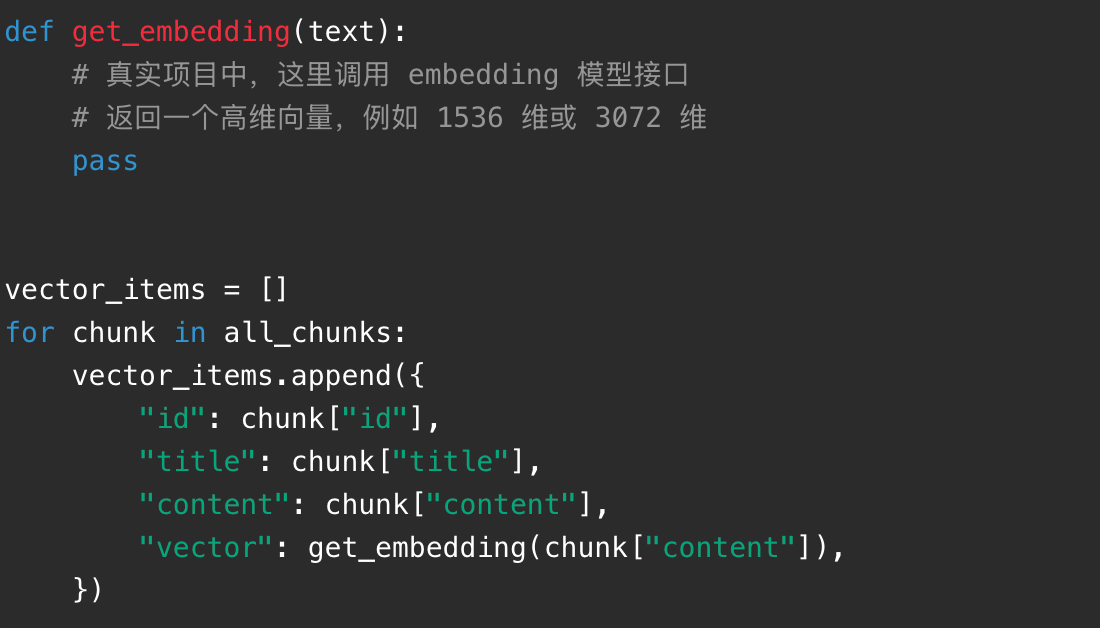
第四步是向量检索。用户提问后,也要把问题转成向量,然后找最相似的文本片段:

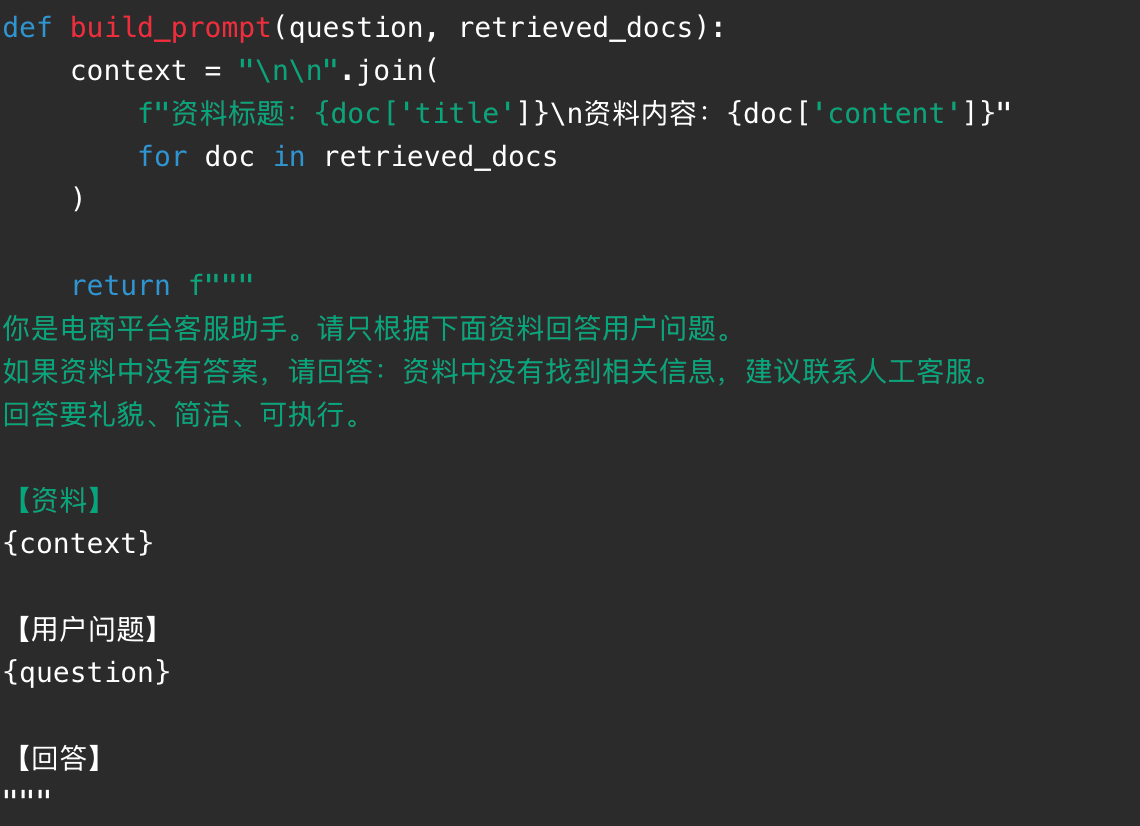
第五步是构造 Prompt。检索到资料后,不要只把用户问题丢给模型,而要把"资料"和"回答规则"一起给模型:
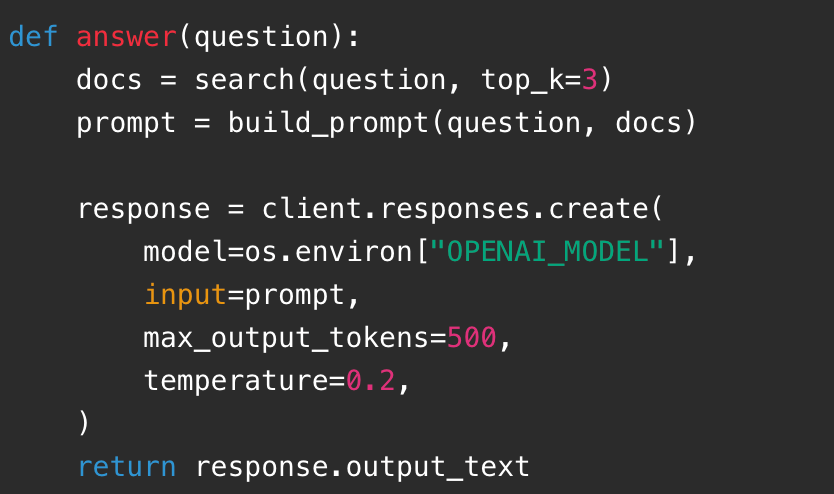
第六步是调用大模型生成答案:
这个项目虽然简化,但已经包含 RAG 的关键思想:资料不靠模型记忆,而是从知识库检索;回答不靠模型自由发挥,而是基于检索结果生成。对于企业场景来说,这一点非常重要。企业文档经常变化,今天退货规则可能是七天,明天某类商品规则可能调整。如果把知识写死在模型里,更新成本很高;如果放在知识库里,只要更新文档和向量索引,就能让系统使用新资料。
一个好用的 RAG 系统,还需要考虑下面这些细节:
- 文档来源:每段答案最好能追溯到哪份文档。
- 权限控制:用户只能检索自己有权限看的资料。
- 片段长度:太短容易丢上下文,太长容易引入无关信息。
- 检索数量:top_k 太小可能漏资料,太大可能干扰模型。
- 重排序:初步检索后,可以再用更强模型重新排序。
- 答案约束:资料没有答案时,必须允许模型说不知道。
- 日志记录:保存用户问题、检索结果、模型回答,方便后期优化。
- 评估集:准备一批标准问答,用来检查系统升级后有没有退步。
如果你想把这个项目做成课程作业或 CSDN 实战文章,可以先不用复杂后端。第一版直接写成命令行程序即可:读取本地 Markdown 文档,切分文本,调用 Embedding,保存到本地 JSON 或 SQLite,再用简单相似度检索,最后调用大模型回答。等流程跑通后,再替换成专业向量数据库和 Web 页面。
二十九、训练与上线排错清单
深度学习和大模型应用最容易让小白头疼的地方,不是概念背不下来,而是代码跑起来以后不知道哪里出了问题。下面整理一份排错清单,适合训练模型和做 RAG 项目时对照检查。
先看训练阶段。如果模型训练效果差,可以按下面顺序排查:
数据是否正确 -> 标签是否可靠 -> 数据是否泄漏 -> 输入是否归一化 -> 模型是否太简单或太复杂 -> 学习率是否合适 -> 损失是否正常下降 -> 训练集和验证集差距是否过大
如果训练集准确率很低,验证集准确率也很低,通常是欠拟合。可能原因包括模型太简单、训练轮数太少、特征不够、学习率不合适、数据标签混乱。解决方向是增加模型能力、训练更久、改善数据、调整学习率。
如果训练集准确率很高,验证集准确率很低,通常是过拟合。模型把训练集记得很熟,但对新数据不稳定。解决方向包括增加数据、数据增强、减少模型复杂度、加入正则化、使用 Dropout、提前停止训练。
