📌 本文覆盖Spring AI Alibaba理论基础 + 核心 API 原理 + 完整实战代码,建议收藏。
写在前面
网上关于 Spring AI Alibaba 的文章,要么是照着官网复制粘贴的快速开始,要么是一堆 Hello World 代码没有任何解释。
这篇文章想干的事不一样:把理论讲透,把原理说清,然后用实战代码去验证它。
你学完不只会"用",还能理解为什么这么设计,遇到问题知道从哪里下手排查。
一、先把大模型的工作机制搞清楚
学任何 AI 框架之前,先把基础概念弄明白,否则后面的代码你只是在抄,不是在学。
1.1 Token:模型"看"世界的最小单位
大模型不认识"字",也不认识"词",它认识的是 Token。
Token 是文本被分词后的基本单元,一个 Token 可以是一个汉字、半个英文单词、或者一个标点符号。以英文为例,"ChatGPT is great" 大概是 5 个 Token;中文由于字符密度高,通常 1 个汉字 ≈ 1.5 个 Token。
为什么 Token 很重要?因为大模型的所有限制都以 Token 为单位:
-
Context Window(上下文窗口):模型一次能"看到"的最大 Token 数,超出就会截断
-
计费单位:API 调用按输入 Token + 输出 Token 收费
-
延迟:Token 越多,生成越慢
Qwen-Max 的 Context Window 是 32K Token,大概能处理约 2 万字的中文文本。这个上限直接决定了你的 RAG 召回策略、Memory 保留策略。
1.2 Prompt 的本质:不只是一段文字
很多人以为 Prompt 就是聊天框里输入的那句话。实际上在模型 API 层面,Prompt 是一个多角色消息列表 ,每条消息有明确的 role:
| Role | 说明 |
|---|---|
system |
系统指令,定义模型的行为边界、角色人设、回答风格 |
user |
用户输入,每轮对话的用户发言 |
assistant |
模型的历史回复,用于保持对话连贯性 |
tool |
Function Calling 工具调用的结果 |
一次完整的多轮对话,实际上是把所有历史消息打包成一个列表,每次请求全量发送给模型。模型本身没有记忆,"记住"你说过什么,是靠把历史消息重复发送实现的------这也是为什么 Token 消耗会随对话轮次线性增长。
在 Spring AI 中,Prompt 不再是简单字符串,而是支持参数绑定、变量替换、上下文嵌入的结构化模板对象。可以类比 Spring MVC 里的 View------一个模型对象(Map)填充模板占位符,渲染后的字符串就是发给模型的 Prompt 内容。
1.3 Embedding:把语义变成数字
Embedding(向量化)是 RAG 的基石,原理要搞清楚。
文本本身是离散的符号,计算机无法直接计算两段文字"有多相似"。Embedding 模型做的事情,就是把一段文字映射到一个高维向量空间里------比如一个 1536 维的浮点数数组。
关键性质:语义相近的文本,向量距离也近。
举个例子:
-
"苹果手机发布会" → 向量 A
-
"iPhone 新品发布" → 向量 B
-
"今天天气不错" → 向量 C
向量 A 和 B 的余弦相似度会远大于 A 和 C,即使 A 和 B 的字面用词完全不同。这就是语义搜索能跨越字面的原理。
