目录
[一、 Deployment介绍](#一、 Deployment介绍)
[1、 Deployment 的概念](#1、 Deployment 的概念)
[2、 Deployment 执行状态分析](#2、 Deployment 执行状态分析)
[3、 Deployment 执行流程总结](#3、 Deployment 执行流程总结)
[二、 K8S中创建资源的方式](#二、 K8S中创建资源的方式)
[3、用 kubectl命令直接创建资源](#3、用 kubectl命令直接创建资源)
[4、通过配置文件和kubectl apply命令创建资源](#4、通过配置文件和kubectl apply命令创建资源)
[1、Deployment 的配置格式](#1、Deployment 的配置格式)
[四、在线增加或减少 Pod 的副本数](#四、在线增加或减少 Pod 的副本数)
[五、通过label 控制 Pod 的位置](#五、通过label 控制 Pod 的位置)
[一、 job使用场景](#一、 job使用场景)
[二、 job应用介绍](#二、 job应用介绍)
[三、 Service IP内部实现原理分析](#三、 Service IP内部实现原理分析)
K8s对象deployment应用详解
一、 Deployment介绍
1、 Deployment 的概念
为了满足不同业务场景,k8s开发了Deployment、ReplicaSet、DaemonSet、StatefuleSet、Job 等多种Controller。这里介绍下最常用的Deployment。
Deployment 为Pod和ReplicaSet提供了一个声明式定义 (declarative) 方法,用来替代以前的 Replication Controller更方便的管理应用。
作为最常用的Kubernetes对象,Deployment 经常会用来创建 ReplicaSet和Pod,我们往往不会直接在集群中使用ReplicaSet部署一个新的微服务,一方面是因为ReplicaSet的功能其实不够强大,一些常见的更新、扩容和缩容运维操作都不支持,Deployment的引入就是为了支持这些复杂的操作。
2、 Deployment 执行状态分析
查看deployment的状态,可以执行如下命令:
[root@master k8s]# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
http-deployment 3/3 3 3 160m可以发现,k8s中目前有一个deployment,名字为http-deployment。此deployment有三个副本,目前都正常运行。
要想查看某个deployment的详细信息,可执行如下命令:
[root@master k8s]# kubectl describe deployment http-deployment从输出可以发现,有一个ReplicaSet http-deployment-749876cdf4,由此可知,Deployment是通过 ReplicaSet来管理 Pod 的,接着来看下ReplicaSet状态,执行kubectl describe replicaset命令如下所示:
[root@master k8s]# kubectl get replicaset http-deployment-749876cdf4接着,在通过用 kubectl describe replicaset命令
查看replicaset的详细信息:
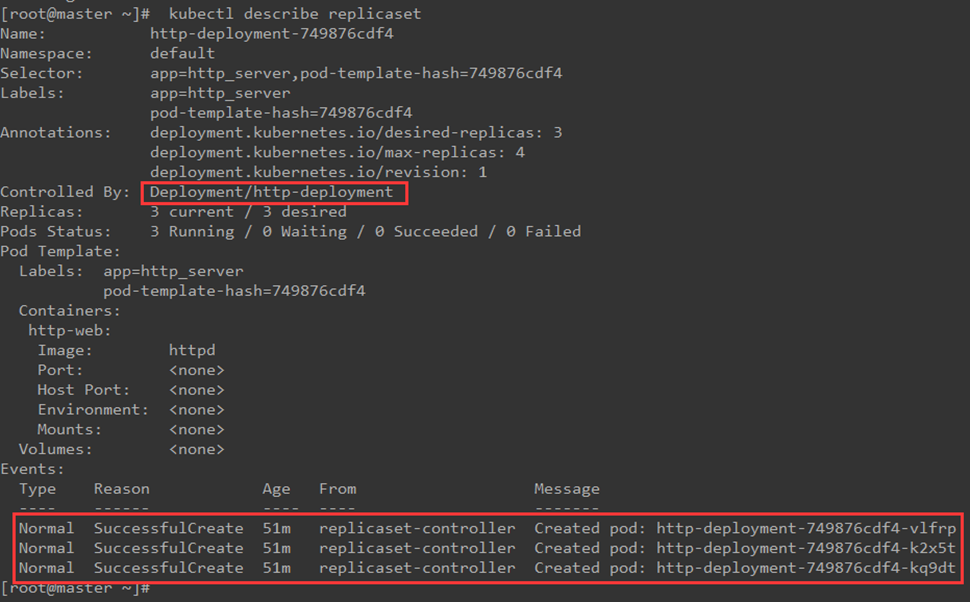
从输出可以看出,Controlled By指明此 ReplicaSet是由 Deployment http-deployment创建。Events记录了3个副本 Pod的创建。
然后,在来看一下Pod状态,执行kubectl get pod命令:
[root@master k8s]# kubectl get pod
NAME READY STATUS RESTARTS AGE
http-deployment-749876cdf4-k2x5t 1/1 Running 0 101s
http-deployment-749876cdf4-kq9dt 1/1 Running 0 101s
http-deployment-749876cdf4-vlfrp 1/1 Running 0 101s从输出可知,3个副本Pod都处于Running 状态.
