2026-05-29 arXiv 论文带读:GeoAI、空间智能与多模态 Agent 的 9 篇高质量新作
今天这篇按"值得认真读"筛,不强行凑 10 篇。筛选标准主要有四个:
- 方向贴近 GeoAI、遥感/地球观测基础模型、空间表示学习、空间 RAG/GIS Agent、多模态 VLM、具身空间推理;
- 论文有明确问题意识,不只是把 LLM/VLM 套到任务上;
- 团队或机构背景可信,或者数据/benchmark/方法有复用价值;
- 有关键图表可以帮助快速理解论文核心贡献。
来源:arXiv CS new listing, Friday, 29 May 2026。图片均来自对应论文的 arXiv HTML 页面,下面只做导读式解读,不搬运论文长摘要。
1. EarthShift:遥感基础模型真正要面对的分布偏移
论文 :EarthShift: a benchmark for measuring robustness to real-world distribution shifts in Earth observation
作者/团队 :Kelsey Doerksen, Hannah Kerner,Arizona State University, School of Computing and Augmented Intelligence
来源:arXiv: https://arxiv.org/abs/2605.29330
Arizona State University 的 Hannah Kerner 团队长期做机器学习与地球观测交叉,方向包括遥感、农业/环境监测、地球科学 AI。这个团队做 EarthShift 很合理:它不是只关心模型在静态测试集上的分数,而是问一个更接近部署的问题:模型换时间、换地区、换传感器、换尺度后还稳不稳?
核心创新:EarthShift 把遥感分布偏移做成了系统 benchmark。论文评估了 8 个 geospatial foundation models、11 个任务、5 类真实 shift。它的重点不是再给一个新模型,而是给 GeoAI 社区一个检验可靠性的公共试验台。
关键图:ID/OOD 鲁棒性分析
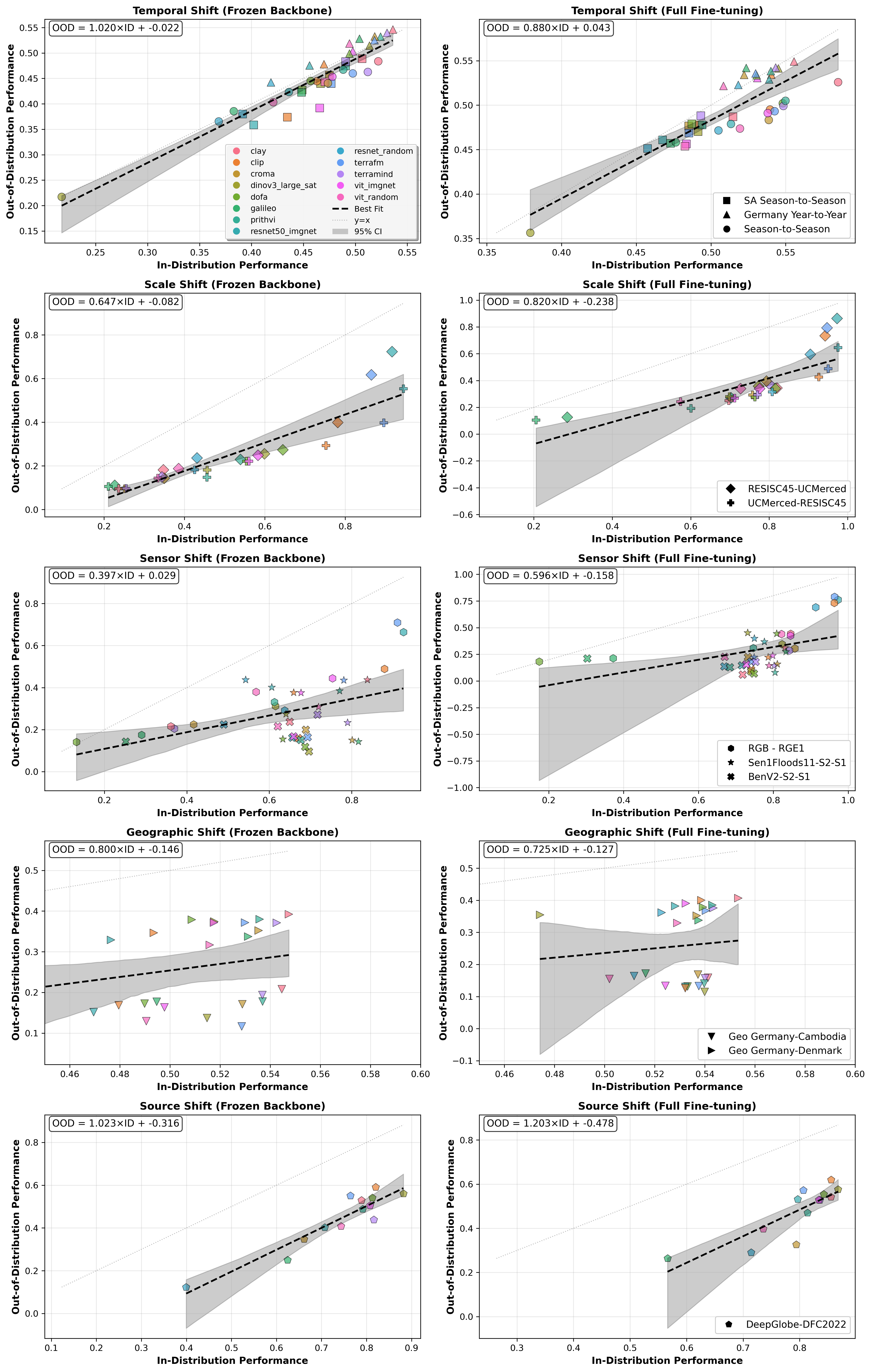
这张图的读法很直接:横轴是 in-distribution 表现,纵轴是 out-of-distribution 表现;如果点落在 y=x 附近,说明模型换场景后性能基本不掉。实际大量点低于对角线,说明 OOD 退化是普遍现象。论文摘要里提到 GFMs 在 OOD 场景平均下降约 15%-20%。
我觉得最值得带走的一点:遥感基础模型如果只在同分布 benchmark 上刷分,离真实应用还差一大截。未来 GeoAI 模型要比的不是"某个数据集上更高一点",而是跨传感器、跨地区、跨时间的鲁棒性。
2. DenseUIS:城中村建筑与道路识别,一个很接地气的城市遥感 benchmark
论文 :Building and Road Recognition in Dense Urban Informal Settlements: A Dataset and Benchmark
作者/团队 :Hongyu Long, Jiaxuan Liu, Rui Cao;论文支持信息显示与广东省项目、广州-HKUST(GZ) 联合资助、城市文化 AI 基地相关
来源:arXiv: https://arxiv.org/abs/2605.29856
这篇不是"大模型味"最浓的一篇,但我很推荐。它聚焦中国城市里的高密度非正式住区,也就是类似城中村的复杂城市肌理。常规遥感建筑/道路数据集多偏正式城区,但城中村里楼距小、道路窄、遮挡重、边界乱,这对 building extraction 和 road extraction 都很难。
核心创新:提出 DenseUIS,高分辨率遥感数据集,覆盖深圳和广州 126 个城中村,用于建筑与道路识别,并系统评估现有深度学习模型在该场景下的局限。
关键图:为什么现有地图和常规数据不够用
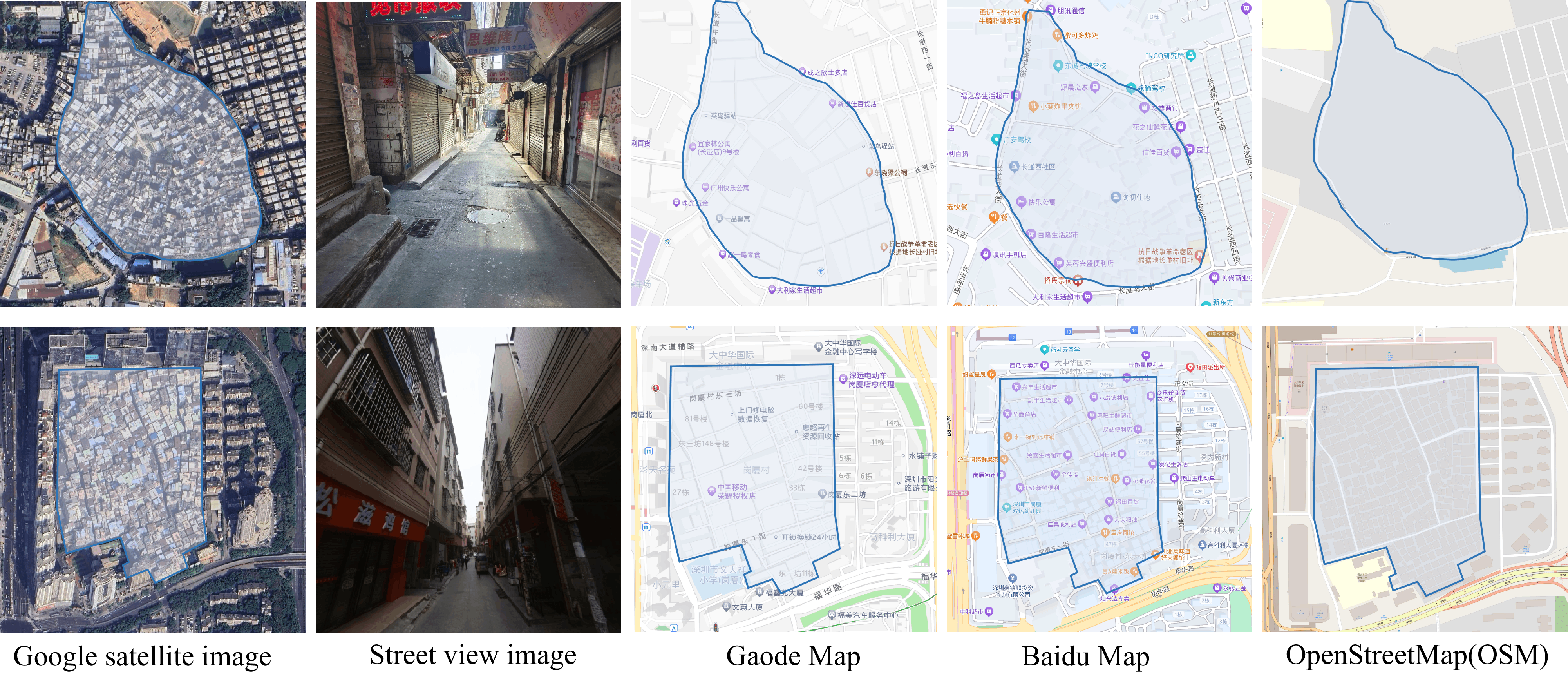
这张图的重点不是视觉好看,而是问题定义:高密度建筑和细碎道路在普通地图平台和通用遥感数据中经常表达不足。你可以把它看成"城市遥感从宏观覆盖走向精细治理"的一个缩影。
我觉得最值得带走的一点:GeoAI 不应该只追求全球尺度和基础模型,也需要这种高难度、强地域性的细粒度 benchmark。对城市治理、韧性城市、基础设施普查来说,这类数据集非常实用。
3. HTP:不是让 LLM 直接吐 GPS 点,而是先生成"出行模式 token"
论文 :From GPS Points to Travel Patterns: Flexible and Semantic Trajectory Generation with LLMs
作者/团队 :Silin Zhou, Chenhao Wang, Yuntao Wen, Shuo Shang, Lisi Chen, Panos Kalnis;电子科技大学与 KAUST 合作
来源:arXiv: https://arxiv.org/abs/2605.30014
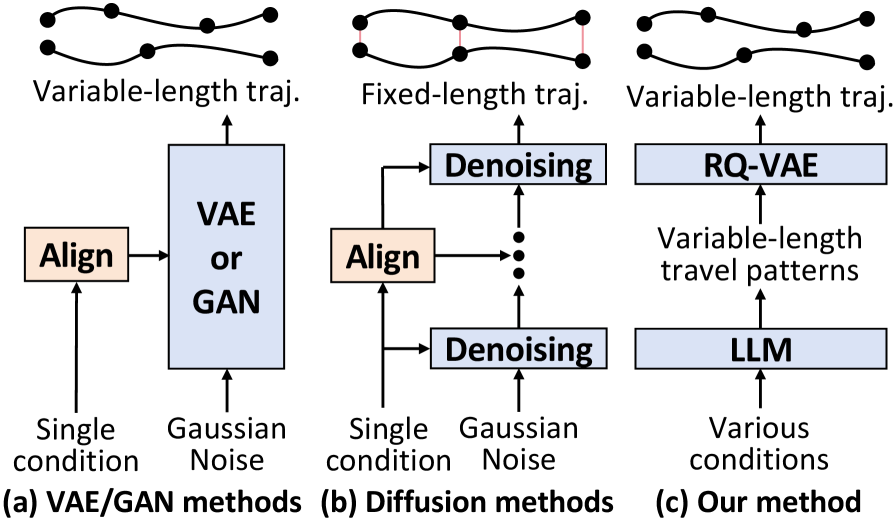
这篇属于城市计算 + LLM 的比较自然的结合。很多轨迹生成方法要么直接生成 GPS 点,要么条件控制能力弱。HTP 的想法是:先把微观 GPS 轨迹压缩成宏观 travel pattern tokens,再让 LLM 学会生成这些模式,最后解码成 GPS 点。
核心创新:用 RQ-VAE 把轨迹编码成层级 travel pattern token,然后扩展 LLM 词表并做 SFT,让 LLM 在不同条件下生成可控的出行模式序列。它不是把经纬度硬塞进 prompt,而是把轨迹变成 LLM 能处理的"语义 token"。
关键图:HTP 与传统轨迹生成 pipeline 的区别
这张图建议重点看左中右的流程差异。传统方法更偏点级生成,而 HTP 先学宏观模式,再落到点。这个设计的好处是更容易表达"通勤型、绕行型、停留密集型"等模式,也更适合隐私保护下的合成 mobility data。
我觉得最值得带走的一点:时空数据接入 LLM 的关键不是"把坐标文本化",而是找到合适的离散语义单元。对 POI 表征、轨迹表示学习、城市仿真都很有启发。
4. UCLA Mobility Lab:用 GPS 空间先验约束 LLM 生成旅游活动链
论文 :GPS-Enhanced Tourist Mobility Modeling with Seasonal Spatial Priors and LLM-Based Activity Chain Generation
作者/团队 :Yifan Liu, Yanling Sang, Xishun Liao, Morgan Sun, Bo Yang, Zhiyuan Zhang, Chris Stanford, Haoxuan Ma, Jiaqi Ma;UCLA Mobility Lab、Novateur Research Solutions、University of Central Florida
来源:arXiv: https://arxiv.org/abs/2605.29578
UCLA Mobility Lab 的方向本来就贴近交通、城市移动性和仿真。这篇的场景是旅游移动性:游客不像通勤者,行为更受季节、目的、同行人、停留天数影响。论文没有让 LLM 自由编行程,而是用 GPS 聚合先验和调查数据给 LLM 加地理约束。
核心创新:四阶段框架:月度空间先验、行程范围预测、距离可行的 ward 序列分配、LLM 活动链生成。它强调 GPS 只用聚合形式,避免暴露个人轨迹。
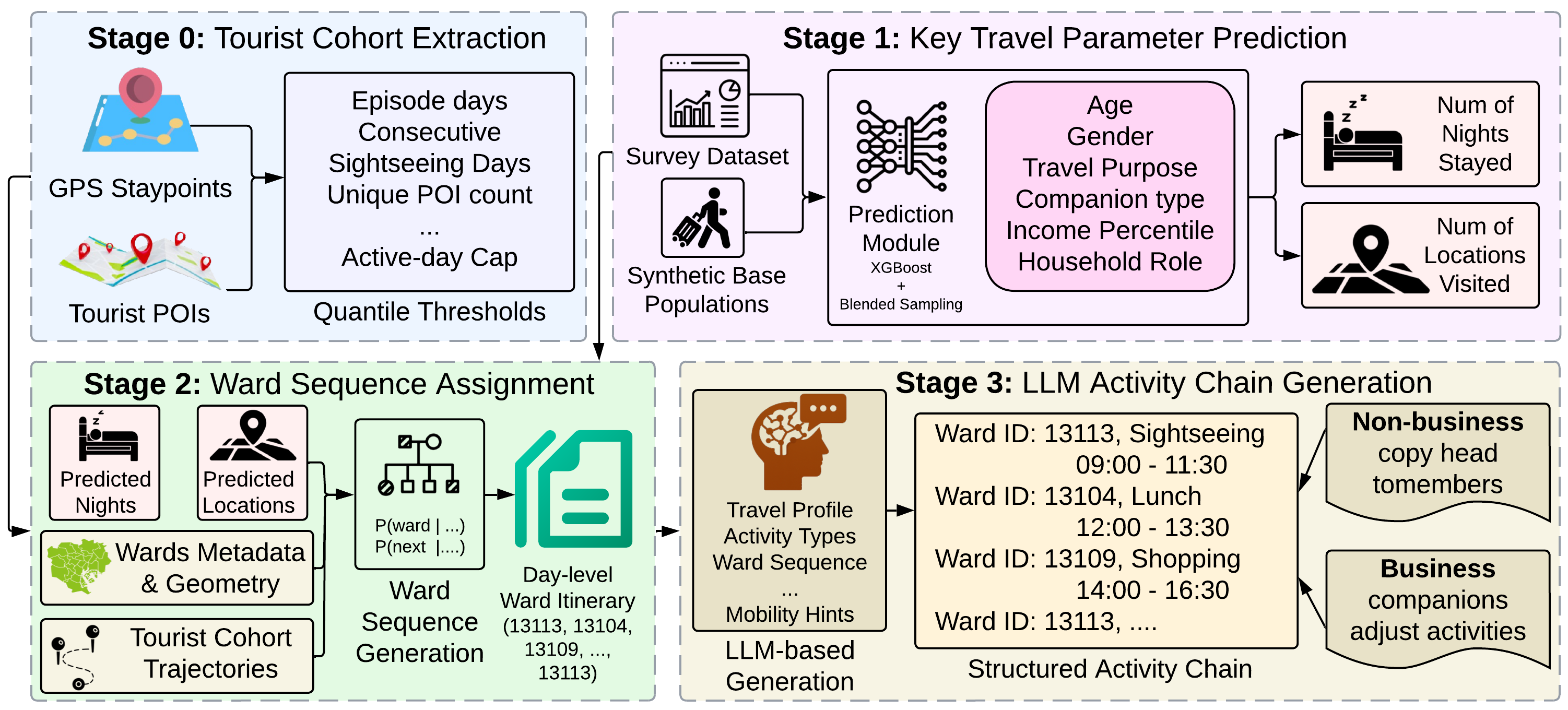
关键图:四阶段旅游移动性建模框架
这张图建议从左到右看:它不是一个端到端黑箱 LLM,而是把传统交通建模的约束与 LLM 的活动链生成结合起来。真正有价值的是"LLM 负责生成语义行程,但空间分布和可达性由数据先验约束"。
我觉得最值得带走的一点:LLM 做城市仿真时,最好不要完全自由生成。把地理先验、交通约束、人口属性放进生成链路,才可能得到可解释、可校准的 synthetic population/activity chain。
5. SNU + OSU + NVIDIA:VLM 空间推理可能只是学到了"远处在上方"的摄影偏差
论文 :Why Far Looks Up: Probing Spatial Representation in Vision-Language Models
作者/团队 :Cheolhong Min, Jaeyun Jung, Daeun Lee, Hyeonseong Jeon, Yu Su, Jonathan Tremblay, Chan Hee Song, Jaesik Park;Seoul National University、The Ohio State University、NVIDIA
来源:arXiv: https://arxiv.org/abs/2605.30161
这篇我很喜欢,因为它不满足于问"VLM 空间题答对了吗",而是问"模型是不是用了错误捷径"。自然图像里远处物体常常在画面上方,所以 VLM 可能把 2D 垂直位置和 3D 深度关系混在一起。
核心创新:提出 representation-level probing 和 SpatialTunnel benchmark,用最小对比样本检查 VLM embeddings 中的空间轴是否解耦。核心发现是多个 VLM 存在 vertical-distance entanglement。
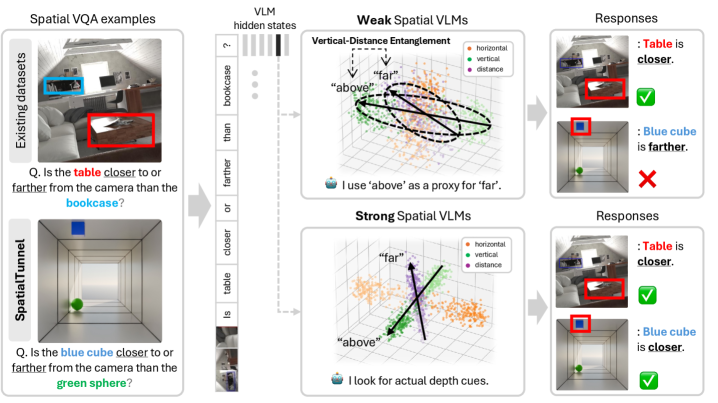
关键图:透视捷径如何误导 VLM
这张图看起来简单,但问题很深:如果远的物体通常更靠上,模型可能把"上方"当成"更远"。一旦构造反常样本,模型就会系统性出错。对地理空间、机器人、自动驾驶来说,这种错误很危险,因为真实空间判断不能依赖摄影数据的统计捷径。
我觉得最值得带走的一点:空间智能不能只看 VQA 准确率。要检查模型内部表征是否真的有几何结构,否则所谓 spatial reasoning 可能只是数据偏差。
6. FAIR at Meta + UC Berkeley + HKU:GASP 给 VLM 注入 3D 几何先验
论文 :Beyond 3D VQAs: Injecting 3D Spatial Priors into Vision-Language Models for Enhanced Geometric Reasoning
作者/团队 :Chun-Hsiao Yeh, Shengyi Qian, Manchen Wang, Yi Ma, Joseph Tighe, Fanyi Xiao;FAIR at Meta、UC Berkeley、HKU。论文说明第一作者在 FAIR 实习期间完成相关工作
来源:arXiv: https://arxiv.org/abs/2605.30231 ,项目页:https://danielchyeh.github.io/GASP/
这个团队背景很强:FAIR、Berkeley、HKU,且 Yi Ma 等作者本身在视觉、几何和表征学习方向影响力很大。这篇和上一篇可以连着读:上一篇指出 VLM 空间表征有偏差,这篇尝试把更底层的几何先验注入模型。
核心创新:GASP 不靠 3D VQA 数据硬微调,而是在 LLM 中间层加入 correspondence head,用点对应和深度一致性信号监督。训练时学几何一致性,推理时丢掉辅助 head,模型仍像普通 VLM 一样使用。
关键图:GASP 的训练思路
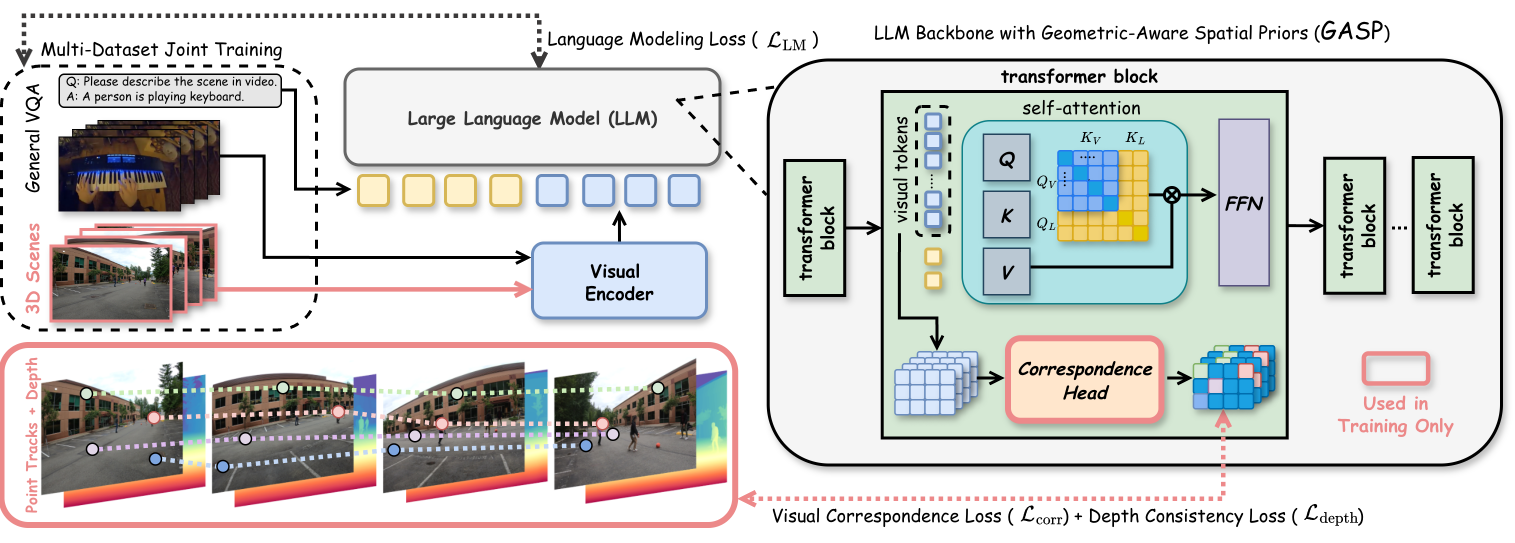
这张图的核心是"训练时加几何监督,推理时不额外依赖 3D 输入"。这比单纯在 3D QA 上 SFT 更有吸引力,因为它试图让模型内部获得可迁移的几何能力,而不是记住某个 benchmark 的问答格式。
我觉得最值得带走的一点:未来空间 VLM 的竞争点可能不只是数据规模,而是如何把几何、对应、深度、多视角一致性这些结构性先验放进模型。
7. SpaMEM:具身 Agent 不是只要看懂一帧图,还要维护动态空间记忆
论文 :SpaMEM: Benchmarking Dynamic Spatial Reasoning via Perception-Memory Integration in Embodied Environments
作者/团队 :Chih-Ting Liao, Xi Xiao, Chunlei Meng, Zhangquan Chen, Yitong Qiao, Weilin Zhou, Tianyang Wang, Xu Zheng, Xin Cao;UNSW Sydney、University of Alabama、Fudan、Tsinghua、Zhejiang University、HKUST(GZ) 等多机构合作
来源:arXiv: https://arxiv.org/abs/2604.22409
这篇虽然 arXiv 号是 2604,但出现在 2026-05-29 的 CS new listing 中,应该是新近进入/更新到该列表。它解决的是具身智能里非常关键的问题:环境会变化,agent 的空间信念也要随着观察更新。
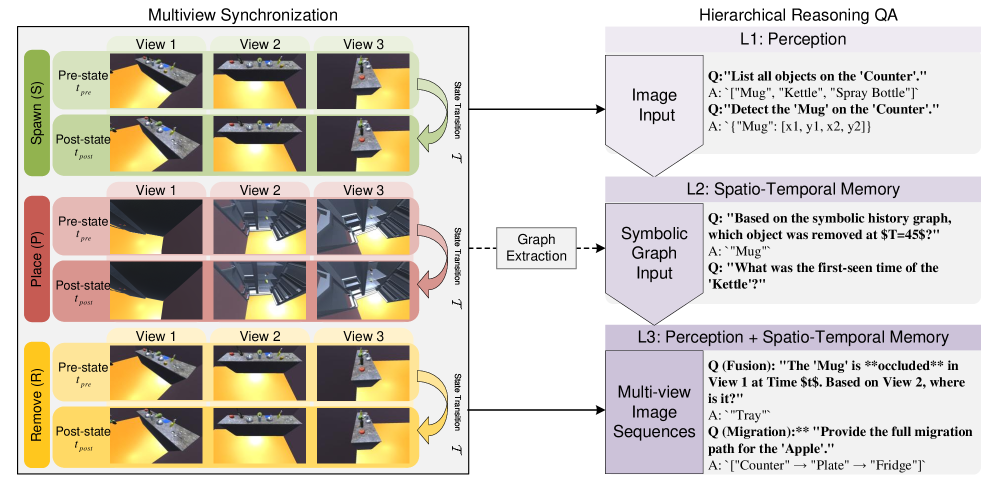
核心创新:SpaMEM 构建动态空间推理 benchmark,用 spawn/place/remove 等动作改变场景,评估模型在长时序中维护空间记忆的能力。它把任务拆成三个层次:单帧空间感知、文本状态历史推理、端到端视觉记忆整合。
关键图:SpaMEM 的三层评估框架
这张图最重要的是 L1/L2/L3:L1 看单次感知,L2 给符号状态历史,L3 要从视觉流里自己维护空间记忆。如果模型 L2 可以、L3 不行,就说明它会"读账本",但不会真正从视觉观察中更新空间世界模型。
我觉得最值得带走的一点:GIS Agent、机器人和空间数字孪生都绕不开 memory。静态 VLM benchmark 不能代表 agent 在动态世界里的能力。
8. Radboud + DFKI:多模态 RAG 不确定性,系统落地必须补的一环
论文 :Uncertainty Quantification for Multimodal Retrieval Augmented Generation
作者/团队 :Simon Binz, Heydar Soudani, Faegheh Hasibi;Radboud University,German Research Center for Artificial Intelligence (DFKI)
来源:arXiv: https://arxiv.org/abs/2605.29956
这篇和空间 RAG/GIS Copilot 很相关。多模态 RAG 的错误来源比文本 RAG 多:检索可能错,图像理解可能错,文本生成也可能过度自信。只看最终答案是否流畅是不够的。
核心创新:LeMUQ 用多种输入条件下的 token probability 信号来估计不确定性,例如去掉图像、去掉检索上下文、同时去掉两者,观察回答概率如何变化,再学习一个多模态 uncertainty estimator。
关键图:LeMUQ pipeline
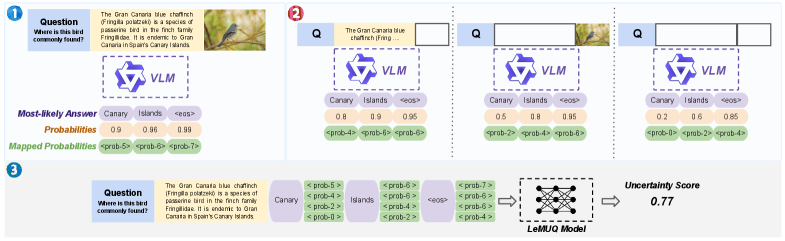
这张图建议看三条信息流:原始 query+image+retrieved context,去模态/去上下文后的替代概率序列,以及最终不确定性估计。它的思想是:一个可靠系统不只回答,还要知道自己依赖了哪些证据,以及证据变化时答案稳定不稳定。
我觉得最值得带走的一点:如果要做遥感问答、地图问答、空间 RAG,uncertainty quantification 不是锦上添花,而是上线前必须考虑的安全模块。
9. SMU + 中山大学:AnomalyAgent,把异常检测从相似度打分推向 agentic reasoning
论文 :AnomalyAgent: Training-Free Agentic Models for Zero-/Few-Shot Anomaly Detection
作者/团队 :Yi Zhang, Jiawen Zhu, Lele Fu, Guansong Pang;Singapore Management University,Sun Yat-sen University
来源:arXiv: https://arxiv.org/abs/2605.30140
Guansong Pang 是异常检测方向活跃学者之一,这篇把 anomaly detection 和 MLLM agent 结合。传统 VLM 异常检测常依赖图文 embedding 相似度,但复杂异常往往需要上下文推理:什么是正常流程、哪里不合逻辑、是否需要调用图像增强/检索等工具。
核心创新:AnomalyAgent 是 training-free agentic framework,包含异常检测工具集、planner/reasoner/reflector 等模块,以及少样本记忆模块。它把 MLLM 的工具使用和推理能力直接放进异常检测流程。
关键图:从相似度检测到 agentic anomaly reasoning
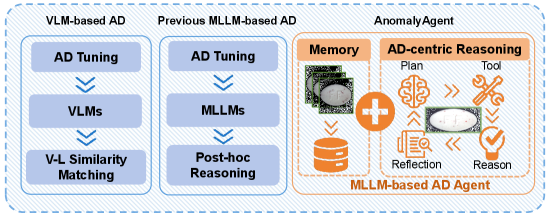
这张图对比了三类路线:传统 VLM-based AD 主要做相似度打分;早期 MLLM-based AD 往往只是后处理解释;AnomalyAgent 则把 MLLM 放进检测流程本身,让模型能规划、调用工具、推理和反思。
我觉得最值得带走的一点:异常检测会从"分数模型"走向"可解释的诊断 agent"。这对工业视觉、遥感灾害异常、城市运行异常都很有想象空间,但也要注意 agent pipeline 的稳定性和成本。
今日总结:这批论文的共同信号
今天最值得关注的不是某一个模型刷了多高分,而是三个趋势:
- GeoAI 从性能走向可靠性:EarthShift 和 DenseUIS 都在提醒我们,遥感模型必须面对真实分布偏移和复杂城市纹理。
- 空间智能从 VQA 走向几何与记忆:Why Far Looks Up、GASP、SpaMEM 都在追问模型是否真的有空间结构,而不是靠数据捷径答题。
- LLM/Agent 进入时空系统,但需要约束和可靠性:HTP、旅游移动性建模、LeMUQ、AnomalyAgent 都说明,LLM 最有价值的位置不是自由生成,而是在空间先验、检索证据、工具调用和不确定性估计的约束下工作。
如果只能读三篇,我建议:
- EarthShift:理解遥感基础模型评估的新门槛;
- Why Far Looks Up + GASP:一篇诊断问题,一篇尝试解决;
- SpaMEM:理解具身/空间 Agent 为什么必须有动态空间记忆。
这也是我接下来会持续跟的方向:可部署的 GeoAI、真正具备几何结构的 VLM、以及面向空间任务的可靠 Agent。