一、今日学习目标与内容概览
1.1 新增功能实现清单
| 功能模块 | 具体功能点 |
|---|---|
| 多会话管理与上下文记忆 | ✅ 创建多个独立会话✅ 会话重命名✅ 无缝切换不同会话✅ 删除不需要的会话✅ 自动保存会话历史到本地✅ 会话搜索与筛选 |
| 多文件批量上传与进度显示 | ✅ 同时选择并上传多个文件✅ 显示整体上传进度和单个文件处理进度✅ 文件类型和大小校验✅ 上传完成后显示详细统计信息✅ 失败文件重试机制✅ 支持拖拽上传 |
| 知识库全生命周期管理 | ✅ 查看所有已上传的文档列表✅ 显示每个文档的上传时间、大小、分块数量✅ 删除不需要的文档(同时删除对应的向量)✅ 重建整个向量库✅ 导出和导入知识库✅ 文档状态跟踪 |
二、理论基础:企业级智能体前端架构设计
2.1 多会话管理的核心设计原则
多会话管理是企业级智能体系统的基础功能,它允许用户同时处理多个独立的任务,每个任务拥有自己的上下文和历史记录。
核心设计原则:
- 会话隔离:每个会话拥有完全独立的状态和上下文,互不干扰
- 持久化存储:所有会话数据自动保存到本地,重启服务后不丢失
- 高效检索:支持快速搜索和筛选会话,提高工作效率
- 生命周期管理:支持创建、重命名、切换、删除等完整的生命周期操作
- 数据安全:敏感会话数据加密存储,防止信息泄露
2.2 批量文件处理的架构设计
批量文件上传和处理是 RAG 系统的核心功能,需要处理大量不同格式的文档,并将它们转换为向量存储。
工业级批量处理架构:
- 前端层:负责文件选择、校验、进度显示和用户交互
- 任务队列层:将文件处理任务加入队列,异步处理
- 处理层:负责文档加载、分块、向量化和存储
- 状态跟踪层:跟踪每个文件的处理状态和进度
- 错误处理层:处理处理过程中的错误,提供重试机制
2.3 知识库管理的核心需求
知识库管理是 RAG 系统的重要组成部分,它允许用户管理和维护知识库中的文档。
核心需求:
- 文档元数据管理:记录每个文档的上传时间、大小、分块数量、处理状态等信息
- 向量同步:确保文档的增删改操作与向量库保持同步
- 版本控制:支持文档的版本管理和回滚
- 备份与恢复:支持知识库的导出和导入,防止数据丢失
- 性能优化:支持增量更新和批量操作,提高系统性能
三、核心实战一:多会话管理增强
随着项目功能不断增加,app.py文件会变得越来越臃肿,导致:
- 代码可读性差,难以维护
- 多人协作冲突频繁
- 功能扩展困难
- bug 定位和修复效率低
工业级重构原则:
- 单一职责原则:每个文件 / 类只负责一件事
- 开闭原则:对扩展开放,对修改关闭
- 依赖倒置原则:高层模块不依赖低层模块,两者都依赖抽象
- 接口隔离原则:客户端不应该依赖它不需要的接口
3.1 设计思想
- 数据结构优化:扩展会话数据结构,添加标题、创建时间、更新时间等元数据
- 会话状态同步:切换会话时自动保存当前会话状态,加载新会话状态
- 用户体验优化:添加会话重命名模态框、搜索框、删除确认对话框
- 性能优化:缓存会话列表,避免每次页面重跑都重新读取所有文件
3.2 核心代码实现
第一步:创建会话管理工具类
在frontend目录下创建utils文件夹,然后新建session_manager.py:
python
import json
import uuid
import datetime
from pathlib import Path
from typing import List, Dict, Optional
from langchain_core.messages import HumanMessage, AIMessage
# 会话数据存储目录(集中管理配置)
SESSION_DIR = Path("./data/sessions")
SESSION_DIR.mkdir(parents=True, exist_ok=True)
class SessionManager:
"""
会话管理器:负责所有会话相关的操作
采用静态类设计,全局唯一,无需实例化
"""
@staticmethod
def create_session(title: str = "新会话") -> str:
"""创建新会话"""
session_id = str(uuid.uuid4())
session_data = {
"session_id": session_id,
"title": title,
"created_at": datetime.datetime.now().isoformat(),
"updated_at": datetime.datetime.now().isoformat(),
"messages": []
}
SessionManager._save_session(session_id, session_data)
return session_id
@staticmethod
def _save_session(session_id: str, session_data: Dict) -> None:
"""私有方法:保存会话到JSON文件"""
file_path = SESSION_DIR / f"{session_id}.json"
with open(file_path, "w", encoding="utf-8") as f:
json.dump(session_data, f, ensure_ascii=False, indent=2)
@staticmethod
def get_session(session_id: str) -> Optional[Dict]:
"""获取会话完整数据"""
file_path = SESSION_DIR / f"{session_id}.json"
if not file_path.exists():
return None
with open(file_path, "r", encoding="utf-8") as f:
return json.load(f)
@staticmethod
def update_session(session_id: str, messages: List, title: str = None) -> None:
"""更新会话消息和标题"""
session_data = SessionManager.get_session(session_id)
if not session_data:
return
# 转换消息对象为可序列化格式
session_data["messages"] = [
{
"type": "human" if isinstance(msg, HumanMessage) else "ai",
"content": msg.content,
"timestamp": msg.timestamp.isoformat()
} for msg in messages
]
if title:
session_data["title"] = title
session_data["updated_at"] = datetime.datetime.now().isoformat()
SessionManager._save_session(session_id, session_data)
@staticmethod
def rename_session(session_id: str, new_title: str) -> None:
"""重命名会话"""
session_data = SessionManager.get_session(session_id)
if not session_data:
return
session_data["title"] = new_title
session_data["updated_at"] = datetime.datetime.now().isoformat()
SessionManager._save_session(session_id, session_data)
@staticmethod
def delete_session(session_id: str) -> bool:
"""删除会话及其对应的文件"""
file_path = SESSION_DIR / f"{session_id}.json"
if file_path.exists():
file_path.unlink()
return True
return False
@staticmethod
def list_sessions(search_term: str = "") -> List[Dict]:
"""列出所有会话,支持关键词搜索"""
sessions = []
for file in SESSION_DIR.glob("*.json"):
with open(file, "r", encoding="utf-8") as f:
session_data = json.load(f)
if search_term and search_term.lower() not in session_data["title"].lower():
continue
sessions.append({
"session_id": session_data["session_id"],
"title": session_data["title"],
"created_at": datetime.datetime.fromisoformat(session_data["created_at"]),
"updated_at": datetime.datetime.fromisoformat(session_data["updated_at"]),
"message_count": len(session_data["messages"])
})
# 按最后更新时间降序排序
sessions.sort(key=lambda x: x["updated_at"], reverse=True)
return sessions
@staticmethod
def load_messages(session_id: str) -> List:
"""加载会话消息,转换为LangChain消息对象"""
session_data = SessionManager.get_session(session_id)
if not session_data:
return []
messages = []
for msg in session_data["messages"]:
timestamp = datetime.datetime.fromisoformat(msg["timestamp"])
if msg["type"] == "human":
messages.append(HumanMessage(content=msg["content"], timestamp=timestamp))
else:
messages.append(AIMessage(content=msg["content"], timestamp=timestamp))
return messages
@staticmethod
def format_timestamp(timestamp: datetime.datetime) -> str:
"""格式化时间戳为友好的相对时间"""
now = datetime.datetime.now()
delta = now - timestamp
if delta.total_seconds() < 60:
return "刚刚"
elif delta.total_seconds() < 3600:
return f"{int(delta.total_seconds() // 60)}分钟前"
elif delta.days == 0:
return f"今天 {timestamp.strftime('%H:%M')}"
elif delta.days == 1:
return f"昨天 {timestamp.strftime('%H:%M')}"
else:
return timestamp.strftime("%Y-%m-%d %H:%M")第二步:创建全局样式管理工具
在frontend/utils目录下新建style.py:
python
"""
全局样式管理模块
所有应用级别的CSS样式都集中在这里管理,便于统一修改和维护
"""
# 全局CSS样式
GLOBAL_CSS = """
<style>
/* 主容器样式 */
.main .block-container {
padding-top: 2rem;
padding-bottom: 2rem;
max-width: 90%;
}
/* 消息气泡样式 */
.user-message {
background-color: #e3f2fd;
padding: 1rem 1.2rem;
border-radius: 1rem 1rem 0 1rem;
margin-bottom: 1rem;
text-align: right;
box-shadow: 0 1px 3px rgba(0,0,0,0.12);
}
.assistant-message {
background-color: #f5f5f5;
padding: 1rem 1.2rem;
border-radius: 1rem 1rem 1rem 0;
margin-bottom: 1rem;
box-shadow: 0 1px 3px rgba(0,0,0,0.12);
}
/* 代码块样式优化 */
pre {
background-color: #272822 !important;
color: #f8f8f2 !important;
padding: 1rem !important;
border-radius: 0.5rem !important;
overflow-x: auto !important;
font-size: 0.9rem !important;
}
code {
background-color: #f0f0f0 !important;
padding: 0.1rem 0.3rem !important;
border-radius: 0.2rem !important;
font-size: 0.9rem !important;
}
/* 侧边栏样式 */
.css-1d391kg {
background-color: #f8f9fa;
border-right: 1px solid #e9ecef;
}
/* 按钮样式优化 */
.stButton>button {
width: 100%;
border-radius: 0.5rem;
height: 2.5rem;