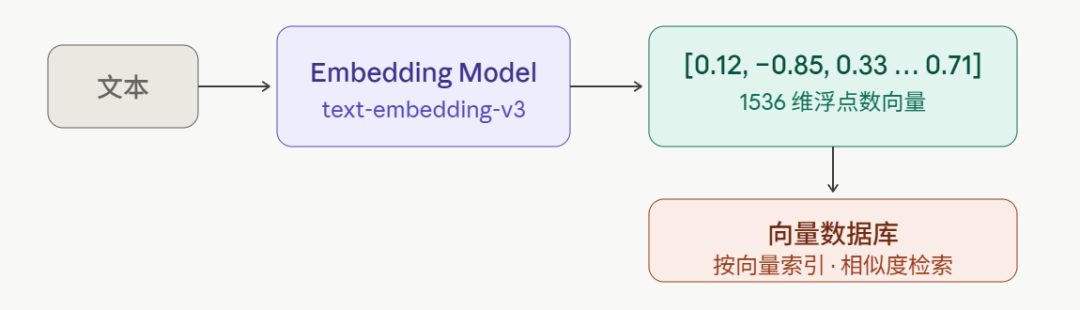
Spring AI 对 Embedding 做了统一抽象,EmbeddingModel 接口屏蔽了不同提供商的差异,DashScope 的 text-embedding-v3 模型就是其中一个实现。
1.4 Structured Output:让模型输出可靠的结构化数据
大模型默认输出自由文本,但实际业务经常需要结构化数据(JSON、对象等)来对接下游系统。
Spring AI 的 Structured Output 工作机制是:**在调用模型之前,自动把期望的输出格式描述追加到 Prompt 里,告诉模型"请按照这个 JSON Schema 输出"**。
需要注意一个重要差异:DashScope(通义千问)目前通过增强 Prompt 实现 JSON 格式,是"尽力而为";OpenAI 在 API 层面原生支持 JSON 格式,提供严格保证。在实际工程中,如果你用国内模型做结构化输出,需要加重试机制和解析兜底逻辑。
二、Spring AI Alibaba 的整体架构
搞清楚了底层概念,现在看框架的整体设计。

2.1 分层架构图
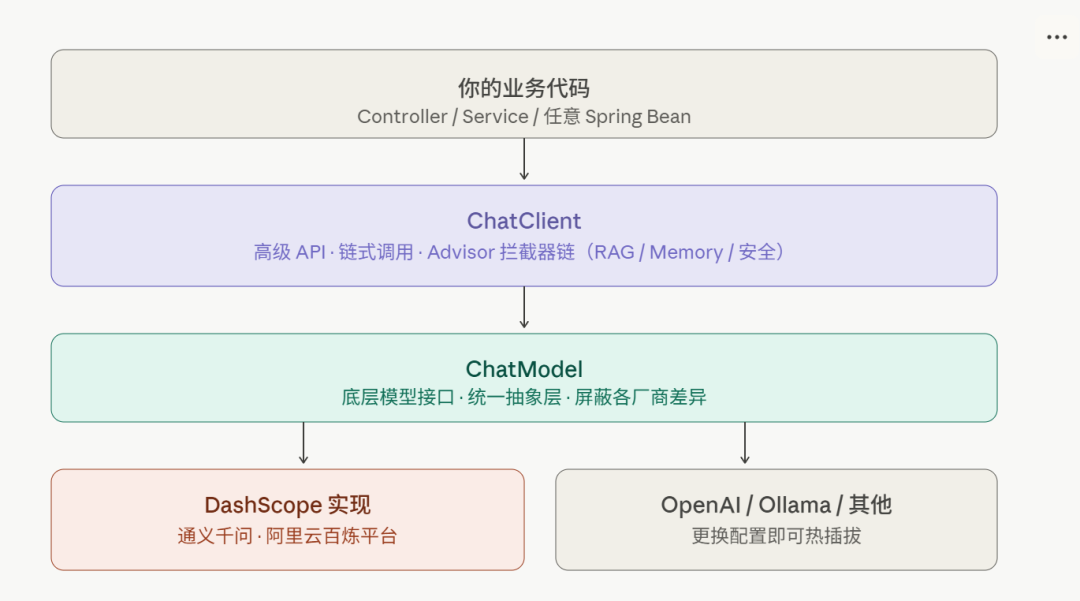
这个分层设计是 Spring AI 最聪明的地方------上层代码对模型提供商无感知 。换模型只改配置文件,业务代码零修改。这跟 Spring Data 的设计思路一模一样:你写的是 JpaRepository,底层换 MySQL 还是 PostgreSQL 跟你没关系。
2.2 ChatModel vs ChatClient:别再傻傻分不清
这两个概念是新手最容易搞混的地方,必须分清楚。
ChatModel 是底层接口,直接对应模型 API 的一次请求:
-
你需要手动构建
Prompt对象,管理消息列表 -
处理
ChatResponse,提取内容 -
样板代码多,但控制精确
-
适合需要精细操控的场景(如框架开发)
ChatClient 是构建在 ChatModel 之上的高级封装:
-
提供 Fluent 链式调用 API
-
内置 Advisor 拦截器链机制
-
自动处理系统提示词、模板注入、Memory 管理
-
日常开发 90% 场景的首选
一个直观的对比:
go
// ❌ ChatModel 写法:繁琐,样板代码多
List<Message> messages = new ArrayList<>();
messages.add(new SystemMessage("你是一个 Java 助手"));
messages.add(new UserMessage(userInput));
Prompt prompt = new Prompt(messages);
ChatResponse response = chatModel.call(prompt);
String content = response.getResult().getOutput().getContent();
// ✅ ChatClient 写法:链式调用,简洁易读
String content = chatClient.prompt()
.system("你是一个 Java 助手")
.user(userInput)
.call()