如果损失一开始就变成 nan,常见原因是学习率太大、输入数据异常、除零错误、数值溢出。可以先把学习率调小,再检查数据中是否有空值、极端值、非法值。
如果模型预测永远是同一个类别,可能是类别不平衡。比如 10000 条样本里 9800 条都是正常样本,模型全部预测正常也能拿到很高准确率。此时不要只看准确率,要看精确率、召回率、F1 值和混淆矩阵。必要时可以做重采样、类别权重调整或补充少数类数据。
再看大模型 API 阶段。如果模型回答质量不好,可以这样排查:
- Prompt 是否明确:有没有告诉模型角色、任务、限制、格式。
- 上下文是否足够:模型是否拿到了完成任务需要的信息。
- 输出是否太短:max_output_tokens 是否限制太小。
- 随机性是否太高:严肃业务中 temperature 是否过大。
- 问题是否拆分:复杂任务是否需要分步骤处理。
- 示例是否充分:是否给了模型参考样例。
如果模型回答太发散,就降低 temperature,加强格式约束。如果模型回答太短,就增加输出长度限制,并在 Prompt 中要求分点说明。如果模型总是编造,就明确要求"资料没有提到就说没有找到",并配合 RAG 检索资料。
最后看 RAG 阶段。RAG 效果不好,往往不是大模型一个环节的问题,而是检索、切分、Prompt、资料质量共同影响。
RAG 常见问题一:检索不到正确资料。
可能原因是文档切分不合理、Embedding 模型不适合、用户问题和文档表达差异太大、top_k 太小。可以尝试增加检索数量、优化切分、加入关键词检索和向量检索混合召回。
RAG 常见问题二:检索到了资料,但模型回答仍然错误。
可能是 Prompt 没有限制模型只根据资料回答,也可能是检索结果太多太杂,干扰了模型。可以把资料编号,让模型引用编号回答;也可以要求模型先判断资料是否相关,再回答。
RAG 常见问题三:答案没有来源。
企业场景最好让答案带引用来源,例如"根据《退货规则》第 2 段"。这需要在入库时保存文档标题、段落编号、URL 或文件名,检索后一起传给模型。
RAG 常见问题四:更新文档后答案没变化。
可能是向量索引没有重新构建,或者旧文档没有删除。知识库系统要设计文档版本号和更新时间,更新资料时同步更新向量数据库。
为了让项目可持续优化,建议从第一天就保存日志:
用户问题 检索到的资料片段 资料相似度分数 最终 Prompt 模型回答 用户是否满意 人工修正答案
有了这些日志,后期才能知道问题到底出在检索、Prompt 还是模型。没有日志,只能凭感觉调参,很容易越调越乱。
对于小白来说,最实用的学习方法是:每次只改一个变量。比如今天只调整切分长度,明天只调整 top_k,后天只调整 Prompt。每次修改后用同一批测试问题评估效果。这样你会慢慢形成工程直觉,而不是靠运气调模型。