从输出可以看出,Controlled By指明此 ReplicaSet是由 Deployment http-deployment创建。Events记录了3个副本 Pod的创建。
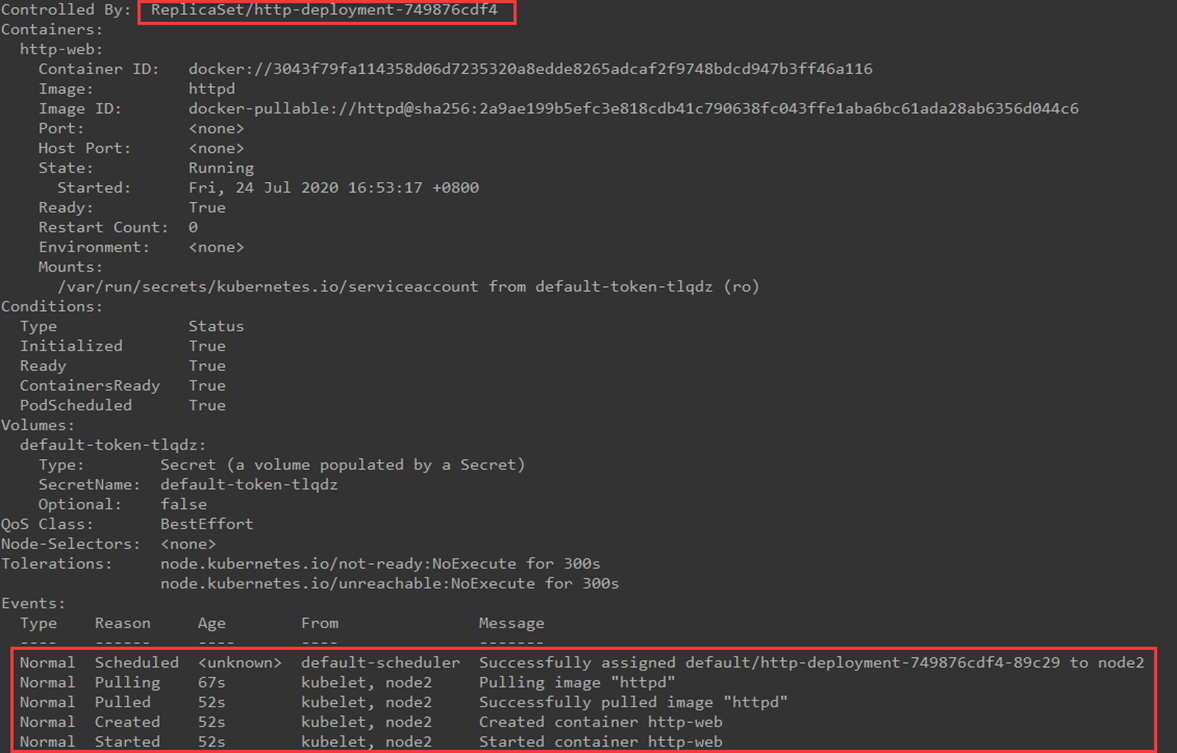
最后,用 kubectl describe pod 查看更详细的信息:右面输出中,Controlled By指明此 Pod 是由ReplicaSet/http-deployment-749876cdf4创建。最后的Events记录了Pod的启动过程。
如果操作失败(比如 image 不存在),从这里也能查看到失败的原因。
3、 Deployment 执行流程总结
最后,总结一下deployment实现的过程:
(1)、首先用户通过 kubectl创建 Deployment。
(2)、接着,Deployment 创建 ReplicaSet。
(3),然后,ReplicaSet创建 Pod
(4)、最后,pod在每个节点上通过kubelet调用docker完成容器创建。
可以看出,对象的命名方式是:子对象的名字 = 父对象名字 + 随机字符串或数字。
从输出可以看出,Controlled By指明此 ReplicaSet是由 Deployment http-deployment创建。Events记录了3个副本 Pod的创建。
二、 K8S中创建资源的方式
1、基于命令的方式
-
- 简单直观快捷,上手快
- 适合临时测试或实验
2、基于配置文件的方式
- 资源的属性写在配置文件中,文件格式为YAML。在配置文件中描述了最终要达到的状态。配置文件提供了创建资源的模板,能够重复部署。
- 可以像管理代码一样管理部署。
- 适合正式的、跨环境、规模化部署。
这种方式要求熟悉配置文件的语法,有一定难度。后面我们都将采用配置文件的方式进行介绍,所以这种方式需要大家尽快熟悉和掌握。
3、用 kubectl命令直接创建资源
[root@master k8s]# kubectl run nginx-deployment --image=nginx --port=80
[root@master k8s]# kubectl get pod
nginx-deployment 1/1 Running 0 31s从1.18版本之后,k8s已经不支持在命令行中通过参数指定资源的属性。这种方式已经基本废弃。
例如---replicas参数已弃用,k8s推荐用deployment创建 pods。
4、通过配置文件和kubectl apply命令创建资源
[root@master k8s]# more http.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: http-deployment
spec:
replicas: 3
selector:
matchLabels:
app: http_server
template:
metadata:
labels:
app: http_server
spec:
containers:
- name: http-web