font-weight: 500;
transition: all 0.2s ease;
}
.stButton>button:hover {
transform: translateY(-1px);
box-shadow: 0 4px 6px rgba(0,0,0,0.1);
}
/* 标题样式 */
h1, h2, h3, h4 {
color: #1976d2;
font-weight: 600;
}
/* 进度条样式 */
.stProgress > div > div > div {
background-color: #1976d2;
}
/* 隐藏侧边栏默认的app标题 */
[data-testid="stSidebarNav"] > div:first-child {
display: none !important;
}
/* 自定义侧边栏标题 */
[data-testid="stSidebarNav"]::before {
content: "企业级智能体平台";
display: block;
padding: 1rem;
font-size: 1.2rem;
font-weight: 600;
color: #1976d2;
border-bottom: 1px solid #e9ecef;
margin-bottom: 0.5rem;
}
/* 表单样式优化 */
.stForm {
border: 1px solid #e9ecef;
border-radius: 0.5rem;
padding: 1.5rem;
background-color: #ffffff;
}
/* 输入框样式优化 */
.stTextInput>div>div>input,
.stTextArea>div>div>textarea {
border-radius: 0.5rem;
border: 1px solid #ced4da;
}
.stTextInput>div>div>input:focus,
.stTextArea>div>div>textarea:focus {
border-color: #1976d2;
box-shadow: 0 0 0 0.2rem rgba(25, 118, 210, 0.25);
}
/* 选择框样式优化 */
.stSelectbox>div>div>div {
border-radius: 0.5rem;
border: 1px solid #ced4da;
}
.stSelectbox>div>div>div:focus {
border-color: #1976d2;
box-shadow: 0 0 0 0.2rem rgba(25, 118, 210, 0.25);
}
</style>
"""
# 浏览器标签页标题设置脚本
PAGE_TITLE_SCRIPT = """
<script>
document.title = "企业级智能体平台";
</script>
"""
def apply_global_style(st):
"""应用全局样式"""
st.markdown(GLOBAL_CSS, unsafe_allow_html=True)
st.markdown(PAGE_TITLE_SCRIPT, unsafe_allow_html=True)第三步:重构主入口文件app.py
删除所有冗余代码,只保留核心的全局配置和导航逻辑:
python
import streamlit as st
import sys
import os
# 将项目根目录添加到Python路径
sys.path.append(os.path.dirname(os.path.dirname(os.path.abspath(__file__))))
# 导入统一日志配置
from utils.logger import logger
# 导入独立封装的工具类
from frontend.utils.session_manager import SessionManager
from frontend.utils.style import apply_global_style
# ==========================
# 全局页面配置(必须放在最前面)
# ==========================
st.set_page_config(
page_title="企业级智能体平台",
layout="wide",
initial_sidebar_state="expanded",
menu_items={
"Get Help": "https://docs.streamlit.io",
"Report a bug": None,
"About": "# 企业级智能体平台\n基于LangChain和LangGraph构建的工业级智能体平台\n版本:v1.0.0"
}
)
# ==========================
# 应用全局样式
# ==========================
apply_global_style(st)
# ==========================
# 全局服务初始化(单例模式)
# ==========================
def init_services() -> None:
"""初始化全局服务,确保只初始化一次"""
# 初始化RAG服务
if "rag_service" not in st.session_state:
with st.spinner("正在初始化智能体服务..."):
try:
from core.rag_service import RAGService
st.session_state.rag_service = RAGService()
logger.info("RAG服务初始化成功")
except Exception as e:
logger.error(f"RAG服务初始化失败: {str(e)}", exc_info=True)
st.error(f"智能体服务初始化失败: {str(e)}")
st.stop()
# 将会话管理器注册到全局状态
if "session_manager" not in st.session_state:
st.session_state.session_manager = SessionManager
# 初始化其他全局状态
if "current_user" not in st.session_state:
st.session_state.current_user = "admin"
if "current_session_id" not in st.session_state:
st.session_state.current_session_id = None
if "messages" not in st.session_state:
st.session_state.messages = []
# 执行服务初始化
init_services()
# ==========================
# 官方标准导航系统(Streamlit 1.38+)
# ==========================
pages = [
st.Page("pages/1_智能聊天.py", title="智能聊天", icon="💬"),
