声明:本篇博客是以吴恩达的【Agent智能体】教程为基础,并对其中的内容做了笔记整理以及个人收获的总结。
前面讲解了反思设计模式的应用,我们能看到反思是可以提升大模型的输出质量的。但是我们只知道反思有用是不够的,在实际开发中一定会遇到这样一个痛点:我修改了反思提示词,AI 的表现到底是变好了,还是变差了,反思真的起作用了吗?
这就引出了我们接下来要探讨的核心:必须为 AI 系统引入一套科学的评估基准(Eval),利用测试集与量化评分标准(Rubric),来判断反思是否真的起作用了!
例子:将自然语言转化为数据库查询(Text-to-SQL)
-
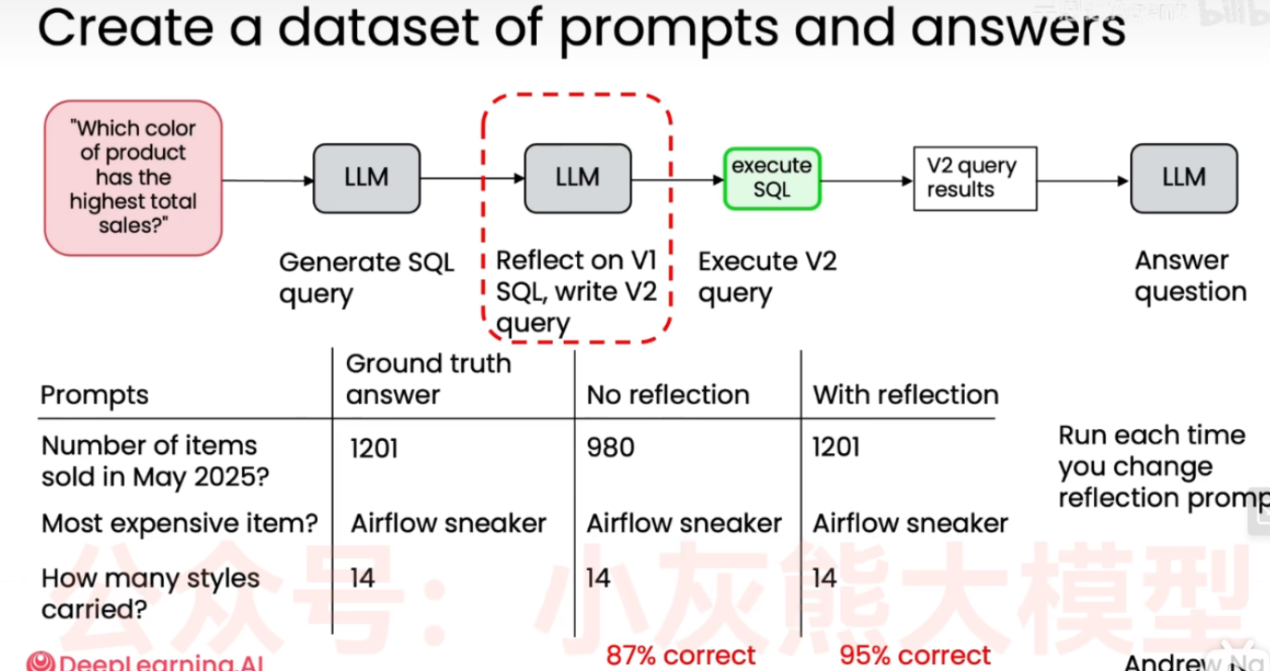
上半部分:带有"反思"机制的工作流程
- 用户输入提示词 (Prompt): 用户提出问题:"Which color of product has the highest total sales?"(哪个颜色的产品总销量最高?)。
- 初次生成 SQL (Generate SQL query): 第一个 LLM 接收到问题后,生成一个初始版本的 SQL 查询语句(V1 版本)。
- 反思与修正 (Reflect on V1 SQL, write V2 query): 这是图中红色虚线框标出的核心创新步骤。系统并没有直接运行 V1 版本的代码,而是让 LLM 对刚刚生成的 V1 代码进行"自我反思"和检查,找出潜在的语法错误或逻辑漏洞,然后重写并生成改进后的 V2 版本查询语句。
- 执行查询 (Execute V2 query): 在数据库中实际执行经过优化后的 V2 SQL 语句。
- 获取查询结果 (V2 query results): 得到数据库返回的原始数据结果。
- 回答问题 (Answer question): 最后一个 LLM 接收到数据库结果,将其转化为人类容易理解的自然语言文本,作为最终答案输出。
-
问题:第二个语言模型反思并优化SQL查询,真的能提升最终输出结果吗?
这个就是我们探讨的核心:我们怎么评估反思是否真的作用了?
答案是做对比。 下半部分的图就是效果的对比与评估。
-
表格列:
- Prompts (提示词): 测试用的各种问题。
- Ground truth answer (真实答案): 标准正确答案。
- No reflection (无反思): LLM 生成第一版 SQL 后直接运行得出的结果。
- With reflection (有反思): LLM 经过自我纠错后运行得出的结果。
-
整体准确率 (Accuracy):
- 底部红字显示,在没有反思 的情况下,系统的准确率为 87%。
- 在加入反思 机制后,准确率跃升至 95%。
-
通过表格做对比,我们发现当前例子的反思机制是非常有用的。这样就相当于我们建立了一个"评测流程"。正如图片右侧的提示:
"Run each time you change reflection prompt"(每次更改反射提示时都要运行一下)
- "Run each time you change reflection prompt":每次更改反射提示时都要运行一下。
这句话就是在提示开发者,这是一种迭代开发的方法。后续我们可以快速尝试不同的提示词思路,并通过重写反思词来测试新的提示词是否能进一步提高准确率,从而筛选出最适合当前应用场景的策略。
但是这个例子说明你可与用客观评测,因为有明确答案。下面看一个主观评估的例子:
例子:主观性任务中的"反思"应用 (What about subjective tasks?)
这个展示了"反思机制"如何应用于像"数据可视化(画图表)"这样没有绝对唯一标准答案的主观任务中。
- 工作流演示:
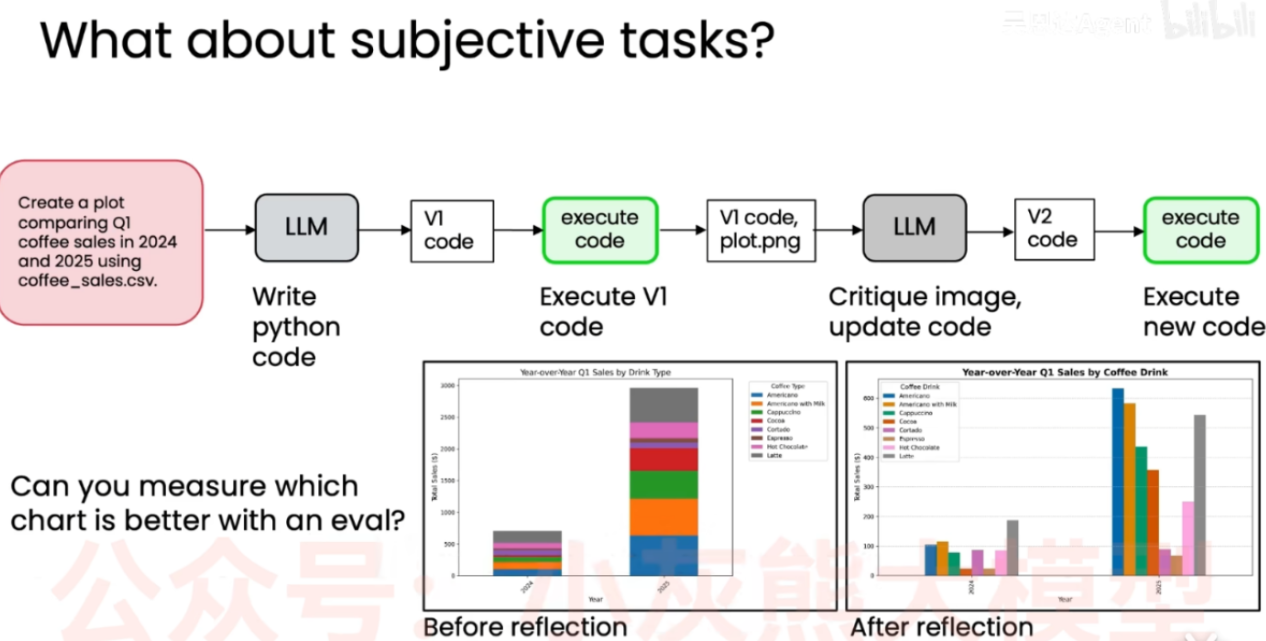
- 用户要求用 Python 根据数据画一个对比 2024 和 2025 年 Q1 咖啡销量的图表。
- 初次生成 (Before reflection): LLM 生成了第一版代码并运行,画出了图一(堆叠柱状图)。这种图很难直观对比这两年的销量。
- 反思与修改 (Critique image, update code): 将第一版的图和代码交给 LLM 进行反思。LLM 发现堆叠图不便于横向对比,于是修改代码,生成了第二版图表。
- 最终结果 (After reflection): 第二版图表变成了"分组柱状图",各咖啡品类的销量对比一目了然,质量显著提升。
问题:"你能否通过某种评估方法(eval)来衡量哪张图更好?"
因为"好坏"是主观的,我们需要一种方法来量化这种进步,下面展示几个方法
方法1:直接让 LLM 当裁判的弊端 (Using an LLM as a judge)

最直观的想法是直接把两张图发给另一个强大的 LLM,问它:"哪张图更好?" 这张图指出了这种简单粗暴做法的致命缺陷。
- 已知问题 (Known issues):
- 回答质量通常不高 (Answers often not very good): 因为"更好"这个词太模糊了,LLM 缺乏具体的评判依据,给出的理由往往站不住脚。
- 位置偏差 (Position bias): 这是一个在 LLM 评测中非常著名的现象。当给出选项 A 和 B 时,LLM 会存在"偏袒第一个选项"的倾向(图中红框圈出了 A),仅仅因为它排在前面,而不是因为它真的更好。
更好的思路:尝试给LLM一些评判标准
方法2:使用量化评分标准才是正解 (Grading with a rubric gives more consistent results)
直接问"哪个更好"行不通,这张图给出了行业内通用的终极解决方案:引入评分标准(Rubric)。
- 评分标准 (Rubric) 的作用:
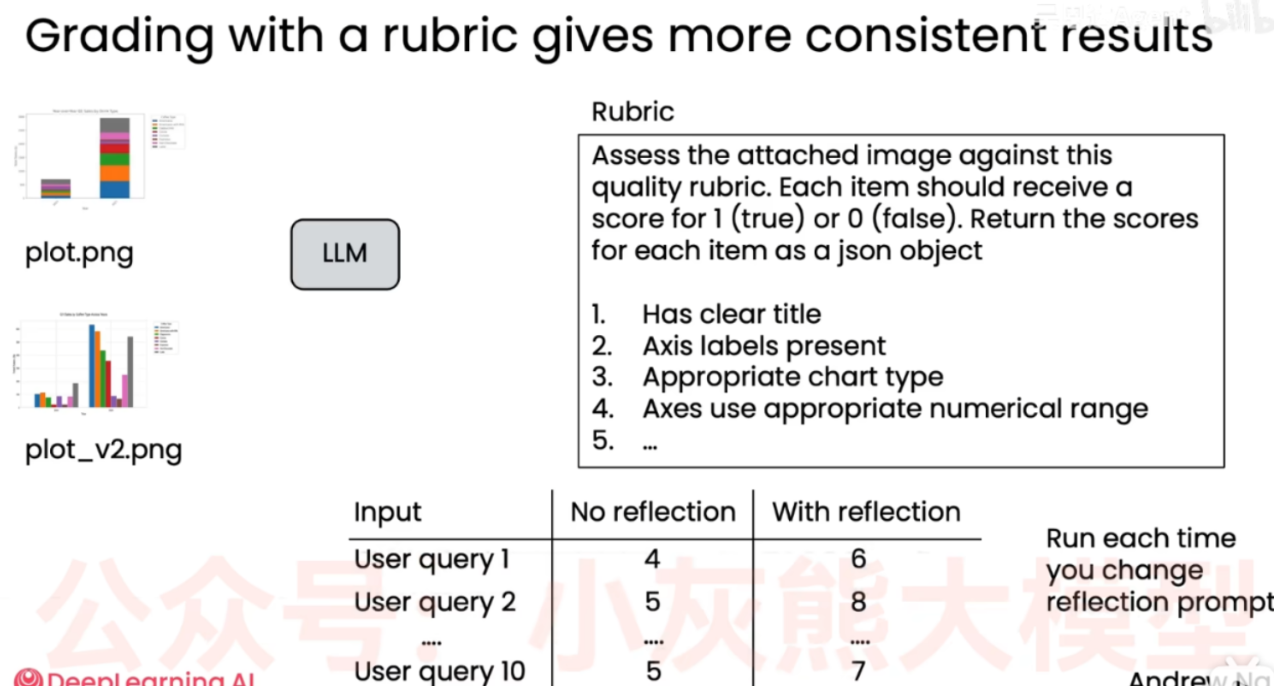
- 不再问笼统的问题,而是给 LLM 提供一个像老师批改试卷一样的"打分表"。
- 图中,提示词明确要求:"根据以下质量标准评估这张图表,每一项为真得1分,为假得0分,并返回 JSON 格式"。
- 具体的客观标准包括:1. 是否有清晰的标题;2. 坐标轴是否有标签;3. 图表类型是否合适;4. 坐标轴数值范围是否合理等。
- 量化成果:
- 通过这种拆解成客观小项的方法,LLM 就能给出稳定、一致的评估结果,有效消除了图二中的"位置偏差"。
- 底部表格展示了评估结果:对于多个用户查询,"没有反思 (No reflection)"生成的图表得分普遍较低(例如 4分、5分),而"经过反思 (With reflection)"生成的图表得分显著提高(例如 6分、8分、7分)。
积累了这样一套评测之后,也可以通过不断修改初始提示词、反思提示词,重新测评,找出最合适的,从而提升性能。
评估方式的总结

-
客观评估 (Objective evals)
这适用于那些有绝对标准答案、对错分明的任务(例如前面的 Text-to-SQL 查销量)。
-
基于代码的评估更容易 (Code-based evals are easier): 评估代码或 SQL 语句非常直接。代码要么能跑通,要么报错;SQL 查出来的数据要么和标准答案一致,要么不一致。这种非黑即白的特性使得自动化测试非常容易。
-
建立包含真实答案的数据集 (Build a dataset of ground truth examples): 为了系统地评估,你需要准备一个测试题库(Dataset),里面不仅有用户的各种提问,还要有对应的人工确认过的"绝对正确答案(Ground truth)"。每次修改反思的提示词,就在这个数据集上跑一遍,看准确率是上升了还是下降了。
-
-
主观评估 (Subjective evals)
这适用于没有唯一标准答案、好坏取决于人类主观感受的任务(例如前面画咖啡销量对比图)。
-
让大语言模型充当裁判 (Use LLM as a judge): 既然人工去评判成千上万张图表太耗时,我们只能依靠另一个强大的大语言模型(LLM)来当裁判,替我们评估生成结果的好坏。
-
基于评分标准的打分效果更好 (Rubric-based grading is better): 这是最重要的一条结论。正如上一组图所演示的,直接让 LLM 评判"哪个更好"会导致随机性高和位置偏差。
- 正确的做法是给 LLM 提供一份详细的量化评分细则(Rubric),让它像老师批改主观题一样,根据诸如"是否有标题"、"坐标轴是否清晰"等具体条目逐项打分。
-
总结:AI 智能体工作流:反思(Reflection)与评估(Eval)
-
核心理念 :AI 应用开发正在从"靠感觉写提示词"走向"以评测驱动的系统工程(Eval-driven Engineering)"。
- 先建好评测这套基础设施,然后通过不断打磨"反思提示词",就能低成本地持续压榨出大模型更高的性能。
-
三个核心:
-
大语言模型(LLM)往往无法一次性完美解决复杂任务。相较于花费巨大成本去训练或微调一个更强的模型,在系统设计中引入"反思机制(生成初版 -> 自我批判 -> 修正输出)"是一种极具性价比的方法。能显著提升最终输出的准确率和质量。
-
反思的效果好不好,很大程度上取决于"反思提示词(Reflection prompt) "怎么写。为了不断优化这个提示词,开发者必须建立一套系统化的评估流程。每次修改提示词后,都要在测试集上重新跑一遍,用数据(分数/准确率)来验证修改是否有效,而不是凭感觉盲目迭代。
-
根据"任务属性"选择正确的评估策略
- 对于客观任务(对错分明,如写 SQL、解数学题): 应该建立包含"绝对正确答案(Ground truth)"的数据集。评估标准极其明确,代码能跑通、结果能对上就是好
- 对于主观任务(没有绝对标准,如画图表、写文章): 必须使用另一个 LLM 来充当"裁判",但绝不能简单粗暴地让 LLM 凭感觉选"哪个好" (这会导致严重的评判偏见和随机性)。唯一的解法是提供"量化评分标准(Rubric)"。把主观感觉拆解成一个个客观的打分项(如:是否有标题、刻度是否准确),让 LLM 像老师批改量表一样逐项打分,从而将主观的优化转化为可追踪的客观分数。
-
如果这篇文章对你有帮助,欢迎点赞、评论、关注、收藏。你们的支持是我前进的动力!