1. LSTM 模型
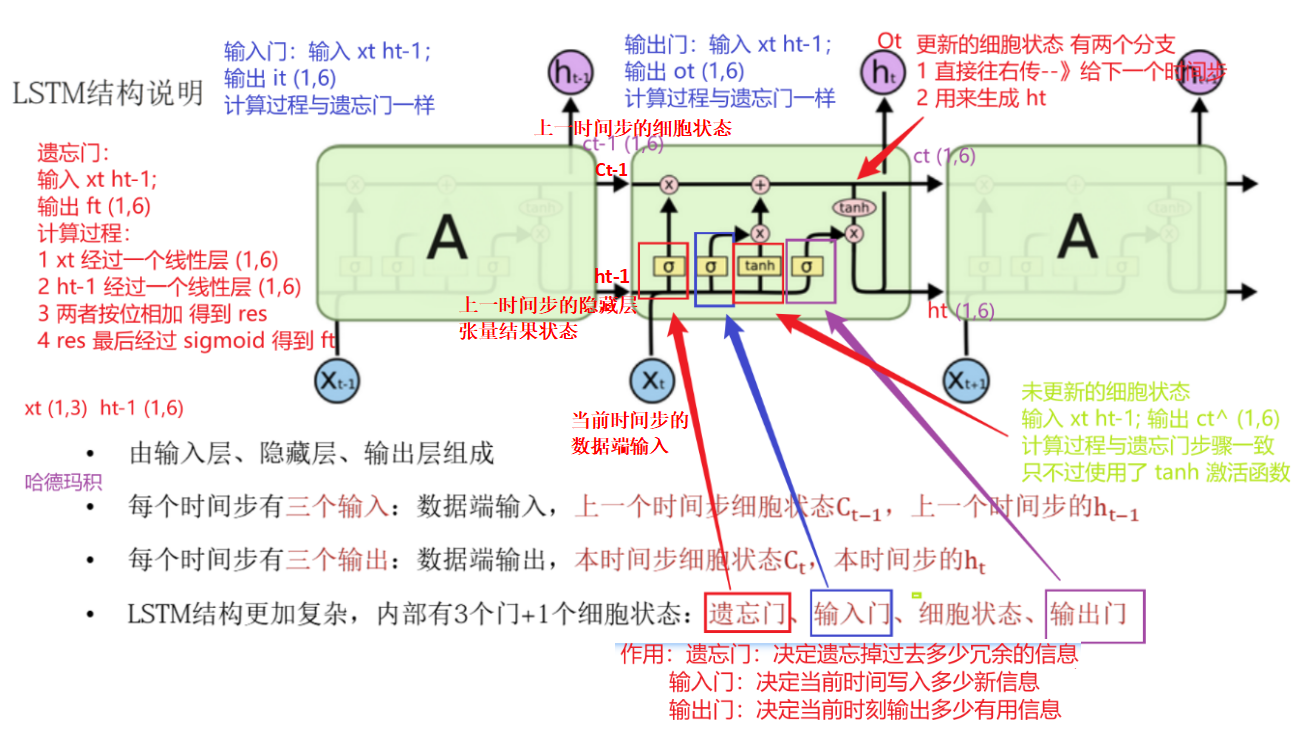
总结:首先 LSTM内部结构是 3个门+1个细胞状态,分别是:遗忘门、输入门、细胞状态、输出门 。首先,①对于遗忘门,遗忘门门值 ft获取:由当前时间步的数据端输入 xt 与上一时间步隐藏层张量的结果 ht-1 按位相加后,经过一个全连接层(工业界实现:xt和 ht-1分别先经过一个 linear层再按位相加),再经过一个 sigmoid激活函数,得到一个遗忘门门值 ft ;② 对于输入门门值 it获取:与 ft获取一样,将 xt和 ht-1按位相加后,经过全连接层,再经过 sigmoid激活函数得到输入门门值 it ;②' 还包括另一部分:xt、ht-1按位相加后送给 linear全连接层,再经过一个 tanh激活函数,得到一个 当前时间步的未更新的临时的细胞状态 Ct~ ;③ 细胞状态更新:(前面得到的遗忘门门值 ft与 上一个时间步的细胞状态 Ct-1按位相乘(点积、哈达玛德积)的结果 )➕(前面得到的输入门门值 it与 当前时间步的未更新的细胞状态 Ct相乘的结果)进行按位相加 = 得到 当前时间步更新后的细胞状态 Ct ;④ 对于输出门:与 ft、it获取一样,将 xt和 ht-1按位相加后,经过全连接层,再经过 sigmoid激活函数得到输出门门值 ot ;④'使用这个门值 Ot产生 当前时间步更新后的隐藏层状态输出 ht :他将作用在当前时间步更新后的细胞状态 Ct 上,并做 tanh激活,最终得到一个 输出门门值ot 向上输出;一个 当前时间步更新后的隐藏层状态输出 ht 作为下一时间步输入的一部分,整个输出门的过程,就是为了产生当前时间步更新后的隐藏层状态 ht。

① 对于 ht-1(隐藏状态)和 Ct-1(细胞状态):两者都包含了历史消息:ht-1是一个短期记忆,临时的上下文;Ct-1是一个长期记忆。② 图中每个黄色块都是一个 linear全连接层、3个σ代表3个门值(σ表示 sigmoid激活函数、tanh代表tanh激活函数?),值域(0,1),它是黄色的,所以每个门的门值对应一个全连接层;③ 图中的 表示按位相加,