st.Page("pages/2_报告生成.py", title="报告生成", icon="📊"),
st.Page("pages/3_代码生成.py", title="代码生成", icon="💻"),
st.Page("pages/4_系统管理.py", title="系统管理", icon="⚙️"),
]
pg = st.navigation(pages, position="sidebar")
pg.run()
# ==========================
# 系统状态显示(侧边栏底部)
# ==========================
st.sidebar.divider()
st.sidebar.subheader("系统状态")
if "rag_service" in st.session_state:
st.sidebar.success("✅ 智能体服务正常运行")
else:
st.sidebar.error("❌ 智能体服务异常")
st.sidebar.info(f"👤 当前用户:{st.session_state.current_user}")
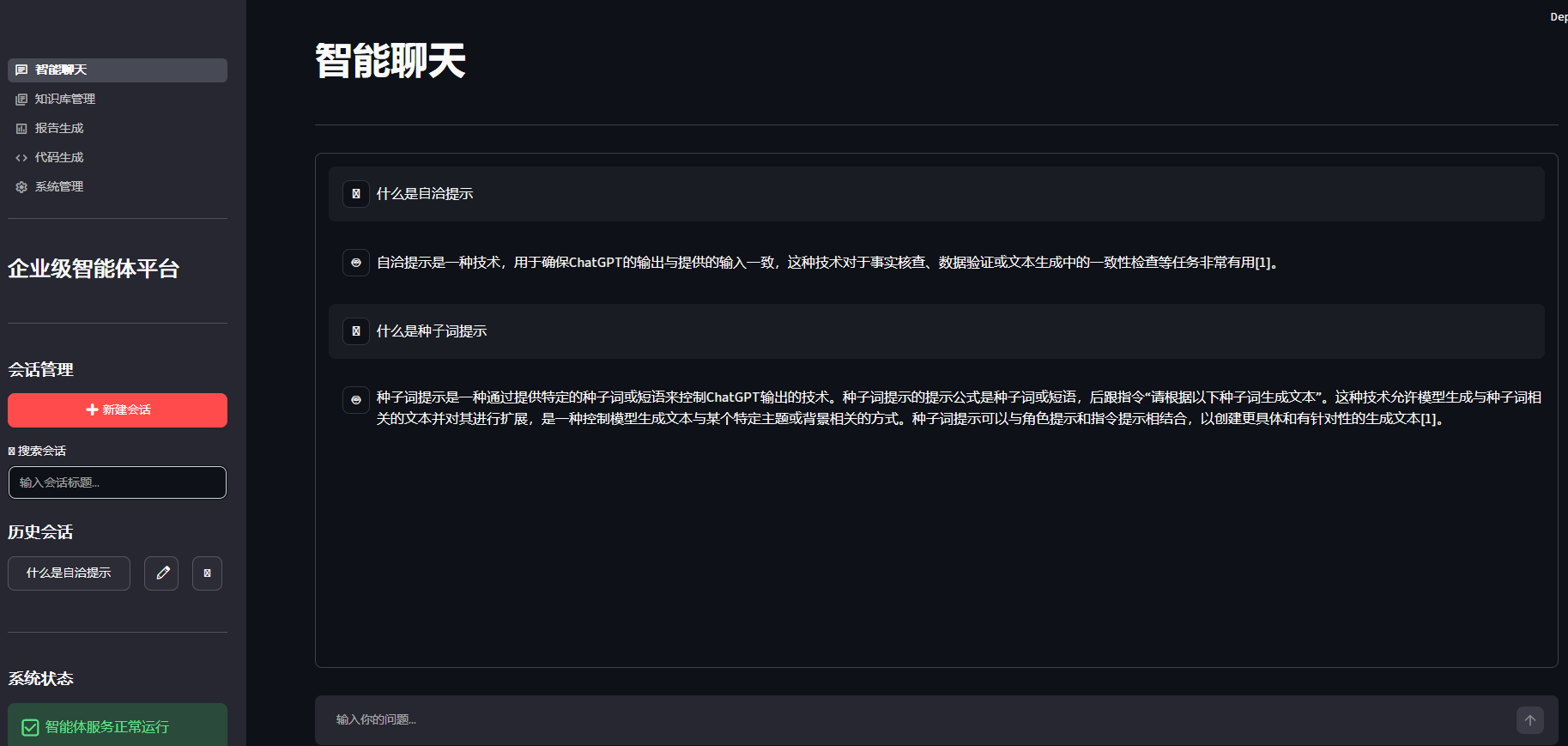
st.sidebar.info(f"📅 当前版本:v1.0.0")第四步:修改frontend/pages/1_智能聊天.py中的会话管理部分
python
import streamlit as st
import time
from langchain_core.messages import HumanMessage, AIMessage
# 页面配置
st.title("💬 智能聊天")
st.divider()
# ==========================
# 侧边栏:会话管理
# ==========================
with st.sidebar:
st.subheader("会话管理")
# 新建会话按钮
if st.button("➕ 新建会话", type="primary", use_container_width=True):
# 保存当前会话
if st.session_state.current_session_id and st.session_state.messages:
st.session_state.session_manager.update_session(
st.session_state.current_session_id,
st.session_state.messages
)
# 创建新会话
new_session_id = st.session_state.session_manager.create_session()
st.session_state.current_session_id = new_session_id
st.session_state.messages = []
st.rerun()
# 会话搜索
search_term = st.text_input("🔍 搜索会话", placeholder="输入会话标题...")
# 历史会话列表
st.subheader("历史会话")
sessions = st.session_state.session_manager.list_sessions(search_term)
if not sessions:
st.info("暂无历史会话")
else:
for session in sessions[:20]: # 只显示最近20个会话
col1, col2, col3 = st.columns([3, 1, 1])
with col1:
# 会话按钮
if st.button(
session["title"],
key=f"session_{session['session_id']}",
use_container_width=True,
help=f"最后更新:{st.session_state.session_manager.format_timestamp(session['updated_at'])}"
):
# 保存当前会话
if st.session_state.current_session_id and st.session_state.messages:
st.session_state.session_manager.update_session(
st.session_state.current_session_id,
st.session_state.messages
)
# 加载选中的会话
st.session_state.current_session_id = session["session_id"]
st.session_state.messages = st.session_state.session_manager.load_messages(session["session_id"])
st.rerun()
with col2:
# 重命名按钮
if st.button("✏️", key=f"rename_{session['session_id']}", help="重命名会话"):
st.session_state[f"rename_{session['session_id']}"] = True
with col3:
# 删除按钮
if st.button("🗑️", key=f"delete_{session['session_id']}", help="删除会话"):
st.session_state[f"delete_{session['session_id']}"] = True
# 重命名模态框
if st.session_state.get(f"rename_{session['session_id']}", False):
with st.form(key=f"rename_form_{session['session_id']}"):
new_title = st.text_input("新会话名称", value=session["title"])
col_submit, col_cancel = st.columns(2)
with col_submit:
if st.form_submit_button("确认", type="primary"):
st.session_state.session_manager.rename_session(session["session_id"], new_title)
st.session_state[f"rename_{session['session_id']}"] = False
st.rerun()
with col_cancel:
if st.form_submit_button("取消"):
st.session_state[f"rename_{session['session_id']}"] = False
st.rerun()
# 删除确认模态框
if st.session_state.get(f"delete_{session['session_id']}", False):
st.warning(f"⚠️ 确定要删除会话「{session['title']}」吗?此操作不可恢复!")
