线性数据--进行机器学习
我们刚从一个地方旅游回来,带回了一个别致的壁挂式模拟温度计,但是不显示单位。
选择一个模型,迭代地调整它的权重,直到误差的度量足够低,最终能够以我们选择的单位来解释新的刻度值
python
# 环境摄氏度
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
# 观测值
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]demo示例
python
import torch
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
t_c = torch.tensor(t_c)
t_u = torch.tensor(t_u)
def model(t_u, w, b):
return w * t_u + b
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c)**2
# 构建一个差分张量,先对其平方进行处理,最后对得到的张量中的所有元素求平均值得到一个标量损失函数,即均方损失函数
return squared_diffs.mean()
def dloss_fn(t_p, t_c):
dsp_diffs = 2 * (t_p - t_c) / t_p.size(0)
#print("dsp_diffs(对预测数据tp求导的均值:\n)",dsp_diffs)
return dsp_diffs
def dmodel_dw(t_u, w, b):
return t_u
def dmodel_db(t_u, w, b):
return 1.0
def grad_fn(t_u, t_c, t_p, w, b):
dloss_dtp = dloss_fn(t_p, t_c)
dloss_dw = dloss_dtp * dmodel_dw(t_u, w, b) # t_p 对 w 的求导
dloss_db = dloss_dtp * dmodel_db(t_u, w, b) # t_p 对 b 的求导
return torch.stack([dloss_dw.sum(), dloss_db.sum()])
def training_loop(n_epochs, learning_rate, params, t_u, t_c):
for epoch in range(1, n_epochs+1):
w, b = params
print('w的权重%f, b的权重%f' %(w,b))
t_p = model(t_u, w, b)
#print("预测数据tp:\n",t_p)
loss = loss_fn(t_p, t_c)
grad = grad_fn(t_u, t_c, t_p, w, b)
params = params - learning_rate * grad
print('Epoch %d, Loss %f' %(epoch, float(loss)))
return params
training_loop(n_epochs = 10, learning_rate = 1e-2, params = torch.tensor([1.0,0.0]),t_u = t_u, t_c= t_c)输出
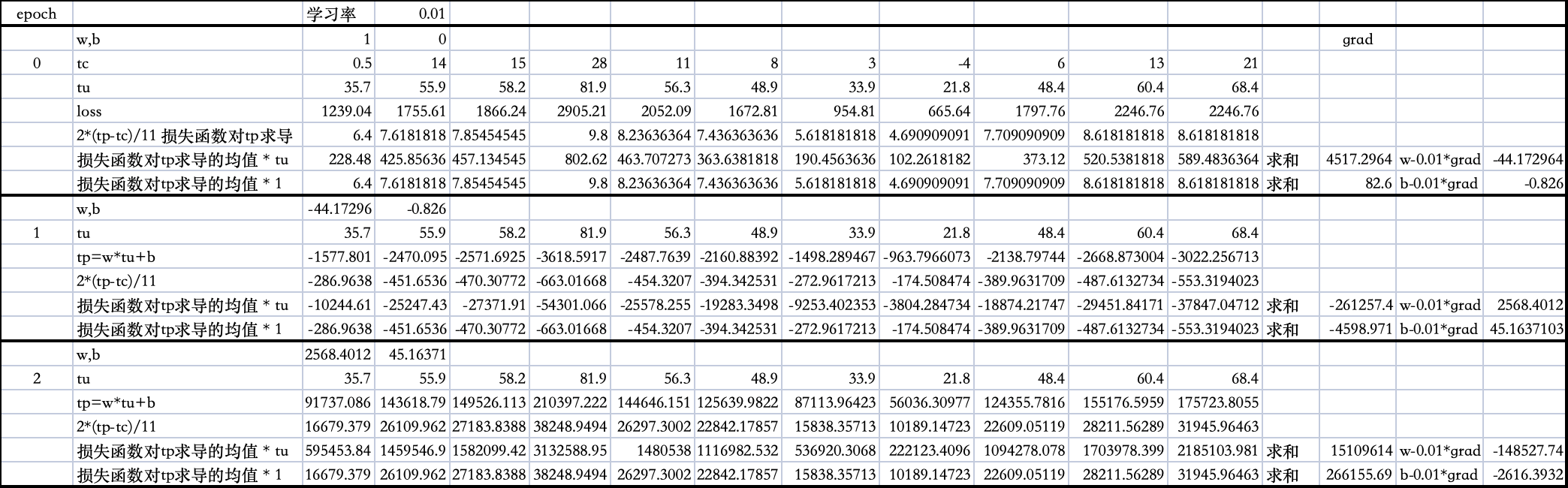
w的权重1.000000, b的权重0.000000
Epoch 1, Loss 1763.884766
w的权重-44.172962, b的权重-0.826000
Epoch 2, Loss 5802484.500000
w的权重2568.401123, b的权重45.163700
Epoch 3, Loss 19408029696.000000
