一、聚类算法的简介
1. 概述
聚类算法是一种无监督学习算法,主要是根据样本之间的相似度将样本划分到不同分类中来进行结果预测的。
2. 相似度
样本的相似性可以通过样本点之间的距离来衡量。常见的相似度计算方法有:
- 欧式距离:样本点的直线距离,通过对应坐标点(维度)的差值求平方和,即勾股定理求模长。
- 曼哈顿距离:也称城市街区距离,横平竖直测量距离,通过对应坐标点(维度)的差值的绝对值求和。
- 切比雪夫距离:类似国际象棋中国王的走法(直行、横行、斜行)测量距离,通过对应坐标点(维度)的差值的绝对值求最大值。
3. 应用场景
- 客户细分:根据消费习惯、年龄、地域,将用户分成不同群组,进行精准营销。
- 图像分割:把图片中颜色、纹理相近的像素点聚成一类,从而分离出前景和背景。
- 文档分类:将内容相似的文章自动归类到同一主题。
- 异常检测:那些无法归入任何簇,或者远离所有簇的数据点,可能就是异常值(如信用卡欺诈检测)。
4. 分类
- 按聚类颗粒度划分
- 细聚类
- 粗聚类
- 按实现方法划分
- K-Means(本文重点介绍)
- 层次聚类
- DBSCAN
几种常见的聚类算法对比
| 算法名称 | 核心思路 | 优点 | 缺点 |
|---|---|---|---|
| K-Means | 预先设定K个中心点(质心),迭代更新,让每个样本点到质心的距离之后最小 | 简单快速,适合大数据集 | 需预先指定K值;对初识中心点敏感;只能发现球形簇 |
| 层次聚类 | 自底向上合并(或自上向下分类)最相似的簇,形成一个树形结构 | 不用指定K值;结果可视化为树形图 | 计算量大,不适合大数据集 |
| DBSCAN | 基于密度,将紧密相连的样本划分为一簇,并自动识别为噪声点 | 能发现任意形状的簇;能自动处理异常点 | 对密度参数敏感;在高纬数据中表现欠佳 |
| 高斯混合模型(Gaussian Mixture Model, GMM) | 假设数据由多个高斯分布混合生成,用概率模型进行软分类 | 可以给出样本属于某个簇的概率;灵活性高 | 计算较复杂;容易过拟合 |
| 谱聚类 | 将数据点视为图的顶点,根据相似度构建带权图,然后对图的拉普拉斯矩阵进行特征分解,利用特征向量进行聚类 | 能发现非凸、非球形、环状等复杂形状的簇;对高维数据有一定鲁棒性;不受数据维度灾难影响严重 | 计算开销大(需构建相似度矩阵及特征分解);对尺度参数(如高斯核带宽)敏感;聚类结果依赖图构建方式 |
二、K-Means
1. 概述
K-Means 是一种最经典、最广泛使用的基于原型的划分聚类算法。它的目标是将 nnn个样本划分到KKK个互不相交的簇(cluster)中,使得每个样本到它所属簇的中心点(centroid)的距离平方和最小。简单说:让簇内点尽可能紧凑,簇间点尽可能分离。
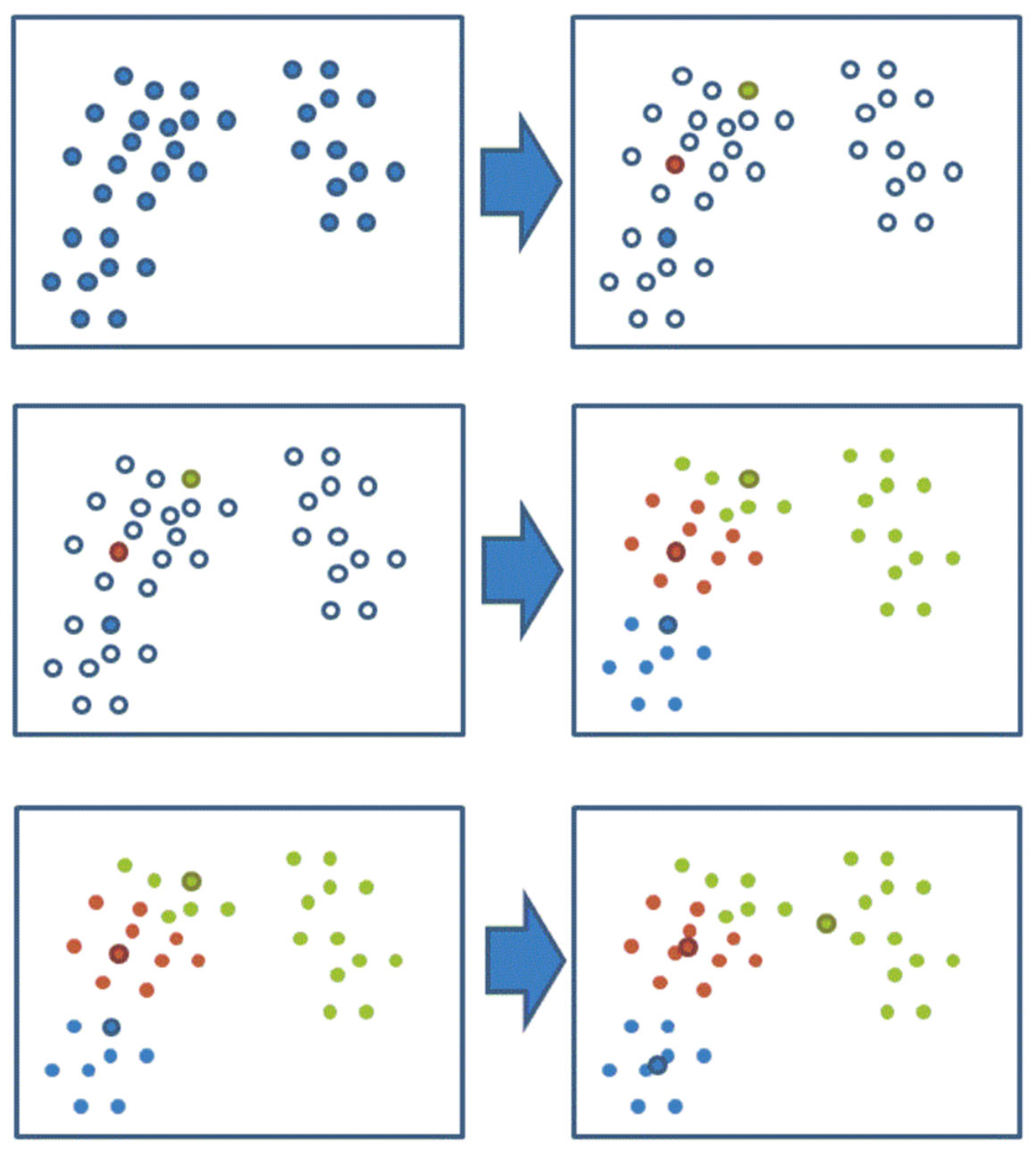
2. 实现流程
- 随机设置K个特征空间内的点作为初始的聚类中心
- 对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
- 接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
- 如果计算得出的新中心点与原中心点一样(质心不再移动),那么结束,否则重新进行第二步过程
3. 常用的评估指标
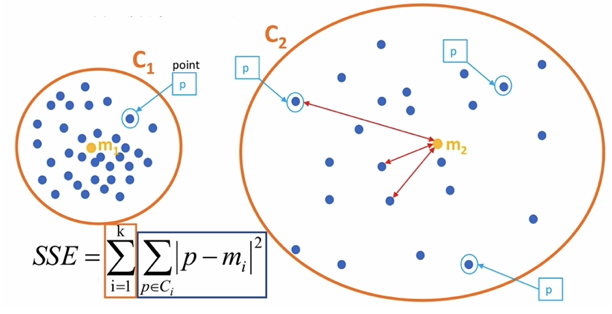
3.1 簇内误差平方和(SSE / Inertia)
- 定义:所有样本点到其所属簇中心点的距离平方之和。**SSE 越小,表示数据点越接近它们的中心,聚类效果越好。**不能单独用于选择最佳 K,通常配合"肘部法则"使用。
- 公式:SSE=∑i=1k∑p∈Ci∣p−mi∣2SSE = \sum_{i=1}^{k} \sum_{p \in C_i} |p - m_i|^2SSE=i=1∑kp∈Ci∑∣p−mi∣2
K 表示聚类中心的个数
Ci 表示簇
p 表示样本
mi 表示簇的质心
- 肘部法则(Elbow Method)
计算不同 K 值下的 SSE(簇内误差平方和),画出 K-SSE 曲线。当 SSE 下降速度明显变缓时对应的 K 即为"肘部",此时就是最佳的K值。
肘部法可以用来确定 K 值
- 对于n个点的数据集,迭代计算 k from 1 to n,每次聚类完成后计算 SSE
- SSE 是会逐渐变小的,因为每个点都是它所在的簇中心本身。
- SSE 变化过程中会出现一个拐点,下降率突然变缓时即认为是最佳 n_clusters 值。
- 在决定什么时候停止训练时,肘形判据同样有效,数据通常有更多的噪音,在增加分类无法带来更多回报时,我们停止增加类别。
3.2 轮廓系数(Silhouette Coefficient)
- 定义:结合了样本与自身簇的紧密程度(凝聚度aaa)和与最近邻簇的分离程度(分离度bbb)。SC值越大,聚类效果越好。
- 公式:s=b−amax(a,b)s = \frac{b - a}{\max(a, b)}s=max(a,b)b−a
a:样本iii到同一簇内其他点距离的平均值
b:样本iii到其他簇内其他点距离的最小值
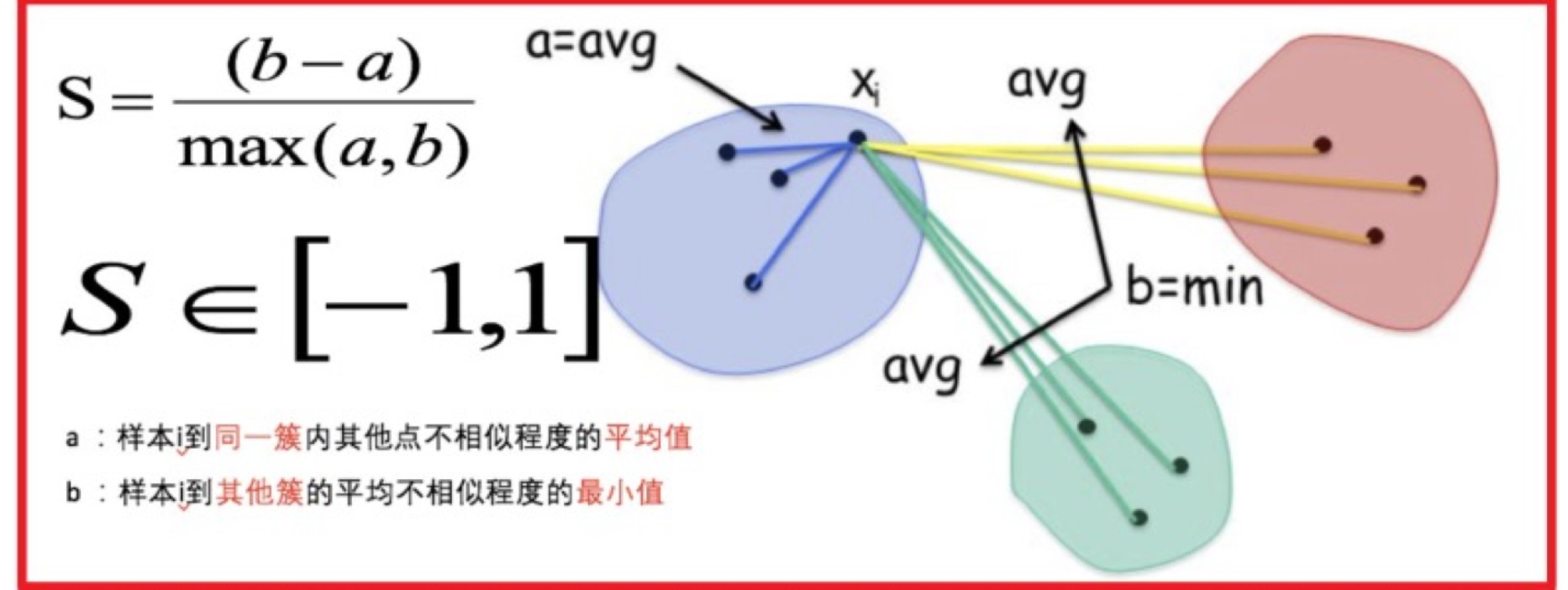
- 计算过程
- 计算每一个样本 i 到同簇内其他样本的平均距离 ai,该值越小,说明簇内的相似程度越大
- 计算每一个样本 i 到最近簇 j 内的所有样本的平均距离 bij,该值越大,说明该样本越不属于其他簇 j
- 计算所有样本的平均轮廓系数
- 轮廓系数的范围为:-1, 1,值越大聚类效果越好
3.3 卡林斯基-哈拉巴斯指数(Calinski--Harabasz Index, CHI)
- 定义:结合了聚类的凝聚度(Cohesion)和分离度(Separation)、质心的个数,希望用最少的簇进行聚类。CHI值越大,聚类效果越好。
- 公式:
CH(k)=SSBSSW⋅m−kk−1\text{CH}(k) = \frac{SSB}{SSW} \cdot \frac{m - k}{k - 1}CH(k)=SSWSSB⋅k−1m−k
SSW=∑i=1m∥xi−Cpi∥2SSW = \sum_{i=1}^{m} \|x_i - C_{p_i}\|^2SSW=i=1∑m∥xi−Cpi∥2
SSB=∑j=1knj∥Cj−Xˉ∥2SSB = \sum_{j=1}^{k} n_j \|C_j - \bar{X}\|^2SSB=j=1∑knj∥Cj−Xˉ∥2
SSW 的含义:
- Cpi 表示质心
- xi 表示某个样本
- SSW 值是计算每个样本点到质心的距离,并累加起来
- SSW 表示表示簇内的内聚程度,越小越好
- m 表示样本数量
- k 表示质心个数
SSB 的含义:
- Cj 表示质心,X 表示质心与质心之间的中心点,nj 表示样本的个数
- SSB 表示簇与簇之间的分离度,SSB 越大越好
评估指标案例演示
python
"""
案例:
演示聚类算法的评估指标, 即: SSE + 肘部法, SC轮廓系数法, CH轮廓系数法
聚类算法的评估指标:
思路1: SSE + 肘部法
SSE:
概述:
所有簇的所有样本到该簇心的误差的平方和
特点:
随着K值的增加, SSE会逐渐减少
目标:
SSE值越小, 代表簇内样本越聚集, 内聚程度越高
肘部法:
K值增大, SSE值会随之减小, 下降梯度陡然变缓的时候, 那个K值, 就是我们要的最佳值
思路2: SC轮廓系数
考虑簇内 -> 聚集程度, 越小越好
考虑簇外 -> 分离程度, 越大越好
思路3: CH轮廓系数
考虑簇内 -> 聚集程度, 越小越好
考虑簇外 -> 分离程度, 越大越好
考虑K值 -> K值越小, 代表簇内样本越聚集, 内聚程度越高
"""
# 导包
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.metrics import calinski_harabasz_score, silhouette_score
# 1. 定义函数, 演示: SSE + 肘部法
def dm01_sse():
# 1. 定义sse列表, 记录: 每个K值的SSE值
sse_list = []
# 2. 生成数据集
# 参1: 样本数量, 参2: 特征数量, 参3: 4个簇, 参4: 4个簇std标准差, 参5: 随机种子
x, y = make_blobs(
n_samples=1000,
n_features=2,
centers=[[-1, 1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.2, 0.2, 0.2],
random_state=23
)
# 3. for循环遍历, 获取到每个K值, 计算对应的sse值, 并添加到sse_list列表中
for k in range(1, 100):
# 3.1 创建KMeans对象, 指定K值, 迭代次数, 随机种子
estimator = KMeans(n_clusters=k, random_state=23)
# 3.2 训练模型
estimator.fit(x)
# 3.3 模型预测, 此处略
# 3.4 获取到每个sse值
sse_value = estimator.inertia_
# 3.5 把sse值添加到sse_list列表中
sse_list.append(sse_value)
# 4. 绘制SSE曲线 -> 数据的可视化
# 4.1 创建画布, 指定画布大小
plt.figure(figsize=(20, 10))
# 4.2 设置标题
plt.title("sse value")
# 4.3 设置x轴刻度
plt.xticks(range(0, 100, 3))
# 4.4 添加x轴, y轴标签
plt.xlabel('k')
plt.ylabel('sse')
# 4.5 绘制网格
plt.grid()
# 4.6 绘制折线图
# 参1: K值, 参2: 该K值对应的sse值
plt.plot(range(1, 100), sse_list)
# 4.7 显示折线图
plt.show()
# 2. 定义函数, 演示: SC轮廓系数法
def dm02_sc():
# 1. 定义sc列表, 记录: 每个K值的sc值
sc_list = []
# 2. 生成数据集
# 参1: 样本数量, 参2: 特征数量, 参3: 4个簇, 参4: 4个簇std标准差, 参5: 随机种子
x, y = make_blobs(
n_samples=1000,
n_features=2,
centers=[[-1, 1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.2, 0.2, 0.2],
random_state=23
)
# 3. for循环遍历, 获取到每个K值, 计算对应的sc值, 并添加到sc_list列表中
for k in range(2, 100): # 考虑簇外, 至少2个簇
# 3.1 创建KMeans对象, 指定K值, 迭代次数, 随机种子
estimator = KMeans(n_clusters=k, random_state=23)
# 3.2 训练模型
estimator.fit(x)
# 3.3 模型预测
y_pred = estimator.predict(x)
# 3.4 获取到每个sc值
sc_value = silhouette_score(x, y_pred)
# 3.5 把sc值添加到sc_list列表中
sc_list.append(sc_value)
# 4. 绘制sc曲线 -> 数据的可视化
# 4.1 创建画布, 指定画布大小
plt.figure(figsize=(20, 10))
# 4.2 设置标题
plt.title("sc value")
# 4.3 设置x轴刻度
plt.xticks(range(0, 100, 3))
# 4.4 添加x轴, y轴标签
plt.xlabel('k')
plt.ylabel('sc')
# 4.5 绘制网格
plt.grid()
# 4.6 绘制折线图
# 参1: K值, 参2: 该K值对应的sc值
plt.plot(range(2, 100), sc_list)
# 4.7 显示折线图
plt.show()
# 3. 定义函数, 演示: CH轮廓系数法
def dm03_ch():
# 1. 定义ch列表, 记录: 每个K值的ch值
ch_list = []
# 2. 生成数据集
# 参1: 样本数量, 参2: 特征数量, 参3: 4个簇, 参4: 4个簇std标准差, 参5: 随机种子
x, y = make_blobs(
n_samples=1000,
n_features=2,
centers=[[-1, 1], [0, 0], [1, 1], [2, 2]],
cluster_std=[0.4, 0.2, 0.2, 0.2],
random_state=23
)
# 3. for循环遍历, 获取到每个K值, 计算对应的ch值, 并添加到ch_list列表中
for k in range(2, 100): # 考虑簇外, 至少2个簇
# 3.1 创建KMeans对象, 指定K值, 迭代次数, 随机种子
estimator = KMeans(n_clusters=k, random_state=23)
# 3.2 训练模型
estimator.fit(x)
# 3.3 模型预测
y_pred = estimator.predict(x)
# 3.4 获取到每个ch值
ch_value = calinski_harabasz_score(x, y_pred)
# 3.5 把ch值添加到ch_list列表中
ch_list.append(ch_value)
# 4. 绘制ch曲线 -> 数据的可视化
# 4.1 创建画布, 指定画布大小
plt.figure(figsize=(20, 10))
# 4.2 设置标题
plt.title("ch value")
# 4.3 设置x轴刻度
plt.xticks(range(0, 100, 3))
# 4.4 添加x轴, y轴标签
plt.xlabel('k')
plt.ylabel('ch')
# 4.5 绘制网格
plt.grid()
# 4.6 绘制折线图
# 参1: K值, 参2: 该K值对应的ch值
plt.plot(range(2, 100), ch_list)
# 4.7 显示折线图
plt.show()
# 4. 测试
if __name__ == '__main__':
# dm01_sse()
# dm02_sc()
dm03_ch()4. 案例演示
已知:客户性别、年龄、年收入、消费指数
需求:对客户进行分析,找到业务突破口,寻找黄金客户
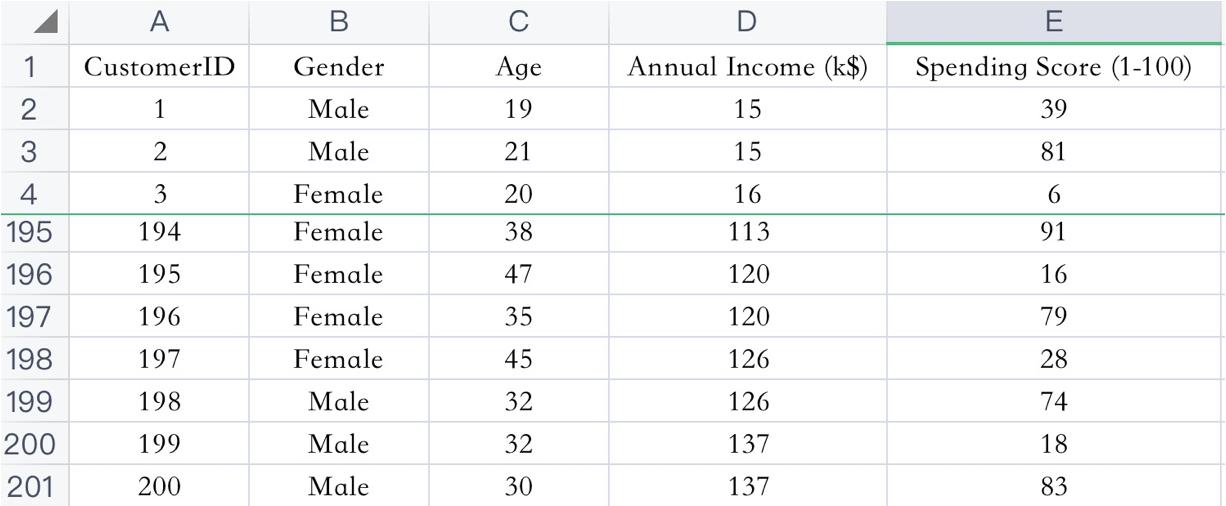
数据集共包含顾客的数据, 数据共有 4 个特征, 数据共有 200 条。接下来,使用聚类算法对具有相似特征的的顾客进行聚类,并可视化聚类结果。
python
"""
案例:
基于用户的年收入和消费指数, 根据用户的相似性进行聚类
"""
# 导包
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.metrics import calinski_harabasz_score, silhouette_score
import pandas as pd
# 1. 定义函数, 找聚类的脂心数(K值)
def dm01_find_k():
# 1. 加载数据集
df = pd.read_csv('data/customers.csv')
# df.info()
# print(df.head())
# 2. 定义sse_list, sc_list, 记录不同k值评估效果
sse_list = [] # sse: 只考虑簇内, 越小越好
sc_list = [] # sc: 考虑簇内和簇间, 越大越好
# 抽取特征
x = df.iloc[:, 3:5]
# print(x.head())
# 3. 定义for循环, 训练不同k值的评估效果
for k in range(2, 20):
# 4. 创建模型对象
estimator = KMeans(n_clusters=k, max_iter=100, random_state=23)
# 5. 模型训练
estimator.fit(x)
# 6. 模型预测
y_pred = estimator.predict(x)
# 7. 分别把评分添加到对应的列表中
sse_list.append(estimator.inertia_)
sc_list.append(silhouette_score(x, y_pred))
# 4. 绘制折线, 看看K值哪个最好
plt.figure(figsize=(20, 10))
plt.plot(range(2, 20), sse_list, label='SSE')
plt.show()
plt.figure(figsize=(20, 10))
plt.plot(range(2, 20), sc_list, label='SC')
plt.show()
# 2. 定义函数, 实现: 模型训练, 模型预测, 模型评估
def dm02_train_predict_evaluate():
# 1. 加载数据集
df = pd.read_csv('data/customers.csv')
# 2. 提取特征
x = df.iloc[:, 3:5]
# print(x.head())
# 3. 模型训练. k=5是刚才通过sse + 肘部法, SC轮廓系数获取出来的
estimator = KMeans(n_clusters=5, max_iter=100, random_state=23)
estimator.fit(x)
# 4. 模型预测
y_pred = estimator.predict(x)
print(f'模型的预测结果为: {y_pred}')
# 5. 绘制5个簇的样本点 -> 散点图
plt.scatter(x.values[y_pred == 0, 0], x.values[y_pred == 0, 1], c='r', label='Standard')
plt.scatter(x.values[y_pred == 1, 0], x.values[y_pred == 1, 1])
plt.scatter(x.values[y_pred == 2, 0], x.values[y_pred == 2, 1])
plt.scatter(x.values[y_pred == 3, 0], x.values[y_pred == 3, 1])
plt.scatter(x.values[y_pred == 4, 0], x.values[y_pred == 4, 1])
# 6. 绘制5个簇的质心 -> 散点图
plt.scatter(estimator.cluster_centers_[:, 0], estimator.cluster_centers_[:, 1], c='black', label='Centroids')
# 7. 设置标题, x轴, y轴标签
plt.title('Clusters of Customers')
plt.xlabel('Annual Income(k$)')
plt.ylabel('Spending Score(1-100)')
plt.legend()
plt.show()
# 3. 测试
if __name__ == '__main__':
# dm01_find_k()
dm02_train_predict_evaluate()