Token、上下文、Prompt:大模型应用开发的三个基础概念
先从一个很像真实工作日的问题说起。
你刚把第一个 AI 问答接口接进 Java 服务里,心里还挺满意。接口能通,模型也能回答,产品同学随手问了一句:
为什么这个回答有时候很准,有时候像在一本正经地胡说?
还有,为什么今天费用一下子涨上去了?你回头一看日志,发现有几次请求把整段历史对话、整页接口文档、几段数据库字段说明全都塞进去了。还有几次请求虽然用户只问了一句话,但后端拼出来的实际输入已经长得像一篇小作文。
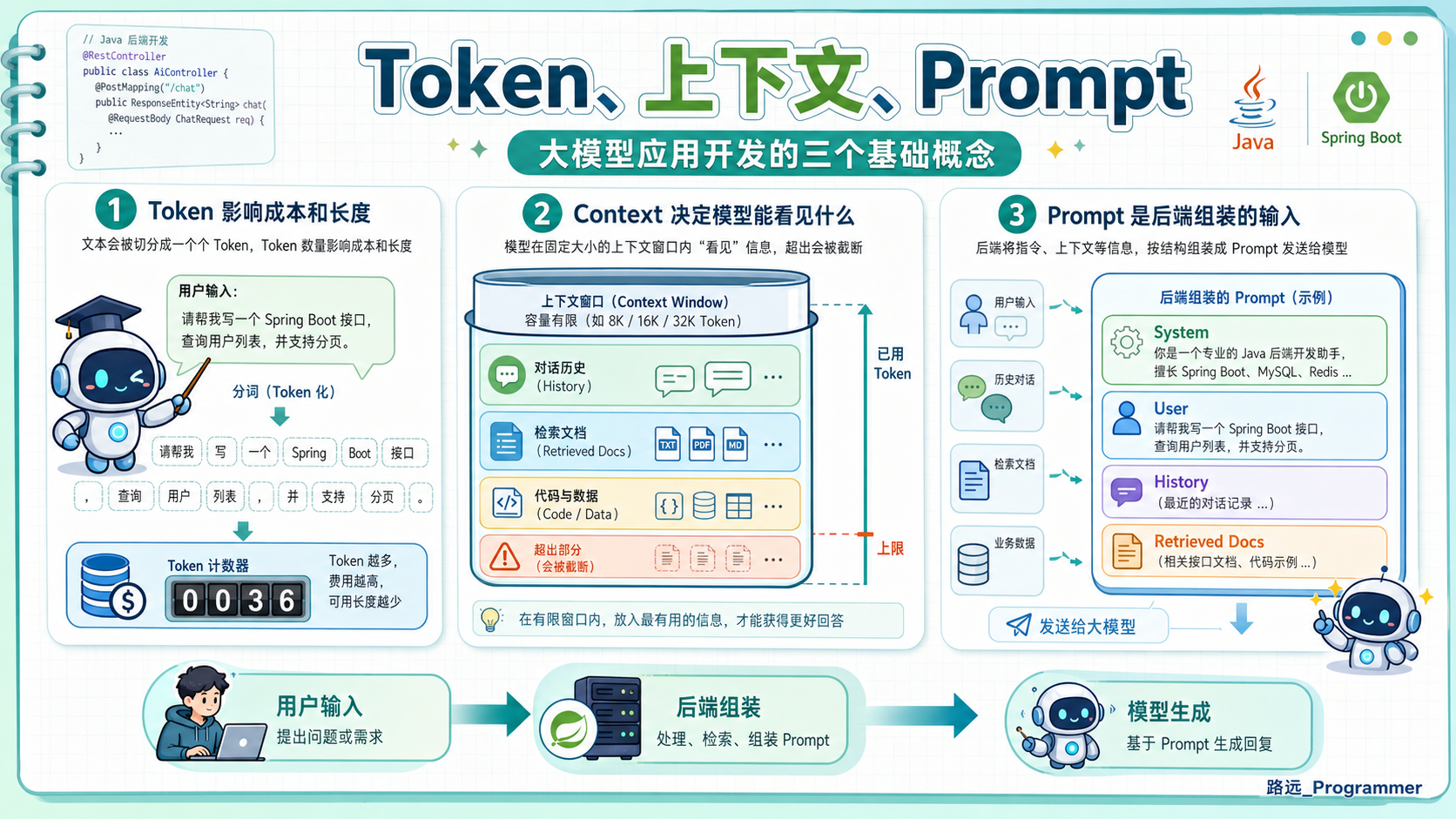
这时候很多人会第一次真正碰到三个概念:
-
Token:模型到底是怎么"计数"的 -
上下文窗口:模型一次请求里到底能看见多少东西 -
Prompt:真正发给模型的输入到底长什么样
如果这三个概念没有搞清楚,后面做 RAG、做 Tool Calling、做 Agent 时,问题只会越来越多。因为几乎所有"不稳定""太贵""答非所问""上下文超限"的问题,最后都能追到这里来。
这篇文章不讲公式,也不讲训练细节。我们只站在 Java 后端开发者的视角,把这三个概念讲清楚。
1. Token:模型不是按"字数"理解世界的
很多人刚接触大模型时,会下意识地把长度理解成"多少个字"或者"多少个单词"。
但模型内部真正处理的不是字数,而是 Token。
你可以先把它理解成:模型在读文本时切出来的一小段一小段单位。它可能是一个字、半个词、一个词的一部分,甚至可能是标点、空格或者代码符号。
这件事为什么重要?因为在大模型应用里,Token 直接影响三件事:
-
成本:很多模型按输入 Token 和输出 Token 计费
-
长度:一次请求能放多少内容,本质上受 Token 限制
-
延迟:输入越长、输出越长,模型处理通常越慢
也就是说,用户看起来只问了一句简单的话,后端真正发给模型的那份上下文,可能已经花掉了不少 Token。
比如用户输入:
帮我解释一下 RAG。看起来很短,但如果后端实际发给模型的是:
你是一个专业的 Java 后端开发助手。
请优先结合 Spring Boot、Spring AI、PostgreSQL 和企业知识库场景回答。
回答时尽量简洁,使用中文,不要编造事实。
最近三轮对话历史:...
系统补充规则:...
检索到的知识片段:...
用户问题:帮我解释一下 RAG。那真正参与计费和长度限制的,就不是用户那一句话,而是整包内容。
对 Java 后端开发者来说,一个很有用的习惯是:不要只盯着用户输入,要盯着"最终发送给模型的完整请求"。
因为真正花钱的,是后者。
2. 上下文窗口:模型不是无穷记忆,它只有一张工作台
如果说 Token 是计量单位,那 上下文窗口 可以理解成模型当前这次请求能摊开的那张工作台。
这张工作台有大小限制。
你放进去的所有内容,都会占位置:
-
System Prompt
-
用户当前问题
-
历史对话
-
检索到的文档片段
-
工具调用结果
-
结构化输出约束
-
甚至还要预留一部分空间给模型生成答案
这也是很多人一开始最容易忽略的地方。
他们会觉得:
我只是加了一点对话历史
我只是塞了一小段产品文档