三十、总结
从深度学习到大语言模型,可以概括成一句话:神经网络通过数据训练学习多层特征,Transformer 让模型更高效地理解长文本关系,BERT 偏理解,GPT 偏生成,Embedding 把文本变成可检索的向量,向量数据库负责相似度搜索,RAG 把检索和生成结合起来,让大模型更适合企业知识库问答。
全文路线如下:
神经网络基础 -> 神经元、权重、偏置、激活函数 -> 前向传播、损失函数、反向传播、梯度下降 -> CNN 处理图像 -> RNN 处理序列 -> Transformer 处理长文本和上下文关系 -> BERT 做文本理解 -> GPT 做文本生成 -> Embedding 表示语义 -> 向量数据库做相似度检索 -> RAG 做知识库问答
如果你能把这条线讲清楚,说明你已经不是只会背 AI 名词,而是开始理解现代 AI 应用的底层逻辑了。接下来最好的学习方式,是用 Python 做一个小型知识库问答系统:准备几篇文档,切分文本,生成向量,存入向量数据库,检索相关片段,再调用大模型生成答案。这个项目做完,你对深度学习、大模型和 RAG 的理解会比单纯看十篇概念文章扎实得多。
参考资料
- LeCun, Bengio, Hinton,《Deep learning》,Nature,2015:https://www.nature.com/articles/nature14539
- Vaswani 等,《Attention Is All You Need》,2017:1706.03762 Attention Is All You Need
- Devlin 等,《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》,2018:1810.04805 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- PyTorch 官方教程 Build the Neural Network:Build the Neural Network --- PyTorch Tutorials 2.12.0+cu130 documentation
- TensorFlow 官方 CNN 教程:https://www.tensorflow.org/tutorials/images/cnn
- OpenAI Text Generation 文档:https://platform.openai.com/docs/guides/text
- OpenAI Embeddings 文档:https://platform.openai.com/docs/guides/embeddings
- Milvus 向量数据库文档:https://milvus.io/docs/overview.md