.content();一句话总结:底层看 ChatModel,开发用 ChatClient。在 Spring AI Alibaba 1.1.x 之后,ChatModel 更多是作为 Agent Framework 内部节点的基础能力,而不是直接暴露给应用层。
2.3 Advisor 机制:Spring AI 的"AOP 切面"
Advisor 是 Spring AI 里最值得深入理解的设计之一,也是 RAG、Memory 能力的实现基础。
把它理解成 Spring MVC 的 Interceptor,或者 AOP 的切面------在请求发给模型之前 和响应回来之后,可以做任意处理:
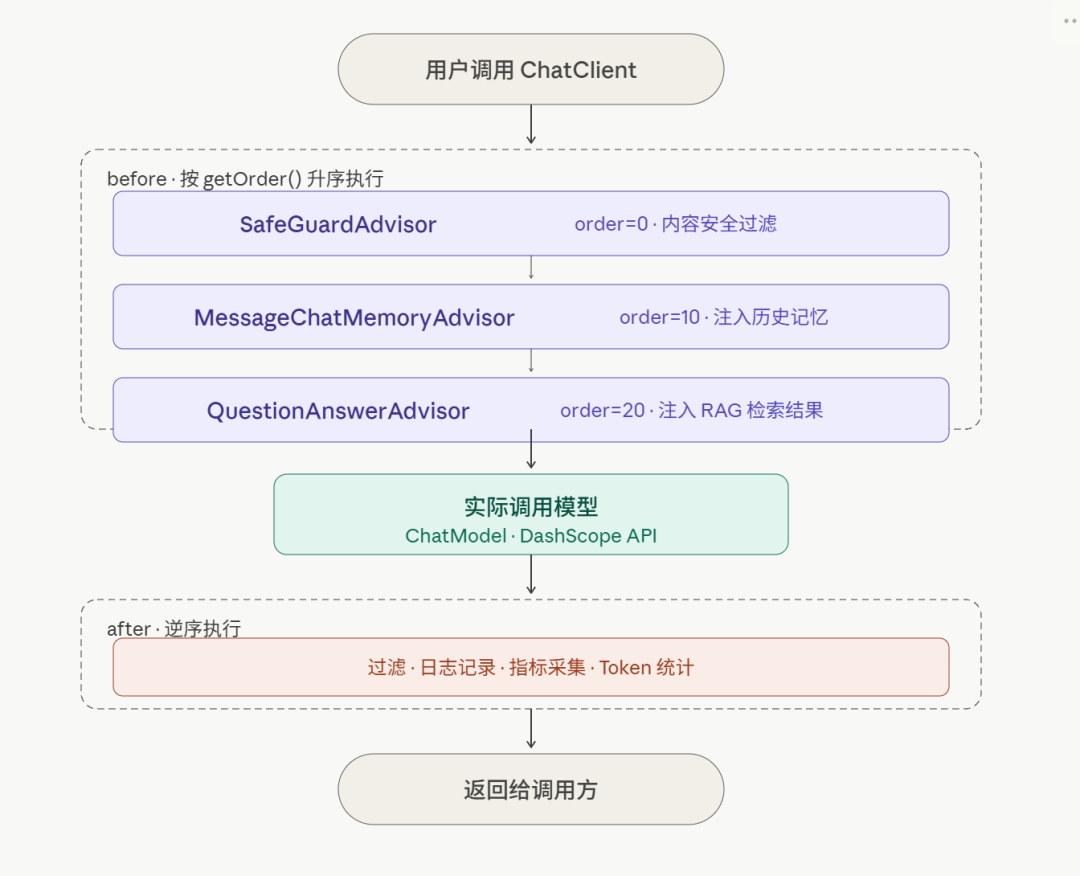
这个设计让 RAG、Memory、安全过滤等能力都变成了可插拔的组件 。你想加哪个能力,就注册哪个 Advisor,不需要改业务代码。getOrder() 方法控制执行顺序,数字越小越先执行(nextAroundCall() 是非流式实现,nextAroundStream() 是流式实现)。
三、环境搭建:正确姿势
3.1 pom.xml 完整配置
go
<properties>
<java.version>17</java.version>
<spring-ai-alibaba.version>1.0.0</spring-ai-alibaba.version>
</properties>
<!-- BOM 管理版本,避免依赖冲突 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-bom</artifactId>
<version>${spring-ai-alibaba.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring AI Alibaba 核心:含 DashScope 接入 -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
</dependency>
</dependencies>
<!--
注意:spring-ai 相关包未完全发布到中央仓库
如果出现 spring-ai-core 依赖解析失败,加这个仓库配置
-->
<repositories>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
<snapshots><enabled>false</enabled></snapshots>
</repository>
</repositories>3.2 application.yml 详解
go
spring:
ai:
dashscope:
# API Key 必须用环境变量注入,严禁硬编码提交到 Git
api-key:${AI_DASHSCOPE_API_KEY}
chat:
options:
model:qwen-max # 可选:qwen-max/qwen-plus/qwen-turbo/qwen-long
temperature:0.7 # 0-1,越高越有创意,越低越确定(推理任务用 0.1-0.3)
max-tokens:2048 # 单次最大输出 Token 数,影响延迟和成本
top-p:0.8 # 控制采样范围,与 temperature 配合使用
embedding:
options:
# 向量化必须用专用模型,不要用 chat 模型!
model:text-embedding-v3模型选型参考:
| 模型 | 特点 | 适用场景 |
|---|---|---|
| qwen-max | 最强效果,价格高 | 复杂推理、代码生成、高质量内容 |
| qwen-plus | 效果/价格均衡 | 大多数业务场景的首选 |
| qwen-turbo | 速度快、价格低 | 实体提取、分类、简单问答 |
| qwen-long | 超长上下文(1M Token) | 长文档处理、大型代码库分析 |
四、Prompt 工程:你和模型沟通的核心
4.1 PromptTemplate:让 Prompt 可复用、可维护
硬编码 Prompt 字符串是最原始也最难维护的写法。Spring AI 提供了 PromptTemplate,底层使用 Terence Parr 开发的 StringTemplate 引擎,通过 {} 占位符实现变量替换。
最佳实践:把 Prompt 模板存到 .st 文件里
src/main/resources/prompts/code-review.st:
go
你是一个资深 Java 工程师,专注于代码质量和性能优化。
请对以下 {language} 代码进行 Code Review,重点关注:
1. 潜在的 Bug 或逻辑问题
2. 性能瓶颈
3. 代码风格和可读性
代码内容:
{code}
请给出具体的改进建议,并说明原因。
go
@Service
publicclass CodeReviewService {
// 直接注入 classpath 文件,不需要手动读文件
@Value("classpath:prompts/code-review.st")
private Resource codeReviewTemplate;
privatefinal ChatClient chatClient;
public String review(String language, String code) {
PromptTemplate template = new PromptTemplate(codeReviewTemplate);
Prompt prompt = template.create(Map.of(
"language", language,
"code", code
));
return chatClient.prompt(prompt).call().content();
}
}这样做的好处:Prompt 和代码分离;可以通过配置中心在不重新部署的情况下更新 Prompt;非技术成员也能参与 Prompt 优化。
特别提示 :如果你的 Prompt 里包含 JSON(花括号),默认的 {} 占位符会和 JSON 语法冲突。这时换成自定义分隔符:
go
PromptTemplate template = PromptTemplate.builder()
.renderer(StTemplateRenderer.builder()
.startDelimiterToken('<')
.endDelimiterToken('>')
.build())
.template("请分析这个 JSON:{\"key\": \"value\"},提取字段 <fieldName>")
.build();4.2 多角色消息手动构建
对于需要精细控制消息结构的场景(比如 Few-Shot 示例注入),直接构建消息列表:
go
// Few-Shot 示例:通过历史对话告诉模型期望的输出格式
List<Message> messages = List.of(
new SystemMessage("""
你是一个严格的代码审查员,只输出 JSON 格式的审查结果,不输出其他任何内容。
输出格式:{"issues": [...], "score": 0-100, "summary": "..."}
"""),
// 注入两个 Few-Shot 示例,帮助模型理解期望的输出
new UserMessage("审查:for(int i=0;i<list.size();i++){}"),
new AssistantMessage("{\"issues\":[\"循环中重复调用list.size(),建议缓存长度\"],\"score\":75,\"summary\":\"存在性能问题\"}"),
new UserMessage("审查:String s = null; s.length();"),
new AssistantMessage("{\"issues\":[\"空指针风险,应在调用前检查null\"],\"score\":40,\"summary\":\"存在严重Bug\"}"),
// 真正要审查的代码
new UserMessage("审查:" + userCode)
);
String result = chatClient.prompt(new Prompt(messages)).call().content();五、Structured Output:让模型输出 Java 对象
5.1 工作原理
Structured Output 的实现分为两步:
-
调用前 :
BeanOutputConverter根据你的 Java 类自动生成 JSON Schema,追加到 Prompt 末尾,告诉模型"请按这个格式输出" -
调用后 :用
converter.convert()把模型返回的 JSON 字符串反序列化为 Java 对象
go
// 定义期望的输出结构
public record ProductAnalysis(
String productName,
List<String> advantages,
List<String> disadvantages,
int recommendScore, // 0-100
String summary
) {}
@GetMapping("/analyze")
public ProductAnalysis analyzeProduct(@RequestParam String productDesc) {
BeanOutputConverter<ProductAnalysis> converter =
new BeanOutputConverter<>(ProductAnalysis.class);
// converter.getFormat() 的返回内容大概是:
// "Your response should be in JSON format.
// The JSON schema is: {"type":"object","properties":{"productName":{...},...}}"
String result = chatClient.prompt()
.system("你是一个产品分析师,请严格按照指定 JSON 格式输出分析结果,不输出其他内容")
.user(productDesc + "\n\n" + converter.getFormat())
.call()
.content();
return converter.convert(result);
}5.2 处理国内模型输出格式不稳定
DashScope 模型偶尔会在 JSON 外面包 Markdown 代码块(json {...} )。生产上必须加容错处理:
go
public <T> T safeConvert(String rawOutput, BeanOutputConverter<T> converter) {
String cleaned = rawOutput
.replaceAll("(?s)```json\\s*", "")
.replaceAll("(?s)```\\s*", "")
.trim();
try {
return converter.convert(cleaned);
} catch (Exception e) {
log.error("结构化输出解析失败,原始内容:\n{}", rawOutput);
throw new AiOutputParseException("模型输出格式异常,请重试", e);
}
}实际落地建议:加 @Retryable 注解,对解析失败自动重试 2 次(因为模型输出有随机性,同样的 Prompt 多试几次往往能成功)。
六、ChatMemory:对话记忆的原理与工程实现
6.1 记忆的本质与 Token 膨胀问题
前面说过,大模型本身无状态。所谓"记忆",是框架把历史消息在每次请求时重新塞给模型。
这带来一个严重问题:Token 消耗随对话轮次线性增长。
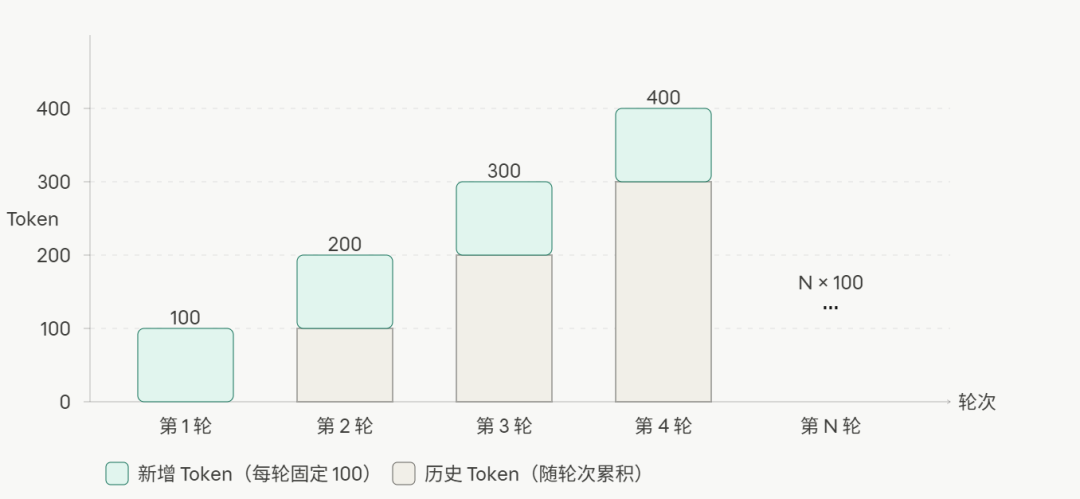
一个没有任何截断策略的客服系统,聊到第 100 轮时,每次请求都要发 1 万个 Token,成本爆炸。
Spring AI 的 MessageChatMemoryAdvisor 在每次请求前自动从 ChatMemory 取历史消息,追加到消息列表里。
6.2 三种 Memory 实现对比选型
| 实现 | 存储位置 | 适用场景 | 缺点 |
|---|---|---|---|
InMemoryChatMemory |
JVM 堆内存 | 开发测试 | 重启丢失,不支持多节点 |
JdbcChatMemory |
关系型数据库 | 需要持久化的单体应用 | 数据库 IO 有延迟 |
RedisChatMemory |
Redis | 生产环境,分布式部署 | 需要 Redis 基础设施 |
6.3 生产级 Memory 配置(Redis 版)
go
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-autoconfigure-memory-redis</artifactId>
</dependency>
go
@Configuration
publicclass AiConfig {
@Bean
public ChatClient chatClient(ChatClient.Builder builder,
RedisChatMemoryRepository memoryRepo) {
// MessageWindowChatMemory:按消息条数截断,简单可靠
ChatMemory memory = MessageWindowChatMemory.builder()
.chatMemoryRepository(memoryRepo)
.maxMessages(20) // 最多保留最近 20 条消息
.build();
return builder
.defaultSystem("你是一个专业的 AI 助手,记住用户的偏好和上下文")
.defaultAdvisors(
MessageChatMemoryAdvisor.builder(memory).build()
)
.build();
}
}
go
@GetMapping("/chat")
public String chat(@RequestParam String message,
@RequestParam String sessionId) {
return chatClient.prompt()
.user(message)
.advisors(spec -> spec.param(
AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY,
sessionId
))
.call()
.content();
}进阶:按 Token 数截断(更精准)
maxMessages(20) 是按条数截断,如果单条消息很长仍可能超出 Context Window。更严谨的方案是实现摘要压缩策略------把旧消息压缩成摘要保留,而不是直接丢弃:
go
// 多层次记忆策略:近期消息完整保留,远期消息压缩为摘要
// 参考:大模型开发系列 - Chat Memory 多层次记忆架构
publicclass SummarizingChatMemory implements ChatMemory {
privatefinal ChatMemory shortTermMemory; // 保留最近 10 轮完整对话
privatefinal ChatClient summaryClient; // 用于生成摘要的 ChatClient
@Override
public List<Message> get(String conversationId, int lastN) {
List<Message> recent = shortTermMemory.get(conversationId, 10);
String summary = getSummary(conversationId);
List<Message> result = new ArrayList<>();
if (summary != null) {
// 把历史摘要作为系统消息注入
result.add(new SystemMessage("之前对话的摘要:" + summary));
}
result.addAll(recent);
return result;
}
}七、RAG 知识库:完整工程实现
7.1 索引阶段:文档处理流水线
RAG 分为离线索引和在线检索两个阶段,很多人只关注检索,忽略了索引阶段的重要性。