我只是补了一段接口说明但模型看到的是总量,不是"每段看起来都不大"。
所以从工程角度看,上下文窗口不是一个抽象概念,而是一个很现实的预算问题。
你可以把它想象成一次 HTTP 请求里的"上下文预算表":
System Prompt 300 tokens
用户问题 80 tokens
历史对话 600 tokens
检索文档 TopK 1800 tokens
工具返回结果 400 tokens
预留输出 500 tokens
------------------------------
合计 3680 tokens如果你不做控制,问题通常会出在两个方向:
第一种是超限。
上下文一旦超过模型支持的范围,请求可能直接报错,或者被截断。最糟糕的是你自己以为"资料都传进去了",其实最关键的后半段已经没被模型看到。
第二种是虽然没超限,但信息质量下降了。
工作台再大,也不代表所有信息都值得放进去。无关历史、重复文本、过长文档、噪声数据都会稀释真正重要的内容,让模型更难抓到重点。
所以当我们说"控制上下文",并不是只为了防止报错,更是为了让模型在有限空间里看到最有价值的信息。
3. Prompt:它不是一句提示词,而是后端组装出来的输入包
很多入门文章会把 Prompt 写成一句很轻巧的话,比如:
请你扮演一个 Java 专家,回答下面的问题。这当然没错,但如果你真的在后端系统里做 AI 应用,就会很快发现,Prompt 根本不是一句话,而是一整个输入包。
在真实项目里,一个完整 Prompt 往往至少包括这些部分:
-
角色设定:模型应该扮演谁
-
任务目标:这次到底要完成什么
-
输出要求:返回自然语言、Markdown,还是 JSON
-
约束条件:不能编造、资料不足就说明不知道
-
上下文信息:历史消息、业务数据、检索片段、工具结果
-
用户问题:用户这次真正想问什么
所以更准确地说,Prompt 不是"用户说了什么",而是后端决定让模型看见什么、怎么理解、按什么方式回答。
这一点对 Java 后端开发尤其关键。
因为你以后做的很多事情,本质上都属于 Prompt 工程的一部分:
-
给知识库问答补检索片段
-
给订单助手补业务字段说明
-
给结构化输出补 JSON Schema
-
给工具调用补可用工具描述
-
给风控场景补安全限制和拒答规则
这些都不是"锦上添花",而是模型能不能稳定工作的基础设施。
4. 从 Java 后端视角看,这三者是怎么串起来的
把这三个概念放在一起看,会更清楚。
用户在前端输入一句话之后,后端通常不会原封不动地把这句话转发给模型,而是会经历一个组装过程:
用户输入
→ 后端读取系统规则
→ 拼接历史对话
→ 注入业务上下文或检索文档
→ 设置输出格式要求
→ 形成最终 Prompt
→ 发给模型
→ 模型在上下文窗口内生成结果这里面:
-
Prompt决定了你发了什么 -
Token决定了这些内容会花多少钱、占多长 -
上下文窗口决定了模型一次最多能看多少
你可以把它们理解成同一个问题的三个视角:
Prompt 是内容组织问题
Token 是成本和长度问题
上下文窗口是容量问题后面做 RAG 时,你会把检索文档塞进 Prompt。