w的权重-148527.734375, b的权重-2616.393066
Epoch 4, Loss 64915905708032.000000
w的权重8589999.000000, b的权重151310.890625
Epoch 5, Loss 217130525461053440.000000
w的权重-496795872.000000, b的权重-8750954.000000
Epoch 6, Loss 726257583152928129024.000000
w的权重28731797504.000000, b的权重506104544.000000
Epoch 7, Loss 2429183416467662896627712.000000
w的权重-1661680746496.000000, b的权重-29270159360.000000
Epoch 8, Loss 8125122549611731432050262016.000000
w的权重96102007177216.000000, b的权重1692816375808.000000
Epoch 9, Loss 27176882120842590626938030653440.000000
w的权重-5557983496896512.000000, b的权重-97902722547712.000000
Epoch 10, Loss 90901105189019073810297959556841472.000000
tensor([3.2144e+17, 5.6621e+15])数据执行过程
数据集可视化
python
import matplotlib
import matplotlib.pyplot as plt
from matplotlib import font_manager
# 环境摄氏度
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
# 观测值
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
# macOS 中文字体路径
myfont = font_manager.FontProperties(fname="/System/Library/Fonts/Supplemental/Arial Unicode.ttf")
plt.scatter(t_c, t_u)
plt.title('观测数据可视化',fontproperties=myfont)
plt.xlabel('温度---摄氏度',fontproperties=myfont)
plt.ylabel('测量值',fontproperties=myfont)
plt.savefig("观测数据可视化.png")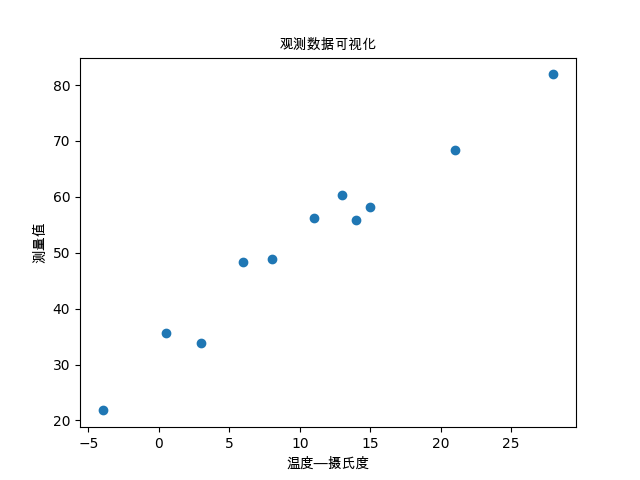
列表数据 转 Tensor 张量
python
import torch
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
t_c = torch.tensor(t_c)
t_u = torch.tensor(t_u)线性函数
tc=w∗tu+bt_c = w * t_u + btc=w∗tu+b
假定 这两组数据集可能是线性相关的,将观测数据tut_utu乘一个因子,再加一个常数,可以得到摄氏温度
python
def model(t_u, w, b):
return w * t_u + b损失函数
损失函数 是一个计算单个数值的函数,学习过程将试图使其值最小化。从概念上讲,损失函数是一种对训练样本中要修正的错误进行优先处理的方法,因此参数更新会导致对高权重样本的输出进行调整,而不是对损失较小的其他样本的输出进行调整。
损失的计算 通常涉及获取一些训练样本的预期输出 与 输入这些样本时模型实际产生的输出 之间的差值。