image: httpdkubectl apply不但能够创建 Kubernetes资源,也能对资源进行更新,非常方便。不过Kubernets还提供了几个类似的命令,例如kubectl create、kubectl replace、kubectl edit 和 kubectl patch。但 kubectl apply命令已经能够应对超过 90% 的场景,我们也主要介绍这个命令的使用。
创建资源命令:
kubectl apply -f http.yml删除资源:
kubectl delete -f http.yml三、通过yml文件编写Deployment配置
1、Deployment 的配置格式
对此yml文件格式介绍如下:
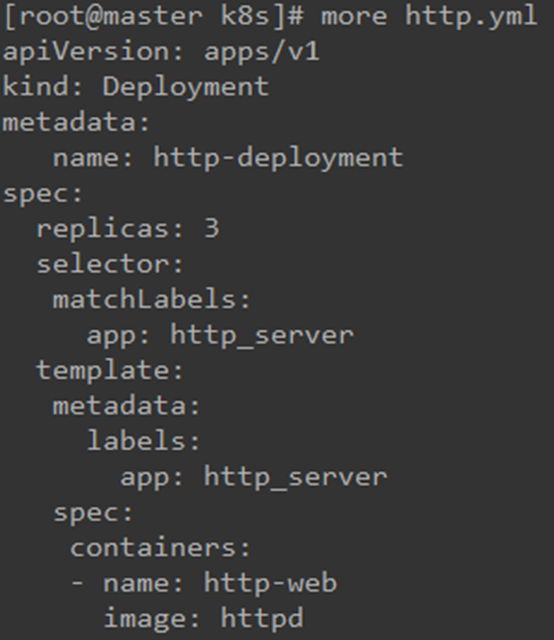
(1)、apiVersion 是当前配置格式的版本。先执行kubectl api-resources找到所有的资源,再执行命令 kubectl explain deploy即可获取到版本和类型信息
(2)kind是要创建的资源类型,这里是Deployment。
(3)metadata是该资源的元数据,name是必需的元数据项,后面名字任意起一个即可。
(4)第一个spec部分是该Deployment的规格说明。
(5)replicas 指明副本数量,默认为 1,这里指定为3。
(6)selector是个选择器, matchLabels是个匹配标签,
在发布Service时,selector需要和这里对应。
(7)template 定义Pod的模板,这是配置文件的重要部分。
(8)metadata 定义Pod的元数据,至少要定义一个label。label的key和value可以任意指定。
(9)第二个spec描述Pod的规格,此部分定义Pod中每一个容器的属性,name和image是必需的。
注意:最后name前面需要加个中杠,是因为container后面是一个列表。
四、在线增加或减少 Pod 的副本数
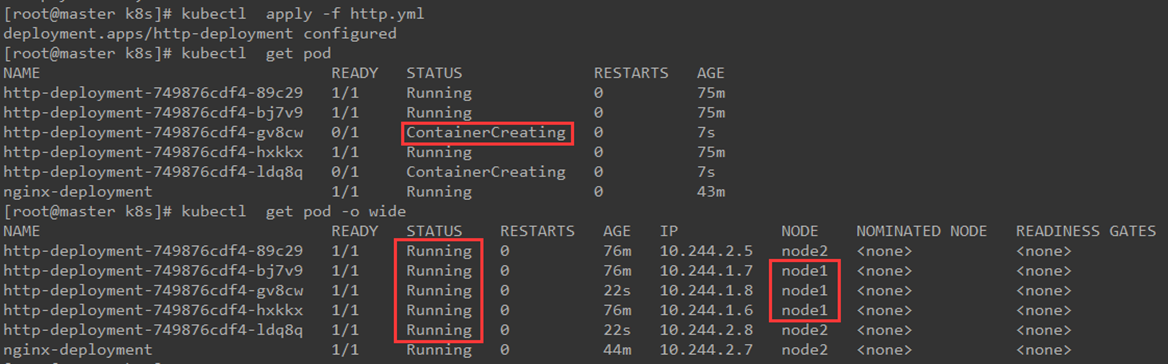
1、增加pod副本数
修改http.yml文件,将副本数从3增加到5,然后查看pod状态,如下图所示:
2、减少pod副本数
修改http.yml文件,将副本数从5减少到2,然后查看pod状态,如下图所示:
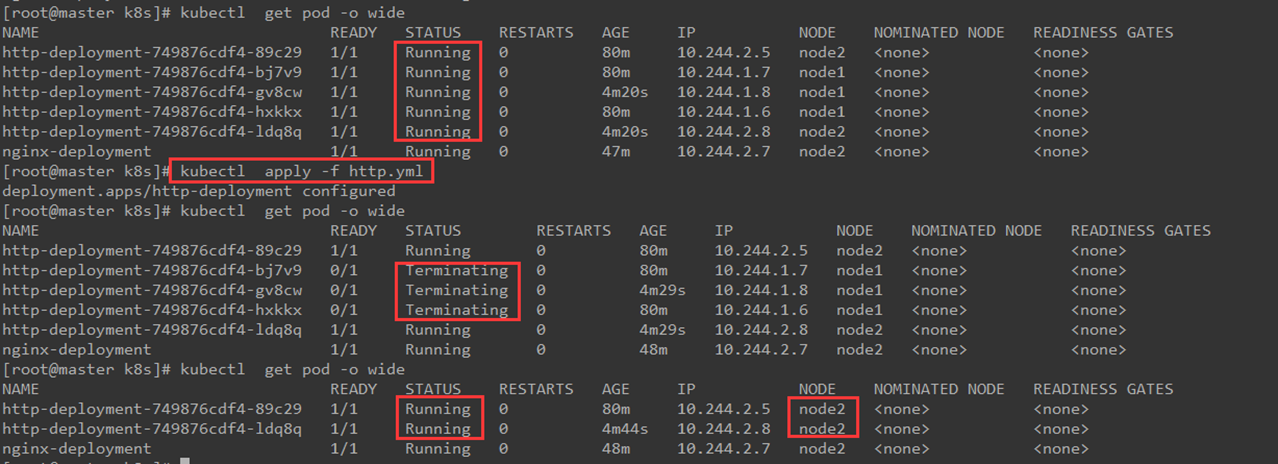
3、node节点故障时pod切换
假定现在有3 个 httpd副本分别运行在node1 和 node2 上。

现在模拟 node1故障,关闭该节点,然后查看pod状态,如下图所示:
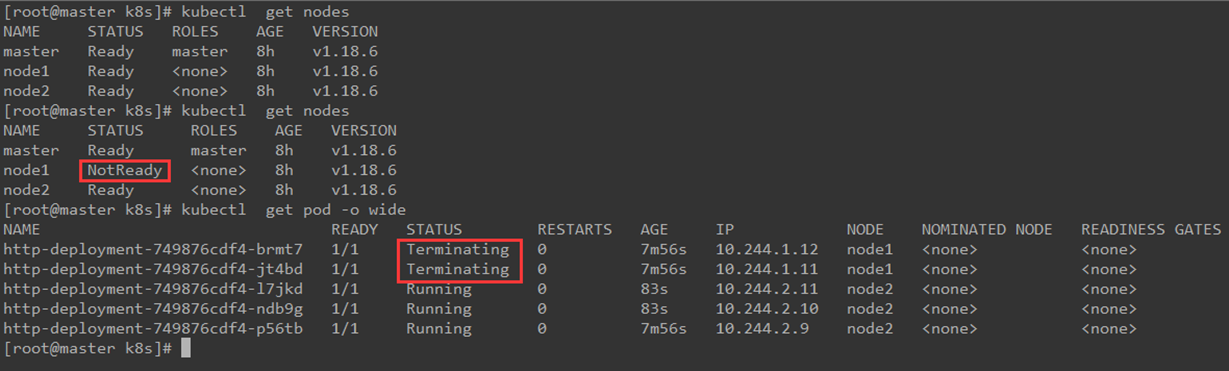
可以发现node1状态为NotReady,等待一段时间,Kubernetes会检查到node1不可用,将node1上的 Pod 标记为 Terminating状态,并在node2上新创建两个Pod,维持总副本数为3。
当 node1恢复后, Terminating的 Pod 会被删除,不过已经在node2上运行的 Pod 不会重新调度回node1。

五、通过label 控制 Pod 的位置
默认配置下,Scheduler 会将 Pod 调度到所有可用的 Node。不过有些情况我们希望将 Pod 部署到指定的 Node,比如将有大量磁盘I/O的Pod部署到配置了SSD的Node节点上;或者Pod需要GPU,需要运行在配置了GPU的节点上。
k8s是通过label来实现这个功能的。label是key-value 对,各种资源都可以设置label,灵活添加各种自定义属性。
执行如下命令标注node1是配置了SSD磁盘的节点。
[root@master k8s]# kubectl label node host1 disk=ssd2
[root@master k8s]# kubectl get node --show-labels注意,这里的disk=ssd,disk是key,ssd为value,都是自定义字符。此外,从第二个命令输出,可以看到,disk=ssd已经成功添加到host1,除了disk的标签,Node1还有几个 k8s自己维护的label。
编写一个文件nginx.yml,内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginx_server
template:
metadata:
labels:
app: nginx_server
spec:
containers:
- name: nginx-web
image: nginx
nodeSelector:
disk: ssd2说明:
此文件,在Pod模板的spec里通过nodeSelector指定将此Pod部署到具有label disk=ssd2的Node上。
注意,nodeSelector需要与containers位置保持一致,nodeSelector中的S必须大写。
要删除 label标签,可执行如下命令:
[root@master k8s]# kubectl label node node1 disk-即可删除。
标签删除之后,Pod 并不会重新部署,依然会在node1上运行。
要改变Pod运行的节点,需要修改nodeSelector设置,然后通过 kubectl apply 重新部署即可。
K8s对象job应用详解
一、 job使用场景
容器按照持续运行的时间可分为两类:服务类容器和工作类容器。
- 服务类容器通常持续提供服务,需要一直运行,比如http server,mysqldb等。
- 工作类容器则是一次性任务,比如批处理程序,完成后容器就退出。
k8s中的的Deployment、ReplicaSet和DaemonSet都用于管理服务类容器;
对于工作类容器,可以使用Job。
二、 job应用介绍
先创建一个基于job的yml文件,内容如下:
# API 组版本:batch/v1 是 Job 资源的稳定版 API(K8s 1.21+ 推荐)
apiVersion: batch/v1
# 资源类型:Job(一次性任务,执行完成就退出)
kind: Job
metadata:
# Job 名称(唯一标识)
name: myjob
spec:
# 任务模板:定义 Pod 运行配置
template:
spec:
# 容器配置
containers:
- name: job # 容器名称
image: busybox # 使用的镜像(轻量级 Linux 工具镜像)
command: ["echo","hello k8s"] # 容器执行命令:输出 hello k8s
# 重启策略:Never 表示任务失败不自动重启(Job 推荐)
restartPolicy: Never
# 可选:任务失败重试次数(默认 6)
backoffLimit: 3其中:
batch/v1是当前Job的apiVersion。
kubectl api-versions | grep batch #查看版本的方式kind指明当前资源的类型为Job。
restartPolicy用来指定什么情况下需要重启容器。对于Job,只能设置为Never或OnFailure。对于其它的controller(比如 Deployment)可以设置为Always。
- Never表示不论状态为何, kubelet都不重启该容器
- OnFailure表示容器终止运行,且退出码不为0时重启
- Always表示容器失效时,kubelet自动重启该容器
三、job失败策略分析
上面介绍了job执行成功的情况,如果失败了会怎么样呢?
首先,修改 myjob.yml,故意引入一个错误:将 command: "echo","hello k8s",修改为:command: "easasacho","hello k8s"
然后执行如下操作:
[root@master k8s]# kubectl delete -f job.yml
[root@master k8s]# kubectl apply -f job.yml
[root@master k8s]# kubectl get pod
[root@master k8s]# kubectl describe pod myjob-vwqs6可以通过最后这个命令发现pod失败的原因,如下图所示:

为什么kubectl get pod会看到这么多个失败的 Pod?如下图所示:
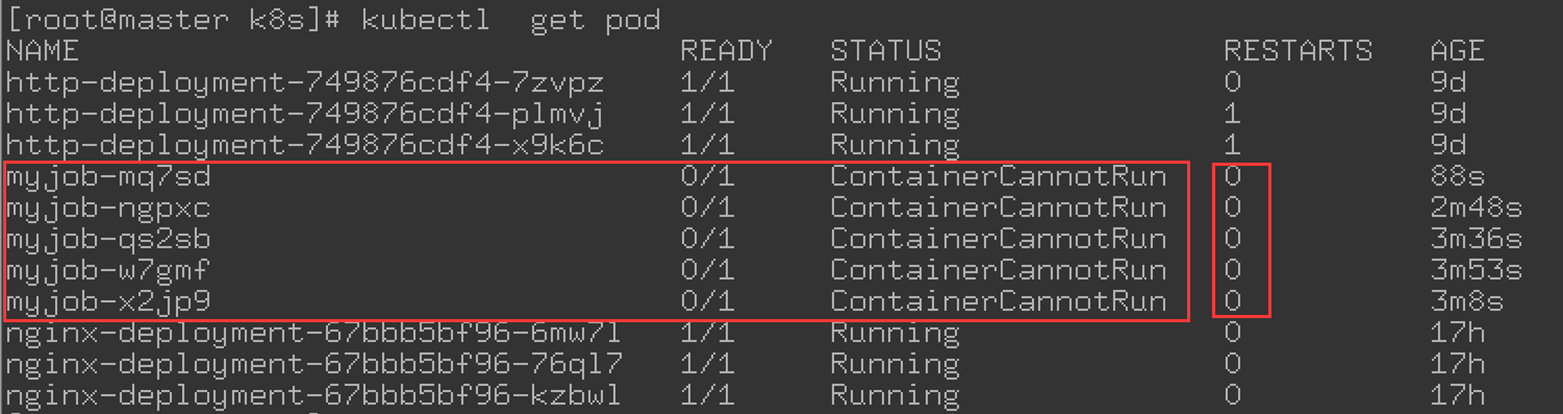
原因是:当第一个Pod启动时,容器失败退出,根据策略:restartPolicy: Never,此失败容器不会被重启,但 Job DESIRED的Pod是1,目前成功的为0,不满足条件,所以 Job controller会启动新的Pod,直到成功为1。对于这个例子,成功永远也到不了1,所以Job controller会一直创建新的Pod。为了终止这个行为,只能删除此job。
而如果将restartPolicy设置为OnFailure会怎么样,根据OnFailure的含义,当pod失败后,会进行重启,因此,可以看到pod只有一个,但是pod的RESTARTS会不断增加,这说明了容器失败后会自动重启。
四、如何定时执行job
Linux中有crontab程序定时执行任务,k8s的CronJob也提供了类似的功能,可以定时执行Job。
先创建一个定时job文件,内容如下:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: hellojob
spec:
schedule: "*/2 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
command: ["echo","hello k8s cron_job!"]
restartPolicy: OnFailure其中:
-
- batch/v1beta1:指定当前CronJob的apiVersion。
- kind:指明当前资源的类型为CronJob。
- schedule:指定什么时候运行Job,其格式与Linux系统中定义crontab的格式一致。例如*/2 * * * * 的含义是每2分钟启动一次。
- jobTemplate定义Job的模板,格式与前面Job一致。
接着,应用这个yml文件,操作如下:
[root@master k8s]# kubectl apply -f cronjob.yml #创建cronjob
[root@master k8s]# kubectl get cronjob #查看cronjob状态
[root@master k8s]# kubectl get job #查看job状态
[root@master k8s]# kubectl get pod #查看pod信息
[root@master k8s]# kubectl logs hellojob-1596513900-hl7nv #查看job对应的pod日志输出
[root@master k8s]# kubectl delete -f cronjob.yml #删除cronjobK8s对象Service应用详解
在k8s中,每个Pod都有自己的IP地址。当controller用新Pod替代发生故障的Pod时,新Pod就会重新分配一个新的IP地址。这样就产生了一个问题:如果一组Pod对外提供服务(比如 HTTP),它们的IP很有可能发生变化,那么客户端如何自动找到,并访问这个服务呢?k8s给出的解决方案就是Service。
k8s中的Service从逻辑上代表了一组Pod,具体是哪些Pod,则是由label来挑选。Service有自己IP,而且这个IP是不变的。客户端只需要访问Service的IP,k8s只负责建立和维护Service与Pod的映射关系。无论后端Pod的IP如何变化,对客户端都不会有任何影响,因为Service一直没有变。
先创建一个基于Deployment的yml文件,内容如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: httpservice-deployment
spec:
replicas: 3
selector:
matchLabels:
run: httpdservice
template:
metadata:
labels:
run: httpdservice
spec:
containers:
- name: httpdservice
image: httpd
ports:
- containerPort: 80然后,执行这个Deployment,执行如下命令:
[root@master service]# kubectl apply -f http-service.yml集群内部测试连通性:
每个Pod会自动分配一个IP,但这些IP只能被k8s Cluster中的容器和节点访问,例如
[root@master service]# curl 10.244.1.28二、创建Service并演示Service的用途
接下来,创建体格Service,其配置文件内容如下:
apiVersion: v1
kind: Service
metadata:
name: service-httpd
spec:
selector:
run: httpdservice
ports:
- protocol: TCP
port: 8080
targetPort: 80其中:
v1是Service的apiVersion。可通过执行"kubectl explain Service"获得。
kind:指明当前资源的类型为Service。
name:指定Service的名字为service-httpd
selector:指明挑选那些label为"run: httpdservice"的Pod作为Service的后端。
ports:端口映射,此配置表示将Service的8080端口映射到Pod的80端口,使用TCP协议。
然后执行如下命令:
[root@master service]# kubectl apply -f service.yml
[root@master service]# kubectl get svc
[root@master service]# curl 10.101.20.80:8080
<html><body><h1>It works!</h1></body></html>根据前面的端口映射,这里要使用 8080 端口。另外,除了我们创建的service-httpd,还有一个 Service kubernetes,Cluster 内部通过这个Service 访问 kubernetes API Server。
通过kubectl describe可以查看service-httpd与Pod的对应关系。如下图所示:
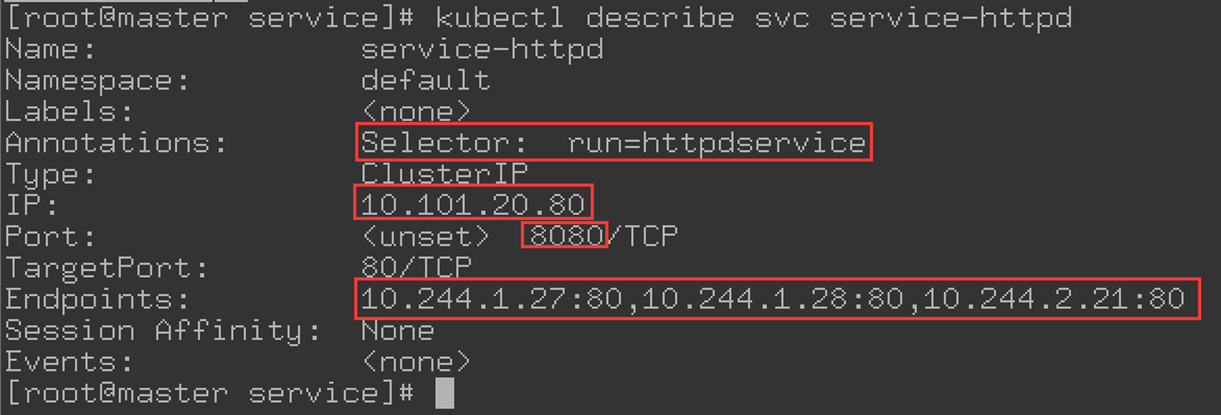
三、 Service IP内部实现原理分析
Pod的IP是在容器中设置的,那么Service的Cluster IP又是在哪里配置的呢?Cluster IP又是如何映射到集群内部的Pod IP 的呢?
答案只有一个:iptables
Service Cluster IP是一个虚拟IP,是由K8s节点上的iptables规则管理的。首先查看svc(service),执行如下命令:

我们通过iptables-save命令打印出当前节点的iptables规则,由于输出较多,这里只截取与service-httpd Cluster IP 10.101.20.80相关的信息。

这两条规则的含义是:如果 Cluster 内的 Pod(源地址来自 10.244.0.0/16)要访问service-httpd,则允许。而其它源地址访问service-httpd,则跳转到规则KUBE-SVC-5FEAUJNCXGRSJFN5。
继续查看KUBE-SVC-5FEAUJNCXGRSJFN5规则,如下图所示:

这几条规则的含义是:
-
- 1/3 的概率跳转到规则 KUBE-SEP-KIILMGZB3LCHX6UB
- 1/3 的概率(剩下 2/3 的一半)跳转到规则 KUBE-SEP-JPXOQHLXQSDHS2NX
- 1/3 的概率跳转到规则 KUBE-SEP-5H6KOBYUZ646ISHJ
那就看看上面的三个跳转规则:
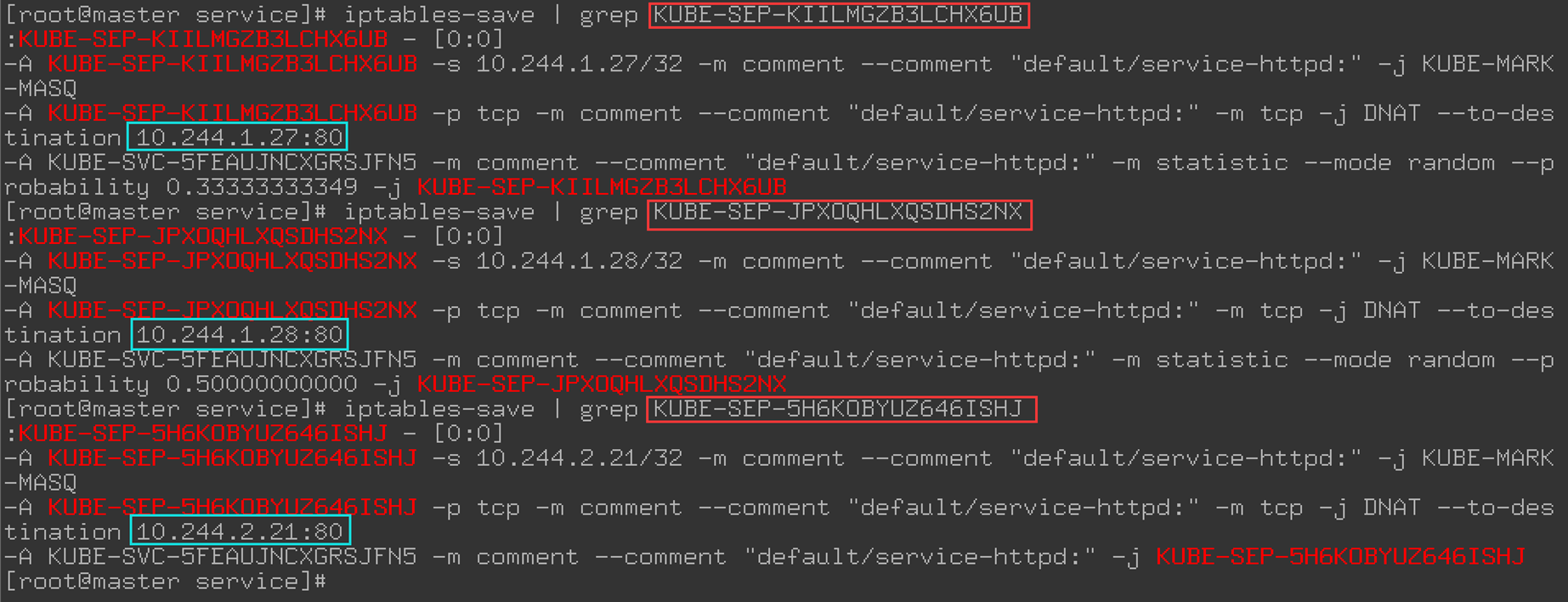
结论:
- 通过上面的分析可知,通过iptables将请求分别转发到后端的三个Pod上。我们得到如下结论:
- iptables将访问Service的流量转发到后端Pod,使用类似轮询的策略实现负载均衡。
- Cluster的每一个节点都配置了相同的iptables规则,这样就确保了整个Cluster都能够通过Service的Cluster IP访问Service。
四、通过DNS访问service
在K8s中,除了可以通过Cluster IP访问Service,K8s还提供了更为方便的DNS访问。
首先,查看coredns,kubeadm初始化部署时,会默认安装coredns组件。
[root@master service]# kubectl get deployment --namespace=kube-system
NAME READY UP-TO-DATE AVAILABLE AGE
coredns 2/2 2 2 10dcoredns是一个DNS服务器。每当有新的Service被创建,coredns会添加该Service的DNS记录。
Cluster中的Pod可以通过 <SERVICE_NAME>.<NAMESPACE_NAME> 访问 Service。
通过service-httpd.default访问Service,先运行一个容器终端,然后通过wget测试,执行如下命令:
kubectl run busybox --rm -it --image=busybox /bin/sh
注意:wget service-httpd:8080后面的这个port必须是service的port不是nodeport,另外,由于这个Pod与服务service-httpd同属于default namespace,因此,可以省略 default,直接用service-httpd访问Service。而如果处于不同的namespace,则必须通过<SERVICE_NAME>.<NAMESPACE_NAME>来访问。
五、如何通过外网访问service
上面介绍的Service访问,仅限于在集群内部,而很多情况下,我们希望应用的Service能够暴露给Cluster外部。K8s提供了多种类型的Service,默认是ClusterIP。
ClusterIP
Service通过Cluster内部的IP对外提供服务,只有Cluster内的节点和Pod可访问,这是默认的Service类型,前面实验中的Service都是ClusterIP。
NodePort
Service通过Cluster节点的静态端口对外提供服务。Cluster外部可以通过<NodeIP>:<NodePort>访问Service。
LoadBalancer
Service利用云平台提供的load balancer对外提供服务,云平台负载均衡负责将流量导向Service。目前支持的有GCP、AWS、Azur等。
这里重点介绍下NodePort实现方式,先修改之前的service.yml文件,内容如下:
apiVersion: v1
kind: Service
metadata:
name: service-httpd
spec:
type: NodePort
selector:
run: httpdservice
ports:
- protocol: TCP
port: 8080
targetPort: 80此文件中主要是添加了type: NodePort,重新执行这个文件,命令如下:
[root@master service]# kubectl apply -f service.yml
从上图可以看出,k8s依然会为service-httpd分配一个 ClusterIP,不同的是:
TYPE变为NodePort,并且PORT(S)变成8080:30271/TCP,
其中,8080 是 ClusterIP监听的端口(每个节点都有该端口),30271则是节点上监听的端口。
K8s会从30000-32767中分配一个可用的端口,每个节点都会监听此端口,并将请求转发给 Service。
现在就可以通过该Cluster每个节点自身的IP访问Service了。
[root@master service]# curl 172.16.213.221:30271
<html><body><h1>It works!</h1></body></html>
[root@master service]# curl 172.16.213.222:30271
<html><body><h1>It works!</h1></body></html>
[root@master service]# curl 172.16.213.223:30271
<html><body><h1>It works!</h1></body></html>通过三个节点IP + 30271端口都能够访问service-httpd服务。
不知道大家注意到了吗,NodePort默认是的随机选择,这不是我们想要的,我们想要固定的端口,此时可以通过nodePort指定某个特定端口。修改之前的service.yml文件,添加NodePort配置:
apiVersion: v1
kind: Service
metadata:
name: service-httpd
spec:
type: NodePort
selector:
run: httpdservice
ports:
- protocol: TCP
nodePort:32000
port: 8080
targetPort: 80现在此配置文件中就有三个Port了,分别是:
- nodePort是节点上监听的端口。
- port是ClusterIP上监听的端口。
- targetPort是Pod监听的端口。
六、外网访问service映射机制
k8s是如何将 <NodeIP>:<NodePort> 映射到 Pod 的呢?其实,与ClusterIP一样,也是借助了iptables。不过与ClusterIP相比,每个节点的iptables中都增加了下面两条规则:
首先,查看svc端口:

接着,查看iptables规则:

规则的含义是:访问当前节点30271端口的请求,会应用到规则KUBE-SVC-5FEAUJNCXGRSJFN5
最后,查看相应规则KUBE-SVC-5FEAUJNCXGRSJFN5:

这其实就是一个负载均衡,将请求负载均衡到后端每个pod上。