索引阶段的完整流水线:
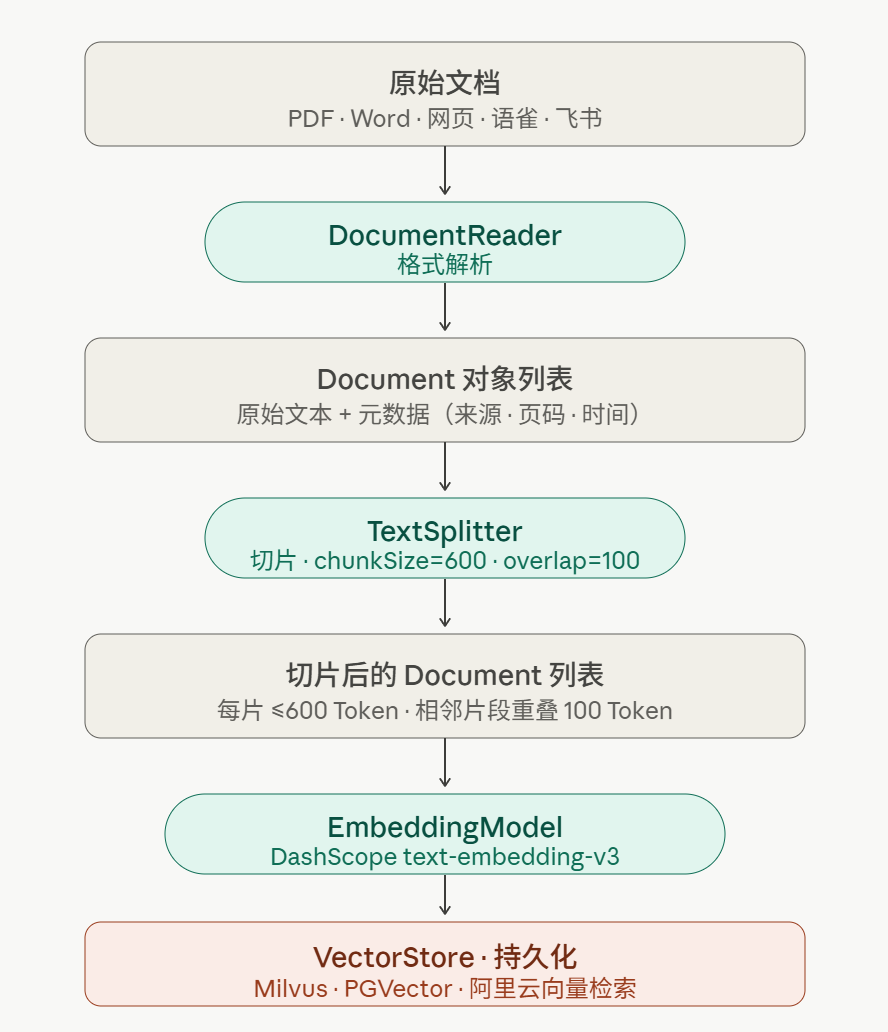
go
@Service
@Slf4j
publicclass DocumentIndexService {
privatefinal VectorStore vectorStore;
public void indexPdf(String filePath, String docId) {
// 1. 解析 PDF(按页切分,保留页码元数据)
var reader = new PagePdfDocumentReader(filePath,
PdfDocumentReaderConfig.builder()
.withPagesPerDocument(1)
.build()
);
List<Document> rawDocs = reader.get();
// 2. 注入业务元数据(后续可按此过滤)
rawDocs.forEach(doc -> {
doc.getMetadata().put("source", filePath);
doc.getMetadata().put("docId", docId);
doc.getMetadata().put("indexTime", LocalDateTime.now().toString());
});
// 3. 切片(核心参数影响最终效果)
// chunkSize: 每片最多 600 Token
// chunkOverlap: 相邻切片重叠 100 Token,防止语义在边界断裂
TokenTextSplitter splitter = TokenTextSplitter.builder()
.withChunkSize(600)
.withMinChunkSizeChars(100) // 过短的片段直接丢弃
.withChunkOverlap(100)
.build();
List<Document> chunks = splitter.apply(rawDocs);
// 4. 向量化并入库(框架自动调用 EmbeddingModel)
vectorStore.accept(chunks);
log.info("文档 {} 入库完成,共 {} 个切片", docId, chunks.size());
}
}7.2 检索阶段:QuestionAnswerAdvisor
go
@Bean
public ChatClient ragChatClient(ChatClient.Builder builder, VectorStore vectorStore) {
var ragAdvisor = QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(SearchRequest.builder()
.topK(5) // 召回前 5 个相关片段
.similarityThreshold(0.72) // 低于此阈值直接丢弃
// 按元数据过滤:只在指定文档里检索
.filterExpression("docId == 'product-manual-v3'")
.build())
.build();
return builder
.defaultSystem("""
你是企业内部知识库助手。
请严格基于 <context> 标签内的参考资料回答用户问题。
如果参考资料中没有相关信息,请明确告知用户,不要编造内容。
回答时引用具体的资料来源和页码。
""")
.defaultAdvisors(ragAdvisor)
.build();
}7.3 RAG 调优:核心参数的影响规律
切片大小(chunkSize)
| 文档类型 | 推荐 chunkSize | 原因 |
|---|---|---|
| 技术文档、API 手册 | 512-800 Token | 技术概念密度高,切太小会截断完整的概念 |
| 新闻、博客文章 | 256-400 Token | 段落较独立,可以切小一点提高精度 |
| 法律合同、规章制度 | 800-1024 Token | 条款之间关联性强,切碎会破坏语义完整性 |
相似度阈值(similarityThreshold)的调试方法
不要拍脑袋定阈值,按下面的流程测试:
-
准备 30 个有代表性的真实问题(覆盖能回答和无法回答两类)
-
阈值从 0.5 开始,每次步进 0.05,直到 0.85
-
记录每个阈值下:召回率(真正相关的有没有召回来)、精准率(召回的有没有不相关的)
-
找召回率和精准率的最佳平衡点
通常 0.68-0.75 是个比较稳的区间,但不同文档类型、不同 Embedding 模型差异较大。
Query Rewriting:提升检索效果的隐藏技巧
用户的问题往往不是最优的检索查询。Spring AI 提供了 RewriteQueryTransformer,先让模型把用户问题改写成更适合向量检索的形式:
go
// 用户问:"这个怎么用?"(指代不明,检索效果差)
// 改写后:"产品 X 的使用方法和操作步骤"(更具体,检索效果好)
var rewriter = new RewriteQueryTransformer(chatClient);
String rewrittenQuery = rewriter.transform(originalQuery, context);八、Function Calling:让模型真正能"做事"
8.1 一次 Function Call 的完整生命周期
很多人用 Function Calling 但不理解内部发生了什么:

关键认知:模型只负责决策(调哪个工具、传什么参数),实际执行由 Java 代码完成,结果再返回给模型生成最终回答。
8.2 工具定义的完整写法
go
@Configuration
publicclass OrderTools {
@Bean
@Description("""
查询指定订单的当前状态和物流信息。
当用户询问订单状态、快递进度、发货情况时调用此工具。
输入:订单编号(格式:以 ORD 开头的字母数字组合)
输出:订单状态、物流单号、预计到达时间
""")
public Function<OrderQueryRequest, OrderQueryResponse> queryOrder(
OrderService orderService) {
return request -> {
log.info("[Tool] 查询订单:{}", request.orderId());
Order order = orderService.findById(request.orderId());
if (order == null) {