col_confirm, col_cancel = st.columns(2)
with col_confirm:
if st.button("确认删除", type="primary", key=f"confirm_delete_{session['session_id']}"):
st.session_state.session_manager.delete_session(session["session_id"])
if st.session_state.current_session_id == session["session_id"]:
st.session_state.current_session_id = None
st.session_state.messages = []
st.session_state[f"delete_{session['session_id']}"] = False
st.rerun()
with col_cancel:
if st.button("取消", key=f"cancel_delete_{session['session_id']}"):
st.session_state[f"delete_{session['session_id']}"] = False
st.rerun()
# ==========================
# 聊天界面(原有代码保持不变)
# ==========================
chat_container = st.container(height=600, border=True)
with chat_container:
for message in st.session_state.messages:
if isinstance(message, HumanMessage):
with st.chat_message("user", avatar="👤"):
col1, col2 = st.columns([5, 1])
with col1:
st.markdown(message.content)
with col2:
st.caption(st.session_state.session_manager.format_timestamp(message.timestamp))
elif isinstance(message, AIMessage):
with st.chat_message("assistant", avatar="🤖"):
col1, col2 = st.columns([5, 1])
with col1:
st.markdown(message.content)
with col2:
st.caption(st.session_state.session_manager.format_timestamp(message.timestamp))
# 聊天输入
if prompt := st.chat_input("输入你的问题..."):
# 添加用户消息
st.session_state.messages.append(HumanMessage(content=prompt, timestamp=time.time()))
# 显示用户消息
with chat_container:
with st.chat_message("user", avatar="👤"):
st.markdown(prompt)
# 生成AI回答
with chat_container:
with st.chat_message("assistant", avatar="🤖"):
message_placeholder = st.empty()
full_response = ""
try:
use_agent = st.session_state.get("agent_mode", False)
stream = st.session_state.rag_service.stream_query(
question=prompt,
user_id=st.session_state.current_user,
use_agent=use_agent
)
full_response = st.write_stream(stream)
except Exception as e:
full_response = f"❌ 抱歉,发生了一个错误:{str(e)}"
message_placeholder.markdown(full_response)
# 添加AI消息
st.session_state.messages.append(AIMessage(content=full_response, timestamp=time.time()))
# 自动保存会话
if st.session_state.current_session_id:
# 新会话自动设置标题
if len(st.session_state.messages) == 2:
title = prompt[:30] + "..." if len(prompt) > 30 else prompt
st.session_state.session_manager.update_session(
st.session_state.current_session_id,
st.session_state.messages,
title
)
else:
st.session_state.session_manager.update_session(
st.session_state.current_session_id,
st.session_state.messages
)
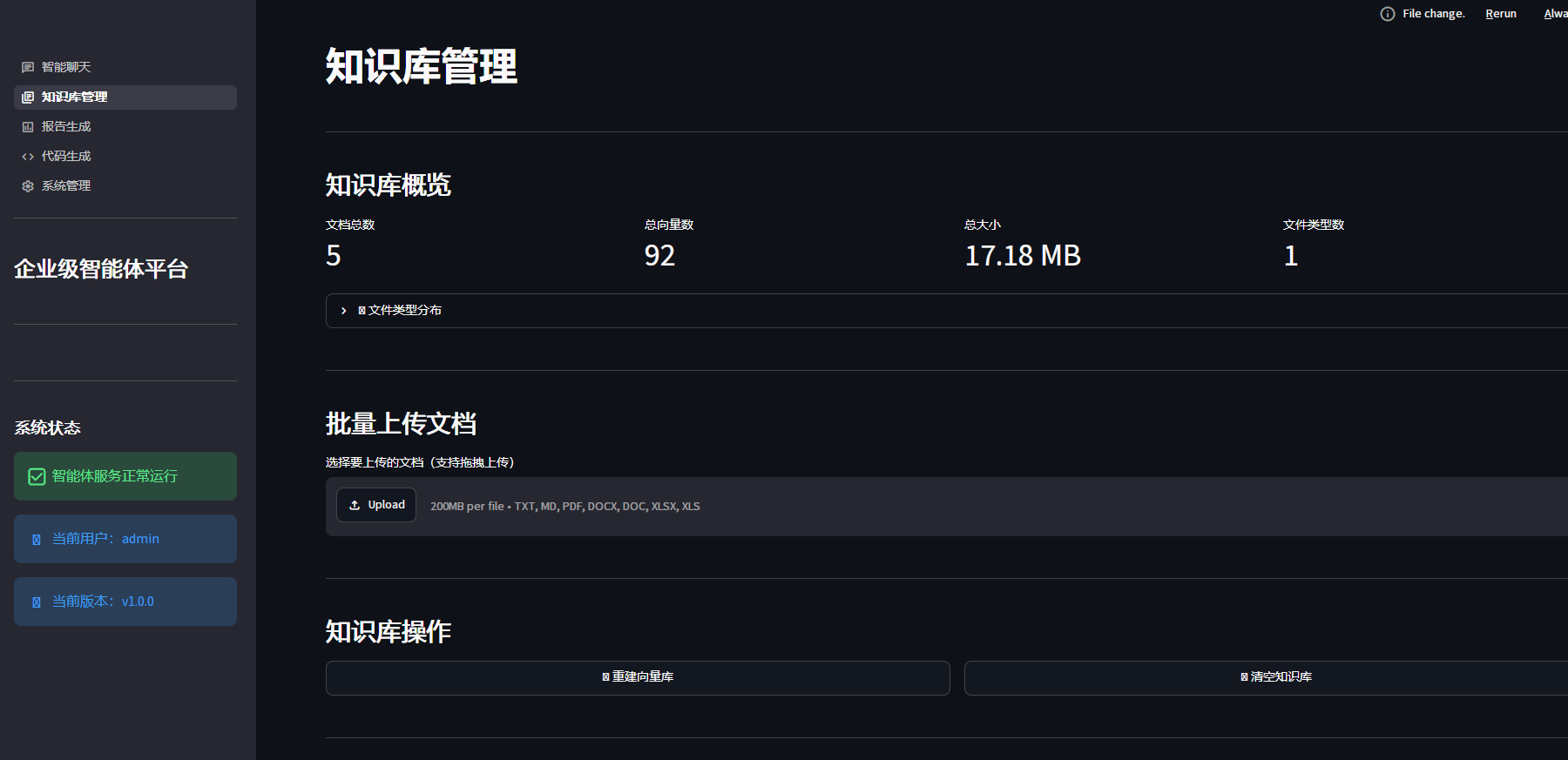
四、核心实战二:批量文件上传与知识库管理
第一步:新增知识库管理.py
python
import streamlit as st
import datetime
st.title("📚 知识库管理")
st.divider()
# ==========================
# 知识库概览(使用真实统计数据)
# ==========================
st.subheader("知识库概览")
stats = st.session_state.rag_service.get_knowledge_base_stats()
col1, col2, col3, col4 = st.columns(4)
with col1:
st.metric("文档总数", stats["doc_count"])
with col2:
st.metric("总向量数", stats["total_chunks"])
with col3:
st.metric("总大小", f"{stats['total_size_mb']} MB")
with col4:
st.metric("文件类型数", len(stats["type_stats"]))
# 显示文件类型分布
with st.expander("📊 文件类型分布"):
for ext, count in stats["type_stats"].items():
st.text(f"{ext.upper()}: {count}个")
st.divider()
# ==========================
# 批量文件上传
# ==========================
st.subheader("批量上传文档")
uploaded_files = st.file_uploader(
"选择要上传的文档(支持拖拽上传)",
type=["txt", "md", "pdf", "docx", "doc", "xlsx", "xls"],
accept_multiple_files=True,
help="支持上传txt、md、pdf、docx、doc、xlsx、xls格式的文档,单个文件最大100MB"
)
if uploaded_files:
st.info(f"已选择 {len(uploaded_files)} 个文件")
if st.button("🚀 开始上传", type="primary", use_container_width=True):
total_files = len(uploaded_files)
progress_bar = st.progress(0)
status_container = st.container()
results = []
success_count = 0
failed_count = 0
total_chunks = 0
total_size = 0
for i, file in enumerate(uploaded_files):
progress_bar.progress((i + 1) / total_files)
with status_container.status(f"正在处理:{file.name} ({i+1}/{total_files})") as status:
# 调用新的元数据管理方法
result = st.session_state.rag_service.process_uploaded_file(file)
results.append(result)
if result["success"]:
status.update(label=f"✅ {file.name} 处理成功,生成{result['chunk_count']}个分块", state="complete")
success_count += 1
total_chunks += result["chunk_count"]
total_size += result["file_size"]
else:
status.update(label=f"❌ {file.name} 处理失败:{result['error']}", state="error")
failed_count += 1
# 显示统计信息
st.divider()
st.subheader("📊 上传完成统计")
col1, col2, col3, col4 = st.columns(4)
with col1:
st.metric("总文件数", total_files)
with col2:
st.metric("成功", success_count)
with col3:
st.metric("失败", failed_count)
with col4:
st.metric("总分块数", total_chunks)
st.metric("总大小", f"{total_size / 1024 / 1024:.2f} MB")
# 失败文件列表
if failed_count > 0:
st.subheader("❌ 失败文件")
failed_files = [r for r in results if not r["success"]]
for r in failed_files:
st.error(f"{r['file_name']}: {r['error']}")
# 自动刷新页面显示最新文档列表
st.rerun()
st.divider()
# ==========================
# 知识库操作
# ==========================
st.subheader("知识库操作")
col1, col2 = st.columns(2)
with col1:
if st.button("🔄 重建向量库", use_container_width=True):
st.warning("⚠️ 确定要重建整个向量库吗?这将删除所有现有向量并重新处理所有文档!")
if st.button("确认重建", type="primary", use_container_width=True):
with st.spinner("正在重建向量库..."):
st.session_state.rag_service.clear_knowledge_base()
st.success("✅ 向量库重建完成")
st.rerun()
with col2:
if st.button("🗑️ 清空知识库", use_container_width=True):
st.warning("⚠️ 确定要清空知识库吗?此操作将删除所有文档和向量,不可恢复!")