tpt_ptp 模型输出的预测温度
tct_ctc 实际测量值
常见损失函数:
绝对差:∣tp−tc∣|t_p-t_c|∣tp−tc∣
平方差:(tp−tc)2(t_p-t_c)^2(tp−tc)2
python
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c)**2
# 构建一个差分张量,先对其平方进行处理,最后对得到的张量中的所有元素求平均值得到一个标量损失函数,即均方损失函数
return squared_diffs.mean()这2个损失函数在零点处都有一个明显的最小值,并且随着预测值在2个方向上远离真实值 而单调递增。
因为增长的陡度也从最小值开始逐渐增加,所以他们都是 凸函数。
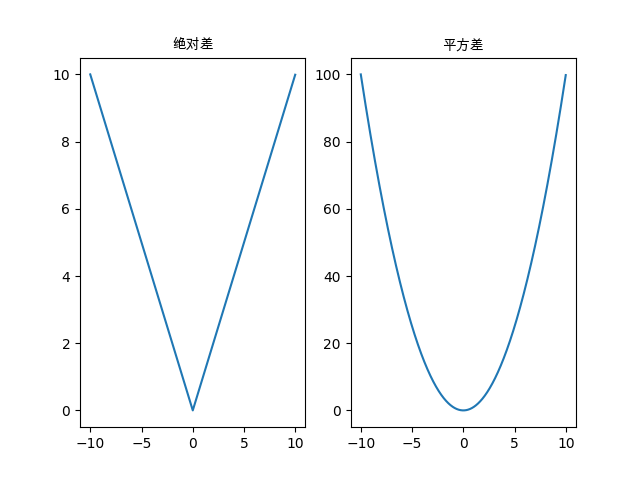
可视化代码
python
import numpy as np
import matplotlib.pyplot as plt
# macOS 中文字体路径
myfont = font_manager.FontProperties(fname="/System/Library/Fonts/Supplemental/Arial Unicode.ttf")
#************** y = |t_p - t_c| **********************
# 定义常数c
c = 0
# 创建一个t的数组,从0到10,步长为0.01
t = np.arange(-10, 10, 0.01)
# 计算|t-c|
abs_diff = np.abs(t - c)
# 绘制图像
plt.subplot(1, 2, 1) # 1行2列,当前是第1个图
#plt.figure(figsize=(10, 6))
plt.title('绝对差',fontproperties=myfont)
plt.plot(t, abs_diff)
#************** y = (t_p - t_c)^2 **********************
# 定义常数 c
c = 0 # 你可以根据需要改变这个值
# 定义函数 (t-c)^2
def f(t):
return (t - c) ** 2
# 生成 t 的值
t = np.arange(-10, 10, 0.01) # 从 -10 到 10,
# 计算函数值
y = f(t)
# 绘制图形
plt.subplot(1, 2, 2) # 1行2列,当前是第1个图
plt.title('平方差',fontproperties=myfont)
plt.plot(t, y)
plt.savefig("损失函数.png")
plt.show()梯度函数
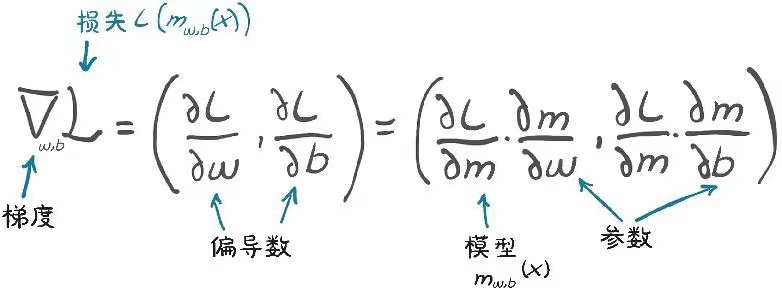
python
def dmodel_dw(t_u, w, b):
return t_u
def dmodel_db(t_u, w, b):
return 1.0
def grad_fn(t_u, t_c, t_p, w, b):
dloss_dtp = dloss_fn(t_p, t_c)
dloss_dw = dloss_dtp * dmodel_dw(t_u, w, b) # t_p 对 w 的求导
dloss_db = dloss_dtp * dmodel_db(t_u, w, b) # t_p 对 b 的求导
return torch.stack([dloss_dw.sum(), dloss_db.sum()])
def training_loop(n_epochs, learning_rate, params, t_u, t_c):
for epoch in range(1, n_epochs+1):
w, b = params
