MDP五元组的意义:
它描述了游戏规则和环境的客观规律
它定义了这个环境都有哪些状态;可以做哪些动作;做了动作,状态如何变幻,奖励雨汇报如何变幻。因此,所有的强化学习都可以归纳为一个MDP问题。
但是MDP没有定义决策,如何得到一个最优决策是强化学习算法要解决的事情
强化学习的目标是什么?
根据文献所述,强化学习的目标可以从"直接目的"和"数学表达"两个层面来理解:
1. 核心目标:寻找最优策略
强化学习的终极目标是找到一个最优策略(Optimal Policy,通常表示为 \pi^\*) 。这个策略能够指导智能体在面对任何环境状态时,做出最正确的决策,从而使得智能体从初始状态出发能获得最多的期望回报 。
2. 数学层面的体现
为了达成上述目标,强化学习在数学上是在求解贝尔曼最优方程(Bellman Optimality Equation) :
最大化价值函数:最优策略 \pi^* 会使得每一个状态的价值都达到最大,即达到最优状态价值函数 v^*(s) 和最优动作价值函数 q^*(s) 。
*
满足最优性原理:在当前的状态动作对之后,智能体后续都会坚定地执行最优策略,确保每一步都选择能带来最大最优动作价值的那个动作 :
v^*(s) = \max_{a \in A} q^*(s, a)
探索与利用问题:
如何在有限探索次数下利用曾经探索过的经验,获得最大的奖励?
解决该问题的方法就是epsilon-greedy测率:

epsilon的不同取值或者与时间的设置就构成了不同的贪婪测率
经验回放:
一、 它是如何工作的?
它的运行机制可以拆解为三个步骤:
-
存储经验: 智能体在与环境交互时,每走一步都会产生一个数据元组:当前状态 s_t、采取的动作 a_t、获得的奖励 r_t 以及下一个状态 s_{t+1}。智能体会把这个元组 (s_t, a_t, r_t, s_{t+1}) 存入一个固定容量的回放缓冲区(Replay Buffer)中。
-
滚动更新: 这个缓冲区通常是一个先进先出(FIFO)的队列。当记忆库达到容量上限后,最新产生的经验会覆盖掉最旧的经验。
-
随机采样训练: 在训练神经网络时,智能体不再是 拿刚刚经历的那一步数据立刻去训练,而是从记忆库中随机抽取一个小批量(Mini-batch,例如 32 或 64 条)的历史经验。利用这些打乱的经验来计算损失函数(Loss),并通过梯度下降更新神经网络的参数。
二、 经验回放有什么用?
经验回放(Experience Replay)在深度强化学习中,主要完美地解决了将神经网络与强化学习结合初期所面临的两个"致命问题":
-
打破数据相关性(消除连续性偏差): 智能体在探索环境时,产生的数据往往是按时间顺序连续且高度相关的(比如玩超级玛丽,连续几十帧画面的背景和状态几乎一模一样)。如果直接用这种高度相关的数据去喂给神经网络,网络很容易产生"过拟合"或"灾难性遗忘"。经验回放通过在巨大的记忆库中随机抽样,彻底打乱了数据的时序连贯性,使得训练数据更加独立(符合独立同分布的假设),极大地稳定了神经网络的收敛过程。
-
提升样本利用率(Sample Efficiency): 在传统的强化学习算法中,智能体经历一次状态转换,用它更新一次价值后就会把这条数据扔掉,这在获取数据成本极高的场景(例如真实的机器人控制或自动驾驶)下非常浪费。通过将数据存入记忆库,一条极其珍贵或罕见的经验可能会被随机抽中多次,反复用来训练网络,这大大提高了每一条数据的利用价值。
动作/状态价值:

最优动作/状态价值:

最优状态/动作价值函数:
状态价值函数描述的是在当前策略下,某一个状态的好坏。这个好坏由长期平均回报表征。
最优价值函数描述的是在最优策略下,某一个状态的好坏。
如果每一个状态的最优价值函数(状态好坏)我们都知道,那我们在状态s_k下采取动作a到达状态s_k+1,这个动作a就是最优动作
如果能够得到每一个状态下的状态价值函数,我们就能够做出最优决策了
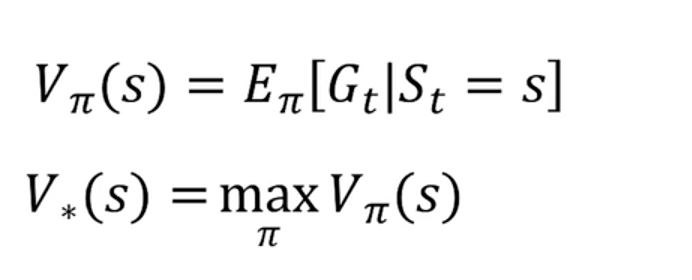
动作价值函数描述的是在当前策略下,在状态s下,采取动作a,随后由当前策略接管走完。用来描述当前状态下,某一个状态的好坏。这个好坏由长期平均回报表征。
最优动作价值函数描述的是在最优策略下,在状态s下,采取动作a,随后由最优策略接管走完。
如果每一个状态的最优价值函数(状态好坏)我们都知道,那我们在状态s_k下采取动作a到达状态s_k+1,这个动作a就是最优动作
如果能够得到每一个状态下的最优动作价值函数,我们就能够做出最优决策了

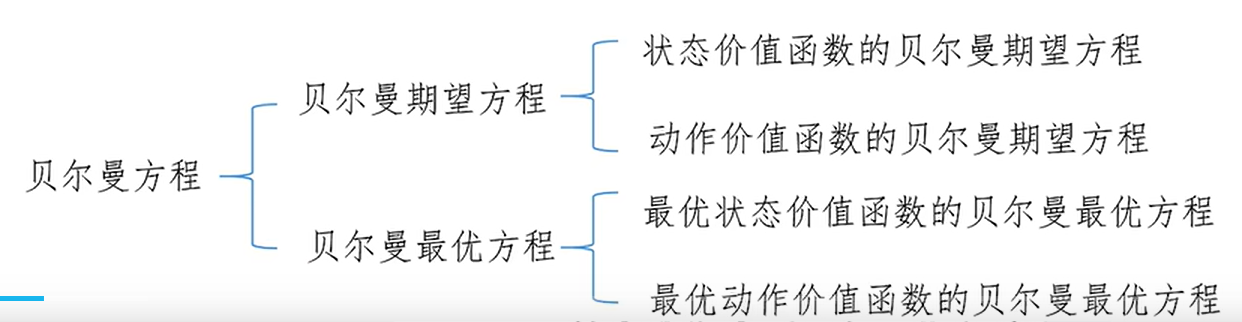
贝尔曼方程:
贝尔曼方程的作用就是用于简化最优状态/动作价值函数的计算。
贝尔曼方程的核心思想: