线性回归
线性模型之所以重要是因为我们人来在考虑问题的时候很难直接思考一个非线性模型。
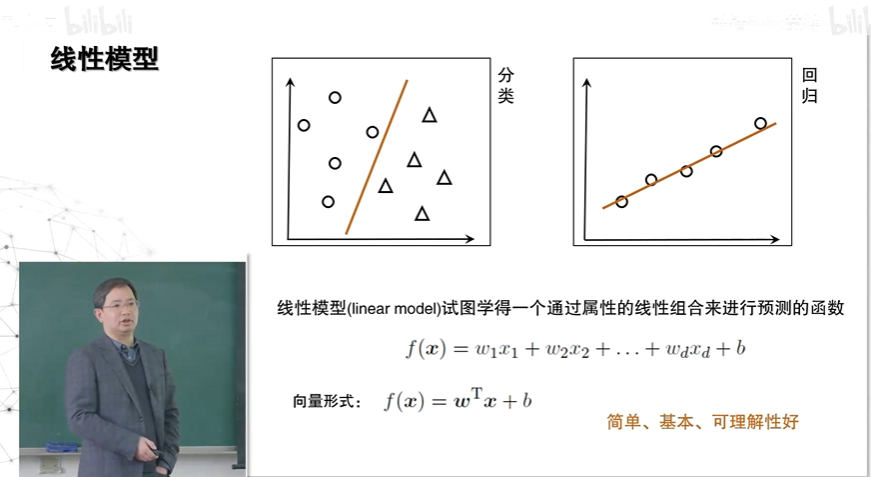
分类模型就是要找f(x) Wx +b 中的 W和b将样本分开。
回归模型就是要到f(x)Wx +b 中的 W和b将所有样本串联。
什么是线性
这是一个非常核心且容易混淆的问题。很多人会把"线性"理解成"数据分布是一条直线",但在回归分析中,"线性"指的是参数(系数)的线性,而不是自变量本身的形状。
一个模型被称为"线性",严格来说是指:因变量 Y 的预测值是参数 β 的线性组合。
数学定义: 如果你把模型写成如下形式,它就是线性的:
Y=β0+β1⋅(X1的函数)+β2⋅(X2的函数)+...
判断标准: 看 β(系数)有没有被乘、除、平方、开方,或者放在 sin/log 里面。
-
如果 β 是孤立的乘在变量前面 → 线性。
-
如果 β 出现在指数、对数、三角函数里(例如 �2β2 或 sin(�)sin(β))→ 非线性。
最大的误区
很多人看到曲线(抛物线、S形),就觉得"这是非线性的"。这是错的。
(1)线性模型也可以拟合曲线
请看下面三个式子,它们都是线性回归:
-
**直线:**Y=β0+β1X (对变量 X 线性)
-
抛物线: Y=β0+β1X+β2X2 (仍然是线性模型!)
-
周期波动: Y=β0+β1sin(X)
为什么它们是线性的?
因为这里的sin(X) 只是预处理后的新变量 。你完全可以在建模前先计算一个新X2,然后模型变成 Y=β0+β1Z,这就是一条直线。
模型从未见过曲线,它只是把高维空间的"直线"投影到低维空间,看起来像个曲线。
(2)真正的非线性模型
下面这些才是真正的非线性模型,因为 β 不再是单纯乘在前面的系数了:
-
指数增长: Y=eβ1X (β 在指数里)
-
**乘法模型:**Y=β0⋅Xβ1 (β 在指数的位置上)
线性回归

线性回归适合做数值型问题模型
线性回归适合做数值型问题的求解,不适合做分类型问题求解。原因在于数值型问题数值间存在"序"而分类问题不存在序。
线性回归是否可以做分类问题模型
也可以,只是我们需要将分类问题的输入从"分类",映射到"数值"。比如下西瓜分类中的三类属性的多个分类值:
颜色:深绿、浅绿、发白,用向量的形式表现出来就是1,0,0、0,1,0、0,0,1,这就用数值的形式表现出来了。
线性回归求解

使用求导的形式求出倒数为0的点(变化率为0)作为最优的w和b。因为最大值不存在,所以倒数为0一定代表的是最优解。
线性回归的目标是找到一条直线(或超平面),让所有数据点到这条线的垂直距离的平方和最小。这个让平方和最小的参数(权重 w 和偏置 b)就是最优解。
理论上,经典线性回归(满足数据点多于特征且特征不相关)确实有一个唯一的数学最优解;但实践中,当特征过多、特征相关或算法参数不当时,这个解要么不唯一,要么算不出来。
多元(Multi-variate)线性回归
多元线性回归 是统计学和机器学习中一种非常基础的监督学习算法。它用于研究一个因变量 (目标值,Y)与两个或两个以上自变量(特征,x1,x2,...,...,Xp)之间的线性关系。
简单来说,它是"一元线性回归"的推广:一元是拟合一条直线y=ax+b),多元是拟合一个超平面(在高维空间)。
数学模型
多元线性回归的数学模型可以表示为:
Y=β0+β1X1+β2X2+...+βpXp+ε
其中:
-
Y:因变量(我们要预测的值)
-
X1,X2,...,Xp:自变量(特征)
-
β0:截距项(当所有特征为0时,Y的期望值)
-
β1,...,βp:回归系数(每个特征对Y的边际影响,即保持其他特征不变时,该特征每变化一个单位,Y平均变化多少)
-
ε:误差项(模型未能解释的随机噪声,通常假设其服从均值为0的正态分布)
用矩阵形式表示更简洁:Y=Xβ+ε
2. 核心目标
通过已有的数据(包含 X 和 Y 的观测值),估计出最优的参数 β,使得模型预测的 Y 与真实的 Y 之间的误差最小。
最常用的估计方法是 普通最小二乘法。
3. 普通最小二乘法
思想 :最小化所有样本点的残差平方和。
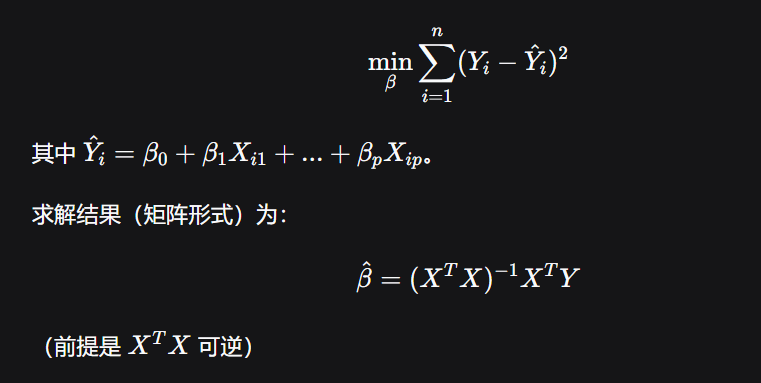
回归的函数也可以用来做分类问题
可以,但需要注意表述 :严格来说,回归函数(线性回归)不适合直接做分类 ,但通过一些关键转换,它可以成为非常强大的分类工具。更准确的说法是:基于线性回归思想的模型(如逻辑回归、线性判别分析)可以用来做分类
线性回归的思想 + 合适的激活函数
既然直接用连续值不行,那就加一个激活函数,把回归的输出压缩到 0,1 区间,解释为概率。
最经典的做法:逻辑回归
逻辑回归虽然叫"回归",但本质是分类模型。它的步骤:

为什么有效?
-
输出有概率含义(某样本属于正类的概率)
-
对异常值鲁棒(Sigmoid 会压制极值)
-
损失函数用交叉熵,而非均方误差(更适合分类)
类比:线性回归是"直接猜数字",逻辑回归是"先猜一个实数,再把它变成 0~1 之间的概率"。