print('w的权重%f, b的权重%f' %(w,b))
t_p = model(t_u, w, b)
#print("预测数据tp:\n",t_p)
loss = loss_fn(t_p, t_c)
grad = grad_fn(t_u, t_c, t_p, w, b)
params = params - learning_rate * grad
print('Epoch %d, Loss %f' %(epoch, float(loss)))
return params归一化数据--进行梯度计算
上诉的示例中,在第1个迭代周期,权重的梯度大约是偏执梯度的50倍。这意味着权重和偏置存在于不同的比例空间中,在这种情况下,如果学习率足够大,能够有效更新其中一个参数,那么对于另一个参数来说,学习率就会变得不稳定,而一个只适合于另一个参数的学习率也不足以有意义地改变前者。这意味着我们无法更新参数,除非我们改变模型的公式。
可以用一种简单的方式来控制:改变输入,这样梯度就不会有太大的不同。粗略地说,我们可以确保输入的范围不会偏离 −1.0−1.0-1.0 -1.0−1.0−1.0 太远。t_nu = 0.1 * t_u
python
import torch
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
t_c = torch.tensor(t_c)
t_u = torch.tensor(t_u)
t_nu = 0.1 * t_u # 数据归一化
def model(t_u, w, b):
return w * t_u + b
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c)**2
# 构建一个差分张量,先对其平方进行处理,最后对得到的张量中的所有元素求平均值得到一个标量损失函数,即均方损失函数
return squared_diffs.mean()
def dloss_fn(t_p, t_c):
dsp_diffs = 2 * (t_p - t_c) / t_p.size(0)
#print("dsp_diffs(对预测数据tp求导的均值:\n)",dsp_diffs)
return dsp_diffs
def dmodel_dw(t_u, w, b):
return t_u
def dmodel_db(t_u, w, b):
return 1.0
def grad_fn(t_u, t_c, t_p, w, b):
dloss_dtp = dloss_fn(t_p, t_c)
dloss_dw = dloss_dtp * dmodel_dw(t_u, w, b) # t_p 对 w 的求导
dloss_db = dloss_dtp * dmodel_db(t_u, w, b) # t_p 对 b 的求导
return torch.stack([dloss_dw.sum(), dloss_db.sum()])
def training_loop(n_epochs, learning_rate, params, t_u, t_c):
for epoch in range(1, n_epochs+1):
w, b = params
if epoch % 500 == 0:
print('epoch:%d,w的权重%f, b的权重%f' %(epoch,w,b))
t_p = model(t_u, w, b)
#print("预测数据tp:\n",t_p)
loss = loss_fn(t_p, t_c)
grad = grad_fn(t_u, t_c, t_p, w, b)
params = params - learning_rate * grad
if epoch % 500 == 0:
print('Epoch %d, Loss %f' %(epoch, float(loss)))
return params
python
params = training_loop(n_epochs = 5000,
learning_rate = 1e-2,
params = torch.tensor([1.0,0.0]),
t_u = t_nu,
t_c= t_c)epoch:500,w的权重4.042069, b的权重-9.800521
Epoch 500, Loss 7.860115
epoch:1000,w的权重4.801176, b的权重-14.097685
Epoch 1000, Loss 3.828538
epoch:1500,w的权重5.125595, b的权重-15.934165
Epoch 1500, Loss 3.092191
epoch:2000,w的权重5.264245, b的权重-16.719034
Epoch 2000, Loss 2.957698
epoch:2500,w的权重5.323496, b的权重-17.054447
Epoch 2500, Loss 2.933134
epoch:3000,w的权重5.348819, b的权重-17.197794
Epoch 3000, Loss 2.928648
epoch:3500,w的权重5.359639, b的权重-17.259048
Epoch 3500, Loss 2.927830
epoch:4000,w的权重5.364264, b的权重-17.285231
Epoch 4000, Loss 2.927680
epoch:4500,w的权重5.366242, b的权重-17.296423
Epoch 4500, Loss 2.927651
epoch:5000,w的权重5.367083, b的权重-17.301184
Epoch 5000, Loss 2.927648可视化线性函数
python
import matplotlib
import matplotlib.pyplot as plt
from matplotlib import font_manager
# macOS 中文字体路径
myfont = font_manager.FontProperties(fname="/System/Library/Fonts/Supplemental/Arial Unicode.ttf")
t_p = model(t_nu, *params)
fig = plt.figure(dpi=600)
plt.title('线性函数',fontproperties=myfont)
plt.xlabel('温度---摄氏度',fontproperties=myfont)
plt.ylabel('测量值',fontproperties=myfont)
plt.plot(t_u.numpy(), t_p.detach().numpy())
plt.plot(t_u.numpy(), t_c.numpy(),'o')
plt.savefig("线性函数.png")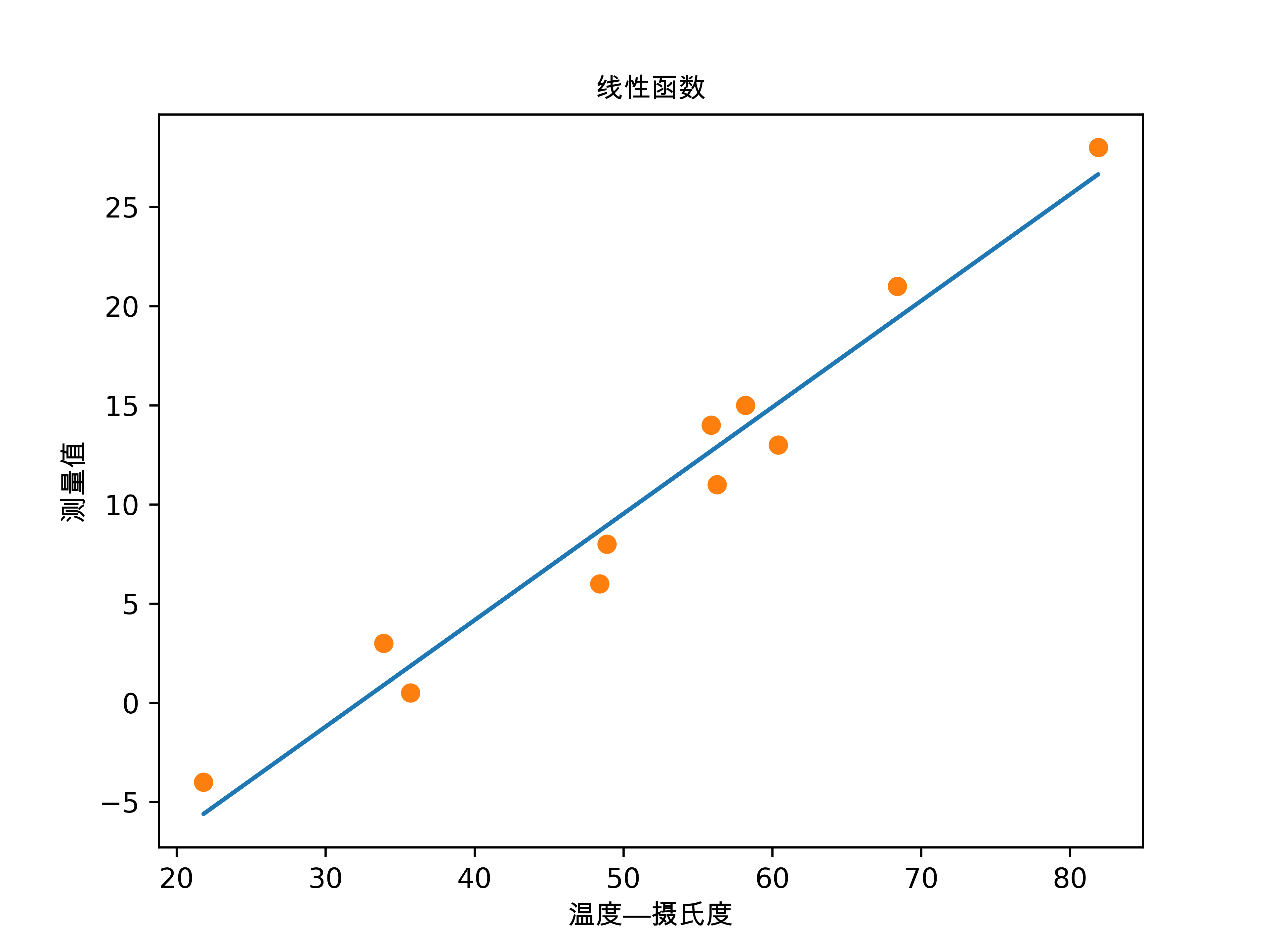
PyTorch 自动求导
python
import torch
import torch.optim as optim
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
t_c = torch.tensor(t_c)
t_u = torch.tensor(t_u)
t_nu = 0.1 * t_u # 数据归一化
def model(t_u, w, b):
return w * t_u + b
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c)**2