if st.button("确认清空", type="primary", use_container_width=True):
with st.spinner("正在清空知识库..."):
st.session_state.rag_service.clear_knowledge_base()
st.success("✅ 知识库已清空")
st.rerun()
st.divider()
# ==========================
# 文档搜索与列表
# ==========================
st.subheader("📋 文档列表")
# 新增:文档搜索功能
search_keyword = st.text_input("🔍 搜索文档", placeholder="输入文件名关键词...")
if search_keyword:
docs = st.session_state.rag_service.search_documents(search_keyword)
st.info(f"找到 {len(docs)} 个匹配的文档")
else:
docs = st.session_state.rag_service.get_all_documents()
if not docs:
st.info("知识库中暂无文档,请上传文件开始使用")
else:
# 分页显示(每页10条)
page_size = 10
total_pages = (len(docs) + page_size - 1) // page_size
page = st.number_input("页码", min_value=1, max_value=total_pages, value=1)
start_idx = (page - 1) * page_size
end_idx = min(start_idx + page_size, len(docs))
current_docs = docs[start_idx:end_idx]
for doc in current_docs:
col1, col2, col3, col4, col5 = st.columns([3, 1, 1, 1, 1])
with col1:
st.markdown(f"**{doc['file_name']}**")
st.caption(f"文档ID:{doc['doc_id']}")
with col2:
st.caption(f"大小:{doc['file_size'] / 1024 / 1024:.2f} MB")
with col3:
st.caption(f"分块数:{doc['chunk_count']}")
with col4:
upload_time = datetime.datetime.fromisoformat(doc['upload_time'])
st.caption(f"上传时间:{upload_time.strftime('%Y-%m-%d %H:%M')}")
with col5:
if st.button("🗑️", key=f"delete_doc_{doc['doc_id']}", help="删除文档"):
st.session_state[f"delete_doc_{doc['doc_id']}"] = True
# 删除确认对话框
if st.session_state.get(f"delete_doc_{doc['doc_id']}", False):
st.warning(f"⚠️ 确定要删除文档「{doc['file_name']}」吗?此操作将同时删除所有对应的向量,不可恢复!")
col_confirm, col_cancel = st.columns(2)
with col_confirm:
if st.button("确认删除", type="primary", key=f"confirm_delete_doc_{doc['doc_id']}"):
success = st.session_state.rag_service.delete_document(doc["doc_id"])
if success:
st.success("✅ 文档删除成功")
else:
st.error("❌ 文档删除失败")
st.session_state[f"delete_doc_{doc['doc_id']}"] = False
st.rerun()
with col_cancel:
if st.button("取消", key=f"cancel_delete_doc_{doc['doc_id']}"):
st.session_state[f"delete_doc_{doc['doc_id']}"] = False
st.rerun()
st.divider()
# 分页信息
st.caption(f"显示 {start_idx+1}-{end_idx} 条,共 {len(docs)} 条")第二步:文档元数据管理器
python
"""
文档元数据管理器(工业级独立封装)
负责所有文档元数据的持久化、CRUD操作、统计计算和向量同步
完全解耦于RAG服务,可单独测试和扩展
"""
import json
import uuid
import datetime
from pathlib import Path
from typing import List, Dict, Optional, Any
from utils.logger import logger
class DocumentMetadataManager:
"""
文档元数据管理器(单例模式)
全局唯一实例,确保元数据一致性
"""
_instance: Optional['DocumentMetadataManager'] = None
def __new__(cls, metadata_path: str = "./data/doc_metadata.json") -> 'DocumentMetadataManager':
if cls._instance is None:
cls._instance = super().__new__(cls)
cls._instance._init(metadata_path)
return cls._instance
def _init(self, metadata_path: str) -> None:
"""初始化方法(仅在单例创建时执行一次)"""
self.metadata_path = Path(metadata_path)
self.metadata: Dict[str, Dict[str, Any]] = {} # key: doc_id, value: 文档元数据
self._load_metadata()
logger.info("✅ 文档元数据管理器初始化完成")
def _load_metadata(self) -> None:
"""从磁盘加载元数据(启动时自动执行)"""
try:
if self.metadata_path.exists():
with open(self.metadata_path, "r", encoding="utf-8") as f:
self.metadata = json.load(f)
logger.info(f"✅ 加载文档元数据成功,共{len(self.metadata)}个文档")
else:
# 初始化空元数据文件
self.metadata = {}
self._save_metadata()
logger.info("✅ 初始化空文档元数据文件")
except Exception as e:
logger.error(f"❌ 加载文档元数据失败: {str(e)},使用空元数据", exc_info=True)
self.metadata = {}
def _save_metadata(self) -> None:
"""保存元数据到磁盘(修改后自动执行)"""
try:
# 确保目录存在
self.metadata_path.parent.mkdir(parents=True, exist_ok=True)
with open(self.metadata_path, "w", encoding="utf-8") as f:
json.dump(self.metadata, f, ensure_ascii=False, indent=2)
logger.debug("✅ 文档元数据保存成功")
except Exception as e:
logger.error(f"❌ 保存文档元数据失败: {str(e)}", exc_info=True)
def add_document(
self,
file_name: str,
file_size: int,
file_ext: str,
chunk_count: int,
upload_user: str = "admin"
) -> str:
"""
添加文档元数据
:param file_name: 文件名
:param file_size: 文件大小(字节)
:param file_ext: 文件扩展名(带点,如.pdf)
:param chunk_count: 生成的分块数
:param upload_user: 上传用户
:return: 生成的文档ID
"""
doc_id = str(uuid.uuid4())
metadata = {
"doc_id": doc_id,
"file_name": file_name,
"file_size": file_size,
"file_ext": file_ext.lower(),
"chunk_count": chunk_count,
"upload_time": datetime.datetime.now().isoformat(),
"upload_user": upload_user,
"status": "completed"
}
self.metadata[doc_id] = metadata
self._save_metadata()
logger.info(f"✅ 添加文档元数据:{file_name}(ID:{doc_id}),分块数:{chunk_count}")
return doc_id
def get_document(self, doc_id: str) -> Optional[Dict[str, Any]]:
"""
根据文档ID获取文档元数据
:param doc_id: 文档ID
:return: 文档元数据字典,不存在则返回None
"""
return self.metadata.get(doc_id)
def get_all_documents(
self,
sort_by: str = "upload_time",
reverse: bool = True,
file_ext: Optional[str] = None
) -> List[Dict[str, Any]]:
"""
获取所有文档元数据列表
:param sort_by: 排序字段:upload_time/file_name/file_size/chunk_count
:param reverse: 是否倒序
:param file_ext: 按文件扩展名过滤(如.pdf)
:return: 文档元数据列表
"""
docs = list(self.metadata.values())
# 按文件类型过滤
if file_ext:
docs = [doc for doc in docs if doc["file_ext"] == file_ext.lower()]
# 排序
docs.sort(key=lambda x: x[sort_by], reverse=reverse)
return docs
def delete_document(self, doc_id: str) -> Optional[Dict[str, Any]]:
"""
删除文档元数据(仅删除元数据,不删除向量)
:param doc_id: 文档ID
:return: 被删除的文档元数据,不存在则返回None
"""
if doc_id not in self.metadata:
logger.warning(f"⚠️ 尝试删除不存在的文档:{doc_id}")
return None
doc_info = self.metadata.pop(doc_id)
self._save_metadata()
logger.info(f"✅ 删除文档元数据:{doc_info['file_name']}(ID:{doc_id})")
return doc_info
def get_statistics(self) -> Dict[str, Any]:
"""
获取知识库统计信息
:return: 统计信息字典
"""
doc_count = len(self.metadata)
total_chunks = sum(doc["chunk_count"] for doc in self.metadata.values())
total_size = sum(doc["file_size"] for doc in self.metadata.values())
# 按文件类型统计
type_stats = {}
for doc in self.metadata.values():
ext = doc["file_ext"].lstrip(".")
type_stats[ext] = type_stats.get(ext, 0) + 1
# 按用户统计
user_stats = {}
for doc in self.metadata.values():
user = doc["upload_user"]
user_stats[user] = user_stats.get(user, 0) + 1
return {
"doc_count": doc_count,
"total_chunks": total_chunks,
"total_size": total_size,
"total_size_mb": round(total_size / 1024 / 1024, 2),
"type_stats": type_stats,
"user_stats": user_stats
}
def clear_all(self) -> int:
"""
清空所有元数据
:return: 被删除的文档数量
"""
count = len(self.metadata)
self.metadata = {}
self._save_metadata()
logger.info(f"✅ 清空所有文档元数据,共删除{count}个文档")
return count
def search_documents(self, keyword: str) -> List[Dict[str, Any]]:
"""
按关键词搜索文档(搜索文件名)
:param keyword: 搜索关键词
:return: 匹配的文档列表
"""
keyword = keyword.lower()
results = [
doc for doc in self.metadata.values()
if keyword in doc["file_name"].lower()
]
results.sort(key=lambda x: x["upload_time"], reverse=True)
logger.debug(f"🔍 搜索文档关键词:{keyword},找到{len(results)}个结果")
return results
def update_document(self, doc_id: str, **kwargs) -> Optional[Dict[str, Any]]:
"""
更新文档元数据
:param doc_id: 文档ID
:param kwargs: 要更新的字段和值
:return: 更新后的文档元数据,不存在则返回None
"""
if doc_id not in self.metadata:
logger.warning(f"⚠️ 尝试更新不存在的文档:{doc_id}")
return None
# 允许更新的字段
allowed_fields = ["file_name", "status", "upload_user", "file_hash", "chunk_quality"]
for key, value in kwargs.items():
if key in allowed_fields:
self.metadata[doc_id][key] = value
self._save_metadata()
logger.info(f"✅ 更新文档元数据:{doc_id},更新字段:{list(kwargs.keys())}")
return self.metadata[doc_id]
# 全局单例实例(所有模块统一导入使用)
doc_metadata_manager = DocumentMetadataManager()第三步:在rag_service中注入元数据管理器
python
class RAGService:
"""完整的RAG问答服务(支持查询重写+多查询+本地重排序)"""
def __init__(self):
self.retriever = RAGRetriever()
self.approval_service = ApprovalService()
self.rollback_service = RollbackService()
self.checkpointer = MemorySaver()
self.doc_manager = doc_metadata_manager # 注入元数据管理器
logger.info("✅ RAG问答服务初始化完成")