归纳偏好(inductive bias)
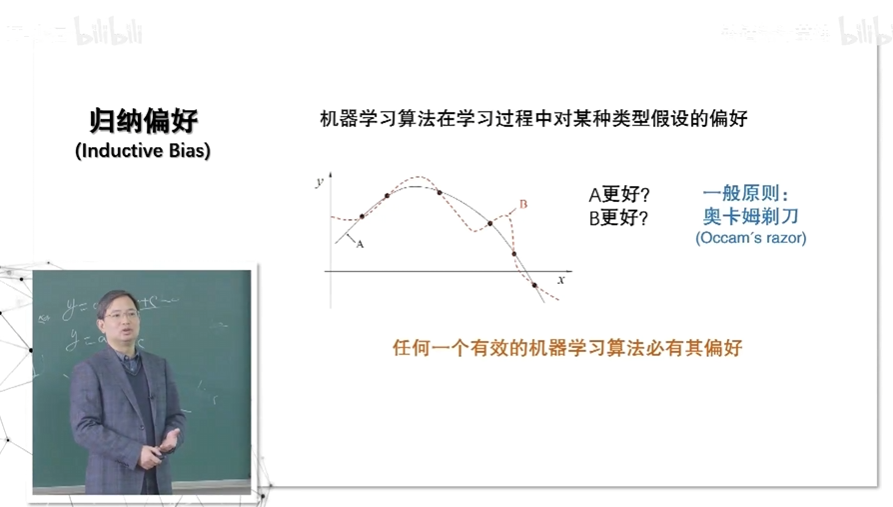
任何一个机器学习算法必有其偏好
很多模型都可以拟合现有训练数据,并且在测试集上达到类似的精度。那么我们如何选择哪一个模型作为我们的成果呢?
一般使用奥卡姆剃刀,若非必要勿增实体,选用最简单的一种。(上图中的A曲线更平滑更简单)
回答"什么是最简单的"这个问题并不简单
举例,下面那个方程式更简单:
y = ax2+bx+c,y = ax3+c
哪一个更简单呢?从变量多少的角度来衡量第二个更简单,但从指数大小来看第一个更简单,所以现实世界中对简单的理解往往是主观的。
什么模型(算法)是好的模型?
学习算法的归纳偏好(假设)与问题本身的匹配度,大多数时候直接决定了算法能否取得好的性能。
但是,衡量问题本身其实并不简单。我们必须对问题有清晰的认识才能选出好的模型。
那个算法更好?
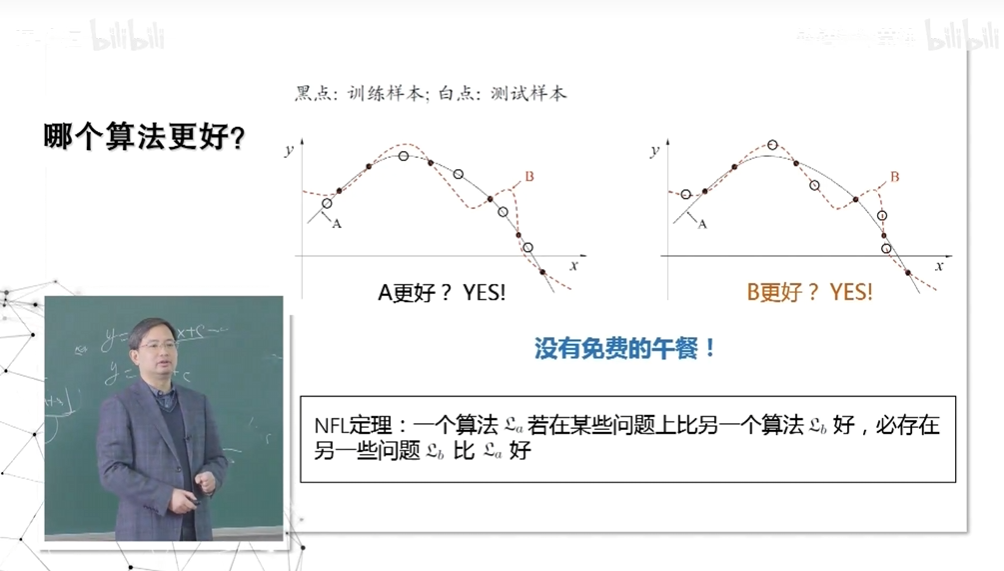