表示按位相加, 表示按位相乘(点积、哈达玛德积);
表示按位相乘(点积、哈达玛德积);

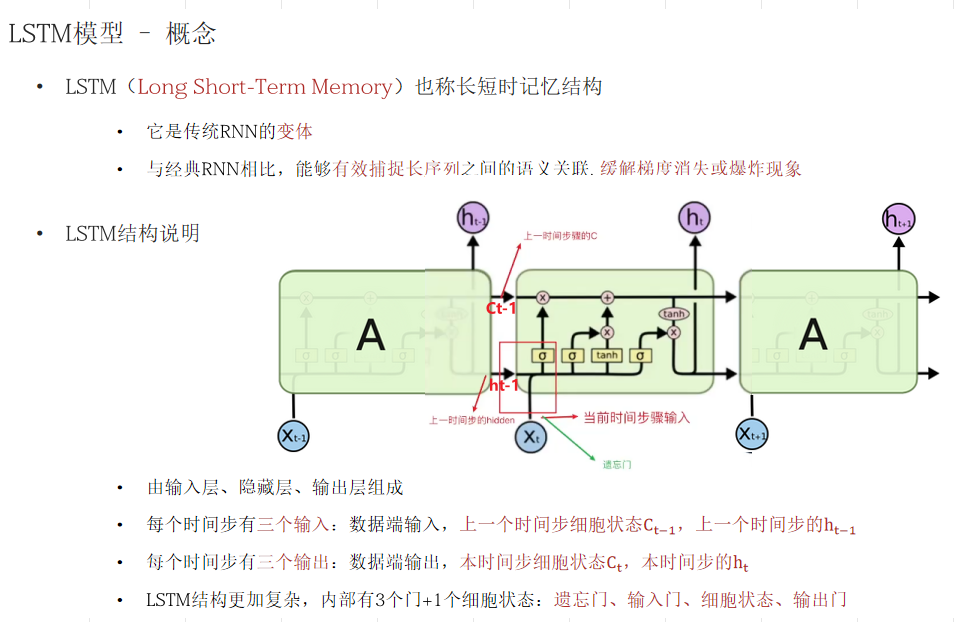
(LSTM的输入包含三部分:当前时间步输入Xt、上一时间步的隐藏层张量输出结果 hidden、上一时间步的C(细胞状态);细胞状态 :图中下面部分进行复制:一个output输出、一个 ht传入下一层,所以上面没有交叉的部分称为细胞状态。)
(总结:为什么每词门值都要用到 ht-1?:因为 ht-1是一个临时的上下文信息、Xt是当前新的信息,根据以往的信息以及当前的信息共同决定哪些历史信息重要 哪些不重要:不重要的进入遗忘门门值作用下进行删除。对于输入门:根据历史上下文信息和当前新的输入是不是共用一个主题,是的话输入门的门值就非常大,将其加入,保留到长期中;否则将门值设定的很小。)
1.1 各组件分析
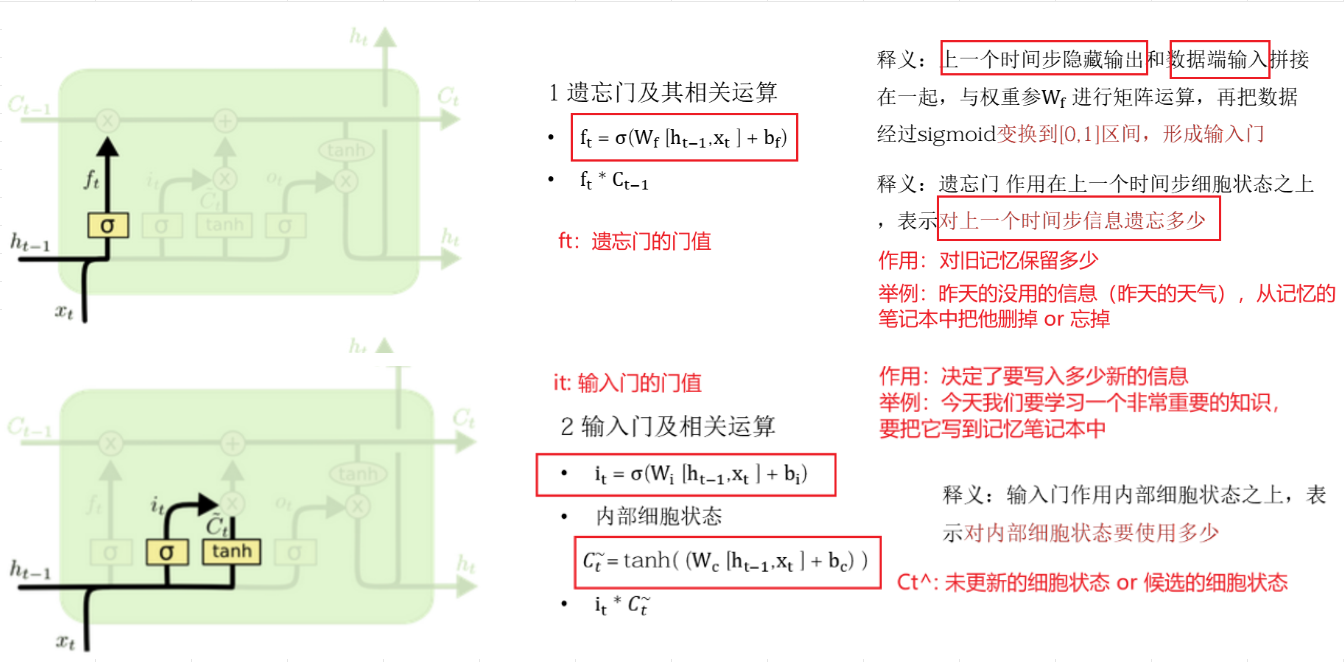
1️⃣ 遗忘门结构分析 :将当前时间步输入 xt与上一时间步隐藏层状态 ht-1进行 concat拼接得到 xt, ht-1,然后通过一个 linear全连接层做变换,最后通过 sigmoid函数进行激活得到一个遗忘门门值 ft,(sigmoid值域(0,1)则 ft值(0,1)),好比一扇门开合的大小程度,门值都将作用在通过该扇门的张量,遗忘门门值将作用的上一层的细胞状态上,代表遗忘过去的多少信息,又因为遗忘门门值是由 xt,ht-1计算得来的,因此整个公式意味着根据当前时间步输入和上一个时间步隐含状态 ht-1来决定遗忘多少上一层的细胞状态所携带的过往信息;
(① concat之后一定要经过一个全连接层,全连接层的核心目标是为了进行形状的转化。② 对于xt, ht-1作用得到一个门值,作用的地方是上一层的细胞状态,上一层的细胞状态包含前文信息,遗忘门会选择性部分遗忘即 选择性部分记忆,并非全部记忆;对于 RNN它的缺点是:链式法则需要考虑到全部,每一个词都要记忆,每次都要对最前面的词进行求导,链式法则时会乘很多元素;现在遗忘门会将前文信息选择性的遗忘删除,使得在连乘时元素个数减少,因此遗忘门可以缓解梯度消失现象。如何判断遗忘?:假设开始时遗忘门的门值都是 1即都进行了保留,但模型本身有损失,损失大效果差,黄色部分是一个 linear层,权重也会更新,导致门值一定也会更新。遗忘门门值获取:由当前时间步的 xt与上一时间步隐藏层张量的结果 ht-1拼接后,经过一个全连接层,再经过一个 sigmoid激活函数,得到一个遗忘门门值 ft; f即 forget)
2️⃣ 输入门结构分析:我们看到输入门的计算公式有两个:第一个就是产生输入门门值的公式,它和遗忘门公式几乎相同,区别只是在于它们之后要作用的目标上,这个公式意味着输入信息有多少需要进行过滤;输入门的第二个公式是与传统 RNN的内部结构计算相同,对于 LSTM来讲,它得到的是当前的细胞状态,而不是像经典 RNN一样得到的是隐含状态。
(① xt与 ht-1拼接后经过 linear全连接层线性变换后,经过 sigmoid激活函数后得到一个 输入门的门值 it ;这个门值乘以 一个xt与 ht-1拼接后经过 linear全连接层线性变换后,经过 tanh得到的结果 Ct~ (此结果类似传统 RNN输出的结果,对此结果做了输入门的选择:Ct~ 可看作是临时的细胞状态或者说是加了新的 xt之后,当前时间步得到的一个新的临时的细胞状态,但需要通过输入门对其进行选择性的记忆(即经过输入门进行一次过滤));② 输入门包含两部分:获取输入门门值、选择输入的对象(即输入门即将作用的对象):第一部分:输入门门值获取:由 xt、ht-1拼接后送给 linear全连接层,sigmoid后得到输入门门值 it;第二部分:作用的对象:xt、ht-1拼接后送给 linear全连接层,再经过一个 tanh激活函数,得到一个结果 Ct~(Ct ~是加了新的 xt之后,当前时间步得到的一个新的临时的细胞状态,但需要通过输入门对其进行选择性的记忆);
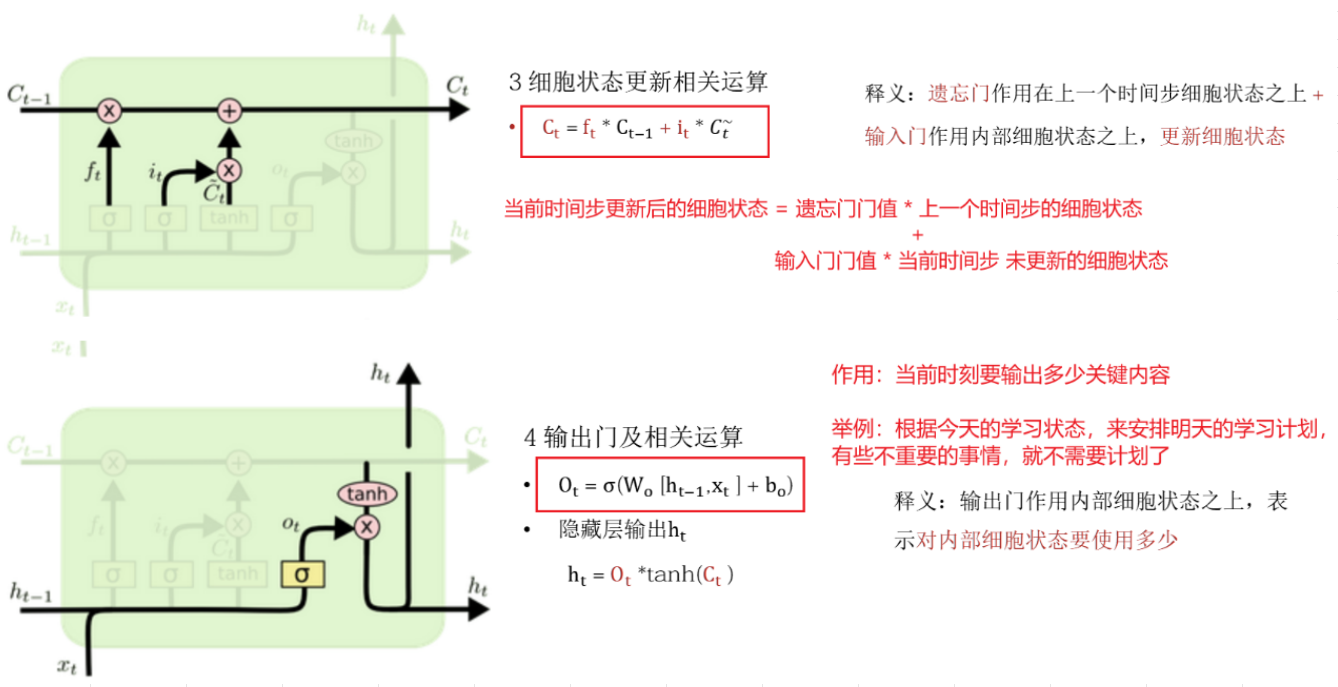
3️⃣ 细胞状态更新分析:细胞更新的结构这里没有全连接层,只是将刚刚得到的遗忘门门值 ft 与 上一个时间步的细胞状态 Ct-1 相乘;再加上输入门门值 it 与 当前时间步的未更新的细胞状态Ct 相乘的结果,最终得到 更新后的细胞状态 Ct作为下一个时间步输入的一部分,整个细胞状态更新过程就是对遗忘门和输入门的应用。
(细胞状态更新用到了遗忘门门值 ft和输入门门值 it,公式: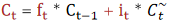 :
:
选择性遗忘:遗忘门 ft作用于上一时间步的细胞状态 Ct-1,ft * Ct-1这个过程是选择性的遗忘'历史的'一些消息 ➕️ 选择性输入:输入门 it作用于'当前'真实输入的一部分 Ct~,哪些重要则记忆,不重要的赋值给小的权重值 = 两者融合:既包含了以前的历史信息、又包含了当前输入的新的信息,最终得到当前时间步新的细胞状态 Ct。得到新的细胞状态 Ct后可直接进行输出,给下一个时间步进行使用;此时当前时间步的细胞状态已经更新完毕。)
4️⃣ 输出门结构分析:输出门部分的公式也是两个,第一个即是计算输出门的门值 ot,它和遗忘门,输入门计算方式相同;第二个即是使用这个门值产生隐含状态 ht,他将作用在更新后的细胞状态 Ct上,并做 tanh激活,最终得到一个 ot向上输出。一个 ht作为下一时间步输入的一部分,整个输出门的过程,就是为了产生隐含状态 ht。
(有 xt、ht-1经过一个 linear层,在经过 sigmoid得到 output,此结果值再(0,1)之间;它作用到已经更新好的 Ct(细胞状态)中,最终得到一个新的结果 ht。)
对于 ht-1(隐藏状态)和 Ct-1(细胞状态):两者都包含了历史消息:ht-1是一个短期记忆,临时的上下文;Ct-1是一个长期记忆。
Ct 细胞状态,可理解为一个长期记忆;即从开始到结束,Ct记录了一个完整的过程;如:对于一个月,如果不考虑遗忘门,Ct保留了 1号~ 30号每天的信息,但是有遗忘门的存在,Ct会选择性的遗忘某些少量的不重要的信息;
Ht 可理解为一个短期记忆;可理解为只保留昨天的内容和今天的主要信息;ht主要作用是帮忙筛选 Ct信息的。
1.2 核心组件的意义
解释 LSTM的输入门、遗忘门、细胞状态的意义,以及**ht-1(隐藏状态)和 Ct-1(细胞状态)**的区别和作用
1️⃣ 细胞状态 Ct(长期记忆)
意义:细胞状态 Ct,是 LSTM的"长期记忆",记录了从开始到现在的关键信息;
作用:通过遗忘门和输入门的调控,Ct能记住长时间跨度的规律(长期依赖),避免遗忘重要信息。
2️⃣ 遗忘门(决定忘掉什么)
·意义:遗忘门决定哪些旧信息(存在Ct-1中)已经不重要,可以"忘掉"。
3️⃣ 输入门(决定记住什么)
意义:输入门决定当前输入 xt中哪些新信息值得加入到细胞状态 Ct中,成为长期记忆。
4️⃣ 隐藏状态 ht-1(短期记忆)
意义:ht-1是上一时间步的输出,相当于对过去信息的"短期总结"。
作用:提供上下文,帮助遗忘门和输入门判断哪些信息重要。
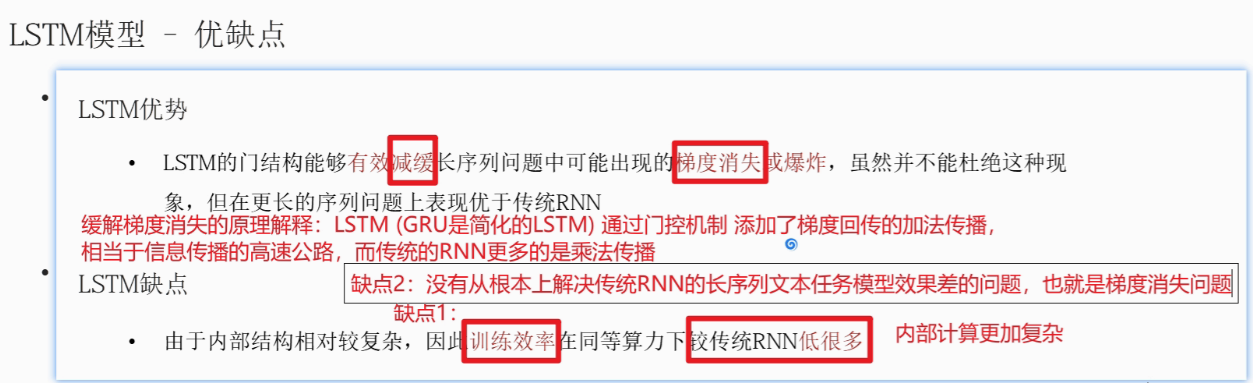
1.3 LSTM优缺点
1.4 LSTM 代码
python
import torch.nn as nn
import torch
def lstm_base():
# 1.实例化模型
# RNN参数说明:
# 第一个参数 input_size:输入的词嵌入维度
# 第二个参数 hidden_size:输出隐藏层的维度(RNN单元输出的隐藏层张量的维度)
# 第三个参数 num_layers:RNN的层数(有几个隐藏层)
model = nn.LSTM(input_size=3, hidden_size=4, num_layers=1,batch_first=True)
# 2.获取 x输入:与RNN一样
# x0的参数说明:
# 第一个参数 batch_size:一个批次送入几个样本(默认batch_size放在第二个参数;因为设置了batch_first=True,所以batch_size放在第一个参数位置)
# 第二个参数 sequence_len:每个样本长度(单词的个数)(因为RNN模型batch_first=False,seq_len放在第一位置)
# 第三个参数 input_size:输入的词嵌入维度
x0 = torch.randn(2, 4, 3) # 每批次两个句子,每个句子4个单词,每个单词的词嵌入维度是3
# 3.获取h0 c0输入
# h0 c0 的参数说明:两者一样,h0.shape = c0.shape
# 第一个参数 num_layers:RNN的层数(有几个隐藏层)
# 第二个参数 batch_size:一个批次送入几个样本
# 第三个参数 hidden_size:隐藏层的维度(RNN单元输出的隐藏层张量的维度)
h0 = torch.randn(1, 2, 4)
c0 = torch.randn(1, 2, 4)
# 将输入送给RNN模型得到下一时间步的输出结果:
output, (hn, cn) = model(x0, (h0, c0))
print(f'output: {output}')
print(f'hn: {hn}')
print(f'cn: {cn}')
if __name__ == '__main__':
lstm_base()2. Bi-LSTM 模型
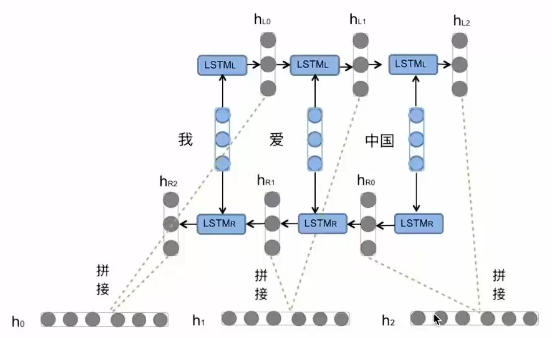
BI-LSTM结构分析:我们看到图中对"我爱中国"这句话或者叫这个输入序列,进行了从左到右和从右到左两次 LSTM处理,将得到的结果张量进行了拼接作为最终输出。这种结构能够捕捉语言语法中一些特定的前置或后置特征,增强语义关联,但是模型参数和计算复杂度也随之增加了一倍,一般需要对语料和计算资源进行评估后决定是否使用该结构。
(总结:一句话从左到右、从右到左分别进行一次 LSTM处理,分别得到一个隐藏层张量,再将两者进行拼接,就是 BI-LSTM的输出结果。)
3. GRU 模型
总结:①对于重置门门值 rt :由当前时间步的数据端输入 xt 与上一时间步隐藏层张量的结果 ht-1 按位相加后,经过一个全连接层(工业界实现:xt和 ht-1分别先经过一个 linear层再按位相加),再经过一个 sigmoid激活函数,得到一个重置门门值 rt;② 对于更新门门值 zt,同重置门 :xt、ht-1按位相加后,经过一个全连接层,再经过一个 sigmoid激活函数,得到更新门门值 zt ;①'得到的重置门门值 rt再与上一时间步隐藏层张量的结果 ht-1按位相乘(两者作用代表控制上一时间步传来的信息有多少可以被利用),再与当前时间步的数据端输入 xt进行拼接,经过一个全连接层,再经过一个 tanh激活函数,得到 当前时间步未更新的的隐藏层状态 ht~ ;③ 对于当前时间步更新后的隐藏层状态输出 ht获取:(1 - 更新门门值 Zt 再与上一时间步隐藏层张量的结果 ht-1按位相乘后的结果)➕(更新门门值 Zt 与 当前时间步未更新的的隐藏层状态 ht ~ 按位相乘后的结果) 进行按位相加 = 得到 当前时间步更新后的隐藏层状态输出 ht:有两个方向,向上的 Ot、向右的 ht;这个过程意味着更新门有能力保留之前的结果,当门值趋于1时,输出就是新的 ht,而当门值趋于0时,输出就是上一时间步的ht-1;)
3.1 GRU定义和概念
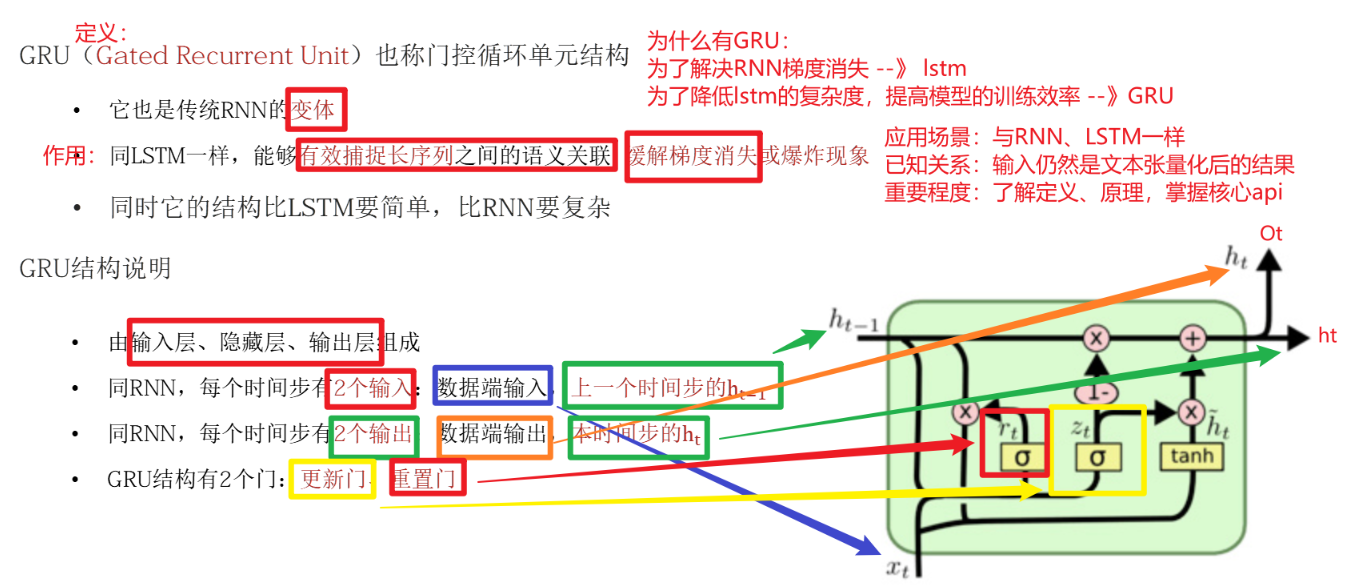
3.2 GRU内部结构
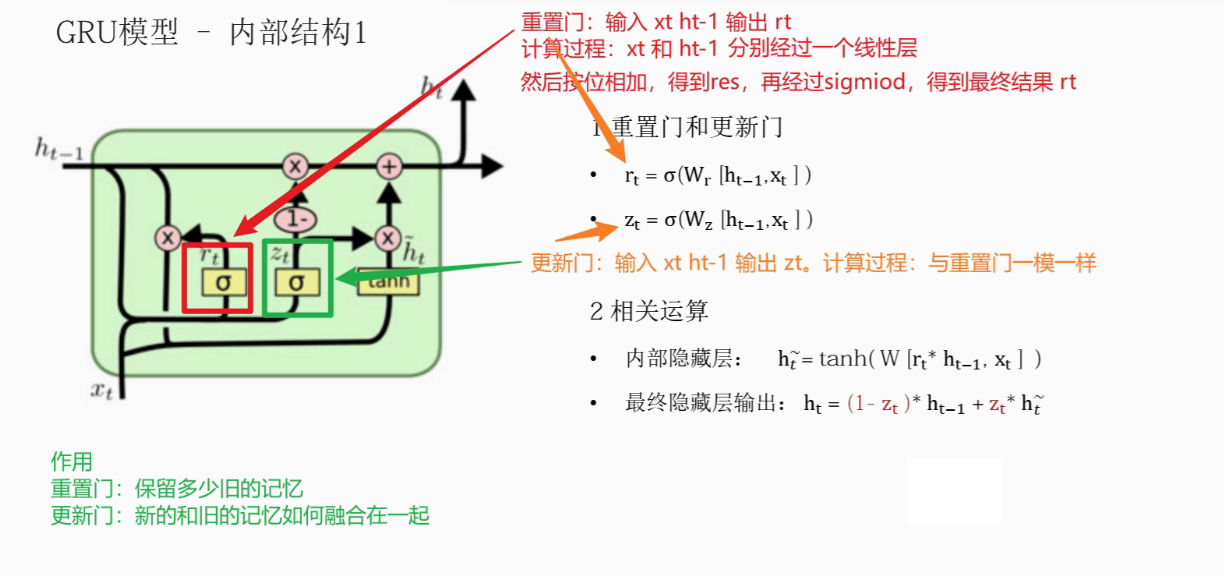
①对于重置门门值 rt (r即reset):由当前时间步的数据端输入 xt 与上一时间步隐藏层张量的结果 ht-1 按位相加后,经过一个全连接层(工业界实现:xt和 ht-1分别先经过一个 linear层再按位相加),再经过一个 sigmoid激活函数,得到一个重置门门值 rt;② 对于更新门门值 zt,同重置门 :xt、ht-1按位相加后,经过一个全连接层,再经过一个 sigmoid激活函数,得到更新门门值 zt ;①'得到的重置门门值 rt再与上一时间步隐藏层张量的结果 ht-1按位相乘(两者作用代表控制上一时间步传来的信息有多少可以被利用),再与当前时间步的数据端输入 xt进行拼接,经过一个全连接层,再经过一个 tanh激活函数,得到 当前时间步未更新的的隐藏层状态 ht~ ;③ 对于当前时间步更新后的隐藏层状态输出 ht获取:(1 - 更新门门值 Zt 再与上一时间步隐藏层张量的结果 ht-1按位相乘后的结果)➕(更新门门值 Zt 与 当前时间步未更新的的隐藏层状态 ht ~ 按位相乘后的结果) 进行按位相加 = 得到 当前时间步更新后的隐藏层状态输出 ht;这个过程意味着更新门有能力保留之前的结果,当门值趋于1时,输出就是新的 ht,而当门值趋于0时,输出就是上一时间步的ht-1;)
rt重置门:与 LSTM中的遗忘门 ft类似:记住多少新的信息,删除过去冗余信息;
zt更新门:确定新记忆与旧记忆以多少比例组合;('1-zt * ht-1过去的记忆'...,zt * ht~新的记忆)
3.3 GRU优缺点

3.4 GRU代码
python
import torch.nn as nn
import torch
def gru_base():
input_ = torch.randn(2, 3, 8)
h0 = torch.randn(2, 2, 3)
gru = nn.GRU(8, 3, 2, batch_first=True)
output, hn = gru(input_, h0)
print(output.shape) # [2, 3, 3]
print(hn.shape) # [2, 3, 3]
if __name__ == '__main__':
gru_base()4. Bi-GRU 模型
Bi-GRU与 Bi-LSTM的逻辑相同,都是不改变其内部结构,而是将模型应用两次且方向不同,再将两次得到的 LSTM结果进行拼接作为最终输出,具体参见.上小节中的 Bi-LSTM。
5. RNN & LSTM & GRU 三者对比
1️⃣ 结构上区别:
RNN:一个输入、一个输出。输入分为两部分:当前时间步数据端输入+ 上一时间步的隐藏层张量结果;
LSTM:遗忘门、输入门、细胞状态、输出门。
GRU:重置门、更新门。
2️⃣ 为什么会有三个模型: 因为 RNN在处理长序列问题时会出现梯度消失和梯度爆炸现象,因此衍生出 LSTM和 GRU;LSTM内部结构较复杂,但能缓解 梯度消失和梯度下降的问题;GRU是针对 LSTM的改进,相比 LSTM的模型更简单,也能缓解梯度消失和梯度下降的问题;