# 构建一个差分张量,先对其平方进行处理,最后对得到的张量中的所有元素求平均值得到一个标量损失函数,即均方损失函数
return squared_diffs.mean()
def training_loop(n_epochs, optimizer, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
t_p = model(t_u, *params)
loss = loss_fn(t_p, t_c)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 500 == 0:
print('Epoch %d, Loss %f' %(epoch, float(loss)))
return params
params = torch.tensor([1.0, 0.0], requires_grad = True)
learning_rate = 1e-2
optimizer = optim.SGD([params],lr=learning_rate)
training_loop(n_epochs = 5000,
optimizer = optimizer,
params=params,
t_u=t_nu,
t_c=t_c)Epoch 500, Loss 7.860115
Epoch 1000, Loss 3.828538
Epoch 1500, Loss 3.092191
Epoch 2000, Loss 2.957698
Epoch 2500, Loss 2.933134
Epoch 3000, Loss 2.928648
Epoch 3500, Loss 2.927830
Epoch 4000, Loss 2.927679
Epoch 4500, Loss 2.927652
Epoch 5000, Loss 2.927647
tensor([ 5.3671, -17.3012], requires_grad=True)张量 自动求导 requires_grad=True
requires_grad=True 这个参数告诉PyTorch跟踪由对 params 张量进行操作后产生的张量的整个系谱树。换句话说,任何将 params 作为祖先的张量都可以访问从 params 到那个张量调用的函数链。如果这些函数是可微的,导数的值将自动填充为 params 张量的 grad 属性。
python
params = torch.tensor([1.0, 0.0], requires_grad=True)
print(params.grad)
import torch
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
t_c = torch.tensor(t_c)
t_u = torch.tensor(t_u)
def model(t_u, w, b):
return w * t_u + b
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c)**2
# 构建一个差分张量,先对其平方进行处理,最后对得到的张量中的所有元素求平均值得到一个标量损失函数,即均方损失函数
return squared_diffs.mean()
loss = loss_fn(model(t_u, *params), t_c)
loss.backward()
print(params.grad)None
tensor([4517.2969, 82.6000])
梯度累加
再次调用 backward() 将导致导数在叶节点上累加,因此如果提前调用 backward(), 则 再次计算损失,再次调用 backward()(就像在任何训练循环中一样),每个叶节点上的梯度将在上一次迭代中计算的梯度之上累加(求和),这回导致梯度计算不正确.
python
loss = loss_fn(model(t_u, *params), t_c)
loss.backward()
print(params.grad)tensor([9034.5938, 165.2000])梯度归零
python
def training_loop(n_epochs, learning_rate, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
if params.grad is not None:
params.grad.zero_() # 梯度归零
t_p = model(t_u, *params)
loss = loss_fn(t_p, t_c)
loss.backward()
with torch.no_grad():
params -= learning_rate * params.grad
if epoch % 500 == 0:
print('Epoch %d, Loss %f' % (epoch, float(loss)))
return params
training_loop(n_epochs = 5000, learning_rate = 1e-2, params = torch.tensor([1.0, 0.0], requires_grad=True),t_u = t_nu, t_c = t_c) Epoch 500, Loss 7.860115
Epoch 1000, Loss 3.828538
Epoch 1500, Loss 3.092191
Epoch 2000, Loss 2.957698
Epoch 2500, Loss 2.933134
Epoch 3000, Loss 2.928648
Epoch 3500, Loss 2.927830
Epoch 4000, Loss 2.927679
Epoch 4500, Loss 2.927652
Epoch 5000, Loss 2.927647
tensor([ 5.3671, -17.3012], requires_grad=True)优化器
SGD优化器
python
params = torch.tensor([1.0, 0.0], requires_grad = True)
learning_rate = 1e-2
optimizer = optim.SGD([params],lr=learning_rate)
training_loop(n_epochs = 5000, optimizer = optimizer, params=params, t_u=t_nu, t_c=t_c)Adam 优化器
Adam 优化器,它是一个更复杂的优化器,其中学习率是自适应设置的。
python
import torch
import torch.optim as optim
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
t_c = torch.tensor(t_c)
t_u = torch.tensor(t_u)
t_nu = 0.1 * t_u # 数据归一化
def model(t_u, w, b):
return w * t_u + b
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c)**2
# 构建一个差分张量,先对其平方进行处理,最后对得到的张量中的所有元素求平均值得到一个标量损失函数,即均方损失函数
return squared_diffs.mean()
def training_loop(n_epochs, optimizer, params, t_u, t_c):
for epoch in range(1, n_epochs + 1):
t_p = model(t_u, *params)
loss = loss_fn(t_p, t_c)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if epoch % 500 == 0:
print('Epoch %d, Loss %f' %(epoch, float(loss)))
return params
params = torch.tensor([1.0, 0.0], requires_grad = True)
learning_rate = 1e-1
optimizer = optim.Adam([params],lr=learning_rate)
training_loop(n_epochs = 5000,
optimizer = optimizer,
params=params,
t_u=t_nu,
t_c=t_c)Epoch 500, Loss 2.962301
Epoch 1000, Loss 2.927645
Epoch 1500, Loss 2.927645
Epoch 2000, Loss 2.927646
Epoch 2500, Loss 2.927646
Epoch 3000, Loss 2.927646
Epoch 3500, Loss 2.927646
Epoch 4000, Loss 2.927646
Epoch 4500, Loss 2.927646
Epoch 5000, Loss 2.927645
tensor([ 5.3677, -17.3048], requires_grad=True)优化器-梯度归零 optimizer.zero_grad()
优化器-梯度自动更新 optimizer.step()
params 的值调用 step() 时更新,而不需要我们自己去操作!即优化器会查看 params.grad 并更新 params, 从中减去学习率乘梯度,就像手动编写的代码一样。
按训练、验证--分割数据
python
import torch
import torch.optim as optim
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
t_c = torch.tensor(t_c)
t_u = torch.tensor(t_u)
# 对数据索引号 进行乱序排序,并分割数据
n_samples = t_u.shape[0]
n_val = int(0.2 * n_samples)
shuffled_indices = torch.randperm(n_samples)
train_indices = shuffled_indices[:-n_val]
val_indices = shuffled_indices[-n_val:]
train_t_u = t_u[train_indices]
train_t_c = t_c[train_indices]
val_t_u = t_u[val_indices]
val_t_c = t_c[val_indices]
train_t_un = 0.1 * train_t_u # 数据归一化
val_t_un = 0.1 * val_t_u # 数据归一化
def model(t_u, w, b):
return w * t_u + b
def loss_fn(t_p, t_c):
squared_diffs = (t_p - t_c)**2
# 构建一个差分张量,先对其平方进行处理,最后对得到的张量中的所有元素求平均值得到一个标量损失函数,即均方损失函数
return squared_diffs.mean()
def training_loop(n_epochs, optimizer, params, train_t_u, val_t_u, train_t_c, val_t_c):
for epoch in range(1, n_epochs+1):
train_t_p = model(train_t_u, *params)
train_loss = loss_fn(train_t_p, train_t_c)
val_t_p = model(val_t_u, *params)
val_loss = loss_fn(val_t_p, val_t_c)
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
if epoch <=3 or epoch % 500 == 0:
print(f"Epoch {epoch}, Training loss {train_loss.item():.4f}, Validation loss {val_loss.item():.4f}")
return params
params = torch.tensor([1.0, 0.0], requires_grad=True)
learning_rate = 1e-2
optimizer = optim.SGD([params], lr=learning_rate)
training_loop(n_epochs=3000, optimizer = optimizer, params = params, train_t_u = train_t_un, val_t_u= val_t_un, train_t_c=train_t_c, val_t_c=val_t_c)Epoch 1, Training loss 81.0008, Validation loss 77.5003
Epoch 2, Training loss 43.3337, Validation loss 20.9351
Epoch 3, Training loss 36.9531, Validation loss 8.1371
Epoch 500, Training loss 7.3156, Validation loss 2.3736
Epoch 1000, Training loss 3.7045, Validation loss 2.2572
Epoch 1500, Training loss 3.2517, Validation loss 2.2199
Epoch 2000, Training loss 3.1950, Validation loss 2.2072
Epoch 2500, Training loss 3.1878, Validation loss 2.2028
Epoch 3000, Training loss 3.1869, Validation loss 2.2012
tensor([ 5.3077, -17.2599], requires_grad=True)torch.randperm()
torch.randperm(n_samples) 生成一个从 0 到 n_samples - 1 的随机排列(无重复整数)的 1D 张量,常用于打乱数据索引(如训练集划分、随机采样
python
torch.randperm(11)tensor([ 8, 9, 6, 2, 5, 7, 10, 3, 0, 4, 1])随机选择张量数据
python
# 对数据索引号 进行乱序排序,并分割数据
n_samples = t_u.shape[0]
print("n_samples:",n_samples)
n_val = int(0.2 * n_samples)
print("n_val",n_val)
shuffled_indices = torch.randperm(n_samples)
print(shuffled_indices)
train_indices = shuffled_indices[:-n_val]
val_indices = shuffled_indices[-n_val:]
train_indices, val_indicesn_samples: 11
n_val 2
tensor([ 3, 8, 1, 0, 4, 6, 7, 9, 5, 2, 10])
(tensor([3, 8, 1, 0, 4, 6, 7, 9, 5]), tensor([ 2, 10]))