returnnew OrderQueryResponse(null, "订单不存在", null, null);
}
returnnew OrderQueryResponse(
order.getId(),
order.getStatus().getDisplayName(),
order.getLogisticsNo(),
order.getEstimatedArrival()
);
};
}
// Record 类型作为工具的输入/输出参数
// @JsonPropertyDescription 会被转换为 JSON Schema 的 description 字段
public record OrderQueryRequest(
@JsonProperty(required = true, value = "orderId")
@JsonPropertyDescription("订单编号,如 ORD20241101,必须完整输入")
String orderId
) {}
public record OrderQueryResponse(
String orderId,
String status,
String logisticsNo,
String estimatedArrival
) {}
}
go
@GetMapping("/customer-service")
public String customerService(@RequestParam String question) {
return chatClient.prompt()
.system("""
你是一个电商客服助手。可以帮用户查询订单状态。
取消订单这类不可逆操作,必须先向用户确认,用户明确同意后才能执行。
""")
.user(sanitize(question)) // 输入消毒(防 Prompt 注入)
.functions("queryOrder") // 声明可用工具
.call()
.content();
}8.3 工具安全:不可忽视的工程要点
Function Calling 给了模型调用真实业务逻辑的能力,必须做好安全防护:
go
// 1. 参数校验:不能信任模型传来的参数
@Bean
public Function<DeleteRequest, DeleteResponse> deleteDocument(DocumentService service) {
return request -> {
// 必须做权限校验,不能只靠模型的描述来限制行为
if (!SecurityContext.currentUser().canDelete(request.docId())) {
returnnew DeleteResponse(false, "无权限删除此文档");
}
// 业务逻辑
service.delete(request.docId());
returnnew DeleteResponse(true, "删除成功");
};
}
// 2. 输入消毒:防御 Prompt 注入攻击
public String sanitize(String userInput) {
if (userInput.length() > 2000) {
thrownew IllegalArgumentException("输入过长");
}
// 过滤明显的注入尝试
String[] dangerousPatterns = {
"忽略之前的指令", "ignore previous instructions",
"you are now", "新的系统提示", "system:"
};
for (String pattern : dangerousPatterns) {
if (userInput.toLowerCase().contains(pattern.toLowerCase())) {
thrownew SecurityException("检测到异常输入");
}
}
return userInput;
}九、Graph 多智能体:复杂业务的工作流编排
9.1 什么时候需要 Graph
单个 ChatClient 能搞定大多数简单场景。当你的业务需要:
-
多步串行:搜集资料 → 起草内容 → 审核 → 发布
-
条件分支:根据审核结果决定是否重新生成
-
并行执行:同时调多个 Agent 再汇聚结果
-
循环重试:不达标就重做,有最大重试次数
这时候就需要 Graph 来编排。Spring AI Alibaba 1.0 正式引入了 Graph 框架,提供基于节点+边的工作流描述方式。
9.2 内容生产 Agent(含审核循环)
go
@Configuration
publicclass ContentAgentGraph {
@Bean
public StateGraph<ContentState> contentGraph(ChatClient chatClient) {
return StateGraph.<ContentState>builder()
// 节点 1:话题分析(确定目标读者和内容方向)
.addNode("analyze", state -> {
String analysis = chatClient.prompt()
.system("分析话题的目标读者、核心卖点,输出 JSON")
.user("话题:" + state.getTopic())
.call().content();
return state.withAnalysis(analysis);
})
// 节点 2:生成大纲
.addNode("outline", state -> {
String outline = chatClient.prompt()
.system("基于分析结果,生成文章大纲(含主标题和 3-5 个子标题)")
.user(state.getAnalysis())
.call().content();
return state.withOutline(outline);
})
// 节点 3:撰写内容(支持根据审核意见修改)
.addNode("write", state -> {
String prompt = "按照大纲撰写完整文章,1000-1500 字,公众号风格";
if (state.getFeedback() != null) {
prompt += "\n\n上次审核意见(请针对性修改):\n" + state.getFeedback();
}
String content = chatClient.prompt()
.system(prompt)
.user("大纲:\n" + state.getOutline())
.call().content();
return state.withContent(content).incrementRetryCount();
})
// 节点 4:质量审核
.addNode("review", state -> {
String review = chatClient.prompt()
.system("""
质量审核,输出 JSON:
{"passed": true/false, "score": 0-100, "feedback": "改进意见"}
通过标准:逻辑清晰、内容充实、score >= 75
""")
.user(state.getContent())
.call().content();
return state.withReview(review);
})
// 定义边
.addEdge(START, "analyze")
.addEdge("analyze", "outline")
.addEdge("outline", "write")
.addEdge("write", "review")
// 条件分支:审核通过 → 结束;不通过且未超次数 → 回到撰写节点
.addConditionalEdge("review", state -> {
ReviewResult result = parseReview(state.getReview());
if (result.passed()) return END;
if (state.getRetryCount() >= 3) {
log.warn("内容质量 3 次审核未通过,强制输出");
return END;
}
return"write"; // 返回撰写节点,携带审核意见重试
})
.build();
}
}十、生产落地的关键工程实践
10.1 Token 成本控制四板斧
go
// 板斧1:按场景选择合适模型(成本差异可达 10 倍)
// 实体提取、分类、简单问答 → qwen-turbo
// 复杂推理、长文本 → qwen-plus
// 顶级质量要求 → qwen-max
// 板斧2:Embedding 结果缓存
// 相同文本的向量化结果是固定的,没必要每次都调 API
@Bean
public EmbeddingModel cachedEmbeddingModel(EmbeddingModel rawModel,
RedisTemplate<String, float[]> redis) {
returnnew CachingEmbeddingModel(rawModel, redis, Duration.ofDays(7));
}
// 板斧3:Memory 截断(前面已讲)
// 板斧4:批量处理用 Batch API
// 离线任务(报告生成、批量处理)用百炼的 Batch API,有折扣10.2 可观测性接入
go
management:
tracing:
sampling:
probability:0.1# 生产环境采样 10%,开发环境设为 1.0
spring:
ai:
observation:
include-prompt:false # 生产环境关闭(Prompt 可能含敏感信息)
include-completion:false通过 Spring AI 的 Observation 机制可以获取:每次调用的 Token 消耗、模型延迟、请求成功率。接入 Micrometer + Prometheus + Grafana,构建 AI 应用专属监控大盘。
10.3 熔断与降级
go
@Service
publicclass ResilientChatService {
privatefinal ChatClient primaryClient; // qwen-max(主)
privatefinal ChatClient fallbackClient; // qwen-turbo(降级)
public String chat(String message) {
try {
return primaryClient.prompt()
.user(message)
.call()
.content();
} catch (DashScopeException e) {
if (e.getStatusCode() == 429) {
// 限流时降级到 turbo
log.warn("主模型限流,降级到 qwen-turbo");
return fallbackClient.prompt()
.user(message)
.call()
.content();
}
throw e;
}
}
}十一、踩坑
花了两个多月把这些坑踩遍了,整理出来:
坑 1:Embedding 用了 Chat 模型 向量化必须用 text-embedding-v3 这类专用模型,用 Chat 模型做 Embedding 不仅效果差,还浪费大量 Token。症状:RAG 召回结果答非所问。
坑 2:换了 Embedding 模型没有重建索引不同 Embedding 模型的向量维度不同,VectorStore 里存的是旧模型的向量,新模型查出来的结果完全不对。换模型必须清库重建。
坑 3:流式输出在 Nginx 后面不 work Nginx 默认缓冲响应,SSE 流会被攒起来再发。需要加配置:proxy_buffering off; proxy_read_timeout 300s;
坑 4:Function Bean 名字冲突 多个 @Bean Function 注册同名会导致模型调用混乱。用 @Bean("uniqueFunctionName") 显式指定。
坑 5:Graph State 修改无效StateGraph 的 State 在节点间传递是不可变的(推荐 Record + Builder),直接修改字段不生效,必须返回新的 State 实例。
坑 6:SimpleVectorStore 生产 OOM这是内存实现,文档量超过几千条直接 OOM。生产必须换 Milvus、PGVector 或阿里云向量检索服务。
坑 7:结构化输出在高并发下偶发 NPE BeanOutputConverter 不是线程安全的,不要当单例注入,每次调用时 new 一个新实例。
总结
用一张图总结整个知识体系:

每一层都有对应的实战代码,跑通一个,再往下走。别一上来就冲 Agent,地基没打好,上面全是沙。
参考文档
-
Spring AI Alibaba 官方网站:https://java2ai.com
-
Spring AI 官方文档:https://docs.spring.io/spring-ai/reference
能看到这里的都是真爱,点个在看支持一下。有问题欢迎评论区留言,看到都会回复。