当我们谈到那个算法更好时,一定是基于具体问题的,脱离具体问题谈论算法的好坏没有意义。具体问题就是弄清楚,输入是什么输出是什么。

选择算法就像买衣服,最好的衣服都是量身定制的!
泛化能力
什么模型好?
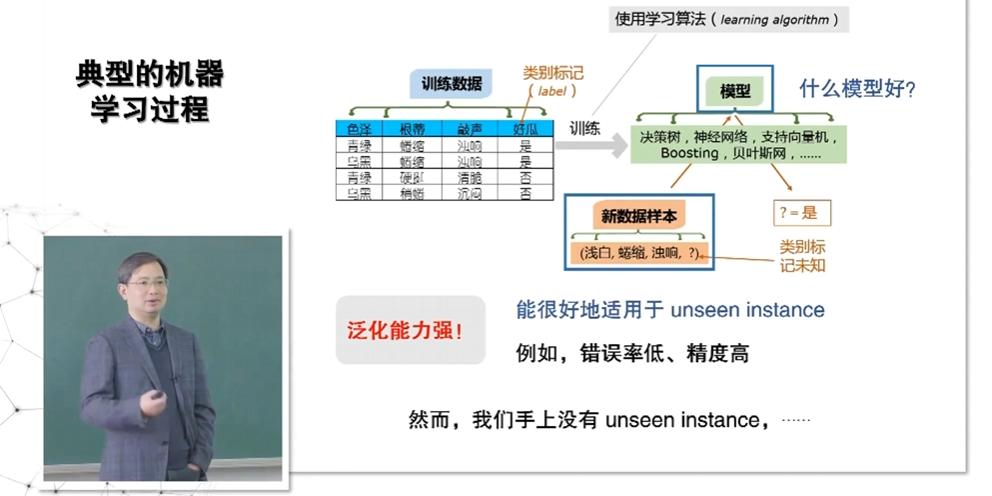
好是来自于具体问题的,得先搞清楚具体问题才能知道"你想要什么"。这就得搞清楚"你想要什么"
泛化误差VS经验误差

我们希望通过缩小经验误差来发现问题的规律进而降低泛化误差,这个隐藏的规律关联起了训练集和样本,似的机器学习有意义。
过拟合VS欠拟合

欠拟合,学到的规律不够多。
过拟合,错误的把非规律当做了规律。
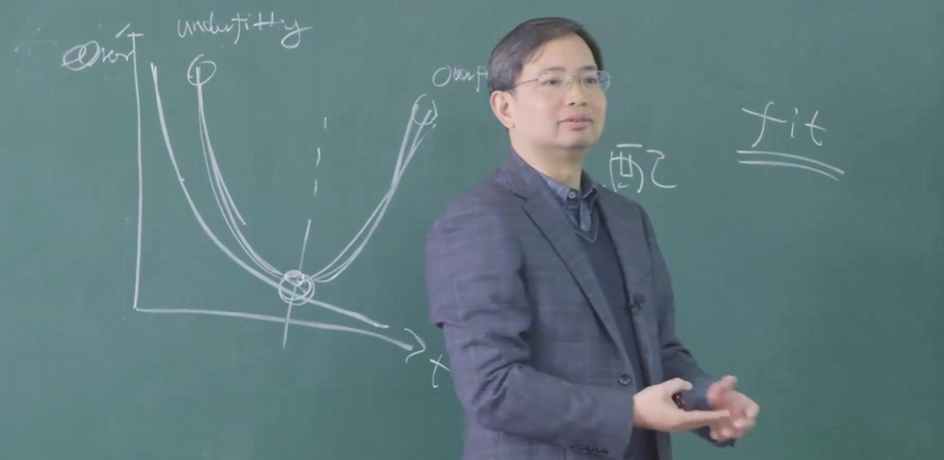
1.上图中,横轴是时间,纵轴是误差。训练集误差在不断降低,样本数据的误差先降低再升高(从欠拟合到过拟合)我们期望找到抛物线的最低点,但是理论上是找不到的,如果找到了,那也就构造性的证明了p=np。所以,我们所能做的只是缓解过拟合尽量逼近最优点。
2.机器学习始终在尝试寻找最优点,不同的算法是在用不同的机制缓解过拟合寻找最优点。
3.如果overfitting不存在,机器学习也就不存在了,直接在测试集上做到100%就可以了。
4.后续如果在学习算法时,要问自己,当前算法是如何缓解overfitting的,它缓解overfitting的策略会在什么时候失效。如果你把握住了这两点,你就知道算法怎么用了。
模型选择


评估方法
留出法(hold-out)

注意:
1.保持数据的一致性(例如:分层抽样,基于类别均匀的采样),测试集和训练集数据分布比例尽可能保持一致。
2.多次重复划分(例如100次随机切分),对模型结果求平均值。
3.测试集不能太大,也不能太小(例如1/5~1/3)。

1.我们在用M80估计M100的分布,想要估计更准确,应该增大训练集规模。
2.我们在用Err80估计Err100,想要估计更准确,应该增大测试集的规模。
上述既要增大训练集的规模,又想增大测试集的规模,显然是不显示的,这就是hold-out算法的问题所在。一般情况下,只能用经验上的比例(20%~30%)。
3.假设我们有L1算法和L2算法,使用同样的hold-out算法后L1,ErrL1 < ErrL2我们是不是要将L1算法直接给用户呢?其实不是的,我们只是在做选择,做完选择后还需要基于已有选择,将M100使用L1算法训练后交付给用户。
留出法存在的问题
按比例随机切分100次,但是还有可能有数据从未出现在训练集/测试集中。比如说某门课有100个知识点,每次取80个取100次但总归会有知识点漏掉,如果这些漏掉的知识点出现在后续的考试中,就会出现问题。
K-折交叉验证法

上述的10次切分,还是太少了,可能由于切分方式导致模型的性能存在扰动,所以我们将上述的动作再重复10次,来减少由于切分方式带来的扰动,10 * 10 CV。
留一法(leave-one-out,LOO)
上述的CV算法是使用M90估计M100,肯定比之前的M90估计M100更加的准确,那能否使用M99估计M100呢,这就是留一法。
NFC!!!留一法也是存在问题的,比如现在又100个人50男50女,我们使用留一法判断每一次进来的人是男生还是女的,测试会有偏差,留男猜女留女猜男,每次判断得出的结果都是不正确的。
自助法
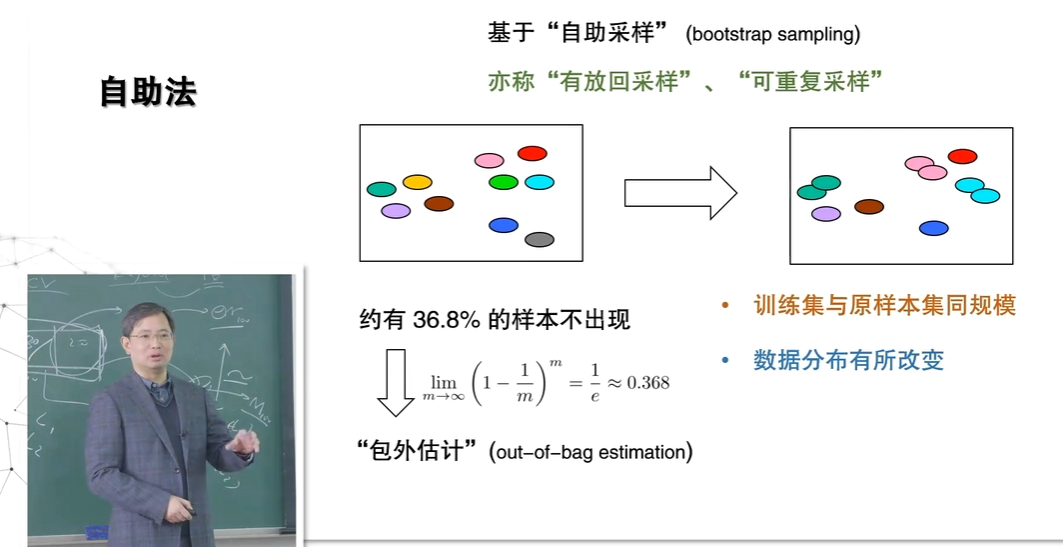
自助法的优势
扩大了训练集的规模,在某些数据较少的场景下有很好的效果。
自助法的劣势
由于是"又放回的抽样"有些数据可能被多次抽到,这改变了原始数据的分布。
具体是否选择使用自助法,需要评估"数据分布的改变"对最终结果的影响到小以及数据集大小。
调参与最终模型

举例
L1: y = ax2+bc+c
L2: y =ax3
针对上述两种算法,我们可以把指数提供给用户选择,如果用户选择2就用L1如果用户选择3我们就用L2,其中指数就是超参数,a,b,c等就是模型参数。不同的超参数和模型参数甚至算法的排列组合都是不同的模型。
验证集(validation set)
1.验证集专门用于调整模型的参数,选择不同的模型。
2.算法参数选定后,要用"训练集+验证集"重新训练得到最终模型,再在测试集上评估。
3.一定不能使用测试集调参数,这会污染模型。
性能度量



举例理解查准率和查全率
例子1:垃圾邮件过滤
-
高查准率:标记为"垃圾"的邮件里,绝大多数真是垃圾。但可能有些垃圾邮件没被拦住(漏网之鱼,查全率低)。
-
高查全率:几乎所有的垃圾邮件都被拦住了。但可能会把一些正常邮件也扔进垃圾箱(误杀,查准率低)。
实际应用:邮箱对重要邮件(如录取通知)宁可漏过(降低查全率),也不能误杀(需要很高查准率)。而对于广告邮件,误杀一两个也没关系,更希望不漏掉太多垃圾(此时查全率优先)。
例子2:医学检测(罕见病)
假设某种病在 1000 人中只有 10 人患病。
-
高查全率的检测 :会把所有可能患病的人都找出来(包括很多健康人被误判)。适用于初步筛查------宁可错判,不能放过。
-
高查准率的检测 :判断为"阳性"的人,几乎肯定真的患病。适用于最终确诊------误判代价很高(比如手术或心理压力)。
鱼与熊掌不可兼得
通常提高查准率会降低查全率,反之亦然。
-
保守模型(只在高置信度时判为"对"):查准率很高,查全率低。
-
激进模型(宁可错杀也不放过):查全率很高,查准率低。

比较检验


这两个都是机器学习中用于比较两个模型(或算法)性能是否存在显著差异的统计检验方法。它们解决的是同一个核心问题:模型A的准确率(或其他指标)比模型B高,到底是真实的能力差异,还是随机波动造成的?
交叉验证t检验
核心思想:通过多次重复的交叉验证,得到多对模型性能差值的样本,然后对这些差值进行 t 检验,判断差值的均值是否显著不为0。
具体步骤(以k折交叉验证为例):
-
将数据集划分为k份(如10折)。
-
进行多次(比如10次)完整的k折交叉验证。每次交叉验证都会产生k个「模型A性能 - 模型B性能」的差值。
-
这样总共会得到
重复次数 × k个性能差值。 -
对这些差值计算均值和标准差,进行配对t检验,看差值的均值是否显著大于0。
优缺点:
-
优点:利用了多次重复划分,结果相对稳健。
-
缺点 :计算开销大;由于训练集有重叠(同一次交叉验证中不同折的训练集有重叠,不同次交叉验证之间的训练集更有重叠),差值之间不独立,可能导致第一类错误(假阳性)概率升高 。有一种改进版叫 5×2交叉验证t检验 可以部分缓解此问题。
适用场景:当你有多对(A模型,B模型)在多个独立测试集上的性能差值时。实际中如果不要求极严格统计,常作为一种参考。
McNemar检验(基于列联保,卡方检验)
核心思想 :专注于两个模型在同一个测试集 上预测结果的不一致性。它不关心两个模型都正确或都错误的样本,只看「一个对一个错」的情况。
核心输入:列联表(对照表)
| 模型B预测正确 | 模型B预测错误 | |
|---|---|---|
| 模型A预测正确 | e00 | e01 |
| 模型A预测错误 | e10 | e11 |
-
e01:模型A正确、模型B错误的样本数
-
e10:模型A错误、模型B正确的样本数
统计量:
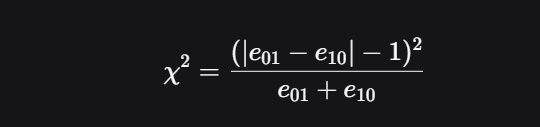
(这个统计量近似服从自由度为1的卡方分布)
关键理解:如果两个模型性能无差异,那么e01和e10应该大致相等(即A对B错 ≈ A错B对)。如果两者相差很大,就说明一个模型显著优于另一个。
优缺点:
-
优点:简单、轻量、无需重复试验;直接基于预测结果的比较,不受整体准确率高低的影响;对样本不独立性不敏感。
-
缺点:只关心「不一致」的样本,忽略了e00和e11的信息;要求测试集足够大(一般建议总样本数≥20,e01+e10≥10),且测试集是固定的独立集(不能是验证集)。
适用场景 :两个模型在同一个固定测试集 上预测后,想快速判断谁更好。是分类任务中比较两个模型的经典且严谨的方法。
什么时候用哪个?
-
你要严谨地比较两个分类器 ,且有一个固定的独立测试集 → McNemar检验(首选,简单规范)
-
你没有独立测试集 ,数据量小,必须用交叉验证估算性能 → 5×2交叉验证t检验(比普通交叉验证t检验更可靠)
-
你只关心平均性能差异,对严格统计显著性要求不高 → 普通交叉验证t检验 + 谨慎解读