做 Agent 时,你会把工具结果、计划步骤、观察结果也塞进 Prompt。
所以如果今天没有把这三个概念捋顺,后面系统一复杂,问题会成倍放大。
5. 一个最小 Spring AI 示例
如果你在 Java 项目里用 Spring AI,可以很直观地看到 Prompt 其实是怎么被后端组装出来的。
下面是一个简化后的示例:
String answer = chatClient.prompt()
.system("""
你是一名 Java 后端开发助手。
回答时优先结合 Spring Boot 和企业应用场景。
如果信息不足,不要编造。
""")
.user("""
背景资料:
%s
用户问题:
%s
""".formatted(retrievedDocs, question))
.call()
.content();这段代码里,真正发送给模型的输入已经不只是 question 了。
后端至少做了三件事:
-
给模型设定角色和回答规则
-
把检索到的资料拼进上下文
-
再把用户问题放进最终输入
这也正是为什么,后端同学不能把 Prompt 理解成"前端传过来的一句话"。它其实是你在服务端编排出来的一次上下文提交。
6. 三个最常见的误区
误区一:用户的问题很短,所以请求一定很便宜
不一定。
很多请求贵,不是贵在用户问题,而是贵在后端悄悄拼进去的大量历史消息、文档片段和格式约束。
误区二:上下文越多,回答一定越好
也不一定。
上下文太杂、太长、重复太多,模型反而更难抓住重点。RAG 里很多"回答不准"的问题,根本不是模型不够聪明,而是喂进去的上下文不够干净。
误区三:Prompt 就是"提示词写得漂不漂亮"
这也是误会。
在工程里,Prompt 更像一套输入协议。它决定了模型在什么边界下工作、能看到哪些资料、要按什么格式返回。
写 Prompt 不是文学创作,更多时候是在做输入设计。
7. 做系统时,真正该盯住什么
如果你接下来准备继续做 RAG 或 Agent,我建议你从现在开始养成这几个习惯:
-
记录每次请求最终发给模型的完整上下文
-
统计输入 Token、输出 Token 和总成本
-
给历史对话、检索片段、工具结果分别设预算
-
在生成答案前,为输出预留足够空间
-
不要默认"多塞一点总没坏处"
这些习惯看起来有点"后端味",但它们会直接决定你的 AI 应用后面能不能稳定演进。
8. 小结
对 Java 后端开发者来说,Token、上下文窗口、Prompt 并不是三个互相独立的术语。
它们其实描述的是同一件事:
你准备把什么内容,以多大的成本,放进模型那张有限的工作台里。
一旦理解了这件事,很多后续概念都会顺起来:
-
为什么 RAG 不能把整篇文档直接塞给模型
-
为什么检索片段需要裁剪和重排
-
为什么 Agent 一多轮就容易成本飙升
-
为什么结构化输出也会占上下文
下一篇最自然要接上的,就是把这些概念真正落到代码里:
用 Spring Boot + Spring AI 写一个最小 AI 问答接口
到那时候,我们就不只是理解概念了,而是开始把这套东西接进一个真实的 Java 服务。
资料来源
这篇文章主要参考了以下官方资料和论文,用来确认 Prompt、Token、上下文和 Spring AI 相关概念: